Geração e visualização de alfa com conjuntos de dados de IA da Vectorspace e o Canvas
Resumo
Esta é a história de como os conjuntos de dados da Vectorspace surgiram usando o Elastic Stack e o Canvas no Kibana, para visualizar informações e aproveitar o poder e o valor dos dados.
Histórico
Em 2002, no Lawrence Berkeley National Laboratory, a Vectorspace criou vetores de características com base na compreensão da linguagem natural (NLU, pela sigla em inglês), também conhecidos hoje como word embeddings. Os vetores de características foram usados para gerar conjuntos de dados de matriz de correlação, com o objetivo de analisar as relações ocultas entre os genes relacionados à extensão da expectativa de vida, ao câncer de mama e ao reparo de danos ao DNA resultantes da radiação espacial.
As fontes de dados incluíram resultados de experimentos de laboratório, literatura científica da National Library of Medicine, ontologias, vocabulários controlados, enciclopédias, dicionários e outros bancos de dados de pesquisa genômica.
Naquela época, eles também implementaram o AutoClass, um classificador bayesiano usado para classificar estrelas, e usaram-no para classificar grupos de genes com base em um conjunto de dados contendo valores de expressão gênica. As perdas foram minimizadas, e os resultados se tornaram mais úteis ao aumentar os conjuntos de dados com word embeddings e modelagem de tópicos. Na época, o objetivo era imitar conexões conceituais que um pesquisador biomédico poderia fazer antes de uma descoberta, in silico. Parte desse trabalho foi publicada em um artigo, descrevendo relações ocultas entre genes relacionados ao prolongamento da expectativa de vida de nematódeos. Em 2005, a divisão SPAWAR da Marinha dos EUA se envolveu, o que permitiu que mais recursos fossem usados para expandir a pesquisa para áreas como os mercados financeiros.
Melhorar o desempenho de um conjunto de dados
Com o tempo, a Vectorspace aprendeu a melhorar o desempenho dos conjuntos de dados aumentando ou juntando vetores de características representados por word embeddings. Isso resultou na geração de novas visualizações, interpretações, hipóteses ou descobertas. O aumento dos conjuntos de dados de série temporal para os mercados financeiros com esses tipos de vetores de características pode produzir sinais únicos ou gerar alfa. Tudo começa com fontes de dados otimizadas para um contexto ou tópico selecionado, conforme ilustrado abaixo:
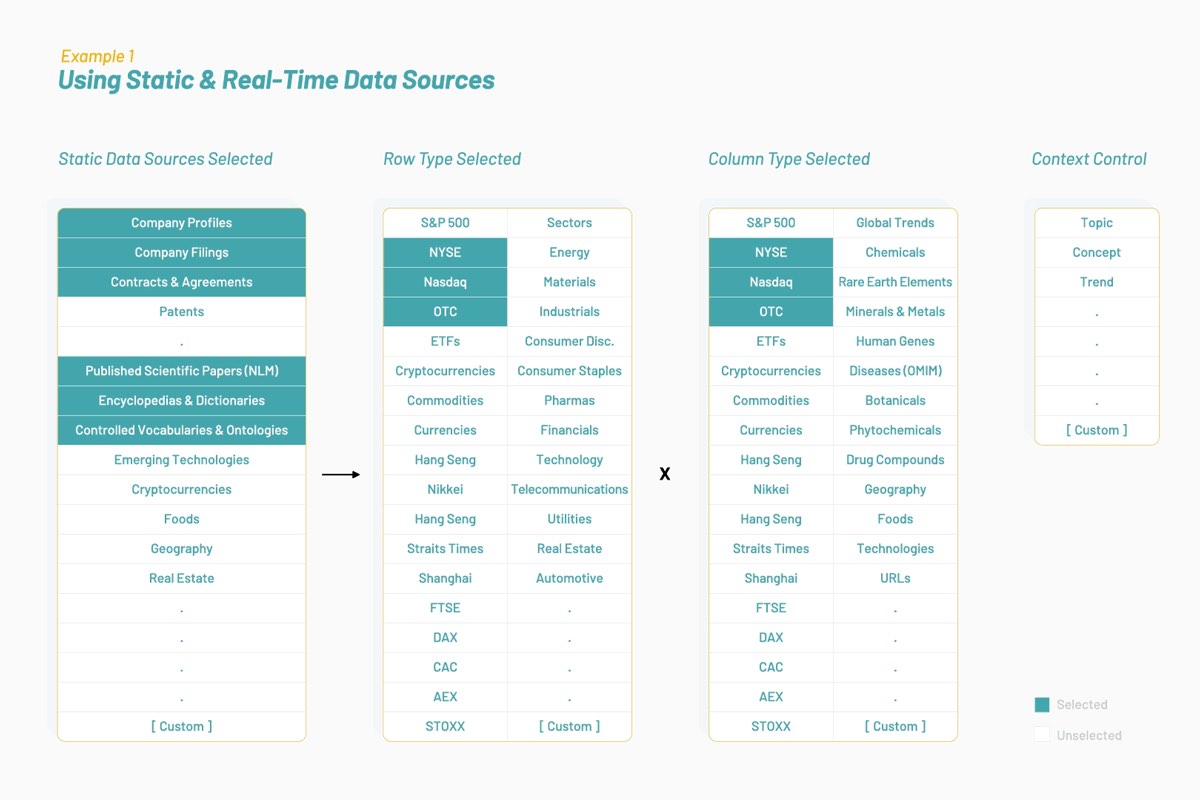
Os conjuntos de dados resultantes são compostos de vetores de características que são word embeddings baseados na literatura biomédica e na linguagem humana em torno de empresas de capital aberto na NYSE e Nasdaq. Uma abordagem interdisciplinar à pesquisa pode determinar se genes e ações têm atributos e comportamentos semelhantes ao interagir nos caminhos que compartilham.
Estabelecer uma meta em duas partes
Parte um: determinar onde aplicar o conhecimento sobre as interações observadas entre genes, proteínas, medicamentos e doenças às ações.
Parte dois: explorar como criar um veículo para financiar pesquisas relacionadas a tornar o voo espacial humano de longo prazo mais seguro usando conjuntos de dados aumentados para gerar alfa nos mercados financeiros.
