Überwachen von Kafka mit Elasticsearch, Kibana und Beats
Unseren ersten Post zur Überwachung von Kafka mit Filebeat gab es 2016. Seit der Version 6.5 unterstützt das Beats-Team ein Kafka-Modul. Dieses Modul automatisiert einen Großteil der Arbeit, die mit dem Überwachen von Kafka-Clustern verbunden ist.
In diesem Blogpost soll es um das Erfassen von Logdaten und Metriken mit den Kafka-Modulen in Filebeat und Metricbeat gehen. Wir werden diese Daten in einen auf dem Elasticsearch Service gehosteten Cluster ingestieren und uns die von den Beats-Modulen bereitgestellten Kibana-Dashboards ansehen.
Dieser Blogpost basiert auf der Version 7.1 des Elastic Stack. Eine Beispielumgebung gibt es bei GitHub.
Warum Module?
Wer schon einmal mit komplexen Logstash-Grok-Filtern gearbeitet hat, wird schnell schätzen lernen, wie einfach die Einrichtung der Logdatenerfassung mit einem Filebeat-Modul ist. Die Nutzung von Modulen in einer Monitoring-Konfiguration hat aber auch noch weitere Vorteile:
- einfachere Konfiguration der Erfassung von Logdaten und Metriken
- Elastic Common Schema ermöglicht die Standardisierung von Dokumenten
- zweckmäßige Indexvorlagen zur Bereitstellung optimaler Felddatentypen
- angemessene Größenanpassung für Indizes; Beats nutzen zur Gewährleistung vernünftiger Shard-Größen für Beats-Indizes die Rollover-API
Eine vollständige Liste der unterstützten Module finden Sie in der Filebeat-Dokumentation und in der Metricbeat-Dokumentation.
Einführung in die Umgebung
Unser Beispiel-Setup besteht aus einem Kafka-Cluster mit den drei Knoten „kafka0“, „kafka1“ und „kafka2“. Auf jedem Knoten werden Kafka 2.1.1 sowie zur Knotenüberwachung Filebeat und Metricbeat ausgeführt. Die Beats werden per Cloud-ID so konfiguriert, dass sie Daten an unseren Elasticsearch Service-Cluster senden. Die Kafka-Module in Filebeat und Metricbeat erstellen Dashboards in Kibana für die Visualisierung der Daten. Ein kleiner Hinweis: Wenn Sie sich ansehen möchten, wie dies in Ihrem eigenen Cluster funktioniert, können Sie den Elasticsearch Service mit all seinen Funktionen 14 Tage lang kostenlos ausprobieren.
Einrichten der Beats
Als Nächstes konfigurieren Sie die Beats und starten sie dann.
Installieren und Aktivieren der Beats-Dienste
Zur Installation von Filebeat und Metricbeat folgen wir der Anleitung in „Erste Schritte“. Da wir mit Ubuntu arbeiten, installieren wir die Beats über das APT-Repository.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list sudo apt-get update sudo apt-get install filebeat metricbeat systemctl enable filebeat.service systemctl enable metricbeat.service
Konfigurieren der Cloud-ID unseres Elasticsearch Service-Deployments
Kopieren Sie die Cloud-ID aus der Elastic Cloud-Konsole und nutzen Sie sie zum Konfigurieren des Outputs für Filebeat und Metricbeat.
CLOUD_ID=Kafka_Monitoring:ZXVyb3BlLXdlc...
CLOUD_AUTH=elastic:password
filebeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/filebeat/filebeat.yml
metricbeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/metricbeat/metricbeat.yml
Aktivieren des Kafka- und des Systemmoduls in Filebeat und Metricbeat
Als Nächstes müssen wir das Kafka-Modul und das Systemmodul für beide Beats aktivieren.
filebeat modules enable kafka system metricbeat modules enable kafka system
Anschließend können wir die Beats-Einrichtung starten. Dabei werden die von den Modulen verwendeten Indexvorlagen und Kibana-Dashboards konfiguriert.
filebeat setup -e --modules kafka,system metricbeat setup -e --modules kafka,system
Die Beats sind startbereit
Nachdem alles konfiguriert wurde, können wir jetzt Filebeat und Metricbeat starten.
