Creación de índices congelados con la API de congelamiento de índices Elasticsearch
Primero, un poco de contexto
Con frecuencia usamos arquitecturas calientes-tibias para sacar el máximo provecho de nuestro hardware. Son particularmente útiles cuando tenemos datos basados en el tiempo, como registros, métricas y datos de APM. La mayoría de estas configuraciones se basan en el hecho de que estos datos son de solo lectura (después de la ingesta) y que los índices pueden estar basados en el tiempo (o el tamaño). Por lo tanto, se pueden eliminar con facilidad según nuestro período de retención deseado. Con este tipo de arquitectura, categorizamos los nodos de Elasticsearch en dos tipos: “caliente” y “tibio”.
Los nodos calientes contienen los datos más recientes y, por lo tanto, manejan toda la carga de indexación. Como los datos recientes suelen ser los que se consultan con mayor frecuencia, estos nodos serán los más potentes de nuestro clúster: almacenamiento rápido, memoria elevada y CPU. Pero esa potencia adicional se vuelve costosa, por lo que no tiene sentido almacenar en un nodo caliente los datos más antiguos que no se consultan con tanta frecuencia.
Por otra parte, los nodos tibios se dedicarán al almacenamiento a largo plazo de una manera más rentable. Los datos de los nodos tibios tienden a consultarse con menor frecuencia, y la información dentro del clúster se trasladará de nodos calientes a tibios según nuestra retención planificada (que se logra mediante el filtrado de asignación de shards), sin dejar de estar disponible en línea para consultas.
Desde Elastic Stack 6.3, estuvimos desarrollando nuevas características para mejorar las arquitecturas calientes-tibias y simplificar el trabajo con datos basados en el tiempo.
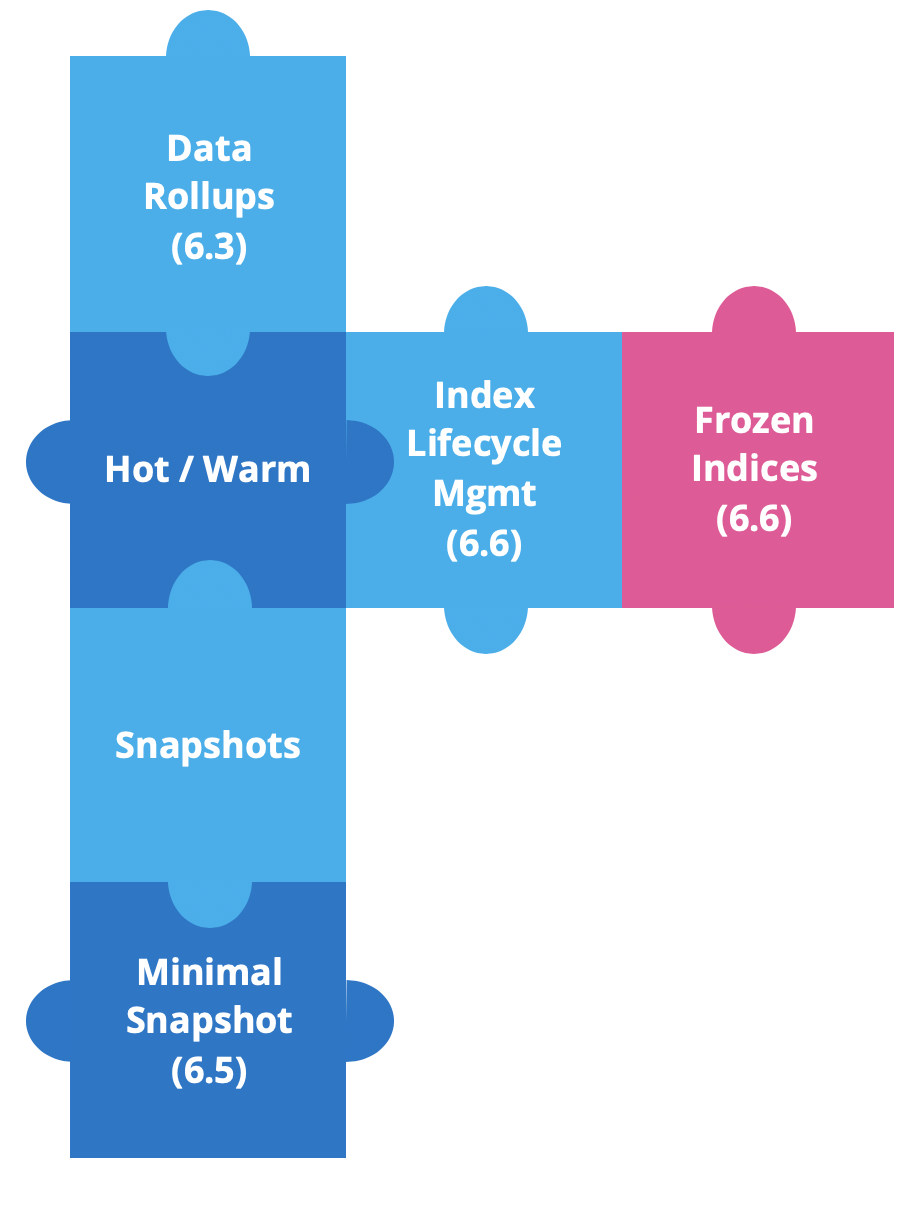
Se introdujeron data rollups por primera vez en la versión 6.3 para ahorrar almacenamiento. En los datos de series temporales, queremos detalles precisos de los datos más recientes. Pero es muy poco probable que necesitemos lo mismo para los datos históricos, en los que normalmente analizaremos sets de datos en su conjunto. Y aquí es donde se introdujeron los rollups, dado que, desde la versión 6.5, podemos crear, gestionar y consolidar datos en Kibana.
