Migración a Elastic Common Schema (ECS) en ambientes de Beats
En febrero de 2019, presentamos Elastic Common Schema (ECS) con un blog y webinar correspondientes. A modo de recapitulación breve: mediante la definición de un conjunto común de campos y tipos de datos, ECS permite una búsqueda, visualización y análisis uniformes de fuentes de datos dispares. Es una ventaja importante para los entornos heterogéneos compuestos por distintos estándares de proveedor en los que el uso simultáneo de fuentes de datos similares, pero diferentes, es frecuente.
También hablamos sobre cómo la implementación de ECS no es una tarea trivial. El hecho es que para producir eventos compatibles con ECS, muchos de los campos emitidos por las fuentes de eventos deben copiarse o cambiar de nombre durante el proceso de ingesta de datos.
Cerramos la introducción a ECS mencionando que si ya has configurado una plantilla de índice de Elasticsearch y has escrito algunas funciones de transformación con los pipelines de ingesta de Logstash o Elasticsearch, tendrás buena noción de lo que esto implica. Según cómo hayas diseñado tus pipelines de ingesta de datos del Elastic Stack, variará la cantidad de trabajo necesaria para migrar tu entorno a ECS. En un extremo del espectro, Beats y los módulos de Beats permitirán una migración curada a ECS. Los eventos de Beats 7 ya están en formato ECS, y lo único que queda por hacer es establecer una conexión entre el contenido de análisis existente y los datos de ECS nuevos. En el otro extremo del espectro se encuentran todos los tipos de pipelines personalizados creados por los usuarios.
En junio también organizamos un webinar sobre cómo migrar a ECS. En este blog se amplían los temas tratados en este webinar y se analiza en más detalle la migración a ECS en entornos de Beats. La migración de los pipelines de ingesta de datos personalizados a ECS se tratará en un próximo blog.
Este es un resumen de lo que se incluye en este blog:
- Migración a ECS con el Elastic Stack 7
- Visión general conceptual de una migración a ECS
- Visión general de la migración de un entorno de Beats a ECS
- Creación de una estrategia de migración propia
- Ejemplo de migración
- Conclusión
- Referencias
Migración a ECS con el Elastic Stack 7
Dado que cambiar los nombres de muchos campos de evento usados por Beats sería un cambio trascendental para los usuarios, introdujimos los nombres de campo de ECS en el lanzamiento principal más reciente, el Elastic Stack versión 7.
Este blog comienza con una visión general de alto nivel sobre la migración a ECS con Beats en el contexto de una actualización desde el Elastic Stack 6.8 al 7.2. Luego seguiremos con un ejemplo de migración paso a paso de una fuente de eventos de Beats.
Es importante tener en cuenta que este blog solo abarcará una parte de una migración a la versión 7. Tal como se sugiere en las pautas de actualización del Elastic Stack, se debe actualizar Beats después de Elasticsearch y Kibana. Por lo tanto, el ejemplo de migración que se incluye en este blog solo abarcará la actualización de Beats, y se supondrá que Elasticsearch y Kibana ya están actualizados a la versión 7. Esto nos permitirá enfocarnos en las cuestiones específicas de la actualización de Beats a ECS desde un esquema previo a ECS.
Cuando planifiques la migración al Elastic Stack 7, asegúrate de revisar las pautas mencionadas anteriormente, echa un vistazo al asistente de actualización de Kibana y, por supuesto, revisa detenidamente las notas de actualización y los cambios trascendentales correspondientes a cualquier parte del Elastic Stack que estés usando.
Nota: Si estás considerando adoptar Beats y no tienes datos de Beats 6, no debes preocuparte por la migración. Puedes simplemente comenzar a usar Beats versión 7.0 o posterior, que genera eventos con el formato de ECS desde el primer momento.
Visión general conceptual de una migración a ECS
Cualquier migración a ECS involucrará los pasos siguientes:
- Traducir tus fuentes de datos a ECS
- Resolver diferencias y conflictos entre el formato de eventos previo a ECS y los eventos de ECS
- Ajustar el contenido de análisis, pipelines y aplicaciones para que consuman eventos de ECS
- Hacer compatibles con ECS los eventos con formato previo a ECS para facilitar la transición
- Eliminar los alias de campo una vez migradas todas las fuentes a ECS
En este blog, analizaremos cada uno de estos pasos específicamente en el contexto de migración de un entorno de Beats a ECS.
Después de la visión general a continuación, veremos un ejemplo paso a paso de actualización de un Filebeat module de la versión 6.8 a la 7.2. Este ejemplo de migración está diseñado para que puedas seguirlo con facilidad en tu estación de trabajo, realizar cada parte de la migración y experimentar mientras lo haces.
Visión general de la migración de un entorno de Beats a ECS
Existen muchas formas de abordar cada parte de la migración descrita anteriormente. Analicemos cada una en el contexto de migración de los eventos de Beats a ECS.
Traducir las fuentes de datos a ECS
Beats incluye muchas fuentes de eventos curadas. A partir de Beats 7.0, cada una ya está convertida al formato de ECS. Los procesadores de Beats que agregan metadatos a tus eventos (como add_host_metadata) también fueron convertidos a ECS.
Sin embargo, es importante comprender que Beats, en ocasiones, funciona como un simple transporte de tus eventos. Algunos ejemplos de esto son los eventos recopilados por Winlogbeat y Journalbeat, al igual que cualquier entrada de Filebeat a través de la cual consumas eventos y logs personalizados (distintos de los Filebeat modules en sí). Deberás mapear cada fuente de eventos personalizada que actualmente estés recopilando y parseando por tu cuenta a ECS.
Resolver los conflictos y las diferencias de esquema
La naturaleza de esta migración a ECS es estandarizar los nombres de campo en muchas fuentes de datos. Esto significa que se le cambiará el nombre a muchos campos.
Cambio de nombres de campo y alias de campo
Existen algunas maneras de trabajar con eventos de ECS y previos a ECS durante la transición entre los dos formatos. Estas son las opciones principales:
- Usar alias de campo de Elasticsearch para que los índices nuevos reconozcan los nombres de campo anteriores
- Duplicar datos en el mismo evento (completando los campos anteriores y los campos de ECS)
- No hacer nada: el contenido antiguo funciona solo con datos antiguos, el contenido nuevo funciona solo con datos nuevos
El enfoque más simple y económico es usar alias de campo de Elasticsearch. Esta es la ruta de migración elegida para el procedimiento de actualización de Beats.