systemctl start metricbeat.service systemctl start filebeat.service
Erkunden der Monitoring-Daten
Im Standard-Logging-Dashboard wird Folgendes angezeigt:
- zuletzt vom Kafka-Cluster gefundene Ausnahmen, gruppiert nach Ausnahmeklasse und unter Angabe aller Details zur Ausnahme
- ein Überblick über den Logdurchsatz nach Ebene unter Angabe aller Details zum Log
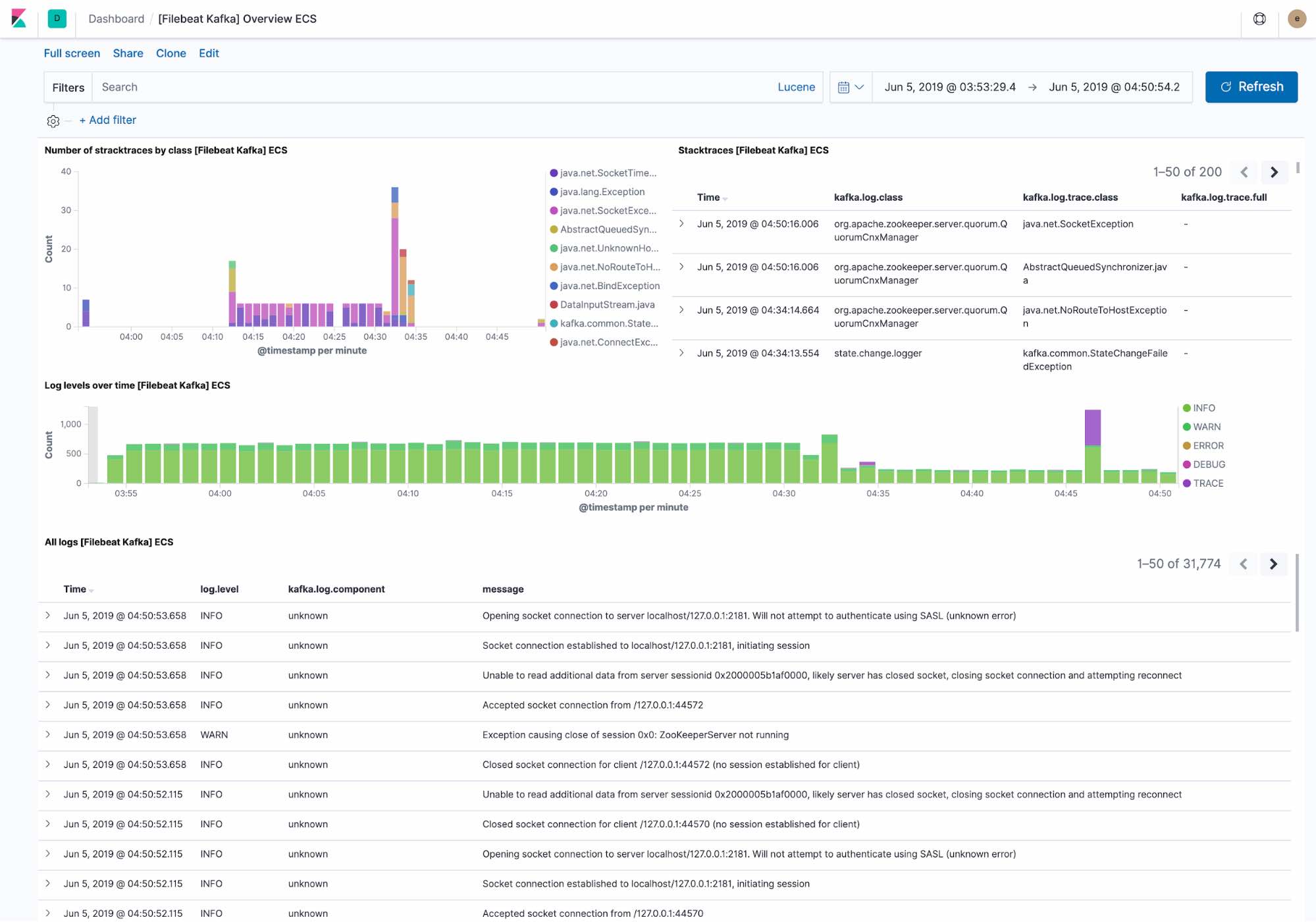