Poco después, agregamos snapshots solo de origen. Estas snapshots mínimas permitirán una reducción considerable de almacenamiento de snapshots, con la desventaja de tener que volver a indexar los datos si queremos restaurarlos y consultarlos. Esto está disponible desde la versión 6.5.
En la versión 6.6, presentamos dos características poderosas: la gestión del ciclo de vida de indexación (ILM) y los índices congelados.
La ILM proporciona los medios para automatizar la gestión de índices con el tiempo. Simplifica el traslado de índices de caliente a tibio, permite eliminar los índices demasiado antiguos o automatiza la fusión forzada de los índices a un segmento.
Y en el resto de este blog, hablaremos acerca de los índices congelados.
¿Para qué congelar un índice?
Uno de los mayores desafíos de los datos “antiguos” es que, independientemente de su antigüedad, tienen una huella de memoria considerable. Incluso si los colocamos en nodos fríos, utilizan heap.
Una posible solución podría ser cerrar los índices. Si cerramos un índice, no requerirá memoria, pero tendremos que volver a abrirlo para realizar búsquedas. La reapertura de índices tendrá un costo operativo y también requerirá la memoria que se usaba antes de su cierre.
En cada nodo, hay una relación entre la memoria (heap) y el almacenamiento que limitará la cantidad de almacenamiento disponible por nodo. Puede variar desde tan solo 1:8 (memoria:datos) en situaciones de uso intensivo de memoria hasta aproximadamente 1:100 en casos de uso de memoria menos exigentes.
Aquí es donde entran en juego los índices congelados. ¿Qué sucedería si pudiéramos tener índices abiertos que permitieran realizar búsquedas sin ocupar memoria? Podríamos agregar más almacenamiento a los nodos de datos que contienen índices congelados y romper la proporción de 1:100, con la desventaja de que las búsquedas posiblemente serían más lentas.
