Introdução às visualizações do Vega no Kibana
A gramática declarativa do Vega é um método poderoso de visualizar dados. Sendo um novo recurso no Kibana 6.2, as visualizações sofisticadas do Vega e do Vega-Lite agora podem ser criadas com os dados do Elasticsearch. Assim, vamos começar aprendendo a linguagem Vega com alguns exemplos simples.
Para começar, abra o editor do Vega --- uma ferramenta conveniente para experimentar o Vega bruto (sem personalizações do Elasticsearch). Copie o código abaixo e você verá o texto "Hello Vega!" no painel direito.

{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width": 100, "height": 30,
"background": "#eef2e8",
"padding": 5,
"marks": [
{
"type": "text",
"encode": {
"update": {
"text": { "value": "Hello Vega!" },
"align": { "value": "center"},
"baseline": { "value": "middle"},
"stroke": { "value": "#A32299" },
"angle": { "value": 15 },
"x": { "signal": "width/2" },
"y": { "signal": "height/2" }
}
}
}
]
}
O bloco marcas é uma matriz de primitivas de desenho, como texto, linhas e retângulos. Cada marca tem um grande número de parâmetros especificados dentro do conjunto de codificação. Cada parâmetro é definido para uma constante (valor) ou um resultado de um (sinal) de computação no estágio "update". Para a marca de texto, especificamos a sequência de caracteres de texto, verificamos se o texto está posicionado corretamente em relação a determinadas coordenadas, girado e com cor de texto definido. As coordenadas x e y são computadas com base na largura e altura do gráfico, posicionando o texto no meio. Existem muitos outros parâmetros de marca de texto. Também existe um gráfico de demonstração de marca de texto interativo para testar diferentes valores de parâmetro.
O $schema é simplesmente um ID da versão do mecanismo Vega necessário. Background torna o gráfico não transparente. Os parâmetros width e height definem o tamanho da tela de desenho inicial. O tamanho final do gráfico pode mudar em alguns casos, com base no conteúdo e nas opções de autodimensionamento. Observe que o parâmetro autosize padrão do Kibana é fit em vez de pad, o que torna height e width opcionais. O parâmetro padding adiciona um pouco de espaço em torno do gráfico além da largura e altura.
Gráfico orientado a dados
Nossa próxima etapa é desenhar um gráfico orientado a dados usando a marca de retângulo. A seção de dados permite várias fontes de dados, seja com hardcoding ou como URL. No Kibana, você também pode usar consultas diretas do Elasticsearch. Nossa tabela de dados vals tem 4 linhas e duas colunas - category e count. Usamos category para posicionar a barra no eixo x, e count para a altura da barra. Observe que 0 referente à coordenada y fica na parte superior e aumenta para baixo.
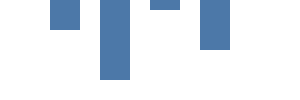
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 300, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": 50, "count": 30},
{"category": 100, "count": 80},
{"category": 150, "count": 10},
{"category": 200, "count": 50}
]
} ],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value": 30},
"y": {"field": "count"},
"y2": {"value": 0}
}
}
} ]
}
A marca rect especifica vals como a fonte de dados. A marca é desenhada uma vez por valor de dados de fonte (também conhecido como linha de tabela ou datum). Diferentemente do gráfico anterior, os parâmetros x e y não são gerados com hardcoding, mas provêm de campos do datum.
Escalonamento
Escalonamento é um dos conceitos mais importantes, porém um pouco complicados no Vega. Nos exemplos anteriores, as coordenadas de pixel da tela eram geradas por hardcoding nos dados. Apesar de o processo ter ficado mais simples, os dados reais quase nunca vêm nesse formato. Em vez disso, os dados da fonte vêm em suas próprias unidades (p. ex.: número de eventos), e fica a critério do gráfico escalonar os valores da fonte para o tamanho de gráfico desejado em pixels.
Neste exemplo, usamos escala linear --- basicamente uma função matemática para converter um valor do domínio dos dados da fonte (neste gráfico valores count de 1000..8000, e incluindo count=0), para o [intervalo] desejado (https://vega.github.io/vega/docs/scales/#range) (em nosso caso a altura do gráfico é 0..99). Adicionar "scale": "yscale" aos parâmetros y e y2 usa o escalonador yscale para converter count para as coordenadas de tela (0 se torna 99, e 8000 - maior valor nos dados da fonte - se torna 0). Observe que o parâmetro de intervalo height é um caso especial, virando o valor para fazer 0 aparecer na parte inferior do gráfico.
