벡터 데이터베이스가 수행해야 하는 기능은 무엇일까요?




Elasticsearch: 개발자들의 사랑을 받는 단순한 벡터 그 이상
틈이나 타협이 없습니다. 모든 것이 완벽하게 조화를 이루도록 설계되었기 때문입니다.

전화 한 통이면 끝
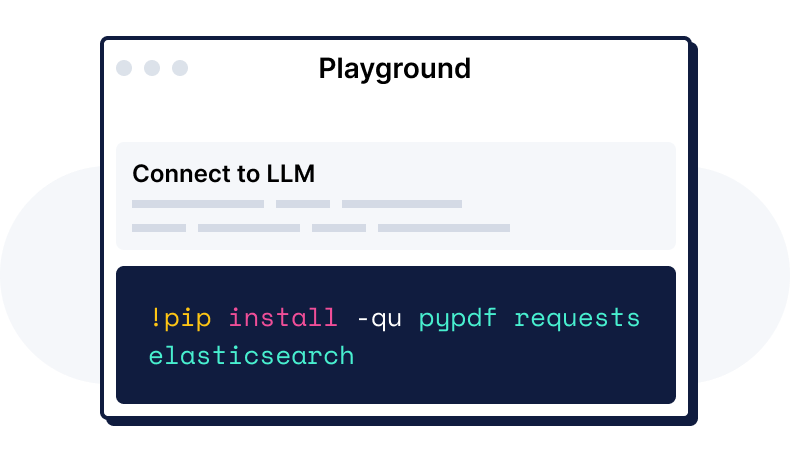
텍스트, 임베딩, 지리 정보, 시계열 데이터, 메타데이터에 대해 인덱싱, 검색, 필터링을 수행하고 역할 기반 접근 제어(RBAC)를 적용하세요.
데이터를 밀집 벡터로 변환하여 데이터에서 의미, 컨텍스트 및 연결을 캡처합니다. 임베딩 블로그 만들기
POST _inference/my-e5-endpoint { "input": "How many adult mallard ducks fit in an american football field?" }
POST _inference/my-e5-endpoint
{
"input": "How many adult mallard ducks fit in an american football field?"
}
동급 최고 성능이 내장되어 있습니다
Elasticsearch에 내장된 Jina AI 모델로 시작해 보세요. 또한 AI 에코시스템 전반에 걸친 네이티브 통합을 통해 기존에 사용 중인 모델을 연동할 수도 있습니다.







고품질 유사 항목군
프롬프트에서 제품까지, 여러 조직에서 Elastic의 차세대 검색 구축 능력을 신뢰합니다.
고객 스포트라이트

영국 최대의 채용 대행사인 Reed는 Elasticsearch의 벡터 임베딩을 사용하여 구직자와 고용주를 연결합니다.
고객 스포트라이트

Stack Overflow는 개발자 지식 기반에서 신뢰할 수 있는 정보를 더 빨리 검색할 수 있도록 인간 전문가의 역량과 생성형 AI를 결합합니다.
고객 스포트라이트

