Elastic Stack 7.6.0 veröffentlicht
In diesem Blogpost wird auf eine Lösung namens „SIEM“ verwiesen. Diese Lösung ist in unserem neuen Produkt „Elastic Security“ aufgegangen. Elastic Security ist breiter angelegt als die alte Lösung und bietet u. a. SIEM, Endpoint-Security, Threat-Hunting und Cloud-Monitoring. Wenn Sie Informationen zu Elastic Security für SIEM-Anwendungsfälle suchen, besuchen Sie unsere SIEM-Seite.
Wir freuen uns, die allgemeine Verfügbarkeit der Version 7.6 des Elastic Stack bekanntgeben zu dürfen. Diese Version vereinfacht mit einer neuen SIEM-Erkennungs-Engine und einem kuratierten Satz von Erkennungsregeln, die auf der MITRE ATT&CK™-Knowledge-Base basieren, die automatisierte Bedrohungserkennung, macht Elasticsearch noch schneller, verhilft dem Machine Learning durch Inferenz-beim-Ingestieren-Funktionen zu mehr Zugänglichkeit und verbessert durch die Einführung neuer Datenintegrationen die Cloud-Observability und ‑Sicherheit. Und das ist nur ein kleiner Teil dessen, was diese Version an Neuem und Interessantem zu bieten hat.
Version 7.6 ist ab sofort in unserem Elasticsearch Service auf Elastic Cloud verfügbar, dem einzigen gehosteten Elasticsearch-Angebot, das diese neuen Features bereithält. Und all diejenigen, die das Ganze lieber selbst verwalten möchten, können den Elastic Stack herunterladen.
Wir stellen Ihnen hier die wichtigsten Neuerungen in aller Kürze vor. Ausführliche Besprechungen der Features finden Sie in den entsprechenden Feature-spezifischen Blogposts.
Elasticsearch wird (noch) schneller
Es passiert nicht jeden Tag, dass wir es schaffen, Elasticsearch-Abfragen um ein Vielfaches zu beschleunigen. Aber wir haben einen Weg gefunden, Abfragen, die nach Datum oder anderen langen Werten sortiert sind, deutlich schneller zu machen. Es ist uns gelungen, die Block-Max-WAND-Optimierung auf sortierte Abfragen anzuwenden und so zu verhindern, dass neue Ergebnisse gezählt werden, wenn deutlich wird, dass diese zu keinen anderen Resultaten führen. Ja, es handelt sich dabei um dieselbe Block-Max-WAND-Optimierung, die in 7.0 unsere Top-k-Abfragen schneller gemacht hat.
Falls das nicht klar herausgekommen sein sollte: Die Performance-Steigerung ist enorm. Das Sortieren nach der Zeit gehört zu den häufigsten Aufgaben in Observability- und Security-Anwendungsfällen. Fehlersuchen in der Elastic Logs-App oder Untersuchungen von Bedrohungen in Discover sind nur einige der vielen Dinge, die dank dieser Änderung schneller von der Hand gehen werden. Und um in den Genuss dieses Performance-Schubs zu kommen, müssen Sie einfach nur auf 7.6 upgraden.