Cuando congelamos un índice, se vuelve de solo lectura y sus estructuras de datos transitorios se eliminan de la memoria. A su vez, cuando ejecutemos una consulta en índices congelados, tendremos que cargar las estructuras de datos en la memoria. Las búsquedas en índices congelados no tienen por qué ser lentas. Lucene depende en gran medida de la caché del sistema de archivos, que puede tener capacidad suficiente para conservar porciones considerables de tu índice en la memoria. En esos casos, las búsquedas son comparables en velocidad por shard. Sin embargo, los índices congelados siguen estando limitados de tal manera que solo se ejecuta un shard congelado por nodo al mismo tiempo. Este aspecto puede disminuir la velocidad de las búsquedas en comparación con los índices no congelados.
Cómo funciona el congelamiento
Las búsquedas en los índices congelados se realizan mediante un threadpool dedicadode búsqueda limitada. Se usa un solo subproceso de forma predeterminada para garantizar que los índices congelados se carguen en la memoria de a uno a la vez. Si se están realizando búsquedas simultáneas, estas entrarán en la cola para agregar protecciones adicionales a fin de evitar que los nodos se queden sin memoria.
Por lo tanto, en una arquitectura caliente-tibia, ahora podremos trasladar índices de caliente a tibio y luego congelarlos antes de archivarlos o eliminarlos, lo que nos permitirá reducir nuestros requisitos de hardware.
Antes de los índices congelados, para reducir costos de infraestructura, teníamos que crear una snapshot y archivar nuestros datos, lo que agregaba costos operativos considerables. Teníamos que restaurar los datos si necesitábamos volver a realizar búsquedas. Ahora, podemos mantener nuestros datos históricos disponibles para búsquedas, sin sobrecargar considerablemente la memoria. Y si necesitamos volver a escribir en un índice que ya está congelado, simplemente podemos descongelarlo.

Cómo congelar un índice de Elasticsearch
Los índices congelados son fáciles de implementar en tu clúster. Veamos cómo se puede usar la API de congelamiento de índices y cómo realizar búsquedas en índices congelados.
Comenzaremos por crear datos de muestra en un índice de prueba.
POST /sampledata/_doc
{
"name": "Jane",
"lastname": "Doe"
}
POST /sampledata/_doc
{
"name": "John",
"lastname": "Doe"
}
Luego, comprobaremos que nuestros datos se hayan ingerido. Esto debería devolver dos resultados:
GET /sampledata/_search
Como mejor práctica, antes de congelar un índice, se recomienda ejecutar force_merge. Esto asegurará que cada shard tenga un solo segmento en el disco. También proporcionará una comprensión mucho mejor y simplificará las estructuras de datos que necesitaremos para ejecutar una agregación o una solicitud de búsqueda clasificada en el índice congelado. Ejecutar búsquedas en un índice congelado con múltiples segmentos puede generar una sobrecarga de rendimiento considerable en varios órdenes de magnitud.
POST /sampledata/_forcemerge?max_num_segments=1
El siguiente paso es simplemente invocar el congelamiento de nuestro índice a través del punto final de la API de congelamiento de índices.
POST /sampledata/_freeze
Búsquedas en índices congelados
Ahora que el índice está congelado, verás que las búsquedas convencionales no funcionarán. Esto se debe a que, para limitar el consumo de memoria por nodo, los índices congelados están limitados. Dado que podríamos dirigirnos a un índice congelado por error, evitaremos demoras accidentales agregando específicamente ignore_throttled=false a la solicitud.
