



Elastic Enterprise Search: 전체 비즈니스 시스템 및 소프트웨어 검색
개요
Elastic Enterprise Search 소개
Elastic Enterprise Search에 대해 좀 더 숙지하시면서 Elastic Cloud를 통해 데이터를 수집하고 확인하는 방법에 대한 개요를 더 자세히 알아보세요.
데이터 온보딩
Enterprise Search 빠른 시작
이 3개의 빠른 시작 동영상 시리즈에서는, 앱과 웹사이트를 위해 미리 조정된 정확도를 갖춘 현대적이고 자연스러운 검색 환경인 Elastic Enterprise Search에 대해 알아보시게 됩니다. 설정, 데이터 수집, 검색 인터페이스 찾기, 필요에 따라 검색 엔진 분석 및 조정 작업을 얼마나 빨리 수행할 수 있는지 확인하세요. Elastic Enterprise Search란 무엇인가, Elastic Enterprise Search로 데이터 색인, 검색 분석 및 개선 등의 주제를 다루게 됩니다.
Elastic Cloud 계정 생성하기
14일 체험판으로 시작해 보세요. cloud.elastic.co에 접속하여 계정을 생성한 후에, 아래 단계를 따라 전 세계 50개 이상의 지원 리전 중 하나에서 Elastic 스택을 처음 시작하는 방법에 대해 알아보세요.
Edit setting(편집 설정)을 클릭하면 Google Cloud, Microsoft Azure, AWS 등 클라우드 서비스 제공자를 선택하실 수 있습니다. 클라우드 서비스 제공자를 선택하고 나면, 관련 리전을 선택하실 수 있게 됩니다. 다음으로, 몇 가지 하드웨어 프로파일 중에서 선택하여 필요에 따라 원하는 대로 배포를 사용자 정의할 수 있는 옵션이 있습니다. 또한 최신 버전의 Elastic이 이미 미리 선택되어 있습니다.
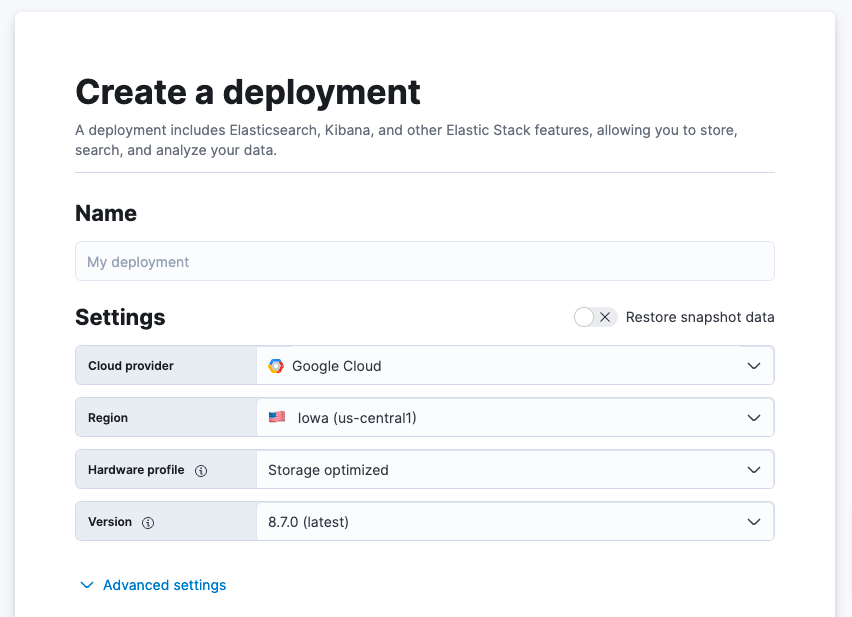
이 사용 사례의 경우, 4GB RAM 인스턴스가 필요합니다. 이를 생성하려면, Advanced settings(고급 설정)를 선택한 다음, 아래의 Enterprise Search 인스턴스로 스크롤하고 드롭다운을 선택하여 배포를 생성하기 전에 Size per zone(영역당 크기)을 4GB RAM으로 늘립니다. 이 작업을 완료한 후 Create deployment(배포 생성하기)를 선택하실 수 있습니다.