Von Training bis Inferenz – beaufsichtigtes Machine Learning ist jetzt nativer Bestandteil des Elastic Stack
Die Einführung von Machine-Learning-Funktionen im Elastic Stack war immer schon mit dem Ziel verbunden, allen Mitarbeitern im Unternehmen die Möglichkeit zu geben, Machine Learning selbst zu nutzen. Bereits in Version 5.4, unserer ersten Version mit Machine-Learning-Funktionen, haben wir das Erkennen von Anomalien so leicht gemacht wie das Erstellen einer Visualisierung in Kibana. So haben wir dafür gesorgt, dass Machine Learning einem breiteren Publikum zugänglich wird und Data-Science-Teams effizienter arbeiten können. In Version 7.6 führen wir komplett beaufsichtigtes Machine Learning ein. „Komplett“ bedeutet dabei, dass die Beaufsichtigung vom Trainieren eines Modells bis hin zur Nutzung des Modells für Inferenzzwecke beim Ingestieren reicht. Wir möchten Methoden für das beaufsichtigte Machine Learning, wie Klassifizierung und Regression in Elasticsearch, für den Praxiseinsatz bei Observability-, Security- und Enterprise Search-Anwendungsfällen noch zugänglicher machen. So kann ein Security-Analyst jetzt mithilfe von Klassifizierung ein Modell zur Bot-Erkennung erstellen und dann die neue Inferenz-beim-Ingestieren-Funktion nutzen, damit schon beim Ingestieren neuer Traffic gegebenenfalls als Bot erkannt und gekennzeichnet wird – alles nativ in Elasticsearch.
Wie schon beim unbeaufsichtigten Lernen und bei der Anomalieerkennung besteht unser Ziel darin, das beaufsichtigte Machine Learning für jedermann einfach und zugänglich zu machen. Statt also ein generisches Data-Science-Toolkit zu entwickeln oder Integrationen mit externen Machine-Learning-Bibliotheken bereitzustellen, die die Nutzer zwingen, komplexe Workflows zusammenzuschustern und zu pflegen, bei denen die Daten mehrere Tools passieren müssen, haben wir uns darauf konzentriert, häufige Anwendungsfälle zu vereinfachen. Auf diese Weise ermöglichen wir neue Anwendungsfälle und sorgen dafür, dass der operative Aufwand so gering wie möglich gehalten wird.
