Elastic Stack 7.3.0 veröffentlicht
Mit großer Freude geben wir bekannt, dass die Version 7.3 des Elastic Stack verfügbar ist – und auch diese Version ist uns gut gelungen.
In diesem Blogpost stellen wir Ihnen einige der Highlights der Version vor. Wenn Sie sich genauer über die Details der einzelnen Produkte informieren möchten, empfehlen wir Ihnen die jeweiligen produktspezifischen Blogposts. Und wer partout nicht warten mag, kann Version 7.3 ab sofort in unserem Elasticsearch Service nutzen, dem einzigen gehosteten Elasticsearch-Angebot, das diese neuen Features bereithält. Alternativ können Sie auch den Elastic Stack herunterladen.
Jetzt aber dazu, weshalb Sie hier sind – wir stellen Ihnen die Neuerungen vor.
Materialisierte Ansicht? Entity-zentrischer Index? Neu in Version 7.3: Datenframes
Mit Datenframes führen wir ein neues Feature ein, das es Ihnen erlaubt, ad hoc Ihre Elasticsearch-Daten zu pivotieren, um Entity-zentrische Indizes zu erstellen. Dieses interessante Feature eröffnet Ihnen eine ganz neue Welt der Analyse, inklusive der neuen Machine-Learning-Analyse – wie Ausreißererkennung (in 7.3 als Experimental-Feature hinzugefügt), Clustering, Klassifizierung und mehr.
Wie bei besonders leistungsfähigen Konzepten häufig der Fall, lässt sich auch dieses am besten anhand eines Beispiels erklären: Stellen Sie sich vor, Sie möchten in Ihren Webserver-Logs verdächtige IP-Adressen ausfindig machen. Zu diesem Zweck wollen Sie sich ansehen, wie viele Anfragen gestellt, welche Antwortcodes zurückgegeben und wie viele Daten insgesamt für jede IP-Adresse übertragen wurden. Mit Datenframes können Sie einen neuen Entity-zentrischen Index mit genau einem Dokument pro IP-Adresse erstellen, der jede der Metriken