Cómo crear un dashboard personalizado de reporte de incidentes de ServiceNow en Canvas
¡Bienvenido una vez más! Esta es la tercera y última parte de esta serie sobre cómo usar el Elastic Stack con ServiceNow para la gestión de incidentes. En el primer blog, presentamos el proyecto y configuramos ServiceNow para que los cambios en un incidente se transfieran automáticamente a Elasticsearch. En el segundo blog, implementamos la lógica para unir ServiceNow y Elasticsearch a través de alertas y transformaciones, y también algunas configuraciones generales de Elasticsearch.
En este punto, todo es completamente funcional. Sin embargo, falta el front end útil (y atractivo) que usaremos para la gestión de incidentes. En este blog, crearemos el panel de trabajo de Canvas siguiente para que las personas puedan tomar todo ese valor que tenemos hasta ahora y convertirlo en algo que puedan comprender y usar con facilidad.
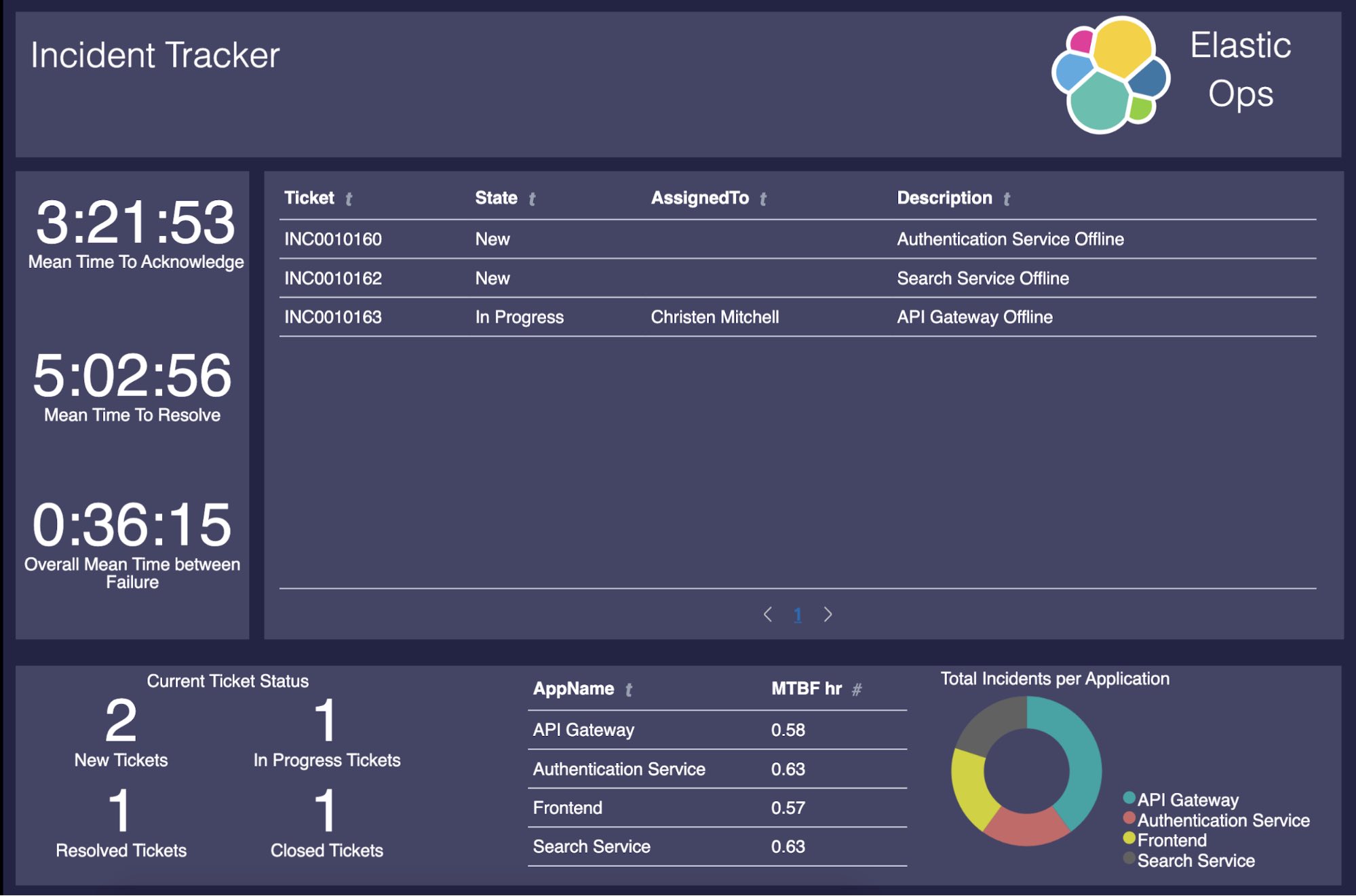
Esto es lo que mostraremos en nuestro dashboard:
- Tickets abiertos, cerrados, resueltos y en proceso
- MTTA de incidentes
- MTTR de incidentes
- MTBF general
- MTBF de las aplicaciones
- Incidentes por aplicación
Comencemos.
