



Elastic Enterprise Search: Geschäftssysteme und Software durchsuchen
Überblick
Einführung in Elastic Enterprise Search
Lernen Sie Elastic Enterprise Search besser kennen und erfahren Sie überblicksmäßig, wie Sie Ihre Daten mit Elastic Cloud ingestieren und ansehen können.
Onboarding der Daten
„Quick Start“-Video zu Enterprise Search
In dieser aus 3 Videos bestehenden „Quick Start“-Serie erfahren Sie mehr über die modernen, auf natürlicher Sprache basierenden Sucherlebnisse mit vorjustierter Relevanz für Ihre Apps und Websites, die Elastic Enterprise Search bietet. Sehen Sie sich an, wie Sie schnell alles einsatzbereit machen und anschließend mit dem Ingestieren von Daten loslegen können, lassen Sie sich die Suchoberfläche zeigen und erfahren Sie, wie Sie Suchmaschinen analysieren und auf Ihre Anforderungen anpassen können. Die Videos geben einen Überblick über Elastic Enterprise Search, erklären das Indexieren von Daten in Elastic Enterprise Search und stellen das Analysieren und Feinjustieren der Suche vor.
Elastic Cloud-Konto erstellen
Probieren Sie Elastic Cloud 14 Tage kostenlos aus. Öffnen Sie cloud.elastic.co, erstellen Sie ein Konto und folgen Sie den Schritten unten, um herauszufinden, wie Sie Ihren ersten Elastic Stack in einer unserer mehr als 50 unterstützten Regionen weltweit starten können.
Wenn Sie auf Edit setting klicken, können Sie einen Cloud-Anbieter – Google Cloud, Microsoft Azure oder AWS – auswählen. Anschließend werden Sie um die Auswahl der zugehörigen Region gebeten. Als Nächstes können Sie festlegen, welches Hardware-Profil verwendet werden soll, und so das Deployment besser an Ihre Anforderungen anpassen. Zudem wurde bereits die neueste Version von Elastic vorausgewählt.
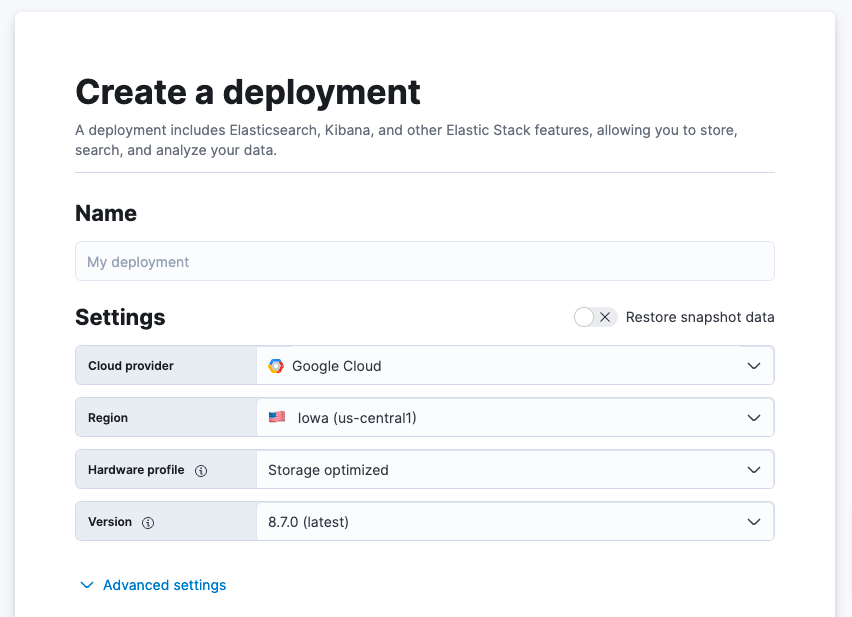
Für diesen konkreten Anwendungsfall benötigen Sie eine 4‑GB-RAM-Instanz. Diese können Sie einrichten, indem Sie vor der Erstellung Ihres Deployments die Option Advanced settings wählen, zum unteren Rand der Enterprise Search-Instanz scrollen und mithilfe des Drop-down-Menüs Size per zone 4 GB RAM als Größe festlegen. Wenn Sie damit fertig sind, können Sie Create deployment wählen.
