Zustandslos – Ihre neue Art, mit Elasticsearch zu suchen
Vereinfachen Sie Ihr Deployment mit der neuen Elasticsearch-Architektur



Auf Twitter teilen


Auf LinkedIn teilen


Auf Facebook teilen


Per E-Mail teilen


Drucken
Unsere Anfänge
Die erste Version von Elasticsearch wurde 2010 als verteilte skalierbare Suchmaschine veröffentlicht, mit der die Nutzer kritische Einblicke schnell finden und zutage fördern konnten. Zwölf Jahre und mehr als 65.000 Commits später liefert Elasticsearch weiterhin kampferprobte Lösungen für eine riesige Menge an Suchanforderungen. Dank der Anstrengungen von mehr als 1.500 Mitwirkenden, darunter auch Hunderte von Elastic-Vollzeitmitarbeitern, konnte sich Elasticsearch fortlaufend an neue Herausforderungen zum Thema Suche anpassen.
Als in der Anfangszeit von Elasticsearch das Thema Datenverluste angesprochen wurde, unternahm das Elastic-Team eine mehrjährige Anstrengung, um das Cluster-Koordinationssystem umzuschreiben und zu garantieren, dass bestätigte Daten sicher gespeichert werden. Als klar wurde, dass die Verwaltung von Indizes in großen Clustern problematisch ist, erarbeitete das Team eine umfangreiche ILM-Lösung, um diese Arbeit zu automatisieren und es den Nutzern zu erlauben, Indexmuster und Lebenszyklusaktionen vorab zu definieren. Als die Nutzer große Mengen an Metrik- und Zeitreihendaten speichern mussten, wurden verschiedene Features wie etwa eine bessere Komprimierung hinzugefügt, um die Größe der Daten zu reduzieren. Als die Speicherkosten beim Durchsuchen großer Mengen an kalten Daten immer weiter stiegen, haben wir in die Erstellung von durchsuchbaren Snapshots investiert, um Nutzerdaten direkt in kostengünstigen Objektspeichern durchsuchen zu können.
All diese Investitionen bilden das Fundament für die nächste Entwicklungsstufe von Elasticsearch. Angesichts der zunehmenden Bedeutung von cloudnativen Diensten und neuen Orchestrierungssystemen ist es an der Zeit, das Elasticsearch-Erlebnis für die Arbeit mit cloudnativen Systemen zu optimieren. Wir sind davon überzeugt, dass diese Änderungen neue Chancen für operationale, Leistungs- und Kostenoptimierungen bei der Ausführung von Elasticsearch in Elastic Cloud bieten.
Ausblick in die Zukunft – Die Zukunft ist zustandslos
Eine der größten Herausforderungen beim Betreiben oder Orchestrieren von Elasticsearch ist die Abhängigkeit von zahlreichen persistenten Zuständen, da es sich um ein zustandsbehaftetes System handelt. Die drei wichtigsten Komponenten sind translog, Indexspeicher und Cluster-Metadaten. Dieser Zustand bedeutet, dass der Speicher persistent sein muss und beim Neustart oder Austausch von Knoten nicht verloren gehen darf.
Die aktuelle Elasticsearch-Architektur in Elastic Cloud muss die Indexierung über mehrere Verfügbarkeitszonen hinweg duplizieren, um Redundanz zum Schutz vor Ausfällen zu garantieren. Wir haben vor, die Persistenz dieser Daten von lokalen Datenträgern in einen Objektspeicher zu verschieben, wie etwa AWS S3. Wenn wir diese Daten in externen Diensten speichern, müssen wir die Indexierung nicht mehr replizieren und brauchen deutlich weniger Hardware beim Ingestieren. Diese Architektur garantiert außerdem eine sehr hohe Dauerhaftigkeit aufgrund der Art und Weise, wie Cloud-Objektspeicher wie AWS S3, GCP Cloud Storage und Azure Blob Storage die Daten über Verfügbarkeitszonen hinweg replizieren.
Durch die Auslagerung des Indexspeichers in einen externen Dienst können wir auch die Architektur von Elasticsearch überarbeiten und die Zuständigkeiten für Indexierung und Suche voneinander trennen. Anstatt beide Workloads mit primären und Replikat-Instanzen zu verarbeiten, haben wir vor, eine Indexierungsebene und eine Suchebene einzuführen. Durch die Trennung dieser Workloads können sie separat voneinander skaliert werden, und die Hardware kann genauer für den jeweiligen Anwendungsfall optimiert werden. Außerdem lösen wir damit die seit Langem bestehende Herausforderung, dass die Lasten für Suche und Indexierung einander beeinträchtigen können.