Configuración de un panel de trabajo de Canvas
En este blog, usaremos mucho las expresiones de Canvas porque todos los elementos en un panel de trabajo están representados internamente por expresiones. Por lo tanto, significa que es la forma más fácil de mostrarte cómo recrear capacidades.
Ten en cuenta que si no tienes ningún dato dentro de los índices centrados en entidades que las transformaciones completan, algunos de los elementos siguientes generarán un mensaje de error similar a “Empty datatable” (tabla de datos vacía).
Antes de comenzar, abramos Canvas:
- Expande la barra de herramientas de Kibana.
- Si estás ejecutando la versión 7.8 o superior, puedes encontrarla en Kibana, de lo contrario estará en la lista de todos los demás íconos.
- Haz clic en el botón Create Workpad (Crear panel de trabajo).
- Una vez creado un panel de trabajo, asígnale un nombre. Se puede configurar dentro de Workpad Settings (Configuraciones del panel de trabajo) sobre el lado derecho. Recomendamos cambiar “My Canvas Workpad” (Mi panel de trabajo de Canvas) a “Incident Tracker” (Rastreador de incidentes). Aquí también configuraremos el color de fondo en los pasos siguientes.
- Para editar la expresión de Canvas de un componente dado, haz clic en ella y después en </> Expression editor (Editor de expresiones) en la parte inferior derecha.
Configuración del tema
El primer paso para crear nuestro panel de trabajo de Canvas es la apariencia del fondo:
- Configura el color de fondo como #232344.
- Crea los cuatro elementos de forma con forma de rectángulo y configura el color de relleno como #444465.
- Agrega el logotipo y texto en la barra superior, como logotipo de la empresa, nombre de la empresa y un título.
Visualización de los tickets en acción
Ahora necesitamos crear la tabla en el medio que muestra cuáles tickets están en acción. Para hacerlo, usaremos una combinación de expresiones de Canvas y Elasticsearch SQL junto con un elemento de "tabla de datos". Para crear el elemento de tabla de datos, copia la siguiente expresión de Canvas en el editor y haz clic en ejecutar:
filters
| essql
query="SELECT incidentID as Ticket, LAST(state, updatedDate) as State, LAST(assignedTo, updatedDate) as AssignedTo, LAST(description, updatedDate) as Description FROM \"servicenow*\" group by Ticket ORDER BY Ticket ASC"
| filterrows fn={getCell "State" | any {eq "New"} {eq "On Hold"} {eq "In Progress"}}
| table
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false} paginate=true perPage=10
| render
En esta expresión, ejecutamos la búsqueda y después filtramos todas las filas excepto aquellas que tienen el campo State (Estado) como “New” (Nuevo), “On Hold” (En espera) o “In Progress” (En progreso).
En este punto, probablemente esté vacía porque no tenemos datos. Esto se debe a que es posible que nuestra regla comercial no se haya ejecutado, por lo que no hay ningún dato de ServiceNow en Elasticsearch. Si lo deseas, puedes crear algunos incidentes falsos aquí. Si lo haces, asegúrate de tener tickets en varias etapas para que la tabla parezca un poco realista.
