Erstellen von eingefrorenen Indizes mit der Elasticsearch Freeze Index API
Zunächst etwas Kontext
Heiß-Warm-Architekturen werden oft eingesetzt, um die vorhandene Hardware optimal auszunutzen. Diese Konfigurationen sind besonders hilfreich für zeitbasierte Daten, wie etwa Logs, Metriken und APM-Daten. Viele dieser Einrichtungen basieren darauf, dass diese Daten nach dem Ingestieren schreibgeschützt sind, und dass Indizes zeit- oder größenbasiert sein können. Wir können sie also mit unserem gewünschten Aufbewahrungszeitraum mühelos löschen. In dieser Architektur kategorisieren wir Elasticsearch-Knoten in zwei Gruppen: „Heiß“ und „Warm“.
Heiße Knoten enthalten die aktuellsten Daten und verarbeiten daher die gesamte Indizierungslast. Da die aktuellsten Daten auch am häufigsten abgefragt werden, sind dies die leistungsstärksten Knoten in unserem Cluster: schneller Speicher, großer Arbeitsspeicher und schnelle CPU. Diese zusätzliche Leistung ist jedoch teuer. Daher macht es wenig Sinn, ältere und seltener abgefragte Daten auf einem heißen Knoten zu speichern.
Warme Knoten eignen sich dagegen besser für die langfristige und kostengünstigere Speicherung. Die Daten auf den warmen Knoten werden vermutlich seltener abgefragt, und die Daten im Cluster werden auf Basis unserer geplanten Aufbewahrung (mithilfe von Shard-Zuweisungsfilterung) von heißen zu warmen Knoten verschoben, sind jedoch weiterhin für Abfragen online verfügbar.
Seit Elastic Stack 6.3 haben wir neue Funktionen für Heiß-Warm-Architekturen implementiert, um die Arbeit mit zeitbasierten Daten zu vereinfachen.
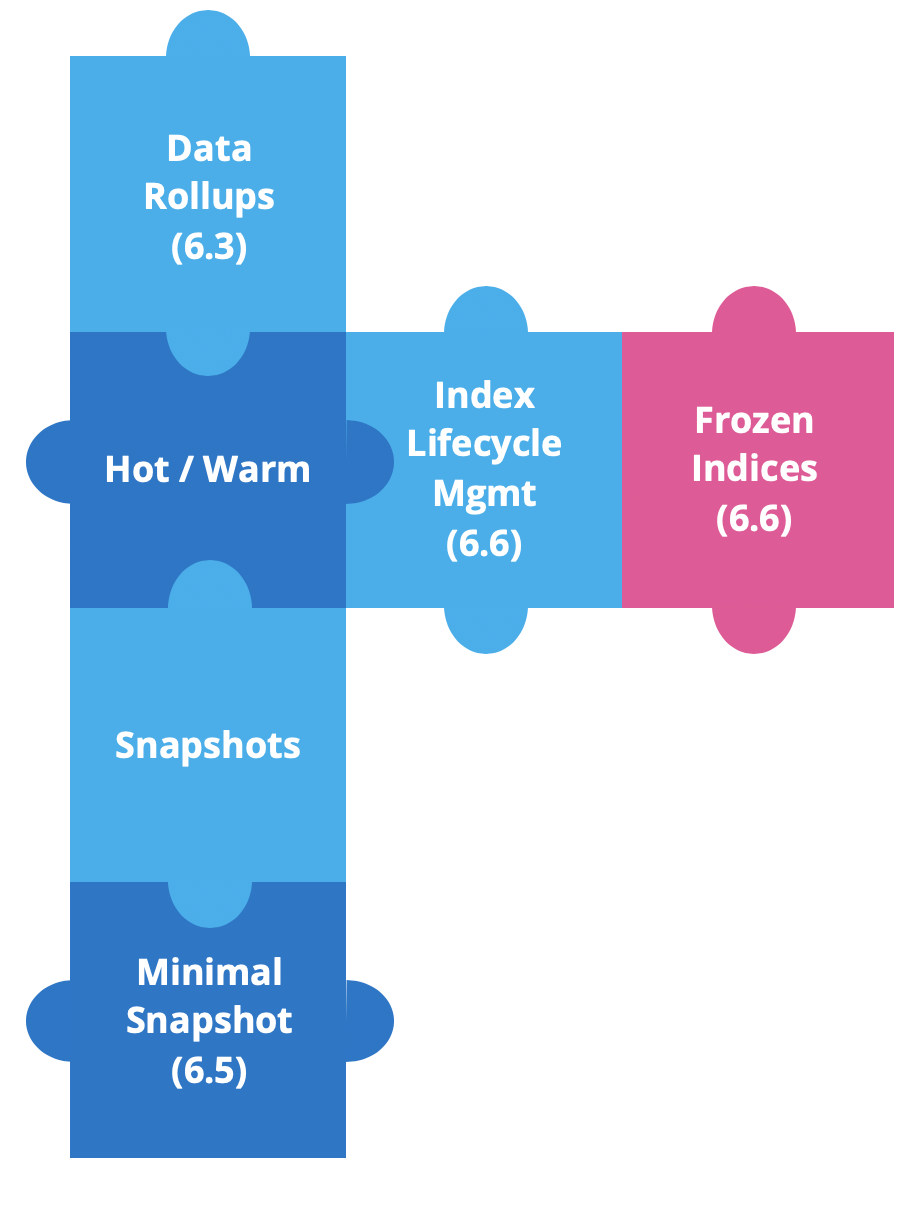
Daten-Rollups wurden in Version 6.3 eingeführt, um Speicherplatz zu sparen. In Zeitreihendaten brauchen wir umfassende Details für die aktuellsten Daten. Es ist jedoch unwahrscheinlich, dass wir dieselben Details für Verlaufsdaten benötigen, da wir dort normalerweise mit ganzen Datensätzen arbeiten. An dieser Stelle kommen Rollups zum Einsatz, da wir seit Version 6.5 Rollup-Daten in Kibana erstellen, verwalten und visualisieren können.