Sin embargo, los alias de campo tienen algunas limitaciones y no son una solución perfecta. Hablemos sobre sus beneficios y limitaciones.
Los alias de campo son simplemente campos adicionales en el mapping de Elasticsearch de índices nuevos. Permiten que los índices nuevos respondan a búsquedas usando los nombres de campo anteriores. Veamos un ejemplo, simplificado para mostrar solo un campo:
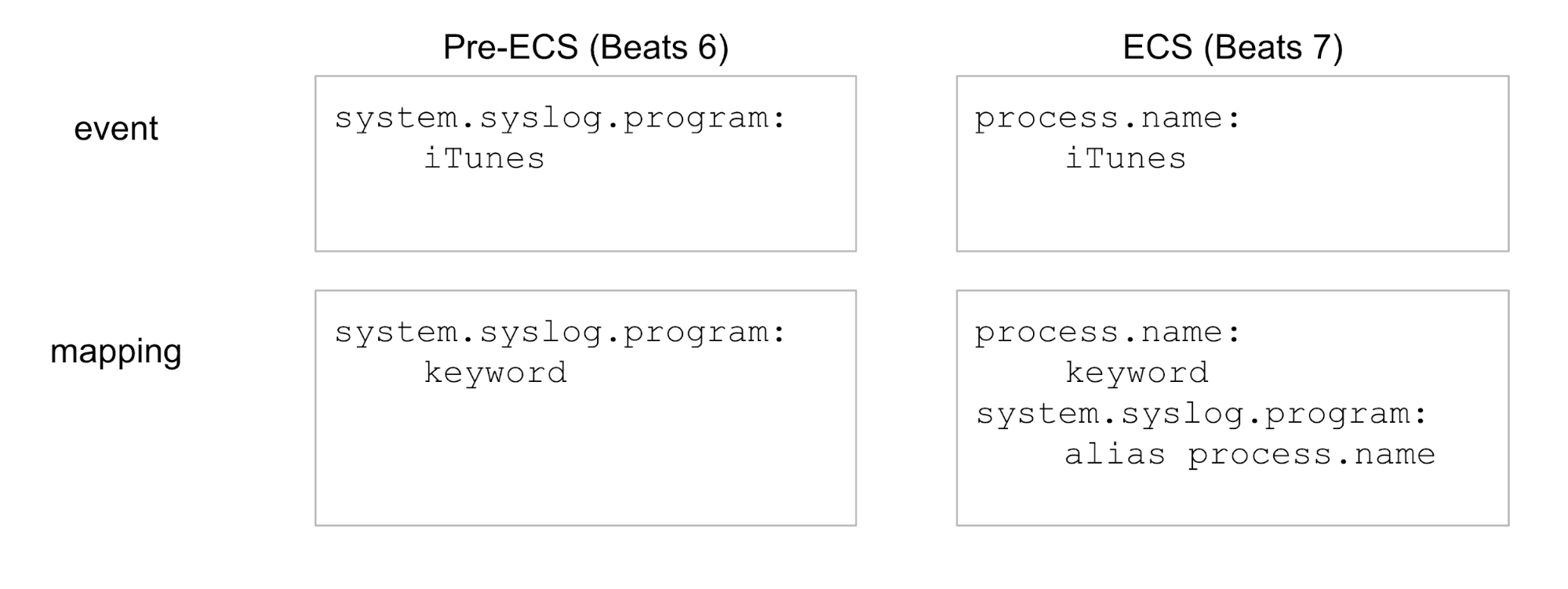
Más precisamente, los alias de campo ayudarán con lo siguiente:
- Agregaciones y visualizaciones en el campo de alias
- Filtrado y búsqueda en el campo de alias
- Autocompletado en el campo de alias
Estas son las advertencias de los alias de campo:
- Los alias de campo son exclusivamente una característica de mapping de Elasticsearch (el índice de búsqueda). Como tal, no modifican la fuente de documentos ni sus nombres de campo. El documento está compuesto ya sea por nombres de campo antiguos o por nuevos. A modo de ejemplo, estos son algunos lugares en los que los alias no ayudan, debido a que se accede a los campos directamente en el documento:
- Las columnas que se muestran en las búsquedas guardadas
- Procesamiento adicional en tu pipeline de ingesta de datos
- Cualquier aplicación que consuma tus eventos de Beats (por ejemplo, mediante la API de Elasticsearch)
- Como los alias de campo son entradas de campo en sí, no podemos crear alias cuando hay un campo de ECS nuevo con el mismo nombre.
- Los alias de campo solo funcionan con campos de hoja; no pueden asignar un alias a campos complejos como campos
object, que contienen otros campos anidados.
Estos alias de campo no se crean de forma predeterminada en los índices de Beats 7. Deben habilitarse estableciendo migration.6_to_7.enabled: true en cada archivo de configuración YAML de Beats antes de ejecutar el paso de configuración de Beats. Esta opción y los alias correspondientes estarán disponibles durante la vida útil del Elastic Stack 7.x y se eliminarán en la versión 8.0.
Conflictos
Al migrar a ECS, es posible que encuentres conflictos de campos, según las fuentes que uses.
Es importante tener en cuenta que algunos tipos de conflictos solo se detectan en los campos que estás usando. Esto significa que no te afectará cualquier cambio o conflicto en fuentes que no estés usando. Pero también significa que cuando planifiques la migración, debes ingestar muestras de eventos de cada una de las fuentes de datos en ambos formatos (Beats 6 y 7) en el entorno de prueba para descubrir todos los conflictos que deberás solucionar.
Los conflictos serán de dos tipos:
- El tipo de datos de un campo está cambiando a un tipo más apropiado.
- Un nombre de campo en uso previo a ECS también está definido en ECS, pero tiene un significado diferente; los llamaremos campos incompatibles.
Las consecuencias precisas de cada tipo de conflicto variarán. Pero, en general, cuando un campo cambia de tipo de datos o si un campo incompatible también cambia con respecto al anidado (por ejemplo, un campo de palabra clave se convierte en un campo de objeto), no podrás realizar búsquedas en el campo en fuentes previas a ECS y fuentes de ECS al mismo tiempo.