Desencadeadores de eventos ascendentes
As interações que estavam sendo observadas entre os genes eram semelhantes às interações entre as ações? Em 20 de setembro de 2004, houve um evento que deu uma resposta, em parte. A Merck (MRK) caiu 21% (provavelmente) devido ao fato de seu medicamento Vioxx potencialmente causar ataques cardíacos. Foi um evento que desencadeou um movimento simpático latente no preço das ações de outras empresas farmacêuticas públicas, em particular a Pfizer (PFE). O aumento do conjunto de dados produzido pela Vectorspace permitiu prever uma reação atrasada no preço da PFE com base em suas associações ao medicamento Vioxx, que a Merck estava produzindo. Detalhes sobre isso serão fornecidos mais adiante.
Pesquisas posteriores descobriram um artigo interessante na edição de fevereiro de 2001 do The Journal of Finance, intitulado “Contagious Speculation and a Cure for Cancer: A Non-Event that Made Stock Prices Soar” (Especulação contagiosa e cura para o câncer: um não evento que elevou os preços das ações). O documento descrevia um evento com uma empresa chamada EntreMed (ENMD era o símbolo na época):
“Um artigo da edição de domingo do New York Times sobre um potencial desenvolvimento de novos medicamentos de cura para o câncer fez com que o preço das ações da EntreMed subisse de 12,063 no fechamento de sexta-feira para abrir a 85 e fechar a quase 52 na segunda-feira. As ações da EntreMed fecharam acima de 30 nas três semanas seguintes. O entusiasmo se espalhou para outras ações de biotecnologia. Entretanto, o potencial avanço na pesquisa do câncer já havia sido relatado na revista Nature e em vários jornais populares, incluindo o Times! mais de cinco meses antes. Assim, a atenção pública entusiasmada induziu a um aumento permanente nos preços das ações, mesmo que nenhuma informação genuinamente nova tivesse sido apresentada.” Entre as muitas observações perspicazes feitas pelos pesquisadores, uma se destacou na conclusão: “Os movimentos [nos preços] podem estar concentrados nas ações que tenham algumas coisas em comum, mas que não precisam ser fundamentos econômicos.” — (Huberman e Regev 387)
Com o histórico prévio das equipes em áreas relacionadas ao desenvolvimento de algoritmos quantitativos, banco de investimento e administração de empresas públicas, eles começaram a observar semelhanças entre genes e ações. Como os genes, as ações têm “valores de expressão”, atributos, relações ocultas entre si e com eventos externos, tópicos ou tendências globais. Essas relações são uma forma de conhecimento que tende a estar incorporado na linguagem humana mais do que qualquer outra coisa. Como os genes, grupos de ações podem interagir e se mover em simpatia um pelo outro. Esses dados podem ser usados para prever futuras correlações de preços entre ações com base no “entrelaçamento latente”. Grupos de ações podem agir como “cestas” que compartilham relações conhecidas e ocultas entre si e com eventos externos. Grupos ou cestas podem ser controlados com o contexto.
Uma maré alta não levanta todas as embarcações
A Vectorspace se propôs a analisar o que estava causando as correlações observadas quando identificou uma oportunidade de criar um veículo de financiamento com base no aproveitamento de uma ineficiência nos mercados financeiros baseada em “bolsões de informações mineráveis”. Eles começaram a observar reações atrasadas entre as ações, semelhantes à maneira como um porto ou baía se enche de água e levanta as embarcações minutos ou horas após o aumento da maré. A elevação do nível da água em um porto pode ser desencadeada por um evento que levanta as embarcações no porto, sendo que, nesse caso, as embarcações podem ser consideradas grupos de ativos negociáveis, como as ações. Nos mercados financeiros, algumas embarcações sobem e outras não. A previsão de quais ativos estão correlacionados a um evento, juntamente com a força e o contexto dessa correlação, pode fornecer um sinal valioso. É como ter uma forma de informação assimétrica que pode ser usada para se posicionar à frente do mercado ou reduzir o risco em posições longas ou curtas ao aplicar o capital. Isso também pode ser conhecido como “gerar alfa”, que pode ser visualizado e interpretado.
Para testar essa hipótese probabilística de elevação de embarcações, foram analisados 20 anos de dados para procurar padrões de movimentos simpáticos ou entrelaçamento latente entre os preços das ações de empresas de capital aberto com base em eventos no mercado. Muitos exemplos foram descobertos, incluindo os três eventos abaixo: EntreMed (ENMD) 1998, Merck (MRK) 2004 e Celgene (CELG) 2019.
Evento 1: EntreMed (ENMD) sobe 608% (4 de maio de 1998)
A EntreMed divulgou notícias de que tinha a cura para um tipo de câncer em uma sexta-feira após o fechamento do mercado. Suas ações estava sendo negociadas a 12 dólares na sexta-feira e abriram a 85 dólares na segunda-feira. Por simpatia, uma cesta de ações também começou a subir. Elas tinham correlações com a ENMD com base na linguagem humana em torno da ciência de proteínas relacionada às terapias contra o câncer.
O artigo que descreve esse evento contém alguns trechos relevantes:
pág. 392 par. 4 “Os retornos de três dessas excederam 100%, os retornos de duas ficaram entre 50% e 100%, e os retornos de outras duas empresas ficaram entre 25% e 50%. Uma comparação desses retornos com a distribuição de retornos extremos relatada na Tabela I mostra quão incomuns foram os retornos das ações dessas sete empresas de biotecnologia e, especialmente, quão inédito foi seu agrupamento.”
pág. 395 par. 1 “Não é surpreendente que as notícias sobre um avanço na pesquisa sobre o câncer não afetem apenas as ações de uma empresa com direitos de comercialização direta sobre o desenvolvimento; o mercado pode reconhecer possíveis efeitos de repercussão e supor que outras empresas possam se beneficiar da inovação.”
pág. 396 par. 3 “os movimentos podem estar concentrados nas ações que tenham algumas coisas em comum, mas que não precisam ser fundamentos econômicos”
Evento 2: Merck (MRK) cai 25,8% (30 de setembro de 2004)
A Merck retirou o Vioxx, um medicamento de 2,5 bilhões de dólares, do mercado porque estava provocando ataques cardíacos e AVCs com base em inibidores da COX-2. Essa correlação teve uma causa. A MRK fechou a 45,07 dólares no dia anterior e abriu a 33,40 dólares em 30 de setembro. Durante a experimentação com word embeddings atuando como vetores de características, verificou-se que a Pfizer (PFE) era a empresa mais estreitamente relacionada à Merck com base em vetores de características semelhantes, pois estavam trabalhando em um composto de medicamento semelhante baseado no inibidor da COX-2 na época. Algumas semanas depois, a PFE declinou significativamente.
