Cómo instrumentar tu aplicación Go con el agente Elastic APM Go
Elastic APM (monitoreo de rendimiento de aplicaciones) proporciona información completa sobre el rendimiento de las aplicaciones y visibilidad de las cargas de trabajo distribuidas, con soporte oficial para varios lenguajes que incluyen Go, Java, Ruby, Python y JavaScript (Node.js y monitoreo de usuario real [RUM] para el navegador).
Para obtener esta información sobre el rendimiento, debes instrumentar tu aplicación. La instrumentación es el acto de alterar el código de la aplicación para medir su comportamiento. En algunos de los lenguajes soportados, solo es necesario instalar un agente. Por ejemplo, las aplicaciones Java pueden instrumentarse automáticamente usando un marcador ‑javaagent simple, que usa instrumentación del código de bytes (este es el proceso de manipular el código de bytes de Java compilado, generalmente cuando se carga una clase Java cuando se inicia el programa). Además de esto, es común que un solo hilo tome el control de una operación de principio a fin, por lo que puede usarse el almacenamiento local de hilos para correlacionar las operaciones.
Los programas Go, en general, se compilan en código máquina nativo, que no resulta tan favorecedor para la instrumentación automatizada. Además, el modelo de creación de hilos de los programas Go es diferente al de la mayoría de los otros lenguajes. En un programa Go, una “goroutine” que ejecuta código puede trasladarse entre hilos de sistema operativo, y las operaciones lógicas generalmente abarcan varias goroutines. Entonces, ¿cómo se instrumenta una aplicación Go?
En este artículo, veremos cómo instrumentar una aplicación Go con Elastic APM para capturar datos de rendimiento detallados sobre el tiempo de respuesta (rastreo), capturar métricas de infraestructura y aplicación, y para la integración con logging: la trifecta de la observabilidad. Desarrollaremos una aplicación y su instrumentación a lo largo del artículo, y abarcaremos los temas siguientes en orden:
- Solicitudes web
- Búsquedas de SQL
- Intervalos personalizados
- Solicitudes HTTP salientes
- Rastreo de pánicos
- Integración con logging
- Métricas de infraestructura y aplicación
Rastreo de solicitudes web
El agente Elastic APM Go proporciona una API para operaciones de “rastreo”, como solicitudes entrantes en un servidor. Rastrear una operación involucra registrar eventos que describen la operación, por ejemplo, el nombre de la operación, el tipo/la categoría y algunos atributos como la IP de origen, el usuario autenticado, etc. El evento también registrará cuándo se inició la operación, el tiempo que tardó y los identificadores que describen el linaje de la operación.
El agente Elastic APM Go proporciona varios módulos para instrumentar diversos marcos de trabajo web, marcos de trabajo RPC y controladores de base de datos, y para la integración con varios marcos de trabajo de logging. Consulta la lista completa de las tecnologías soportadas.
Agreguemos la instrumentación de Elastic APM a un servicio web simple usando el enrutador gorilla/mux y mostremos cómo procederíamos para capturar su rendimiento mediante Elastic APM.
Este es el código original sin instrumentar:
package main
import (
"fmt"
"log"
"net/http"
"github.com/gorilla/mux"
)
func helloHandler(w http.ResponseWriter, req *http.Request) {
fmt.Fprintf(w, "Hello, %s!\n", mux.Vars(req)["name"])
}
func main() {
r := mux.NewRouter()
r.HandleFunc("/hello/{name}", helloHandler)
log.Fatal(http.ListenAndServe(":8000", r))
}
Para instrumentar las solicitudes respondidas por el enrutador gorilla/mux, necesitarás una versión reciente de gorilla/mux (v1.6.1 o posterior) que soporte middleware. Después, todo lo que tienes que hacer es importar go.elastic.co/apm/module/apmgorilla y agregar la línea de código siguiente:
r.Use(apmgorilla.Middleware())
El middleware apmgorilla reportará cada solicitud como una transacción al servidor de APM. Dejemos de lado por un momento la instrumentación y veamos cómo se ve eso en la UI de APM.
Visualización del rendimiento
Instrumentamos el servicio web, pero no tiene adónde enviar los datos. De manera predeterminada, los agentes de APM intentarán enviar los datos a un servidor de APM en http://localhost:8200. Configuremos un Stack nuevo con el recientemente lanzado Elastic Stack 7.0.0. Puedes descargar el despliegue predeterminado del Stack de forma gratuita o puedes iniciar una prueba gratuita de 14 días de Elasticsearch Service en Elastic Cloud. Si prefieres ejecutar tu propia instancia, puedes encontrar la configuración de Docker Compose de ejemplo en https://github.com/elastic/stack-docker.
Una vez configurado el Stack, puedes configurar tu aplicación para que envíe los datos al servidor de APM. Necesitarás conocer la URL del servidor de APM y el token secreto. Si usas Elastic Cloud, puedes encontrar esta información en la página “Activity” (Actividad) durante el despliegue y en la página “APM” una vez finalizado este. Durante el despliegue, también debes tomar nota de la contraseña de Elasticsearch y Kibana, debido a que no podrás verla nuevamente después (aunque sí podrás restablecerla si es necesario).
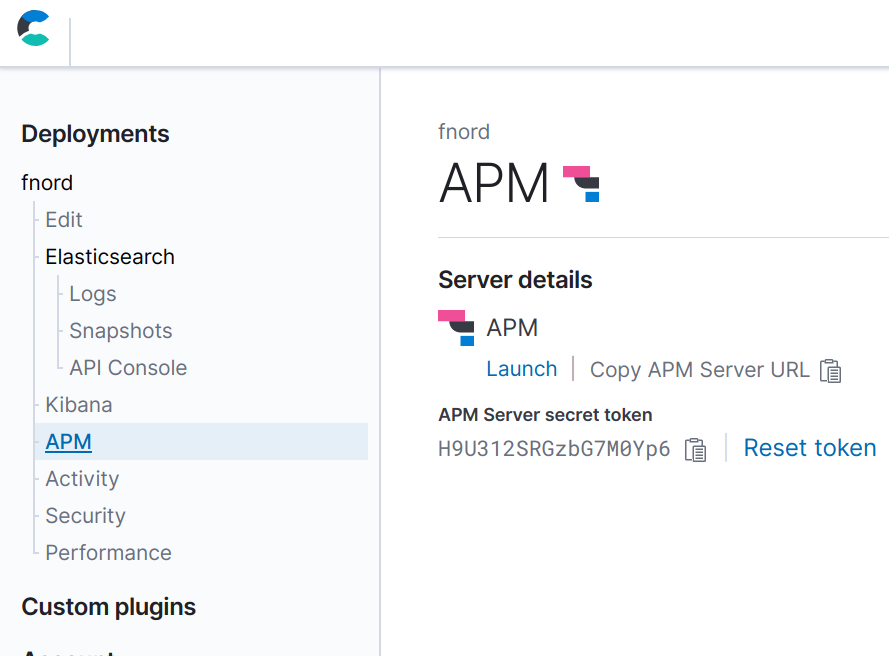
El agente APM Go se configura mediante variables de entorno. Para configurar el token secreto y la URL del servidor de APM, exporta las variables de entorno siguientes para que tu aplicación las detecte:
export ELASTIC_APM_SERVER_URL=https://bdf8658ddda74d47af1875242c3ef203.apm.europe-west1.gcp.cloud.es.io:443 export ELASTIC_APM_SECRET_TOKEN=H9U312SRGzbG7M0Yp6
Ahora, si ejecutamos el programa instrumentado, deberíamos ver algunos datos en la UI de APM en poco tiempo. El agente enviará métricas periódicamente: uso de CPU y memoria, y estadísticas de tiempo de ejecución de Go. Cuando se responde una solicitud, el agente también registrará una transacción; estas se almacenan en búfer y se envían en batches, de manera predeterminada, cada 10 segundos. Entonces, ejecutemos el servicio, enviemos algunas solicitudes y veamos lo que sucede.