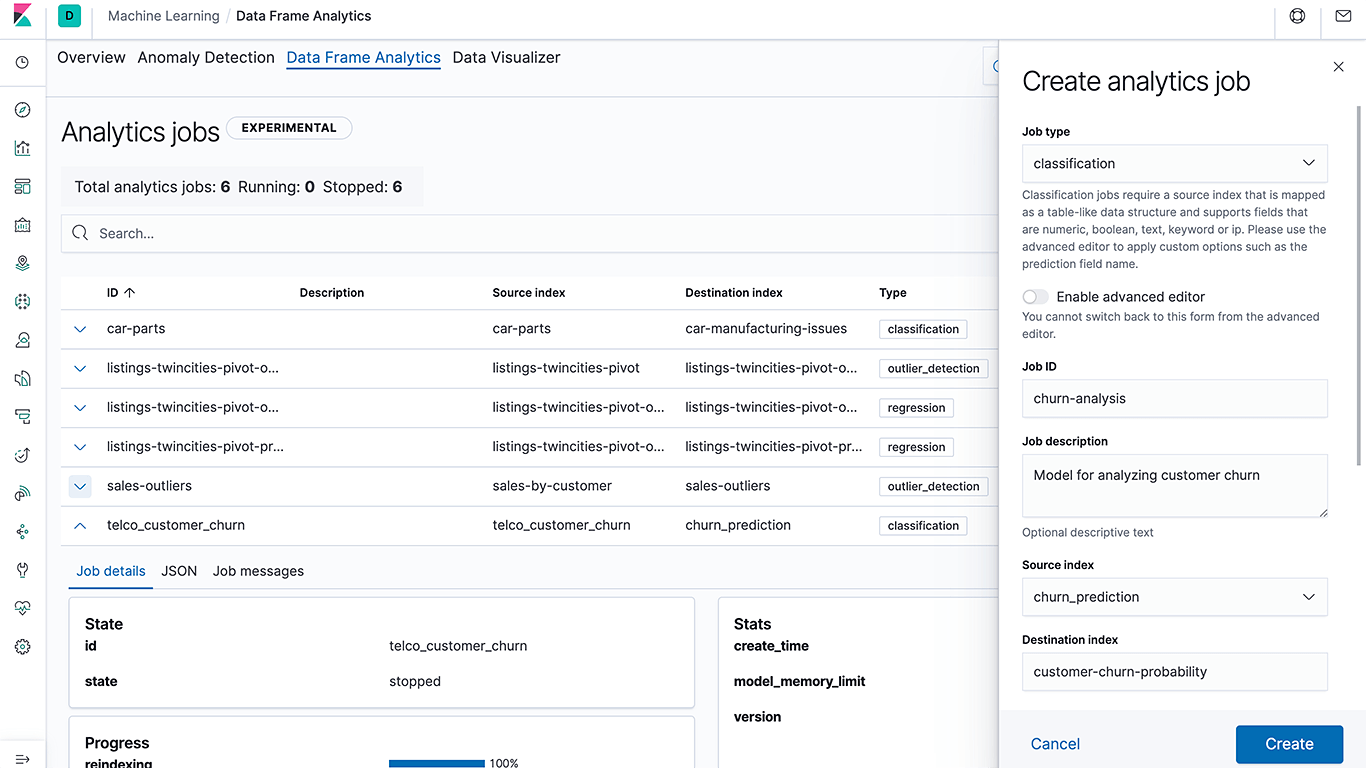
Wir entwickeln nicht nur die Rahmenbedingungen – wir sind auch Nutzer. Daher freut es uns sehr, ein Modell zur Erkennung von Sprachen bereitstellen zu können, mit dem Dokumenten während des Ingestierens gleich eine Sprache zugeordnet werden kann. Es gibt eine Vielzahl von Anwendungsfällen, in denen es sehr hilfreich ist, wenn die verwendete Sprache automatisch erkannt wird. So kann zum Beispiel ein Supportcenter dieses Feature nutzen, um ankommende Fragen sofort an den für die jeweilige Sprache zuständigen Support-Mitarbeiter oder ‑Standort zu leiten, und es kann genutzt werden, um sicherzustellen, dass eingehender Text in Elasticsearch ordnungsgemäß indexiert wird. Zu diesem Thema wird es einen eigenen Blogpost geben – bleiben Sie dran!
„Wir sind als Team für das Funktionieren des WLAN in den U-Bahnen von New York City und Toronto zuständig und wissen daher genau, wie wichtig es ist, Systemprobleme und Konnektivitätsanomalien erkennen zu können. Auf diese Weise sorgen wir jeden Tag für Qualitätsverbindungen für Millionen von Passagieren. Seit 2017 setzen wir zur Anomalieerkennung das unbeaufsichtigte Machine Learning von Elastic ein. So können wir in Echtzeit Probleme aufspüren, die andernfalls verborgen geblieben wären, und die Auswirkungen auf die Netzwerkleistung möglichst gering halten“, berichtet Jeremy Foran, Technology Specialist bei BAI Communications. „Mit Blick auf die Zukunft und die Absicht, unser Angebot auf weitere Nahverkehrssysteme in der ganzen Welt auszudehnen, werden wir das beaufsichtigte Machine Learning in Version 7.6 des Elastic Stack für den Aufbau neuer Netzwerke nutzen.“
Weitere Einzelheiten zu all diesen Features und mehr finden Sie im Blogpost zu Elasticsearch 7.6 und im Blogpost zu Kibana 7.6.