Nach einer mehrmonatigen Proof-of-Concept- und Experimentierphase sind wir davon überzeugt, dass diese Objektspeicherdienste unsere Anforderungen für Indexspeicher und Cluster-Metadaten erfüllen. Unsere Tests und Benchmarks haben ergeben, dass diese Speicherdienste die hohen Indexierungsanforderungen für die größten Cluster erfüllen, die wir in Elastic Cloud gesehen haben. Mit der Speicherung der Daten im Objektspeicher können wir außerdem die Indexierungskosten reduzieren und die Suchleistung sehr einfach optimieren. Zum Durchsuchen der Daten verwendet Elasticsearch das kampferprobte System der durchsuchbaren Snapshots, das Daten dauerhaft im cloudnativen Objektspeicher persistiert und lokale Datenträger als Cache für häufig verwendete Daten nutzt.
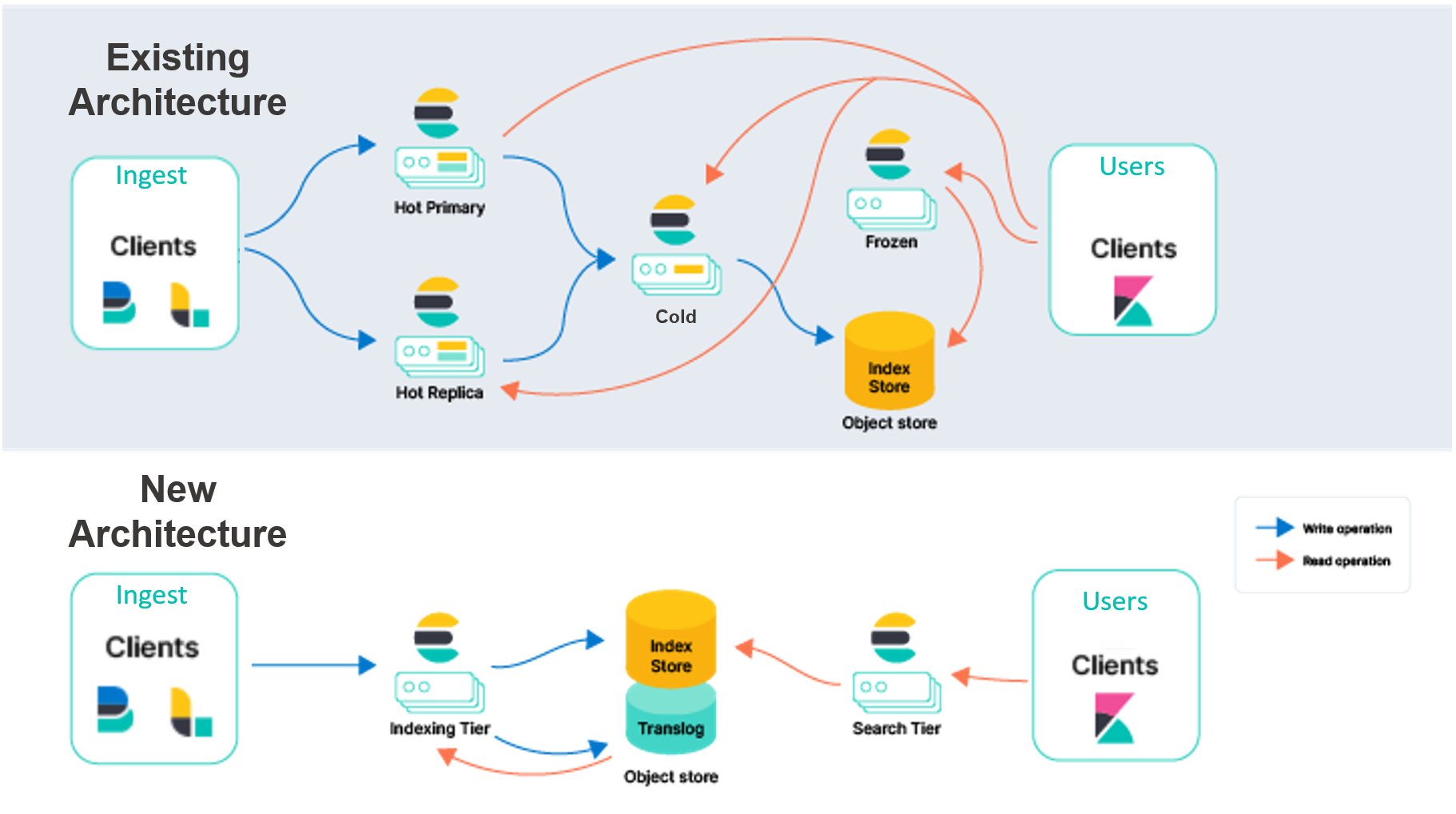
Um die Differenzierung zu vereinfachen, bezeichnen wir unser vorhandenes Modell als „Knoten-zu-Knoten“-Replikation. In der heißen Ebene für dieses Modell teilen sich primäre und Replikat-Shards die Schwerstarbeit beim Verarbeiten von Ingestions- und Suchanfragen. Diese Knoten sind zustandsbehaftet, da sie lokale Datenträger verwenden, um die Daten für die auf ihnen gehosteten Shards sicher zu persistieren. Außerdem kommunizieren primäre und Replikat-Shards ständig miteinander, um die Synchronisierung zu erhalten. Zu diesem Zweck werden die auf der primären Shard ausgeführten Operationen auf der Replikat-Shard repliziert. Die Kosten für diese Operationen (hauptsächlich CPU) fallen also pro verwendetem Replikat an. Dieselben Shards und Knoten, die für die Ingestion zuständig sind, verarbeiten auch Suchanfragen. Daher müssen beim Bereitstellen und Skalieren beide Workloads berücksichtigt werden.