verfolgt, die Sie interessieren. In diesem Fall wären das die Gesamtzahl der Anfragen, die Zahl pro Antwortstatus und die Summe der übertragenen Bytes. Das Sahnehäubchen ist, dass Datenframes die kontinuierliche Verarbeitung unterstützen, was bedeutet, dass dieser transformierte Entity-zentrische Index automatisch aktualisiert wird, sobald neue Dokumente zum Eingabeindex hinzukommen.
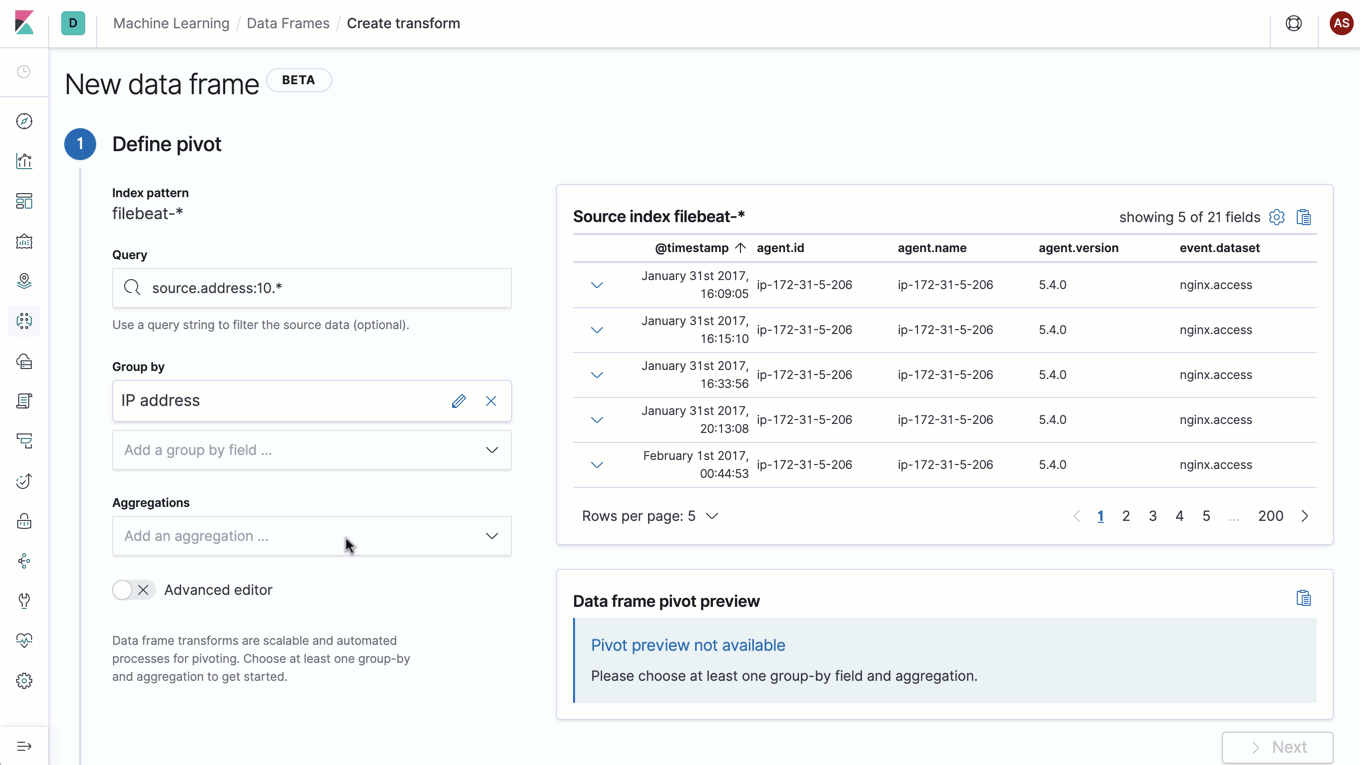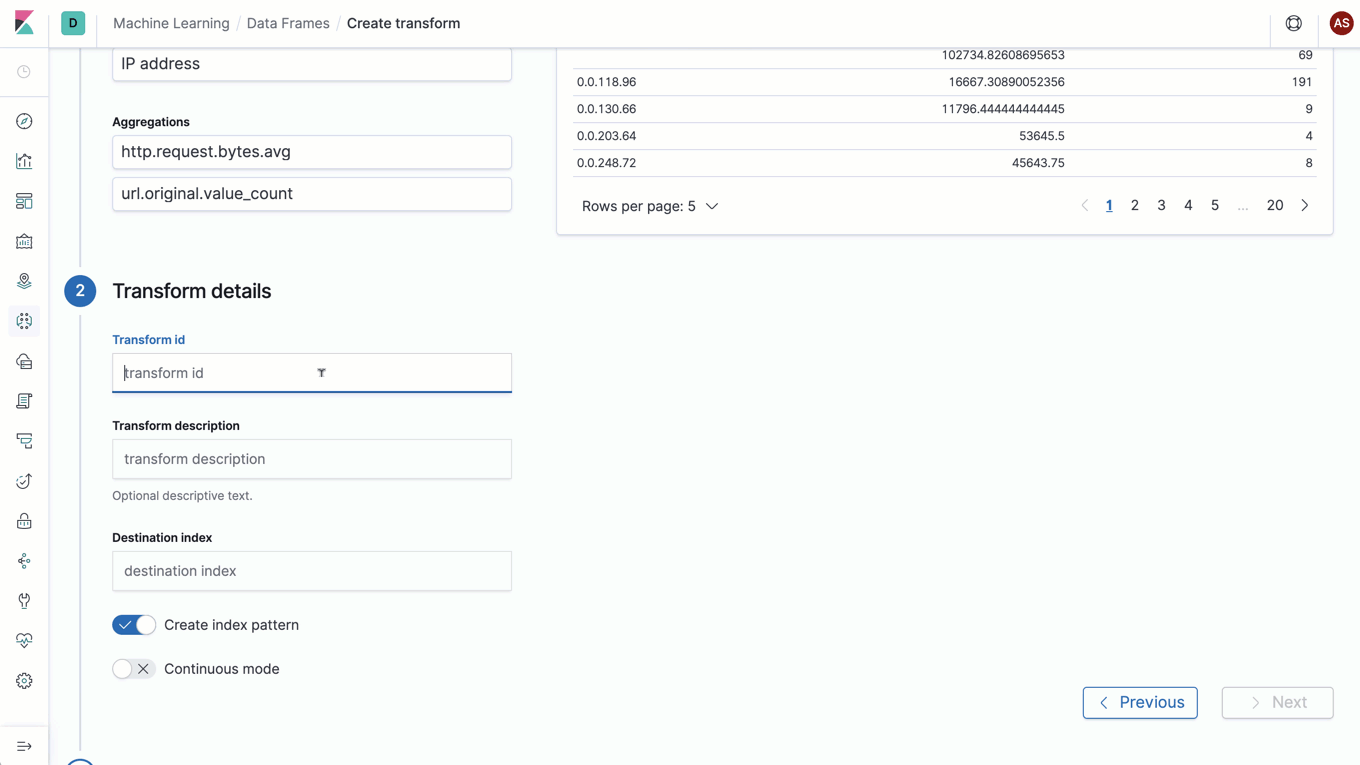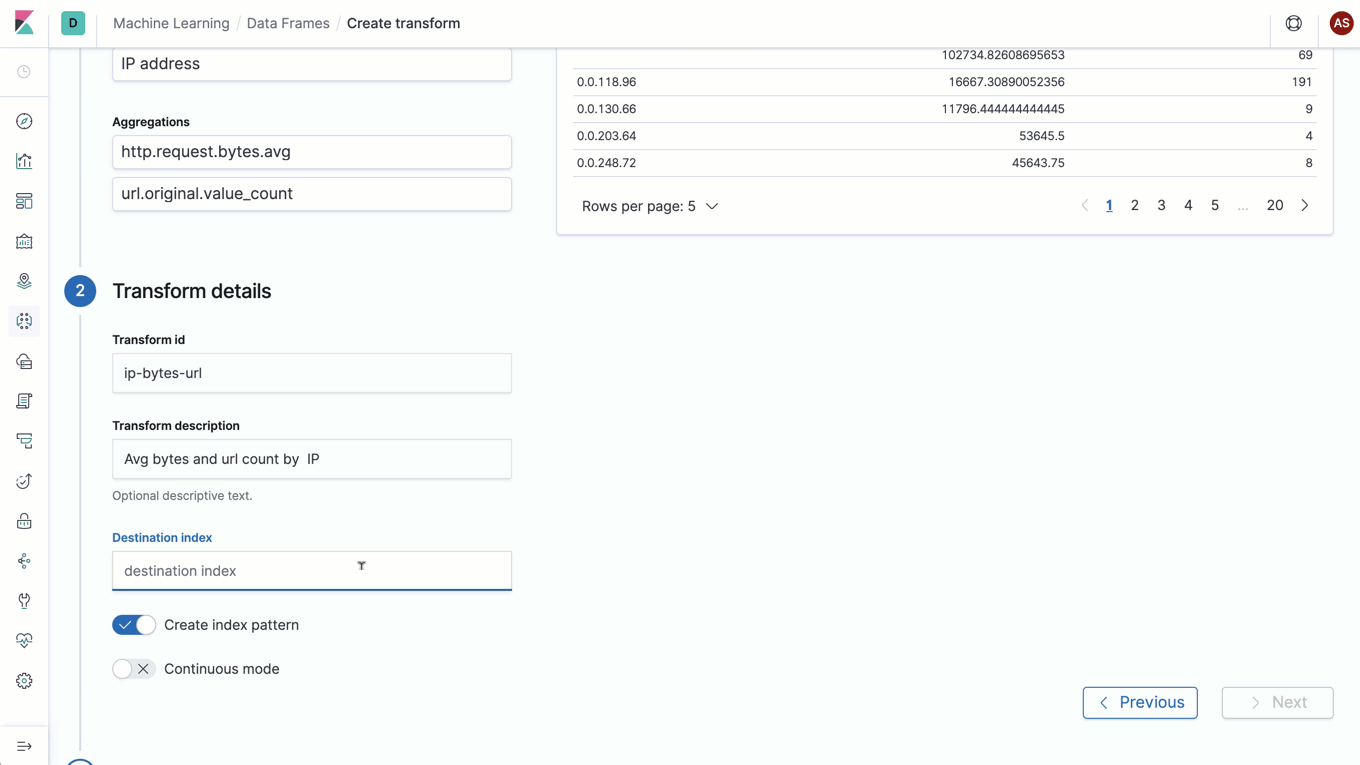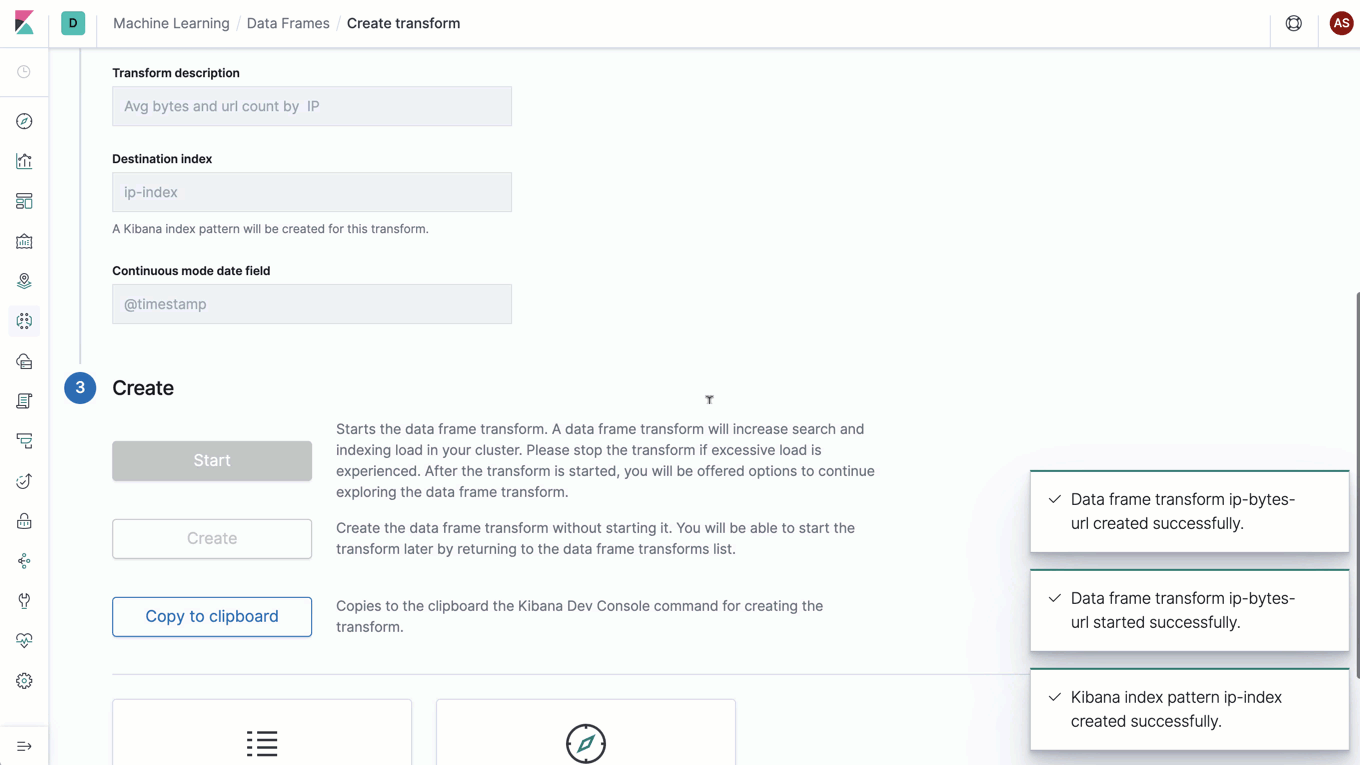
Mit Datenframes steht eine leistungsfähige Methode zur Verfügung, Daten für neue Analysearten zu transformieren. Diese Live-Pivots sind nur ein Vorgeschmack auf die verschiedenen Transformationen, die mit Datenframes möglich werden. Für die Zukunft sind weitere Transformationen geplant, mit denen das Datenframes-Konzept auf eine noch größere Zahl von Anwendungsfällen ausgedehnt wird.
Weitere Informationen zu Datenframes.
Elastic SIEM jetzt mit Anomalieerkennung – weil Regeln allein nicht ausreichen
Unsere SIEM-Lösung gibt es seit Version 7.2 und wir haben fleißig daran gearbeitet, sie weiter auszubauen.
Mit Regeln allein lassen sich nur die wenigsten bösen Buben (und Mädchen) stellen. Aus diesem Grund haben wir die Bedrohungserkennungs- und Threat-Hunting-Workflows in Elastic SIEM für 7.3 erweitert, indem wir unsere Machine-Learning-Funktionen direkt in die SIEM-App integriert haben. So können die Nutzer jetzt ohne viel Aufwand direkt in der SIEM-App verschiedene Machine-Learning-Anomalieerkennungsjobs zur Erkennung von spezifischem Angriffsverhalten einrichten und ausführen lassen. Die dabei erkannten Anomalien werden in den Host- und Netzwerkansichten der SIEM-App angezeigt.