Cómo calcular el tiempo promedio de reconocimiento (MTTA)
Para mostrar el MTTA de los incidentes, agregaremos un elemento de métrica y usaremos la expresión de Canvas siguiente.
filters
| essql
query="SELECT * FROM (SELECT incidentID, updatedDate, state FROM \"servicenow-incident-updates\") PIVOT (MIN(updatedDate) FOR state IN ('New' as New, 'In Progress' as \"InProgress\"))"
| mapColumn "New" fn={getCell "New" | formatdate "X" | math "value"}
| mapColumn "InProgress" fn={getCell "InProgress" | formatdate "X" | math "value"}
| filterrows fn={getCell "InProgress" | gt 0}
| mapColumn "Duration" expression={math expression="InProgress - New"}
| math "mean(Duration)"
| metric "Mean Time To Acknowledge"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
Esta expresión usa funciones de Elasticsearch SQL más avanzadas, incluida PIVOT. Para calcular el MTTA, calculamos el tiempo total entre la creación y el reconocimiento y después lo dividimos por la cantidad de incidentes.. Aquí necesitamos usar PIVOT porque almacenamos cada actualización que hace el usuario en el ticket en ServiceNow. Esto significa que cada vez que alguien actualiza el estado, las notas de trabajo, el usuario asignado, etc., la actualización se transfiere a Elasticsearch. Resulta fantástico para realizar analíticas en esos resultados. Debido a esto, necesitaremos reorganizar los datos para obtener una fila por incidente, con la primera vez que el incidente era “New” (Nuevo) y la primera vez que pasó a “In Progress” (En progreso).
Después podemos calcular el tiempo de reconocimiento restando la hora en que se creó de la hora en que se reconoció cada incidente. El MTTA se calcula con la función de promedio sobre este campo de duración.
Cómo calcular el tiempo promedio de resolución (MTTR)
Para mostrar el MTTR de los incidentes, agregaremos un elemento de métrica y usaremos la expresión de Canvas siguiente:
filters
| essql
query="SELECT * FROM (SELECT incidentID, updatedDate, state FROM \"servicenow-incident-updates\") PIVOT (MIN(updatedDate) FOR state IN ('New' as New, 'Resolved' as \"Resolved\"))"
| mapColumn "New" fn={getCell "New" | formatdate "X" | math "value"}
| mapColumn "Resolved" fn={getCell "Resolved" | formatdate "X" | math "value"}
| filterrows fn={getCell "Resolved" | gt 0}
| mapColumn "Duration" expression={math expression="Resolved - New"}
| math "mean(Duration)"
| metric "Mean Time To Resolve"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
Tal como para el MTTA, usamos la función PIVOT porque necesitamos acceder a una vista de resumen de cada incidente. A diferencia del MTTA, obtenemos la primera vez que vemos el estado cuando es nuevo y también resuelto. Esto se debe a que el MTTR es el tiempo promedio que se tarda en resolver un ticket. Es muy similar al MTTA, y por cuestiones de brevedad no repetiremos los mismos detalles.
Cómo calcular el tiempo promedio entre fallas (MTBF) general
Ahora que tenemos el MTTA y MTTR, es hora del MTBF de cada aplicación. Para esto, usaremos nuestras dos transformaciones: app_incident_summary_transform y calculate_uptime_hours_online_transfo. Gracias a estas transformaciones, calcular el MTBF general es muy fácil. Como el MTBF se mide en horas y nuestra transformación lo calcula en segundos, calculamos el promedio de todas las apps y después multiplicamos el resultado por 3600 (segundos en una hora).
Creemos otro elemento de métrica usando la expresión de Canvas siguiente:
filters
| essql query="SELECT AVG(mtbf) * 3600 as MTBF FROM app_incident_summary"
| math "MTBF"
| metric "Overall Mean Time between Failure"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
Cómo calcular el tiempo promedio entre fallas (MTBF) de las aplicaciones
Ahora que calculamos el MTBF general, podemos mostrar con facilidad el MTBF de cada aplicación. Todo lo que debemos hacer es crear un nuevo elemento de tabla de datos y mostrar los datos en una tabla usando la expresión de Canvas siguiente. Por motivos de legibilidad, redondeamos el MTBF de cada aplicación a dos decimales.
filters
| essql
query="SELECT app_name as AppName, ROUND(mtbf,2) as \"MTBF hr\" FROM app_incident_summary"
| table paginate=false
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false}
| render
Cómo calcular tickets resueltos
Queremos ver algunas victorias, así que nos aseguraremos de tener un recuento "cerrado" en nuestro panel de trabajo. Este es un elemento de métrica simple que obtiene todos los incidentes en los que el estado es “Resolved” (Resuelto) y después la función matemática cuenta la cantidad de ID únicos de incidentes.