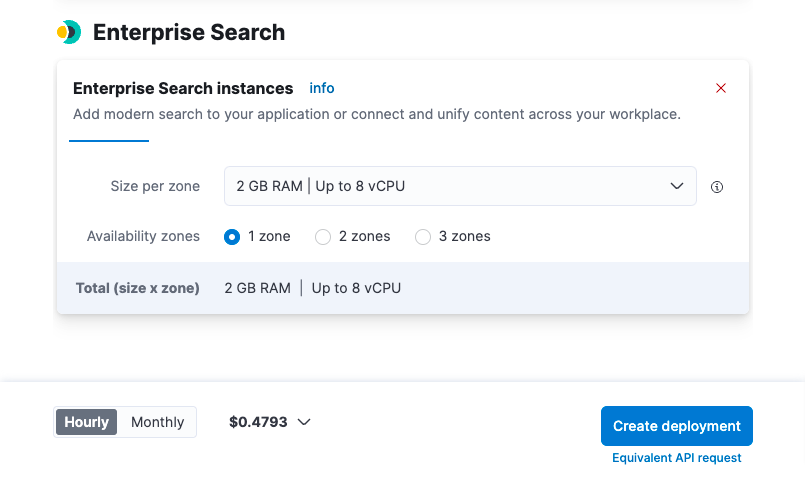
배포가 생성되는 동안 사용자 이름과 비밀번호가 제공됩니다. 통합을 설치할 때 필요할 때 이것을 복사하거나 다운로드해야 합니다.
배포가 완료되면 Search across databases and business systems(데이터베이스 및 비즈니스 시스템 전체에서 검색)를 선택합니다.
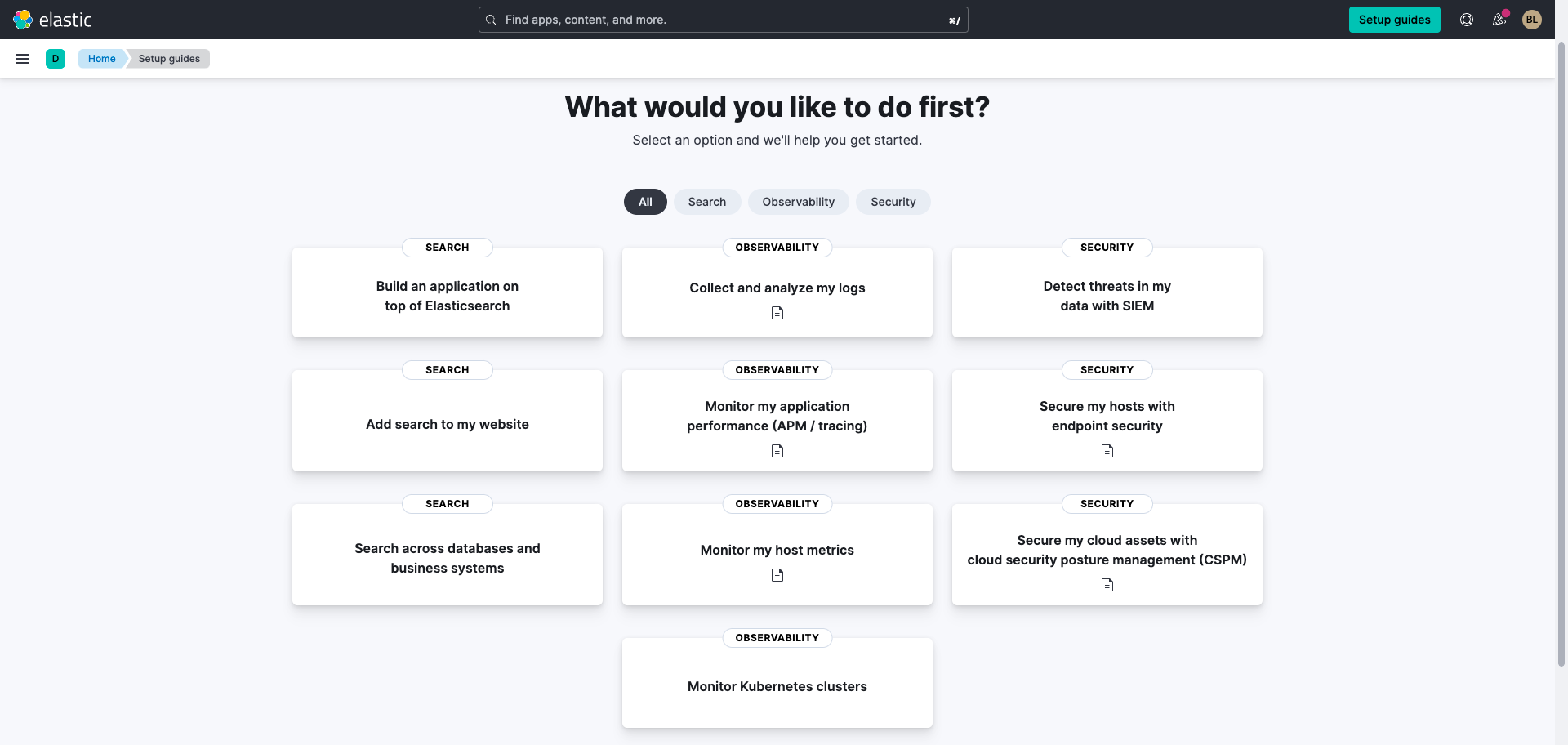
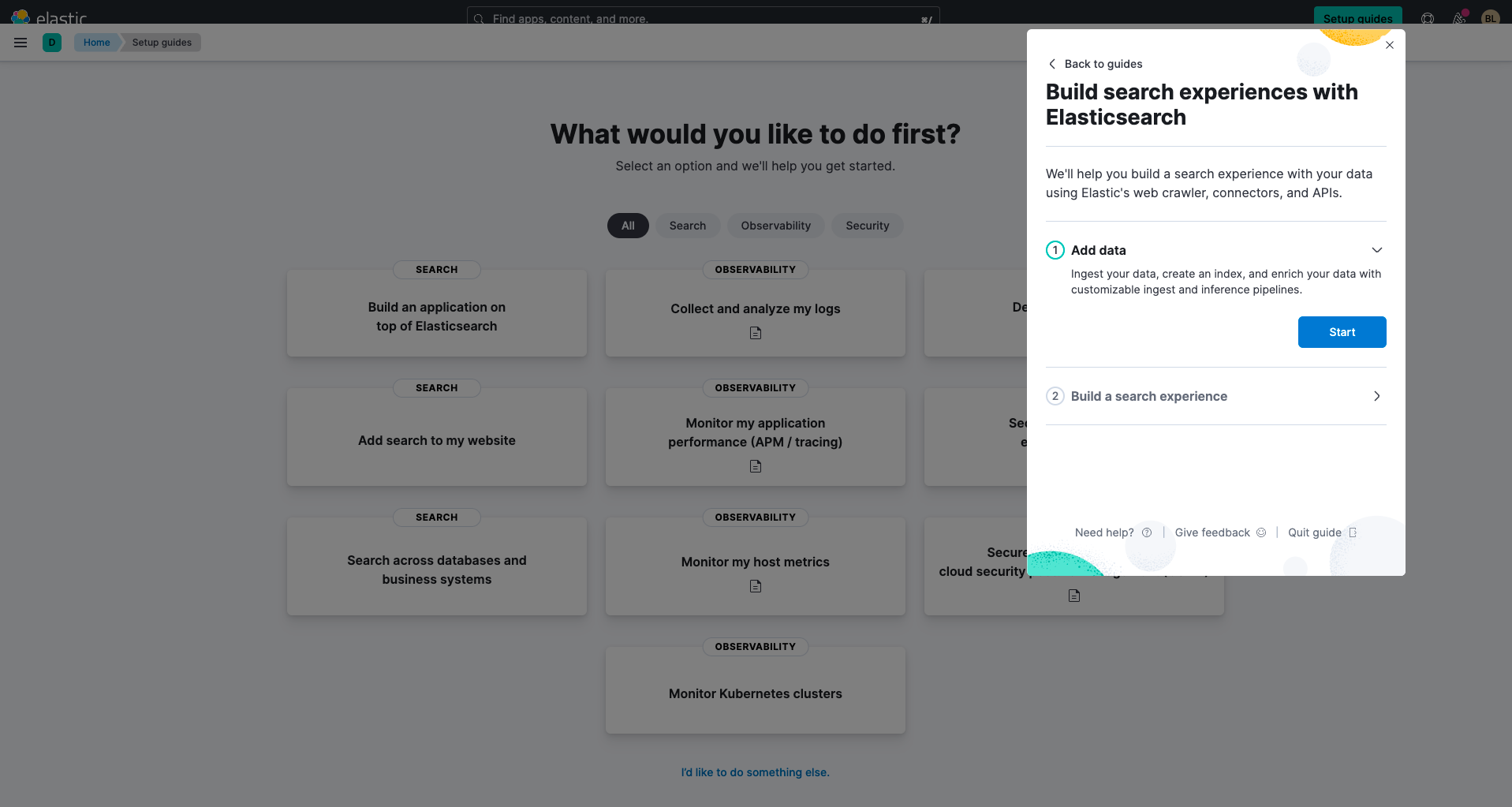
Elasticsearch를 사용하여 데이터베이스에 연결
