


AI 기술이 완벽하게 탑재되어 있어 기존 업무 환경 어디에서든 적용 가능
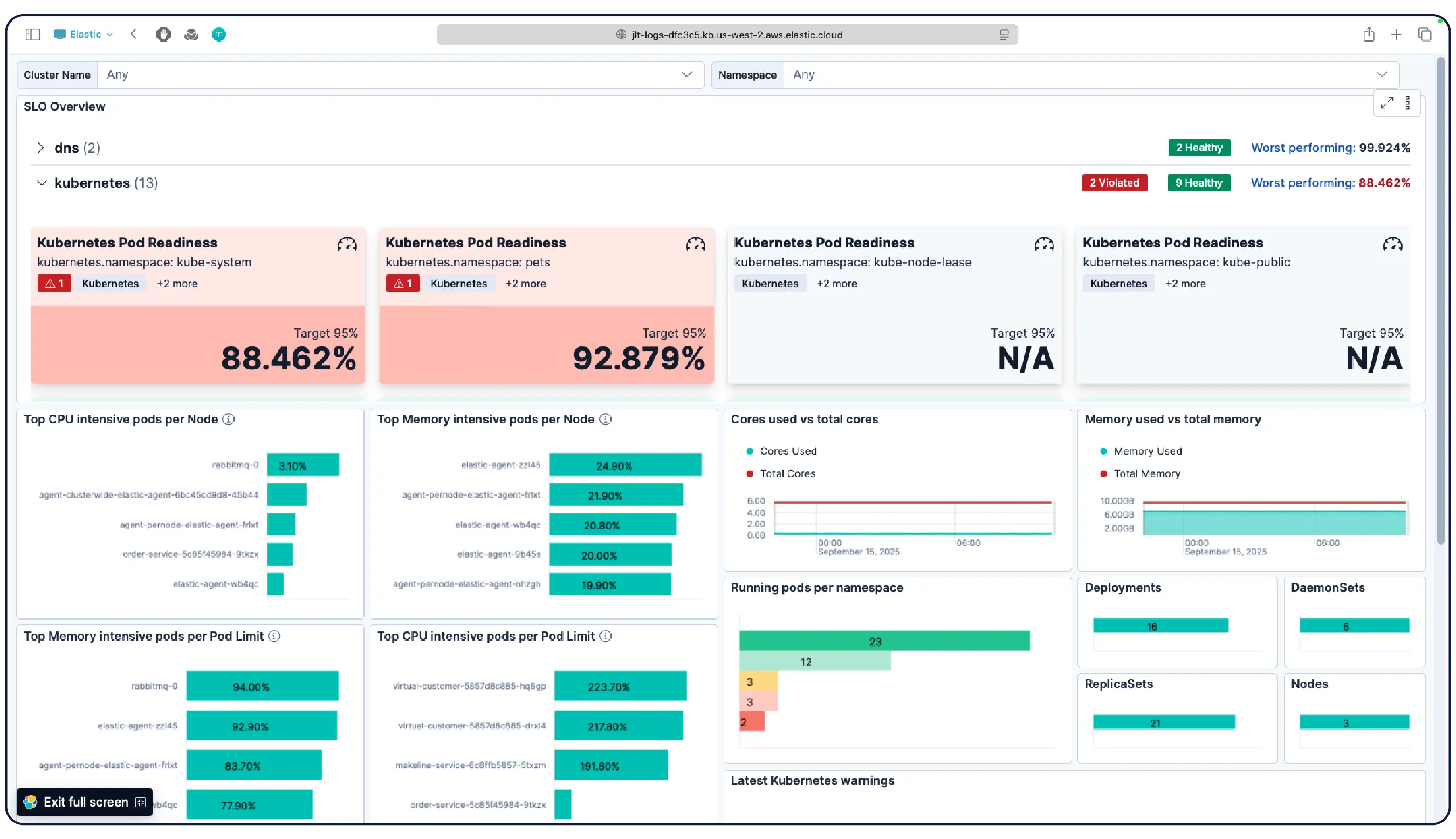
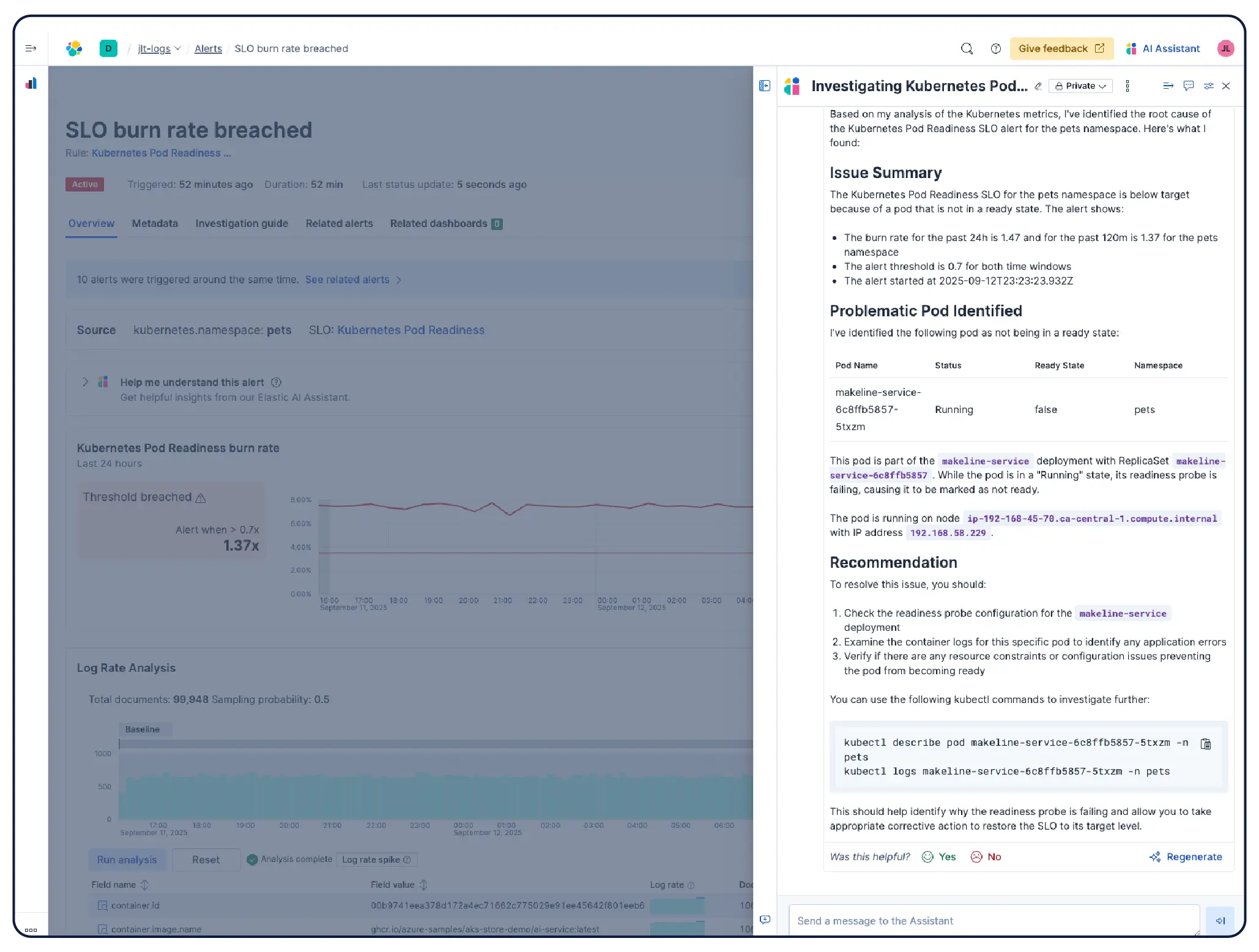
연결하는 즉시 사용할 수 있도록 작동 환경을 준비하세요. Elastic의 Kubernetes 모니터링 솔루션은 사전 구성된 대시보드, 알림, SLO, 머신 러닝 작업은 물론, 에이전트 스킬과 MCP 앱을 포함하여 상태 모니터링, 이상 탐지, 사고 조사 및 복구를 위한 모든 기능을 제공합니다.

동급 최고 수준의 효율성
성능 저하나 데이터 손실 없이 완벽한 인프라 가시성과 풍부한 로그 분석 기능을 활용하세요. Elasticsearch 열 형식 메트릭 엔진은 모든 규모에서 데이터 인제스트, 저장 및 쿼리 속도 면에서 타의 추종을 불허합니다.
Elasticsearch를 선도적인 열 형식 메트릭 데이터 저장소로 재구축한 방법을 알아보세요. 벤치마크를 확인하세요.
스키마 독립성
하나의 데이터 저장소로 모든 형식을 지원하며 컨텍스트 전환이 필요 없습니다
대부분의 인프라 모니터링 스택은 모든 것을 단일 스키마로 표준화하거나 여러 백엔드와 쿼리 언어를 사용하도록 강요합니다. Elasticsearch는 그렇지 않습니다. OpenTelemetry, Prometheus, Beats 또는 기타 어떤 형식으로 데이터를 보내더라도 Elasticsearch는 각 데이터를 통합 데이터 저장소에 기본적으로 저장하고 그대로 쿼리합니다. 번역 단계도 없고, 정보 손실도 없고, 상황 판단을 위한 반복적인 조사도 필요 없습니다.