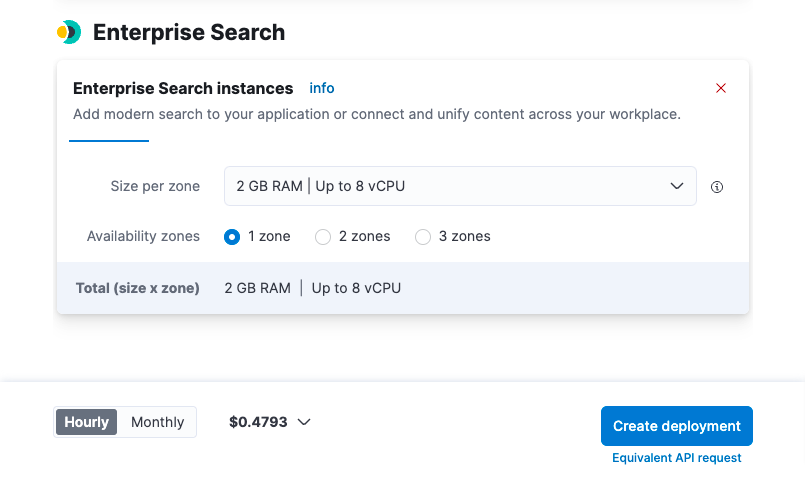
Beim Erstellen Ihres Deployments erhalten Sie einen Nutzernamen und ein Passwort. Denken Sie daran, die Informationen herunterzuladen oder zu kopieren, da Sie sie für die Installation Ihrer Integrationen benötigen.
Wenn Ihr Deployment fertig eingerichtet ist, wählen Sie Search across databases and business systems.
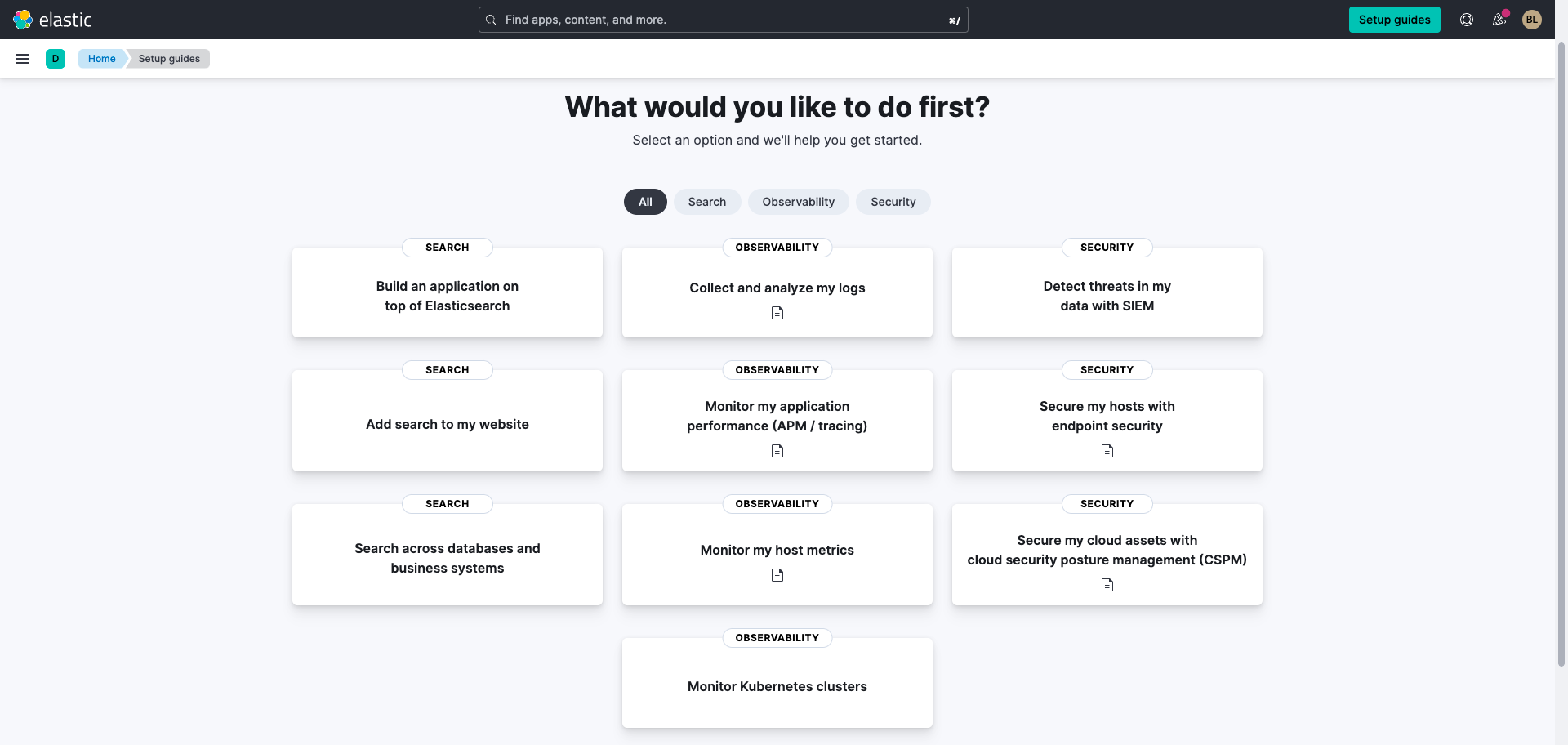
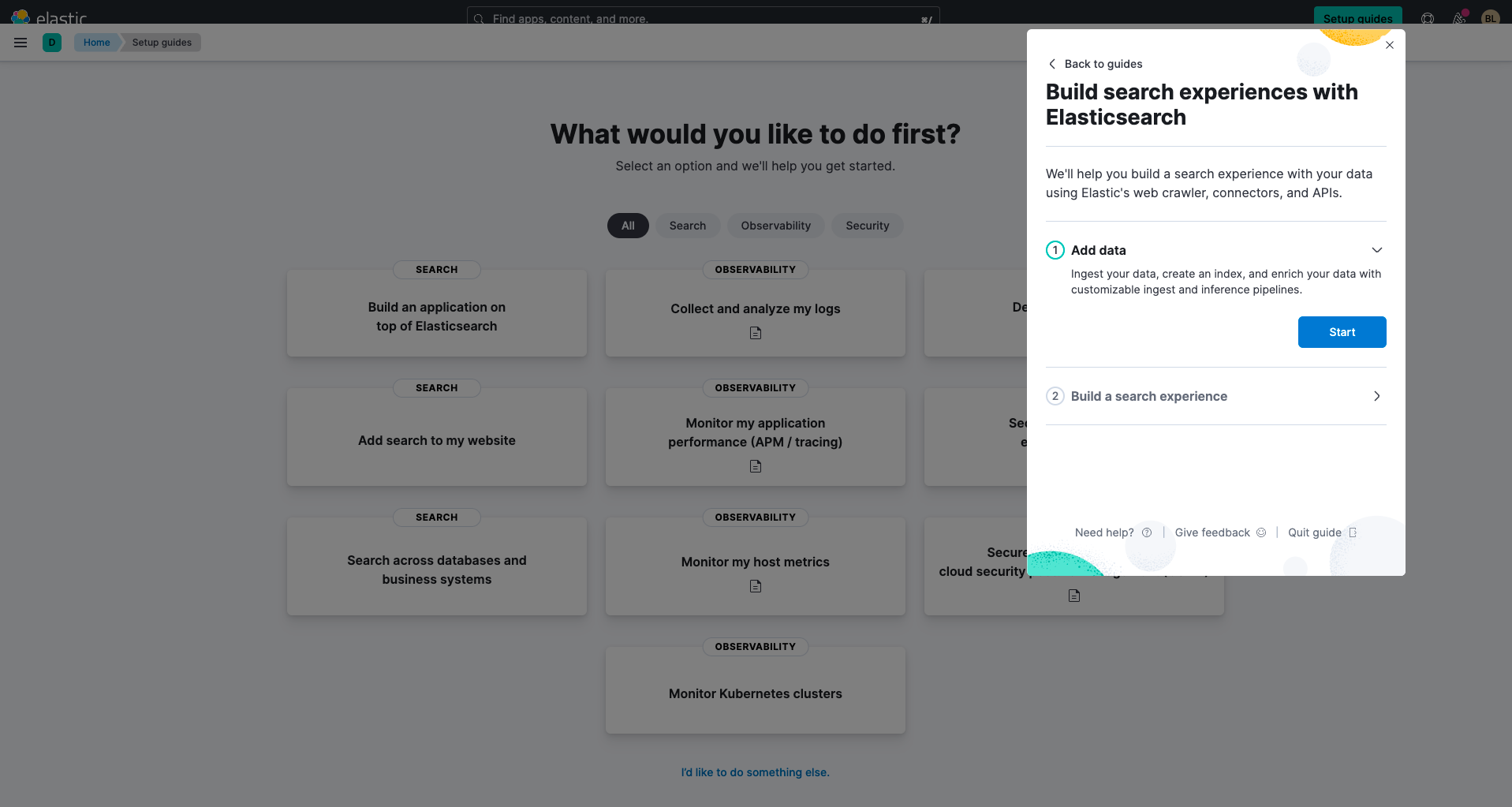
Verbinden mit Ihren Datenbanken mit Elasticsearch
Wenn Sie Elastic zum ersten Mal nutzen, müssen Sie Ihre Ingestionsmethode auswählen. Für das Durchsuchen Ihrer Datenbank wird als Ingestionsmethode Use a connector empfohlen.