Para ver que los eventos se estén enviando al servidor de APM correctamente, podemos configurar algunas variables de entorno adicionales:
export ELASTIC_APM_LOG_FILE=stderr export ELASTIC_APM_LOG_LEVEL=debug
Ahora, inicia la aplicación (hello.go contiene el programa instrumentado anterior):
go run hello.go
A continuación, usaremos github.com/rakyll/hey para enviar algunas solicitudes al servidor:
go get -u github.com/rakyll/hey hey http://localhost:8000/hello/world
En la salida de la aplicación deberías ver algo similar a esto:
{"level":"debug","time":"2019-03-28T20:33:56+08:00","message":"sent request with 200 transactions, 0 spans, 0 errors, 0 metricsets"}
Y en la salida de hey deberías ver varias estadísticas, incluido un histograma de latencias del tiempo de respuesta. Si ahora abrimos Kibana y navegamos a la UI de APM, deberíamos ver un servicio llamado “hello”, con un grupo de transacciones llamado “/hello/{name}”. Veamos:
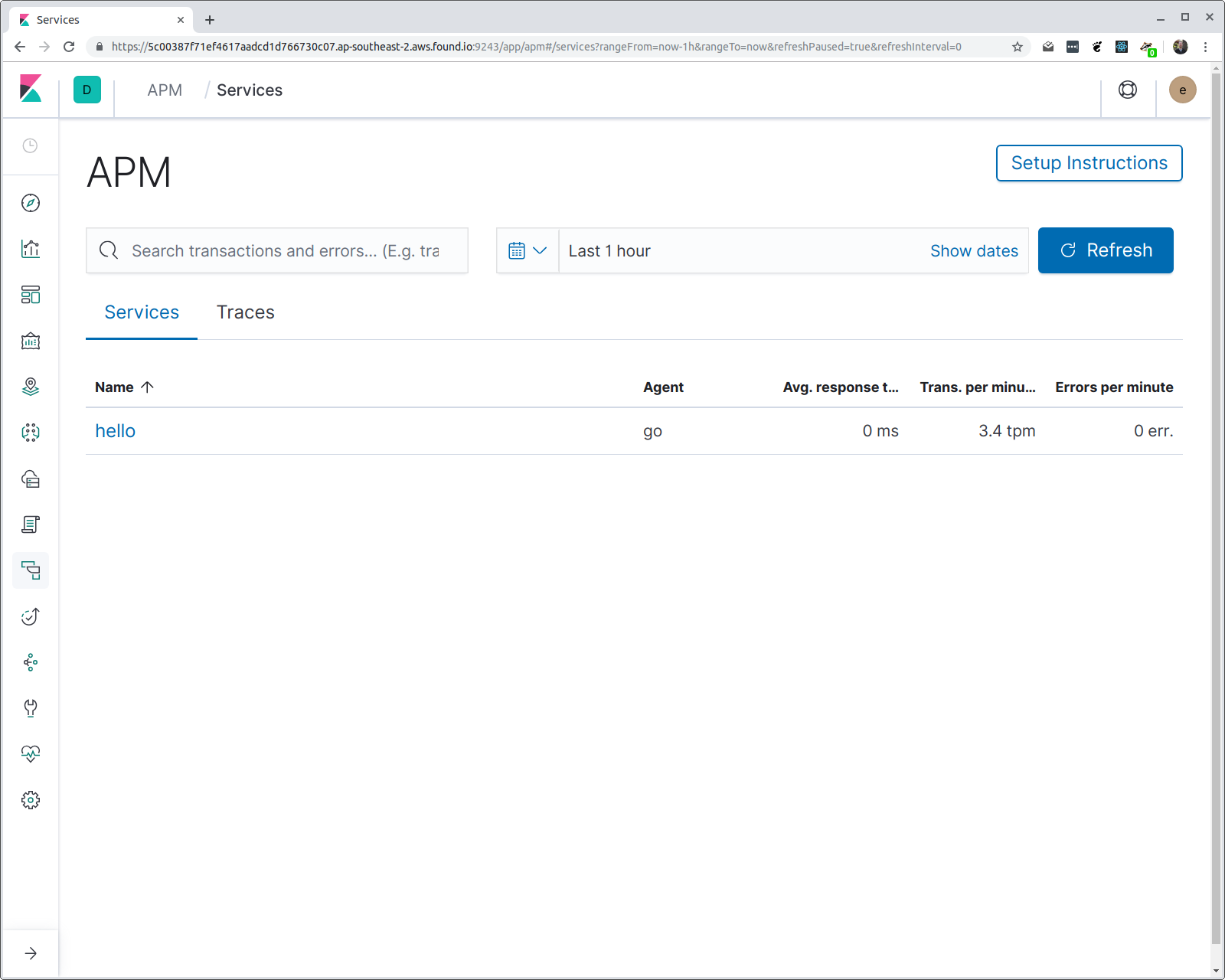
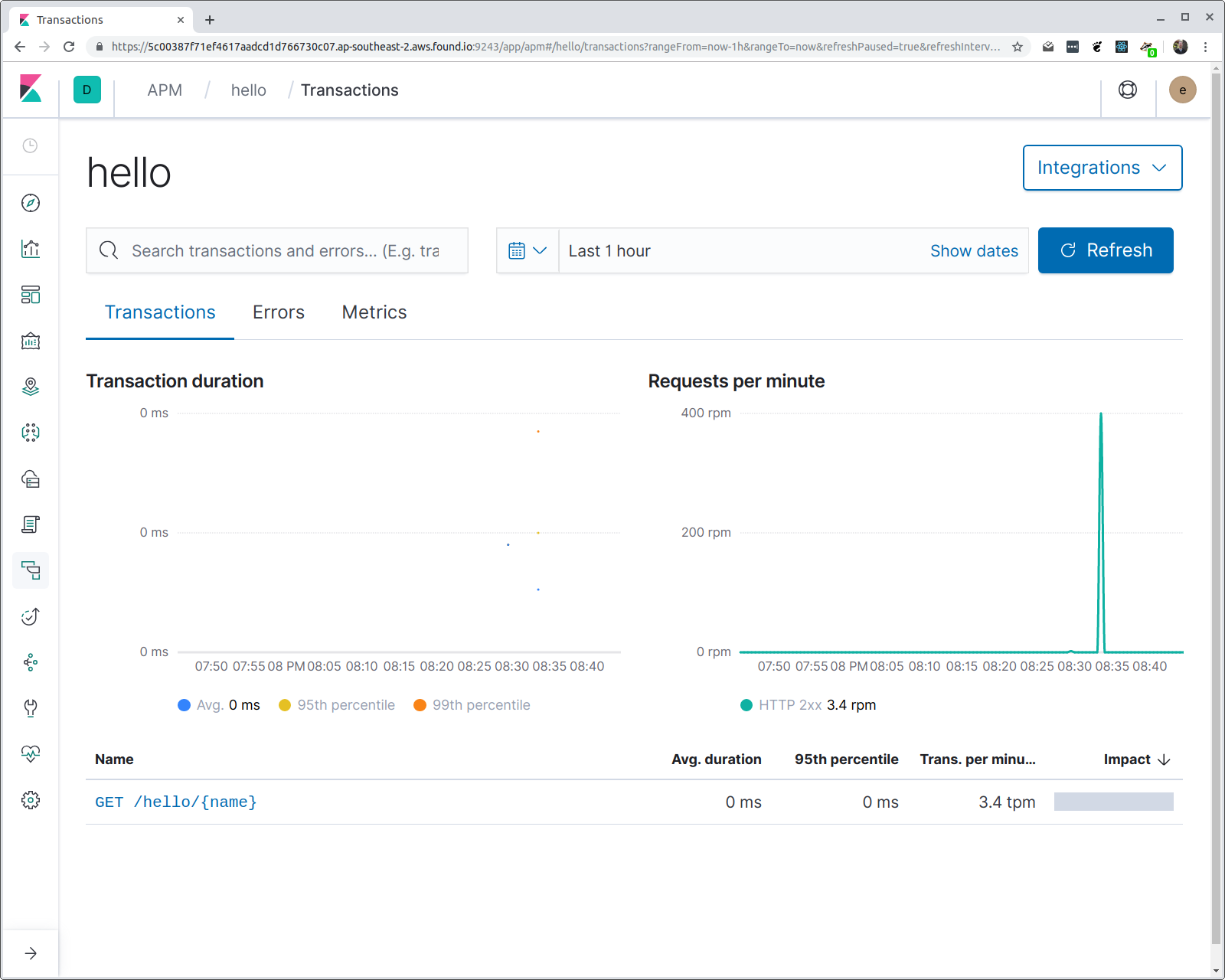
Es posible que te estés preguntando algunas cosas: ¿cómo sabe el agente qué nombre darle al servicio? y ¿por qué se usa el patrón de ruta en lugar de la URI de solicitud? La primera es fácil: si no especificas el nombre del servicio (mediante una variable de entorno), entonces se usa el nombre binario del programa. En este caso, el programa se compila en un binario denominado “hello”.
El motivo por el cual se usa el patrón de ruta es para habilitar agregaciones. Si ahora hacemos clic en la transacción, podemos ver un histograma de latencias del tiempo de respuesta.
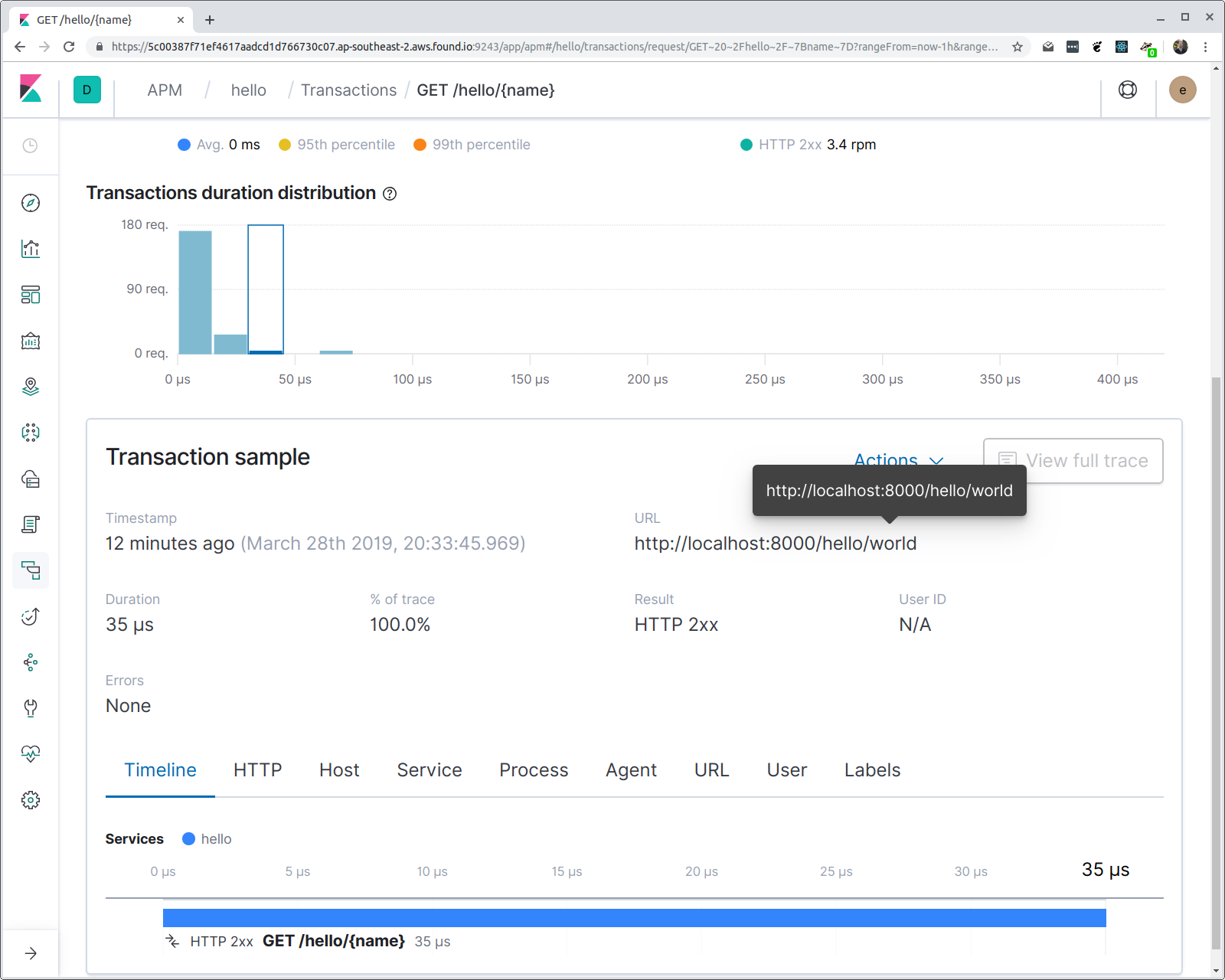
Ten en cuenta que, a pesar de que realicemos agregaciones en el patrón de ruta, la URL solicitada completa está disponible en las propiedades de la transacción.
Rastreo de búsquedas de SQL
En una aplicación típica, tendrás una lógica más compleja que involucre servicios externos como bases de datos, memorias caché, etc. Cuando intentas diagnosticar problemas de rendimiento en tu aplicación, resulta crucial poder ver las interacciones con estos servicios.
Echemos un vistazo a cómo podemos observar las búsquedas de SQL que realizó nuestra aplicación Go.
Para la demostración, usaremos una base de datos de SQLite incorporada; pero siempre y cuando uses database/sql, no importa qué controlador uses.
Para rastrear operaciones de database/sql, proporcionamos el módulo de instrumentación go.elastic.co/apm/module/apmsql. El módulo apmsql instrumenta controladores de database/sql para reportar operaciones de la base de datos como intervalos dentro de una transacción. Para usar este módulo, tendrás que hacer cambios en la manera de registrar y abrir el controlador de la base de datos.
