정의
벡터 검색은 무엇인가요?
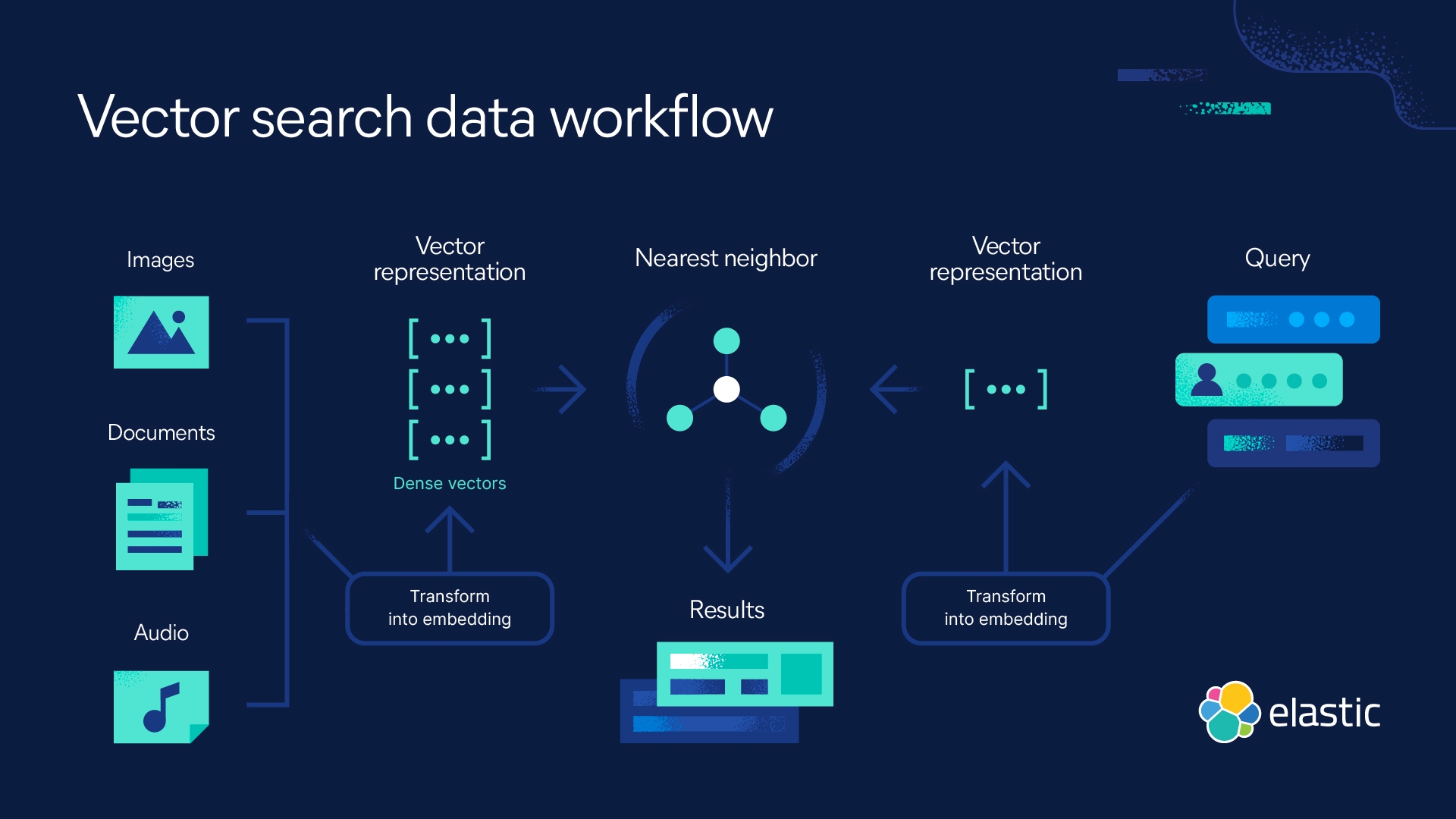
벡터 검색은 머신 러닝(ML)을 활용하여 텍스트, 이미지 등 비정형 데이터의 의미와 컨텍스트를 캡처한 후 이를 숫자 표현으로 변환합니다. 시맨틱 검색에 자주 사용되는 벡터 검색은 근사 최근접 이웃(ANN) 알고리즘을 사용하여 유사한 데이터를 찾습니다. 기존 키워드 검색과 비교할 때 벡터 검색은 더 정확한 결과를 제공하고 더 빠르게 실행됩니다.

벡터 검색이 중요한 이유
무언가를 찾지만 정확한 명칭이 무엇인지 모르는 경우가 얼마나 자주 있으신가요? 아마도 그것이 어떤 일을 하는지 알거나 그것에 대해 설명할 수 있으실 겁니다. 하지만 키워드가 없으면 계속해서 검색을 하게 됩니다.
벡터 검색은 이러한 한계를 극복하고 의미를 기반으로 검색할 수 있도록 지원합니다. 유사성 검색을 기반으로 쿼리에 대한 답변을 신속하게 제공할 수 있습니다. 벡터 임베딩이 동영상, 이미지 및 오디오 등과 같이 텍스트를 넘어 비정형 데이터를 캡처하기 때문입니다. 벡터 검색을 필터링 및 집계와 결합하여 하이브리드 검색을 구현하고 이를 기존 점수와 결합함으로써 정확도를 최적화하면 검색 경험을 향상시킬 수 있습니다.
벡터 검색 사용 사례
벡터 검색은 차세대 검색 경험을 강화할 뿐만 아니라 다양한 새로운 가능성의 문을 열어줍니다.
시작하는 방법
Elastic으로 간편해진 벡터 검색 및 NLP
큰 노력 없이도 벡터 검색을 구현하고 NLP 모델을 적용할 수 있습니다. Elasticsearch Relevance Engine™(ESRE)을 사용하면 생성형 AI 및 대규모 언어 모델(LLM)과 함께 사용할 수 있는 AI 검색 애플리케이션을 구축하기 위한 툴킷을 확보할 수 있습니다.
ESRE를 사용하면 혁신적인 검색 애플리케이션을 구축하고, 임베딩을 생성하고, 벡터를 저장 및 검색하고, Elastic의 Learned Sparse Encoder를 사용하여 시맨틱 검색을 구현할 수 있습니다. Elasticsearch를 벡터 데이터베이스로 사용하는 방법에 대해 자세히 알아거나, 벡터 검색을 위한 자기 주도형 실습을 체험해 보세요.
