Migração do Elastic Common Schema (ECS) em ambientes do Beats
Em fevereiro de 2019, apresentamos o Elastic Common Schema (ECS) com uma postagem de blog e um webinar relacionados. Só para recapitular um pouco: definindo um conjunto comum de campos e tipos de dados, o ECS permite a busca, visualização e análise uniformes de fontes de dados distintas. Essa é uma enorme vantagem para ambientes heterogêneos compostos por padrões de fornecedor diversos em que é frequente o uso simultâneo de fontes de dados semelhantes porém diferentes.
Também falamos sobre em que medida a implementação do ECS não é uma tarefa banal. O fato é que, para produzir eventos compatíveis com o ECS, muitos dos campos emitidos pelas fontes de eventos devem ser copiados ou renomeados durante o processo de ingestão de dados.
Encerramos nossa apresentação ao ECS mencionando que, se você já configurou um modelo de índice do Elasticsearch e escreveu algumas funções transform com o Logstash ou os pipelines de ingestão do Elasticsearch, já tem uma noção de como é. Dependendo de como foram projetados os pipelines de ingestão de dados do Elastic Stack, a quantidade de trabalho necessário para migrar seu ambiente para o ECS vai variar. Em uma extremidade do espectro, o Beats e os os módulos do Beats permitirão uma migração selecionada para o ECS. Os eventos do Beats 7 já estão no formato do ECS, e o único trabalho remanescente é a interação entre o conteúdo de análise existente e os novos dados do ECS. Na outra extremidade do espectro estão todas as formas de pipelines personalizados que foram desenvolvidos pelos usuários.
Em junho, também hospedamos um webinar que tratava de como migrar para o ECS. Esta postagem de blog se desenvolve a partir da discussão que tivemos nesse webinar e analisa em mais detalhes a migração para o ECS em ambientes do Beats. A migração de pipelines de ingestão de dados personalizados para o ECS será tratada em uma futura postagem de blog.
A seguir estão uma visão geral do conteúdo tratado nesta postagem de blog:
- Migração para o ECS com o Elastic Stack 7
- Visão geral conceitual de uma migração para o ECS
- Visão geral da migração de um ambiente do Beats para o ECS
- Desenvolva sua própria estratégia de migração
- Exemplo de migração
- Conclusão
- Referências
Migração para o ECS com o Elastic Stack 7
Percebemos que a alteração dos nomes de muitos campos de eventos usados pelo Beats seria uma grande ruptura para os usuários, por isso introduzimos os nomes de campos do ECS em nossa versão principal mais recente, o Elastic Stack versão 7.
Esta postagem começa com uma visão geral sofisticada de como migrar para o ECS com o Beats no contexto de uma atualização do Elastic Stack 6.8 para o Elastic Stack 7.2. Depois seguiremos com um exemplo de migração passo a passo de uma fonte de eventos do Beats.
É importante observar que esta postagem de blog tratará somente de uma parte de uma migração para a versão 7. Como sugerem nossas diretrizes de atualização do stack, o Beats deve ser atualizado depois do Elasticsearch e do Kibana. Sendo assim, o exemplo de migração nesta postagem de blog tratará somente da atualização do Beats e pressuporá que o Elasticsearch e o Kibana já foram atualizados para a versão 7. Isso permitirá termos foco nos aspectos específicos de atualizar o Beats do esquema pré-ECS para o ECS.
Ao planejar sua migração do Elastic Stack 7, verifique se revisou as diretrizes mencionadas anteriormente, analise o assistente de atualização do Kibana e evidentemente examine com cuidado as notas de atualização e as alterações importantes para qualquer parte do stack que está usando.
Observação: se você estiver avaliando se adota o Beats e não dispuser de dados do Beats 6, não precisará se preocupar com a migração. Basta começar a usar o Beats versão 7.0 ou posterior, que produz eventos formatados pelo ECS imediatamente.
Visão geral conceitual de uma migração para o ECS
Qualquer migração para o ECS envolverá as seguintes etapas:
- Converter suas fontes de dados no ECS
- Resolver diferenças e conflitos entre o formato de evento pré-ECS e os eventos do ECS
- Ajustar conteúdo de análise, pipelines e aplicativos para que consumam eventos do ECS
- Tornar os eventos pré-ECS compatíveis com o ECS para suavizar a transição
- Remover aliases de campo depois que todas as fontes tiverem sido migradas para o ECS
Nesta postagem de blog, vamos tratar de cada uma dessas etapas especificamente no contexto da migração de um ambiente do Beats para o ECS.
Depois da visão geral a seguir, vamos mostrar um exemplo passo a passo de atualização de um módulo do Filebeat da versão 6.8 para a 7.2. Esse exemplo de migração foi projetado para facilitar as suas tarefas de acompanhar sua estação de trabalho, executar cada parte da migração e experimentar durante o processo.
Visão geral da migração de um ambiente do Beats para o ECS
Existem muitas maneiras de abordar cada parte da migração descrita anteriormente. Vamos estudar cada parte no contexto da migração de eventos do Beats para o ECS.
Converter fontes de dados no ECS
O Beats fornece muitas fontes de evento selecionadas. A partir da versão Beats 7.0, cada uma delas já foi convertida no formato do ECS para você. Os processadores do Beats que adicionam metadados aos seus eventos (como add_host_metadata) também estão convertidos no ECS.
Entretanto, é importante entender que o Beats às vezes atua como um simples meio de transporte para seus eventos. Exemplos disso são os eventos coletados pelo Winlogbeat e pelo Journalbeat, além de quaisquer entradas do Filebeat pelas quais você consome logs e eventos personalizados (além dos próprios módulos do Filebeat). Você precisará mapear por conta própria para o ECS cada fonte de evento personalizada que esteja coletando e analisando no momento.
Resolver diferenças e conflitos de esquema
A natureza dessa migração para o ECS é padronizar nomes de campo entre muitas fontes de dados. Isso significa que muitos campos estão sendo renomeados.
Renomeações de campo e aliases de campo
Existem algumas maneiras de trabalhar com eventos pré-ECS e do ECS durante a transição entre os dois formatos. Estas são as principais opções:
- Usar aliases de campo do Elasticsearch para que os novos índices reconheçam os nomes de campo antigos.
