¡Demasiados campos! Tres formas de evitar la explosión de mapeos en Elasticsearch

 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
Se dice que un sistema es "observable" cuando tiene tres componentes: logs, métricas y rastreos. Mientras que las métricas y los rastreos tienen estructuras predecibles, los logs (especialmente los de las aplicaciones) suelen ser datos no estructurados que hay que recopilar y parsear para que sean realmente útiles. Por lo tanto, lograr controlar los logs es posiblemente la parte más difícil de alcanzar la observabilidad.
En este artículo, nos adentraremos en tres estrategias eficaces que los desarrolladores pueden usar para gestionar logs con Elasticsearch. Para obtener una visión general más detallada, mira el siguiente video.
[Artículo relacionado: Aprovechar Elastic para mejorar la gestión de datos y la observabilidad en el cloud]
Cómo poner Elasticsearch al servicio de tus datos
En algunas ocasiones, no podemos controlar los tipos de logs que recibimos en nuestro cluster. Piensa en un proveedor de analíticas de logs que tiene un presupuesto específico para guardar los logs de sus clientes y necesita controlar el almacenamiento (Elastic se ocupa de muchos casos similares en Consultoría).
Algunos clientes indexan campos "por si acaso" deben usarlos para la búsqueda. Si ese es tu caso, las siguientes técnicas deberían poder ayudarte a reducir costos y centrar el rendimiento de tu cluster en lo que realmente importa.
Pero primero describamos el problema. Supongamos que tienes un documento JSON con tres campos: message, transaction.user y transaction.amount:
{
"message": "2023-06-01T01:02:03.000Z|TT|Bob|3.14|hello",
"transaction": {
"user": "bob",
"amount": 3.14
}
}
El mapeo de un índice que contenga documentos como estos podría verse de la siguiente forma:
PUT dynamic-mapping-test
{
"mappings": {
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}
Sin embargo, Elasticsearch nos permite indexar nuevos campos sin tener que especificar necesariamente un mapeo de antemano, y eso es parte de lo que hace que Elasticsearch sea tan fácil de usar: podemos incorporar nuevos datos fácilmente. Por lo tanto, es correcto indexar algo que se desvíe del mapeo original, como lo siguiente:
POST dynamic-mapping-test/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field with arbitrary data"
}
}
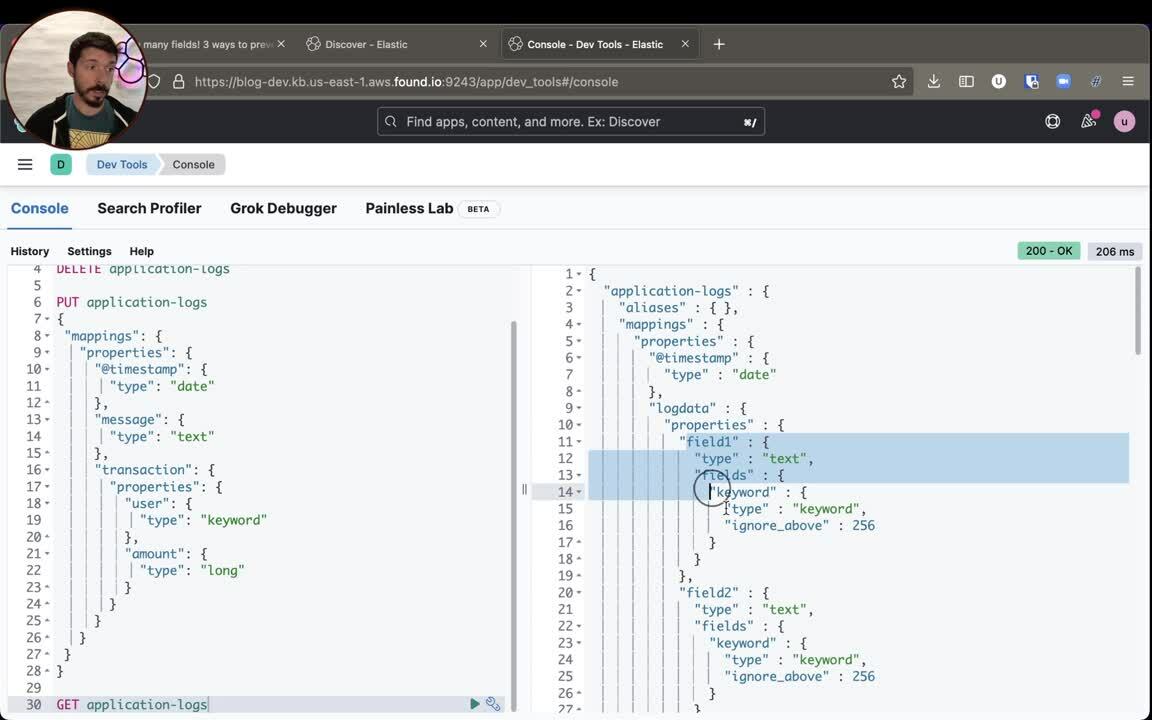
Un GET dynamic-mapping-test/_mapping nos mostrará el nuevo mapeo resultante para el índice. Ahora tiene transaction.field3 tanto como text y keyword, que son, de hecho, dos campos nuevos.
