Logstash oder Elasticsearch-Ingest-Knoten – was ist besser für mich?
Logstash war einer der Originalbestandteile des Elastic Stack und ist seit Langem das Mittel der Wahl, wenn es um das Parsen, Anreichern oder Verarbeiten von Daten geht. Im Laufe der Jahre kamen immer mehr Input-, Output- und Filter-Plugins hinzu, sodass mit Logstash heute ein extrem flexibles und leistungsfähiges Tool für eine Vielzahl unterschiedlicher Architekturen zur Verfügung steht.
Ingest-Knoten wurden in Elasticsearch 5.0 als Möglichkeit eingeführt, Dokumente in Elasticsearch zu verarbeiten, bevor sie indexiert werden. Sie ermöglichen einfache Architekturen mit einer geringen Zahl von Komponenten, bei denen Anwendungen die zu verarbeitenden und zu indexierenden Daten direkt an Elasticsearch senden. Das vereinfacht häufig den Einstieg in die Nutzung des Elastic Stack, ohne den Weg für eine Skalierung bei wachsendem Datenvolumen zu verstellen.
Der Ingest-Knoten hat jedoch einige Funktionen, die es auch in Logstash gibt, weshalb wir immer wieder von Benutzern gefragt werden, welche dieser beiden Möglichkeiten denn nun die richtige für sie ist. In diesem Blogpost besprechen wir die Architekturaspekte, die bei der Wahl zwischen den beiden herangezogen werden sollten, um eine fundierte Entscheidung zu ermöglichen.
Dies ist die dritte Folge in unserer Reihe zu häufigen Fragen unserer Benutzer. Die anderen beiden waren:
- How many shards should I have in my Elasticsearch cluster?
- Why am I seeing bulk rejections in my Elasticsearch cluster?
Wie kommen die Daten rein und raus?
Einer der Hauptunterschiede zwischen Logstash und dem Ingest-Knoten besteht darin, wie die Daten hinein- und herauskommen.
Da der Ingest-Knoten im Rahmen des Indexierungs-Flows in Elasticsearch ausgeführt wird, müssen die Daten über Bulk- oder Indexierungsanforderungen zum Knoten gesendet werden. Es bedarf also eines Prozesses, der aktiv Daten schreibt und sie an Elasticsearch sendet. Ein Ingest-Knoten kann sich nicht selbst Daten von einer externen Quelle, wie einer Nachrichtenwarteschlange oder einer Datenbank, holen.
Ähnliches gilt für die Zeit nach der Verarbeitung der Daten – die einzige Möglichkeit ist die lokale Indexierung von Daten nach Elasticsearch.
Für Logstash gibt es dagegen ein großes Angebot an Input- und Output-Plugins und es kann zur Unterstützung einer Vielzahl unterschiedlicher Architekturen verwendet werden. Logstash kann als Server agieren und Daten akzeptieren, die Clients ihm über TCP, UDP und HTTP senden, aber auch aktiv Daten von Datenbanken, Nachrichtenwarteschlangen und so weiter abrufen. Auch für die Ausgabe stehen verschiedenste Optionen zur Verfügung, ob Nachrichtenwarteschlangen, wie Kafka und RabbitMQ, oder die Langfristarchivierung auf S3 oder HDFS.
Wie sieht es mit Warteschlangen und Gegendruck aus?
Beim Senden von Daten an Elasticsearch, gleich ob direkt oder über eine Ingest-Pipeline, muss jeder Client darauf vorbereitet sein, dass Elasticsearch nicht in der Lage ist, mit der Verarbeitung der Daten nachzukommen oder weitere Daten zu akzeptieren. Wir nennen das „Gegendruck anwenden“. Wenn die Datenknoten keine Daten akzeptieren können, nimmt auch der Ingest-Knoten keine Daten mehr an.
In Architekturen, bei denen in der Pipeline kein Warteschlangenmechanismus eingebaut ist – weder an der Quelle noch irgendwo dahinter –, kann es zu Datenverlust kommen, wenn Elasticsearch für einen längeren Zeitraum nicht erreichbar oder nicht in der Lage ist, Daten anzunehmen. Dazu gehören auch Beats, die keine Daten speichern oder aus der Datei lesen können, sowie andere Prozesse mit der Fähigkeit, Daten direkt nach Elasticsearch zu schreiben, zum Beispiel syslog-ng.
Logstash kann dank der Funktion Persistent Queues Daten in eine Warteschlange auf Platte einreihen und damit eine mindestens einmalige Zustellung garantieren sowie Daten bei Verarbeitungsspitzen lokal puffern. Darüber hinaus unterstützt Logstash die Integration mit den unterschiedlichsten Arten von Nachrichtenwarteschlangen, was die Unterstützung einer großen Palette von Deployment-Mustern ermöglicht.