- Duplicar dados no mesmo evento (populando tanto campos antigos quanto campos do ECS).
- Não fazer nada: o conteúdo antigo trabalha somente em dados antigos, enquanto o conteúdo novo trabalha somente em dados novos.
A abordagem mais simples e econômica é usar os aliases de campo do Elasticsearc. Esse é o processo de migração que foi adotado para o procedimento de atualização do Beats.
Entretanto, os aliases de campo apresentam algumas limitações e não são uma solução perfeita. Vamos discutir suas vantagens e também suas limitações.
Os aliases de campo são simplesmente campos adicionais no mapeamento de novos índices do Elasticsearch. Eles permitem que os novos índices respondam às consultas usando os antigos nomes de campo. Vamos analisar um exemplo simplificado para exibir somente um campo:
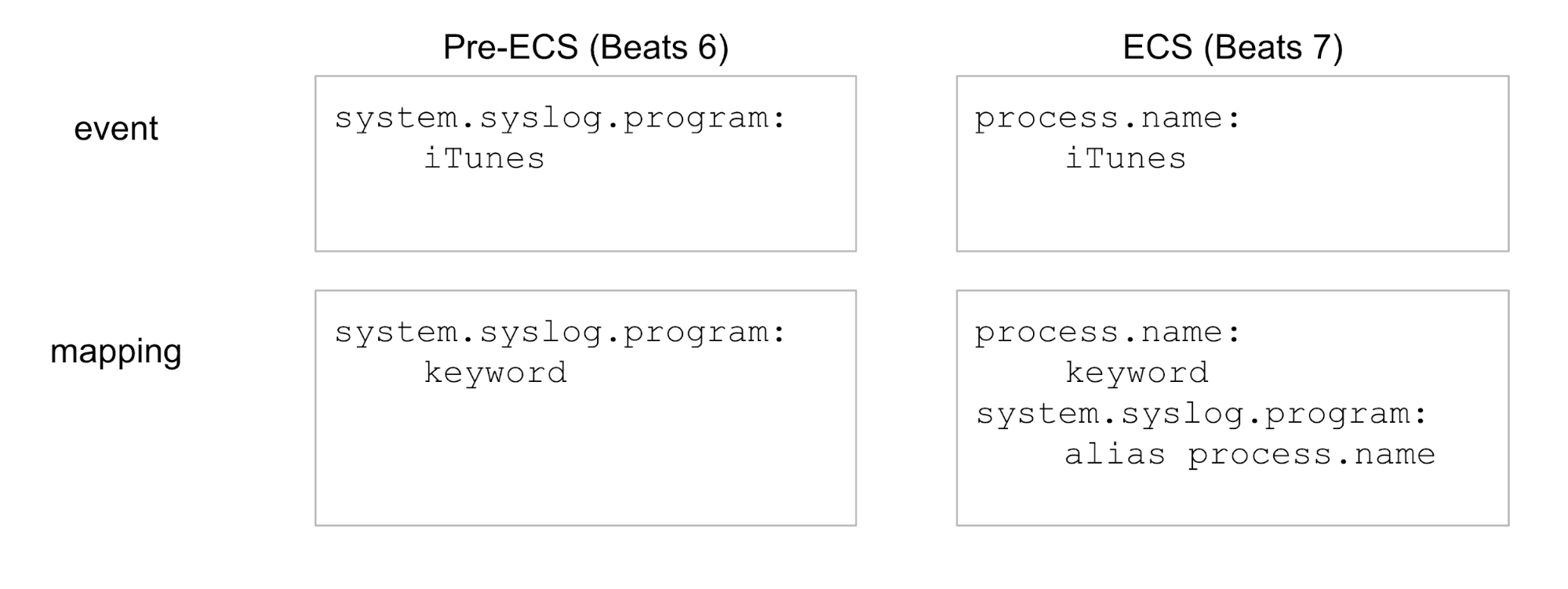
Mais precisamente, os aliases de campo são úteis em:
- Agregações e visualizações no campo do alias.
- Filtragem e busca no campo do alias.
- Recurso de autocompletar no campo do alias.
A seguir estão as ressalvas quanto aos aliases de campo:
- Os aliases de campo são puramente um recurso dos mapeamentos do Elasticsearch (o índice de busca). Dessa maneira, eles não modificam a fonte do documento ou seus respectivos nomes de campo. O documento consiste nos nomes de campo antigos ou nos novos. Para ilustrar, mostramos algumas situações em que os aliases não são úteis, porque os campos são acessados diretamente no documento:
- Colunas exibidas em buscas salvas.
- Processamento adicional em seu pipeline de ingestão de dados.
- Qualquer aplicativo que consuma seus eventos do Beats (por exemplo: via API do Elasticsearch).
- Como os aliases de campo são entradas de campo em si, não podemos criar aliases quando há um novo campo do ECS do mesmo nome.
- Os aliases de campo só funcionam com campos leaf — não é possível aplicar aliases em campos complexos como campos
object, que contêm outros campos aninhados.
Esses aliases de campo não são criados por padrão nos seus índices do Beats 7. Eles devem ser habilitados configurando migration.6_to_7.enabled: true em cada arquivo de configuração YAML do Beat antes de executar a etapa de instalação do Beats. Essa opção e os respectivos aliases estarão disponíveis durante a vida útil do Elastic Stack 7.x e serão removidos na versão 8.0.
Conflitos
Ao migrar para o ECS, você também pode encontrar conflitos de campo, dependendo de quais fontes esteja usando.
É importante observar que alguns tipos de conflitos são detectados somente para campos que você realmente esteja usando. Isso significa que quaisquer alterações ou conflitos nas fontes que você não esteja usando não o afetarão. Mas isso também significa que, ao planejar a migração, você deve fazer ingestão de amostras de evento de cada uma das fontes de dados em ambos os formatos (do Beats 6 e do 7) em seu ambiente de teste para desvendar todos os conflitos que precisará abordar.
Os conflitos são de dois tipos:
- Um tipo de dados de campo está mudando para um tipo mais apropriado.
- Um nome de campo sendo usado antes do ECS também está definido no ECS, mas tem um significado diferente; vamos chamá-los de campos incompatíveis.