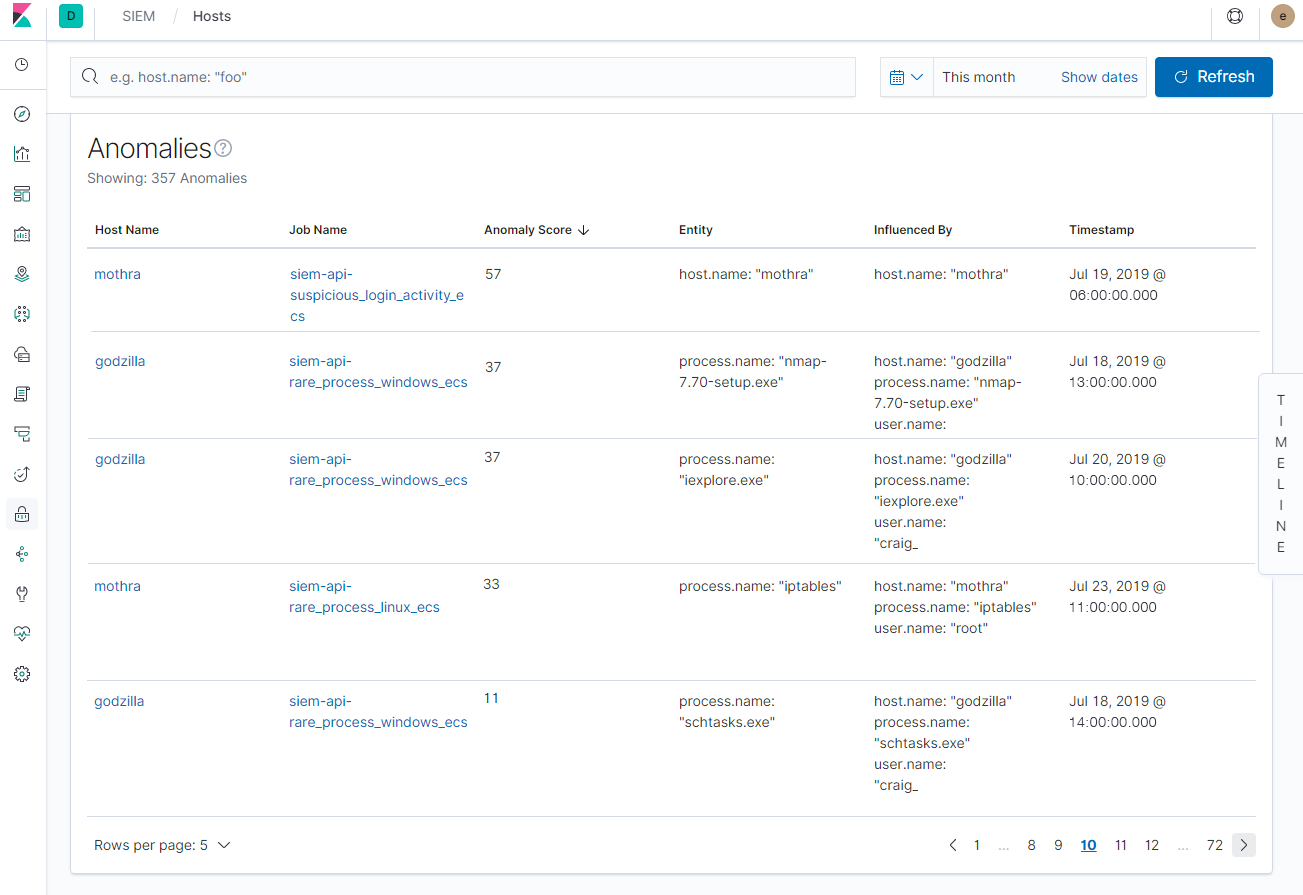
Und wer mehr machen möchte, als mit den vorgefertigten Aufgaben möglich, kann über die Machine-Learning-App schnell und einfach benutzerdefinierte Anomalieerkennungsaufgaben hinzufügen.