A medida que los datos ingresan a los índices de Beats 6 y 7, actualizar los patrones de índice de Kibana revelará estos conflictos. Si después de actualizar el patrón de índice no se observa ninguna advertencia de conflicto, no quedan conflictos por resolver. Si recibes una advertencia, puedes configurar el selector de tipo de datos para que muestre solo los conflictos:

La forma de lidiar con estos conflictos será reindexar los datos anteriores para que sean más compatibles con el esquema nuevo. Los conflictos causados por los cambios de tipo son bastante sencillos de resolver. Puedes simplemente sobrescribir los patrones (template) de índice de Beats 6 para que usen el tipo de datos más adecuado, reindexar a un índice nuevo (para que haga efecto el mapping actualizado) y luego borrar el índice anterior.
Si tienes campos incompatibles, tendrás que decidir si borrarlos o cambiarles el nombre. Si cambias el nombre del campo, asegúrate de definirlo primero en tu patrón de índice.
Ajustar el entorno para el consumo de eventos de ECS
Con el cambio de nombre de tantos campos, el contenido del análisis de muestra (por ejemplo, dashboards) proporcionado con Beats se modificó para usar los nombres de campo de ECS nuevos. El contenido nuevo funcionará solo con los datos de ECS producidos por Beats 7.0 y posterior. Dicho esto, la configuración de Beats no sobrescribirá tu contenido de Beats 6 existente, sino que creará una segunda copia de cada visualización de Kibana. Cada visualización de Kibana nueva tiene el mismo nombre que la anterior y se le agrega “ECS” al final.
El contenido de muestra de Beats 6 y tu contenido personalizado basado en este esquema antiguo seguirán funcionando, mayormente, con datos de Beats 6 y 7 gracias a los alias de campo. Como mencionamos anteriormente, sin embargo, los alias de campo son solo una solución parcial y temporal para ayudar con la migración a ECS. Por lo tanto, parte de la migración también debería incluir la actualización o duplicación de los dashboards customizados para comenzar a usar los nombres de campo nuevos.
Ejemplifiquemos esto con una tabla:
|
Previo a ECS (Beats 6, tus dashboards customizados) |
ECS (Beats 7) |
| [Filebeat System] Syslog dashboard | [Filebeat System] Syslog dashboard ECS |
|
|
Además de revisar y modificar el contenido de análisis en Kibana, también deberás revisar cualquier parte personalizada de tu pipeline de eventos y las aplicaciones que acceden a los eventos de Beats mediante la API de Elasticsearch.
Hacer compatibles con ECS los eventos con formato previo a ECS
Ya hablamos sobre usar la reindexación para abordar conflictos de tipos de datos y campos incompatibles. La reindexación para abordar estos dos tipos de cambios es opcional, pero bastante sencilla de implementar y, por lo tanto, probablemente valga la pena en la mayoría de los casos. Ignorar los conflictos también puede ser una solución viable en casos de uso simples, pero ten en cuenta que los potenciales conflictos de campo te afectarán desde el momento en que comiences a ingestar datos de Beats 7 hasta que Beats 6 expire en el cluster.
Reindexación
Si el soporte proporcionado por los alias de campo no es suficiente en tu situación, también puedes reindexar datos anteriores para reponer los nombres de campo de ECS en tus datos de Beats 6. Esto garantiza que todo el contenido de análisis nuevo que depende de los campos de ECS (contenido de Beats 7 nuevo y tu contenido personalizado actualizado) podrá buscar en los datos antiguos además de en los datos de Beats 7.
Modificación de eventos durante la ingesta de datos
Si prevés un período de lanzamiento prolongado para los agentes de Beats 7, puedes ir más allá simplemente reindexando los índices anteriores. También puedes modificar los eventos de Beats 6 entrantes durante la ingesta de datos.
Existen algunas maneras de reindexar y realizar manipulaciones en el documento, como copiar, eliminar o cambiar el nombre de los campos. La forma más sencilla es usar los pipelines de ingesta de Elasticsearch. Estas son algunas ventajas:
- Son fáciles de probar con la API _simulate.
- Puedes usar el pipeline para reindexar índices anteriores.
- Puedes usar el pipeline para modificar los eventos de Beats 6 que siguen ingresando.
Para modificar los eventos a medida que ingresan, en la mayoría de los casos simplemente necesitas establecer la configuración de “pipeline” de salida de Elasticsearch para que envíe al pipeline. Esto sucede en Logstash y Beats.
Ten en cuenta que los Filebeat modules ya usan pipelines de ingesta para realizar el parseo. También es posible modificarlos, solo necesitas sobrescribir los pipelines de Filebeat 6 y agregar una llamada a tu pipeline de ajuste.
Eliminar los alias de campo
Cuando ya no necesites los alias de campo, deberías considerar eliminarlos. Ya mencionamos que son más livianos que duplicar todos los datos. Sin embargo, aún así consumen memoria en el estado de cluster, un recurso crítico. También aparecen en autocompletar de Kibana y ocupan recursos innecesariamente.
Para eliminar tus alias de campo antiguos, simplemente elimina (o establece en false) la configuración migration.6_to_7.enabled en Beats (por ejemplo, filebeat.yml), vuelve a realizar la operación “setup” (configuración) y sobrescribe la plantilla.
Ten en cuenta que una vez sobrescribas las plantillas para que ya no incluyan alias, aún deberás esperar a que los índices se implementen para que los mappings de índice no contengan los alias. Luego, cuando los índices estén implementados, tienes que esperar a que los datos de Beats 7 que contenían los alias expiren en el cluster para que desaparezcan por completo.
Creación de una estrategia de migración propia
Repasamos lo que proporciona Beats para ayudar con la migración de los datos de Beats a ECS. También hablamos sobre los pasos adicionales que puedes tomar para que la migración sea más fluida.
Debes evaluar el trabajo necesario para cada fuente de datos de forma independiente. Es posible que tengas la opción de hacer menos en las fuentes de datos menos críticas.
Estos son algunos criterios que puedes tener en cuenta cuando revisas cada fuente de datos:
- ¿Cuál es el período de retención? ¿Se estipula de forma externa? ¿Tienes la opción de eliminar datos antes en el transcurso de la migración?