Kurz darauf haben wir Source-Only-Snapshots eingeführt. Diese minimalen Snapshots benötigen deutlich weniger Snapshot-Speicher, dafür müssen die Daten jedoch neu indiziert werden, um sie wiederherstellen oder abfragen zu können. Diese Funktion ist seit Version 6.5 verfügbar.
In Version 6.6 haben wir zwei leistungsstarke Funktionen eingeführt Index-Lifecycle-Management (ILM) und eingefrorene Indizes.
Mit ILM können Sie Ihre Indexverwaltung zeitlich planen und automatisieren. Sie können Ihre Indizes mühelos von heiß nach warm verschieben, alte Indizes löschen oder Indizes zwangsweise in einem Segment zusammenführen.
Der Rest dieses Blogeintrags befasst sich mit eingefrorenen Indizes.
Warum frieren wir Indizes ein?
Eines der größten Probleme mit alten Daten ist die Tatsache, dass die Indizes unabhängig vom Alter immer noch erheblichen Speicherplatz verbrauchen. Selbst wenn wir sie auf kalten Knoten ablegen, verbrauchen sie weiterhin Heap-Speicher.
Dies ließe sich beispielsweise beheben, indem wir den Index schließen. Ein geschlossener Index verbraucht keinen Speicherplatz, muss jedoch neu geöffnet werden, um eine Suche auszuführen. Das erneute Öffnen von Indizes ist mit Betriebsaufwand verbunden, und der vor dem Schließen verbrauchte Heap-Speicher wird wieder belegt.
Der verfügbare Speicherplatz auf den einzelnen Knoten wird durch das Verhältnis zwischen Arbeitsspeicher (Heap) und Festplattenspeicher festgelegt. Dieses Verhältnis reicht von 1:8 (Arbeitsspeicher:Daten) in arbeitsspeicherintensiven Szenarien bis hin zu fast 1:100 für weniger anspruchsvolle Anwendungsfälle.
An dieser Stelle kommen eingefrorene Indizes ins Spiel. Was wäre, wenn wir unsere Indizes offen - und damit durchsuchbar - halten können, ohne dafür Heap-Speicher zu verbrauchen? Wir könnten den Speicher der Datenknoten mit eingefrorenen Indizes erweitern und das Verhältnis von 1:100 knacken. Dabei müssen wir jedoch beachten, dass die Suche möglicherweise verlangsamt wird.