Neben Suche und Ingestion sind die Shards beim Knoten-zu-Knoten-Replikationsmodell auch noch für weitere aufwändige Aufgaben zuständig, wie etwa das Zusammenführen von Lucene-Segmenten. Dieses Design hat zwar gewisse Vorteile, aber wir haben bei unserer Zusammenarbeit mit Kunden im Lauf der Jahre und der allgemeinen Entwicklung des Cloud-Ökosystems viel Verbesserungspotenzial gesehen.
Die neue Architektur ermöglicht zahlreiche sofortige und zukünftige Verbesserungen, wie etwa:
- Sie können den Durchsatz beim Ingestieren auf derselben Hardware deutlich steigern, oder anders gesagt die Effizienz für dieselbe Ingestions-Workload deutlich verbessern. Dies liegt daran, dass die Indexierungsoperationen nicht mehr für jedes Replikat dupliziert werden. Die CPU-intensiven Indexierungsoperationen werden nur einmal auf der Indexierungsebene ausgeführt, und die resultierenden Segmente werden von dort aus an einen Objektspeicher übertragen. Von dort aus können die Daten ohne weitere Veränderung von der Suchebene verarbeitet werden.
- Sie können Compute- und Speicherebenen voneinander trennen, um Ihre Cluster-Topologie zu vereinfachen. Elasticsearch verwendet heutzutage je nach Daten und Hardwareprofil mehrere Datenebenen (Inhalt, heiß, warm, kalt und eingefroren). Die heiße Ebene enthält Daten, die in Quasi-Echtzeit durchsucht werden müssen, und die eingefrorene Ebene enthält weniger häufig benötigte Daten. Diese Ebenen sind zwar hilfreich, bringen jedoch auch zusätzliche Komplexität mit sich. In der neuen Architektur sind keine Datenebenen mehr erforderlich, was die Konfiguration und den Betrieb von Elasticsearch vereinfacht. Außerdem trennen wir Indexierung und Suche voneinander, was die Komplexität weiter reduziert und es uns ermöglicht, beide Workloads unabhängig voneinander zu skalieren.
- Sie können die Speicherkosten in der Indexierungsebene optimieren, indem Sie die Menge der Daten reduzieren, die auf einem lokalen Datenträger gespeichert werden müssen. Momentan speichert Elasticsearch für die Indexierung eine komplette Kopie der Shard auf heißen Knoten (primär und Replikat). Beim zustandslosen Ansatz mit Indexierung direkt im Objektspeicher ist nur ein Teil dieser lokalen Daten erforderlich. Für Anwendungsfälle, bei denen nur Daten angefügt werden, müssen nur bestimmte Metadaten für die Indexierung gespeichert werden. Dadurch wird deutlich weniger lokaler Speicher für die Indexierung benötigt.
- Sie können die Speicherkosten für die Verarbeitung von Suchabfragen reduzieren. Durch die Verwendung des Modells für durchsuchbare Snapshots als nativen Modus zum Durchsuchen von Daten können Sie die Speicherkosten für die Verarbeitung von Suchabfragen deutlich reduzieren. Je nach Nutzeranforderungen im Hinblick auf die Suchlatenz können Sie Elasticsearch so anpassen, dass das lokale Caching für häufig angeforderte Daten verbessert wird.