- ¿Necesitas continuidad en los datos? ¿O puedes permitir una transición? Esto te ayudará a saber si necesitas realizar una reposición, como se describió anteriormente.
- ¿Cuánto tiempo demorará tu lanzamiento de Beats 7? ¿Necesitas modificar los eventos de Beats 6 a medida que ingresan?
Si planeas reponer muchos campos, deberías echar un vistazo a dev-tools/ecs-migration.yml en el repositorio de Beats. En este archivo se enumeran todos los cambios de campo para la migración de Beats 6 a 7.
Ejemplo de migración
En el resto de este blog, te mostraremos paso a paso cómo puedes migrar a ECS actualizando de Beats 6.8 a 7.2, los beneficios y las limitaciones de los alias, cómo resolver conflictos, cómo reindexar datos anteriores recientes para ayudar en la transición y también cómo modificar los eventos de Beats 6 que siguen ingresando. En este ejemplo, usaremos el módulo de Syslog de Filebeat.
Como ya mencionamos, en este ejemplo no se abarca la actualización completa del Elastic Stack. Supondremos que Elasticsearch y Kibana ya se actualizaron a la versión 7 para poder enfocarnos en cómo llevar a cabo la actualización del esquema de datos a ECS.
Si quieres ir siguiendo los pasos, usa la versión más reciente de Elasticsearch 7 y Kibana 7. Puedes usar una cuenta de Elastic Cloud de prueba gratuita o ejecutarlos de forma local siguiendo las instrucciones de instalación de Elasticsearch y Kibana.
Ejecución de Beats 6.8
En esta demostración, ejecutaremos Filebeat 6.8 y 7.2 al mismo tiempo en la misma máquina. Por lo tanto, es importante instalar ambas versiones con una instalación de archivo (usando el archivo .zip o .tar.gz). Las instalaciones de archivo están autocontenidas en su directorio y facilitarán el proceso.
Con Elasticsearch y Kibana 7 en ejecución, instala Filebeat 6.8. Si tienes Windows, puedes experimentar instalando Winlogbeat en su lugar.
En la mayoría de los sistemas, Syslog usa la hora local para las marcas de tiempo sin especificar la zona horaria. Configuraremos Filebeat para agregar la zona horaria en cada evento mediante el procesador add_locale, luego configuraremos el pipeline del módulo del sistema para interpretar la zona horaria conforme a este. Esto garantizará que podamos validar la migración a ECS más adelante cuando observemos los eventos recibidos recientemente.
En filebeat.yml, busca la sección “processors” (procesadores) y agrega el procesador add_locale. Debajo de la sección de procesadores, agrega la configuración de módulo siguiente:
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_locale: ~
filebeat.modules:
- module: system
syslog:
var.convert_timezone: true
Si ejecutas Elasticsearch y Kibana de forma local, lo anterior debería ser suficiente. Si usas Elastic Cloud, también deberás agregar tus credenciales de nube a filebeat.yml; ambas pueden encontrarse en Elastic Cloud cuando creas un cluster:
cloud.id: 'my-cluster-name:a-very-long-string....' cloud.auth: 'username:password'
Ahora preparemos Filebeat 6.8 para capturar logs del sistema:
./filebeat setup -e ./filebeat -e
Observemos el dashboard denominado [Filebeat System] Syslog dashboard para confirmar que los datos están ingresando. Deberíamos ver los eventos de Syslog más recientes generados en el sistema en el que se instaló Filebeat.
Este dashboard es interesante porque incluye visualizaciones y una búsqueda guardada. Esto será útil para demostrar los beneficios y las limitaciones de los alias de campo.
Ejecución de Beats 7 (ECS)
Enfrentémoslo: no todos los entornos pueden hacer una transición instantánea de una versión de Beats a otra. Los eventos probablemente ingresarán desde Filebeat 6 y 7 en forma simultánea durante un tiempo. Así que, hagamos exactamente lo mismo en este ejemplo.
Para lograrlo, podemos simplemente ejecutar Filebeat 7.2 junto a la versión 6.8 en el mismo sistema. Extraeremos Filebeat 7.2 en un directorio diferente y aplicaremos los mismos cambios de configuración que aplicamos en la versión 6.8.
Pero todavía no ejecutes la configuración. En Beats 7, también necesitamos habilitar la configuración de migración, que crea alias de campo. Elimina el comentario de esta línea al final de todo en filebeat.yml:
migration.6_to_7.enabled: true
Nuestro archivo de configuración de la versión 7.2 ahora debería contener este atributo de migración adicional, el procesador add_locale, la configuración del módulo del sistema y, en caso de ser necesario, nuestras credenciales de nube.
Pongamos en marcha Filebeat 7.2 desde otra terminal:
./filebeat setup -e ./filebeat -e
Conflictos
Antes mirar los dashboards, vayamos directamente a la gestión de índices de Kibana para confirmar que se haya creado el índice nuevo y que los datos estén ingresando. Deberías ver algo así:
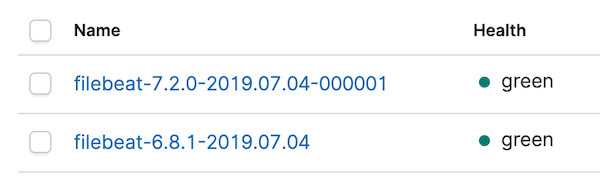
Vayamos también a los patrones de índice y actualicemos el patrón de índice filebeat-*. Con el patrón de índice actualizado para los datos de las versiones 6.8 y 7.2, debería haber algunos conflictos. Podemos enfocarnos en los conflictos cambiando el selector de tipo de datos a la derecha de All field types (Todos los tipos de campo) a conflict:
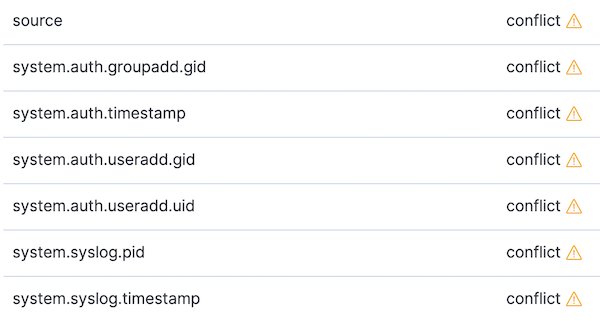
Echemos un vistazo a dos de los conflictos anteriores y exploremos cómo pueden abordarse.