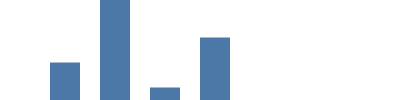
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": 50, "count": 3000},
{"category": 100, "count": 8000},
{"category": 150, "count": 1000},
{"category": 200, "count": 5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value": 30},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0}
}
}
} ]
}
Escalonamento de faixa
Para o nosso tutorial, precisaremos de outro dos mais de 15 tipos de escala Vega --- uma escala de faixa. Essa escala é usada quando temos um conjunto de valores (como categorias), que precisam ser representadas como faixas, cada uma ocupando a mesma largura proporcional da largura total do gráfico. Aqui, a escala de faixa oferece a cada uma das 4 categorias exclusivas a mesma largura proporcional (cerca de 400/4, menos 5% de padding entre barras e em ambas as extremidades). A expressão {"scale": "xscale", "band": 1} obtém 100% da largura da faixa para o parâmetro width da marca.
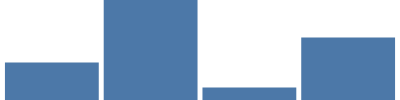
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": "Oranges", "count": 3000},
{"category": "Pears", "count": 8000},
{"category": "Apples", "count": 1000},
{"category": "Peaches", "count": 5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding": 0.05
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band": 1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0}
}
}
} ]
}
Eixos
Um gráfico comum não seria completo sem as identificações de eixo. A definição de eixo usa as mesmas escalas que definimos antes, por isso adicioná-las é tão simples quanto fazer referência à escala pelo nome e especificar o lado do posicionamento. Adicione este código como elemento superior ao último código de exemplo.
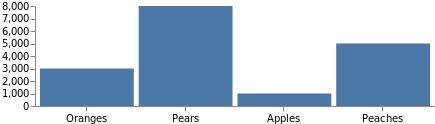
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
Observe que o tamanho total do gráfico aumentou automaticamente para conciliar esses eixos. O gráfico pode ser forçado a ficar no tamanho original adicionando "autosize": "fit" na parte superior da especificação.
Transformações de dados e condicionais
Os dados geralmente precisam de manipulação adicional antes de poder usá-los para desenho. O Vega fornece inúmeras transformações para ajudá-lo com isso. Vamos usar a [transformação de fórmula] mais comum (https://vega.github.io/vega/docs/transforms/formula/) para adicionar dinamicamente um campo de valor count aleatório a cada um dos datums da fonte. Além disso, neste gráfico manipularemos a cor de preenchimento da barra, tornando-a vermelha se o valor for inferior a 333, amarela se o valor for inferior a 666 e verde se o valor for superior a 666. Observe que isso poderia ser feito com uma escala, mapeando o domínio dos dados da fonte para o conjunto de cores ou para um esquema de cores.
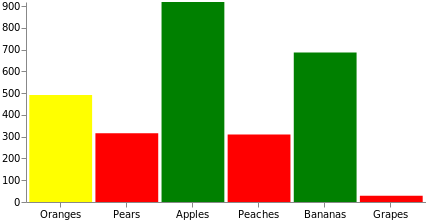
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 200,
"data": [ {
"name": "vals",
"values": [
{"category": "Oranges"},
{"category": "Pears"},
{"category": "Apples"},
{"category": "Peaches"},
{"category": "Bananas"},
{"category": "Grapes"}
],
"transform": [
{"type": "formula", "as": "count", "expr": "random()*1000"}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding": 0.05
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band": 1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0},
"fill": [
{"test": "datum.count < 333", "value": "red"},
{"test": "datum.count < 666", "value": "yellow"},
{"value": "green"}
]
}
}
} ]
}
Dados dinâmicos com Elasticsearch e Kibana
Agora que você conhece os fundamentos básicos, vamos tentar criar um gráfico de linha baseado em tempo usando alguns dados do Elasticsearch gerados aleatoriamente. Isso é semelhante àquilo que você vê inicialmente ao criar um novo gráfico do Vega no Kibana, com exceção de que usamos a linguagem Vega em vez do padrão no Kibana que é o Vega-Lite (a versão simplificada e superior do Vega).
Para este exemplo, geraremos hardcoding dos dados usando values, em vez de fazer a consulta real com url. Dessa maneira, podemos continuar testando no editor do Vega que não oferece suporte a consultas Elasticsearch do Kibana. O gráfico vai se tornar totalmente dinâmico no Kibana se você substituir values pela seção url conforme mostrado a seguir.