Adobe는 Elastic을 통해 여러 사용 사례를 확장하고 관리하며 머신 러닝 기능을 활용합니다.
벡터 데이터베이스 상위 집합
구축하려는 벡터 검색 경험을 기반으로 벡터 데이터베이스를 선택하세요.
기타 벡터 데이터베이스
Elasticsearch
유연한 문서 모델
일부 지원
전체 지원(무료)
안전한 저장 공간(문서 및 필드 수준 보안)
일부 지원
전체 지원(유료)
정형 및 비정형 데이터 처리
일부 지원
전체 지원(무료)
수집 도구(클라이언트, 웹 크롤러*, 커넥터*, 유추 파이프라인*)
일부 지원
전체 지원(유료)
실시간 문서 및 메타데이터 업데이트
일부 지원
전체 지원(무료)
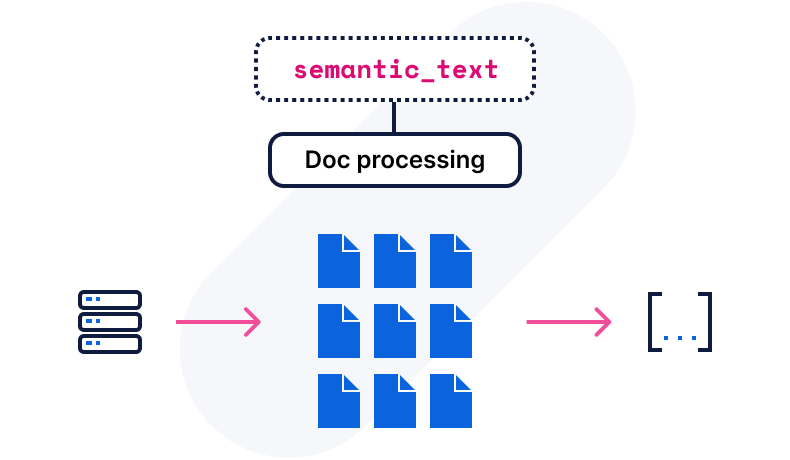
벡터 저장 공간 최적화를 위한 시맨틱 텍스트
일부 지원
전체 지원(무료)
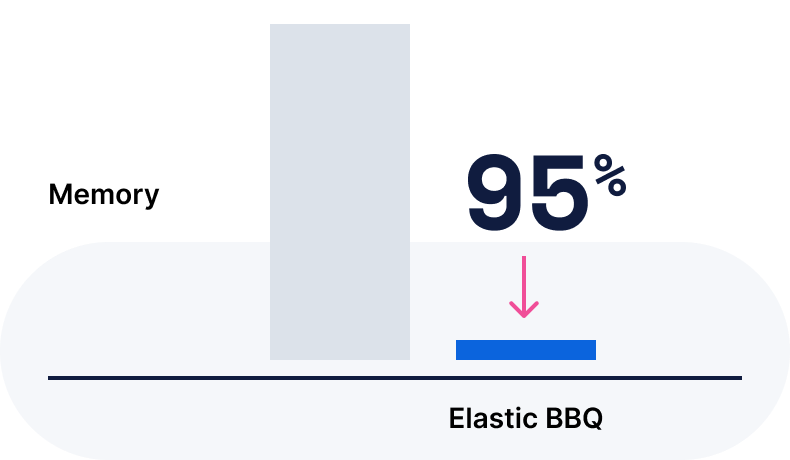
임베딩 저장(기본값은 int8, 그 외 float, int4, bit, BBQ 등 옵션 제공)
일부 지원
전체 지원(무료)
임베딩 생성
일부 지원
전체 지원(유료)
임베딩 검색 (벡터 검색)
전체 지원
전체 지원(무료)
풀텍스트 검색(BM25)
일부 지원
전체 지원(무료)
네이티브 하이브리드 검색(BM25 + 벡터 검색)
일부 지원
전체 지원(무료)
필터링, 패싯 검색, 집계
일부 지원
전체 지원(무료)
검색 자동 완성
일부 지원
전체 지원(무료)
여러 데이터 유형(텍스트, 벡터, 위치 정보 등)에 최적화됨
일부 지원
전체 지원(무료)
클러스터 간 검색
일부 지원
전체 지원(무료)
온프레미스 및 에어갭 배포
지원 없음
전체 지원(무료)
여러 임베딩 모델 유형 지원
일부 지원
전체 지원(유료)
기본 제공 시맨틱 검색 모델
지원 없음
전체 지원(유료)
기본 제공 순위 재지정 모델 및 순위 학습
지원 없음
전체 지원(유료)
파이프 쿼리(ES|QL)
지원 없음
전체 지원(무료)
Observability 도구(Kibana)
지원 없음
전체 지원(무료)
AI 어시스턴트
지원 없음
전체 지원(유료)
검색 UI 구성 요소
지원 없음
전체 지원(무료)
자주 묻는 질문
벡터 데이터베이스란 무엇이며 어떻게 작동합니까?
벡터 데이터베이스란 무엇이며 어떻게 작동합니까?
벡터 데이터베이스는 정보를 벡터, 즉 벡터 임베딩이라고도 하는 데이터 객체의 수치적 표현으로 저장합니다. 이미지, 텍스트, 비디오, 오디오 등 정형, 비정형, 반정형 데이터로 이루어진 방대한 데이터 세트 전반에서 다중 모드 검색을 위해 벡터 임베딩을 사용합니다. 벡터 데이터베이스는 벡터 임베딩을 관리하도록 구축되었기 때문에 완벽한 데이터 관리 솔루션을 제공합니다.
벡터 임베딩이란 무엇인가요?
벡터 임베딩이란 무엇인가요?