As consequências exatas de cada tipo de conflito variam. Mas em geral, quando um campo está mudando o tipo de dados ou se um campo incompatível também está mudando com relação ao aninhamento (por exemplo: campo de palavra-chave virando um campo de objeto), você não poderá consultar o campo nas fontes pré-ECS e do ECS simultaneamente.
Com os dados entrando nos índices do Beats 6 e 7, a atualização dos padrões de índice do Kibana revelará esses conflitos. Se depois de atualizar o padrão de índice você não vir um aviso de conflito, isso significará que não há conflitos a resolver. Se um aviso for exibido, você poderá definir o seletor de tipo de dados para que exiba somente os conflitos:

A maneira de lidar com esses conflitos será reindexar os dados antigos para torná-los mais compatíveis com o novo esquema. Os conflitos causados por mudanças de tipo são bastante simples de resolver. Basta substituir os padrões de índice do Beats 6 para que usem o tipo de dados mais adequado, reindexar para um novo índice (para o mapeamento atualizado entrar em vigor) e excluir o índice antigo.
Se você tiver campos incompatíveis, terá de decidir se vai excluí-los ou renomeá-los. Se você renomear o campo, verifique se o definiu primeiro no padrão de índice.
Ajustar o ambiente para que consuma eventos do ECS
Com tantos nomes de campo mudando, a amostra de conteúdo de análise (por exemplo: painéis) fornecida com o Beats foi toda modificada para que use os novos nomes de campo do ECS. O novo conteúdo funcionará somente nos dados do ECS produzidos pelo Beats 7.0 e versões posteriores. Considerando esse fato, a instalação do Beats não substituirá o conteúdo existente do Beats 6, mas sim criará uma segunda cópia de cada visualização do Kibana. Cada nova visualização do Kibana tem o mesmo nome de antes, com “ECS” adicionado ao final.
A amostra de conteúdo do Beats 6 e o conteúdo personalizado baseado nesse esquema antigo em sua maior parte continuará trabalhando em dados do Beats 6 e 7 graças aos aliases de campo. Como discutimos anteriormente, porém, os aliases de campo são apenas uma solução parcial e provisória para ajudar na migração para o ECS. Portanto, parte da migração também deve incluir a atualização ou duplicação dos painéis personalizados para começar a usar os novos nomes de campo.
Vamos ilustrar isso com uma tabela:
|
Pré-ECS (Beats 6, seus painéis personalizados) |
ECS (Beats 7) |
| [Filebeat System] Syslog dashboard | [Filebeat System] Syslog dashboard ECS |
|
|
Além de revisar e modificar conteúdo de análise no Kibana, você também precisará revisar qualquer parte personalizada do pipeline do evento, além dos aplicativos que acessam eventos do Beats via API do Elasticsearch.
Tornar eventos pré-ECS compatíveis com o ECS
Já discutimos o uso da reindexação para abordar conflitos de tipo de dados e campos incompatíveis. A reindexação para abordar esses dois tipos de mudanças é opcional, mas bem simples de implementar e possivelmente útil na maioria dos casos. Ignorar os conflitos pode ser uma solução viável também para casos de uso simples, mas esteja ciente de que potenciais conflitos de campo afetarão você a partir do momento em que você começar a fazer a ingestão de dados do Beats 7 até o momento em que o Beats 6 perder a validade no cluster.
Reindexação
Se o suporte oferecido pelos aliases de campo não for suficiente para sua situação, você também poderá reindexar os dados antigos para preencher nomes de campo do ECS em seus dados do Beats 6. Isso garante que todo novo conteúdo de análise que dependa dos campos do ECS (o novo conteúdo do Beats 7 e o seu conteúdo personalizado atualizado) possam consultar seus dados antigos além dos dados do Beats 7.
Modificação de eventos durante a ingestão de dados
Se você espera um longo período de implantação para os agentes do Beats 7, pode ir além de simplesmente reindexar índices antigos. Também pode modificar os eventos de entrada do Beats 6 durante a ingestão de dados.
Há algumas maneiras de reindexar e executar manipulações de documentos, como copiar, excluir ou renomear campos. O método mais simples de fazer isso é usar os pipelines de ingestão do Elasticsearch. A seguir estão algumas vantagens:
- São fáceis de testar com a API _simulate
- Os pipelines permitem reindexar índices antigos.
- Os pipelines permitem modificar eventos do Beats 6 que ainda estão entrando.
Para modificar os eventos à medida que estão entrando, na maioria dos casos basta configurar a configuração “pipeline” da saída do Elasticsearch para que envie ao seu pipeline. Isso vale para o Logstash e o Beats.
Observe que os módulos do Filebeat já usam pipelines de ingestão para executar análise. É possível modificar eles também, e para isso basta substituir os pipelines do Filebeat 6 e adicionar uma chamada ao pipeline de ajuste.
Remover aliases de campo
Depois que você não precisar mais dos aliases de campo, avalie a remoção deles. Já mencionamos que eles são mais leves do que duplicar todos os dados. Entretanto, ainda assim consomem memória no estado do cluster — um recurso crucial. Também aparecem no recurso de autocompletar do Kibana, sobrecarregando tudo desnecessariamente.
Para remover os aliases de campo antigos, basta remover (ou definir como false) a configuração migration.6_to_7.enabled no Beats (por exemplo, filebeat.yml), executar a operação "setup" outra vez e substituir o modelo.
Observe que, depois que os modelos forem substituídos para não mais incluírem aliases, você ainda terá de esperar os índices passarem por rollover antes que seus mapeamentos de índice parem de conter os aliases. Depois que os índices tiverem passado por rollover, você precisará esperar os dados do Beats 7 que continham os aliases passarem da validade no cluster antes de serem eliminados completamente.
Desenvolva sua própria estratégia de migração
Revisamos o que o Beats fornece para ajudar com a migração dos dados do Beats para o ECS. Também discutimos etapas adicionais que você pode executar para tornar sua migração mais perfeita.
Você deve avaliar o trabalho necessário para cada uma das suas fontes de dados de maneira independente. Talvez esteja disponível a opção de fazer menos para as fontes de dados menos cruciais.