인프라에 집중
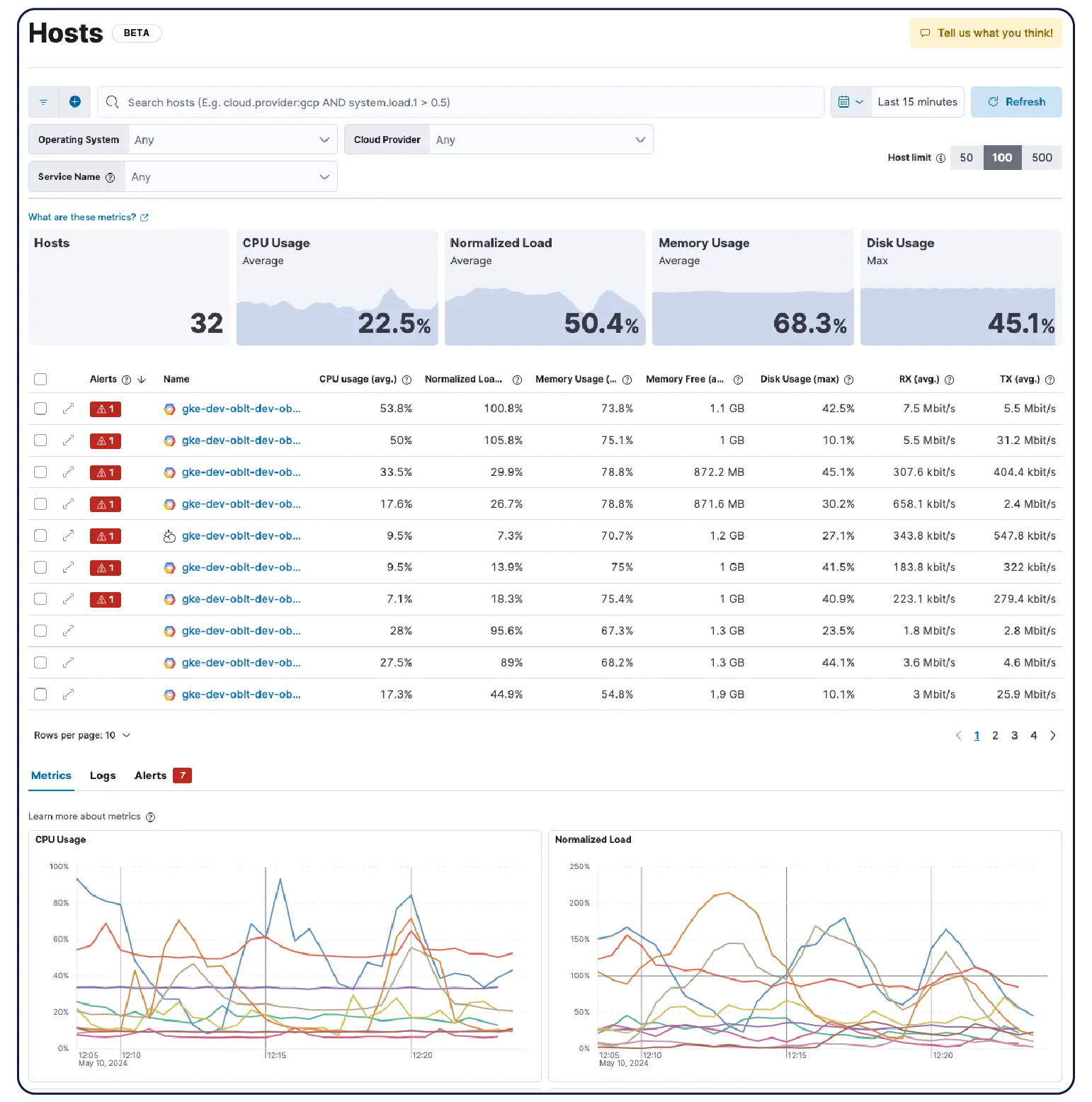
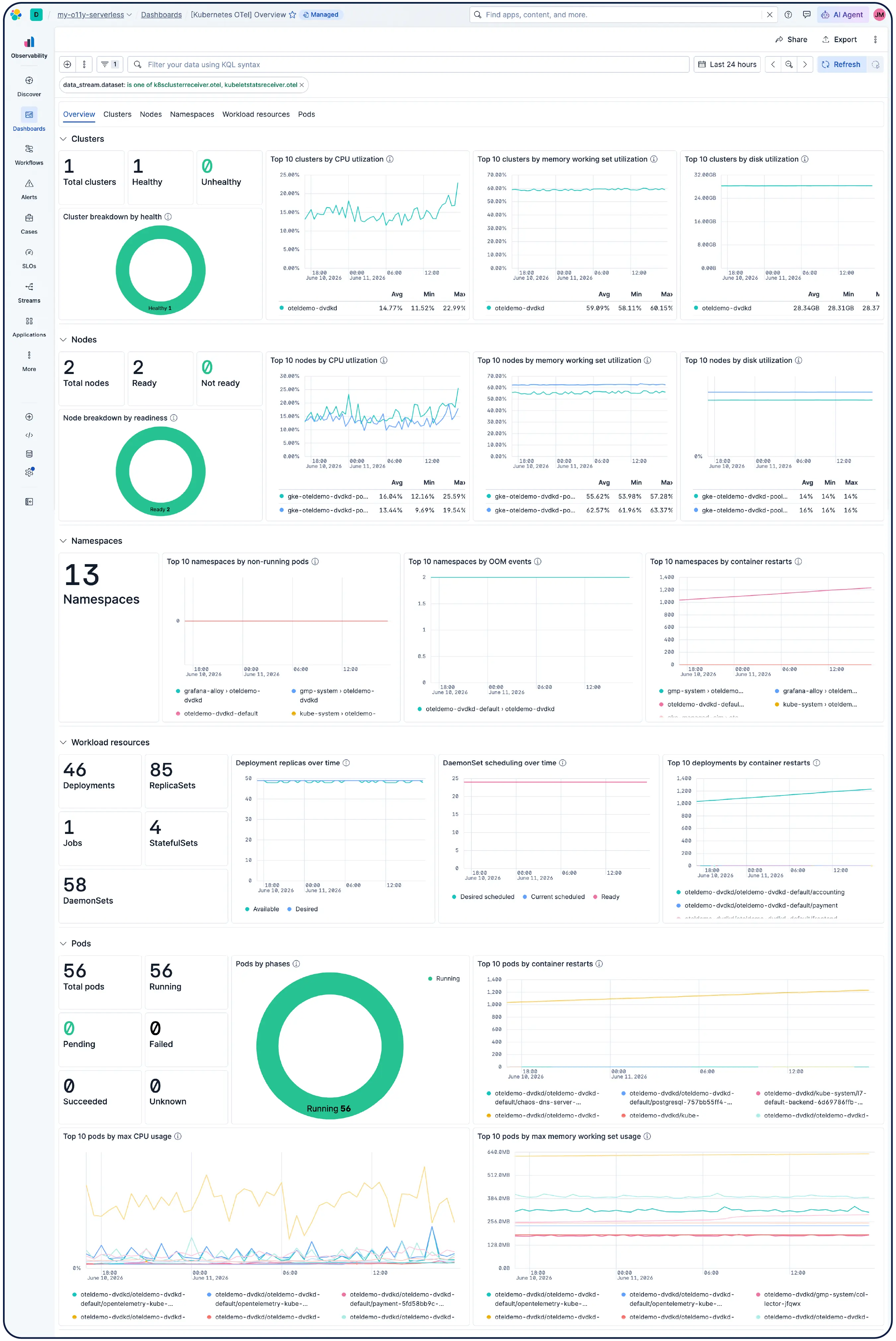
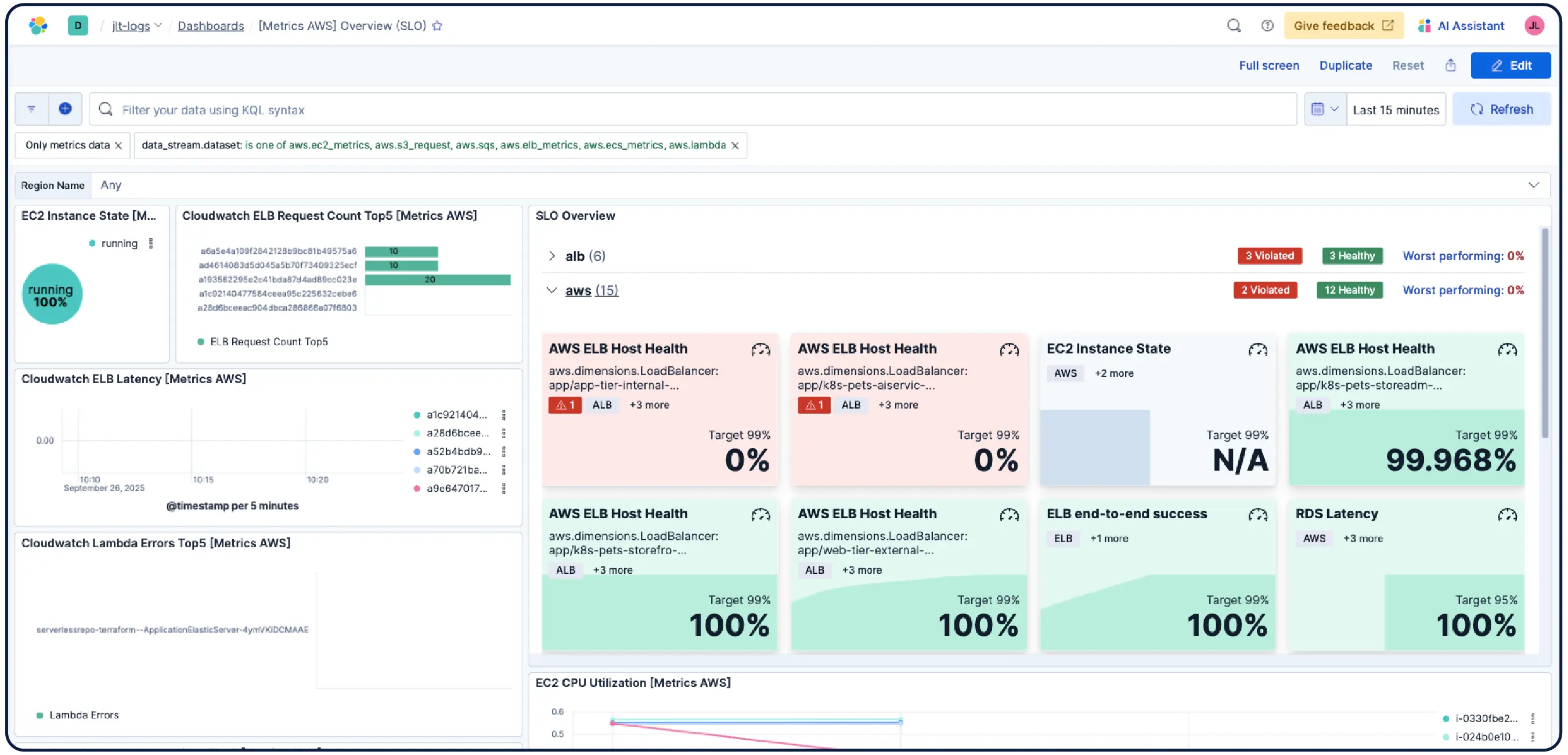
Kubernetes 클러스터, VM, 클라우드 또는 온프레미스 서버를 운영하든 관계없이 550개 이상의 사전 구축된 통합 기능, 경량 에이전트 및 AWS, Azure, GCP용 에이전트리스 수집기를 통해 간편하게 데이터를 수집할 수 있습니다.
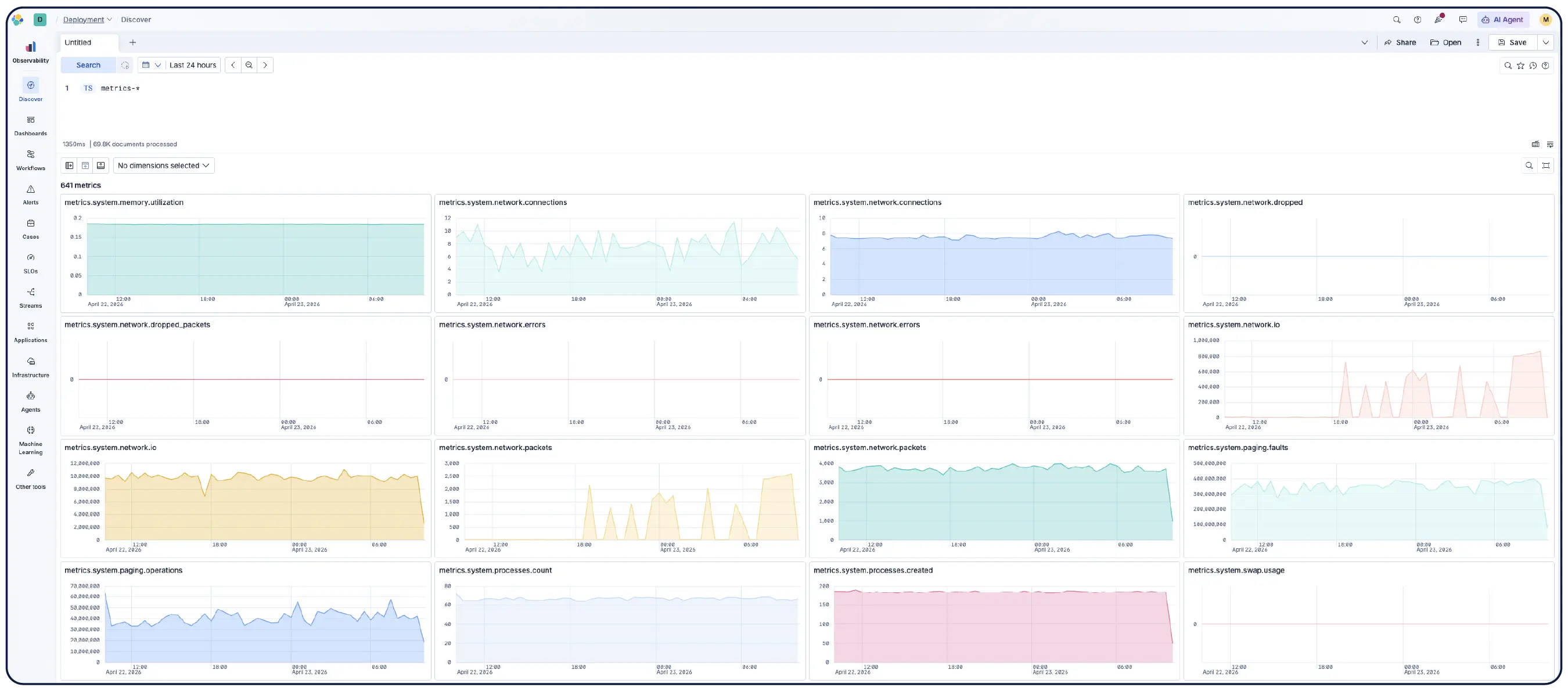