벡터 임베딩은 머신 러닝 모델을 사용하여 텍스트를 숫자로 변환하여 벡터 검색을 수행할 수 있게 합니다. 임베딩은 데이터를 벡터로 변환하여 이 공간에서 항목 간의 유사성을 쉽게 비교, 검색 및 분석할 수 있게 해줍니다.
벡터 데이터베이스의 이점은 무엇입니까?
벡터 데이터베이스의 이점은 무엇입니까?
벡터 데이터베이스는 온프레미스, 에어갭, 주권형 클라우드 환경 간의 원활한 데이터 마이그레이션을 지원하며, 벡터 임베딩을 위한 저장 공간을 제공함으로써 확장성에서 효율성을 제공합니다. 벡터 데이터베이스는 유사성 검색에 탁월하여 관련 항목을 쉽게 찾을 수 있게 해주므로 추천 시스템, 이미지 검색 및 콘텐츠 검색에 필수적입니다. 시맨틱 검색 기능을 갖추고 있어 단순한 키워드 매칭을 넘어 의미와 맥락에 기반한 결과를 제공합니다. 벡터 임베딩을 저장함으로써 AI 및 머신 러닝 애플리케이션을 지원하여 NLP 및 추천 모델을 더 쉽게 배포할 수 있습니다. 규제 대상 또는 기밀 환경(정부, 국방 및 금융 서비스)의 조직을 위해 Elasticsearch는 외부 연결이 필요 없는 완전한 온프레미스 및 에어갭 배포를 지원합니다.
Elasticsearch는 벡터 데이터베이스인가요?
Elasticsearch는 벡터 데이터베이스인가요?
예, Elasticsearch는 세계에서 가장 널리 배포된 오픈 소스 벡터 데이터베이스로, 벡터 임베딩을 규모에 맞게 생성, 저장 및 검색하는 효율적인 방법을 제공합니다. Elastic의 엔터프라이즈급 벡터 데이터베이스를 사용하면 빠르게 변화하는 데이터 환경에서도 빠른 쿼리 시간과 최적의 성능을 달성할 수 있습니다. 확장 가능하도록 설계되어 개발 프로세스를 간소화하면서 관련성 높고 개인화된 검색 결과를 제공합니다.
왜 벡터 데이터베이스로 Elastic을 선택해야 하나요?
왜 벡터 데이터베이스로 Elastic을 선택해야 하나요?
Elasticsearch를 온프레미스 또는 에어갭 방식의 벡터 데이터베이스로 실행할 수 있나요?
Elasticsearch를 온프레미스 또는 에어갭 방식의 벡터 데이터베이스로 실행할 수 있나요?
예. Elasticsearch는 베어메탈, 프라이빗 클라우드 또는 외부 연결이 없는 완전한 에어갭 네트워크에서 완전히 온프레미스로 배포할 수 있습니다. 정부 기관, 국방 계약자 및 규제 대상 기업에서는 Elastic Cloud Enterprise(ECE)를 사용하여 기밀 환경 및 연결되지 않은 환경을 포함한 온프레미스 Elasticsearch 클러스터를 대규모로 오케스트레이션합니다. Elastic Cloud에서 사용할 수 있는 모든 벡터 검색, 하이브리드 검색 및 RAG 기능은 온프레미스 배포에서도 동일하게 사용할 수 있습니다.