En primer lugar, veamos un conflicto específico de syslog: system.syslog.pid. Si vamos a la página de gestión de índices y observamos el mappings de la versión 6.8, podemos ver que el campo está indexado como keyword. Si miramos el mapping del índice de la versión 7.2, podemos ver que system.syslog.pid es un alias de process.pid. Esto está bien, no es la causa del conflicto. Sin embargo, después del alias, si observamos el tipo de datos de process.pid, podemos ver que el tipo de datos ahora es long. El cambio de keyword a long causó el conflicto de tipos de datos.
En segundo lugar, veamos un conflicto por campo incompatible. Este será común a todas las migraciones de Filebeat: el campo source. En Filebeat 6, source es un campo keyword que generalmente contiene una ruta de archivo (o, a veces, una dirección de origen de syslog). En ECS, y por lo tanto en los mappings de campo de Filebeat 7, source se convierte en un objeto con campos anidados usado para describir la fuente de un evento de red (source.ip, source.port, etc.). Como todavía existe un campo llamado source en Beats 7, no podemos crear un campo de alias allí.
Identificamos dos campos en los que podemos trabajar como parte de nuestro procedimiento de migración. Volveremos a ellos en un momento.
Alias
Mantengamos [Filebeat System] Syslog dashboard de Beats 6 abierto. Como el patrón de índice filebeat-* cambió desde que cargamos este dashboard por primera vez, volvamos a cargar la página completa con Comando R o F5.
En una pestaña nueva, abramos el dashboard [Filebeat System] Syslog dashboard ECS nuevo.
Si observamos la búsqueda guardada en la parte inferior del dashboard de la versión 6.8, podemos ver las brechas de datos. Algunos eventos tienen valores para system.syslog.program y system.syslog.message, y algunos no. Si abrimos aquellos con valores vacíos, podemos ver que son los mismos eventos de Syslog que detecta la versión 7.2, pero con nombres de campo diferentes. Si observamos el mismo período en la pestaña con el dashboard de ECS, podemos ver el mismo comportamiento en sentido inverso. Los campos de ECS process.name y message están completados para los eventos de la versión 7.2, pero no para los de la versión 6.8.
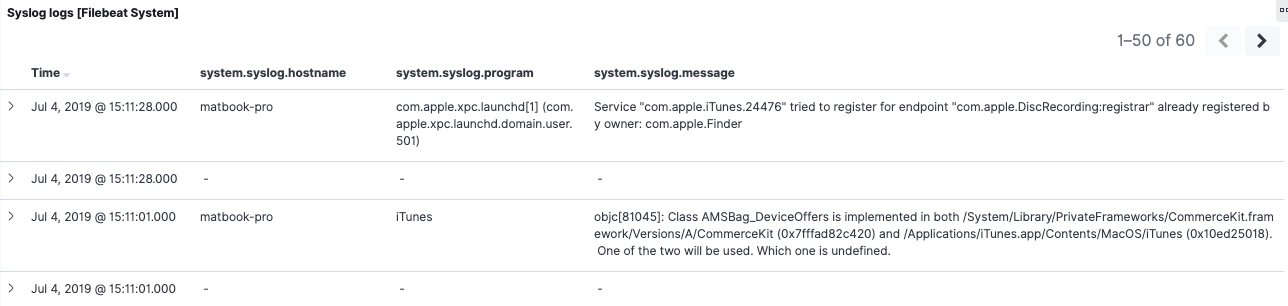
Esta es una manera concreta en la que los alias de campo no nos ayudan. Las búsquedas guardadas dependen del contenido del documento, no del mapping de índices. Como ya mencionamos en la visión general, si necesitas continuidad, reindexar para reponer (y cambiar los eventos a medida que ingresan) abordará esto. Lo haremos a la brevedad.
Ahora veamos en qué nos ayudan los alias de campo. Echa un vistazo a la visualización de anillo en el dashboard de la versión 6.8 y pasa el puntero sobre el anillo externo, que muestra los valores de system.syslog.program:
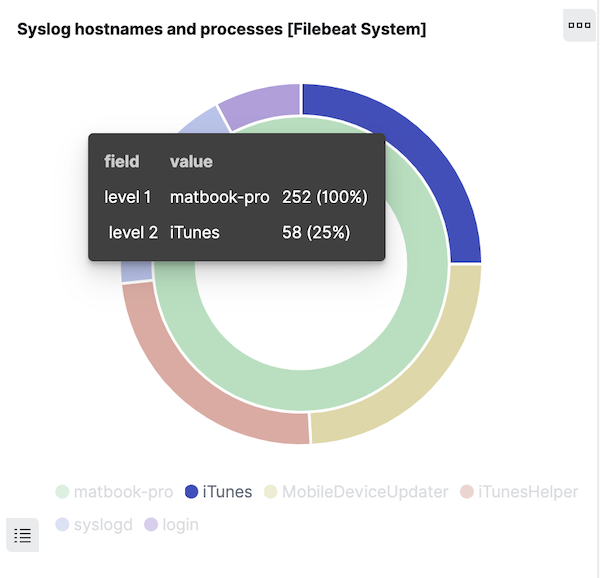
Haz clic sobre una sección del anillo para filtrar los mensajes generados por un programa. Seleccionemos solamente el filtro del nombre del programa:
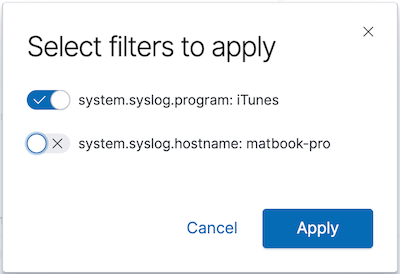
Acabamos de agregar un filtro en un campo que ya no está presente en la versión 7.2: system.syslog.program. Sin embargo, aún podemos ver ambos conjuntos de mensajes en la búsqueda guardada:
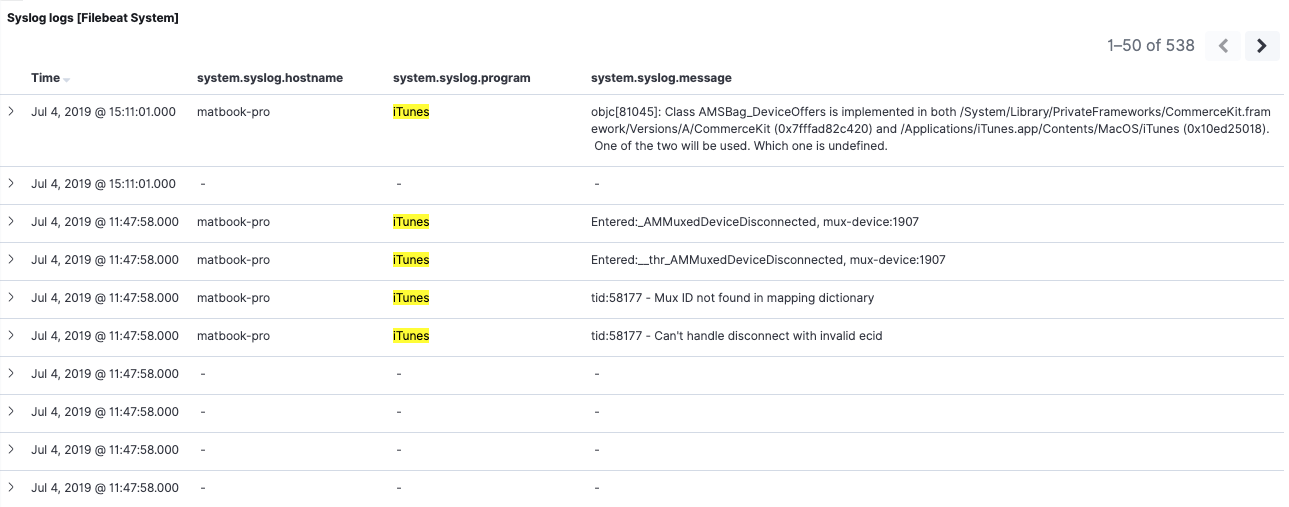
Si inspeccionamos los elementos de la versión 7.2, podemos ver que el filtro se aplicó correctamente a ellos también. Esto confirma que nuestro filtro en system.syslog.program funciona con los datos de la versión 7.2, gracias al alias system.syslog.program.
Ten en cuenta que la visualización (respaldada por una agregación de Elasticsearch) también muestra correctamente los resultados tanto para la versión 6.8 como para la 7.2 en el campo system.syslog.program migrado.
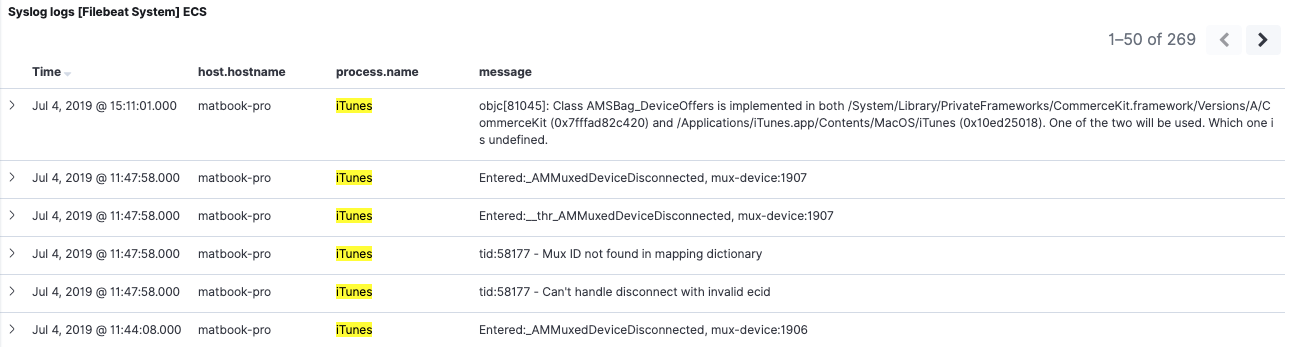
Si regresamos al dashboard de la versión 7.2, sin filtros activos, podemos ver tanto los datos de la versión 6.8 como los de la 7.2. Si aplicamos el mismo filtro como lo hicimos en la versión 6.8, sin embargo, veremos un comportamiento diferente. El filtro process.name:iTunes ahora solo devuelve los eventos de la versión 7.2. El motivo es que los índices de la versión 6.8 no tienen un campo de nombre process.name ni un alias con ese nombre.
Reindexar para migrar sin inconvenientes
Hablamos sobre cómo la reindexación puede ayudar a abordar tres aspectos diferentes de la migración: resolver conflictos de tipos de datos, resolver campos incompatibles y reponer campos de ECS para preservar la continuidad. Analicemos un ejemplo a la vez.
Así modificaremos nuestros datos de Beats 6:
- Conflicto de tipos de datos: cambia el tipo de datos correspondiente a system.syslog.pid de keyword a long.
- Campo incompatible: elimina el campo source de Filebeat después de copiar su contenido a log.file.path. Esto eliminará el conflicto con el conjunto de campos fuente de ECS. Ten en cuenta que Beats 6.6 y las versiones posteriores ya completan log.file.path con el mismo valor; pero no sucede lo mismo en las versiones anteriores a Beats 6, por lo que lo copiaremos de forma condicional.
- Repón el campo de ECS process.name con el valor system.syslog.process.
Así realizaremos estos cambios:
- Modificaremos la plantilla de índice de Filebeat 6.8 para usar los tipos de datos nuevos y agregaremos y eliminaremos definiciones de campos.
- Crearemos un pipeline de ingesta nuevo que modifique los eventos de la versión 6.8 eliminando o copiando campos.
- Probaremos el pipeline con la API _simulate.
- Usaremos el pipeline para reindexar datos anteriores.
- También adjuntaremos un llamado a este pipeline nuevo al final del pipeline de ingesta de Filebeat 6.8 para modificar los eventos a medida que ingresan.
Cambios en la plantilla de índice
Las mejoras en el tipo de datos deben realizarse en la plantilla de índice y harán efecto cuando el índice se implemente. De manera predeterminada, se implementa el día siguiente. Si usas la gestión de ciclo de vida del índice (ILM) en la versión 6.8, puedes forzar una implementación con la API de rollover.