Eingefrorene Indizes sind schreibgeschützt, und ihre kurzlebigen Datenstrukturen werden aus dem Arbeitsspeicher gelöscht. Wenn wir eine Abfrage an einen eingefrorenen Index ausführen, müssen wir die Datenstrukturen daher in den Arbeitsspeicher laden. Suchvorgänge in einem eingefrorenen Index müssen nicht unbedingt langsam sein. Lucene verlässt sich beispielsweise auf den Zwischenspeicher des Dateisystems, der ausreichen kann, um einen Großteil Ihres Index im Arbeitsspeicher aufzubewahren. In diesen Fällen ist die Suchgeschwindigkeit pro Shard in etwa vergleichbar. Trotzdem werden eingefrorene Indizes dadurch ausgebremst, dass nur eine eingefrorene Shard pro Knoten gleichzeitig ausgeführt wird. Dieser Aspekt kann Suchvorgänge im Vergleich zu nicht eingefrorenen Indizes verlangsamen.
So funktioniert das Einfrieren
Eingefrorene Indizes werden mit einem dedizierten, gedrosselten Such-Threadpool durchsucht. Diese Funktion verwendet standardmäßig einen einzigen Thread, um sicherzustellen, dass eingefrorene Indizes einzeln in den Arbeitsspeicher geladen werden. Parallele Suchvorgänge werden als zusätzliche Sicherheitsmaßnahme in einer Warteschlange abgelegt, um den Arbeitsspeicher des Knotens nicht zu überlasten.
In einer Heiß-Warm-Architektur können wir also Indizes von heiß nach warm verschieben und anschließend einfrieren, bevor wir sie archivieren oder löschen, um unsere Hardwareanforderungen zu reduzieren.
Vor der Einführung der eingefrorenen Indizes mussten wir Snapshots unserer Daten erstellen und archivieren, um die Infrastrukturkosten zu senken, wodurch zusätzliche Betriebskosten entstanden. Wir mussten die Daten wiederherstellen, um sie erneut durchsuchen zu können. Jetzt können wir unsere Verlaufsdaten ohne spürbare Mehrbelastung des Arbeitsspeichers weiterhin durchsuchbar aufbewahren. Und falls wir je wieder in einen bereits eingefrorenen Index schreiben müssen, können wir das Einfrieren jederzeit aufheben.

So frieren Sie einen Elasticsearch-Index ein
Sie können eingefrorene Indizes mühelos zu Ihrem Cluster hinzufügen. Wir befassen uns also zunächst mit der Freeze Index API und dem Durchsuchen von eingefrorenen Indizes.
Zunächst werden wir einige Beispieldaten in einem Testindex erstellen.
POST /sampledata/_doc
{
"name": "Jane",
"lastname": "Doe"
}
POST /sampledata/_doc
{
"name": "John",
"lastname": "Doe"
}
Anschließend überprüfen wir, ob unsere Daten ingestiert wurden. Diese Abfrage sollte zwei Treffer zurückgeben:
GET /sampledata/_search
Als Best Practice sollten Sie immer ein force_merge ausführen, bevor Sie einen Index einfrieren. Damit stellen Sie sicher, dass jede Shard nur ein einziges Segment auf dem Datenträger belegt. Außerdem verbessert dieser Vorgang die Komprimierung und vereinfacht die Datenstrukturen, die wir für Aggregationen oder sortierte Suchanfragen an den eingefrorenen Index brauchen. Suchvorgänge in einem eingefrorenen Index mit mehreren Segmenten können einen beträchtlichen Mehraufwand von mehreren Größenordnungen verursachen.
POST /sampledata/_forcemerge?max_num_segments=1
Im nächsten Schritt rufen wir die Freeze-Funktion für unseren Index über den Freeze Index API-Endpunkt ab.
POST /sampledata/_freeze
Suchvorgänge in eingefrorenen Indizes
Nachdem Sie den Index eingefroren haben, funktionieren normale Suchvorgänge nicht mehr. Dies liegt daran, dass eingefrorene Indizes gedrosselt werden, um den Speicherverbrauch pro Knoten zu begrenzen. Da wir möglicherweise versehentlich einen eingefrorenen Index als Ziel verwenden, können wir unbeabsichtigte Leistungsprobleme vermeiden, indem wir ignore_throttled=false zur Anfrage hinzufügen.