filters
| essql query="SELECT state,incidentID FROM \"servicenow*\" where state = 'Resolved'"
| math "unique(incidentID)"
| metric "Resolved Tickets"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="0,0.[000]"
| render
Cómo calcular los incidentes por aplicación
Ahora crearemos un gráfico tipo dona que cuenta la cantidad de incidentes únicos por aplicación. Recomendamos agregar un elemento de reducción sobre este con el texto “Total de incidentes por aplicación” para proporcionar contexto sobre lo que muestra el gráfico tipo dona.
filters
| essql
query="SELECT incidentID as IncidentCount, app_name as AppName FROM \"servicenow*\""
| pointseries color="AppName" size="unique(IncidentCount)"
| pie hole=41 labels=false legend="se" radius=0.72
palette={palette "#01A4A4" "#CC6666" "#D0D102" "#616161" "#00A1CB" "#32742C" "#F18D05" "#113F8C" "#61AE24" "#D70060" gradient=false} tilt=1
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false}
| render
Cómo calcular los estados actuales de los tickets
Esta sección consta de cuatro elementos de métrica. Todos tienen expresiones de Canvas muy similares con solo cambios menores. En resumen, obtendremos la actualización más reciente de todos los incidentes y después usaremos la función de expresión filterrows de Canvas para mantener los que queramos según su estado. Con eso, simplemente contamos la cantidad de incidentes únicos.
Usa la expresión siguiente y actualiza el estado de New (Nuevo) a cada estado deseado. Además, no olvides actualizar el texto en la métrica de “New Tickets” (Nuevos tickets).
filters
| essql
query="SELECT incidentID, LAST(state, updatedDate) as State FROM \"servicenow*\" group by incidentID" count=1000
| filterrows fn={getCell "State" | eq 'New'}
| math "unique(incidentID)"
| metric "New Tickets"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="0,0.[000]"
| render
Producto terminado
Ahora que tenemos creadas todas las diferentes partes de nuestro panel de trabajo de Canvas, obtenemos este dashboard de gestión de incidentes extremadamente útil:
Terminamos, ¡comienza a usar lo que aprendiste!
Eso es todo. En este viaje usamos varios componentes del Elastic Stack para calcular el MTTA, MTTR y MTBF según los incidentes de ServiceNow y después mostramos esa información en un dashboard útil y visualmente atractivo. Una conclusión importante aquí es que esta información reside junto con tus datos reales, en lugar de en otra herramienta. Estas métricas proporcionan unos buenos cimientos de conocimiento que las personas pueden usar para entender el estado de una aplicación en relación con los incidentes reportados. Por ejemplo, si el MTBF es muy bajo, significa que la aplicación falla con mucha frecuencia. Si el MTTA es alto, significa que se tarda mucho en comenzar la investigación de una falla.
Si solo estuviste leyendo y no probaste hacerlo tú mismo, te recomendamos que pongas manos a la obra y lo intentes. Puedes activar una prueba gratuita de Elastic Cloud y usarla con tu instancia de ServiceNow existente o con una instancia de desarrollador personal.
Además, si estás interesado en buscar datos de ServiceNow junto con otras fuentes como GitHub, Google Drive y más, Elastic Workplace Search tiene un conector ServiceNow prediseñado. Workplace Search proporciona una experiencia de búsqueda unificada para tus equipos, con resultados relevantes en todas tus fuentes de contenido. También se incluye en tu prueba de Elastic Cloud.
Este blog proporciona los cimientos de uso de tus datos para rastrear estas métricas. A modo de ejemplo, si quieres ir más allá, puedes crear incidentes basados en tus logs, métricas de infraestructura, rastreos de APM y tus anomalías de Machine Learning. Para proporcionar valor adicional a las partes interesadas de este dashboard de Canvas, por qué no agregar enlaces a las apps en Kibana (Logs, APM, etc.) o tus propios dashboards que les den una ventaja inicial para interrogar sobre la causa raíz del problema respectivo.
Si disfrutaste esta serie, aquí tienes algunos enlaces que creemos que también te gustarán:
- When to use Data Transforms (Cuándo usar transformaciones de datos)
- Getting started with machine learning (Primeros pasos con Machine Learning)
- Intro to Canvas: A new way to tell visual stories in Kibana (Introducción a Canvas: Una forma nueva de contar historias visuales en Kibana)
- Cómo usar el elemento de métrica de Canvas y reducción para agregar enlaces
¡Disfrútalo!