GET /sampledata/_search?ignore_throttled=false
{
"query": {
"match": {
"name": "jane"
}
}
}
Ahora, podemos verificar el estado de nuestro índice nuevo ejecutando la siguiente solicitud:
GET _cat/indices/sampledata?v&h=health,status,index,pri,rep,docs.count,store.size
Esto devolverá un resultado similar al siguiente, y el estado del índice será “abierto”:
health status index pri rep docs.count store.size
green open sampledata 5 1 2 17.8kb
Como se mencionó anteriormente, debemos proteger el clúster para evitar que se quede sin memoria, por lo tanto, la cantidad de índices congelados que podemos cargar a la vez para realizar búsquedas en un nodo es limitada. La cantidad de procesos del threadpool de búsquedas limitadas se establece en 1 de forma predeterminada, con una cola de 100 por defecto. Esto quiere decir que, si ejecutamos más de una solicitud, las solicitudes se colocarán en cola hasta cien. Podemos supervisar el estado del threadpool para verificar las colas y los rechazos con la siguiente solicitud:
GET _cat/thread_pool/search_throttled?v&h=node_name,name,active,rejected,queue,completed&s=node_name
Lo que debería devolver una respuesta similar a la siguiente:
node_name name active rejected queue completed
instance-0000000000 search_throttled 0 0 0 25
instance-0000000001 search_throttled 0 0 0 22
instance-0000000002 search_throttled 0 0 0 0
Los índices congelados pueden ser más lentos, pero pueden filtrarse previamente de una manera muy eficiente. También se recomienda establecer el parámetro de solicitud pre_filter_shard_size en 1.
GET /sampledata/_search?ignore_throttled=false&pre_filter_shard_size=1
{
"query": {
"match": {
"name": "jane"
}
}
}
Esto no agregará una sobrecarga considerable a la búsqueda, y nos permitirá aprovechar el escenario habitual. Por ejemplo, al realizar una búsqueda en un intervalo de fechas en índices de series temporales, no todos los shards coincidirán.
Cómo escribir en un índice congelado Elasticsearch
¿Qué sucede al intentar escribir en un índice congelado? Comprobémoslo.
POST /sampledata/_doc
{
"name": "Janie",
"lastname": "Doe"
}
¿Qué ocurrió? Los índices congelados son de solo lectura, por lo tanto, la escritura está bloqueada. Podemos verificarlos en los ajustes de los índices:
GET /sampledata/_settings?flat_settings=true
Lo que devolverá:
{
"sampledata" : {
"settings" : {
"index.blocks.write" : "true",
"index.frozen" : "true",
....
}
}
}
Debemos usar la API de descongelamiento de índices para invocar el punto final de descongelamiento en el índice.
POST /sampledata/_unfreeze
Y, ahora, podremos crear un tercer documento y buscarlo.
POST /sampledata/_doc
{
"name": "Janie",
"lastname": "Doe"
}
GET /sampledata/_search
{
"query": {
"match": {
"name": "janie"
}
}
}
El descongelamiento se debe realizar únicamente en situaciones excepcionales. Recuerda ejecutar siempre “force_merge” antes de volver a congelar el índice para asegurar un rendimiento óptimo.
Uso de índices congelados en Kibana
Para comenzar, necesitaremos cargar algunos datos de muestra, por ejemplo,datos de vuelo de muestra.
Haz clic en el botón “Agregar” en los Datos de vuelo de muestra.
Ahora, deberíamos poder ver los datos cargados haciendo clic en el botón “Ver datos”. El dashboard será similar a este.