GET /sampledata/_search?ignore_throttled=false
{
"query": {
"match": {
"name": "jane"
}
}
}
Anschließend können wir die folgende Anfrage ausführen, um den Status unseres neuen Index zu überprüfen:
GET _cat/indices/sampledata?v&h=health,status,index,pri,rep,docs.count,store.size
Daraufhin wird in etwa das folgende Ergebnis zurückgegeben, und der Status des Index wird als „open“ (offen) angezeigt:
health status index pri rep docs.count store.size
green open sampledata 5 1 2 17.8kb
Wie bereits erwähnt müssen wir verhindern, dass der Arbeitsspeicher im Cluster überbelastet wird. Daher gilt eine Obergrenze für die Anzahl der eingefrorenen Indizes, die wir parallel für die Suche in einem Knoten laden können. Der gedrosselte Such-Threadpool enthält standardmäßig einen einzigen Thread und eine Warteschlange mit 100 Plätzen. Wenn wir also mehr als eine Anfrage ausführen, werden bis zu 100 zusätzliche Anfragen in der Warteschlange abgelegt. Mit der folgenden Anfrage können wir den Threadpool-Status überwachen, um Warteschlangen und abgelehnte Anfragen zu überprüfen:
GET _cat/thread_pool/search_throttled?v&h=node_name,name,active,rejected,queue,completed&s=node_name
Diese Anfrage sollte in etwa das folgende Ergebnis liefern:
node_name name active rejected queue completed
instance-0000000000 search_throttled 0 0 0 25
instance-0000000001 search_throttled 0 0 0 22
instance-0000000002 search_throttled 0 0 0 0
Eingefrorene Indizes sind zwar langsamer, können jedoch sehr effektiv vorab gefiltert werden. Außerdem empfehlen wir, den Anfrageparameter pre_filter_shard_size auf 1 festzulegen.
GET /sampledata/_search?ignore_throttled=false&pre_filter_shard_size=1
{
"query": {
"match": {
"name": "jane"
}
}
}
Diese Änderung verursacht keinen nennenswerten Mehraufwand und ist hilfreich für viele gängige Szenarien. Wenn wir in einem Zeitreihenindex nach einem Zeitintervall suchen, enthalten beispielsweise nicht alle Shards Übereinstimmungen.
So schreiben Sie in einen eingefrorenen Elasticsearch-Index
Was passiert, wenn wir versuchen, in einen bereits eingefrorenen Index zu schreiben? Lassen Sie es uns ausprobieren.
POST /sampledata/_doc
{
"name": "Janie",
"lastname": "Doe"
}
Was ist passiert? Eingefrorene Indizes sind schreibgeschützt, daher wird der Schreibvorgang blockiert. Wir können diese Option in den Indexeinstellungen überprüfen:
GET /sampledata/_settings?flat_settings=true
Das Ergebnis dieser Abfrage:
{
"sampledata" : {
"settings" : {
"index.blocks.write" : "true",
"index.frozen" : "true",
....
}
}
}
Wir müssen die Unfreeze index API verwenden und den Unfreeze-Endpunkt für den Index aufrufen.
POST /sampledata/_unfreeze
Anschließend können wir ein drittes Dokument erstellen und danach suchen.
POST /sampledata/_doc
{
"name": "Janie",
"lastname": "Doe"
}
GET /sampledata/_search
{
"query": {
"match": {
"name": "janie"
}
}
}
„Unfreeze“ sollte nur in Ausnahmesituationen aufgerufen werden. Und vergessen Sie nicht, vor dem erneuten Einfrieren immer „force_merge“ für den Index aufzurufen, um die Leistung zu optimieren.
Eingefrorene Indizes in Kibana
Zunächst laden wir einige Beispieldaten, etwa die Beispielflugdaten.
Klicken Sie auf die Schaltfläche „Add“ (Hinzufügen) für die Beispielflugdaten.
Mit der Schaltfläche „View Data“ (Daten anzeigen) sollten Sie die geladenen Daten jetzt abrufen können. Das Dashboard sollte in etwa wie folgt aussehen.
