Lanzamiento del Elastic Stack 7.0.0
¡Llegó la versión 7.0! Este lanzamiento representa más de 10 000 solicitudes de extracción de 861 committers, por lo que queremos agradecer en primer lugar a nuestros empleados y nuestra comunidad.
Si deseas obtener más información sobre el lanzamiento, haremos un evento de lanzamiento virtual en vivo con los responsables de escribir el código el 25 de abril de 2019, a las 8 a. m. PDT. Únete a nosotros para ver demostraciones de la versión 7.0, acompáñanos en una ronda de preguntas con los ingenieros de Elastic de todo el mundo y más.
El Elastic Stack 7.0 está disponible para descargar de inmediato, o puedes activar despliegues totalmente administrados en Elasticsearch Service en Elastic Cloud (la única solución hospedada que ofrece las versiones nuevas del Elastic Stack el día de su lanzamiento).
Con tantas buenas novedades en la versión 7.0, es difícil saber por dónde comenzar; así que no perdamos tiempo.
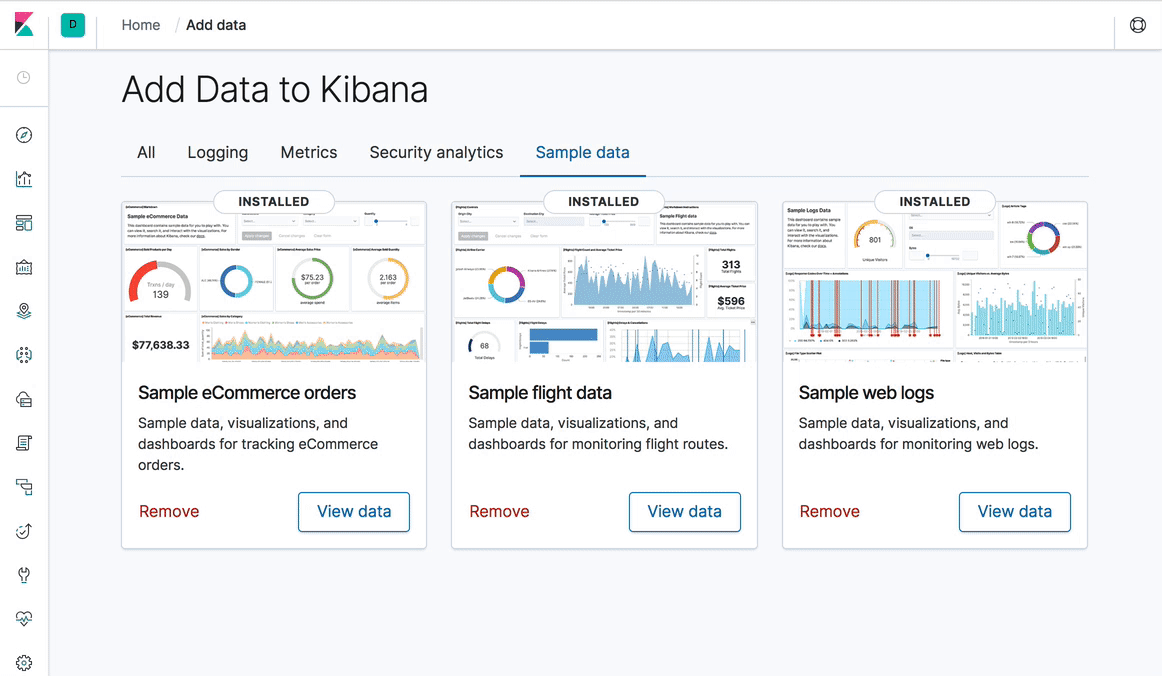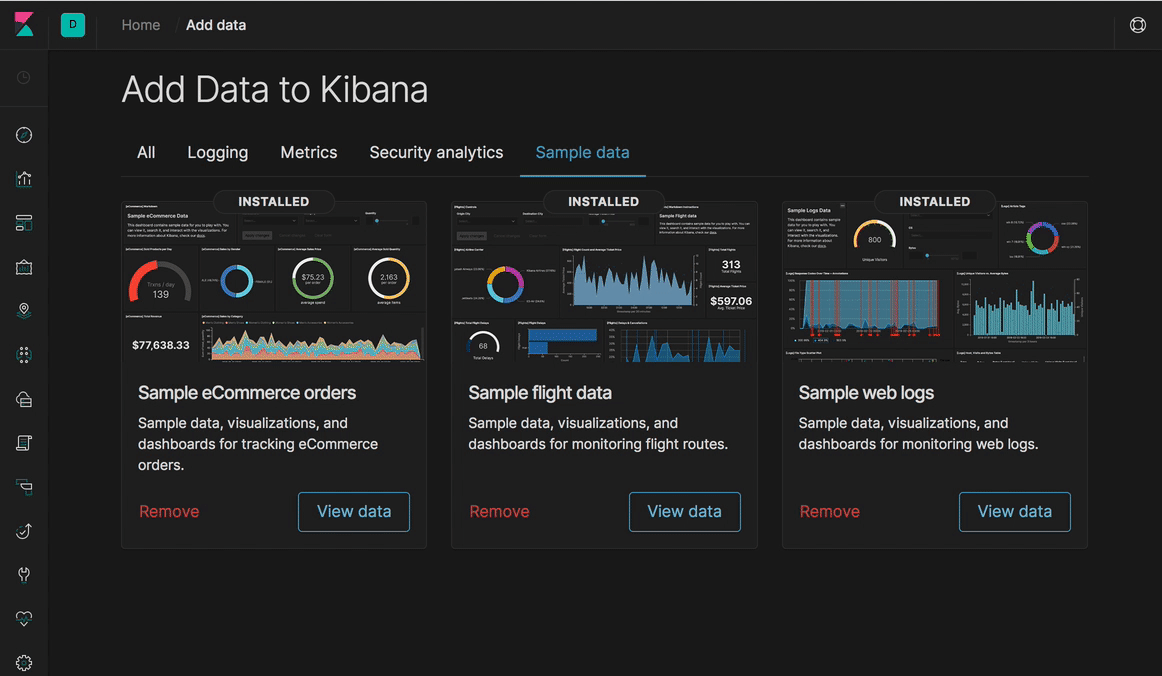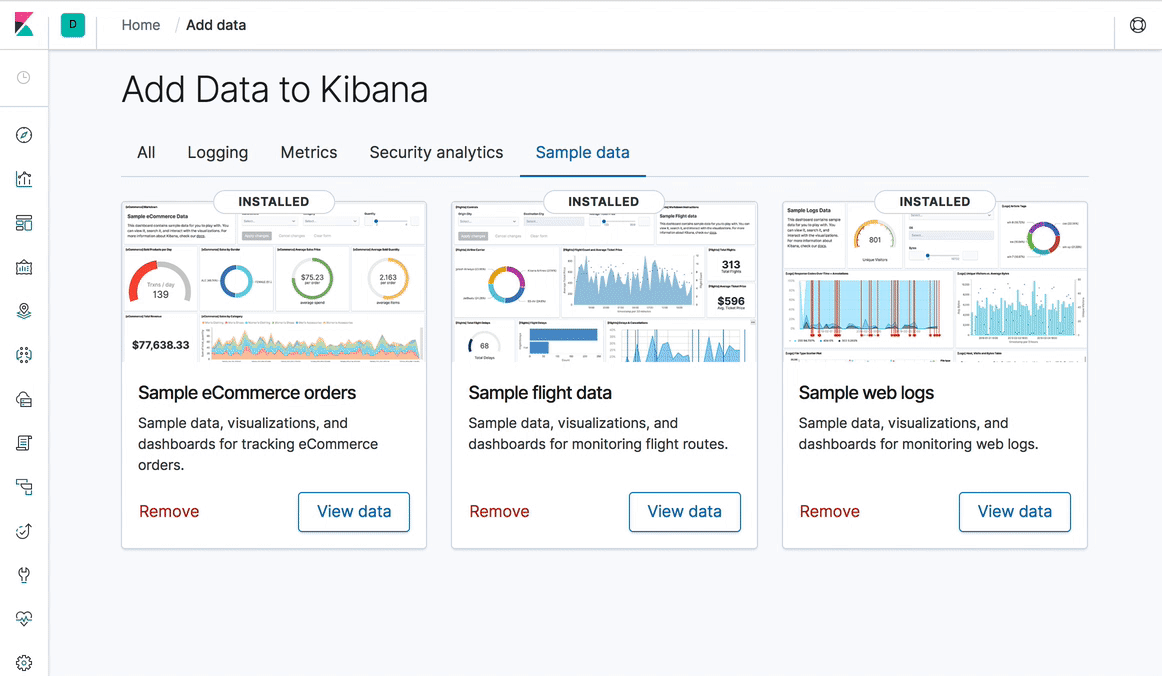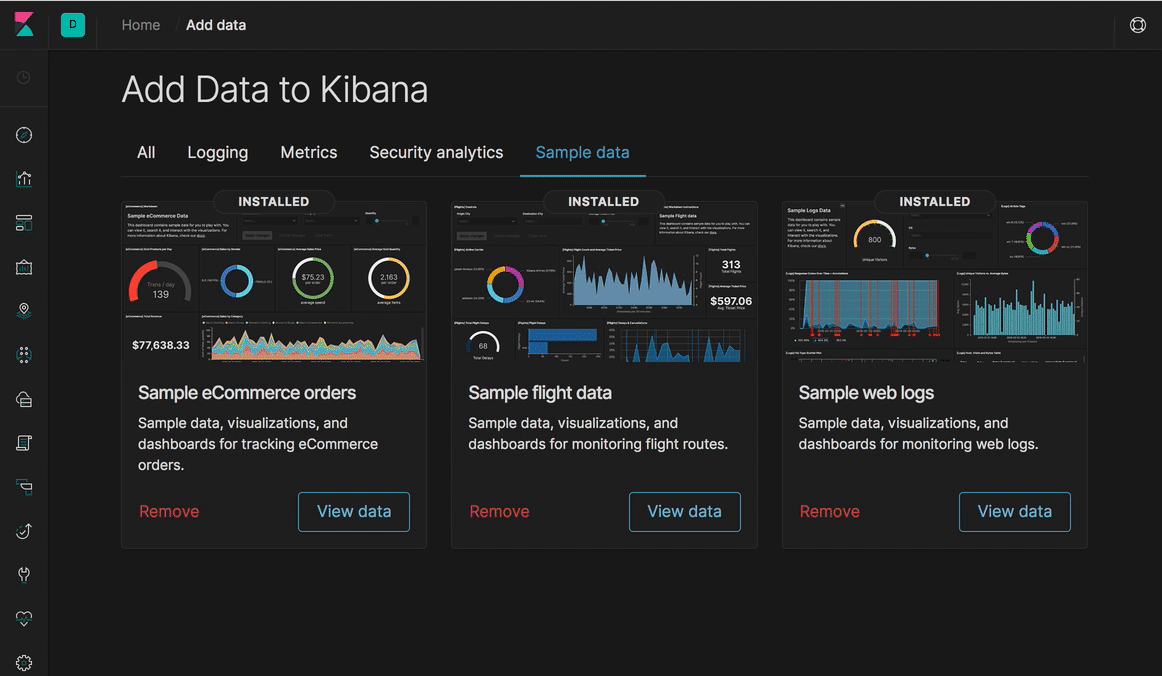
Kibana 7.0: Diseño y navegación nuevos... ¡y dark mode!
En el diseño de Kibana 7.0, decidimos enfocarnos en el contenido; por lo que verás que toda la UI tiene un aspecto más ligero y minimalista. Lo más llamativo es el cambio a una nueva navegación global que introduce un encabezado constante para cambiar entre espacios de Kibana, mostrar rutas de navegación e iniciar acciones del usuario como cambiar la contraseña o cerrar sesión. Para lograr esto y aumentar la coherencia, creamos Elastic UI Framework. Durante el último año, convertimos Kibana casi por completo para usar estos componentes. Gracias a estos componentes y a un esfuerzo enorme de nuestros equipos de diseño e ingeniería, también simplificamos drásticamente la forma de aplicar estilos y hojas de estilo.