Wählen Sie als Nächstes MongoDB und geben Sie in die Konfigurationsfelder des MongoDB-Connectors die oben zusammengesammelten Informationen ein. Wenn es keinen Grund dafür gibt, Lesevorgänge auf einem konkret benannten Host zu erzwingen, sollten Sie für „Direct connection“ „false“ festlegen (Näheres können Sie dem MongoDB-Artikel „Connection Options“ entnehmen).
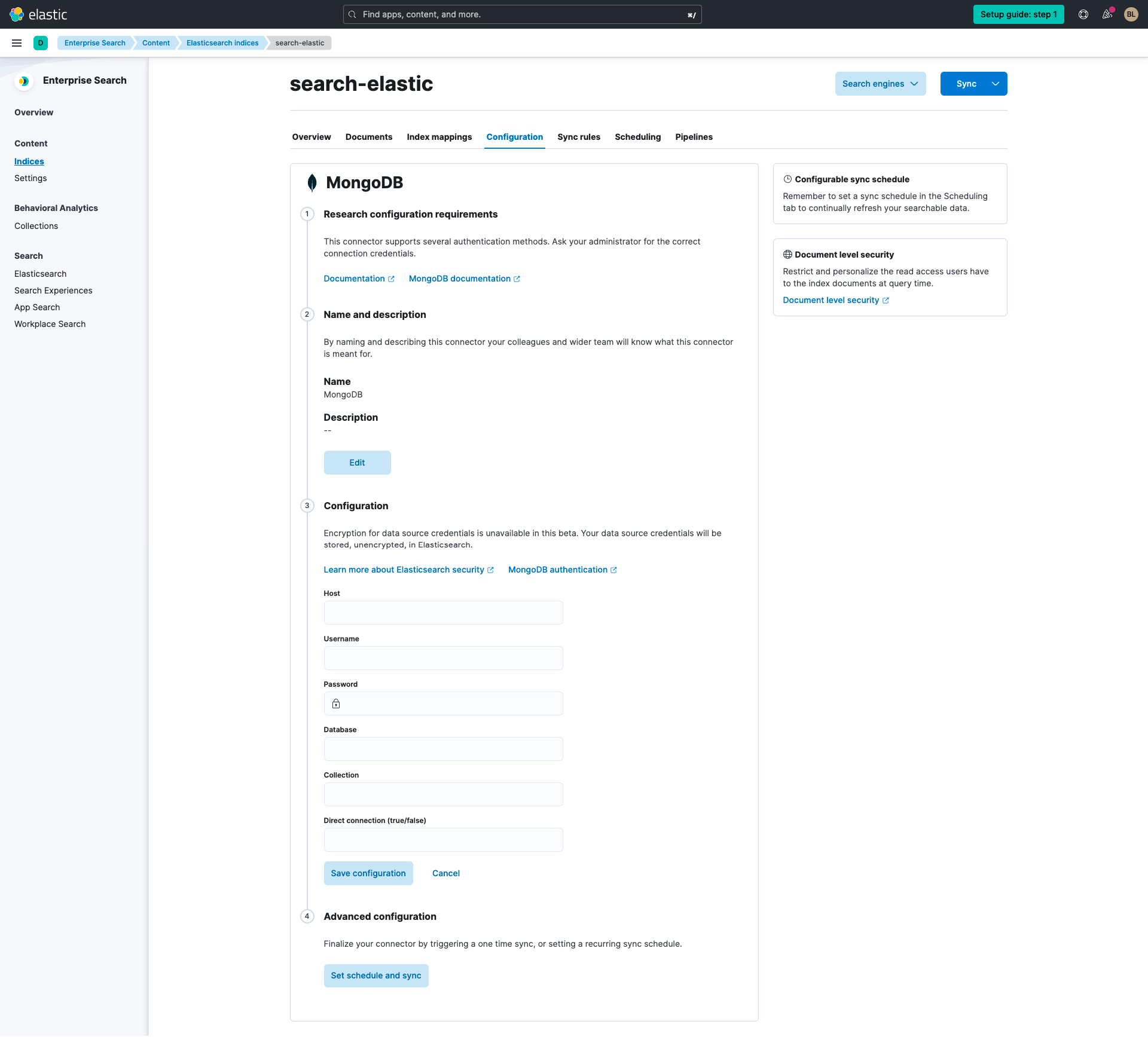
Nachdem Sie Ihre Informationen eingegeben haben, sollten Sie auf dem Tab Scheduling den für Ihren Anwendungsfall am besten passenden Zeitplan für die