“Em 17 de dezembro de 2004, a Pfizer e o Instituto Nacional do Câncer dos EUA anunciaram que pararam de administrar o Celebrex (Celebra no Brasil, cujo princípio ativo é o celecoxib), um inibidor da ciclo-oxigenase-2 (COX-2), em um ensaio clínico em andamento que investiga seu uso na prevenção de pólipos do cólon devido ao aumento no risco de eventos cardiovasculares. O rofecoxib da Merck (Vioxx), outro inibidor da COX-2, foi retirado do mercado no mundo inteiro em setembro de 2004 devido ao aumento do risco de infarto do miocárdio e AVC.” — CMAJ
A PFE caiu 24%, do fechamento do dia anterior a 28,98 dólares para o mínimo de 21,99 dólares naquele dia.
Evento 3: Celgene (CELG) sobe 31,8% (3 de janeiro de 2019)
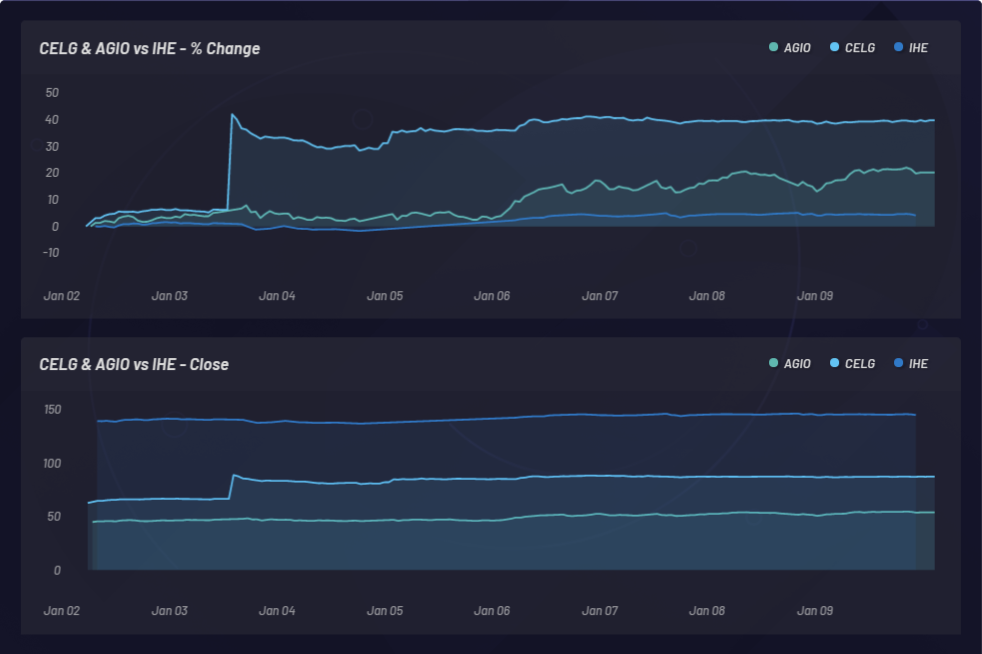
Em 3 de janeiro de 2019, a Bristol-Myers Squibb (BMY) adquiriu a Celgene (CELG) por 74 bilhões de dólares. A CELG subiu da noite para o dia de 66,64 para 87,86 dólares por ação ou um ganho de 31,8%. No decorrer de um período de quatro dias, uma cesta de ações relacionadas à CELG produziu um lucro de 20% com base nos relacionamentos encontrados na linguagem humana em torno dessas empresas. As fontes de dados que possibilitam as conexões entre essas entidades incluem repositórios de perfis de empresas de capital aberto e literatura científica publicada com revisão por pares.
Na análise desse processo feita pela Vectorspace, verificou-se que algumas correlações de NLU podem causar correlações latentes baseadas em preços entre ações e entre ações e eventos. A equipe observou muitos exemplos como os acima que podem ser usados para posicionar uma empresa à frente do mercado ou se envolver em formas de arbitragem de informações.