A seguir estão alguns critérios que podem ser avaliados ao analisar cada fonte de dados:
- Qual é seu período de retenção? Ele é ordenado externamente? Você tem a opção de disponibilizar os dados prematuramente durante essa migração?
- Você exige continuidade nos dados? Ou pode ter um cutover? Isso vai ajudar a informar se você precisa fazer backfill, conforme descrito anteriormente.
- Quanto tempo levará a implantação do Beats 7? Você precisa modificar os eventos do Beats 6 à medida que entram?
Se você pretende fazer backfill em muitos campos, deve analisar dev-tools/ecs-migration.yml no repositório do Beats. Esse arquivo lista todas as alterações de campo para a migração do Beats 6 para a versão 7.
Exemplo de migração
No lembrete desta postagem de blog, vamos mostrar passo a passo como migrar para o ECS atualizando um Beat da versão 6.8 para a 7.2, como os aliases ajudam e suas limitações, como resolver conflitos, como reindexar dados antigos recentes para ajudar com a transição e também como modificar eventos do Beats 6 que ainda estão entrando. Neste exemplo, usaremos o módulo Syslog do Filebeat.
Como já mencionamos, este exemplo não tratará de uma atualização completa do Elastic Stack. Vamos pressupor que o Elasticsearch e o Kibana já estão atualizados para a versão 7, e assim poderemos nos concentrar em como trabalhar com a atualização do esquema de dados para o ECS.
Se quiser acompanhar, use a versão mais recente do Elasticsearch 7 e do Kibana 7. Você pode usar uma conta de avaliação grátis do Elastic Cloud ou executá-las localmente seguindo as instruções de instalação para o Elasticsearch e o Kibana.
Execução do Beats 6.8
Nesta demonstração, vamos executar o Filebeat 6.8 e o 7.2 simultaneamente no mesmo computador. Portanto, é importante instalar ambas as versões com uma instalação de arquivo (usando .zip ou .tar.gz). As instalações de arquivo são autocontidas no respectivo diretório e facilitarão o processo.
Com o Elasticsearch e o Kibana 7 em execução, instale o Filebeat 6.8. Se você estiver usando o Windows, também terá a opção de experimentar instalando o Winlogbeat.
Na maioria dos sistemas, o Syslog usa o horário local para os carimbos de data e hora sem especificar o fuso horário. Vamos configurar o Filebeat para que adicione o fuso horário a cada evento por meio do processador add_locale, depois vamos configurar o pipeline do módulo do sistema para que interprete o carimbo de data e hora adequadamente. Isso garantirá que possamos validar nossa migração do ECS posteriormente ao analisarmos os eventos recebidos recentemente.
No arquivo filebeat.yml, localize a seção “processors” e adicione o processador add_locale. Abaixo da seção processors, adicione a seguinte configuração de módulo:
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_locale: ~
filebeat.modules:
- module: system
syslog:
var.convert_timezone: true
Se você estiver executando o Elasticsearch e o Kibana localmente, o código anterior deverá ser suficiente. Se estiver usando o Elastic Cloud, você também precisará adicionar suas credenciais de nuvem ao arquivo filebeat.yml — ambas podem ser encontradas no Elastic Cloud ao criar um cluster:
cloud.id: 'my-cluster-name:a-very-long-string....' cloud.auth: 'username:password'
Agora vamos preparar o Filebeat 6.8 para capturar logs de sistema:
./filebeat setup -e ./filebeat -e
Vamos confirmar se os dados estão entrando analisando o painel chamado [Filebeat System] Syslog dashboard. Devemos ver os eventos do Syslog mais recentes gerados no sistema no qual o filebeat estava instalado.
Esse painel é interessante porque ele inclui visualizações e uma busca salva. Isso será útil ao demonstrar o que os aliases de campo podem e o que não podem fazer por nós.
Execução do Beats 7 (ECS)
Vamos encarar os fatos: nem todos os ambientes permitem executar um cutover instantâneo de uma versão do Beats para outra. Os eventos provavelmente entrarão vindos do Filebeat 6 e 7 simultaneamente por um período de tempo. Assim vamos fazer exatamente o mesmo neste exemplo.
Para fazer isso, bastará executar o Filebeat 7.2 paralelamente à versão 6.8 no mesmo sistema. Vamos extrair o Filebeat 7.2 em um diretório diferente e aplicar as mesmas alterações de configuração que aplicamos na versão 6.8.
Mas não execute a instalação ainda! Para o Beats 7, também precisamos habilitar a configuração de migração, que cria aliases de campo. Retorne ao código-fonte o comentário desta linha ao final do arquivo filebeat.yml:
migration.6_to_7.enabled: true
Nosso arquivo de configuração da versão 7.2 agora deve conter este atributo de migração adicional, o processador add_locale, a configuração para o módulo do sistema e, se necessário, nossas credenciais de nuvem.
Vamos preparar o Filebeat 7.2 a partir de um terminal diferente:
./filebeat setup -e ./filebeat -e
Conflitos
Antes de analisar os painéis, vamos diretamente ao gerenciamento de índices do Kibana para confirmar se o novo índice foi criado e se os dados estão entrando. Você deverá ver algo assim:
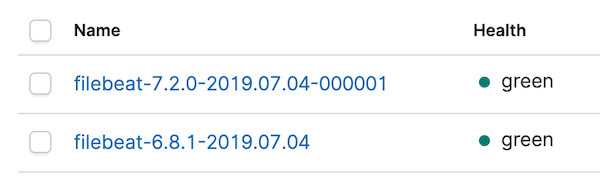
Vamos também acessar os padrões de índice e atualizar o padrão de índice filebeat-*. Com o padrão de índice atualizado para os dados das versões 6.8 e 7.2, deverá haver alguns conflitos. Podemos nos concentrar nos conflitos alterando o seletor de tipo de dados à direita de All field types para conflict:
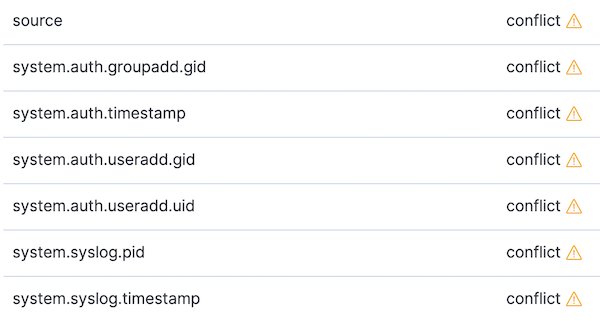
Vamos analisar dois dos conflitos anteriores e como eles podem ser resolvidos.