Elastic Security
Reduzierung der Verweildauer auf beinahe Null dank neuer SIEM-Erkennungs-Engine und auf MITRE ATT&CK™ basierenden Regeln
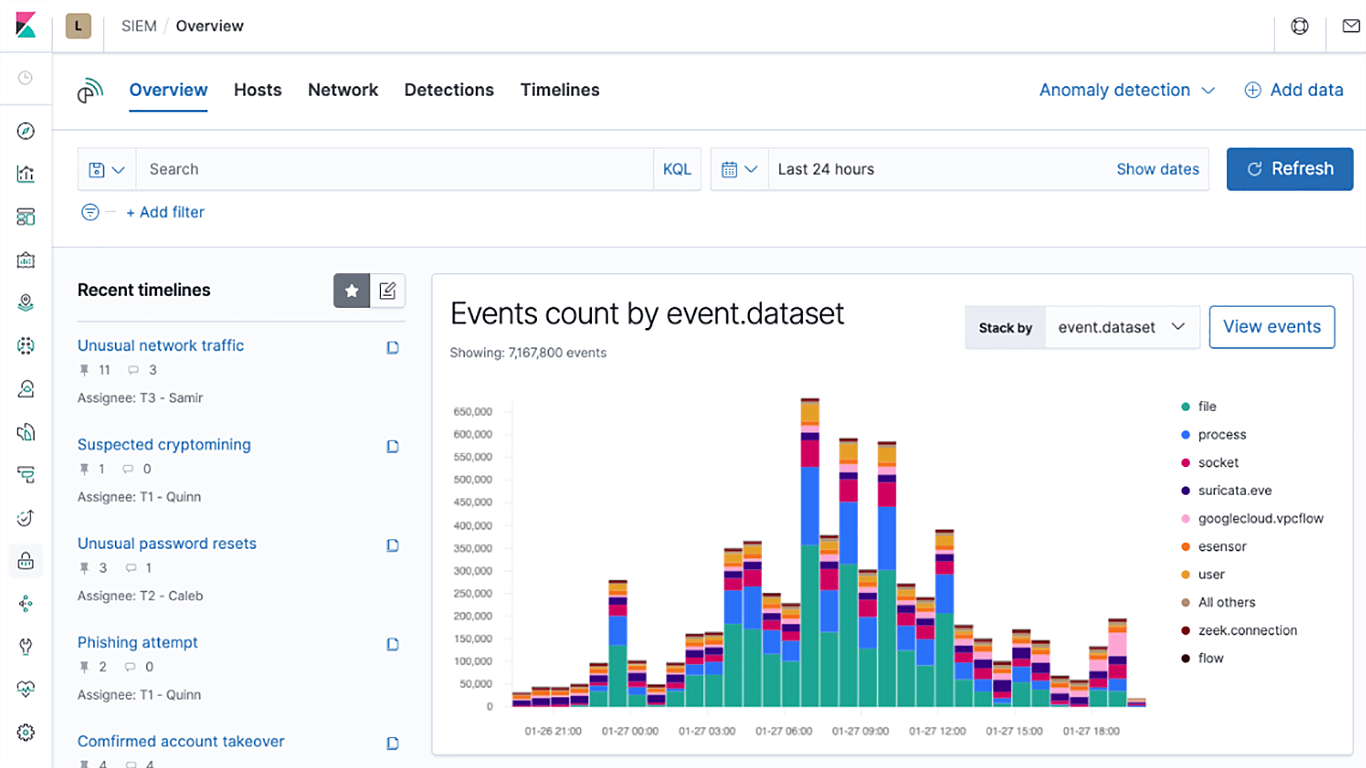
Neu in Elastic Security 7.6 ist eine SIEM-Erkennungs-Engine, die die Erkennung von Bedrohungen automatisiert und den MTTD-Wert (Mean Time to Detect – mittlere Zeit bis zur Erkennung) auf ein Minimum reduziert. Mit der Einführung von Elastic SIEM, in dessen Hintergrund Elasticsearch arbeitet, konnte die für die Untersuchung von Sicherheitsproblemen erforderliche Zeit bereits von Stunden auf Minuten reduziert werden. Die neue automatisierte Erkennungsfunktion in 7.6 verringert die Verweildauer von Bedrohungen noch weiter, da sie Bedrohungen erkennt, die ohne die Funktion unter dem Radar geblieben wären.