Wie kann ich meine Daten anreichern und verarbeiten?
Der Ingest-Knoten verfügt über mehr als 20 unterschiedliche Processors, die die Funktionalität der am häufigsten verwendeten Logstash-Plugins abdecken. Eine Einschränkung besteht jedoch darin, dass die Ingest-Knoten-Pipeline nur im Kontext jeweils eines Ereignisses arbeiten kann. Die Processors sind darüber hinaus generell nicht in der Lage, Kontakt mit anderen Systemen herzustellen oder Daten von Platte zu lesen, was die zur Verfügung stehenden Anreicherungsoptionen etwas begrenzt.
Logstash kann aus einem wesentlich größeren Angebot von Plugins wählen, wozu unter anderem auch Plugins zum Hinzufügen oder Transformieren von Content auf der Basis von Lookups in Konfigurationsdateien, Elasticsearch oder relationalen Datenbanken zählen.
Beats und Logstash unterstützen zudem das konfigurierbare Herausfiltern und Ignorieren von Ereignissen, was der Ingest-Knoten derzeit nicht kann.
Welche Option lässt sich einfacher konfigurieren?
Das ist sehr subjektiv und hängt von Ihrem Hintergrund und Ihren Gewohnheiten ab. Für jede Ingest-Knoten-Pipeline gibt es ein eigenes JSON-Dokument, das in Elasticsearch gespeichert ist. Trotz der Möglichkeit, große