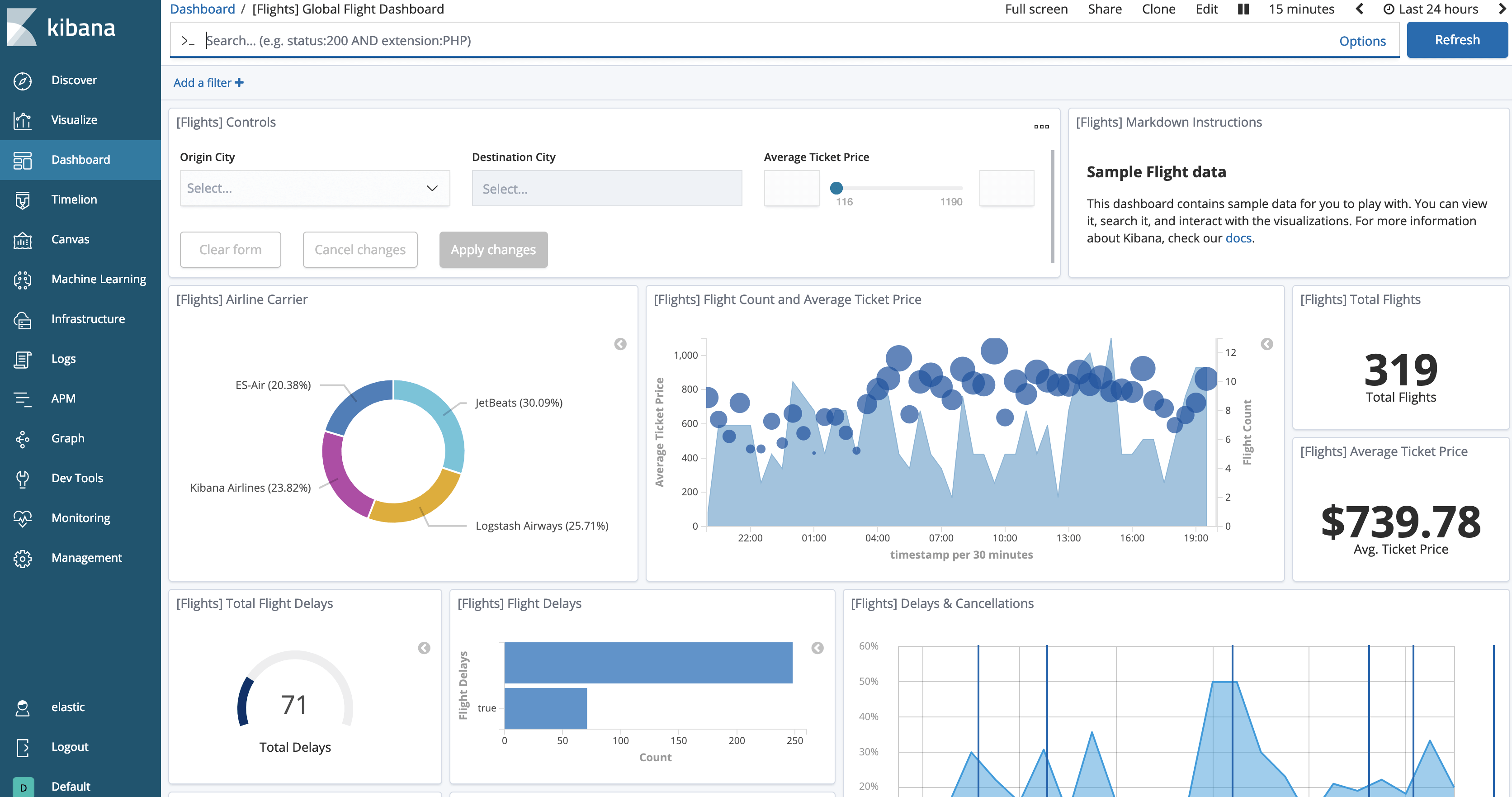
Anschließend können wir versuchen, den Index einzufrieren:
POST /kibana_sample_data_flights/_forcemerge?max_num_segments=1
POST /kibana_sample_data_flights/_freeze
Wenn wir zum Dashboard zurückkehren, scheinen die Daten verschwunden zu sein.
