Canvas에서 사용자 지정 ServiceNow 문제 보고서 대시보드를 만드는 방법
다시 한 번 환영합니다! 이 시리즈의 세 번째이자 마지막 부분에서는 문제 관리를 위해 ServiceNow와 함께 Elastic Stack을 사용하는 방법을 다룹니다. 첫 번째 블로그에서는 프로젝트를 소개하고 문제의 변경 사항이 Elasticsearch로 자동 푸시되도록 ServiceNow를 설정했습니다. 두 번째 블로그에서는 경보와 데이터 트랜스폼 및 일반적인 Elasticsearch 구성 몇 가지를 통해 ServiceNow와 Elasticsearch를 결합하는 논리를 구현했습니다.
이 시점에서는 모든 것이 완벽하게 작동합니다. 하지만 문제 관리에 사용할 편리한 (그리고 보기 좋은) 프런트 엔드가 없습니다! 이 포스팅에서는 아래의 Canvas 워크패드를 만들어 지금까지 우리가 구축한 모든 가치를 사람들이 쉽게 이해하고 사용할 수 있는 것으로 바꿔보겠습니다.
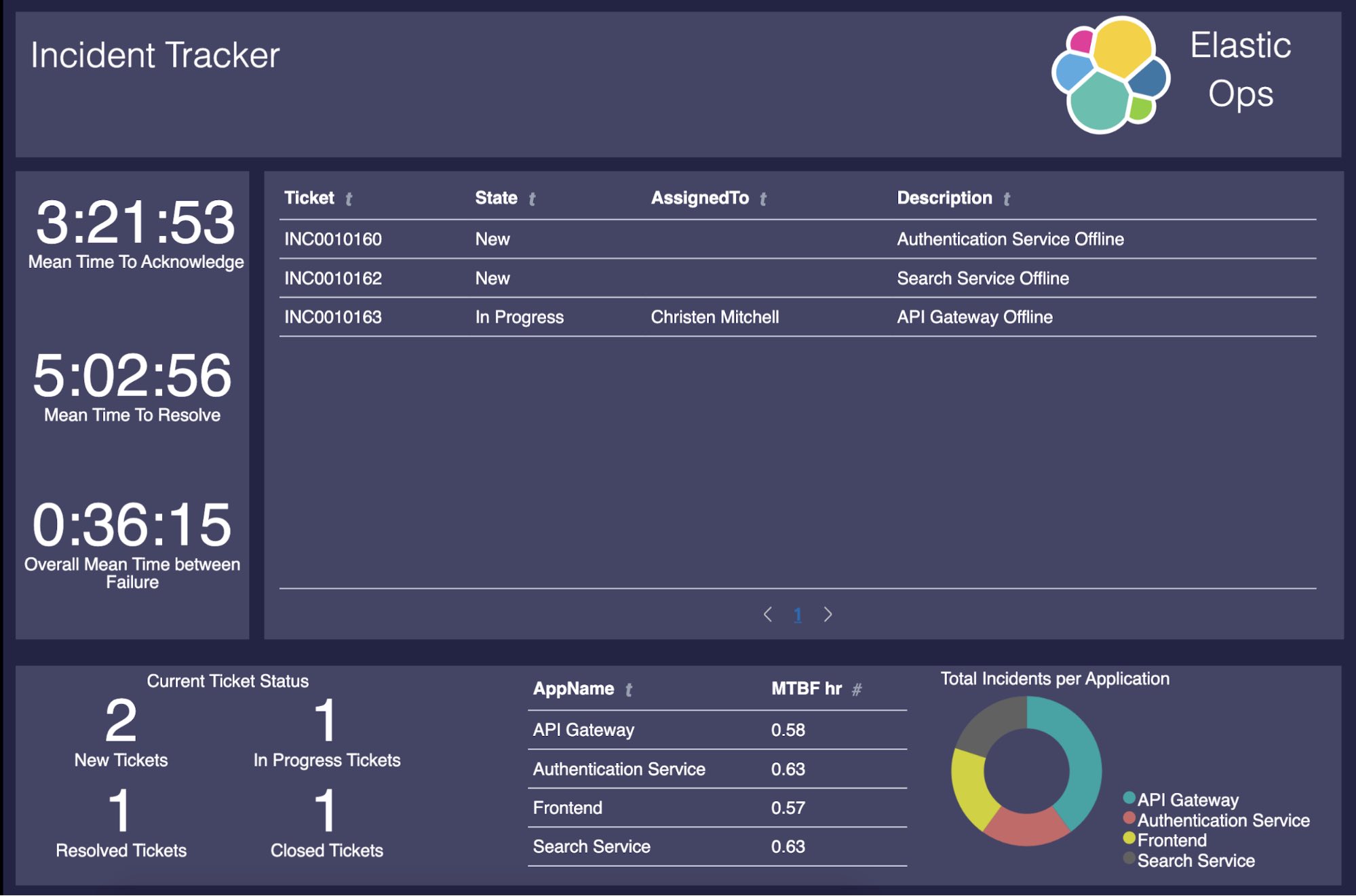
대시보드에 표시되는 내용은 다음과 같습니다.
- 열린 티켓, 종결된 티켓, 해결된 티켓, 진행 중인 티켓
- 문제 MTTA
- 문제 MTTR
- 전체 MTBF
- 애플리케이션 MTBF
- 애플리케이션당 문제 수
그럼 시작해볼까요?
Canvas 워크패드 설정
이 포스팅에서는 Canvas 표현식을 많이 사용하게 됩니다. 워크패드의 모든 요소를 내부적으로는 표현식으로 나타내기 때문입니다. 따라서 Canvas 표현식은 기능을 재생성하는 방법을 보여주는 가장 쉬운 방법입니다.
데이터 트랜스폼이 채우는 엔티티 중심 인덱스 내에 데이터가 없는 경우 다음 요소 중 일부가 "데이터 테이블 비우기"와 유사한 오류 메시지를 표시합니다.
시작하기 전에 다음과 같이 Canvas를 열어 보겠습니다.
- Kibana 도구 모음을 확장합니다.
- 버전 7.8 이상을 실행하는 경우 Kibana에서 찾을 수 있으며, 그렇지 않으면 다른 모든 아이콘 목록에 표시됩니다.
- Create Workpad(워크패드 생성) 버튼을 클릭합니다.
- 워크패드가 생성되면 이름을 지정합니다. 오른쪽의 Workpad Settings(워크패드 설정) 내에서 이를 설정할 수 있습니다. "My Canvas Workpad(내 Canvas 워크패드)"를 "Incident Tracker(문제 추적기)"로 변경하는 것이 좋습니다. 다음 단계에서 배경색을 설정할 수도 있습니다.
- 해당 구성 요소의 Canvas 표현식을 편집하려면, 해당 표현식을 클릭한 다음 오른쪽 아래에 있는 </> Expression editor를 클릭합니다.
테마 설정
Canvas 워크패드를 만드는 첫 번째 단계는 배경 화면입니다.
- 배경 색상을 #232344로 설정합니다.
- 직사각형 모양으로 네 개의 도형 요소를 만들고 채우기 색상을 #444465로 설정합니다.
- 회사 로고, 회사 이름 및 제목과 같이 상단 표시줄에 로고와 텍스트를 추가합니다.
실행 중인 티켓 표시
이제 어떤 티켓이 실행 중인지 보여주는 테이블을 가운데에 만들어야 합니다. 이를 위해 "데이터 테이블" 요소와 함께 Elasticsearch SQL 및 Canvas 표현식을 조합하여 사용하겠습니다. 데이터 테이블 요소를 생성하려면, 다음 Canvas 표현식을 편집기에 복사한 다음 실행을 클릭합니다.
filters
| essql
query="SELECT incidentID as Ticket, LAST(state, updatedDate) as State, LAST(assignedTo, updatedDate) as AssignedTo, LAST(description, updatedDate) as Description FROM \"servicenow*\" group by Ticket ORDER BY Ticket ASC"
| filterrows fn={getCell "State" | any {eq "New"} {eq "On Hold"} {eq "In Progress"}}
| table
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false} paginate=true perPage=10
| render
이 표현식에서는 쿼리를 실행한 다음 상태 필드가 "New", "On Hold" 또는 "In Progress"로 설정된 행을 제외한 모든 행을 필터링합니다.
이 시점에는 데이터가 없기 때문에 비어 있을 수 있습니다. 우리의 비즈니스 규칙이 실행되지 않아 Elasticsearch 내에 ServiceNow 데이터가 없을 수 있기 때문입니다. 원한다면 여기서 가짜 문제를 만들 수 있습니다. 만약 그렇다면, 테이블이 좀 사실적으로 보이도록 하기 위해 다양한 단계의 티켓을 확보하세요.
평균 확인 시간(MTTA) 계산
문제 MTTA를 표시하기 위해, 메트릭 요소를 추가하고 아래 Canvas 표현식을 사용하겠습니다.
filters
| essql
query="SELECT * FROM (SELECT incidentID, updatedDate, state FROM \"servicenow-incident-updates\") PIVOT (MIN(updatedDate) FOR state IN ('New' as New, 'In Progress' as \"InProgress\"))"
| mapColumn "New" fn={getCell "New" | formatdate "X" | math "value"}
| mapColumn "InProgress" fn={getCell "InProgress" | formatdate "X" | math "value"}
| filterrows fn={getCell "InProgress" | gt 0}
| mapColumn "Duration" expression={math expression="InProgress - New"}
| math "mean(Duration)"
| metric "Mean Time To Acknowledge"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
이 표현식은 PIVOT을 포함하여 고급 Elasticsearch SQL 함수를 사용합니다. MTTA를 계산하기 위해, 생성과 확인 사이의 총 시간을 계산한 다음 그것을 문제 수로 나눕니다. 사용자가 만든 각 업데이트를 ServiceNow에 저장하기 때문에 여기서 PIVOT을 사용해야 합니다. 즉, 다른 사용자가 상태, 메모, 피할당자 등을 업데이트할 때마다 업데이트가 Elasticsearch로 푸시됩니다. 이것은 그러한 결과를 분석하는 데 매우 유용합니다. 이 때문에, 우리는 데이터를 피벗하여 문제가 처음 "New"가 된 시간과 그 문제가 처음 "In Progress"로 이동한 시간을 포함해 문제당 한 행이 나오도록 해야 합니다.
그런 다음 각 문제가 확인된 시간에서 생성된 시간을 빼서 확인 시간을 계산할 수 있습니다. MTTA는 이 지속 시간 필드 함수에 대한 평균을 사용하여 계산됩니다.
평균 해결 시간(MTTR) 계산
문제 MTTR을 표시하기 위해, 메트릭 요소를 추가하고 다음 Canvas 표현식을 사용하겠습니다.
filters
| essql
query="SELECT * FROM (SELECT incidentID, updatedDate, state FROM \"servicenow-incident-updates\") PIVOT (MIN(updatedDate) FOR state IN ('New' as New, 'Resolved' as \"Resolved\"))"
| mapColumn "New" fn={getCell "New" | formatdate "X" | math "value"}
| mapColumn "Resolved" fn={getCell "Resolved" | formatdate "X" | math "value"}
| filterrows fn={getCell "Resolved" | gt 0}
| mapColumn "Duration" expression={math expression="Resolved - New"}
| math "mean(Duration)"
| metric "Mean Time To Resolve"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
MTTA와 마찬가지로, 각 문제에 대한 요약 보기를 살펴봐야 하기 때문에 PIVOT 함수를 사용합니다. MTTA와 달리, 새 티켓이며 또한 해결된 티켓일 때 우리는 이 상태를 처음으로 볼 수 있습니다. MTTR은 티켓이 해결되는 데 걸리는 평균 시간이기 때문입니다. 이것은 MTTA와 매우 유사하므로 간략히 하기 위해 동일한 세부 작업을 반복하지 않겠습니다.
전체 평균 고장 간격(MTBF) 계산
이제 MTTA와 MTTR이 있으므로 각 애플리케이션에 대한 MTBF가 필요합니다. 이를 위해 app_incident_summary_transform과 calculate_uptime_hours_online_transfo라는 두 가지 데이터 프랜스폼을 사용하겠습니다. 이러한 데이터 프랜스폼 덕분에, 전체 MTBF를 아주 쉽게 계산할 수 있습니다. MTBF는 시간 단위로 측정되고 데이터 프랜스폼은 초 단위로 계산되므로, 모든 애플리케이션에서 평균을 계산한 다음 그 결과를 3600(한 시간의 초 단위)으로 곱합니다.
아래 Canvas 표현식을 사용하여 다른 메트릭 요소를 생성해 보겠습니다.
filters
| essql query="SELECT AVG(mtbf) * 3600 as MTBF FROM app_incident_summary"
| math "MTBF"
| metric "Overall Mean Time between Failure"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
애플리케이션 평균 고장 간격(MTBF) 계산
이제 전체적인 MTBF를 계산했으므로 각 애플리케이션에 대한 MTBF를 손쉽게 표시할 수 있습니다. 새 데이터 테이블 요소를 만들고, 다음 Canvas 표현식을 사용하여 테이블에 데이터를 표시하기만 하면 됩니다. 가독성을 위해 각 애플리케이션의 MTBF를 소수점 두 자리로 반올림했습니다.
filters
| essql
query="SELECT app_name as AppName, ROUND(mtbf,2) as \"MTBF hr\" FROM app_incident_summary"
| table paginate=false
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false}
| render
해결된 티켓 계산
몇 가지 성공 사례를 보고 싶기 때문에 워크패드에서 "closed" 수를 확인해 보겠습니다. 이것은 상태가 "Resolved"로 설정된 모든 문제를 가져온 다음 산술 함수를 통해 고유한 문제 ID의 수를 세는 간단한 메트릭 요소입니다.