Nossa consulta conta o número de documentos por intervalo de tempo, usando o intervalo de tempo e filtros de contexto conforme selecionados pelo usuário do painel. Veja como consultar o Elasticsearch no Kibana para obter mais informações.
"url": {
"%context%": true,
"%timefield%": "@timestamp",
"index": "_all",
"body": {
"aggs": {
"time_buckets": {
"date_histogram": {
"field": "@timestamp",
"interval": {"%autointerval%": true},
"extended_bounds": {
"min": {"%timefilter%": "min"},
"max": {"%timefilter%": "max"}
},
"min_doc_count": 0
}
}
},
"size": 0
}
Quando executarmos, os resultados terão esta aparência (alguns campos não relacionados foram removidos por brevidade):
"aggregations": {
"time_buckets": {
"buckets": [
{"key": 1528061400000, "doc_count": 1},
{"key": 1528063200000, "doc_count": 45},
{"key": 1528065000000, "doc_count": 49},
{"key": 1528066800000, "doc_count": 17},
...
Como você pode ver, os dados reais de que precisamos estão dentro da matriz aggregations.time_buckets.buckets. Podemos informar ao Vega para verificar somente a matriz com "format": {"property": "aggregations.time_buckets.buckets"} dentro da definição de dados.
Nosso eixo x não se baseia mais nas categorias, mas no tempo (o campo key é um tempo UNIX que o Vega pode usar diretamente). Assim, alteramos o tipo xscale para tempo e ajustamos todos os campos para usar key e doc_count. Também precisamos alterar o tipo de marca para line e incluir apenas os canais de parâmetro x e y. E pronto! Você agora tem um gráfico de linha. Talvez também tenha interesse em personalizar as identificações de eixo x com os [parâmetros] format, labelAngle e tickCount (https://vega.github.io/vega/docs/axes/).
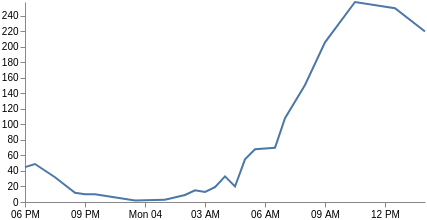
{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 200,
"data": [
{
"name": "vals",
"values": {
"aggregations": {
"time_buckets": {
"buckets": [
{"key": 1528063200000, "doc_count": 45},
{"key": 1528065000000, "doc_count": 49},
{"key": 1528068600000, "doc_count": 32},
{"key": 1528072200000, "doc_count": 12},
{"key": 1528074000000, "doc_count": 10},
{"key": 1528075800000, "doc_count": 10},
{"key": 1528083000000, "doc_count": 2},
{"key": 1528088400000, "doc_count": 3},
{"key": 1528092000000, "doc_count": 9},
{"key": 1528093800000, "doc_count": 15},
{"key": 1528095600000, "doc_count": 13},
{"key": 1528097400000, "doc_count": 19},
{"key": 1528099200000, "doc_count": 33},
{"key": 1528101000000, "doc_count": 20},
{"key": 1528102800000, "doc_count": 55},
{"key": 1528104600000, "doc_count": 68},
{"key": 1528108200000, "doc_count": 70},
{"key": 1528110000000, "doc_count": 108},
{"key": 1528113600000, "doc_count": 151},
{"key": 1528117200000, "doc_count": 206},
{"key": 1528122600000, "doc_count": 258},
{"key": 1528129800000, "doc_count": 250},
{"key": 1528135200000, "doc_count": 220}
]
}
}
},
"format": {"property": "aggregations.time_buckets.buckets"}
}
],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "doc_count"},
"range": "height"
},
{
"name": "xscale",
"type": "time",
"domain": {"data": "vals", "field": "key"},
"range": "width"
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [
{
"type": "line",
"from": {"data": "vals"},
"encode": {
"update": {
"x": {"scale": "xscale", "field": "key"},
"y": {"scale": "yscale", "field": "doc_count"}
}
}
}
]
}
Fique atento em nosso blog para as futuras postagens sobre o Vega. Pretendo fazer outra postagem sobre manipulação de resultados do Elasticsearch, principalmente agregações e dados aninhados.
Links úteis
- Documentos do Vega para Kibana
- Documentação do Vega
- Exemplos do Vega
- Documentação do Vega-Lite
- Exemplos do Vega-Lite