Descubrimiento de patrones anómalos basados en relaciones de procesos principales-secundarios
Como los antivirus y la detección de malware basada en Machine Learning aumentaron su efectividad para detectar ataques basados en archivos, los adversarios migraron a técnicas “living off the land” para evitar el software de seguridad moderno. Esto incluye ejecutar herramientas del sistema preinstaladas con el sistema operativo o generalmente incorporadas por los administradores para realizar tareas como automatizar tareas administrativas de TI, ejecutar scripts de forma regular, ejecutar código en sistemas remotos y mucho más. Los atacantes que usan herramientas de confianza del SO como powershell.exe, wmic.exe o schtasks.exe pueden ser difíciles de identificar. Estos binarios son inherentemente benignos y se usan con frecuencia en la mayoría de los entornos, por lo que los atacantes pueden evitar de forma trivial la mayoría de las defensas de primera línea con solo camuflarse en el ruido de lo que se ejecuta de manera recurrente. Detectar patrones como este posteriores a la vulneración requiere examinar millones de eventos sin un punto de inicio claro.
En respuesta, los investigadores de seguridad han comenzado a crear detectores de cadenas de procesos principales-secundarios sospechosas. Con MITRE ATT&CK™ como cuaderno de estrategias, los investigadores pueden escribir lógica de detección para alertar sobre un proceso principal específico que lanza un proceso secundario con ciertos argumentos de línea de comando. Un buen ejemplo es alertar un powershelll.exe con argumentos codificados en base64 generado por un proceso de MS Office. Sin embargo, este proceso lleva tiempo y requiere experiencia en dominios y un bucle de comentarios explícito para ajustar los detectores ruidosos.
Los trabajadores de seguridad han convertido en open source varios marcos de trabajo rojos vs. azules para simular ataques y evaluar el rendimiento del detector; pero independientemente de lo efectivo que sea el detector, su lógica solo puede resolver un ataque específico. Una falla de los detectores para generalizar y detectar ataques emergentes presenta una oportunidad única para Machine Learning.
Pensar en grafos
Cuando comenzamos a pensar en detectar procesos principales-secundarios anómalos, inmediatamente se nos ocurrió convertir esto en un problema de grafos. Después de todo, la ejecución de procesos se puede expresar como un grafo de un host dado. Los nodos de tu grafo serán procesos individuales separados por ID de proceso (PID), mientras que cada extremo, que conecta los nodos, será un evento process_creation. Un extremo dado estará repleto de metadatos importantes derivados del evento, como marcas de tiempo, argumentos de línea de comando y el usuario.
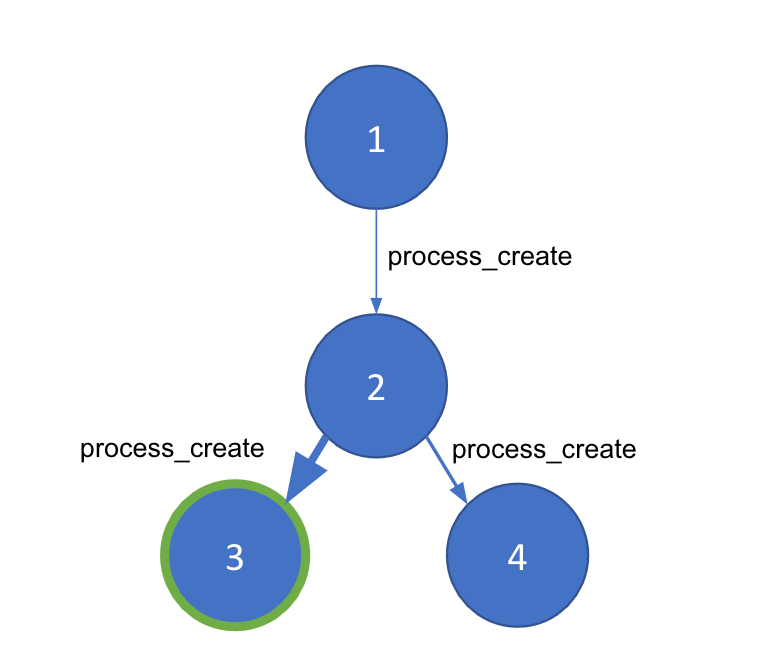
Ahora tenemos una representación de grafo de eventos de procesos de una máquina host. Sin embargo, los ataques living off the land pueden generarse en los mismos procesos a nivel del sistema que se ejecutan siempre. Necesitas una forma de separar las cadenas de procesos buenas y malas dentro de un grafo dado. La detección de comunidades es una técnica que segmenta un grafo grande en “comunidades” más pequeñas según la densidad de los extremos entre nuestros nodos. Para usarla, necesitamos una manera de generar una ponderación entre nodos para asegurar que la detección de comunidades funcione correctamente e identifique las porciones anómalas en nuestro grafo. Para ello, recurriremos a Machine Learning.
Machine Learning
Para generar nuestro modelo de ponderación de extremos, usaremos el aprendizaje supervisado, un enfoque de Machine Learning que requiere datos etiquetados para alimentar el modelo. Afortunadamente, podemos usar los marcos de trabajo rojos y azules open source que mencionamos antes para ayudar a generar algunos datos de práctica. A continuación se presentan algunos de los marcos de trabajo rojos y azules open source usados en nuestro corpus de práctica:
Marcos de trabajo del equipo rojo
- Atomic Red Team (Red Canary)
- Red Team Automation (Endgame/Elastic)
- Caldera Adversary Emulation (MITRE)
- Metta (Uber)
Marcos de trabajo del equipo azul
- Atomic Blue (Endgame/Elastic)
- Cyber Analytics Repository (MITRE)
- MSFT ATP Queries (Microsoft)
Ingesta y normalización de datos