Zahlen separater Pipelines zu definieren, kann jedes Dokument beim Durchlaufen des Ingest-Knotens immer nur von einer Pipeline verarbeitet werden. Der Umgang mit diesem Format kann, zumindest für relativ einfache und „ordentlich“ definierte Pipelines, etwas einfacher sein als das Konfigurationsdateiformat von Logstash. Aber bei komplexeren Pipelines, die mehrere Datenformate zu verarbeiten haben, ist es oft einfacher, Logstash zu nutzen, weil Logstash die Verwendung von Bedingungsparametern zur Flusssteuerung unterstützt. Hinzu kommt, dass bei Logstash auch mehrere logisch separate Pipelines unterstützt werden, die über eine Benutzeroberfläche auf Kibana-Basis verwaltet werden können.
Es sollte auch beachtet werden, dass Logstash generell Vorteile beim Messen und Optimieren der Pipeline-Performance bietet, da es Monitoring unterstützt und über eine exzellente Pipeline-Viewer-UI verfügt, mit der sich Engpässe und potenzielle Probleme schnell und einfach aufspüren lassen.
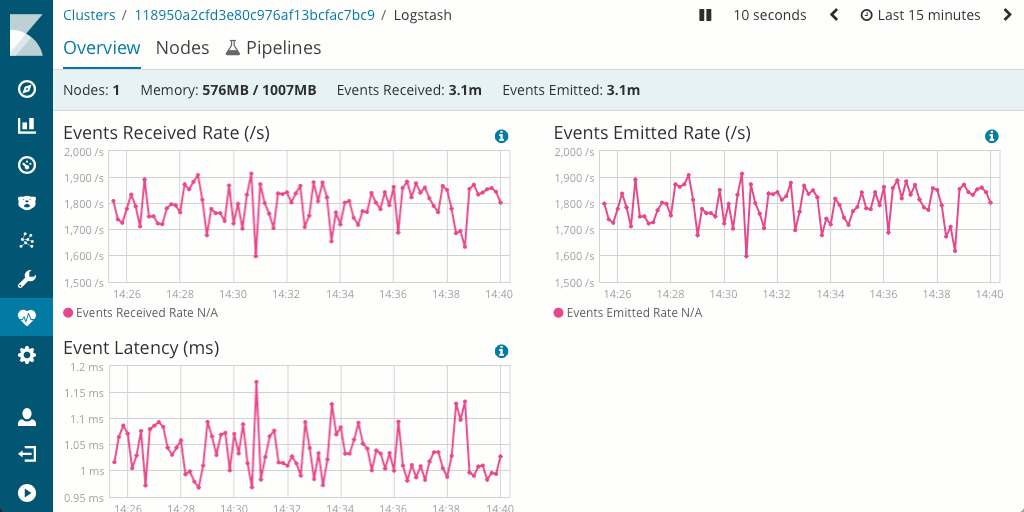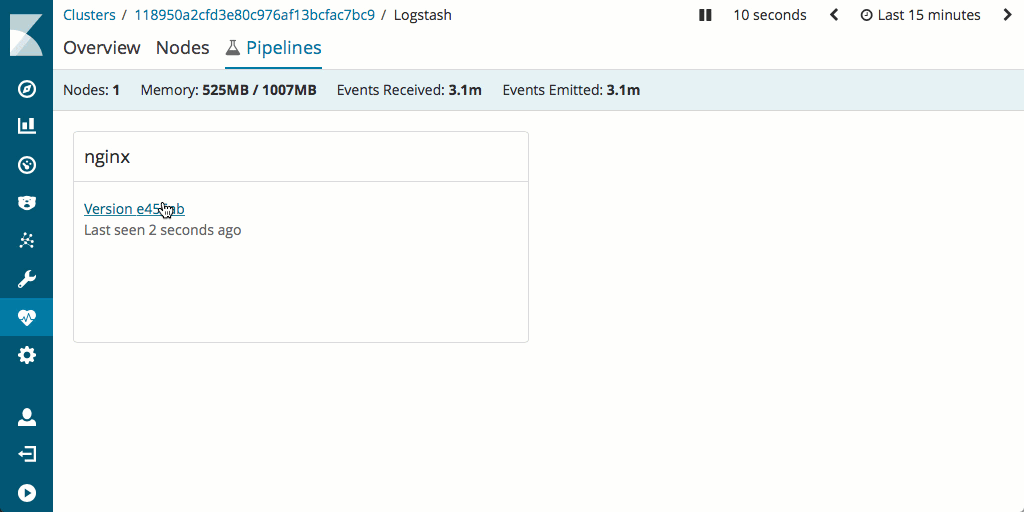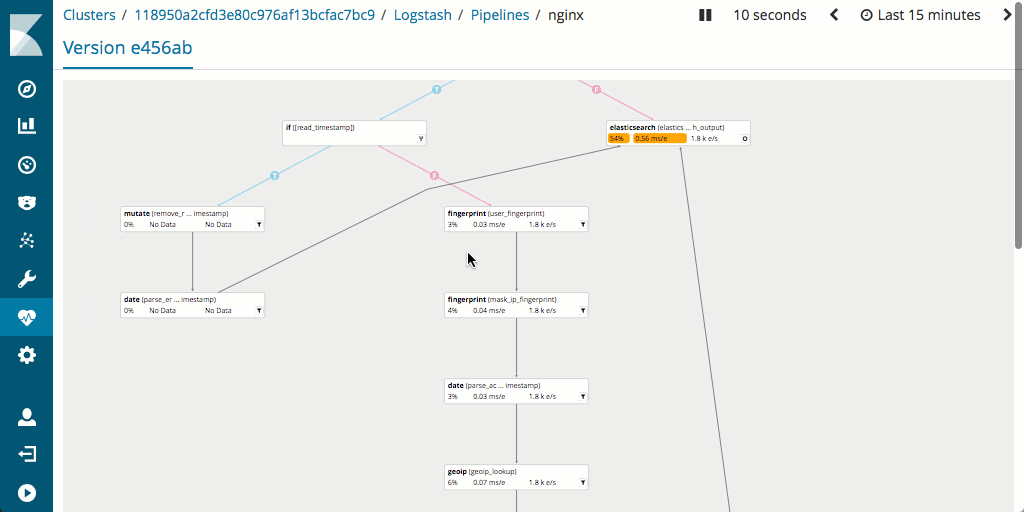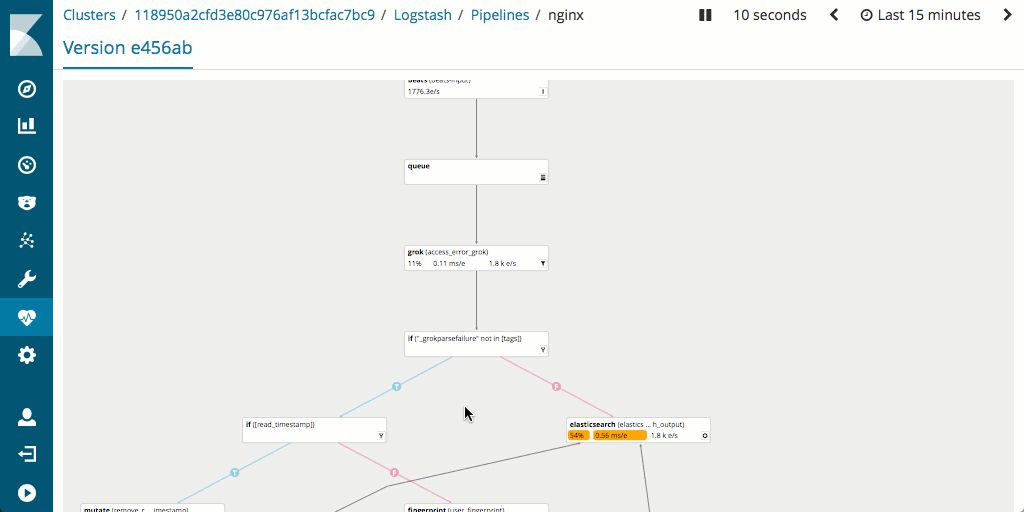
Wie sieht es mit dem Hardware-Footprint aus?