Außerdem führen wir fast 100 vorkonfigurierte Regeln ein, die auf der ATT&CK-Knowledge-Base basieren und dazu beitragen können, Signale für Bedrohungen zu erkennen, die von anderen Tools häufig nicht gefunden werden. Diese von Security-Experten bei Elastic entwickelten und gepflegten Regeln spüren automatisch Tools, Taktiken und Prozeduren auf, die auf Bedrohungsaktivitäten hindeuten. Die Erkennungs-Engine generiert Risiko- und Schweregrad-Scores für Signale, die Analysten dabei helfen, effiziente Vorabeinstufungen vorzunehmen und sich dann auf die Probleme zu konzentrieren, die die höchste Priorität haben.
Wir stellen die Erkennungs-Engine und die vorkonfigurierten Regeln in der kostenlosen Basic-Version von Elastic Security bereit – und machen damit die automatisierte Analyse für Security-Experten überall offen zugänglich.
Neuartige Einblicke in Windows-Endpunkte ermöglichen die Aufdeckung von Bedrohungsverstecken
Aufgrund ihrer großen Verbreitung und des laxen Benutzerberechtigungsmodells von Windows sind Systeme mit diesem Betriebssystem ein Hauptziel für Angreifer. Die neue Version verbessert die Möglichkeiten, Einblick in die Windows-Aktivitäten zu nehmen. Dazu werden Daten von Orten, die bekanntermaßen für die Taktiken zur Erkennungsvermeidung von hochentwickelten Bedrohungen anfällig sind, gesammelt und angereichert. Neue vorkonfigurierte Erkennungsregeln können anhand dieser Daten dann Versuche aufspüren, Tastatureingaben abzufangen, Schadcode in andere Prozesse zu laden und so weiter. Security-Experten haben die Möglichkeit, den so gefundenen Ereignissen automatisierte Reaktionen zuzuordnen (z. B. Prozessabbruch), um eine mehrschichtige Prävention sicherzustellen.
Mit dieser Funktionalität erhalten Unternehmen, in denen sehr viele Windows-Systeme im Einsatz sind, ein bisher ungekanntes Maß an Einblicksmöglichkeiten und Schutz – zu einem Preispunkt, der für jeden Analysten erschwinglich ist.
Das ist aber lange noch nicht alles, was Elastic Security zu bieten hat …
Elastic SIEM ist in 7.6 allgemein verfügbar. Zusätzlich zur Erkennungs-Engine bietet Elastic SIEM jetzt auch eine neu gestaltete Übersichtsseite und etliche UX-Verbesserungen, die das Aufspüren, Vorabbewerten und Untersuchen von Bedrohungen beschleunigen. Neue Integrationen für Amazon Web Services (AWS)- und Google Cloud Platform (GCP)-Logs sorgen für eine höhere Cloud-Security. Die ausführlichen Details erfahren Sie im Blogpost zur Veröffentlichung von Elastic Security 7.6.
Elastic Enterprise Search
Suche über alle Unternehmensbereiche hinweg, ohne Einbußen bei der Autonomie der einzelnen Funktionsbereiche
Für große Unternehmen ist es oft alles andere als leicht, die Suche über Standort- und Geschäftsbereichsgrenzen hinweg zu verwalten. In Elastic App Search 7.6 stehen mit Meta-Engines dokumentlose Engines zur Verfügung, die ihrerseits mehrere Engines auf einmal abfragen können. Mit Meta-Engines können Unternehmen die Möglichkeit anbieten, über ein einziges Suchfeld mehrere Engines abzufragen, ohne dass die Administratoren dabei die Kontrolle über das Verhalten der einzelnen Sub-Engines einbüßen würden.
Dieses Feature steht für App Search in der Elastic-Cloud und für die selbstverwaltete Version zur Verfügung.