Visualizar alfa
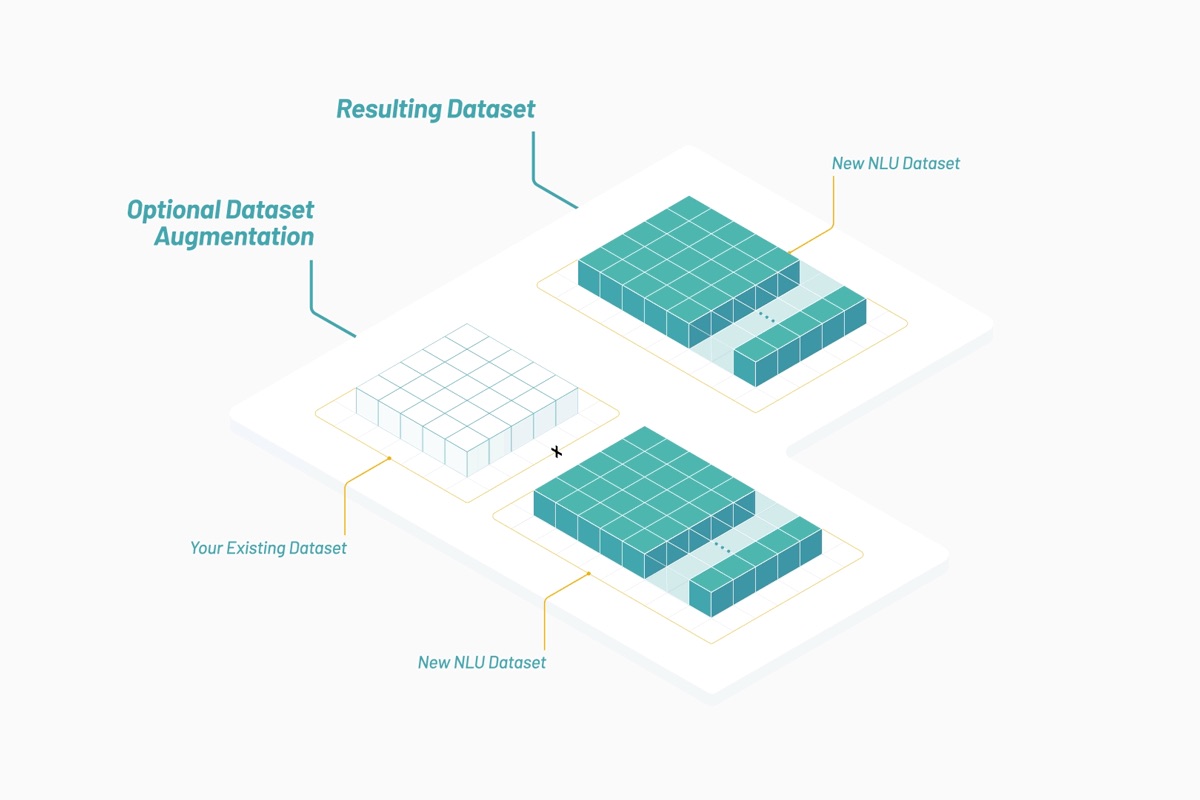
Hoje, na inteligência artificial da Vectorspace, os conjuntos de dados são projetados para detectar redes de relações ocultas entre interações de genes, proteínas, micróbios, medicamentos e doenças em ciências biológicas ou entre ações nos mercados financeiros. Na maioria das vezes, nossos clientes usam esses conjuntos de dados para aumentar os conjuntos de dados internos existentes. Os conjuntos de dados são gerados usando combinações de vetores de características que consistem em atributos pontuados com base na vetorização de palavras e objetos. Os conjuntos de dados são atualizados quase em tempo real e acessados via API usando créditos de token utilitário.
Ao utilizar o Elastic Stack e o Canvas, a Vectorspace pode fornecer aos clientes visualização e interpretação de dados quase em tempo real. As visualizações são white label e completamente configuráveis. Isso é importante para o processo geral, pois novas interpretações e insights podem levar a novas hipóteses, sinais ou descobertas.
É comum que empresas e instituições de gestão de ativos solicitem soluções de pipeline de engenharia de dados no local para privacidade. A criação de um pacote para o nosso pipeline de engenharia de dados usando o Elastic Cloud Enterprise permite a entrega de uma solução pronta para geração de sinal.
Os clientes da Vectorspace nos mercados financeiros buscam otimizar as proporções entre sinal e ruído, a geração de alfa, a minimização de uma função de perda ou a maximização dos índices de Sharpe ou Sortino. Eles fazem isso enquanto visualizam e interpretam os resultados de estratégias de backtesting com base no aumento do conjunto de dados quase em tempo real, enquanto limitam o sobreajuste do backtest.
A frequência de atualização do conjunto de dados pode variar de um minuto a um mês, dependendo da volatilidade das fontes de dados subjacentes. Um pacote popular de conjunto de dados solicitado consiste em um conjunto de dados de preços de série temporal no qual as linhas contêm empresas farmacêuticas de capital aberto aumentadas com vetores de características, que são compostos de medicamentos com uma pontuação de correlação baseada em NLU. A escolha de um contexto no qual operar pode ser crucial. Assim como o contexto pode alterar uma definição, adicionar as restrições contextuais corretas pode orientar uma alteração no valor de uma pontuação de correlação ao longo do tempo. O contexto também pode controlar a força das relações entre entidades e entre entidades e eventos.
Visualização com o Canvas
Vamos ver mais detalhes e usar um destes conjuntos de dados para gerar e visualizar a cesta de ações relacionadas à Celgene (CELG) junto com o evento que desencadeou uma elevação atrasada no preço entre algumas dessas ações. Isso mostrará as etapas típicas que um cliente da Vectorspace pode seguir usando estes conjuntos de dados enquanto interpreta resultados quase em tempo real e os resultados de um backtest no Canvas. Primeiro, seria importante observar os resultados finais de um grupo inteiro de cestas para confirmar que a cesta da Celgene não teve supressão de evidências.