Elastic을 처음 사용하는 경우에는 수집 방법을 선택하셔야 합니다. 데이터베이스에서 검색하려면 수집 방법으로 Use a connector(커넥터 사용)를 선택하는 것이 좋습니다.
다음으로 MongoDB를 선택하고 MongoDB 커넥터의 구성에서 위에서 수집한 정보를 입력합니다. 지정된 특정 호스트에 대해 읽기를 강제할 이유가 없는 한 'Direct connection(직접 연결)'을 'false'로 설정해야 합니다(자세한 내용은 MongoDB connection guide(MongoDB 연결 가이드) 참조)
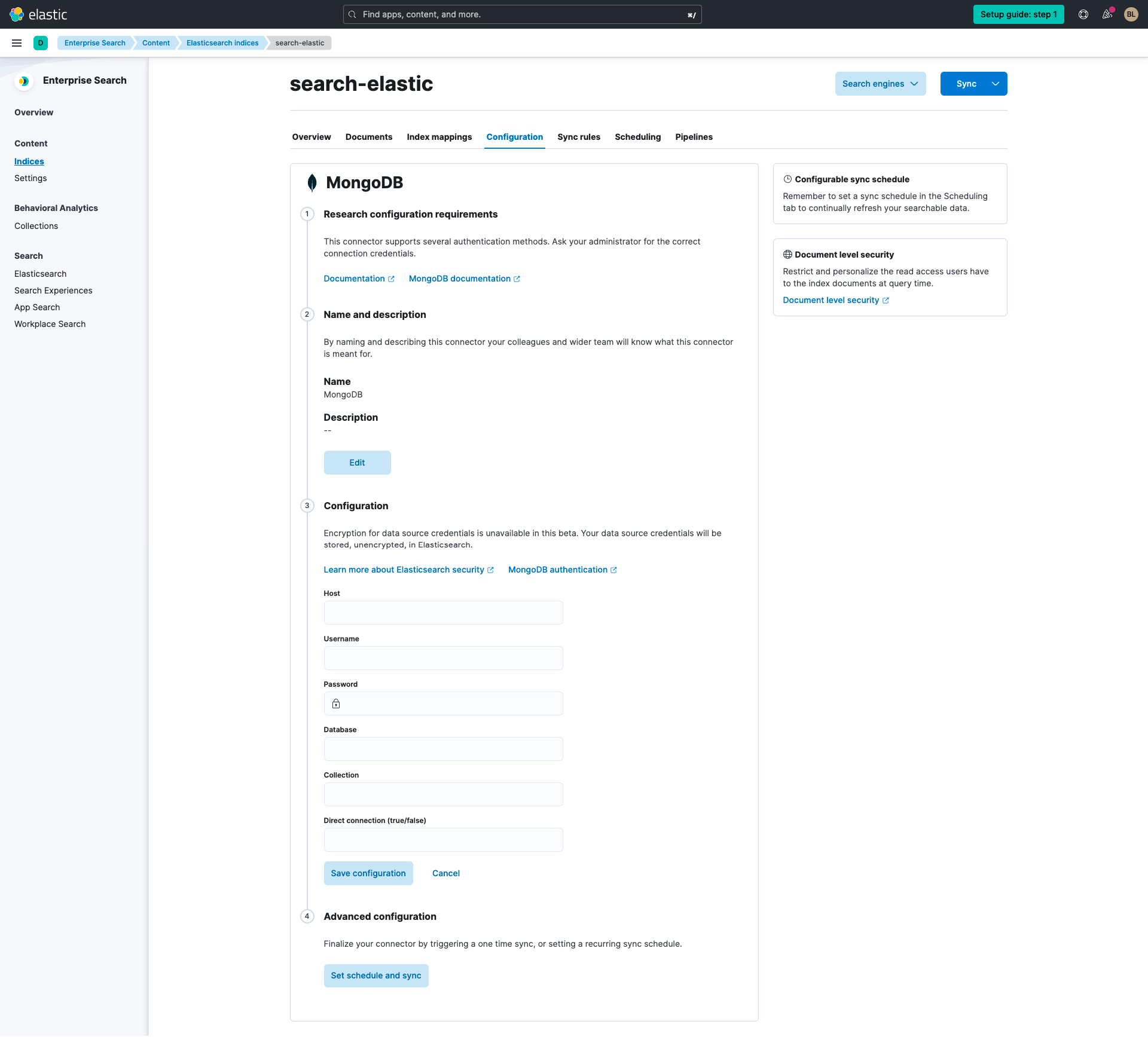
정보를 입력한 후 Scheduling(스케줄링) 탭을 선택하여 사용 사례에 대해 선호하는 데이터베이스 동기화 일정을 설정합니다. 예약 옵션을 구성한 후, Sync(동기화)를 클릭하여 프로세스를 완료합니다.
Elastic Enterprise Search 활용
Elastic으로 검색 경험을 구축하세요
뛰어난 검색 경험에는 데이터 수집, 검색 인터페이스 구축, 분석 보기 및 정확도를 위한 검색 튜닝 도구가 포함됩니다. 아래 웨비나에서 검색 애플리케이션 구축을 시작하는 방법에 대해 알아보세요.
Elastic을 사용하여 검색 개인 맞춤 설정
검색 준비를 이미 완료하고 한 단계 더 나아가려면, 검색 경험을 개인 맞춤화하는 데 대한 웨비나를 소개합니다.
또한 분석을 사용하여 검색 경험을 강화할 수 있는 방법에 대한 자세한 내용은 이 블로그를 확인하세요.
다음 단계
시간을 내셔서 Elastic Cloud를 통해 데이터베이스를 Elasticsearch에 연결해 주셔서 감사합니다.
Elastic과 함께 하는 여정을 시작하면서, 환경 전체에 배포할 때 사용자로서 관리해야 하는 운영, 보안 및 데이터 구성 요소를 이해해야 합니다.