Das Produkt „Enterprise Search“ heißt jetzt „Workplace Search“
„Elastic Enterprise Search“ ist fortan der Name für unsere Dachlösung, die unser gesamtes Angebot an Suchprodukten umfasst. Und unser Produkt „Enterprise Search“, das wir im Mai 2019 als Beta gestartet haben, heißt jetzt „Elastic Workplace Search“. Workplace Search bietet Teams und Unternehmen die Möglichkeit, alle Inhalte an allen Orten und in allen Tools zu durchsuchen und zu finden, die der Mitarbeiterschaft von heute zur Verfügung stehen. Mit einem einzigen Suchfeld erhalten Sie Zugang zu allen Ihren Arbeitsdaten.
Mehr über Meta-Engines und andere Neuerungen erfahren Sie im Blogpost zu Elastic Enterprise Search.
Elastic Observability
Neue AWS- und GCP-Integrationen bieten tiefere Einblicke in Cloud-Operationen
Wir erweitern unsere Integrationen in das Cloud-Ökosystem und helfen unseren Nutzern so, ihre Cloud-Operationen im Griff zu behalten. Das AWS-Abrechnungsmodul erlaubt es Unternehmen, ihre AWS-Abrechnung und ‑Nutzung zu verwalten. Wenn Sie diese Daten mit Machine-Learning- und Alerting-Features kombinieren, können Sie sich über abweichende Nutzungsmuster benachrichtigen lassen, bevor die Ausgaben außer Kontrolle geraten. Neue GCP-Module ermöglichen die direkte Überwachung von VMs sowie von von StackDriver überwachten GCP-Diensten, und vorkonfigurierte Kibana-Dashboards tragen dazu bei, dass die Zeit und der Aufwand für die Gewinnung von Erkenntnissen aus den ingestierten Daten auf ein Minimum reduziert werden. Diese neuen Cloud-Datenintegrationen ergänzen die in früheren Versionen bereits hinzugefügten und ermöglichen tiefere Einblicke in Cloud-Operationen.
Native Jaeger-Unterstützung in Elastic APM demonstriert unser Engagement für offene Standards
Von Open Source zu Open Code – Offenheit ist uns eine Herzensangelegenheit. Es ist für uns immer wieder inspirierend zu sehen, wie die Observability-Community Initiativen wie OpenTracing und OpenTelemetry nutzt, um offene Standards zu entwickeln und weiterzuführen, und wir unterstützen diese offenen Standards in Elastic Observability von ganzem Herzen. Jaeger, ein mit OpenTracing-Standards kompatibles CNCF-Projekt mit dem Status „graduated“, ist eine beliebte Wahl für das End-to-End-Tracing von Anforderungen. Elastic APM-Agents sind schon seit ihren Anfangstagen OpenTracing-kompatibel. Mit der neuen Jaeger-Intake-Unterstützung in Version 7.6 steht nun eine noch direktere Brücke zwischen Elastic APM und Jaeger zur Verfügung.
Elastic APM fungiert jetzt als Jaeger-Intake, sodass Kunden Jaeger-instrumentierte Traces über den APM-Server direkt in Elasticsearch ingestieren lassen können, ohne bestehenden Jaeger-instrumentierten Code ändern zu müssen. Nutzer können jetzt ihre Jaeger-instrumentierten Traces in Elastic APM importieren und sie zusammen mit ihren Logdaten und Metriken erkunden – schnell und ohne großen Aufwand.
Weitere Highlights in Elastic Observability:
- Machine-Learning-gestützte Logdatenkategorisierung gruppiert Logdaten mit ähnlichen Formaten und vereinfacht die Trendanalyse
- Versions-Annotation in Elastic APM erkennt, wenn neue Versionen von Diensten veröffentlicht werden, und annotiert die Timeline in der APM-App entsprechend
Informationen zu allen neuen Features in Elastic Observability erhalten Sie im ausführlichen Blogpost.
Wie immer gibt es noch viel mehr zu berichten –
viel, viel mehr! Nähere Informationen zu all den Neuerungen, die Sie in Version 7.6 erwarten, finden Sie in den Blogposts zu den einzelnen Produkten:
Der Elastic Stack
Lösungen