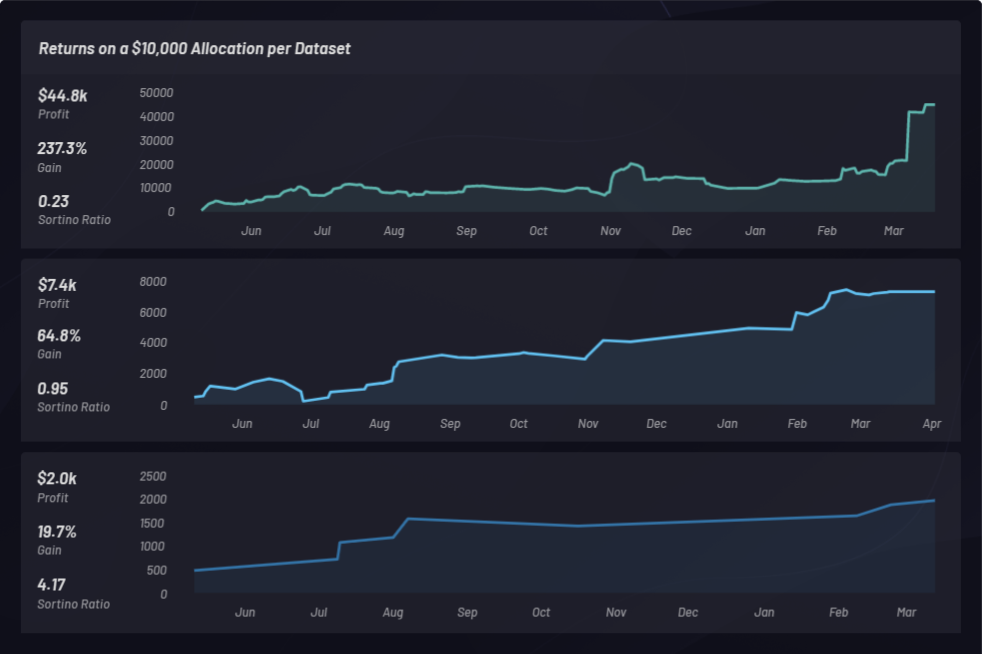
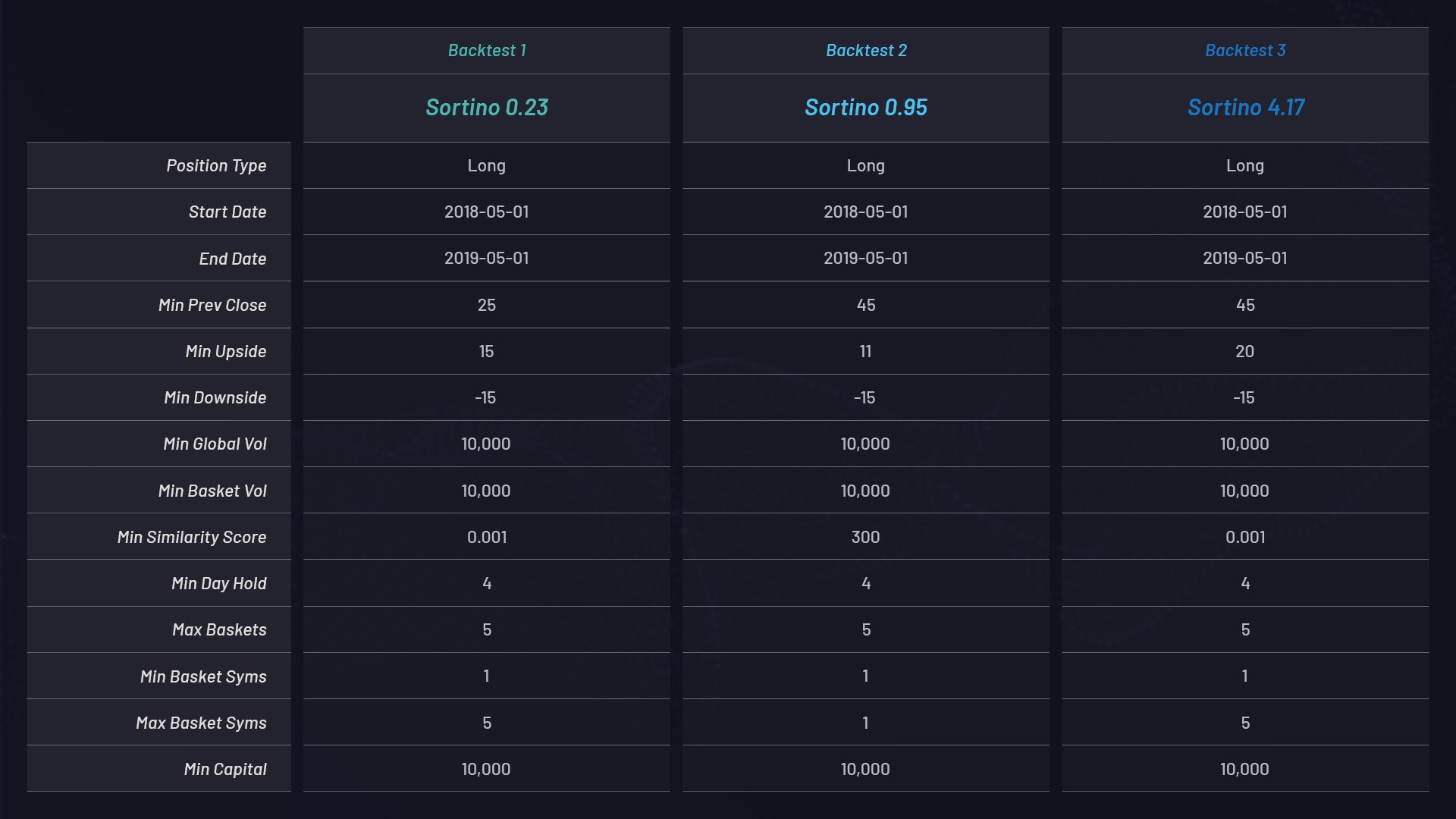
Veja abaixo três backtests separados usando cestas apenas com posições longas e diferentes configurações de parâmetros. Cada uma tem uma alocação de capital de 10 mil dólares e é classificada por seu índice de Sortino:
Configurações de parâmetros para cada cesta:
Abaixo, os resultados do backtest são carregados no Kibana, e as estatísticas são exibidas:
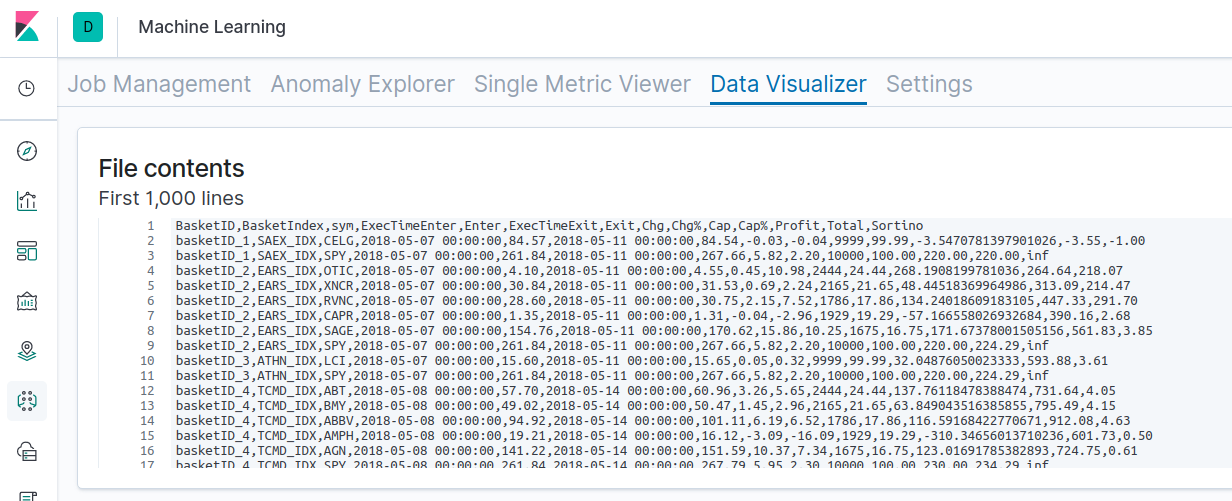
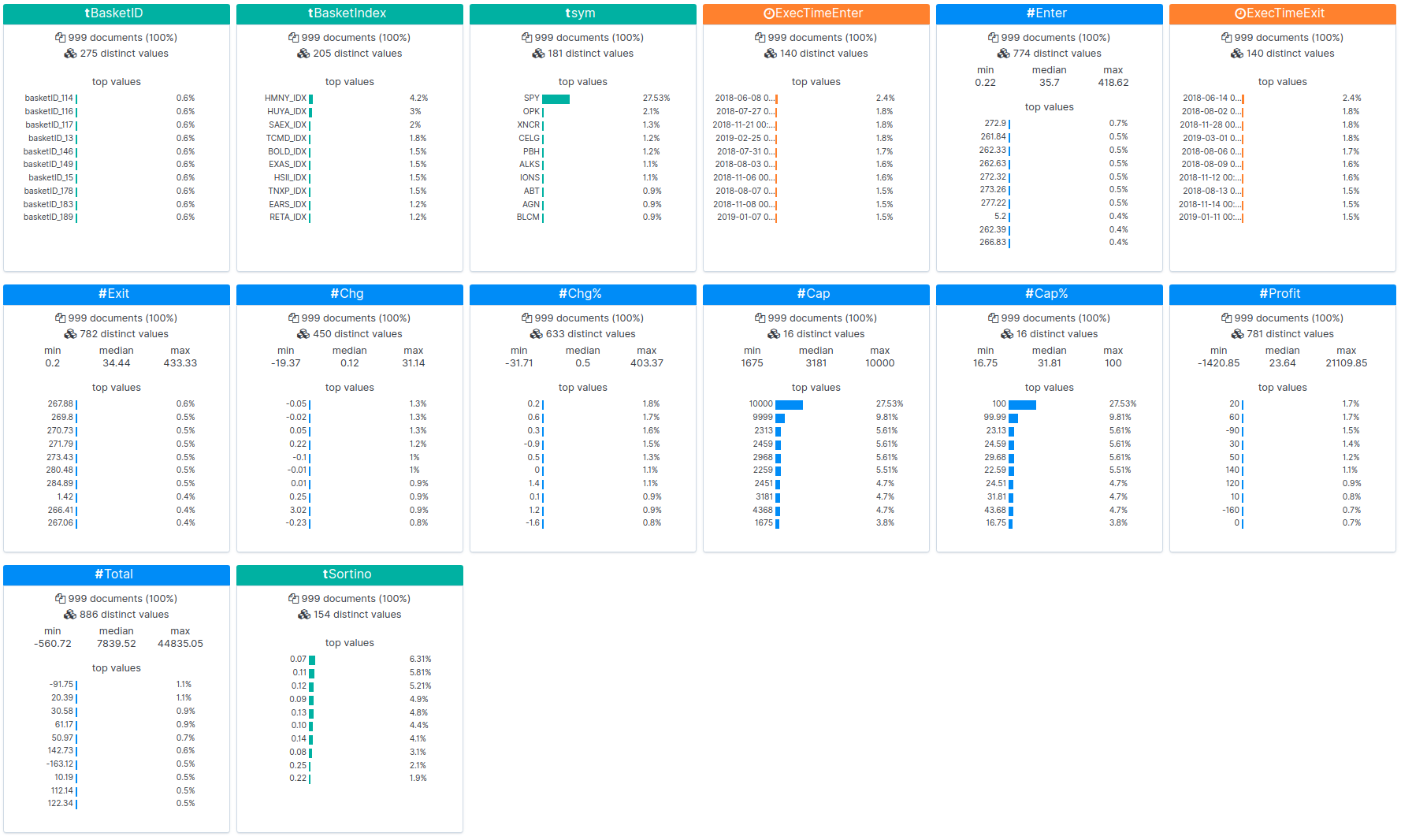
Você pode visualizar os resultados brutos de um dos backtests aqui. Os conjuntos de dados de NLU aumentados pelo backtesting podem ser executados usando as etapas a seguir. Usamos estas etapas para gerar os resultados acima.
- O word embedding usado como vetores de características é gerado para todas as ações da NYSE e da Nasdaq usando a API do conjunto de dados.
- Um período histórico de um ano de dados de preços de 1º de maio de 2018 a 1º de maio de 2019 para todas as ações da NYSE e da Nasdaq é usado para verificar os desencadeadores de eventos especiais definidos por um pico no preço das ações.
- Para qualquer ação com picos superiores a um limite percentual escolhido, por exemplo, +15%, um grupo ou cesta de ações relacionadas é gerado usando o conjunto de dados. Veja o parâmetro MIN_UPSIDE na tabela acima.
- Parâmetros de filtragem como volume, capitalização de mercado, flutuação e outros são usados para refinar a cesta.
- Os horários de entrada e saída da negociação são definidos como retenções de quatro dias.
- Os retornos são calculados para cestas de posições longas e curtas, juntamente com o S&P 500 para comparação de linha de base, além dos índices de Sortino.
- Conjuntos de dados e retornos são monitorados, visualizados e interpretados via Canvas.
Retornos do backtest
Vamos dar uma olhada nos resultados gerais de três backtests de um ano com o Canvas, de 1º de maio de 2018 a 1º de maio de 2019, com base no desempenho de todas as cestas geradas durante esse período.