Datenbanksynchronisierung festlegen. Klicken Sie nach dem Konfigurieren des Synchronisierungszeitplans auf Sync, um den Vorgang abzuschließen.
Arbeiten mit Elastic Enterprise Search
Erstellen eines Sucherlebnisses mit Elastic
Für ein hochwertiges Sucherlebnis müssen Sie eine Benutzeroberfläche für die Suche entwickeln, sich Analytics-Daten ansehen, die Relevanz der Suche justieren und Tools zum Ingestieren von Daten beschaffen. Im folgenden Webinar erfahren Sie, wie Sie in die Erstellung einer Suchanwendung einsteigen können:
Personalisieren der Suche mit Elastic
Wenn Sie bereits eine fertige Suchanwendung haben und jetzt einen Schritt weiter gehen möchten, haben wir auch ein Webinar zur Personalisierung des Sucherlebnisses für Sie.
Außerdem möchten wir Sie auf diesen Blogpost hinweisen, in dem Sie erfahren, wie Sie mithilfe von Analytics Ihr Sucherlebnis vervollkommnen können.
Wie geht es weiter?
Vielen Dank dass Sie sich die Zeit genommen haben, Ihre Datenbanken mithilfe von Elastic Cloud mit Elasticsearch zu verbinden.
Für Ihre Elastic-Journey sollten Sie die wichtigsten operativen, Security- und Datenkomponenten kennen, die Sie als Nutzer:in verwalten müssen, wenn Sie einen Cluster in Ihrer Umgebung bereitstellen.