Muestra la plantilla de índice actual desde las herramientas de desarrollo de Kibana:
GET _template/filebeat-6.8.1
Las plantillas de índice no se pueden modificar, deben sobrescribirse por completo (documentación). Prepara una llamada de API PUT con la plantilla de índice completa mientras ajustas algunas cosas:
- Elimina la definición de source (todas las líneas que comienzan con
-a continuación). - Agrega una definición de campo a program.name.
- Cambia el tipo de campo system.syslog.pid a long.
PUT _template/filebeat-6.8.1
{
"order" : 1,
"index_patterns" : [
"filebeat-6.8.1-*"
]
...
"mappings": {
"properties" : {
- "source" : {
- "ignore_above" : 1024,
- "type" : "keyword"
- },
"program" : {
"properties" : {
"name": {
"type": "keyword",
"ignore_above": 1024
}
}
},
"system" : {
"properties" : {
"syslog": {
"properties" : {
"pid" : {
"type" : "long"
}
...
}
Una vez listo el cuerpo de la llamada de API, ejecútalo para sobrescribir la plantilla de índice. Si planeas reponer muchos campos de ECS, echa un vistazo a las plantillas de Elasticsearch de ECS en el repositorio git de ECS.
Reindexación
El paso siguiente es escribir un pipeline de ingesta nuevo para modificar nuestros eventos de Beats 6.8. En el ejemplo, copiaremos system.syslog.program a process.name, copiaremos source a log.file.path (a menos que ya esté completado) y eliminaremos el campo source:
PUT _ingest/pipeline/filebeat-system-6-to-7
{ "description": "Pipeline to modify Filebeat 6 system module documents to better match ECS",
"processors": [
{ "set": {
"field": "process.name",
"value": "{{system.syslog.program}}",
"if": "ctx.system?.syslog?.program != null"
}},
{ "set": {
"field": "log.file.path",
"value": "{{source}}",
"if": "ctx.containsKey('source') && ctx.log?.file?.path == null"
}},
{ "remove": {
"field": "source"
}}
],
"on_failure": [
{ "set": {
"field": "error.message",
"value": "{{ _ingest.on_failure_message }}"
}}
]
}
Obtén más información sobre pipelines de ingesta y el lenguaje Painless (que se usa en las cláusulas if).
Podemos probar este pipeline con la API _simulate usando eventos totalmente completos, pero aquí hay una prueba más minimalista que se adapta mejor a un blog. Notarás que un evento ya tiene log.file.path completo (Beats 6.6 y versiones posteriores) y que otro no (versión 6.5 y anteriores):
POST _ingest/pipeline/filebeat-system-6-to-7/_simulate
{ "docs":
[ { "_source": {
"log": { "file": { "path": "/var/log/system.log" } },
"source": "/var/log/system.log",
"system": {
"syslog": {
"program": "syslogd"
}}}},
{ "_source": {
"source": "/var/log/system.log",
"system": {
"syslog": {
"program": "syslogd"
}}}}
]
}
La respuesta a la llamada de API contiene los dos eventos modificados. Podemos confirmar que nuestro pipeline funcionó porque el campo source desapareció y ambos eventos tienen el valor almacenado en log.file.path.
Ahora podemos realizar la reindexación de índices que ya no reciben escrituras (por ejemplo, el índice de ayer y anteriores) usando este pipeline de ingesta para cada índice de Filebeat que migremos. Asegúrate de leer los documentos de _reindex para comprender cómo reindexar en segundo plano, regular la operación de reindexación, etc. Esta es una reindexación simple que será suficiente para los pocos eventos que tenemos:
POST _reindex
{ "source": { "index": "filebeat-6.8.1-2019.07.04" },
"dest": {
"index": "filebeat-6.8.1-2019.07.04-migrated",
"pipeline": "filebeat-system-6-to-7"
}}
Si estás siguiendo los pasos y solo tienes el índice de hoy, siéntete libre de probar la llamada de API de todos modos e inspeccionar el mapping del índice migrado. Pero no elimines luego el índice de hoy, solo se recreará porque Filebeat 6.8 aún envía datos.
De lo contrario, una vez reindexados los índices inactivos, podemos confirmar que los índices nuevos tienen todas las correcciones que deseamos y luego eliminar los índices antiguos.
Modificación de eventos entrantes
La mayoría de las versiones de Beats pueden configurarse para enviar directamente a un pipeline de ingesta en su salida de Elasticsearch (lo mismo sucede con la salida de Elasticsearch de Logstash). En su lugar, como en esta demostración usamos un Filebeat module (que ya usa pipelines de ingesta), tendremos que modificar los pipelines del módulo.
El pipeline de ingesta instalado por la configuración de Filebeat 6.8 para procesar se denomina filebeat-6.8.1-system-syslog-pipeline. Todo lo que tenemos que hacer aquí es agregar una llamada a nuestro propio pipeline al final del pipeline Syslog de Filebeat.
Mostraremos el pipeline que estamos a punto de modificar:
GET _ingest/pipeline/filebeat-6.8.1-system-syslog-pipeline
A continuación, prepararemos la llamada de API para sobrescribir el pipeline pegando el pipeline completo debajo de la llamada de API PUT. Luego, agregaremos un procesador “pipeline” al final para llamar a nuestro nuevo pipeline:
PUT _ingest/pipeline/filebeat-6.8.1-system-syslog-pipeline
{ "description" : "Pipeline for parsing Syslog messages.",
"processors" :
[
{ "grok" : { ... }
...
{ "pipeline": { "name": "filebeat-system-6-to-7" } }
],
"on_failure" : [
{ ... }
]
}
Después de ejecutar esta llamada de API, todos los eventos entrantes se modificarán para coincidir mejor con ECS, antes de indexarse.