O backtesting permitiu a detecção de empresas de capital aberto com preços de ações que aumentaram de valor após a aquisição da Celgene. Um conjunto de dados aumentado é carregado onde é possível observar correlações. Cestas (grupos) gerados a partir do conjunto de dados também podem ser visualizados com base em seu desempenho. Uma cesta pode ser comparada ao desempenho de linha de base do S&P 500 para garantir que você esteja obtendo um retorno do investimento acima do índice. Cestas individuais são monitoradas para determinar se estão superando o índice S&P 500 (SPY):
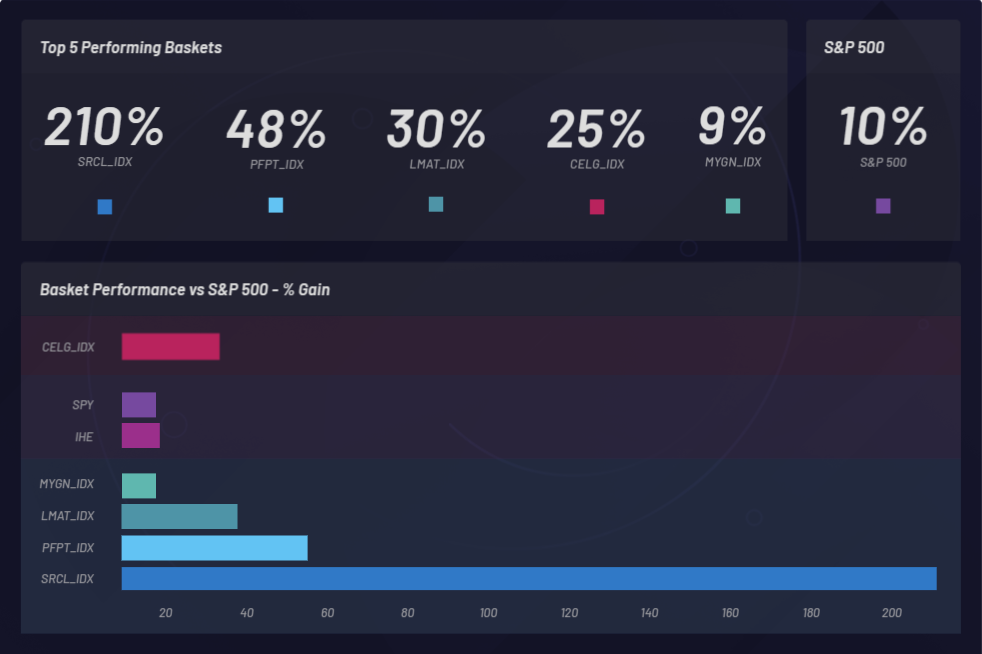
O gráfico abaixo mostra o monitoramento de um evento e os movimentos simpáticos latentes que são resultantes em outras ações. Nesse caso, CELG (Celgene) foi o evento e EPZM (Epizyme) foi escolhida como um componente resultante da cesta. As correlações baseadas em NLU podem prever correlações baseadas em preços. A captura de atualizações de correlações baseadas em NLU entre ações e eventos pode fornecer uma vantagem com base na arbitragem de informações assimétricas. Ser capaz de se posicionar à frente do mercado só poderá acontecer se houver uma resposta atrasada na ação ou na correlação de preços, em oposição a quaisquer correlações baseadas em NLU entre a CELG e a EPZM, que podem ser observadas aqui:
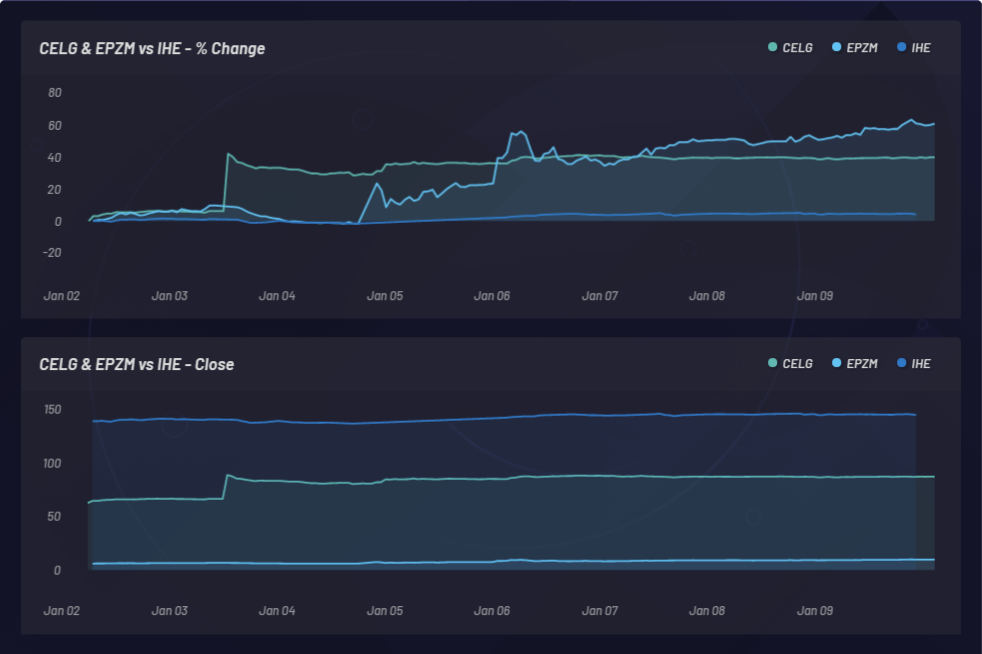
CELG (Celgene) x AGIO (Agios Pharmaceuticals):
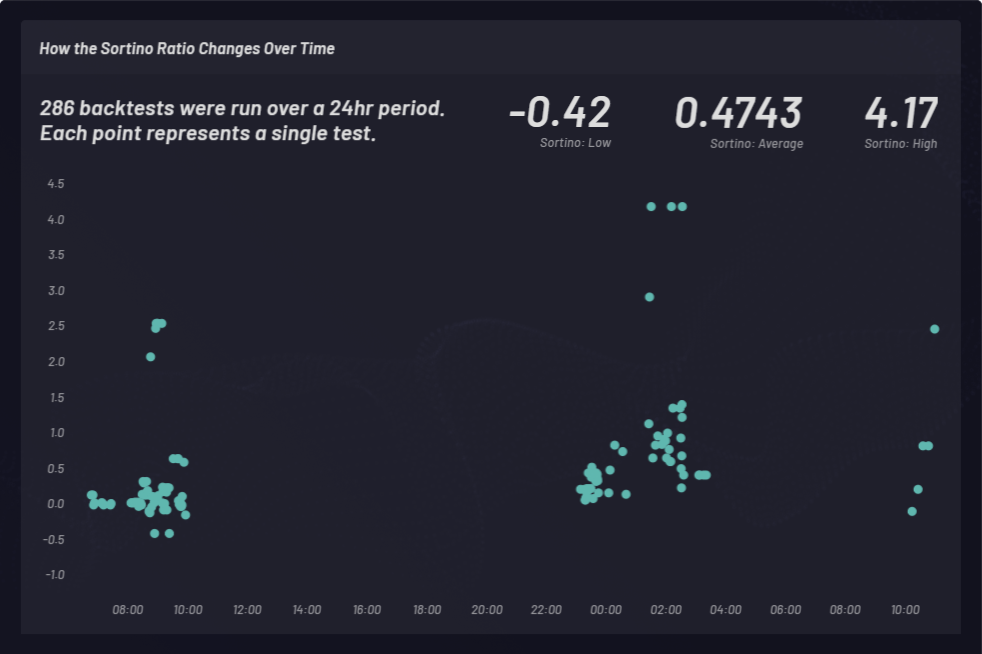
Um índice de Sortino é calculado para medir retornos ajustados ao risco. No exemplo a seguir, o índice de Sortino foi escolhido em vez do índice de Sharpe para fatorar a volatilidade positiva um pouco melhor. O índice de Sortino muda com o tempo. Os backtests foram realizados com cestas de posições longas em três momentos diferentes durante um período de 24 horas, como mostrado abaixo. Um total de 286 execuções de backtest com diferentes configurações de parâmetros globais foram realizadas. Cada ponto no grupo abaixo representa um único backtest com seu índice de Sortino correspondente no eixo y:
Utilização de correlações variáveis
A National Library of Medicine (NLM) publica cerca de 1,5 mil artigos científicos revisados por pares a cada 24 horas. A Vectorspace usa a NLM como uma de suas fontes de dados.

As correlações entre genes, compostos de medicamentos, notícias de empresas farmacêuticas e empresas de capital aberto mudam com o tempo, às vezes em segundos. Isso pode afetar as proporções entre sinal e ruído na descoberta de compostos que sejam candidatos a reaproveitamento e reposicionamento de medicamentos.
Se houver alterações nos valores de correlação entre uma empresa farmacêutica de capital aberto e um gene, proteína, composto de medicamento, micróbio ou doença, essas novas relações serão refletidas no conjunto de dados e poderão ser monitoradas quase em tempo real com o Canvas.

O uso do controle de contexto na criação de conjuntos de dados baseados em NLU pode resultar em novos tipos de pontuação de correlação. Controlar o contexto dos relacionamentos de NLU pode ser vital para obter novos insights.