Generalmente, en una aplicación importas un paquete de controladores de database/sql para registrar el controlador, por ejemplo:
import _ “github.com/mattn/go-sqlite3” // registers the “sqlite3” driver
Proporcionamos varios paquetes de utilidades para hacer lo mismo, pero que registran versiones instrumentadas de los mismos controladores. Por ejemplo, para SQLite3 en cambio, importarías de la siguiente manera:
import _ "go.elastic.co/apm/module/apmsql/sqlite3"
Bajo la cubierta, esto usa el método apmsql.Register, que equivale a llamar a sql.Register, pero instrumenta el controlador registrado. Cada vez que usas apmsql.Register, debes usar pmsql.Open para abrir una conexión, en lugar de usar sql.Open:
import (
“go.elastic.co/apm/module/apmsql”
_ "go.elastic.co/apm/module/apmsql/sqlite3"
)
var db *sql.DB
func main() {
var err error
db, err = apmsql.Open("sqlite3", ":memory:")
if err != nil {
log.Fatal(err)
}
if _, err := db.Exec("CREATE TABLE stats (name TEXT PRIMARY KEY, count INTEGER);"); err != nil {
log.Fatal(err)
}
...
}
Antes mencionamos que en Go, a diferencia de muchos otros lenguajes, no hay un almacenamiento local de hilos para unir las operaciones relacionadas. En cambio, debes propagar el contexto explícitamente. Cuando comenzamos a registrar una transacción para una solicitud web, almacenamos una referencia a la transacción en progreso en el contexto de la solicitud, disponible a través del método net/http.Request.Context. Echemos un vistazo a cómo se ve esto registrando la cantidad de veces que se visualizó cada nombre y reportando las búsquedas en la base de datos en Elastic APM.
var db *sql.DB
func helloHandler(w http.ResponseWriter, req *http.Request) {
vars := mux.Vars(req)
name := vars[“name”]
requestCount, err := updateRequestCount(req.Context(), name)
if err != nil {
panic(err)
}
fmt.Fprintf(w, "Hello, %s! (#%d)\n", name, requestCount)
}
// updateRequestCount incrementa un recuento de nombre en la base de datos, lo que devuelve el recuento nuevo.
func updateRequestCount(ctx context.Context, name string) (int, error) {
tx, err := db.BeginTx(ctx, nil)
if err != nil {
return -1, err
}
row := tx.QueryRowContext(ctx, "SELECT count FROM stats WHERE name=?", name)
var count int
switch err := row.Scan(&count); err {
case nil:
count++
if _, err := tx.ExecContext(ctx, "UPDATE stats SET count=? WHERE name=?", count, name); err != nil {
return -1, err
}
case sql.ErrNoRows:
count = 1
if _, err := tx.ExecContext(ctx, "INSERT INTO stats (name, count) VALUES (?, ?)", name, count); err != nil {
return -1, err
}
default:
return -1, err
}
return count, tx.Commit()
}
Hay dos cuestiones cruciales a destacar en este código:
- Estamos usando los métodos database/sql *Context (ExecContext, QueryRowContext).
- Pasamos el contexto de la solicitud de inclusión a esas llamadas de método.
El controlador de la base de datos instrumentada con apmsql espera encontrar una referencia a la transacción en progreso en el contexto proporcionado; es de esta manera que la operación de la base de datos reportada se asocia con el controlador de solicitudes que realiza la llamada. Enviemos algunas solicitudes a este servicio renovado y echemos un vistazo a cómo se ve:
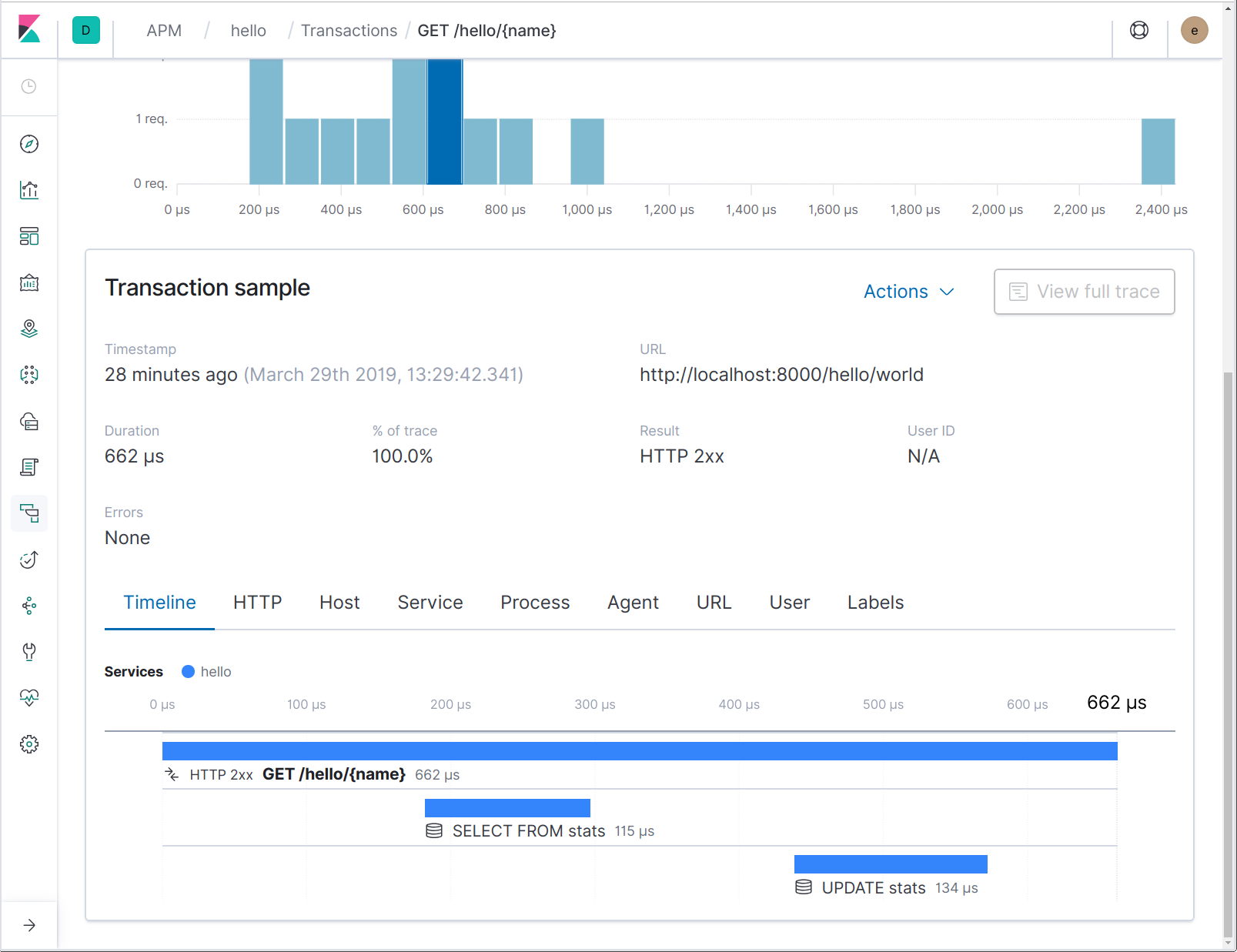
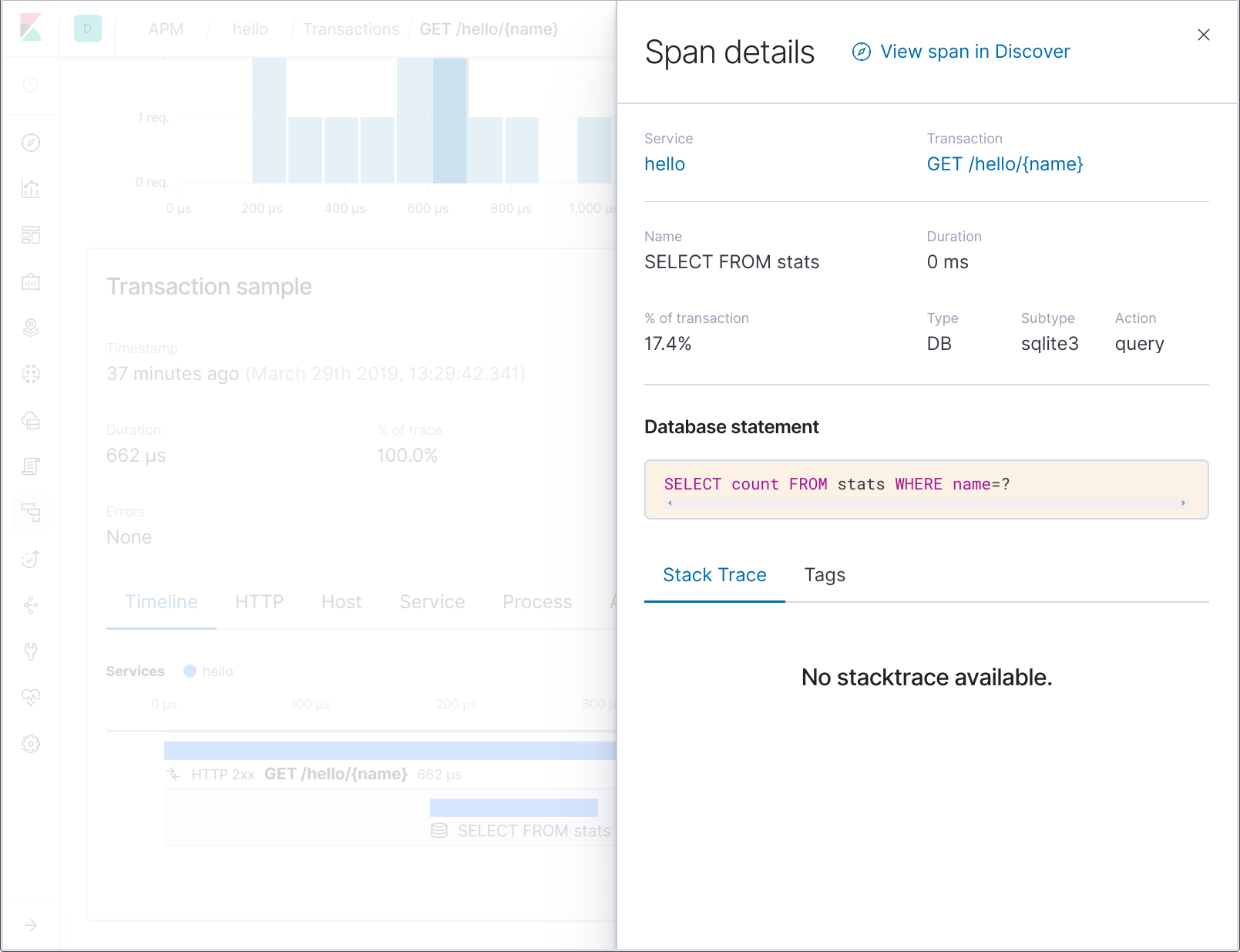
Observa que los nombres de intervalo de la base de datos no contienen la expresión SQL completa, sino solo una parte. Esto nos permite agregar con mayor facilidad los intervalos que representan operaciones en un nombre de tabla determinado, por ejemplo. Si haces clic en el intervalo, puedes ver la expresión SQL completa dentro de los detalles del intervalo:
Rastreo de intervalos personalizados
En la sección anterior, introdujimos intervalos de búsqueda de la base de datos en nuestros rastreos. Si conoces bien el servicio, es posible que sepas inmediatamente que esas dos búsquedas son parte de la misma operación (búsqueda y actualización de un contador); otra persona podría no saberlo. Además, si hay algún procesamiento importante en curso entre dichas búsquedas o entorno a ellas, puede ser útil atribuirlo al método “updateRequestCount”. Podemos hacerlo reportando un intervalo personalizado para dicha función.