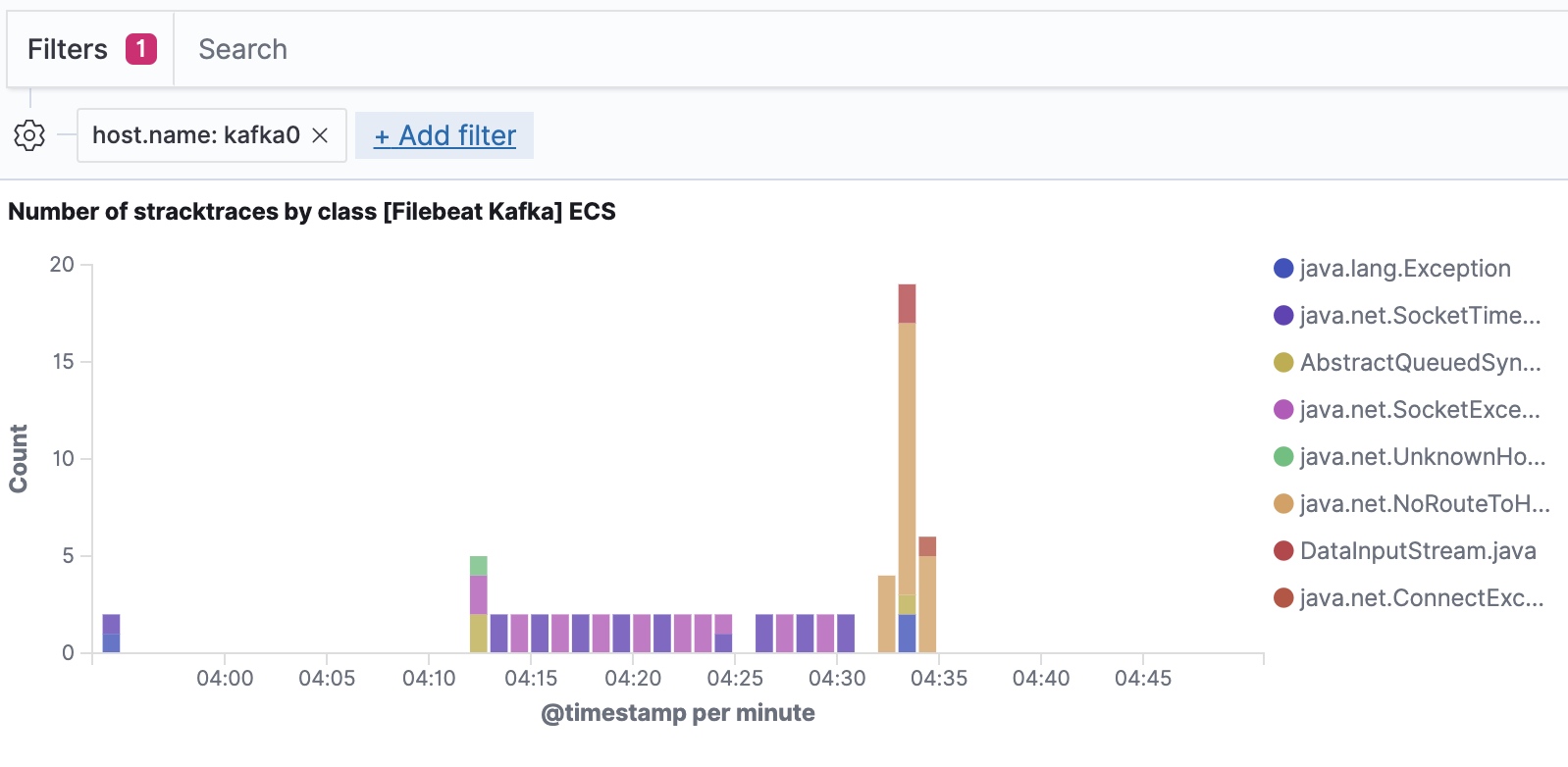
Filebeat ingestiert Daten unter Berücksichtigung des Elastic Common Schema, sodass wir bis hinunter auf die Host-Ebene filtern können.
Das von Metricbeat bereitgestellte Dashboard zeigt den aktuellen Status der Themen innerhalb des Kafka-Clusters. Über ein Drop-down-Menü kann die Dashboard-Anzeige auf ein einzelnes Thema eingeschränkt werden.