Ao adicionar controle de contexto, os conjuntos de dados baseados em NLU podem ajudar os pesquisadores a responder a perguntas como “Quais ações de empresas farmacêuticas estão correlacionadas a estes compostos de medicamentos no contexto dos genes de reparo de danos ao DNA com base nas pesquisas mais recentes?”, enquanto oferecem maneiras poderosas de visualizar e interpretar as respostas ou resultados no Canvas.
Como aproximadamente 1,5 mil novos artigos científicos revisados por pares são publicados a cada 24 horas, juntamente com notícias e outros registros públicos, ocorrem alterações nas pontuações de correlação, as quais, por sua vez, definem as relações atualizadas entre, por exemplo, empresas farmacêuticas de capital aberto e compostos de medicamentos. Combinados com fontes de dados internas, os conjuntos de dados baseados em NLU podem fornecer sinais exclusivos.
Conclusão
As correlações baseadas no processamento de linguagem natural (NLP, pelas iniciais em inglês) e na NLU podem abrir caminhos para gerar novos insights, hipóteses ou descobertas.
Pode-se fazer muito mais com os conjuntos de dados de NLU nas ciências biológicas e nos mercados financeiros relacionados a correlações contextualizadas, fontes de dados alternativas, vetores de características, visualização e interpretação. Talvez no futuro nossas equipes discutam alguns desses tópicos, incluindo o aumento de conjuntos de dados de série temporal para uma variedade de ativos negociáveis. Com vetores de características de NLU individuais, nossas equipes podem explicar como construir redes de relacionamento baseadas em gráficos ou redes inteiras de clusters renderizados com o Canvas e outras ferramentas no Elastic Stack. Além disso, nossas equipes podem descrever maneiras de fazer com que as máquinas transacionem vetores de características entre si para minimizar as funções de perda selecionadas com base em uma API de token utilitário combinada com um livro de ofertas de mercado aberto.
A Vectorspace continua a criar aplicações relacionadas para conjuntos de dados na análise do reparo de danos cromossômicos conectados à radiação LET (radiação espacial), epigenética e expectativa de vida relacionadas ao voo espacial humano. Tudo isso se torna mais criativo e útil com o Elastic Stack, incluindo o Canvas e outras ferramentas. Se quiser saber mais sobre aumentos de conjuntos de dados ou como obter créditos gratuitos da API de token utilitário, entre em contato com a Vectorspace e forneceremos com o maior prazer os dados necessários para você começar.
E se quiser experimentar o Elastic Stack, faça uma avaliação gratuita de 14 dias do Elasticsearch Service ou baixe-o como parte da distribuição padrão.
A Vectorspace inventa sistemas e conjuntos de dados que imitam a cognição humana para fins de arbitragem de informações e descoberta científica (IA/NLP/ML de alto nível) para a Genentech, o Lawrence Berkeley National Laboratory, o Departamento de Energia (DOE) dos EUA, o Departamento de Defesa (DOD) dos EUA, a divisão de biociências espaciais da NASA, a DARPA e a SPAWAR (divisão Space and Naval Warfare Systems da Marinha dos EUA), entre outros.
Shaun McGough é gerente de produtos da Elastic, com experiência de domínio em visualização de dados e investimentos alternativos.