Puedes reportar un intervalo personalizado de diversas maneras, la más sencilla es usando apm.StartSpan. Debes pasar a esta función un contexto que contenga una transacción y un nombre y tipo de intervalo. Creemos un intervalo llamado “updateRequestCount”:
func updateRequestCount(ctx context.Context, name string) (int, error) {
span, ctx := apm.StartSpan(ctx, “updateRequestCount”, “custom”)
defer span.End()
...
}
Como podemos ver en el código anterior, apm.StartSpan devuelve un intervalo y un contexto nuevo. Ese contexto nuevo debería usarse en lugar del contexto que se pasó; contiene el intervalo nuevo. Así es como se ve en la UI ahora:
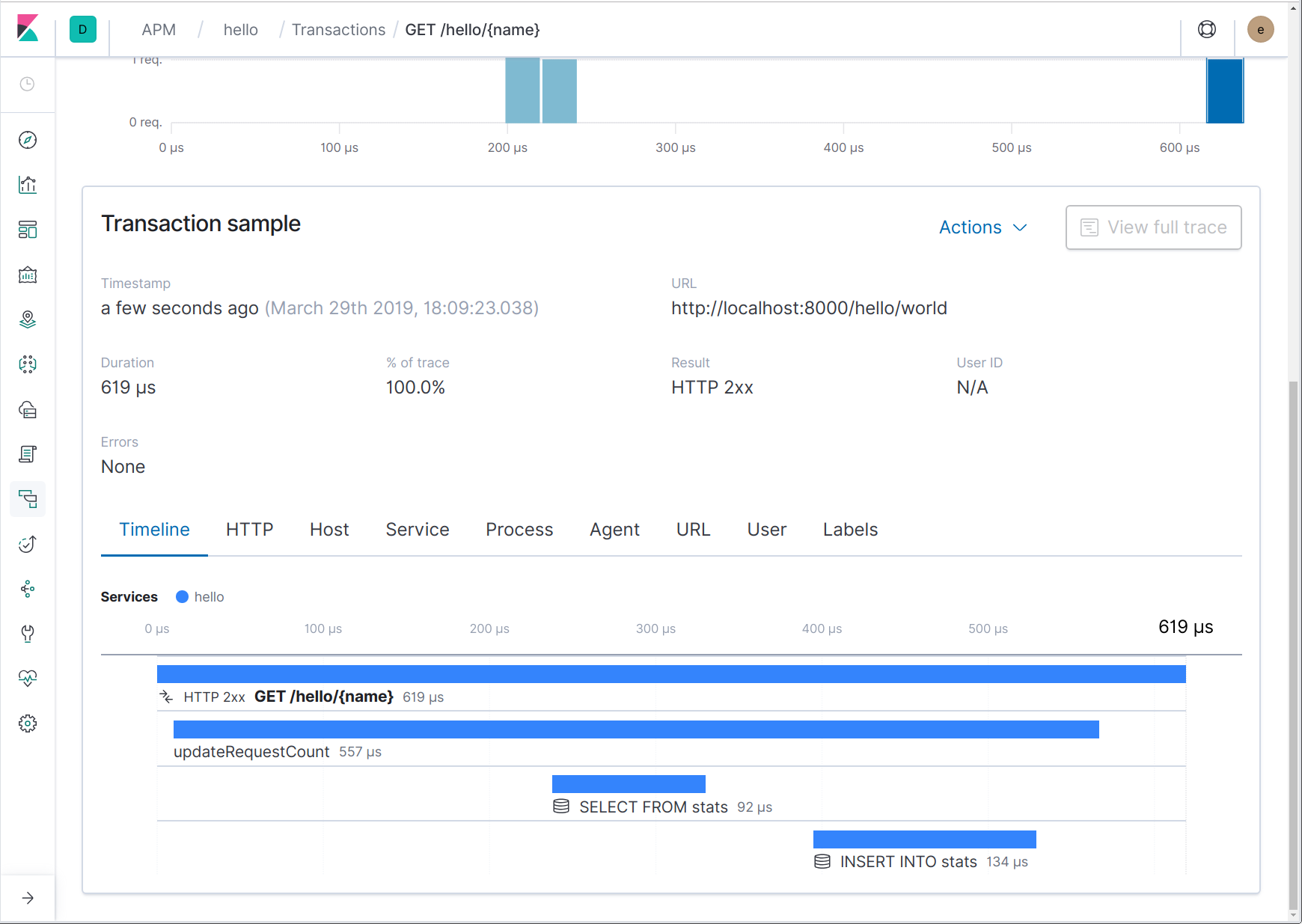
Rastreo de solicitudes HTTP salientes
Lo que describimos hasta ahora es en realidad el rastreo de proceso único. Si bien se involucran varios servicios, solo realizamos el rastreo dentro de un proceso: solicitudes entrantes y búsquedas en la base de datos desde la perspectiva del cliente.
Los microservicios se han vuelto cada vez más habituales en los últimos años. Antes de la llegada de los microservicios, la arquitectura orientada al servicio (SOA) era otro enfoque popular para desglosar las aplicaciones monolíticas en componentes modulares. El efecto, en cualquier caso, es un aumento de la complejidad, lo que complica la observabilidad. Ahora no solo tenemos que asociar operaciones dentro de un proceso, sino también entre procesos y potencialmente (probablemente) en diferentes máquinas, incluso diferentes centros de datos o servicios de terceros.
La forma en que manejamos el rastreo dentro de los procesos y entre ellos en el agente Elastic APM Go es muy similar. Por ejemplo, para rastrear una solicitud HTTP saliente, debes instrumentar el cliente HTTP y asegurarte de que el contexto de la solicitud de inclusión se propague a la solicitud saliente. El cliente instrumentado usará esto para crear un intervalo y también para inyectar encabezados en la solicitud HTTP saliente. Echemos un vistazo a cómo se ve en la práctica:
// apmhttp.WrapClient instrumenta el http.Client dado. client := apmhttp.WrapClient(http.DefaultClient) // Si “ctx” contiene una referencia a una transacción en progreso, entonces la llamada a continuación iniciará un intervalo nuevo. resp, err := client.Do(req.WithContext(ctx)) … resp.Body.Close() // the span is ended when the response body is consumed or closed
Si otra aplicación instrumentada con Elastic APM maneja esta solicitud saliente, terminarás con un “rastreo distribuido”: un rastreo (recopilación de intervalos y transacciones relacionados) que cruza servicios. El cliente instrumentado inyectará un encabezado que identifique el intervalo de la solicitud HTTP saliente, y el servicio receptor extraerá dicho encabezado y lo usará para correlacionar el intervalo cliente con la transacción que registra. Esto está todo manejado por los diversos módulos de instrumentación de marcos de trabajo web proporcionados en go.elastic.co/apm/module.
Para demostrar esto, ampliemos nuestro servicio y agreguemos algunas trivialidades en la respuesta: la cantidad de bebes nacidos con un nombre especificado en 2018, en el sur de Australia. El servicio “hello” obtendrá esta información de un segundo servicio a través de una API basada en HTTP. El código de este segundo servicio se omite por cuestiones de brevedad, pero puedes imaginar que está implementado e instrumentado de manera muy similar al servicio “hello”.
func helloHandler(w http.ResponseWriter, req *http.Request) {
...
stats, err := getNameStats(req.Context(), name)
if err != nil {
panic(err)
}
fmt.Fprintf(w, "Hello, %s! (#%d)\n", name, requestCount)
fmt.Fprintf(w, "In %s, %d: ", stats.Region, stats.Year)
switch n := stats.Male.N + stats.Female.N; n {
case 1:
fmt.Fprintf(w, "there was 1 baby born with the name %s!\n", name)
default:
fmt.Fprintf(w, "there were %d babies born with the name %s!\n", n, name)
}
}
type nameStatsResults struct {
Region string
Year int
Male nameStats
Female nameStats
}
type nameStats struct {
N int
Rank int
}
func getNameStats(ctx context.Context, name string) (nameStatsResults, error) {
span, ctx := apm.StartSpan(ctx, "getNameStats", "custom")
defer span.End()
req, _ := http.NewRequest("GET", "http://localhost:8001/stats/"+url.PathEscape(name),
nil)
// Instrumenta el cliente HTTP y agrega el contexto circundante a la solicitud.
// Esto provocará la generación de un intervalo para la solicitud HTTP saliente, incluido
// un encabezado de rastreo distribuido para continuar con el rastreo en el servicio de destino.