{
"dynamic-mapping-test" : {
"mappings" : {
"properties" : {
"transaction" : {
"properties" : {
"user" : {
"type" : "keyword"
},
"amount" : {
"type" : "long"
},
"field3" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"message" : {
"type" : "text"
}
}
}
}
}
Lamentablemente, eso es ahora parte del problema: cuando no tenemos ningún control sobre lo que se envía a Elasticsearch, podemos enfrentarnos fácilmente al problema llamado explosión de mapeos. Nada te impide crear subcampos y subsubcampos, que tendrán los mismos dos tipos de text y keyword, como lo siguiente:
POST dynamic-mapping-test/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field",
"field4": {
"sub_user": "a sub field",
"sub_amount": "another sub field",
"sub_field3": "yet another subfield",
"sub_field4": "yet another subfield",
"sub_field5": "yet another subfield",
"sub_field6": "yet another subfield",
"sub_field7": "yet another subfield",
"sub_field8": "yet another subfield",
"sub_field9": "yet another subfield"
}
}
}Estaríamos desperdiciando memoria RAM y espacio en disco para almacenar esos campos, ya que se crearán estructuras de datos para hacerlos buscables y agregables. Puede ser que esos campos no se utilicen nunca. Están ahí "por si acaso" hay que utilizarlos para la búsqueda.
Uno de los primeros pasos que damos en la consultoría cuando se nos pide que optimicemos un índice es inspeccionar el uso de cada campo de un índice para ver cuáles son realmente buscados y cuáles son un desperdicio de recursos.
Estrategia n.° 1: Usar strict
Si queremos tener un control total de la estructura de los logs que almacenamos en Elasticsearch y cómo lo hacemos, podemos establecer una definición clara de mapeo para que simplemente no se almacene cualquier cosa que se desvíe de lo que queremos.
Al usar dynamic: strict en el nivel superior o en algún subcampo, rechazamos los documentos que no coinciden con lo que hay en nuestras definiciones de mapeos, lo que obliga al emisor a cumplir con el mapeo predefinido:
PUT dynamic-mapping-test
{
"mappings": {
"dynamic": "strict",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}Entonces, cuando intentamos indexar nuestro documento con un campo adicional…
POST dynamic-mapping-test/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field"
}
}
}Obtenemos esta respuesta:
{
"error" : {
"root_cause" : [
{
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [field3] within [transaction] is not allowed"
}
],
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [field3] within [transaction] is not allowed"
},
"status" : 400
}Si sabes con certeza que solo quieres almacenar lo que está en los mapeos, esta estrategia obliga al emisor a cumplir con el mapeo predefinido.
Estrategia n.° 2: Usar pocos valores strict
Podemos ser un poco más flexibles y dejar pasar los documentos, aunque no sean exactamente como esperamos, utilizando "dynamic": "false".
PUT dynamic-mapping-disabled
{
"mappings": {
"dynamic": "false",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}Al usar esta estrategia, aceptamos todos los documentos que nos llegan, pero solo indexamos los campos que se especifican en el mapeo, lo que hace que los campos adicionales simplemente no se puedan buscar. En otras palabras, no estamos desperdiciando RAM en los nuevos campos, solo espacio en el disco. Los campos siguen siendo visibles en el campo hits de una búsqueda, y eso incluye la agregación top_hits. Sin embargo, no podemos buscarlos ni agruparlos, ya que no se crearon estructuras de datos para mantener su contenido.
No es necesario que sea todo o nada: incluso puedes hacer que la raíz sea strict y que un subcampo acepte campos nuevos sin indexarlos. En nuestra documentación Cómo establecer dynamic en objetos internos (Setting dynamic on inner objects), se describe eso en profundidad.
PUT dynamic-mapping-disabled
{
"mappings": {
"dynamic": "strict",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"dynamic": "false",
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}Estrategia n.° 3: Usar campos de tiempo de ejecución
Elasticsearch admite tanto el esquema en lectura como en escritura, cada uno con sus salvedades. Con dynamic:runtime, se agregarán los nuevos campos al mapeo como campos de tiempo de ejecución. Indexamos los campos que se especifican en el mapeo y hacemos que los campos adicionales se puedan buscar/agrupar solo en el momento de la búsqueda. En otras palabras, no consumimos memoria RAM por adelantado en los nuevos campos, pero obtenemos una respuesta más lenta a la búsqueda, ya que las estructuras de datos se compilarán durante el tiempo de ejecución.