Discover에서 데이터를 검색, 필터링, 집계 및 시각화하세요. 세션을 대시보드에 저장하고, 알림을 설정하고, 모든 데이터에 대해 ES|QL 쿼리를 실행하여 통합 분석을 수행하세요. 모든 차원의 모든 메트릭으로 필터링하고 Kibana에서 바로 PromQL을 실행할 수 있습니다.
수많은 기업이 Elastic Observability를 선택하는 이유를 알아보세요
고객 스포트라이트

Comcast는 Elastic을 통해 매일 400테라바이트의 데이터를 수집하여 서비스를 모니터링하고 근본 원인 분석을 가속화함으로써 최상의 고객 경험을 보장합니다.
고객 스포트라이트

Zooplus는 Elasticsearch를 사용하여 2,500개의 마이크로서비스, 20,000개의 컨테이너, 70개의 AWS 서비스가 있는 600개의 AWS 계정, 그리고 40개의 Kubernetes 클러스터를 모니터링합니다.
고객 스포트라이트

Informatica는 100개 이상의 애플리케이션과 300개 이상의 Kubernetes 클러스터에서 로깅 워크로드 전체를 Elastic으로 마이그레이션하여 비용을 절감하고 MTTR을 단축했습니다.
채팅 참여
Elastic의 글로벌 커뮤니티에 연결하여 열린 대화와 협업에 참여해 보세요.


.jpg)

자주 묻는 질문
인프라 모니터링이란 무엇입니까?
인프라 모니터링이란 무엇입니까?
인프라 모니터링은 웹 서버, 컨테이너, 클라우드 인스턴스, 네트워크 장치, 캐시, 큐, 데이터베이스, 스토리지 등 애플리케이션이 실행되는 시스템의 상태와 성능을 추적합니다. CPU 사용량, 메모리 소비량, 디스크 I/O, 포드 재시작과 같은 메트릭을 수집하여 팀이 리소스 포화 상태를 감지하고, 장애가 확산되기 전에 해결하며, 인프라 환경이 애플리케이션 동작에 미치는 영향을 파악할 수 있도록 지원합니다. 효과적인 인프라 모니터링은 이러한 메트릭을 로그 및 추적과 연관시켜 엔지니어가 도구를 변경하지 않고도 "이 호스트의 리소스 사용량이 높다"와 같은 문제에서 근본 원인을 찾아낼 수 있도록 합니다.
Elastic은 인프라를 어떻게 모니터링하나요?
Elastic은 인프라를 어떻게 모니터링하나요?
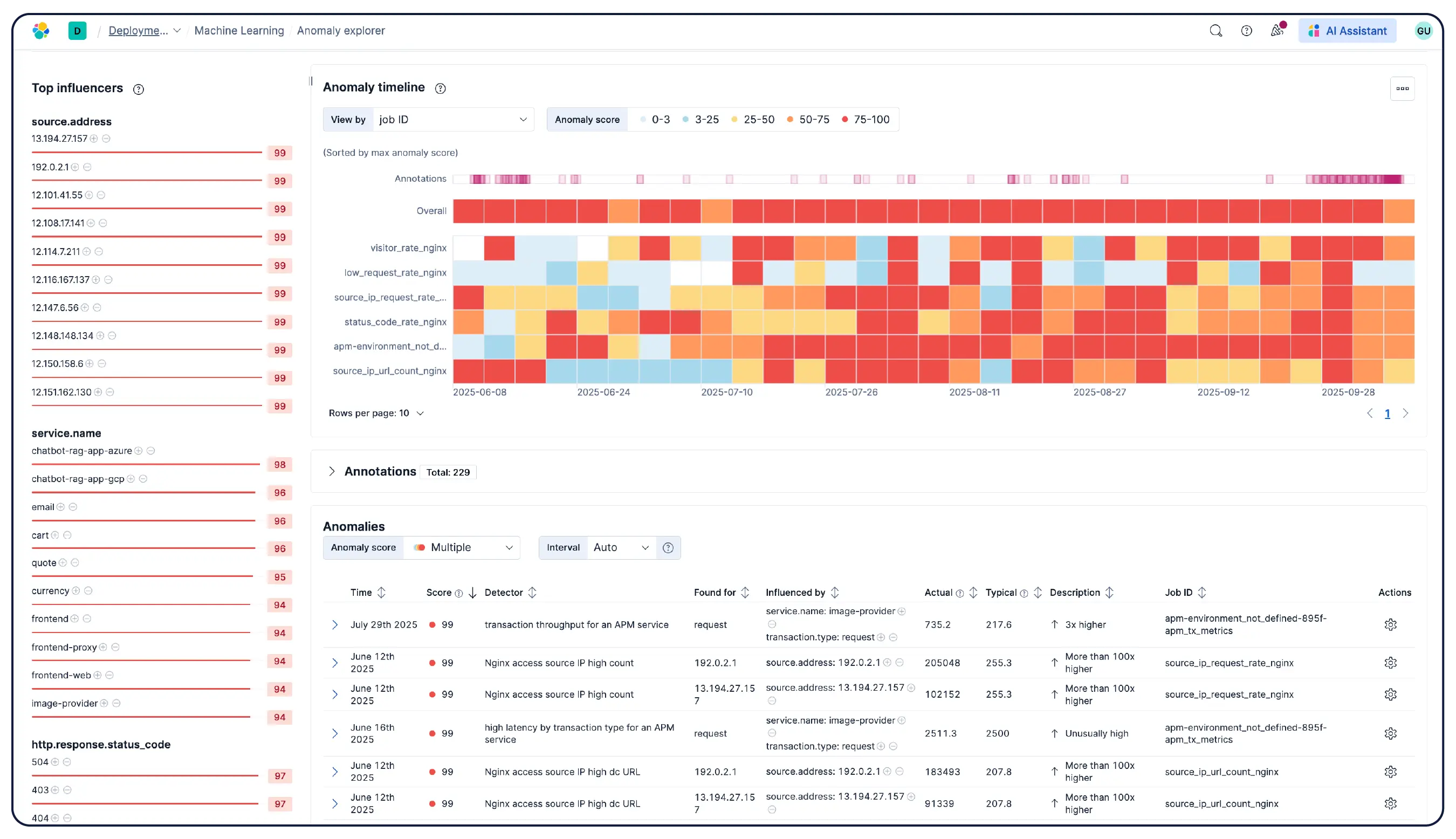
Elastic Observability는 호스트, 컨테이너, 클라우드 서비스 및 Kubernetes 클러스터에서 메트릭, 로그 및 추적을 수집하고 Elasticsearch에 저장하여 상관관계를 분석함으로써 팀이 모든 신호를 한 곳에서 조사할 수 있도록 지원합니다. Elastic은 550개 이상의 기본 통합 기능과 OpenTelemetry 네이티브 지원을 통해 클라우드, 온프레미스, Kubernetes, 서버리스 및 호스트 전반에 걸쳐 가시성을 제공합니다. Elastic Agent는 Fleet을 통해 중앙 집중식으로 데이터 수집을 처리하므로 호스트별 에이전트 구성이 필요하지 않습니다. 머신 러닝 기반 이상 탐지 기능은 비정상적인 사용 패턴을 자동으로 감지하며, 인프라 메트릭이 애플리케이션 추적 및 로그와 함께 저장되므로 엔지니어는 플랫폼을 벗어나지 않고도 경고에서 바로 상관관계가 있는 컨텍스트로 전환하여 분석할 수 있습니다.