client := apmhttp.WrapClient(http.DefaultClient)
resp, err := client.Do(req.WithContext(ctx))
if err != nil {
return nameStatsResults{}, err
}
defer resp.Body.Close()
var res nameStatsResults
if err := json.NewDecoder(resp.Body).Decode(&res); err != nil {
return nameStatsResults{}, err
}
return res, nil
}
Una vez instrumentados ambos servicios, ahora vemos un rastreo distribuido para cada solicitud al servicio “hello”:
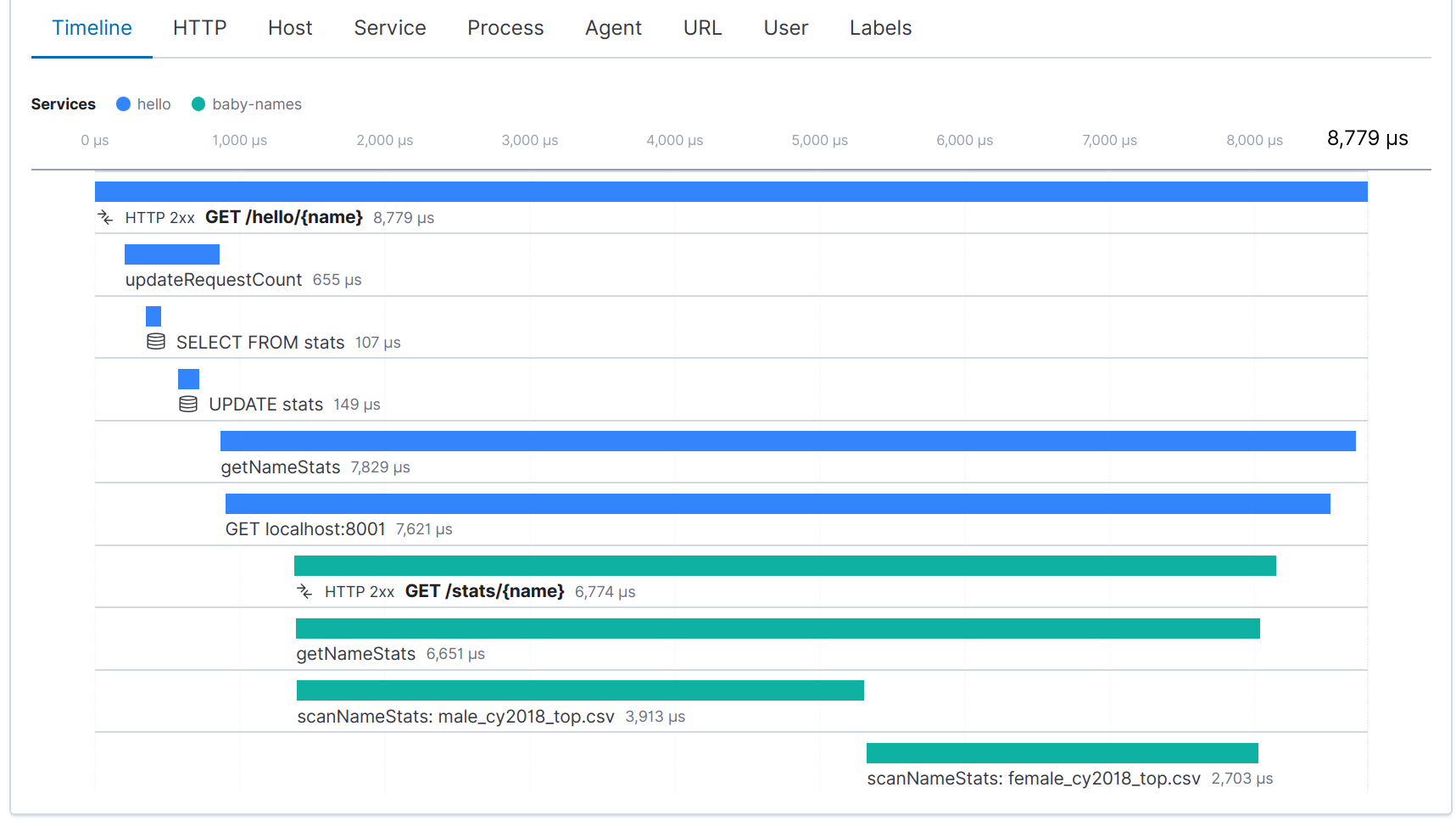
Puedes leer más sobre el tema de rastreo distribuido en el blog de Adam Quan, Rastreo distribuido, OpenTracing y Elastic APM.
Rastreo de excepciones pánicos
Como hemos visto, los módulos de instrumentación del marco de trabajo web proporcionan middleware que registra transacciones. Además, también capturarán pánicos y los reportarán a Elastic APM para ayudar en la investigación de solicitudes erróneas. Probémoslo modificando updateRequestCount para que entre en pánico cuando detecte caracteres que no sean ASCII:
func updateRequestCount(ctx context.Context, name string) (int, error) {
span, ctx := apm.StartSpan(ctx, “updateRequestCount”, “custom”)
defer span.End()
if strings.IndexFunc(name, func(r rune) bool {return r >= unicode.MaxASCII}) >= 0 {
panic(“non-ASCII name!”)
}
...
}
Ahora envía una solicitud con algunos caracteres que no sean ASCII:
curl -f http://localhost:8000/hello/世界 curl: (22) The requested URL returned error: 500 Internal Server Error
Mmm. ¿Cuál podría ser el problema? Echemos un vistazo en la UI de APM, en la página Errors (Errores) del servicio “hello”:
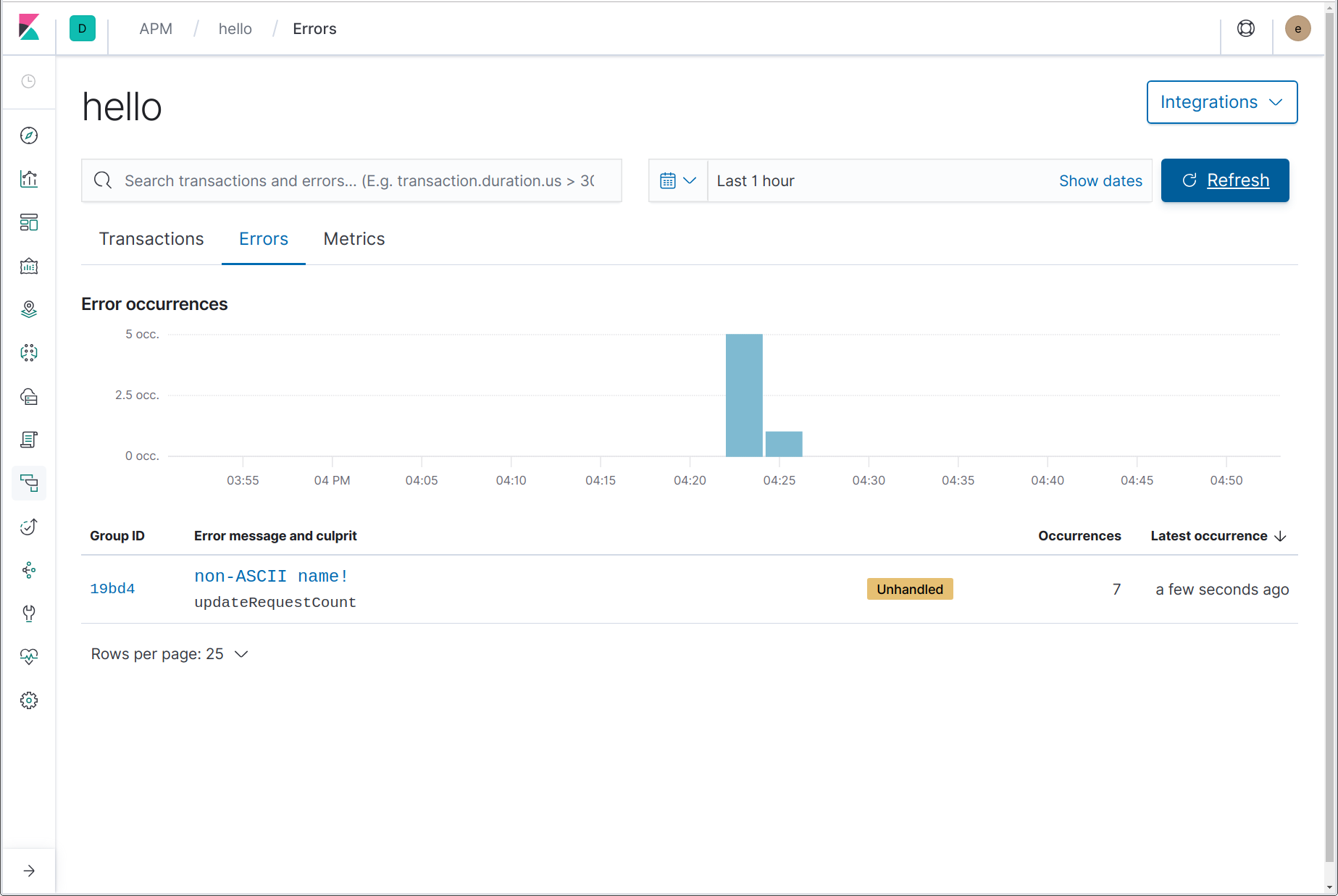
Aquí podemos ver que ocurrió un error, incluido el mensaje de error (pánico), “non-ASCII name!” (nombre con caracteres que no son ASCII), y el nombre de la función en la que se originó el pánico, updateRequestCount. Si haces clic en el nombre del error, el enlace nos lleva a los detalles de la instancia más reciente de dicho error. En la página de detalles del error, podemos ver el rastreo del Stack completo y un snapshot de los detalles de la transacción en la que ocurrió el error al momento del error, junto con un enlace a la transacción finalizada.
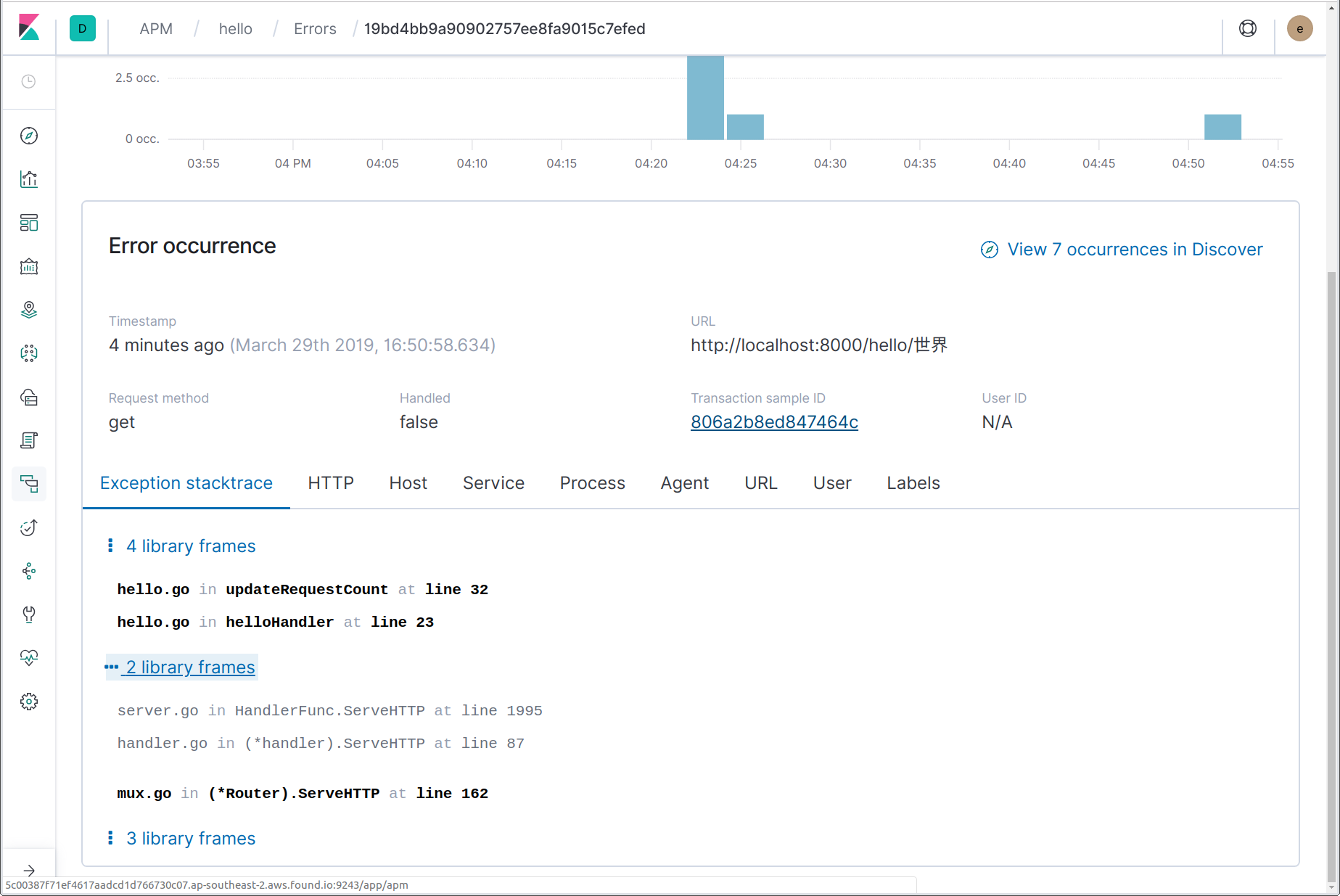
Además de capturar estos pánicos, también puedes reportar explícitamente errores en Elastic APM usando la función apm.CaptureError. Debes pasar a esta función un contexto que contenga una transacción y un valor de error. CaptureError devolverá un objeto “apm.Error”, que opcionalmente puedes personalizar y después finalizar usando su método Send:
if err != nil {
apm.CaptureError(req.Context(), err).Send()
return err
}
Por último, es posible la integración con marcos de trabajo de logging para enviar logs de error a Elastic APM. Hablaremos sobre esto en más detalle en la sección siguiente.