Primeiro, vamos examinar um conflito específico de syslog: system.syslog.pid. Acessando a página de gerenciamento de índices e analisando o mapeamento para a versão 6.8, podemos ver que o campo está indexado como keyword. Se analisarmos o mapeamento de índices da versão 7.2, poderemos ver que system.syslog.pid é um alias para process.pid. Isso não tem problema; não é a causa do conflito. Entretanto, seguindo o alias e analisando o tipo de dados para process.pid, podemos ver que o tipo de dados agora é long. A mudança de keyword para long ocasionou nosso conflito de tipo de dados.
Segundo, vamos analisar um conflito ocasionado por um campo incompatível. Esse conflito será comum a todas as migrações do Filebeat: o campo source. No Filebeat 6, source é um campo keyword que normalmente contém um caminho de arquivo (ou às vezes um endereço de fonte de syslog). Nos mapeamentos de campo do ECS e portanto do Filebeat 7, source vira um objeto com campos aninhados usados para descrever a fonte de um evento de rede (source.ip, source.port etc.). Como um campo chamado source ainda existe no Beats 7, não podemos criar um campo de alias nele.
Identificamos dois campos em que podemos trabalhar como parte de nosso procedimento de migração. Vamos voltar a eles logo mais.
Aliases
Vamos manter aberto o nosso [Filebeat System] Syslog dashboard do Beats 6. Como o padrão de índices filebeat-* foi alterado desde a primeira vez em que carregamos esse painel, vamos fazer um recarregamento de página completo com as teclas Command-R ou F5.
Em uma nova guia, vamos abrir o novo painel [Filebeat System] Syslog dashboard ECS.
Olhando a busca salva na parte inferior do painel da versão 6.8, podemos ver lacunas nos dados. Alguns eventos têm valores para system.syslog.program e system.syslog.message, enquanto outros não têm. Abrindo eles com valores vazios, podemos ver que são os mesmos eventos do Syslog sendo escolhidos pela versão 7.2, mas com nomes de campo diferentes. Observando o mesmo período na guia com o painel do ECS, podemos ver o mesmo comportamento invertido. Os campos do ECS process.name e message estão preenchidos para os eventos da versão 7.2, mas não para os eventos da versão 6.8.
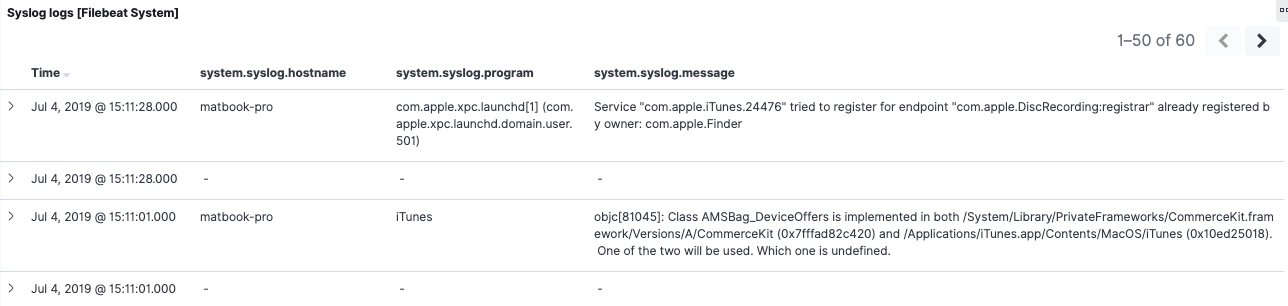
Esse é um exemplo concreto de como os aliases de campo não são úteis. As buscas salvas dependem do conteúdo do documento — e não do mapeamento de índices. Como já mencionamos na visão geral, se você precisar de continuidade, a reindexação para backfill (e alteração de eventos à medida que chegam) resolverá essa questão. Faremos isso em breve.
Agora vamos ver em que os aliases de campo são úteis. Analise o gráfico de rosca no painel da versão 6.8 e passe o mouse sobre o anel externo, que exibe os valores para system.syslog.program:
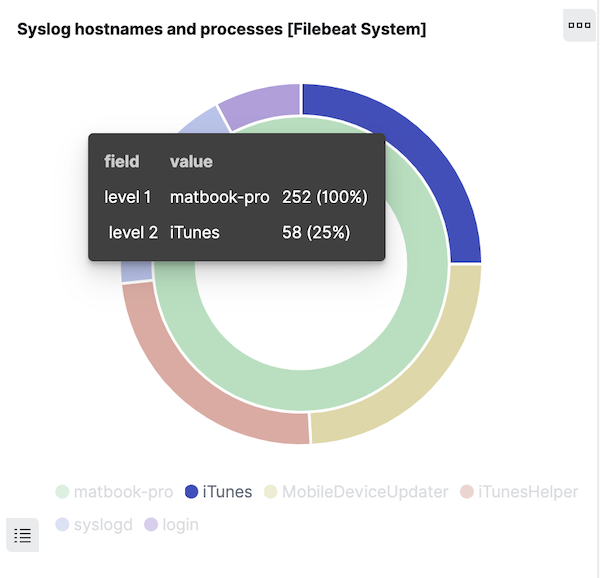
Clique em uma seção do anel para filtrar as mensagens geradas por um programa. Vamos apenas selecionar o filtro no nome do programa:
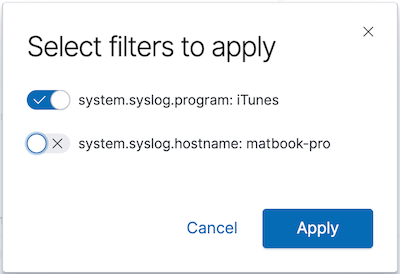
Acabamos de adicionar um filtro em um campo que não está mais presente na versão 7.2 — system.syslog.program. Entretanto, ainda podemos ver ambos os conjuntos de mensagens na busca salva:
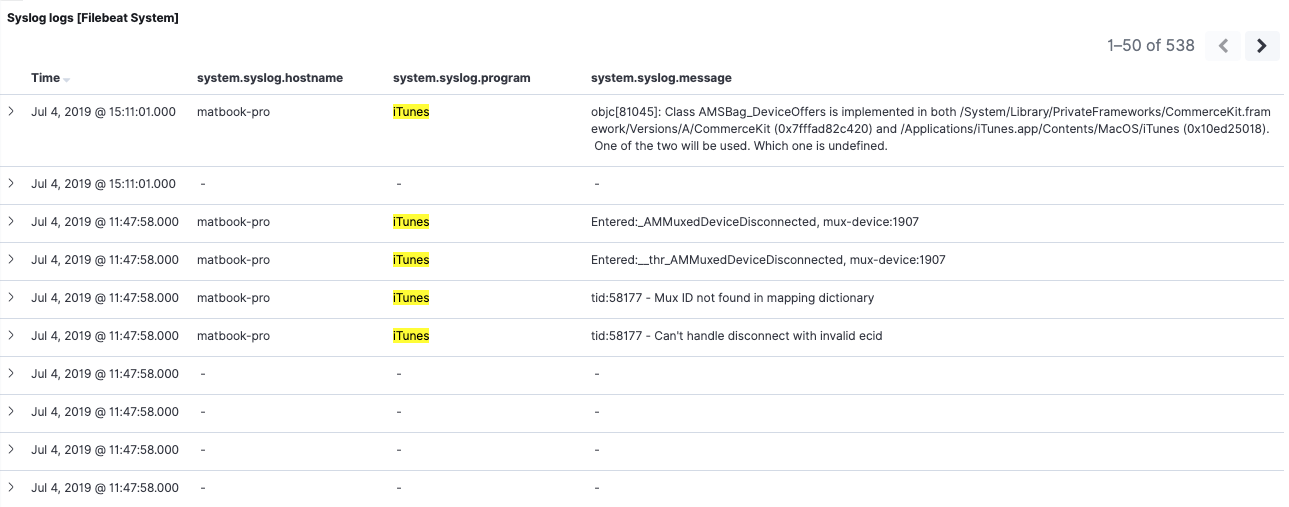
Se inspecionarmos os elementos da versão 7.2, poderemos ver que o filtro foi aplicado com êxito a eles também. Isso confirma que o nosso filtro emsystem.syslog.program funciona com os dados da versão 7.2, graças ao alias de system.syslog.program.
Observe que a visualização — respaldada por uma agregação do Elasticsearch — também está exibindo corretamente os resultados para as versões 6.8 e 7.2 no campo de system.syslog.program migrado.
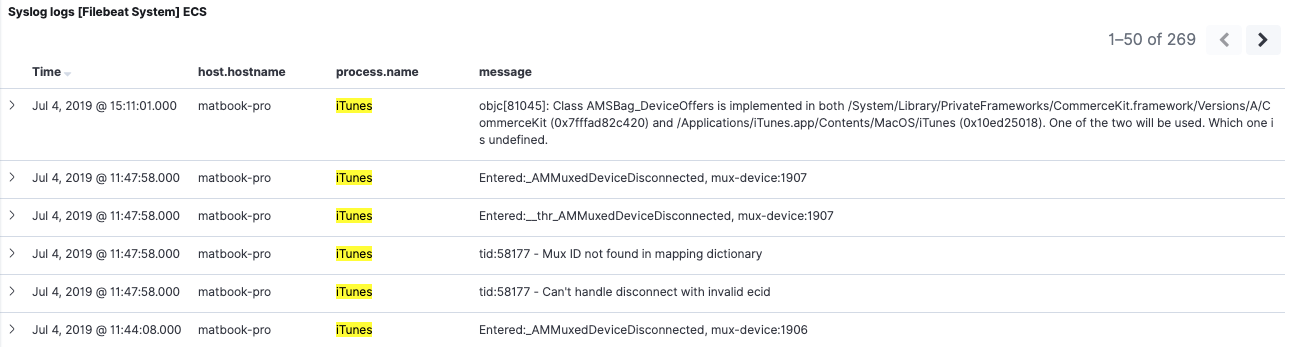
Voltando ao painel da versão 7.2, sem filtros ativos, podemos ver os dados das versões 6.8 e 7.2. Entretanto, se aplicarmos o mesmo filtro que aplicamos na versão 6.8, veremos um comportamento diferente. A filtragem de process.name:iTunes agora só retorna eventos da versão 7.2. O motivo disso é que os índices da versão 6.8 não têm um campo chamado process.name, nem um alias desse nome.
Reindexação para uma migração tranquila
Discutimos como a reindexação pode ajudar a tratar de três aspectos diferentes da migração: resolver conflitos de tipos de dados, resolver campos incompatíveis e fazer backfill de campos do ECS para preservar a continuidade. Agora vamos ver um exemplo de cada.
É assim que modificaremos os dados do Beats 6:
- Conflito de tipo de dados: altere o tipo de dados referente a system.syslog.pid de keyword para long
- Campo incompatível: Exclua o campo source do Filebeat depois de copiar seu conteúdo para log.file.path. Isso eliminará o conflito com o conjunto de campos de fonte do ECS. Observe que as versões Beats 6.6 e superiores já populam log.file.path com o mesmo valor… mas esse não é o caso para as versões anteriores do Beats 6, por isso vamos copiá-lo sob algumas condições.
- Faça backfill do campo do ECS process.name com o valor de system.syslog.process.
É assim que faremos essas alterações:
- Vamos modificar o modelo de índices do Filebeat 6.8 para que use os novos tipos de dados e adicionar e remover as definições de campo.
- Vamos criar um novo pipeline de ingestão que modifica os eventos da versão 6.8 removendo ou copiando campos.
- Vamos testar o pipeline com a API _simulate.
- Vamos usar o pipeline para reindexar dados antigos.
- Também incluiremos uma chamada a esse novo pipeline ao final do pipeline de ingestão do Filebeat 6.8 para modificar os eventos à medida que entram.