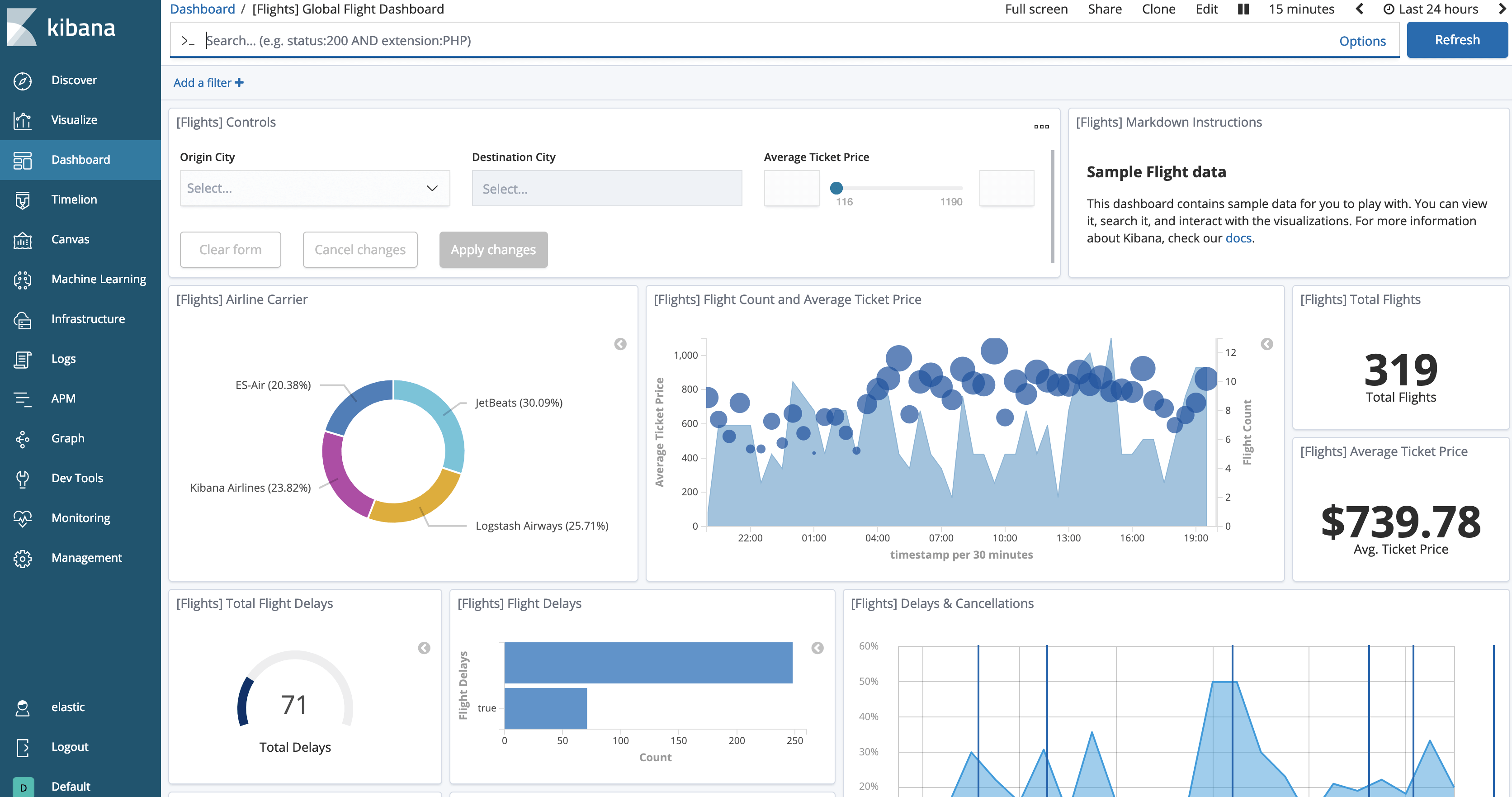
Ahora, podemos probar congelar el índice:
POST /kibana_sample_data_flights/_forcemerge?max_num_segments=1
POST /kibana_sample_data_flights/_freeze
Y si regresamos al dashboard, observaremos que los datos aparentemente “desaparecieron”.