Integración con logging
En los últimos años, se ha hablado mucho sobre los “tres pilares de la observabilidad”: rastreos, logs y métricas. Lo que hemos estado viendo hasta ahora es el rastreo, pero el Elastic Stack abarca estos tres pilares y más. Hablaremos sobre las métricas un poco más adelante; veamos cómo Elastic APM se integra con tu logging de aplicación.
Si realizaste algún tipo de logging centralizado, probablemente ya estés muy familiarizado con el Elastic Stack, antes conocido como el ELK (Elasticsearch, Logstash, Kibana) Stack. Cuando tienes tanto los logs como los rastreos en Elasticsearch, la referencia cruzada se vuelve directa.
El agente Go cuenta con módulos de integración para varios marcos de trabajo de logging populares: Logrus (apmlogrus), Zap (apmzap) y Zerolog (apmzerolog). Agreguemos un poco de logging a nuestro servicio web usando Logrus y veamos cómo podemos integrarlo con nuestros datos de rastreo.
import "github.com/sirupsen/logrus"
var log = &logrus.Logger{
Out: os.Stderr,
Hooks: make(logrus.LevelHooks),
Level: logrus.DebugLevel,
Formatter: &logrus.JSONFormatter{
FieldMap: logrus.FieldMap{
logrus.FieldKeyTime: "@timestamp",
logrus.FieldKeyLevel: "log.level",
logrus.FieldKeyMsg: "message",
logrus.FieldKeyFunc: "function.name", // non-ECS
},
},
}
func init() {
apm.DefaultTracer.SetLogger(log)
}
Construimos un logrus.Logger que escribe en stderr y da formato JSON a los logs. Para una mejor adecuación al Elastic Stack, estamos mapeando algunos de los campos de log estándares a sus equivalentes en Elastic Common Schema (ECS). Alternativamente, podríamos dejarlos en la configuración predeterminada y después usar procesadores Filebeat para traducir, pero esto es un poco más simple. También le indicamos al agente APM que use este logger Logrus para registrar mensajes de depuración a nivel del agente.
Ahora echemos un vistazo a cómo podemos integrar los logs de aplicaciones con datos de rastreo de APM. Agregaremos un poco de logging en nuestro controlador de rutas helloHandler y veremos cómo podemos agregar las ID de rastreo a los mensajes de log. Después veremos cómo podemos enviar los registros de log de error a Elastic APM para que se muestren en la página “Errors” (Errores).
func helloHandler(w http.ResponseWriter, req *http.Request) {
vars := mux.Vars(req)
log := log.WithFields(apmlogrus.TraceContext(req.Context()))
log.WithField("vars", vars).Info("handling hello request")
name := vars["name"]
requestCount, err := updateRequestCount(req.Context(), name, log)
if err != nil {
log.WithError(err).Error(“failed to update request count”)
http.Error(w, "failed to update request count", 500)
return
}
stats, err := getNameStats(req.Context(), name)
if err != nil {
log.WithError(err).Error(“failed to update request count”)
http.Error(w, "failed to get name stats", 500)
return
}
fmt.Fprintf(w, "Hello, %s! (#%d)\n", name, requestCount)
fmt.Fprintf(w, "In %s, %d: ", stats.Region, stats.Year)
switch n := stats.Male.N + stats.Female.N; n {
case 1:
fmt.Fprintf(w, "there was 1 baby born with the name %s!\n", name)
default:
fmt.Fprintf(w, "there were %d babies born with the name %s!\n", n, name)
}
}
func updateRequestCount(ctx context.Context, name string, log *logrus.Entry) (int, error) {
span, ctx := apm.StartSpan(ctx, "updateRequestCount", "custom")
defer span.End()
if strings.IndexFunc(name, func(r rune) bool { return r >= unicode.MaxASCII }) >= 0 {
panic("non-ASCII name!")
}
tx, err := db.BeginTx(ctx, nil)
if err != nil {
return -1, err
}
row := tx.QueryRowContext(ctx, "SELECT count FROM stats WHERE name=?", name)
var count int
switch err := row.Scan(&count); err {
case nil:
if count == 4 {
return -1, errors.Errorf("no more")
}
count++
if _, err := tx.ExecContext(ctx, "UPDATE stats SET count=? WHERE name=?", count, name); err != nil {
return -1, err
}
log.WithField("name", name).Infof("updated count to %d", count)
case sql.ErrNoRows:
count = 1
if _, err := tx.ExecContext(ctx, "INSERT INTO stats (name, count) VALUES (?, 1)", name); err != nil {
return -1, err
}
log.WithField("name", name).Info("initialised count to 1")
default:
return -1, err
}
return count, tx.Commit()
}
Si ahora ejecutamos el programa con la salida redirigida a un archivo (/tmp/hello.log, suponiendo que ejecutas Linux o macOS), podemos instalar y ejecutar Filebeat para enviar los logs al mismo Elastic Stack que recibe los datos de APM. Después de instalar Filebeat, modificaremos su configuración en filebeat.yml de la siguiente manera:
- Establece “enabled: true” en la entrada de log en “filebeat.inputs” y cambia la ruta a “/tmp/hello.log”.
- Si estás usando Elastic Cloud, establece “cloud.id” y “cloud.auth” o, de lo contrario, “output.elasticsearch.hosts”.
- Agrega un procesador “decode_json_fields”, y “processors” se verá de la siguiente manera:
processors:
- add_host_metadata: ~
- decode_json_fields:
fields: ["message"]
target: ""
overwrite_keys: true
Ahora ejecuta Filebeat y los logs comenzarán a fluir. Si enviamos algunas solicitudes al servicio, podremos saltar de los rastreos a los logs al mismo momento usando la acción “Show host logs” (Mostrar logs de host).
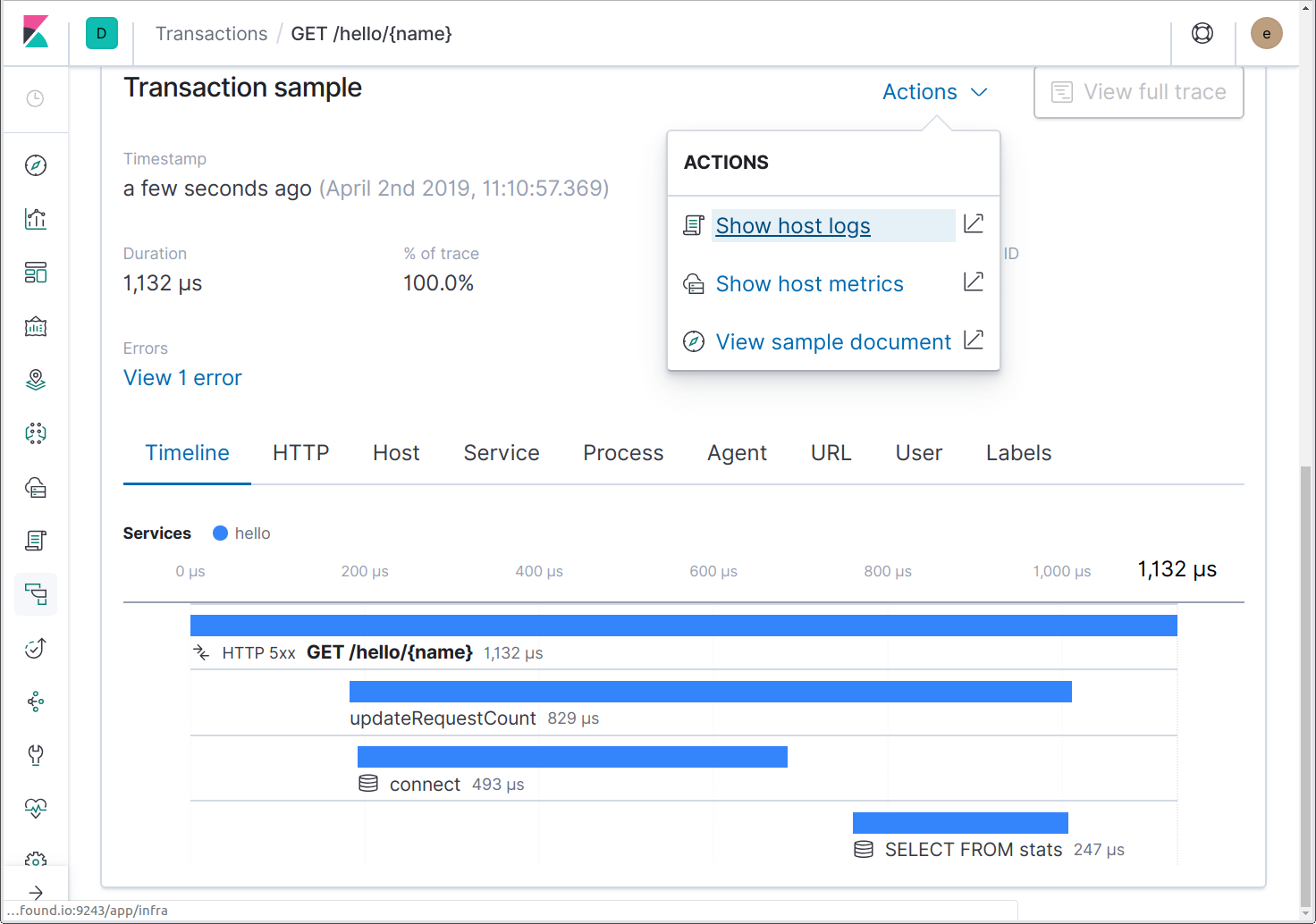
Esta acción nos llevará a la UI de Logs, filtrada para el host. Si la aplicación estuviera ejecutándose en un contenedor Docker o dentro de Kubernetes, habría disponibles acciones para enlazar a logs del contenedor Docker o el pod de Kubernetes.