Diese Integration macht es jetzt so einfach wie nie, mittels Machine Learning Angriffsverhaltensmuster zu erkennen. Die ausführlichen Details erfahren Sie im Blogpost zu Elastic SIEM
Elastic Maps ist allgemein verfügbar
Positionsdaten waren immer schon ein kritischer Teil der Suche, egal, ob es darum geht, die Quelle von Angriffen im Netzwerk zu untersuchen, langsame Antwortzeiten in einer konkreten Region zu diagnostizieren, Zustellfahrzeuge in Echtzeit zu verfolgen oder einfach nur die beste Pizza in der Nähe zu finden. Daher arbeiten wir von Anfang an (0.9.1!) daran, im Elastic Stack schnellere, leistungsfähigere und effizientere Geodatenfunktionen bereitzustellen.
Mit der Einführung von Elastic Maps als Beta-Feature in 6.7 wollten wir unseren Nutzern einen intuitiveren und interaktiveren Weg zum Erkunden und Verstehen von Geodaten in Kibana bieten und ein solides Fundament für die Zukunft legen. Und in 7.3 können wir voller Stolz verkünden, dass Maps jetzt Produktionsreife erlangt hat.
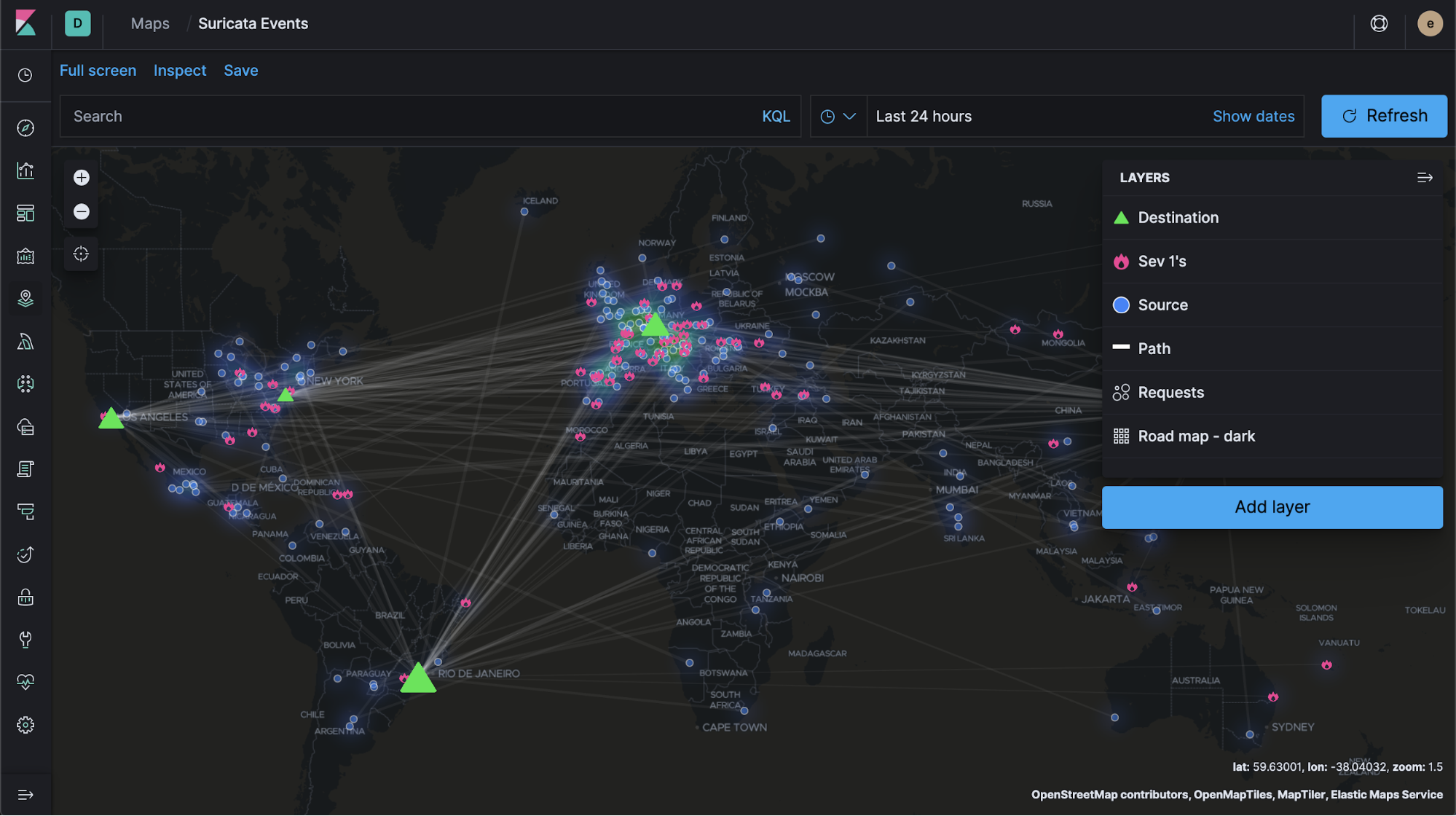
In Elastic Maps gibt es jetzt auch verschiedene neue Features und das spannendste dürfte die Fähigkeit sein, Merkmale, Formen und Ebenen aus GeoJSON-Dateien in Karten zu laden. Andere Verbesserungen, wie die Möglichkeit, benutzerdefinierte Symbole einzufügen und die letztbekannte Position zu visualisieren, tragen ebenso zur Erhöhung der Benutzerfreundlichkeit bei.