Una vez que hayamos ingestado algunos datos del evento, tendremos que transformarlos en una representación numérica (Fig. 2). Esta representación permitirá al modelo aprender detalles más amplios de una relación principal-secundario en el ámbito de un ataque, lo cual ayuda a evitar solo aprender firmas.
Primero, realizamos la ingeniería de características (Fig. 3) en los nombres de procesos y argumentos de línea de comando. La vectorización TF-IDF capturará la importancia estadística de una palabra dada para un evento en todo nuestro set de datos. La conversión de marcas de tiempo a enteros nos permitirá determinar la diferencia entre el tiempo de inicio del proceso principal y el momento de lanzamiento de un proceso secundario. Otras características son de naturaleza binaria (por ejemplo, 1 o 0, sí o no). Los siguientes son algunos buenos ejemplos de este tipo de característica:
- ¿El proceso está firmado?
- ¿Confiamos en el firmante?
- ¿El proceso es elevado?

Una vez transformado nuestro set de datos, lo usaremos para entrenar un modelo de aprendizaje supervisado (Fig. 4). El modelo proporciona una “puntuación anómala” para un evento de creación de procesos dado entre 0 (benigna) y 1 (anómala). Podemos usar la puntuación anómala como ponderación de extremo en nuestro grafo.
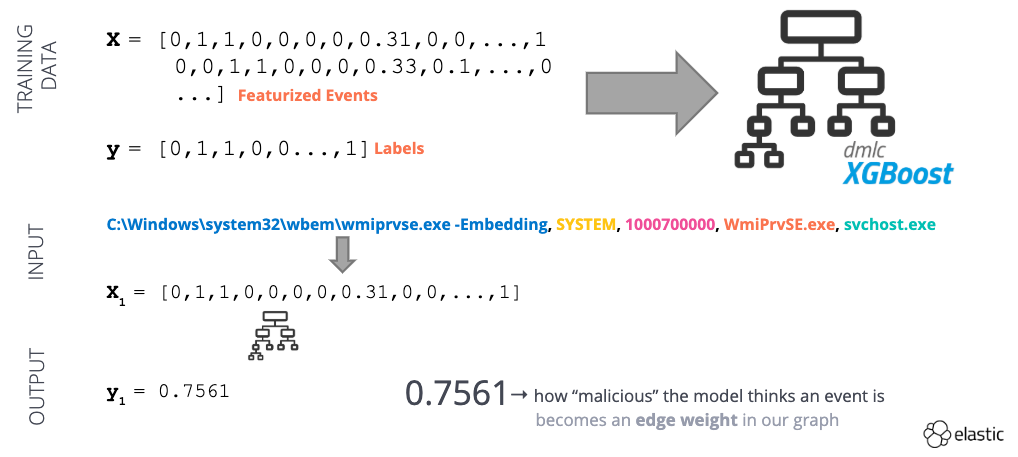
Fig. 4: Ejemplo de un flujo de trabajo de Machine Learning supervisado
Servicio de prevalencia


Fig 5: Probabilidades condicionales usadas por el motor de prevalencia
Ahora tenemos un grafo de ponderación; cortesía de nuestro modelo de Machine Learning. Misión cumplida, ¿no? El modelo que entrenamos hace un trabajo excelente para decidir si una cadena principal-secundario dada es buena o mala conforme a nuestra interpretación general de lo bueno y lo malo. Pero cada entorno de cliente será diferente. Habrá procesos que no hayamos visto antes y administradores de sistemas que usan PowerShell para... bueno, todo.
Básicamente, si usáramos este modelo solo, probablemente veríamos un gran caudal de falsos positivos y aumentaríamos la cantidad de datos que un analista debe examinar. Para compensar este problema potencial, desarrollamos un servicio de prevalencia que nos indica qué tan habitual es una cadena de procesos principales-secundarios dada dentro de ese entorno. Tener en cuenta los matices locales del entorno nos permitirá elevar o suprimir con más confianza eventos sospechosos y quitar cadenas de procesos verdaderamente anómalas.
El servicio de prevalencia (Fig. 5) se basa en dos estadísticas derivadas de la probabilidad condicional que nos permite decir lo siguiente: “De este proceso principal, vi este secundario más que el X % de otros secundarios” Y “de estos procesos, vi esta línea de comando más que el X % de otras líneas de comando asociadas con el proceso”. Una vez que el servicio de prevalencia esté listo, podemos agregar los toques finales a nuestra lógica de detección central, find_bad_communities.
Búsqueda de comunidades “malas”