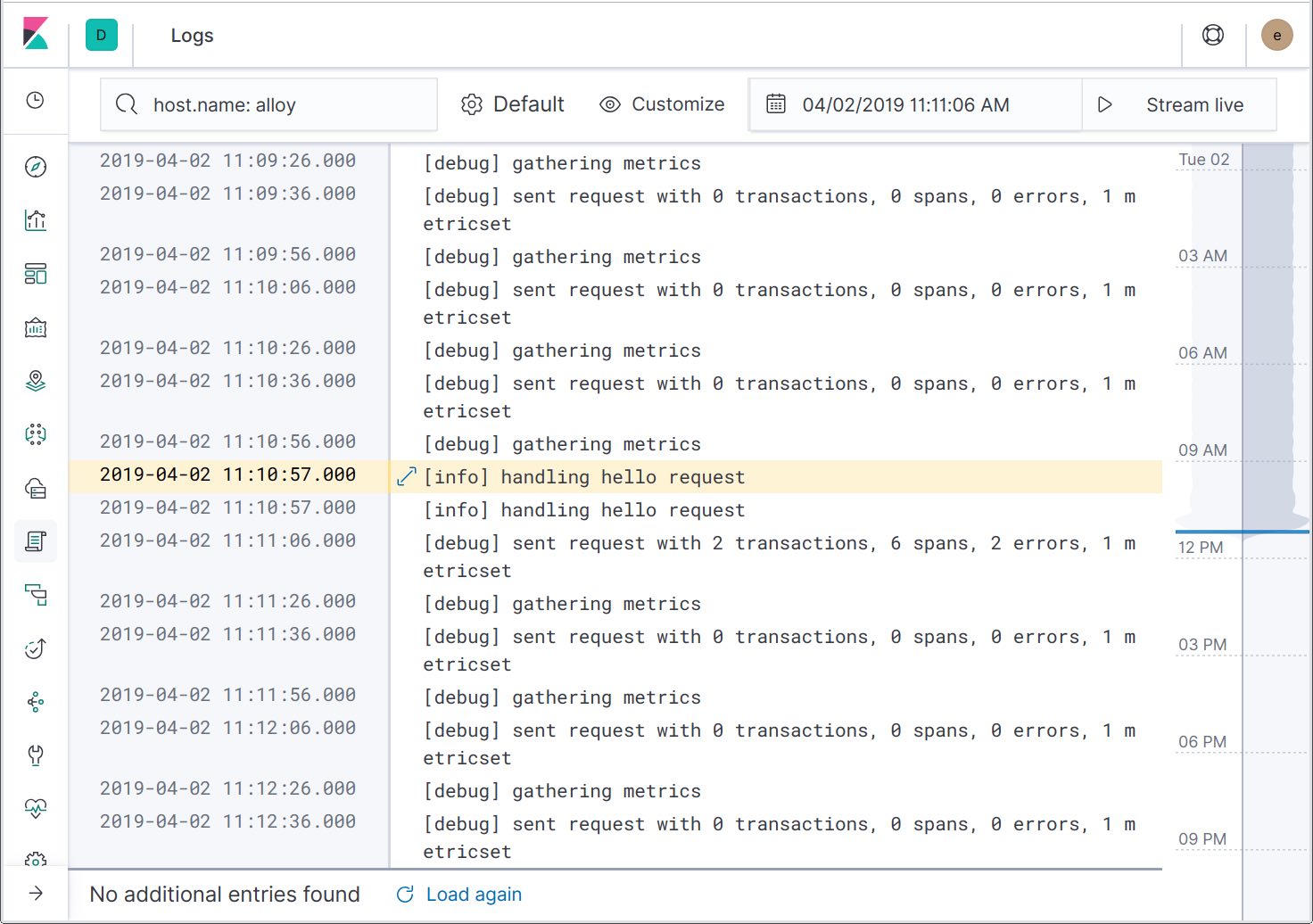
Si ampliamos los detalles del registro de log, podemos ver que las ID de rastreo se incluyeron en los mensajes de log. Más adelante, se agregará otra acción para filtrar los logs hasta el rastreo específico, lo que te permitirá ver solamente los mensajes de log relacionados.
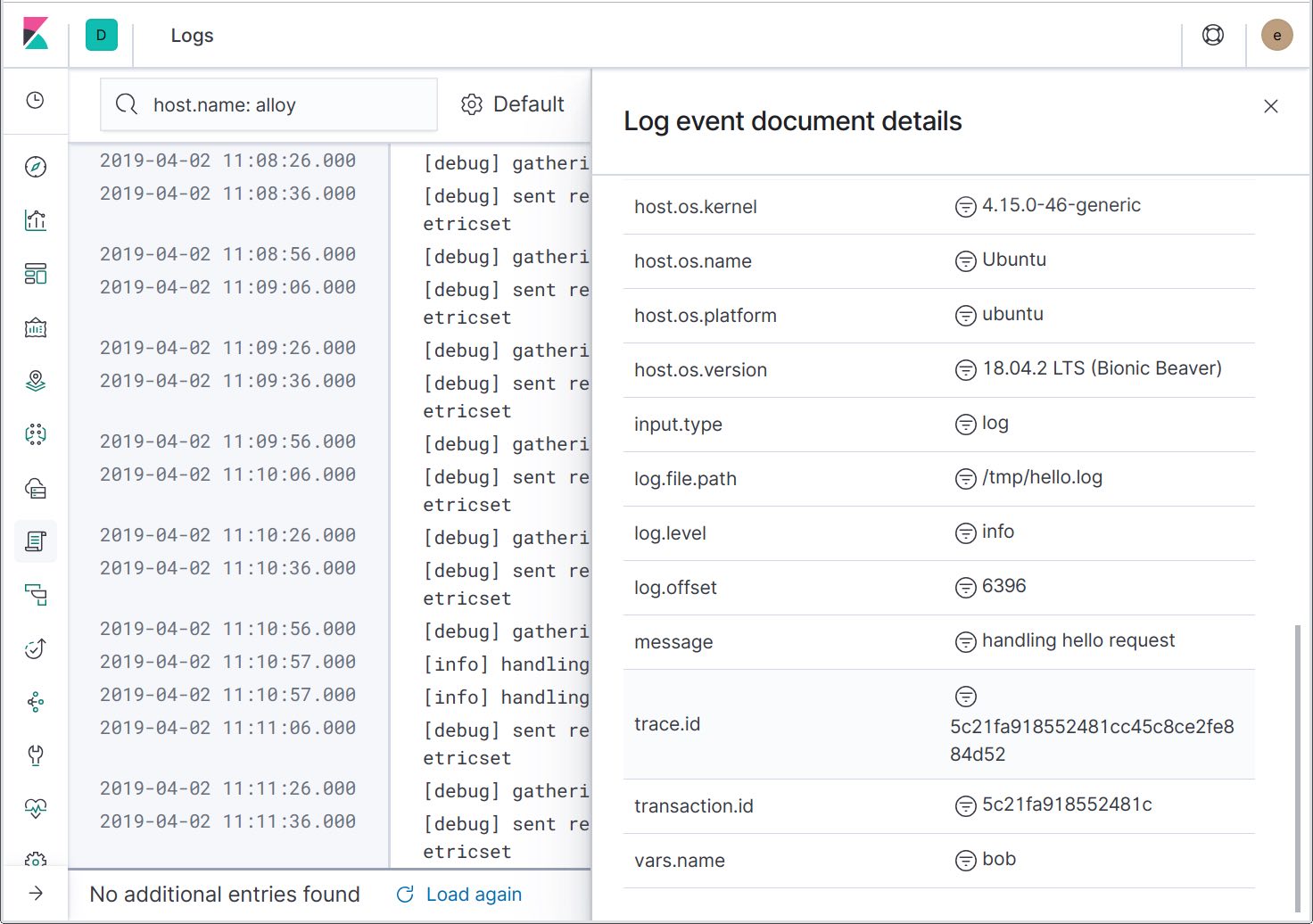
Ahora que tenemos la habilidad de saltar de los rastreos a los logs, veamos el otro punto de integración: enviar logs de error a Elastic APM para que se muestren en la página “Errors” (Errores). Para lograr esto, debemos agregar un apmlogrus.Hook al logger:
func init() {
// apmlogrus.Hook enviará los mensajes de log “error”, “panic” y “fatal” a Elastic APM.
log.AddHook(&apmlogrus.Hook{})
}
Antes cambiamos updateRequestCount para que devuelva un error después de la 4ta llamada y helloHandler para que registre eso como un error. Enviemos 5 solicitudes para el mismo nombre y veamos qué se muestra en la página “Errors” (Errores).
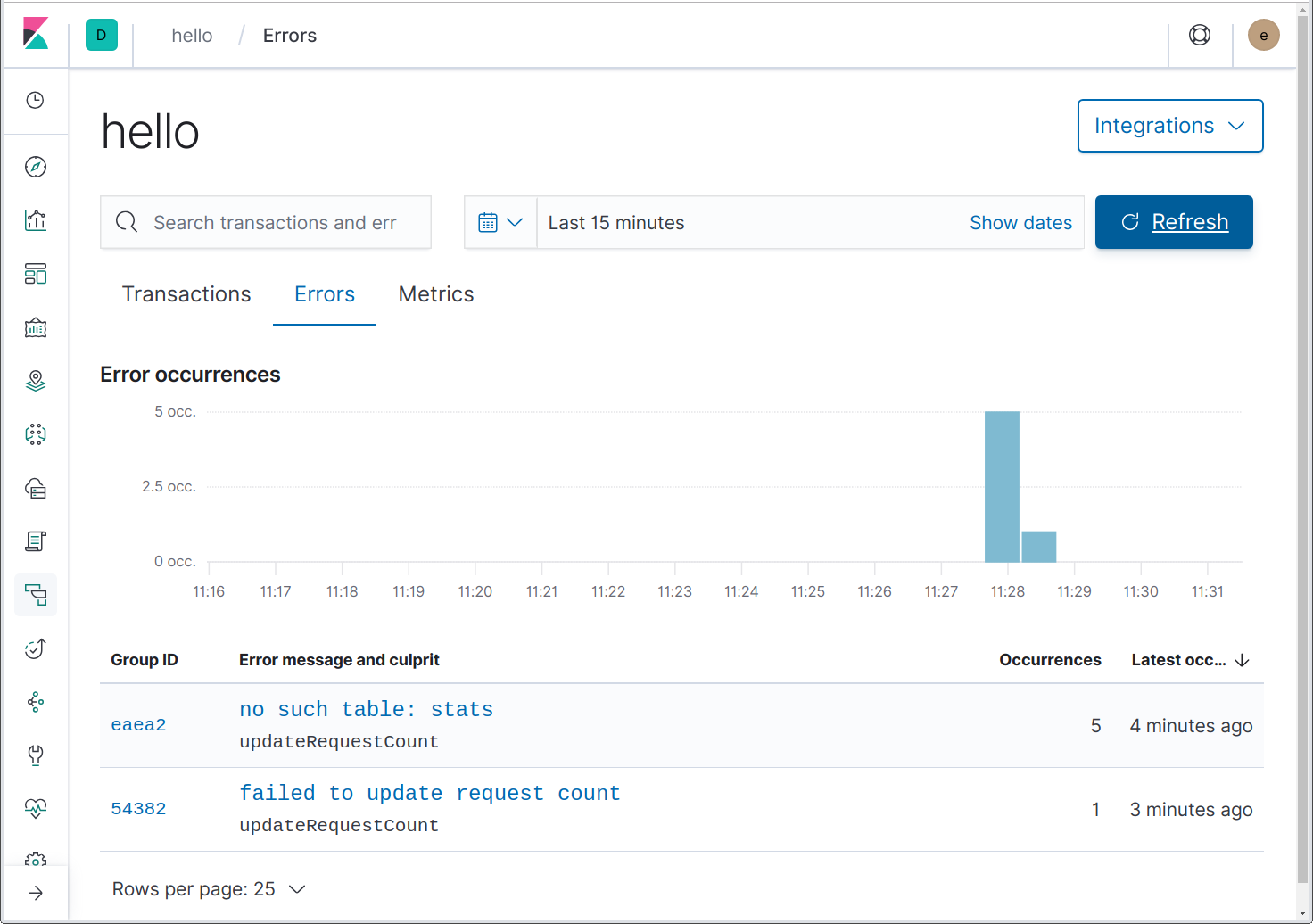
Aquí podemos ver dos errores. Uno de ellos es un error inesperado debido al uso de una base de datos dentro de la memoria, lo cual está mejor explicado en https://github.com/mattn/go-sqlite3/issues/204. ¡Bien hecho! El error “failed to update request count” (error al actualizar el recuento de solicitudes) es el que vinimos a ver.