Eine der Stärken des Ingest-Knotens besteht darin, dass er sehr einfache Architekturen ermöglicht, bei denen Beats direkt in eine Ingest-Knoten-Pipeline schreiben können. Jeder Knoten in einem Elasticsearch-Cluster kann als Ingest-Knoten agieren, der, zumindest bei kleineren Anwendungsfällen, den Hardware-Footprint begrenzen und die Komplexität der Architektur reduzieren kann.
Wenn dann das Datenvolumen steigt oder die Verarbeitung komplexer wird, wodurch sich die CPU-Last im Cluster erhöht, wird im Allgemeinen der Umstieg auf dedizierte Ingest-Knoten empfohlen. Das ist der Zeitpunkt, zu dem auch zusätzliche Hardware – entweder für dedizierte Ingest-Knoten oder Logstash – benötigt wird, sodass die Unterschiede beim Hardware-Footprint sehr stark vom jeweiligen Anwendungsfall abhängen.
Kann der Ingest-Knoten irgendetwas, was Logstash nicht kann?
Bisher könnte man den Eindruck erhalten, dass der Ingest-Knoten einfach nur eine Teilmenge der von Logstash gebotenen Funktionalität bietet. Das stimmt aber so nicht ganz.
Der Ingest-Knoten unterstützt das Ingest-Attachment-Processor-Plugin, mit dessen Hilfe sich Anhänge in populären Formaten, wie PPT, XLS und PDF, verarbeiten und indexieren lassen. Für Logstash ist solch ein Plugin derzeit nicht erhältlich. Wenn Sie also planen, verschiedene Arten von Anhängen zu indexieren, kommen Sie möglicherweise nicht um den Ingest-Knoten umhin.
Da die Ausführung der Ingest-Pipeline direkt vor der Indexierung der Daten erfolgt, handelt es sich dabei auch um die zuverlässigste Methode zum Hinzufügen eines Zeitstempels, mit dem der Indexierungszeitpunkt des Ereignisses angegeben wird. So können zum Beispiel Verzögerungen bei der Verarbeitung exakt gemessen und analysiert werden. Würde der Zeitstempel angebracht werden, bevor die Daten erfolgreich bei Elasticsearch angekommen sind, könnte dies zu Messfehlern führen, da der Zeitstempelwert nicht unbedingt mit dem Zeitpunkt der Indexierung in Elasticsearch übereinstimmt, beispielsweise weil es gerade Gegendruck gibt oder der Client gezwungen ist, die Datenindexierung mehrmals zu wiederholen. Mit diesem Zeitstempel lässt sich die Ingest-Verzögerung pro Dokument ermitteln.
Kann ich Logstash und den Ingest-Knoten zusammen verwenden?
Obwohl viele sich entweder für die eine oder für die andere Option entscheiden, ist es natürlich auch möglich, beide zusammen zu verwenden, da Logstash das Senden von Daten an eine Ingest-Pipeline unterstützt. Bei komplexeren Architekturen kann es auch mehrere logische Flows geben, die sehr unterschiedliche Anforderungen haben können. Einige können Logstash durchlaufen, während andere direkt an Elasticsearch-Ingest-Knoten gesendet werden. Im Sinne einer einfacheren Wartung der Architektur sollte die Option gewählt werden, die für den jeweiligen Datenstrom allgemein am sinnvollsten ist.
Fazit
Die Funktionalitäten von Logstash und des Elasticsearch-Ingest-Knotens überlappen sich, sodass einige Architekturen mit jeder der beiden Technologien implementiert werden können. Beide Optionen haben jedoch ihre Stärken und Schwächen, weshalb es wichtig ist, die Anforderungen und die Architektur der gesamten Verarbeitungspipeline zu analysieren und auf der Basis der in diesem Blogpost besprochenen Kriterien die geeignetste auszuwählen. Nicht immer muss dabei eine Entweder-oder-Entscheidung getroffen werden: Sie können auch zusammen oder parallel zueinander für unterschiedliche Teile der Verarbeitungspipeline zum Einsatz kommen.