PUT dynamic-mapping-runtime
{
"mappings": {
"dynamic": "runtime",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}Indexemos este enorme documento:
POST dynamic-mapping-runtime/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field",
"field4": {
"sub_user": "a sub field",
"sub_amount": "another sub field",
"sub_field3": "yet another subfield",
"sub_field4": "yet another subfield",
"sub_field5": "yet another subfield",
"sub_field6": "yet another subfield",
"sub_field7": "yet another subfield",
"sub_field8": "yet another subfield",
"sub_field9": "yet another subfield"
}
}
}Un GET dynamic-mapping-runtime/_mapping mostrará que nuestro mapeo cambia cuando se indexa nuestro documento:
{
"dynamic-mapping-runtime" : {
"mappings" : {
"dynamic" : "runtime",
"runtime" : {
"transaction.field3" : {
"type" : "keyword"
},
"transaction.field4.sub_amount" : {
"type" : "keyword"
},
"transaction.field4.sub_field3" : {
"type" : "keyword"
},
"transaction.field4.sub_field4" : {
"type" : "keyword"
},
"transaction.field4.sub_field5" : {
"type" : "keyword"
},
"transaction.field4.sub_field6" : {
"type" : "keyword"
},
"transaction.field4.sub_field7" : {
"type" : "keyword"
},
"transaction.field4.sub_field8" : {
"type" : "keyword"
},
"transaction.field4.sub_field9" : {
"type" : "keyword"
}
},
"properties" : {
"transaction" : {
"properties" : {
"user" : {
"type" : "keyword"
},
"amount" : {
"type" : "long"
}
}
},
"message" : {
"type" : "text"
}
}
}
}
}Ahora los nuevos campos se pueden buscar como un campo normal de palabras clave. Ten en cuenta que el tipo de datos se adivina al indexar el primer documento, pero esto también se puede controlar usando plantillas dinámicas.
GET dynamic-mapping-runtime/_search
{
"query": {
"wildcard": {
"transaction.field4.sub_field6": "yet*"
}
}
}Resultado:
{
…
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"hits" : [
{
"_source" : {
"message" : "hello",
"transaction" : {
"user" : "hey",
"amount" : 3.14,
"field3" : "hey there, new field",
"field4" : {
"sub_user" : "a sub field",
"sub_amount" : "another sub field",
"sub_field3" : "yet another subfield",
"sub_field4" : "yet another subfield",
"sub_field5" : "yet another subfield",
"sub_field6" : "yet another subfield",
"sub_field7" : "yet another subfield",
"sub_field8" : "yet another subfield",
"sub_field9" : "yet another subfield"
}
}
}
}
]
}
}¡Excelente! Es fácil ver cómo esta estrategia podría ser útil cuando no se sabe qué tipo de documentos se van a ingestar, por lo que el uso de los campos de tiempo de ejecución parece un enfoque conservador con un buen equilibrio entre el rendimiento y la complejidad del mapeo.
Información importante sobre el uso de Kibana y los campos de tiempo de ejecución
Hay que tener en cuenta que si no especificamos un campo cuando buscamos en Kibana usando su barra de búsqueda (por ejemplo, simplemente escribiendo "hello" en lugar de "message: hello", esa búsqueda coincidirá con todos los campos, y eso incluye todos los campos de tiempo de ejecución que hemos declarado. Como probablemente no quieras este comportamiento, nuestro índice debe usar la configuración dinámica index.query.default_field. Configúrala para que sean todos o algunos de nuestros campos mapeados, y dejar que los campos de tiempo de ejecución sean consultados explícitamente (p. ej., "transaction.field3: hey").
Nuestro mapeo actualizado sería finalmente:
PUT dynamic-mapping-runtime
{
"mappings": {
"dynamic": "runtime",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
},
"settings": {
"index": {
"query": {
"default_field": [
"message",
"transaction.user"
]
}
}
}
}Cómo elegir la mejor estrategia
Cada estrategia tiene sus propias ventajas y desventajas, por lo que la mejor estrategia dependerá, en última instancia, de tu caso de uso específico. A continuación, encontrarás un resumen que te ayudará a tomar la decisión correcta para tus necesidades:
|
Estrategia |
Ventajas |
Desventajas |
|
n.° 1: strict |
Se garantiza que los documentos almacenados se ajustan al mapeo. |
Los documentos se rechazan si tienen campos que no están declarados en el mapeo. |
|
n.° 2: dynamic: false |
Los documentos almacenados pueden tener cualquier número de campos, pero solo los campos asignados utilizarán recursos. |
Los campos que no están asignados no pueden usarse para búsquedas o agregaciones. |
|
n.° 3: campos de tiempo de ejecución |
Obtienes todas las ventajas de n.° 2. Los campos de tiempo de ejecución se pueden usar en Kibana como cualquier otro campo. |
Los tiempos de respuesta de búsqueda son relativamente más lentos al buscar los campos de tiempo de ejecución. |
Observability es donde el Elastic Stack realmente brilla. Independientemente de si se trata de almacenar de forma segura años de transacciones financieras mientras se rastrean sistemas afectados o se ingestan varios terabytes de métricas de red diarias, nuestros clientes implementan la observabilidad diez veces más rápido a una fracción del costo.
¿Buscas dar los primeros pasos con Elastic Observability? La mejor manera de hacerlo es en el cloud. Inicia tu prueba gratuita de Elastic Cloud hoy mismo.
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime