Elastic Enterprise Search 엔진에서 더 많은 언어에 대한 지원을 추가하는 방법


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
Elastic App Search의 Engines를 사용하면 문서를 색인하고 즉시 사용할 수 있는 조정 가능한 검색 기능을 제공할 수 있습니다. 기본적으로, 엔진은 미리 정의된 언어 목록을 지원합니다. 여러분이 사용하시는 언어가 목록에 없는 경우, 이 블로그에서 더 많은 언어에 대한 지원을 추가할 수 있는 방법을 설명해 드립니다. 이를 위해 해당 언어에 대한 분석기가 설정된 App Search 엔진을 만들 것입니다.
더 자세한 내용을 다루기 전에, Elasticsearch 분석기가 무엇인지 정의해 보겠습니다.
Elasticsearch 분석기는 캐릭터 필터, 토크나이저, 토큰 필터, 이렇게 세 개의 하위 레벨 구성 요소가 포함되는 패키지입니다. 분석기는 기본 제공되거나 사용자 정의될 수 있습니다. 기본 제공되는 분석기는 구성 요소를 다양한 언어와 텍스트 유형에 적합한 분석기로 미리 패키지화합니다.
각 필드의 분석기는 다음 용도로 사용됩니다.
- 색인. 각 문서 필드는 해당 분석기로 처리되고, 검색이 용이하도록 토큰으로 분할됩니다.
- 검색. 검색 쿼리는 이미 분석된 인덱스 필드와 올바르게 일치하도록 분석됩니다.
Elasticsearch 인덱스 기반 엔진을 사용하면 기존 Elasticsearch 인덱스에서 App Search 엔진을 만들 수 있습니다. 우리는 자체 분석기와 매핑으로 Elasticsearch 인덱스를 만들고 App Search에서 해당 인덱스를 사용할 것입니다.
이 프로세스에는 다음 4단계가 있습니다.
1. Elasticsearch 인덱스 및 인덱스 문서 만들기
먼저, 어떤 언어에도 최적화되지 않은 인덱스를 살펴보겠습니다. 이것이 미리 정의된 매핑이 없는 새로운 인덱스이며 문서가 처음 색인될 때 작성된다고 가정해 봅시다.
Elasticsearch에서, 매핑은 문서와 그 문서에 포함된 필드를 저장하고 색인하는 방법을 정의하는 프로세스입니다. 각 문서는 고유한 데이터 유형을 가진 필드의 모음입니다. 데이터를 매핑할 때 여러분은 문서와 관련된 필드 목록을 포함하는 매핑 정의를 작성합니다.
우리의 예제로 돌아가면, 인덱스는 books라고 하며, title은 루마니아어로 되어 있습니다. 루마니아어가 제 모국어이기도 하고 App Search가 기본적으로 지원하는 언어 목록에 포함되어 있지 않기 때문에 루마니아어를 선택했습니다.
POST books/_doc/1
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
}
POST books/_doc/2
{
"title": "Dragoste în vremea holerei",
"author": "Gabriel García Márquez"
}
POST books/_doc/3
{
"title": "Obosit de viaţă, obosit de moarte",
"author": "Mo Yan"
}
POST books/_doc/4
{
"title": "Maestrul și Margareta",
"author": "Mihail Bulgakov"
}2. books 인덱스에 언어 분석기 추가
books 인덱스 매핑을 검사해 보면, 루마니아어에 최적화되어 있지 않음을 알 수 있습니다. settings 요소에 analysis 필드가 없고 텍스트 필드가 사용자 정의 분석기를 사용하지 않으므로 이를 알 수 있습니다.
GET books
{
"books": {
"aliases": {},
"mappings": {
"properties": {
"author": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "books",
"creation_date": "1679310576178",
"number_of_replicas": "1",
"uuid": "0KuiDk8iSZ-YHVQGg3B0iw",
"version": {
"created": "8080099"
}
}
}
}
}books 인덱스로 App Search 엔진을 만들려고 하면, 두 가지 문제가 발생합니다. 첫째, 검색 결과가 루마니아어에 최적화되지 않고, 다음으로 정밀 조정과 같은 기능이 비활성화됩니다.
다양한 유형의 Elastic App Search 엔진에 대해 참고하실 사항을 간단히 소개합니다.
- 기본 옵션은 숨겨진 Elasticsearch 인덱스를 자동으로 만들고 관리하는 App Search 관리 엔진입니다. 이 옵션을 사용하면, App Search 문서 API를 사용하여 여러분의 엔진으로 데이터를 수집해야 합니다.
- 다른 옵션을 사용하면, App Search는 기존 Elasticsearch 인덱스를 사용하는 엔진을 만듭니다. 이 경우, App Search는 인덱스를 있는 그대로 사용합니다. 여기서, Elasticsearch 인덱스 문서 API.를 사용하여 기본 인덱스에서 직접 데이터를 수집할 수 있습니다.
[관련 게시물: Elasticsearch Search API: App Search 문서를 찾는 새로운 방법]
기존 Elasticsearch 인덱스에서 엔진을 생성할 때, 매핑이 App Search 규칙을 따르지 않으면 해당 엔진에 대해 일부 기능이 활성화되지 않습니다. App Search에서 완벽하게 관리되는 엔진을 살펴봄으로써 App Search 매핑 규칙을 좀더 자세히 알아보겠습니다. 이 엔진은 title과 author라는 두 가지 필드가 있으며, 영어를 사용합니다.
GET .ent-search-engine-documents-app-search-books/_mapping/field/title
{
".ent-search-engine-documents-app-search-books": {
"mappings": {
"title": {
"full_name": "title",
"mapping": {
"title": {
"type": "text",
"fields": {
"date": {
"type": "date",
"format": "strict_date_time||strict_date",
"ignore_malformed": true
},
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"float": {
"type": "double",
"ignore_malformed": true
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"location": {
"type": "geo_point",
"ignore_malformed": true,
"ignore_z_value": false
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
}
}
}
}
}
}title 필드에는 여러 하위 필드가 있습니다. date, float, location 하위 필드는 텍스트 필드가 아닙니다.
여기서 우리가 관심을 갖는 것은 App Search에 필요한 텍스트 필드를 설정하는 방법입니다. 필드가 한두 개가 아닙니다! 이 설명서 페이지에서는 App Search에서 사용되는 텍스트 필드를 설명합니다. App Search가 App Search 관리 엔진에 속하는 숨겨진 인덱스에 대해 설정하는 분석기를 살펴보겠습니다.
GET .ent-search-engine-documents-app-search-books/_settings/index.analysis*
{
".ent-search-engine-documents-app-search-books": {
"settings": {
"index": {
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"en-stem-filter": {
"name": "light_english",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true",
"stem_english_possessive": "true"
},
"en-stop-words-filter": {
"type": "stop",
"stopwords": "_english_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}
}
}
}App Search에서 다른 언어(예: 노르웨이어, 핀란드어 또는 아랍어)에 사용할 수 있는 인덱스를 만들려면, 유사한 분석기가 필요합니다. 예를 들어, 어간 및 불용어 필터가 루마니아어 버전을 사용하는지 확인해야 합니다.
우리의 초기 books 인덱스로 돌아가서, 올바른 분석기를 추가해 보겠습니다.
여기서 간단한 주의사항을 알려드리겠습니다. 기존 인덱스의 경우, 분석기는 인덱스를 닫을 때만 변경할 수 있는 Elasticsearch 설정 유형입니다. 이 접근 방법에서는, 기존 인덱스로 시작하므로 인덱스를 닫고 분석기를 추가한 다음, 인덱스를 다시 열어야 합니다.
유의사항: 또는 올바른 매핑을 사용하여 인덱스를 처음부터 다시 작성한 다음 모든 문서를 색인할 수도 있습니다. 사용 사례에 더 적합한 경우, 인덱스 열기 및 닫기, 재색인에 대해 설명하는 이 안내서 부분은 건너뛰셔도 좋습니다.
POST books/_close를 실행하여 인덱스를 닫을 수 있습니다. 그 후에, 다음과 같이 분석기를 추가합니다.
PUT books/_settings
{
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"ro-stem-filter": {
"name": "romanian",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true"
},
"ro-stop-words-filter": {
"type": "stop",
"stopwords": "_romanian_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}루마니아어로 어간 추출(스테밍)을 하기 위해 ro-stem-filter를 추가하고 있는 것을 보실 수 있습니다. 이는 루마니아어에 고유한 단어 변형에 대한 검색 정확도를 향상시키게 됩니다. 루마니아어 불용어가 검색 목적으로 고려되지 않도록 하기 위해 루마니아어 불용어 필터(ro-stop-words-filter)를 포함하고 있습니다.
이제 POST books/_open을 실행하여 인덱스를 다시 열겠습니다.
3. 분석기를 사용하도록 인덱스 매핑 업데이트
분석 설정이 완료되면, 인덱스 매핑을 수정할 수 있습니다. App Search는 동적 템플릿을 사용하여 새 필드에 올바른 하위 필드와 분석기가 있는지 확인합니다. 이 예에서는, 하위 필드를 기존 title과 author 필드에만 추가합니다.
PUT books/_mapping
{
"properties": {
"author": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
},
"title": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
}
}
}4. 문서 재색인
이제 books 인덱스를 App Search에서 사용할 준비가 거의 다 되었습니다!
매핑을 수정하기 전에 색인한 문서에 올바른 하위 필드가 있는지 확인해야 합니다. 이를 위해, update_by_query를 사용하여 재색인을 실행할 수 있습니다.
POST books/_update_by_query?refresh
{
"query": {
"match_all": {
}
}
}우리는 match_all 쿼리를 사용하고 있기 때문에, 기존의 모든 문서가 업데이트됩니다.
update by query 요청을 통해 문서 업데이트 방법을 정의하는 스크립트 매개 변수를 포함할 수도 있습니다.
문서를 변경하지는 않지만 author와 title 텍스트 필드에 올바른 하위 필드가 있는지 확인하기 위해 기존 문서를 있는 그대로 재색인하려고 합니다. 따라서, update by query 요청에 script를 포함할 필요가 없습니다.
이제 Elasticsearch 엔진을 통해 App Search에서 사용할 수 있는 언어에 최적화된 인덱스가 있습니다! 다음 스크린샷에서 그 이점을 확인하실 수 있습니다.
우리는 백년 동안의 고독이라는 책 제목을 참고로 사용할 것입니다. 루마니아어로 번역된 제목은 Un veac de singurătate입니다. "세기"를 뜻하는 루마니아어 단어인 veac를 눈여겨 봐주세요. veac의 복수형인 veacuri로 검색해 보겠습니다. 우리는 이제 보려고 하는 다음 두 가지 예제 양쪽 모두에서 이 데이터 레코드를 수집했습니다.
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
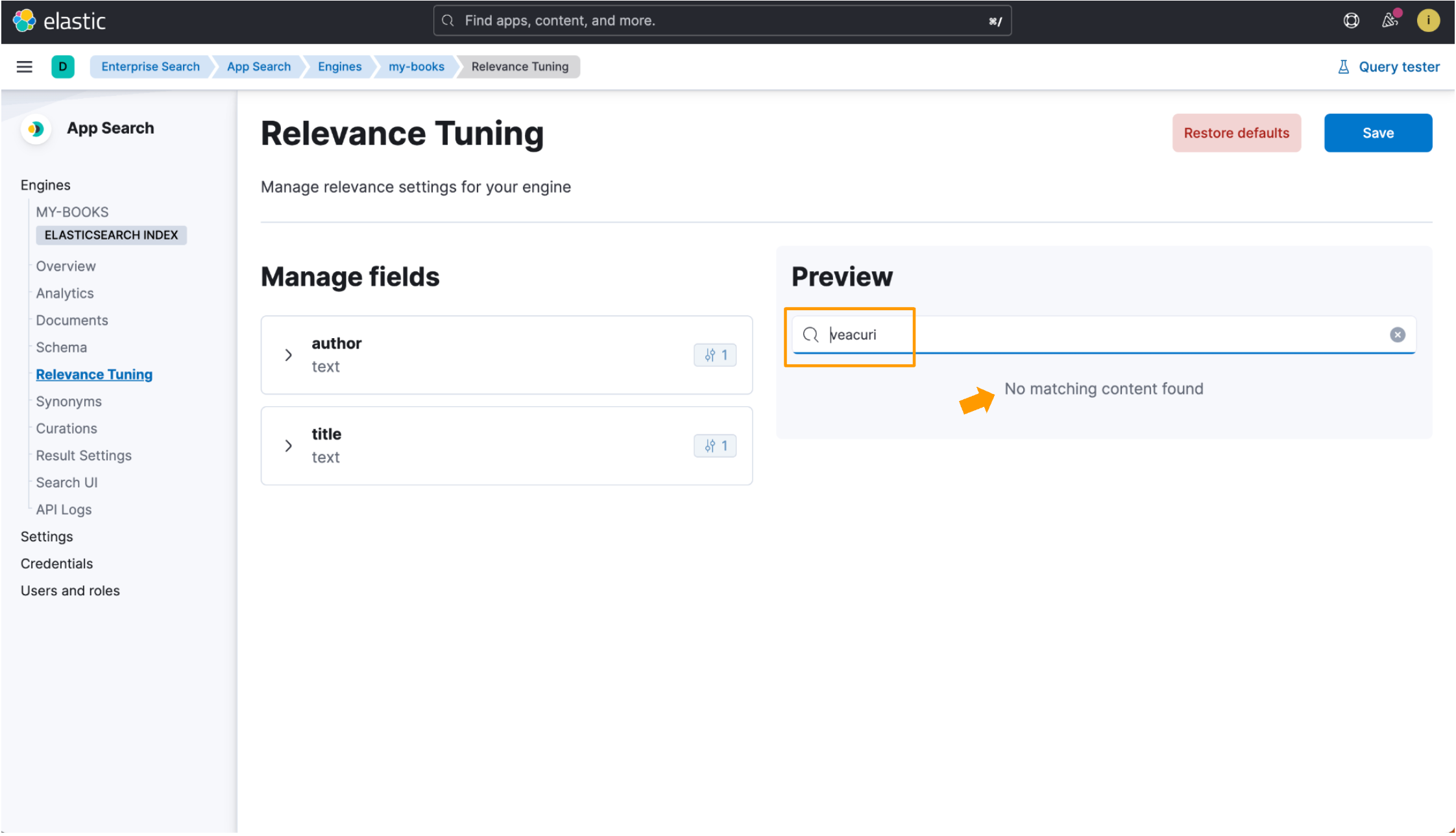
}인덱스가 어떤 언어에 최적화되지 않은 경우, 루마니아어 책 제목인 Un veac de singurătate는 표준 분석기로 색인되며, 이는 대부분의 언어에서 잘 작동하지만 관련 문서에서 항상 일치하지 않을 수 있습니다. 이 검색 입력이 데이터 레코드의 일반 텍스트와 일치하지 않기 때문에, veacuri를 검색해도 결과가 표시되지 않습니다.
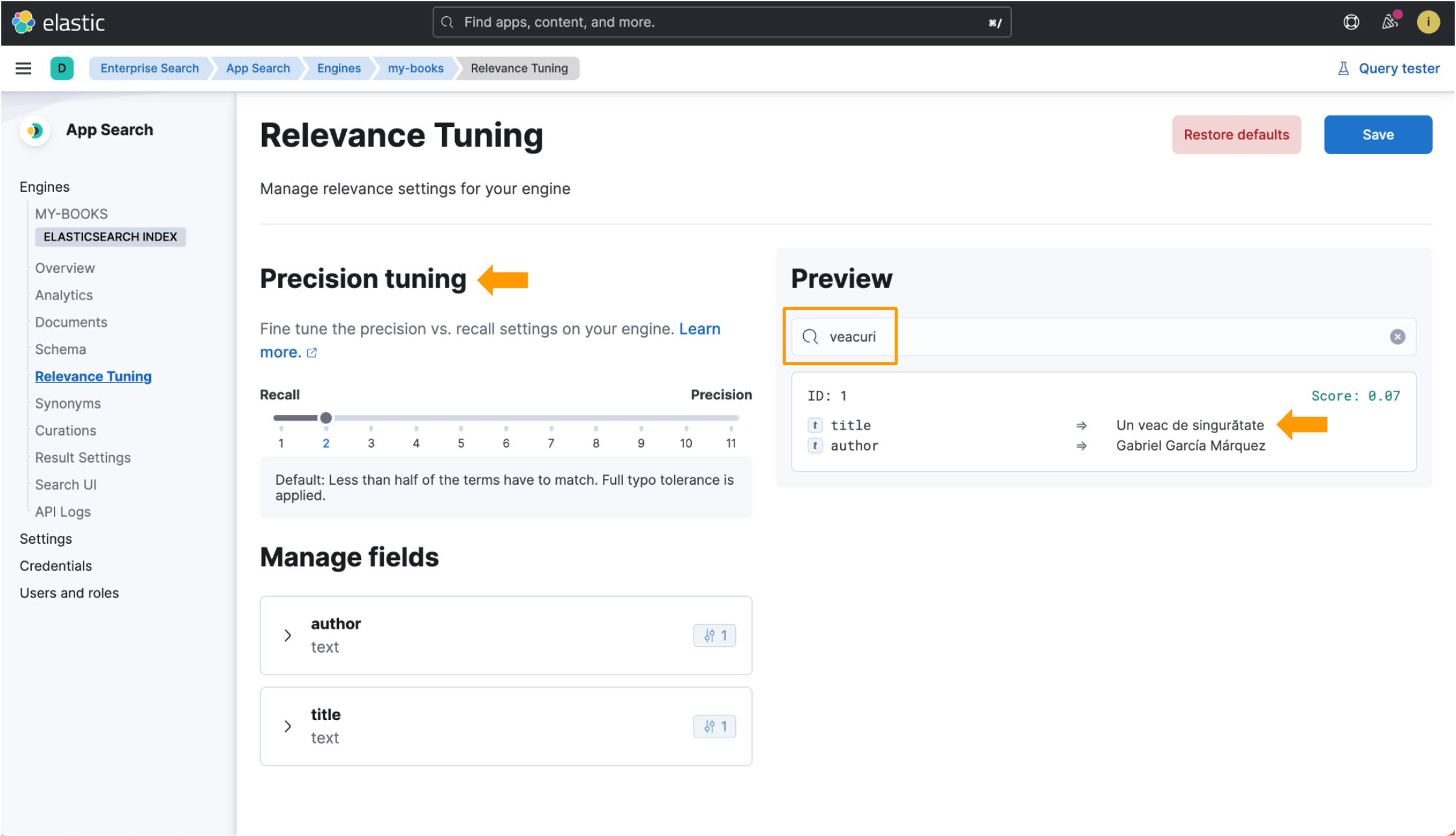
그러나 언어에 최적화된 인덱스를 사용할 때 veacuri를 검색하면, Elastic App Search가 해당 인덱스를 루마니아어 veac와 일치시키고 우리가 찾고 있는 데이터를 반환합니다. 정밀 조정 필드는 정확도 조정 뷰 내에서도 사용할 수 있습니다! 이 이미지에서 강조 표시된 부분들을 모두 확인해 보세요.
이제 이로써 우리는 제 모국어인 루마니아어를 위해 Elastic Enterprise Search에서 지원을 추가했습니다! 이 안내서에 사용된 프로세스를 복제하여 Elasticsearch에서 지원하는 다른 언어에 최적화된 인덱스를 만들 수 있습니다. Elasticsearch에서 지원되는 언어 분석기의 전체 목록을 보려면, 이 설명서 페이지를 참조하세요.
Elasticsearch의 분석기는 정말 매력적인 주제입니다. 자세한 내용은 다음과 같은 몇 가지 리소스를 참조하세요.
- Elasticsearch 텍스트 분석 개요 설명서 페이지
- Elasticsearch 기본 제공 분석기 참조 설명서 페이지(지원되는 언어 분석기 목록은 이 하위 페이지를 확인하세요.)
- Elastic Enterprise Search 및 Elastic Cloud 체험판에 대해 자세히 알아보기
공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기