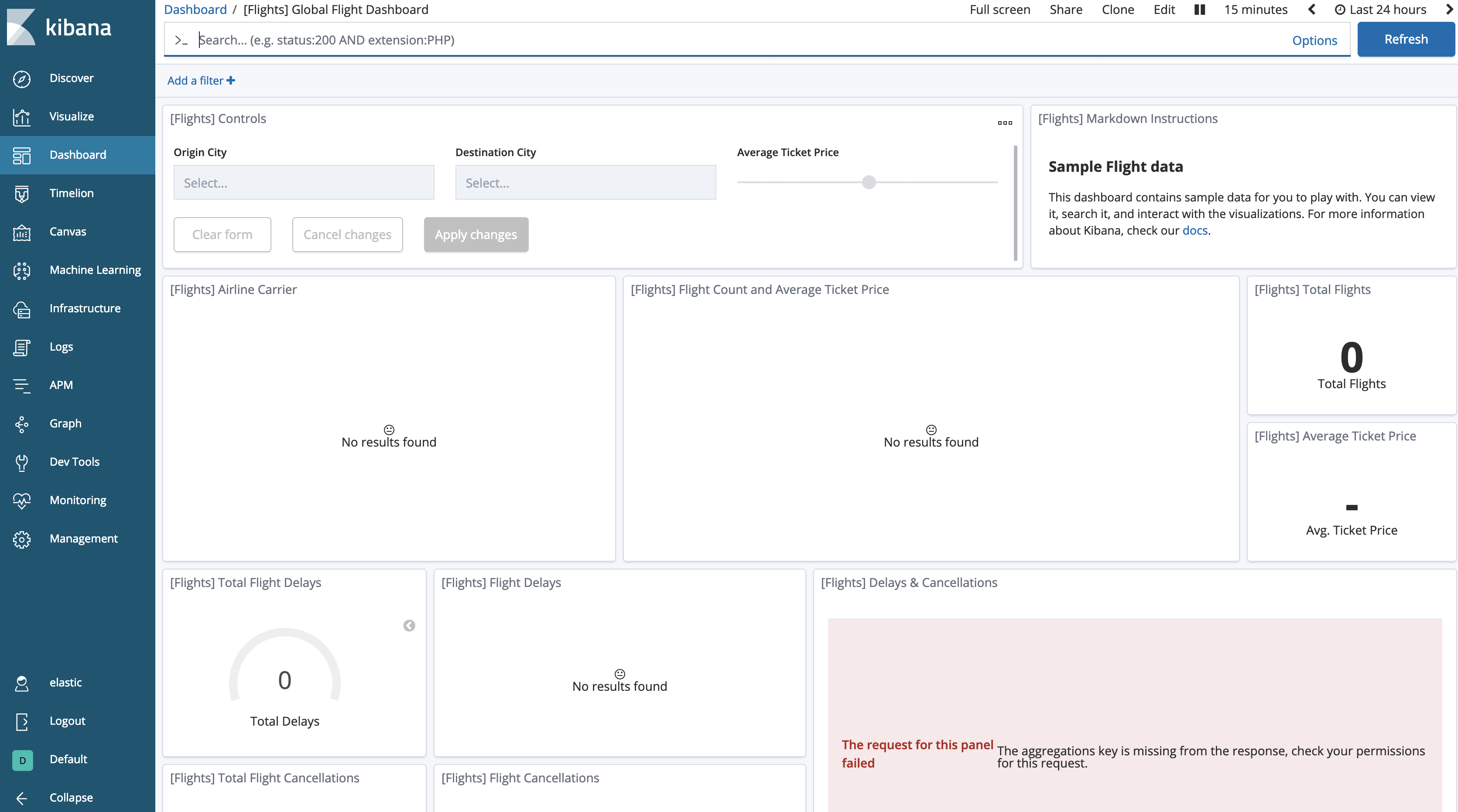
Wir müssen Kibana mitteilen, dass wir auch in eingefrorenen Indizes suchen möchten. Diese Option ist standardmäßig deaktiviert.
Navigieren Sie zu „Kibana Management“ (Kibana-Verwaltung) und wählen Sie „Advanced Settings“ (Erweiterte Einstellungen) aus. Im Bereich „Search“ (Suche) werden Sie feststellen, dass „Search in frozen indices“ (Suche in eingefrorenen Indizes) deaktiviert ist. Aktivieren Sie die Option und speichern Sie Ihre Änderungen.

Jetzt werden die Daten wieder im Flug-Dashboard angezeigt.
Fazit
Eingefrorene Indizes sind extrem hilfreich in Heiß-Warm-Architekturen. Sie ermöglichen kostengünstige Lösungen für eine längere Aufbewahrung, und die Daten bleiben online durchsuchbar. Ich empfehle, die Suchlatenz für Ihre Daten mit Ihrer vorhandenen Hardware zu testen, um die passende Größe und Suchlatenz für Ihre eingefrorenen Indizes zu ermitteln.
In der Elasticsearch-Dokumentation erfahren Sie mehr über die Freeze index API. Falls Sie Fragen haben, empfehlen wir Ihnen wie immer unsere Diskussionsforen. Viel Spaß beim Einfrieren!