Elasticsearch 6.5.0 Released
Today we are pleased to announce the release of Elasticsearch 6.5.0, based on Lucene 7.5.0. This is the latest stable release, and is already available for deployment via our Elasticsearch Service on Elastic Cloud.
Latest stable release in 6.x:
You can read about all the changes in the release notes linked above, but there are some big changes which are worth highlighting:
Cross-Cluster Replication
Elasticsearch is already great — and we’ve made continual improvements in dealing with automated replication, failover, and recovery of data within one cluster. However, multi-datacenter systems are a different beast. The high latencies, low bandwidth, and more frequent network partitions that are common when going across datacenters mean that traditional approaches within Elasticsearch of data replication would lead to a bad experience if they extended to WAN-like connections. Users have had to switch gears to go multi-datacenter by using an external queue to distribute the data to those datacenters or doing a periodic snapshot to a third party system in case you’ve needed to recover from a disaster. There are multiple ways to get data into multiple clusters across datacenters, but they each come with tradeoffs: from operational complexity to higher costs to significant delays for recovery.
Users have been asking to have a self-contained mechanism for replicating data across clusters. And if you’ve been keeping up with our releases, you might have heard of or noticed the addition of sequence numbers, starting in Elasticsearch 6.0 which was the first step in the direction of getting there. About 6 months ago, we made our next major stride in this effort by implementing soft-deletes. With 6.5, we’re really excited to announce we’re ready to release our first beta version of cross-cluster replication.
Cross-cluster replication is a Platinum-level feature for Elasticsearch in which in your local cluster you can create an index to follow an index in a remote cluster or automatically-follow indices in a remote cluster that match a pattern pattern. For information on how to set up cross-cluster replication, see the cross-cluster getting started documentation.
Minimal Snapshots
Snapshots are a great way to keep off-cluster backups. Snapshots are copies of your indices that can be taken incrementally. Those snapshots include everything you’d need to restore an index and make it searchable quickly, including the indices Elasticsearch uses to make search fast. Elastic provides official plugins to store (and retrieve/restore) those snapshots on Google Cloud Storage, S3, Azure, and Hadoop HDFS or you can snapshot to a shared filesystem on all the nodes like an NFS mount.
Existing snapshots are great for a lot of users, but sometimes disaster recovery windows are long enough that actually storing all the indices to make searches fast isn’t necessary and the cost of storing all of that information may be too high. With 6.5, we’re introducing a new source-only repository which you can use to make that trade-off. The idea of these source-only snapshots is that you store a minimal amount of information (namely, the _source and index metadata) so that the indices can be rebuilt through a reindex operation if necessary. The advantage can be very large: up to a 50% reduction in disk space of the snapshots. They will take longer to restore (in full) though, as you’ll need to do a reindex to make them searchable, so they aren’t for everyone. But if you have longer recovery windows and are space constrained, you may want to consider making use of this new feature.