La mayor coherencia y las mejoras en las hojas de estilo nos permitieron considerar como cumplida una de las solicitudes de características más importantes en la historia de Kibana: el dark mode (modo oscuro) en todo Kibana. Otro de los beneficios de estos cambios es que ahora los dashboards de Kibana tienen un diseño receptivo, lo que constituye el primer paso para una mejora drástica en la facilidad de uso en dispositivos móviles.
Una nueva era para la coordinación de clusters en Elasticsearch
Desde el comienzo, nos hemos enfocado en hacer que Elasticsearch sea fácil de escalar y resistente a errores catastróficos. Para dar soporte a estos requisitos, adoptamos varios enfoques: desde hacer los nodos individuales más escalables y confiables hasta mejorar continuamente nuestra capa de coordinación de clusters, conocida como Zen Discovery. Con la versión 7.0, presentamos nuevamente grandes mejoras en ambas áreas.
Existe una capa de coordinación de clusters completamente nueva para Elasticsearch, que es más rápida, segura y fácil de usar. Para lograr esto, comenzamos por enfocarnos en la corrección teórica de nuestro nuevo algoritmo de consenso distribuido mediante [modelos formales] (https://www.elastic.co/es/elasticon/conf/2018/sf/reliable-by-design-applying-formal-methods-to-distributed-systems) para [validar el diseño] (https://www.elastic.co/es/elasticon/conf/2018/sf/reliable-by-design-applying-formal-methods-to-distributed-systems). Aunque existen algoritmos de consenso conocidos (como Paxos, Raft, Zab y Viewstamped Replication [VR]), las demandas de un cluster de Elasticsearch requieren mayor rendimiento para cambios de cluster, soporte para hacer crecer o reducir un cluster, y una estrategia de actualización continua y fluida que permita la actualización continua de los clusters 6.7 a la versión 7.0; y estos algoritmos de referencia no los proporcionan. La nueva capa de coordinación de clusters también incluye varios cambios que reducen la probabilidad de error humano y proporciona opciones más claras durante la recuperación de un error catastrófico. No es fácil mejorar al mismo tiempo la confiabilidad, el rendimiento y la experiencia del usuario, especialmente en un componente que ocupa un lugar tan central. Estamos orgullosos de la nueva capa de coordinación de clusters y del proceso que emprendimos para lograr este avance. Para obtener más información, lee el blog.
Los nodos individuales en Elasticsearch se crean teniendo en cuenta la resistencia. Si envías demasiadas solicitudes a un nodo o tus solicitudes son muy grandes, el nodo las rechazará. Logramos esto mediante interruptores de circuito en Elasticsearch, que determinan que el nodo no podrá manejar una solicitud dada y responden de inmediato solicitándole al cliente que vuelva a intentarlo, tal vez en un nodo diferente. Esto es incluso más importante en el caso de los nodos con tamaños de heap JVM más pequeños, que son cada vez más comunes a medida que los usuarios cambian a un modelo de cluster por usuario en lugar de tener un gran cluster con usuarios múltiples. En la versión 7.0 presentamos el interruptor de circuito de memoria real, que detecta de forma mucho más precisa las solicitudes que no pueden responderse y evita que estas desestabilicen un nodo individual. Lee el blog para conocer más sobre cómo este cambio mejora la confiabilidad general en el nodo y el cluster.
Mejora de la relevancia y la velocidad en todos los casos de uso
La relevancia y la velocidad son las piezas clave de una buena experiencia de búsqueda. Y Elasticsearch 7.0 presenta varias características fundamentales que mejoran ambas.