Alterações no modelo de índice
As melhorias no tipo de dados precisam ser feitas no modelo de índice e entrarão em vigor quando o índice passar por rollover. Por padrão, o rollover ocorre no dia seguinte. Se estiver usando o Index Lifecycle Management (ILM) na versão 6.8, você poderá forçar um rollover com a API de rollover.
Exiba o modelo de índice atual com o Kibana Dev Tools:
GET _template/filebeat-6.8.1
Os modelos de índice não podem ser modificados — eles precisam ser substituídos completamente (documentação). Prepare uma chamada à API PUT com o modelo de índice completo ao ajustar alguns elementos nele:
- Remova a definição para source (todas as linhas que começam com
-a seguir). - Adicione uma definição de campo para program.name.
- Altere o tipo do campo system.syslog.pid para long.
PUT _template/filebeat-6.8.1
{
"order" : 1,
"index_patterns" : [
"filebeat-6.8.1-*"
]
...
"mappings": {
"properties" : {
- "source" : {
- "ignore_above" : 1024,
- "type" : "keyword"
- },
"program" : {
"properties" : {
"name": {
"type": "keyword",
"ignore_above": 1024
}
}
},
"system" : {
"properties" : {
"syslog": {
"properties" : {
"pid" : {
"type" : "long"
}
...
}
Depois que a chamada à API estiver pronta, execute-a para substituir o modelo de índice. Se você pretende fazer backfill de muitos campos do ECS, confira a amostra dos modelos do ECS Elasticsearch no repositório git do ECS.
Reindexação
A próxima etapa é escrever um novo pipeline de ingestão para modificar nossos eventos do Beats 6.8. Para o nosso exemplo, copiaremos system.syslog.program para process.name, copiaremos source para log.file.path (a menos que já esteja populado) e removeremos o campo source:
PUT _ingest/pipeline/filebeat-system-6-to-7
{ "description": "Pipeline to modify Filebeat 6 system module documents to better match ECS",
"processors": [
{ "set": {
"field": "process.name",
"value": "{{system.syslog.program}}",
"if": "ctx.system?.syslog?.program != null"
}},
{ "set": {
"field": "log.file.path",
"value": "{{source}}",
"if": "ctx.containsKey('source') && ctx.log?.file?.path == null"
}},
{ "remove": {
"field": "source"
}}
],
"on_failure": [
{ "set": {
"field": "error.message",
"value": "{{ _ingest.on_failure_message }}"
}}
]
}
Saiba mais sobre pipelines de ingestão e a linguagem Painless (usada nas cláusulas if).
Podemos testar esse pipeline com a API _simulate usando eventos totalmente populados, mas a seguir está um teste mais minimalista que é mais adequado em uma postagem de blog. Você perceberá que um evento tem log.file.path já preenchido (Beats 6.6 e versões superiores) e que outro não tem (6.5 e versões anteriores):
POST _ingest/pipeline/filebeat-system-6-to-7/_simulate
{ "docs":
[ { "_source": {
"log": { "file": { "path": "/var/log/system.log" } },
"source": "/var/log/system.log",
"system": {
"syslog": {
"program": "syslogd"
}}}},
{ "_source": {
"source": "/var/log/system.log",
"system": {
"syslog": {
"program": "syslogd"
}}}}
]
}
A resposta da chamada à API contém os dois eventos modificados. Podemos confirmar que nosso pipeline funcionou porque o campo source não existe mais, e ambos os eventos têm o respectivo valor armazenado em log.file.path.
Agora podemos executar nossa reindexação em índices que não estão mais recebendo gravações (por exemplo, o índice de ontem e de horários anteriores) usando esse pipeline de ingestão para cada índice do Filebeat que estamos migrando. Verifique se leu os documentos _reindex para entender como reindexar em segundo plano, ajustar a operação de reindexação etc. A seguir está uma reindexação simples que trabalhará os poucos eventos que temos:
POST _reindex
{ "source": { "index": "filebeat-6.8.1-2019.07.04" },
"dest": {
"index": "filebeat-6.8.1-2019.07.04-migrated",
"pipeline": "filebeat-system-6-to-7"
}}
Se você estiver acompanhando e somente tem o índice de hoje, de qualquer maneira fique à vontade para experimentar a chamada à API e inspecionar o mapeamento do índice migrado. Mas não exclua depois o índice de hoje; ele será recriado porque o Filebeat 6.8 ainda está enviando dados.
Caso contrário, depois que os índices inativos tiverem sido reindexados, poderemos confirmar se os novos índices têm todas as correções que queremos e excluir os antigos.
Modificação de eventos de entrada
A maioria dos Beats podem ser configurados para que sejam enviados diretamente a um pipeline de ingestão em sua saída do Elasticsearch (o mesmo vale para a saída do Elasticsearch do Logstash). Como estamos testando com um módulo do Filebeat nesta demonstração — que já usa pipelines de ingestão — teremos de modificar o pipeline do módulo.
O pipeline de ingestão instalado pelo Filebeat 6.8 a ser processado é chamado filebeat-6.8.1-system-syslog-pipeline. Tudo o que é preciso fazer aqui é adicionar uma chamada ao nosso próprio pipeline ao final do pipeline Syslog do Filebeat.
Exibiremos o pipeline que estamos prestes a modificar:
GET _ingest/pipeline/filebeat-6.8.1-system-syslog-pipeline
Depois, vamos preparar a chamada à API para substituir o pipeline colando o pipeline completo abaixo da chamada à API PUT. Assim, adicionaremos um processador “pipeline” ao final para chamar nosso novo pipeline:
PUT _ingest/pipeline/filebeat-6.8.1-system-syslog-pipeline
{ "description" : "Pipeline for parsing Syslog messages.",
"processors" :
[
{ "grok" : { ... }
...
{ "pipeline": { "name": "filebeat-system-6-to-7" } }
],
"on_failure" : [
{ ... }
]
}
Depois de executar essa chamada à API, todos os eventos que chegam serão modificados para melhor corresponder o ECS, antes de ser indexados.