SQL / ODBC
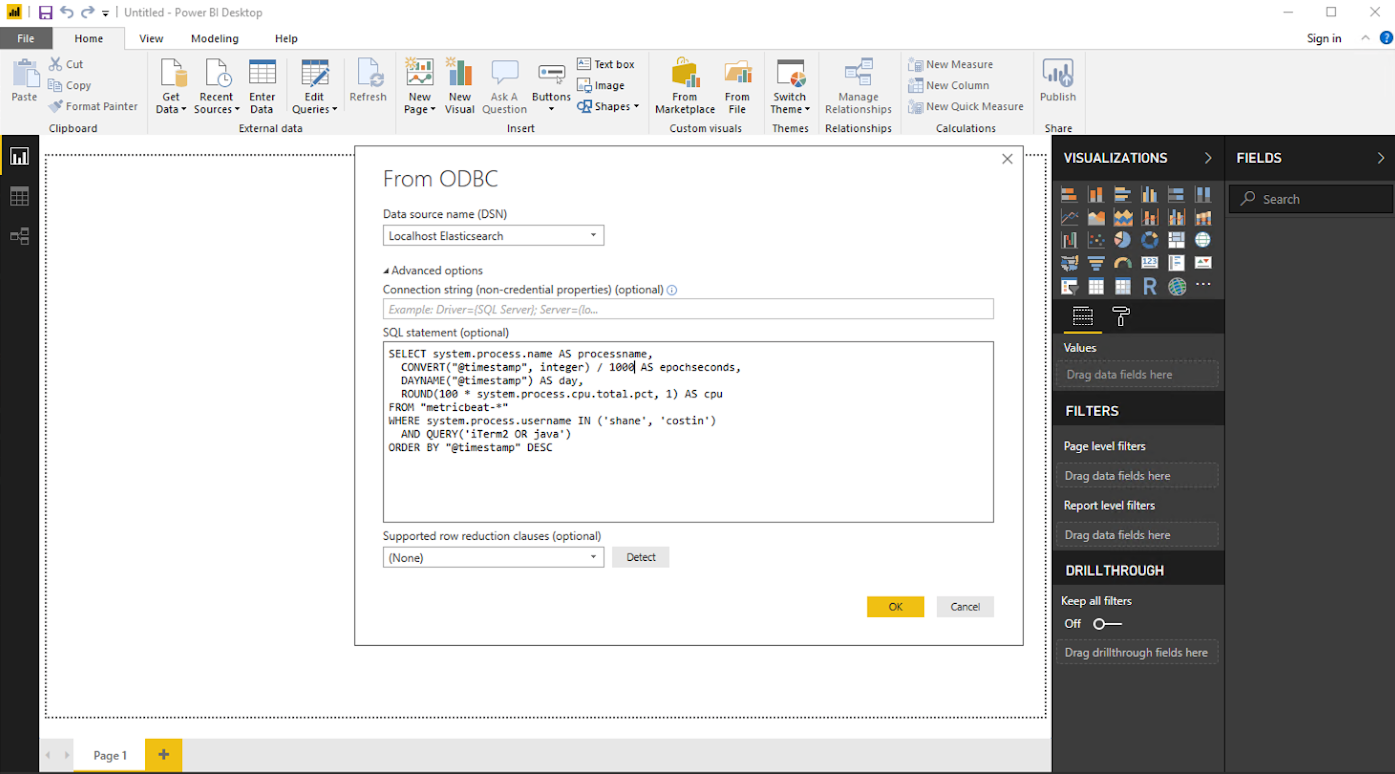
Exciting news on the SQL front! With 6.5, we’re releasing an initial (alpha status) ODBC driver for Elasticsearch, which you can find here. Our initial release is for Windows, as an MSI. This complements our existing JDBC driver, useful for java-y goodness. As ODBC is supported by many BI tools, you can now connect Elasticsearch to a lot of your favorite 3rd party tools (notably, many of your favorite BI tools), which gives you the speed, flexibility, and power of full-text search and relevance, all ready to go.
We also added quite a few functions and capabilities to our SQL capabilities. ROUND, TRUNCATE, IN, MONTHNAME, DAYNAME, QUARTER, CONVERT, and a number of string manipulation functions such as CONCAT, LEFT, RIGHT, REPEAT, POSITION, LOCATE, REPLACE, SUBSTRING, and INSERT are all new for us in 6.5.0. And you can now query across indices, with different mappings, as long as the mapping types are compatible. And we added support for Elasticsearch’s IP datatype in SQL. Here’s what you can do when you put all of this together:
SELECT system.process.name AS processname,
CONVERT("@timestamp",integer) AS epochmillis,
DAYNAME("@timestamp") AS day,
ROUND(100 * system.process.cpu.total.pct,1) AS cpu
FROM "metricbeat-*"
WHERE system.process.username IN ('shane','costin')
AND QUERY('iTerm2 OR java')
ORDER BY "@timestamp" DESC
And then you can put your query into a BI tool with ODBC and visualize it!
SQL via REST is a free feature while using ODBC or JDBC requires a Platinum-level subscription.
Speaking of visualizing data from SQL, hop on over to the Kibana 6.5 release blog for information on Canvas!