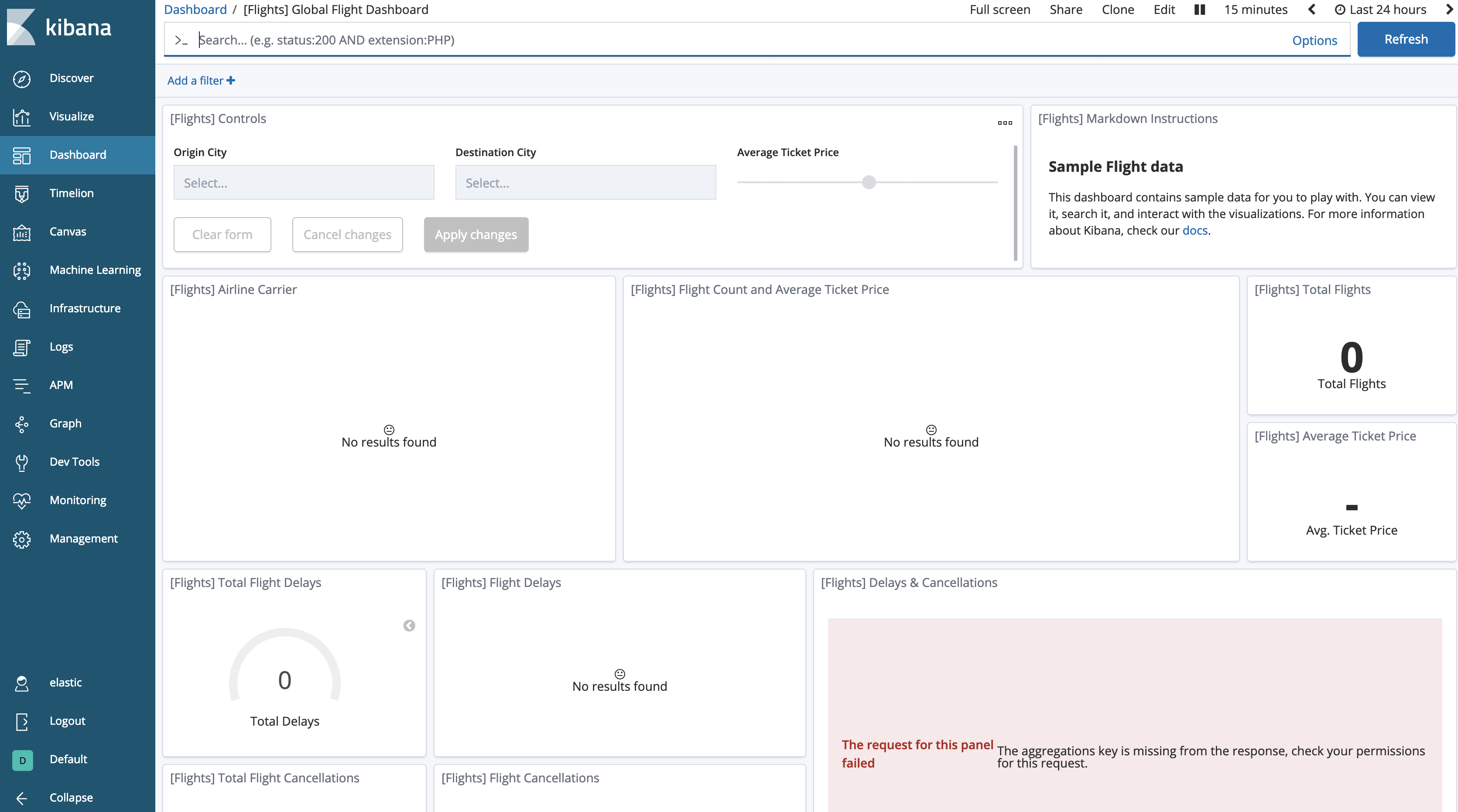
Debemos indicarle a Kibana que permita las búsquedas en índices congelados, que están desactivadas por defecto.
Ve a Administración de Kibana y selecciona Configuración avanzada. En la sección de Búsqueda, verás que la “Búsqueda en índices congelados” está desactivada. Actívala y guarda los cambios.

De esta manera, el dashboard de vuelos volverá a mostrar los datos.
Resumen
Los índices congelados son una herramienta muy potente en las arquitecturas calientes-tibias. Brindan una solución más rentable para una mayor retención a la vez que mantienen las búsquedas en línea. Te recomiendo probar la latencia de búsqueda con tu hardware y tus datos para determinar el tamaño y la latencia de búsqueda adecuados para tus índices congelados.
Consulta la documentación de Elasticsearch para obtener más información acerca de la API de congelamiento de índices. Y como siempre, si tienes preguntas, puedes consultar en nuestros foros de Debate. ¡Feliz congelamiento!