Por último, podemos usar _update_by_query para modificar los documentos en el índice activo inmediatamente anterior a la modificación del pipeline. Podemos confirmar documentos que aún necesitan actualización buscando aquellos que todavía tienen el campo fuente:
GET filebeat-6.8.1-*/_search
{ "query": { "exists": { "field": "source" }}}
Y reindexamos solo esos:
POST filebeat-6.8.1-*/_update_by_query?pipeline=filebeat-system-6-to-7
{ "query": { "exists": { "field": "source" }}}
Verificación de conflictos
Una vez eliminados todos los índices con conflictos, solo quedan aquellos reindexados. Podemos actualizar el patrón de índice para confirmar que no queden conflictos. Podemos regresar al dashboard de Filebeat 7 y ver que nuestros datos de la versión 6.8 incluidos ahora son más utilizables gracias a la reposición del campo process.name:
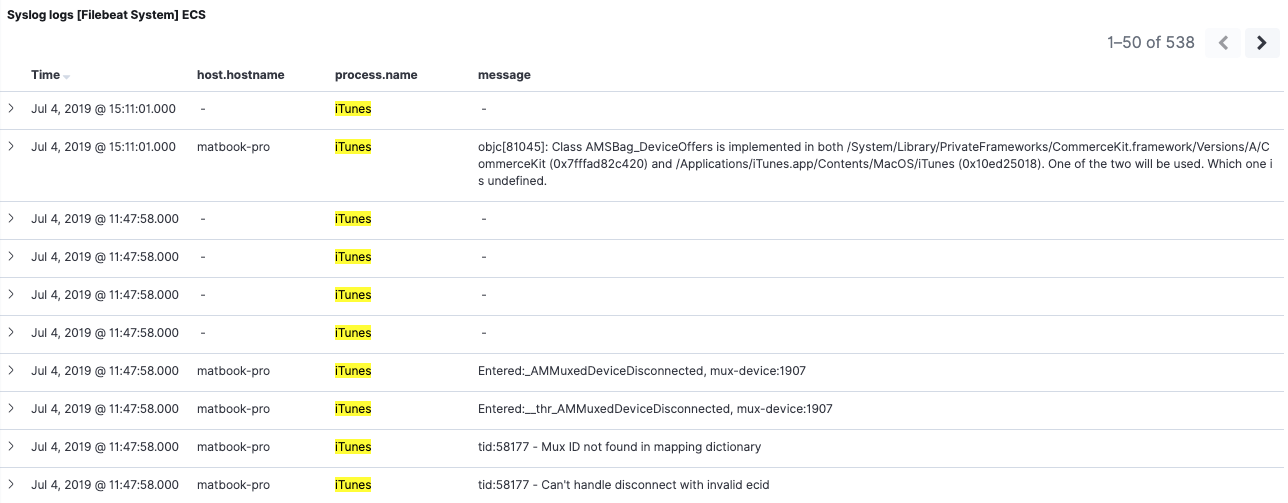
En nuestro ejemplo, solo repusimos un campo. Por supuesto, eres libre de reponer tantos campos como necesites.
Limpieza después de la migración
La migración probablemente involucre modificar los dashboards customizados y las aplicaciones que consumen eventos de Beats mediante la API para usar los nombres de campo de ECS nuevos.
Una vez que hayas migrado completamente a Beats 7 y los alias de campo ya no se usen, podemos eliminarlos para aprovechar los beneficios de ahorro de memoria que mencionamos antes. Para eliminar los alias, eliminemos el atributo migration.6_to_7.enabled de filebeat.yml para luego sobrescribir la plantilla de Filebeat 7.2 con lo siguiente:
./filebeat setup --template -e -E 'setup.template.overwrite=true'
Al igual que los cambios realizados anteriormente en la plantilla de Filebeat 6.8, la plantilla nueva sin alias hará efecto la próxima vez que se implemente Filebeat 7.2.
Conclusión
En este artículo, hablamos sobre los pasos necesarios para migrar los datos a ECS en un entorno de Beats. Exploramos los beneficios del procedimiento de actualización y sus limitaciones. Estas limitaciones pueden abordarse reindexando los datos anteriores e incluso modificando los datos entrantes de Beats 6 actuales durante el proceso de ingesta.
Después de explicar la migración a un nivel alto, realizamos un ejemplo paso a paso de actualización del módulo del sistema de Filebeat de la versión 6.8 a la 7.2. Observamos las diferencias entre los eventos de Filebeat 6.8 y 7.2, luego revisamos todos los pasos que los usuarios pueden tomar para reindexar datos anteriores y para modificar los datos a medida que ingresan.
Presentar un esquema inevitablemente tiene un gran impacto sobre las instalaciones existentes, pero realmente creemos que esta migración valdrá la pena. Puedes leer los motivos en Presentamos el Elastic Common Schema y en Why Observability loves the Elastic Common Schema (Por qué la observabilidad prefiere Elastic Common Schema).
Si tu entorno usa otros pipelines de ingesta de datos diferentes a Beats, mantente atento. Tenemos planificado publicar otro blog en el que hablaremos sobre cómo migrar un pipeline de ingesta personalizado a ECS.
Si tienes preguntas sobre ECS o necesitas ayuda con la actualización de Beats, dirígete a los foros de debate y etiqueta tu pregunta con elastic-common-schema. Puedes obtener más información sobre ECS en nuestra documentación y contribuir a ECS en GitHub.
Referencias
Documentación
- Upgrade Assistant (Asistente de actualización)
- Upgrading the Elastic Stack (Actualización del Elastic Stack)
- Breaking changes in 7.0 (Novedades en la versión 7.0)
- Reindexación
- Pipeline de ingesta
- API simulate del pipeline de ingesta
- Lenguaje Painless
- Mappings e Index Templates (Plantillas de índice)
- Archivo de documentación de todos los cambios de campos: ecs-migration.yml
- Plantillas de índice de Elasticsearch de ECS de muestra
Blogs y videos
- Presentamos el Elastic Common Schema (blog)
- Introducing the Elastic Common Schema (webinar) (Presentamos el Elastic Common Schema)
- ECS: How to migrate your data (webinar) (ECS: Cómo migrar los datos)
- Why observability loves the Elastic Common Schema (blog) (Por qué la observabilidad prefiere Elastic Common Schema)
- Upgrading the Elastic Stack with the 7.x Upgrade Assistant (blog) (Actualización del Elastic Stack con el asistente de actualización 7.x)
General
- Haz preguntas sobre ECS en los foros de debate y etiqueta tus preguntas con “elastic-common-schema”.
- Documentación oficial de ECS
- Repositorio de Github de ECS