Search Use Cases
We’ve got several exciting new features specific to the search use case. First, we know that not everyone is a Java developer and writing (and maintaining) Java code shouldn’t be necessary for simple things. Simple things should be simple! One of those “simple things” is token filtering: making words (tokens) lowercase or upper case or stemming them, for example. While we’ve had a lot of out-of-the-box token filters, 6.5 introduces 2 new scriptable token filters. A new predicate token filter lets you remove tokens that don’t match a script — for example, “remove all the words that aren’t at least 5 letters long” can be done with a simple script. A new conditional token filter builds on the same idea of scriptable token filters but lets you apply other token filters that match a script — for example, “only lowercase the tokens that are less than 5 characters long.” These are really powerful ways to manipulate the data you’re indexing without ever having to write a Java plugin.
Elasticsearch 6.5 also brings a new text type, called annotated_text, to a new plugin we’re releasing. In many applications where natural language processing (NLP) is in play, it’s common to want to tag, or annotate, the text you’re using. For example, you may use named-entity recognition to identify where a company, person, or place is in text. This new annotated_text type allows you to use markdown-like syntax to then link those entities. Have a look at our data modelling tips if you want to get the most out of this new plugin.
JDK 11 & G1GC
The Java ecosystem has been rapidly evolving, with Java 9, 10, and 11 all being released in the past 15 months. Java 9 and 10 were short-term releases that have already hit end of support, but Java 11 is the new long-term support release. Starting with Elasticsearch 6.5, we’re now supporting JDK 11.
Java 9 also deprecated the Concurrent Mark Sweep (CMS) garbage collector, in favor of G1. In earlier JDK versions, we found G1 bugs in the types of workloads Elasticsearch places on the garbage collector. However, after an immense amount of testing on G1, Elasticsearch is now committed to supporting the G1 garbage collector on JDK 10+. We do want to take this opportunity to remind our users: large heaps are a source of trouble and should be avoided.
Security and Audit Logging
Elasticsearch 6.5 brings several exciting security features. First on the list is authorization realms. Authorization realms allow an authenticating realm to delegate the task of pulling the user information (with the user name, the user’s roles, etc) to one or more other realms. For example, a client could authenticate using PKI, but then delegate to an LDAP realm for the user information. For information on how to use this platinum-level feature, check out the documentation.
The next security-related feature is structured security audit logging. Prior to 6.5, security audit logging had a non-standard text log format where the entry was a mixture of a few positional attributes followed by named attributes (in a key=[value] form). With 6.5, we’re introducing a new, completely structured format, where all attributes are named. Specifically, each log entry is a one line JSON document and each one is printed on a separate line. The best news is that attributes are ordered, just like in any other normal log entry (but unlike an ordinary JSON). This way, the file is human friendly and machine parsable simultaneously. The previous format will work alongside the new one, each under a separate file namespace, for the entire 6.x series. The old format will be removed in Elasticsearch 7.0.
Machine Learning
A multi-metric machine learning job is one that analyzes multiple time series together. Anomaly scoring for multi-metric jobs has been updated so that the scores for each time-series are now less affected by the behavior of other time series in the job. This brings a significant change to the individual results for each partitioned time series, making them similar to having been run as a single metric machine learning job, while the overall anomaly score remains a top level and rate limited view of the job as a whole.
In version 6.5, we also introduce multi-bucket analysis for machine learning jobs, where features from multiple contiguous buckets are used for anomaly detection. The final anomaly score is a combination of values from both the “standard” single-bucket analysis and the new multi-bucket analysis.
Also new in 6.5, an experimental find file structure API aims to help you discover the structure of a text file. It attempts to read the file and if successful, will return statistics about the most common values of the detected fields and mappings that you can use when you ingest the file into Elasticsearch. This API is also used by the new File Data Visualizer in Kibana.
Conclusion
Please download Elasticsearch 6.5.0, try it out, and let us know what you think on Twitter (@elastic) or in our forum. You can report any problems on the GitHub issues page.