Elastic은 Kubernetes 모니터링을 지원합니까?
Elastic은 Kubernetes 모니터링을 지원합니까?
네. Elastic Observability는 EKS, AKS, GKE의 관리형 클러스터와 자체 관리형 클러스터를 포함한 Kubernetes 환경 모니터링을 위해 설계되었습니다. Elastic은 동적인 Kubernetes 워크로드의 변경 사항을 자동으로 검색하고 서비스와 구성 요소가 실행되는 모든 위치에서 모니터링하며, 인제스트 시 메타데이터를 보강하여 시스템 전체에서 공통 속성을 필터링, 추적 및 식별할 수 있도록 지원합니다. 포드가 생성되거나 소멸될 때 Elastic은 수동 재구성 없이도 그에 맞춰 작동합니다. 클러스터 리소스 사용률, 포드 수준 로그, 애플리케이션 추적 및 인프라 메트릭은 모두 단일 배포에서 수집되어 Kibana에서 상호 연관 분석되며, 이상 탐지 및 로그 분류 기능을 통해 미처 인지하지 못했던 문제를 발견할 수 있습니다.
Elastic은 어떤 데이터 형식을 지원합니까?
Elastic은 어떤 데이터 형식을 지원합니까?
Elastic Observability는 개방형 표준을 기반으로 구축되었습니다. 스키마 변환이나 독점적인 변환 없이 OpenTelemetry Protocol(OTLP)의 로그, 메트릭, 추적을 기본적으로 수집합니다. EDOT(Elastic Distributions of OpenTelemetry)는 프로덕션 환경에 최적화된 OTel 네이티브 에코시스템을 제공합니다. EDOT Collector를 설치하고 언어 SDK를 사용하여 자동 계측을 활성화하면 OTel 스키마를 그대로 유지한 채 데이터가 Elasticsearch로 전송됩니다. Prometheus 메트릭과 PromQL을 기본적으로 지원하며, 클라우드 서비스 제공자, 데이터베이스, 메시지 큐, 네트워크 장치, 애플리케이션 프레임워크 등 450개 이상의 원클릭 통합 기능을 제공합니다. Elastic Agent와 Beats는 거의 모든 일반적인 소스의 구조화된 로그 형식과 비구조화된 로그 형식을 처리합니다.
Elastic은 어떻게 인프라 모니터링 비용을 절감합니까?
Elastic은 어떻게 인프라 모니터링 비용을 절감합니까?
Elastic은 저장 공간 및 아키텍처 계층 모두에서 통합 가시성 비용을 해결합니다. Logsdb 인덱스 모드는 데이터 순서를 최적화하고, 합성 소스를 제거하며, 압축을 개선함으로써 로그 저장 공간 요구 사항을 최대 65%까지 줄일 수 있습니다. 메트릭의 경우, 시계열 데이터 스트림(TSDS)은 열 형식 저장 및 시계열 특화 코덱(델타 오브 델타, 실행 길이 인코딩, XOR 인코딩)을 사용하여 Kubernetes, AWS 및 Nginx와 같은 통합 전반에 걸쳐 메트릭 디스크 공간을 최대 70%까지 줄입니다. Elastic Cloud Serverless를 사용하는 팀의 경우, 클라우드 네이티브 객체 저장 공간이 기록 시스템이므로 모든 데이터는 객체 저장 공간 경제성으로 저장되며 계층 또는 용량 계획이 필요하지 않습니다.
Elastic의 지표 가격은 경쟁사와 비교했을 때 어떠합니까?
Elastic의 지표 가격은 경쟁사와 비교했을 때 어떠합니까?
Elastic Observability는 사용량 기반 요금제를 사용하며 호스트별 요금이나 최고 사용량 기준 요금제가 없습니다. Datadog의 호스트별 요금제는 월평균 사용량이 아닌 월 전체의 최대 노드 수를 기준으로 자동 스케일링 이벤트에 대한 요금을 부과합니다. 사용자 지정 메트릭은 추가 비용이 발생하며 평균 요금의 최대 52%를 차지할 수 있습니다. Elastic의 요금 모델 덕분에 임시 워크로드나 고용량 Prometheus 환경에서도 월말에 예상치 못한 요금 폭탄을 피할 수 있습니다.