Por fim, podemos usar _update_by_query para modificar documentos no índice ao vivo exatamente de onde modificamos o pipeline. Podemos confirmar os documentos que ainda precisam de atualização procurando aqueles que ainda têm o campo de fonte:
GET filebeat-6.8.1-*/_search
{ "query": { "exists": { "field": "source" }}}
E reindexamos somente aqueles:
POST filebeat-6.8.1-*/_update_by_query?pipeline=filebeat-system-6-to-7
{ "query": { "exists": { "field": "source" }}}
Verificação de conflitos
Depois que todos os índices com conflitos forem excluídos, restarão somente os reindexados. Podemos atualizar o padrão de índice para confirmar se os conflitos foram eliminados. Podemos voltar para o painel do Filebeat 7 e ver que nossos dados da versão 6.8 contidos agora são mais úteis graças ao backfill do campo process.name:
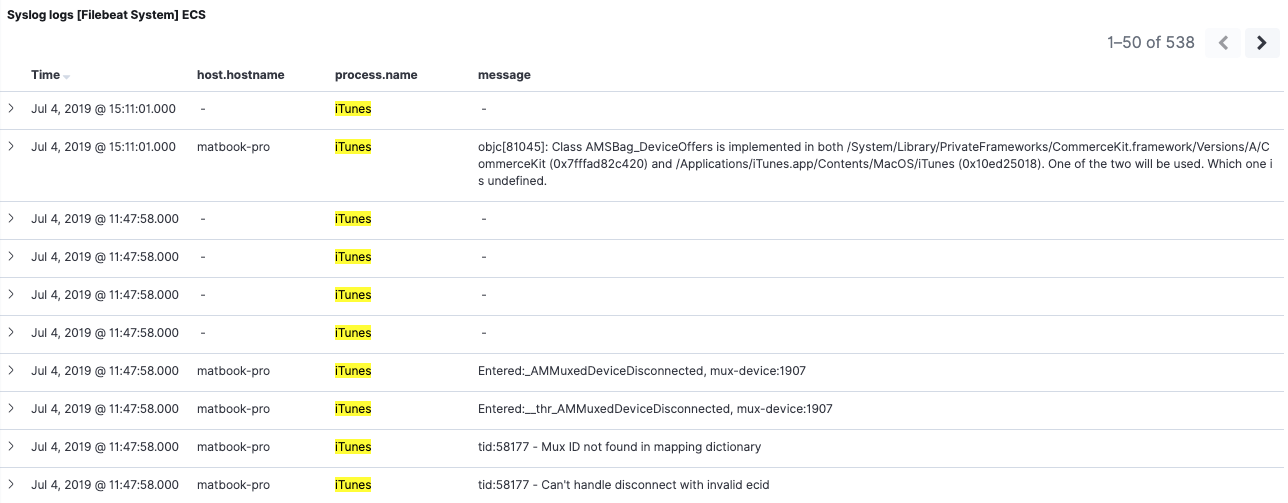
Em nosso exemplo, somente fizemos backfill de um campo. Evidentemente, você está livre para fazer backfill de quantos campos forem necessários.
Limpeza após a migração
Sua migração provavelmente envolverá a modificação de painéis e aplicativos personalizados que estejam consumindo eventos do Beats por meio da API para usar os novos nomes de campo do ECS.
Depois que a migração para o Beats 7 estiver concluída e os aliases de campo não estiverem mais sendo usados, poderemos removê-los para obter os benefícios de economia de memória discutidos anteriormente. Para remover os aliases, vamos remover o atributo migration.6_to_7.enabled do arquivo filebeat.yml para substituir o modelo do Filebeat 7.2 por:
./filebeat setup --template -e -E 'setup.template.overwrite=true'
Assim como as alterações feitas no modelo do Filebeat 6.8 anteriormente, o novo modelo sem aliases entrará em vigor na próxima vez em que ocorrer rollover do índice do Filebeat 7.2.
Conclusão
Neste artigo, tratamos das etapas necessárias para migrar seus dados para o ECS em um ambiente do Beats. Analisamos os benefícios do procedimento de atualização, além de suas limitações. Essas limitações podem ser tratadas reindexando os dados antigos e inclusive modificando os dados atuais de entrada do Beats 6 durante o processo de ingestão.
Após discutir a migração em alto nível, executamos um exemplo passo a passo de atualização do módulo System do Filebeat da versão 6.8 para a 7.2. Analisamos as diferenças entre eventos do Filebeat 6.8 e do 7.2, e percorremos todas as etapas que os usuários podem executar para reindexar dados antigos — e modificá-los à medida que ainda estão entrando.
A introdução de um esquema inevitavelmente gera um grande impacto nas instalações existentes, mas acreditamos firmemente que essa migração valerá a pena. Você pode ler as causas disso nos artigos Introducing the Elastic Common Schema (Apresentação do Elastic Common Schema) e Why Observability loves the Elastic Common Schema (Por que a observabilidade adora o Elastic Common Schema).
Se o ambiente usar pipelines de ingestão de dados que sejam diferentes do Beats, fique ligado. Temos outra postagem de blog prevista em que discutiremos como migrar um pipeline de ingestão personalizado para o ECS.
Se tiver dúvidas sobre o ECS ou precisar de ajuda com a atualização do Beats, acesse os fóruns de discussão e marque sua pergunta com elastic-common-schema. Você pode aprender mais sobre o ECS em nossa documentação e contribuir para o ECS no GitHub.
Referências
Documentação
- Upgrade Assistant
- Atualização do Elastic Stack
- Alterações importantes na versão 7.0
- Reindexação
- Pipeline de ingestão
- API simulate do pipeline de ingestão
- Linguagem Painless
- Mapeamentos e modelos de índice
- Arquivo que documenta todas as alterações no arquivo: ecs-migration.yml
- Amostra de modelos de índice do ECS Elasticsearch
Blogs e vídeos
- Apresentação do ECS (blog)
- Apresentação do ECS (webinar)
- ECS: como migrar seus dados (webinar)
- Por que a observabilidade adora o Elastic Common Schema (blog)
- Atualização do Elastic Stack com o 7.x Upgrade Assistant (blog)
Geral
- Faça perguntas sobre o ECS nos fóruns de discussão e marque sua pergunta com “elastic-common-schema”
- Documentação oficial do ECS
- Repositório Github do ECS