Alle Details finden Sie in unserem Blogpost zu Maps. Es macht uns unglaublich stolz, was wir mit Elastic Maps alles geschafft haben, und wir hoffen, dass unsere Nutzer die neuen Features in 7.3 sowie die spannenden Features, die wir für die Zukunft geplant haben, genauso toll finden.
Ja, es gibt noch mehr –
viel, viel mehr! Nähere Informationen zu all den guten Sachen, die Sie in Version 7.3 erwarten, finden Sie in den Blogposts zu den individuellen Produkten:
- Elasticsearch bietet jetzt „Voting-only“-Master-Knoten, fügt die lang ersehnte Aggregation seltener Begriffe hinzu, verfügt über eine neue Benutzeroberfläche zur Verwaltung von Snapshots und Wiederherstellungen, ermöglicht das Hinzufügen dynamisch aktualisierbarer Synonyme und und und … Die Einzelheiten finden Sie im Blogpost zur neuen Elasticsearch-Version.
- Neu in Kibana sind die Unterstützung für Kerberos, die automatische Vervollständigung und die KQL-Unterstützung zum Filtern von Aggregationen sowie Canvas-Workpad-Vorlagen, die das Erstellung ansprechender Präsentationsansichten vereinfachen – und die Liste ist damit noch lange nicht am Ende.
- In Beats werden jetzt etliche neue Datenquellen, einschließlich relationaler Datenbanken wie Oracle und Amazon RDS, Metriken für Kubernetes kube-proxy, kube-scheduler und kube-controller-manager sowie Network Flow für GCP-VPC-Flow-Logdaten unterstützt, und die Functionbeat-Unterstützung für Amazon Kinesis-Daten-Streams und Amazon Cloudwatch wurde verbessert. Wenn Sie mehr dazu wissen möchten, lesen Sie unseren Blogpost zur neuen Beats-Version.
- Logstash bietet jetzt standardmäßig JMS-Unterstützung.
- Der Elastic APM-.NET-Agent ist jetzt allgemein verfügbar. Und in Elastic APM gibt es eine neue Möglichkeit, Dienste mit aggregierten, nach Diensten aufgeschlüsselten Diagrammen anzeigen zu lassen, die Agent-Abtastrate direkt in Kibana zu konfigurieren und eine ganze Menge mehr.
- In Elastic Uptime lassen sich jetzt mit Monitorzusammenfassungen und ‑details das Aussehen und die Arbeitsweise von Monitoren an verschiedenen Standorten verbessern.
- Neu in Elastic Logs sind die Suchbegriffmarkierung sowie die Möglichkeit, anhand von
trace.idzu konkreten APM-Traces zu springen. - Der Metrics Explorer in der Elastic Infrastructure-App, mit dem Sie schnell und einfach Aggregationsvisualisierungen gegen Zeitreihenmetriken durchführen können, kann jetzt in Produktionssystemen eingesetzt werden. Elastic Infrastructure bietet auch eine verbesserte Überwachung zusätzlicher Kerndienste von Kubernetes sowie einen neuen RDS-Metrikensatz im AWS-Modul. Mehr erfahren Sie im Blogpost zu Elastic Infrastructure.
Viel Spaß!