Fig. 6: Código Python para descubrir comunidades anómalas
Arriba (Fig. 6) vemos el código Python usado para generar las comunidades malas. La lógica de find_bad_communities es muy directa:
- Clasifica cada evento process_create de una máquina host para generar un par de nodos (por ejemplo, nodo principal y nodo secundario) y una ponderación asociada (por ejemplo, la salida de nuestro modelo).
- Construye un grafo dirigido.
- Realiza la detección de comunidades para generar una lista de comunidades en el grafo.
- En cada comunidad, determinamos qué tan prevalente es una relación principal-secundario (por ejemplo, cada conexión). Representamos el carácter común de un evento principal-secundario en la anomalous_score final.
- Si la anomalous_score llega al umbral o lo supera, separamos la comunidad completa para que la revise un analista.
- Una vez analizada cada comunidad, devolvemos una lista de comunidades “malas” ordenadas por la anomalous_score máxima.
Resultados
Entrenamos el modelo final con una combinación de datos benignos y malintencionados simulados y del mundo real. Los datos benignos eran datos de eventos de procesos de Windows recopilados de nuestra red interna durante 3 días. Las fuentes de estos datos fueron una combinación de estaciones de trabajo de usuarios y servidores para replicar una organización pequeña. Generamos datos malintencionados detonando todas las técnicas ATT&CK disponibles a través del marco de trabajo Endgame RTA y lanzando malware basado en macros y binarios desde adversarios avanzados como FIN7 y Emotet.
Para nuestro experimento principal, decidimos usar datos de eventos de la evaluación de MITRE ATT&CK que se proporciona en el proyecto Mordor de Roberto Rodriguez. La evaluación de ATT&CK buscaba emular la actividad de APT3 usando herramientas FOSS/COTS como PSEmpire y CobaltStrike. Estas herramientas permiten que las técnicas living off the land se agreguen a la cadena para realizar tareas de ejecución, persistencia o evasión de defensa.
El marco de trabajo pudo identificar varias cadenas de ataque multitécnica usando exclusivamente eventos de creación de procesos. Descubrimiento (Fig. 7) y movimiento lateral (Fig. 8) que descubrimos y resaltamos para la revisión por parte de analistas.

Fig. 7: Cadena de procesos realizando técnicas de “descubrimiento”

Fig. 8: Cadena de procesos realizando movimiento lateral
Reducción de datos
Un efecto secundario de nuestro enfoque es no solo la capacidad de descubrir cadenas de procesos anómalas, sino la capacidad de demostrar el valor del motor de prevalencia para suprimir falsos positivos. En combinación, pudimos reducir drásticamente la cantidad de datos de eventos que necesitan revisión de un analista. En números:
- Calculamos aproximadamente 10 000 eventos de creación de procesos por endpoint en el escenario de APT3 (5 endpoints en total).
- Identificamos aproximadamente 6 comunidades anómalas por endpoint.
- Cada comunidad tenía aproximadamente entre 6 y 8 eventos.
Con la mirada en el futuro
Nos encontramos en el proceso de llevar esta investigación de la prueba de concepto a una solución integrada como característica de Elastic Security. La característica más prometedora es el motor \prevalence. Los motores de prevalencia que resaltan la frecuencia de las repeticiones de archivos son comunes, pero describir la prevalencia de relaciones entre eventos ayudará a los profesionales de seguridad a detectar amenazas de formas nuevas, tanto mirando lo inusual/habitual en sus empresas como lo eventualmente incrementado según mediciones de lo inusual a nivel global.
Conclusión
Presentamos este marco de trabajo basado en grafos (llamado ProblemChild) en VirusBulletin y CAMLIS el año pasado con el objetivo de disminuir la necesidad de experiencia en dominios en el proceso de escritura de detectores. Con la aplicación de Machine Learning supervisada para derivar un grafo ponderado, demostramos la capacidad de identificar comunidades de eventos aparentemente dispares en secuencias de ataque más grandes. Nuestro marco de trabajo aplica la probabilidad condicional para clasificar de forma automática las comunidades anómalas y para suprimir las cadenas principal-secundario que ocurren de manera habitual. Cuando se aplica para ambos objetivos, los analistas pueden usar este marco de trabajo como ayuda para crear o ajustar detectores y reducir los falsos positivos con el tiempo.