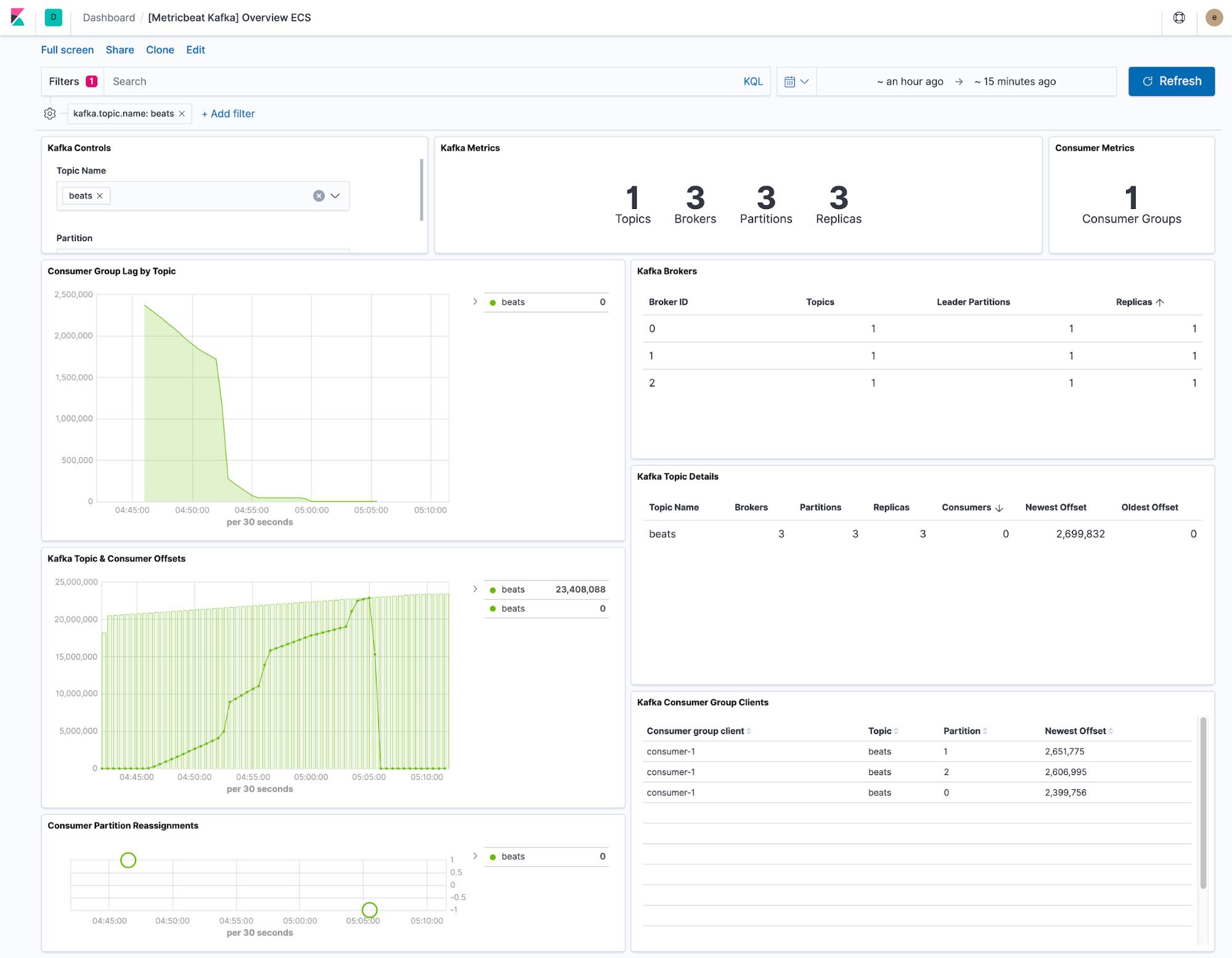
Die Visualisierung von „Consumer Lag“ und „Offset“ zeigen, ob Verbraucher bei bestimmten Themen ins Hintertreffen geraten. Den partitionsspezifischen Offset-Angaben kann entnommen werden, ob eine bestimmte Partition zurückbleibt.
In der standardmäßigen Metricbeat-Konfiguration werden die beiden Datensätze „kafka.partition“ und „kafka.consumergroup“ erfasst. Diese Datensätze geben Einblick in den Zustand des jeweiligen Kafka-Clusters und seiner Verbraucher.
Der Datensatz „kafka.partition“ enthält alle Einzelheiten über den Zustand der Partitionen im Cluster. Diese Daten können eingesetzt werden, um
- Dashboards zur Visualisierung der Zuordnung zwischen Partitionen und Cluster-Knoten zu erstellen,
- auf Partitionen hinzuweisen, die nicht synchron laufen,
- die Partitionszuweisung im Laufe der Zeit zu verfolgen und
- Partitions-Offset-Grenzwerte über einen bestimmten Zeitraum hinweg zu visualisieren.
Unten sehen Sie ein vollständiges „kafka.partition“-Dokument.

Der Datensatz „kafka.consumergroup“ erfasst den Zustand eines einzelnen Verbrauchers. Diese Daten können genutzt werden, um darzustellen, aus welchen Partitionen der Verbraucher liest und wie es mit den aktuellen Offsets dieses Verbrauchers aussieht.