filters
| essql query="SELECT state,incidentID FROM \"servicenow*\" where state = 'Resolved'"
| math "unique(incidentID)"
| metric "Resolved Tickets"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="0,0.[000]"
| render
애플리케이션당 문제 계산
이제 애플리케이션당 고유한 문제 수를 세는 도넛 차트를 만들겠습니다. 도넛 차트에 표시되는 내용에 대한 컨텍스트를 제공하기 위해 "애플리케이션당 총 문제 수"라는 텍스트와 함께 그 위에 마크다운 요소를 추가하는 것이 좋습니다.
filters
| essql
query="SELECT incidentID as IncidentCount, app_name as AppName FROM \"servicenow*\""
| pointseries color="AppName" size="unique(IncidentCount)"
| pie hole=41 labels=false legend="se" radius=0.72
palette={palette "#01A4A4" "#CC6666" "#D0D102" "#616161" "#00A1CB" "#32742C" "#F18D05" "#113F8C" "#61AE24" "#D70060" gradient=false} tilt=1
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false}
| render
현재 티켓 상태 계산
이 섹션은 네 가지 메트릭 요소로 구성됩니다. 이 요소들은 모두 매우 유사한 Canvas 표현식으로 아주 조금씩만 다릅니다. 간단히 말해, 모든 문제에 대한 최신 업데이트를 받은 다음 filterrows Canvas 표현식 함수를 사용하여 상태를 기준으로 원하는 문제를 유지합니다. 이를 통해 고유한 문제 수를 계산할 수 있습니다.
아래 표현식을 사용하고 상태를 New에서 원하는 각 상태로 업데이트합니다. 또한 메트릭의 텍스트를 "새 티켓"에서 업데이트하는 것을 잊지 마세요.
filters
| essql
query="SELECT incidentID, LAST(state, updatedDate) as State FROM \"servicenow*\" group by incidentID" count=1000
| filterrows fn={getCell "State" | eq 'New'}
| math "unique(incidentID)"
| metric "New Tickets"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="0,0.[000]"
| render
최종 완성
이제 Canvas 워크패드의 다양한 부분이 모두 생성되었으므로 다음과 같이 대단히 유용한 문제 관리 대시보드를 갖게 됩니다.
이제 끝났습니다. 배운 내용을 사용해 보세요!
다 됐습니다! Elastic Stack의 여러 구성 요소를 사용하여 ServiceNow 문제를 기반으로 MTTA, MTTR, MTBF를 계산한 다음 유용하고 시각적으로 매력적인 대시보드에 해당 정보를 표시하는 작업을 했습니다. 여기서 중요한 점은 이 정보가 다른 도구 내에서가 아니라 실제 데이터와 함께 사용된다는 것입니다. 이러한 메트릭은 보고된 문제와 관련하여 사람들이 애플리케이션의 상태를 이해하는 데 사용할 수 있는 좋은 지식 기반을 제공합니다. 예를 들어, MTBF가 매우 낮으면 애플리케이션이 매우 자주 실패한다는 의미입니다. MTTA가 높으면 실패에 대한 조사를 시작하는 데 시간이 오래 걸린다는 의미입니다.
만약 여러분이 단지 읽어보기만 하셨고 직접 해 보지 않으셨다면, 소매를 걷어붙이고 시도해 보실 것을 권합니다. Elastic Cloud 무료 체험판을 활용해 기존 ServiceNow 인스턴스 또는 개인 개발자 인스턴스와 함께 사용할 수 있습니다.
또한 GitHub, Google Drive 등과 같은 다른 소스와 함께 ServiceNow 데이터를 검색하려는 경우, Elastic Workplace Search에 미리 빌드된 ServiceNow 커넥터가 탑재되어 있습니다. Workspace Search는 모든 컨텐츠 소스에서 관련 결과를 포함하여 팀에게 통합 검색 환경을 제공합니다. 또한 Elastic Cloud 체험판에도 포함되어 있습니다.
이 블로그는 이러한 메트릭을 추적하기 위해 데이터를 사용하는 기반을 제공합니다. 예를 들어, 로그, 인프라 메트릭, APM 추적 및 머신 러닝 이상 징후를 기반으로 문제를 생성할 수 있습니다. 이 Canvas 대시보드의 이해 관계자들에게 추가적인 가치를 제공하기 위해, 각 문제의 근본 원인이 무엇이었는지 문의할 수 있는 Kibana(Logs, APM 등) 앱이나 자체적인 대시보드로의 링크를 추가하는 것이 좋습니다.
이 시리즈를 즐겨 보셨다면 다음과 같은 링크도 마음에 드실 것입니다.
- 데이터 트랜스폼을 사용하는 시기
- 머신 러닝 시작하기
- Canvas 소개: Kibana에서 시각적인 이야기를 하는 새로운 방법
- Canvas의 메트릭 요소와 마크다운을 사용하여 링크 추가하기
즐겁게 사용하셨으면 합니다!