- Búsquedas más rápidas de un número determinado de resultados (top k): En muchos casos de uso de búsqueda, ver rápidamente los resultados top k (digamos 20) de una búsqueda es mucho más importante para el usuario que el recuento de coincidencias exacto (es decir, la cantidad total de resultados que coinciden con la búsqueda). Por ejemplo, si alguien busca un producto en un sitio web de comercio electrónico, estará mucho más interesado en los 10 resultados más relevantes que en los otros 120 897 resultados que coinciden con su consulta de búsqueda. Elasticsearch 7.0 (y Lucene 8.0) implementa un algoritmo nuevo (Block-Max WAND) que proporciona una gran mejora en la velocidad al momento de recuperar las coincidencias principales.
- Búsquedas de intervalos: Algunos casos de uso, como las búsquedas legales y de patentes, introducen la necesidad de encontrar registros en los que las palabras o frases se encuentren a cierta distancia entre sí. Las búsquedas de intervalos en Elasticsearch 7.0 presentan una manera completamente nueva de estructurar tales búsquedas y son significativamente más simples de usar y definir en comparación con el método anterior (búsquedas de extensión). Las búsquedas de intervalos también son mucho más resistentes en los casos extremos en comparación con las búsquedas de extensión.
- Puntaje de función 2.0: La puntuación personalizada es esencial en los casos de uso de búsqueda avanzada en los que se desea un control más refinado de la relevancia y la clasificación de los resultados. Elasticsearch proporciona esta capacidad desde sus comienzos. La versión 7.0 presenta la próxima generación de la capacidad de puntaje de función que proporciona una manera más simple, modular y flexible de generar un puntaje de clasificación por registro. La nueva estructura modular permite a los usuarios mezclar y combinar un conjunto de funciones aritméticas y de distancia para crear cálculos de puntaje de función arbitrarios, lo que brinda mayor control sobre cómo se puntúan y clasifican los resultados.
Zoom perfecto en Elastic Maps con la cuadrícula de mosaicos geográficos
Nuestro soporte de los datos geográficos ha mejorado continuamente a lo largo de los años: desde el inicio cuando se agregó el soporte geográfico por primera vez a Elasticsearch, la introducción de la estructura de datos Bkd-Tree y Lucene y su uso para mejorar más de 25 veces el rendimiento de las búsquedas de geoformas, hasta Elastic Maps Service que impulsa el mapa base global en Kibana.
Con la versión 7.0, continuamos con esta inversión y presentamos una agregación nueva en Elasticsearch para manejar mosaicos de mapa (geográficos) de una manera que permita al usuario acercar y alejar el mapa sin modificar la forma de los datos resultantes. La nueva agregación geotile_grid agrupa geo_points en depósitos que representan celdas en una cuadrícula, en la que cada celda se corresponde con un mosaico de un mapa. Antes de este cambio, los márgenes de una forma podían modificarse levemente con el cambio en el nivel de zoom, debido a que los mosaicos rectangulares cambiaban de orientación en los distintos niveles de zoom. Elastic Maps ya usa esta agregación nueva en la versión 7.0 para garantizar que la vista se mantenga estable cuando acercas y alejas. Este nivel de precisión es importante, ya sea para proteger la red frente a atacantes, investigar tiempos de respuesta lentos de aplicaciones en ubicaciones específicas o rastrear a tu hermano que está haciendo el Sendero de la Cresta del Pacífico.
Fortalecimiento de los casos de uso de series temporales con soporte de precisión en nanosegundos
Ya sean métricas de infraestructura, logs de auditoría de sistemas, tráfico de red o el róver en Marte, los datos temporales son un motivo esencial por el cual muchas personas usan el Elastic Stack. La capacidad de ordenar y correlacionar con precisión eventos en varios sistemas y servicios es clave.
Hasta ahora, Elasticsearch solo almacenaba marcas de tiempo con precisión en milisegundos. En la versión 7.0 se agregan algunas cifras que brindan una precisión en nanosegundos, lo que proporciona a los usuarios con necesidades de recopilación de datos de alta frecuencia la precisión necesaria para almacenar y ordenar en secuencia dichos datos de forma precisa. El cambio fue posible gracias a la migración de la biblioteca JODA histórica a la API de tiempo oficial de Java en JDK 8.