Introducing Elastic Learned Sparse Encoder: Elastic’s AI model for semantic search



트위터에서 공유하기


링크드인에서 공유하기


페이스북에서 공유하기


이메일로 공유하기


인쇄하기
Searching for meaning, not just words
We are thrilled to share that with 8.8, Elastic® offers semantic search out of the box. Semantic search is designed to search with the intent or meaning of the text as opposed to a lexical match or keyword query. It is a qualitative leap compared to traditional lexical term-based search, offering breakthrough relevance. It captures relationships between words on the conceptual level, understanding the context and surfacing relevant results based on meanings, instead of simply query terms.
Aiming to eliminate the barrier to AI-powered search, in 8.8 we are introducing a new semantic search model in technical preview, trained and optimized by Elastic. Use it to instantly leverage superior semantic relevance with vector and hybrid search, natively in Elastic.
Introducing Elastic Learned Sparse Encoder, a new text expansion model for semantic search
Elastic has been investing in vector search and AI for three years and released support for approximate nearest neighbor search in 8.0 (with HNSW in Lucene). Recognizing that the landscape of tools to implement semantic search is rapidly evolving, we have offered third-party model deployment and management, both programmatically and through the UI. With the combined capabilities, you can onboard your vector models (embeddings) and perform vector search through the familiar search APIs, which we enhanced with vector capabilities.
Let's say an employee is looking for leadership courses. With vector search in Elastic Enterprise Search, we can better understand the user’s intent and return courses that are tailored to their industry, organization, and role.
Jon Ducrou, Senior Vice President of Engineering, Go1
The results from using vector search have been astonishing. But to achieve them, organizations need significant expertise and effort that go well beyond typical software productization. This includes annotating a sufficient number of queries within the domain in which search will be performed (typically in the order of tens of thousands), in-domain re-training the machine learning (so called “embedding”) model to achieve domain adaptation, and maintaining the models against drift. At the same time, you may not want to rely on third-party models due to privacy, support, competitiveness, or licensing concerns. As a result, AI-powered search is still outside the reach of the majority of users.
With that in mind, in 8.8 we are introducing Elastic Learned Sparse Encoder — in technical preview. You can start using this new retrieval model with a click of a button from within the Elastic UI for a wide array of use cases, and you need exactly zero machine learning expertise or deployment effort.
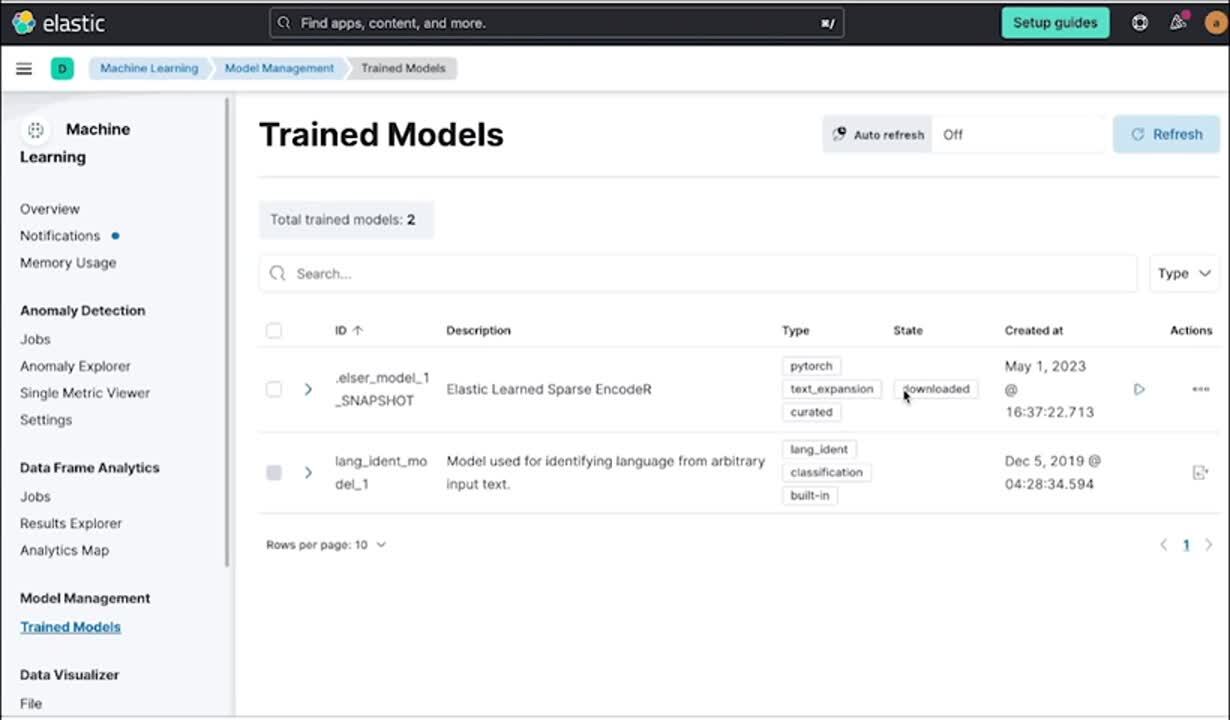
Superior semantic search out of the box
Elastic’s Learned Sparse Encoder uses text-expansion to breathe meaning into simple search queries and supercharge relevance. It captures the semantic relationships between words in the English language and based on them, it expands search queries to include relevant terms that are not present in the query. This is more powerful than adding synonyms with lexical scoring (BM25) because it uses this deeper language-scale knowledge to optimize for relevance. And not only that, but context is also factored in, helping to eliminate ambiguity from words that may have different interpretations in different sentences.
As a result, this model helps mitigate the vocabulary mismatch problem: Even if the query terms are not present in the documents, Elastic Learned Sparse Encoder will return relevant documents if they exist.
Based on our comparison, this novel retrieval model outperforms lexical search in 11 out of 12 prominent relevance benchmarks, and the combination of both using hybrid search in all 12 relevance benchmarks. If you’ve already spent the effort to fine-tune lexical search in your domain, you can get an additional boost from hybrid scoring!
Why choose Elastic’s Learned Sparse Encoder?
Above all, you can use this new model out of the box, without domain adaptation — we’ll explain that more below; it is a sparse-vector model that performs well out-of-domain or zero-shot. Let’s break down how these terms directly translate to value for your search application.
- Our model is trained and architected in such a way that you do not need to fine tune it on your data. As an out-of-domain model, it outperforms dense vector models when no domain-specific retraining is applied. In other words, just click “deploy” on the UI and start using state-of-the-art semantic search with your data.
- Our model outperforms SPLADE (Sparse Lexical and Expansion Model), the previous out-of-domain, sparse-vector, text-expansion champion, as measured by the same benchmarks.
- In addition, you don’t have to worry about licensing, support, continuity of competitiveness, and extensibility beyond your Elastic license tier. For example, SPLADE is licensed for non-commercial use only. Our model is available on our Platinum subscription tier.
- As sparse-vector representation, it uses the Elasticsearch, Lucene-based inverted index. This means decades of optimizations are leveraged to provide optimal performance. As a result, Elastic offers one of the most powerful and effortless hybrid search solutions in the market.
- For the same reason, it is both more efficient and more interpretable. Fewer dimensions are activated than in dense representations, and they often directly map to words, in contrast with the opaqueness of dense representations. In a vocabulary mismatch scenario, this will clearly show you which words non-existing in the query triggered the results.
Let’s speak to performance and Elasticsearch as a vector database
Keeping vectors of tens of thousands of dimensions and performing vector similarity on them may sound like a scale and latency stretch. However, sparse vectors compress wonderfully well, and the Elasticsearch (and Lucene) inverted index is a strong technical approach to this use case. In addition, for Elastic, vector similarity is a less computationally intensive operation, due to some clever inverted index tricks that Elasticsearch hides up its sleeve. Overall, both the query performance and index size when using our sparse retrieval model are surprisingly good and require fewer resources compared to the typical dense vector index.
That said, vector search, sparse or dense, has an inherently larger memory footprint and time complexity compared to lexical search universally, regardless of the platform. Elastic, as a vector database, is optimized and provides all gains possible on all levels (data structures and algorithmic). Although learned sparse retrieval might require more resources compared to lexical search, based on your application and data, the enhanced capabilities it offers could well be worth the investment.
The future: The most powerful hybrid search in the market out of the box
In this first tech preview release, we are limiting the length of the input to 512 tokens, which is approximately the first 300–400 words in each field going through an inference pipeline. This is sufficient for many use cases already, and we are working on methods for handling longer documents in a future version. For a successful early evaluation, we suggest using documents where most information is stored in the first 300–400 words.
As we evaluated different models for relevance, it became clear that the best results are obtained from an ensemble of different ranking methods. You can combine vector search — with or without the new retrieval model — with Elastic’s lexical search through our streamlined search APIs. Linearly combining normalized scores from each method can provide excellent results.
However, we want to push boundaries and offer the most powerful hybrid search out of the box, by eliminating any search science effort toward fine tuning based on the distribution of scores, data, queries, etc. To this aim, we are releasing Reciprocal Rank Fusion (RRF) in 8.8 for use initially with third-party models in Elastic and we are working toward integrating our sparse retrieval model and lexical search through RRF in the subsequent releases. This way, you will be able to leverage Elastic's innovative hybrid search architecture, combining semantic, lexical, and multimedia, through the Elastic search APIs that you are familiar with and trust through years of maturity.
Finally, in working toward a GA production-ready version, we are exploring strategies for handling long documents and overall optimizations to further boost performance.
Get started with Elastic’s AI-powered search today
To try Elastic Learned Sparse Encoder, head to Machine Learning at the trained models view or Enterprise Search to start using semantic search with your data, in a simple click of a button. If you don't have access to Elastic yet, you can request access to the premium trial needed here.
To learn more about our investments and trajectory in the vector search and AI space, watch this ElasticON Global spotlight talk by Matt Riley, general manager of Enterprise Search.
For a deeper understanding of the new model’s architecture and training, read the blog by the creator machine learning scientists.
To learn how you can use the model for semantic and hybrid search, head to our API and requirements documentation.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
공유하기
트위터에서 공유하기
링크드인에서 공유하기
페이스북에서 공유하기
이메일로 공유하기
인쇄하기