Observa que el causante de ambos errores es updateRequestCount. ¿Cómo sabe esto Elastic APM? Porque estamos usando github.com/pkg/errors, lo que agrega un rastreo del Stack a cada error que cree o incluya, y el agente Go sabe hacer uso de estos rastreos del Stack.
Métricas de infraestructura y aplicación
Por último, llegamos a las métricas. De manera similar a como saltas con Filebeat a logs de host y contenedor, puedes saltar con Metricbeat a métricas de infraestructura de host y contenedor. Además, los agentes Elastic APM reportan periódicamente el uso de memoria y CPU del sistema y los procesos.
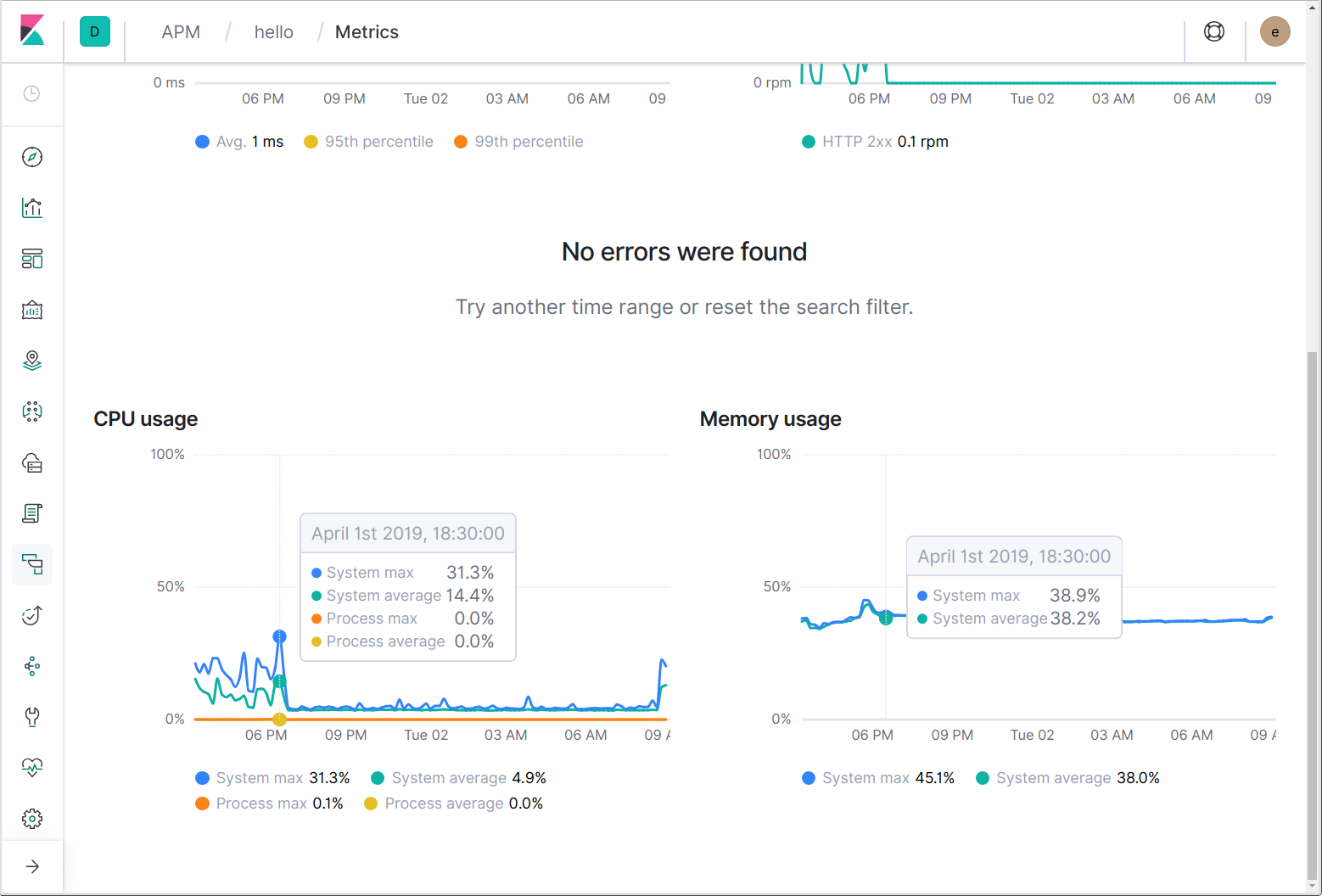
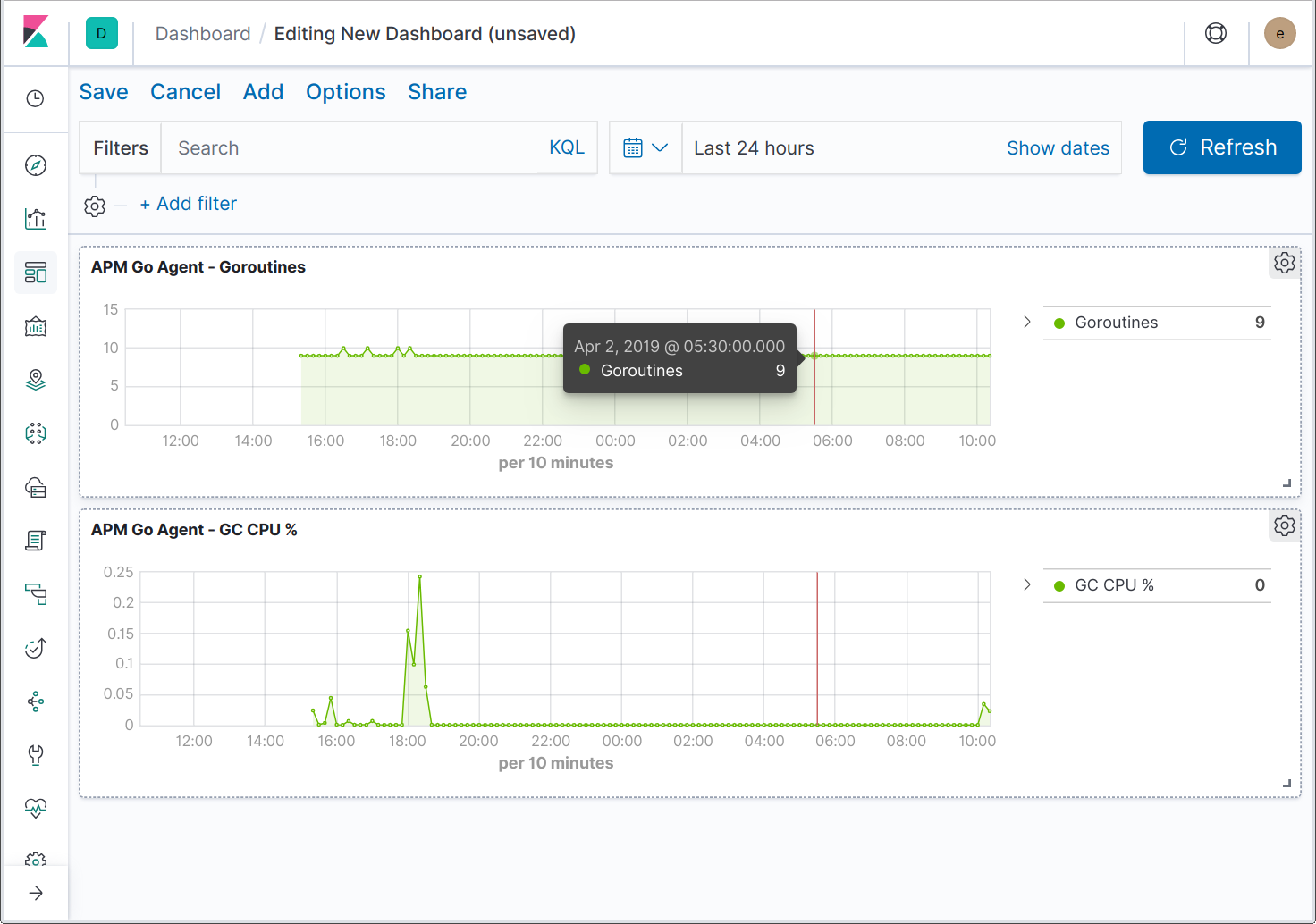
Los agentes también pueden enviar métricas específicas de la aplicación y el lenguaje. Por ejemplo, el agente Java envía métricas específicas de JVM, mientras que el agente Go envía métricas del tiempo de ejecución de Go, por ejemplo, la cantidad actual de goroutines, .la cantidad acumulada de asignaciones de heap y el porcentaje de tiempo dedicado a la recolección de basura.
Ya están en marcha las tareas de ampliación de la UI para soportar métricas de aplicaciones adicionales. Mientras, puedes crear dashboards para visualizar las métricas específicas de Go.
Espera, ¡hay más!
Hemos pasado por alto el agente Monitoreo de usuario real (RUM), que te permitiría ver un rastreo distribuido comenzando en el navegador y siguiendo todo el recorrido por tus servicios de backend. Analizaremos este tema en un futuro blog. Mientras, puedes comenzar por A Sip of Elastic RUM (Un pantallazo de Elastic RUM).
Abarcamos mucho contenido en este artículo. Si tienes más preguntas, únete en el foro de Debate y haremos todo lo posible por responder.