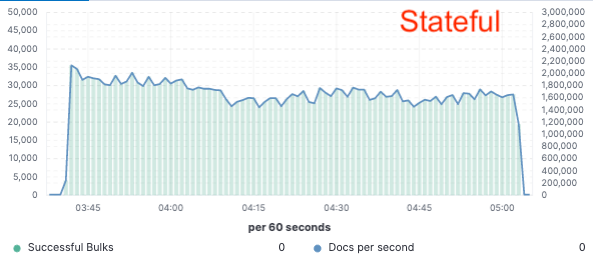
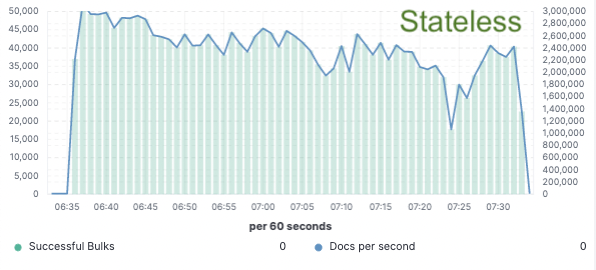
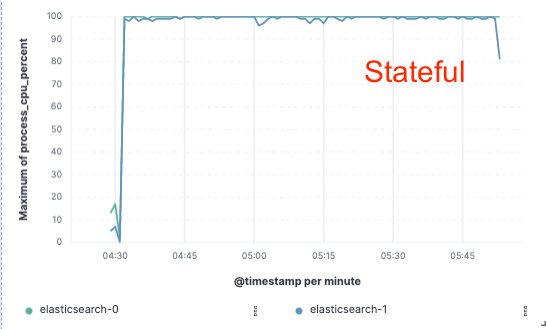
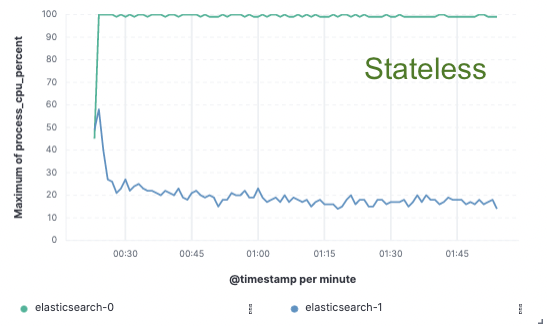
Benchmarks – 75 % mehr Durchsatz beim Indexieren
Um diesen Ansatz zu beurteilen, haben wir eine umfangreiche Machbarkeitsstudie implementiert, bei der Daten nur auf einem einzigen Knoten indiziert und die Replikation mit Cloud-Objektspeichern umgesetzt wurde. Dabei haben wir 75 % mehr Durchsatz beim Indexieren erreicht, da wir keine dedizierte Hardware mehr zum Replizieren der Indexierung einsetzen mussten. Außerdem waren die CPU-Kosten für einfache Datenabfragen aus dem Objektspeicher deutlich niedriger als beim Indexieren und lokalen Schreiben der Daten, wie es momentan für die heiße Ebene üblich ist. Dies bedeutet, dass die Suchknoten ihre CPU vollständig für die Suche bereitstellen können.
Wir haben diese Leistungstests in einem Cluster mit zwei Knoten auf den drei größten öffentlichen Cloud-Anbietern (AWS, GCP und Azure) durchgeführt. Wir werden auch weiterhin noch größere Benchmarks durchführen, um eine produktionstaugliche zustandslose Implementierung zu erreichen.
Indexierungsdurchsatz
CPU-Verbrauch
Zustandslos für uns, günstiger für Sie
Mit der zustandslosen Architektur in Elastic Cloud können Sie den Mehraufwand für die Indexierung reduzieren, Ingestion und Suche unabhängig voneinander skalieren, die Verwaltung Ihrer Datenebenen vereinfachen und den Betrieb beschleunigen, etwa beim Skalieren oder Aktualisieren. Dies ist der erste Meilenstein auf dem Weg zu einer umfassenden Modernisierung der Elastic Cloud-Plattform.
Werden auch Sie Teil unserer zustandslosen Vision.
Sie möchten diese Lösung vor allen anderen testen? Sie erreichen uns in den Diskussionsforen oder in unserem Community-Slack-Channel. Mit Ihrem Feedback können Sie mithelfen, die zukünftige Ausrichtung unserer neuen Architektur zu prägen.
Teilen
Auf Twitter teilen
Auf LinkedIn teilen
Auf Facebook teilen
Per E-Mail teilen
Drucken

