해야 할 일을 언제나 정확히 이해하는 AI 에이전트를 위한 컨텍스트 엔지니어링
컨텍스트 엔지니어링과 에이전트 AI를 위한 개방형 통합 플랫폼인 Elasticsearch를 사용해 비정형 비즈니스 데이터를 신뢰할 수 있는 컨텍스트로 전환하여 LLM에 활용하세요.
컨텍스트 엔지니어링의 핵심 역량
신뢰할 수 있는 AI 구축은 컨텍스트에서 시작됩니다.
컨텍스트 엔지니어링은 모델이 올바른 정보로부터 학습하고, 추론하고, 행동할 수 있도록 하는 필수 구성 요소인 데이터, 검색, 도구 및 메모리를 연결합니다.




Elastic의 장점: 에이전트에게 올바른 정보, 도구 및 가드레일 제공
모든 데이터. 컨텍스트를 위한 단일 플랫폼.
Elasticsearch를 사용하여 컨텍스트를 엔지니어링하세요. 정확한 검색 기능을 추가하거나 대화형 AI 스택 전체를 구성하세요. 기본값과 확장 옵션을 사용하여 원하는 지점에서 시작하고, 간단한 Q&A부터 정교한 에이전트 워크플로우까지 관련성 여정을 설계하세요. 클라우드, 온프레미스 또는 완전한 에어갭 환경에 배포하여 데이터가 있는 위치에서 컨텍스트 계층을 운영하세요.
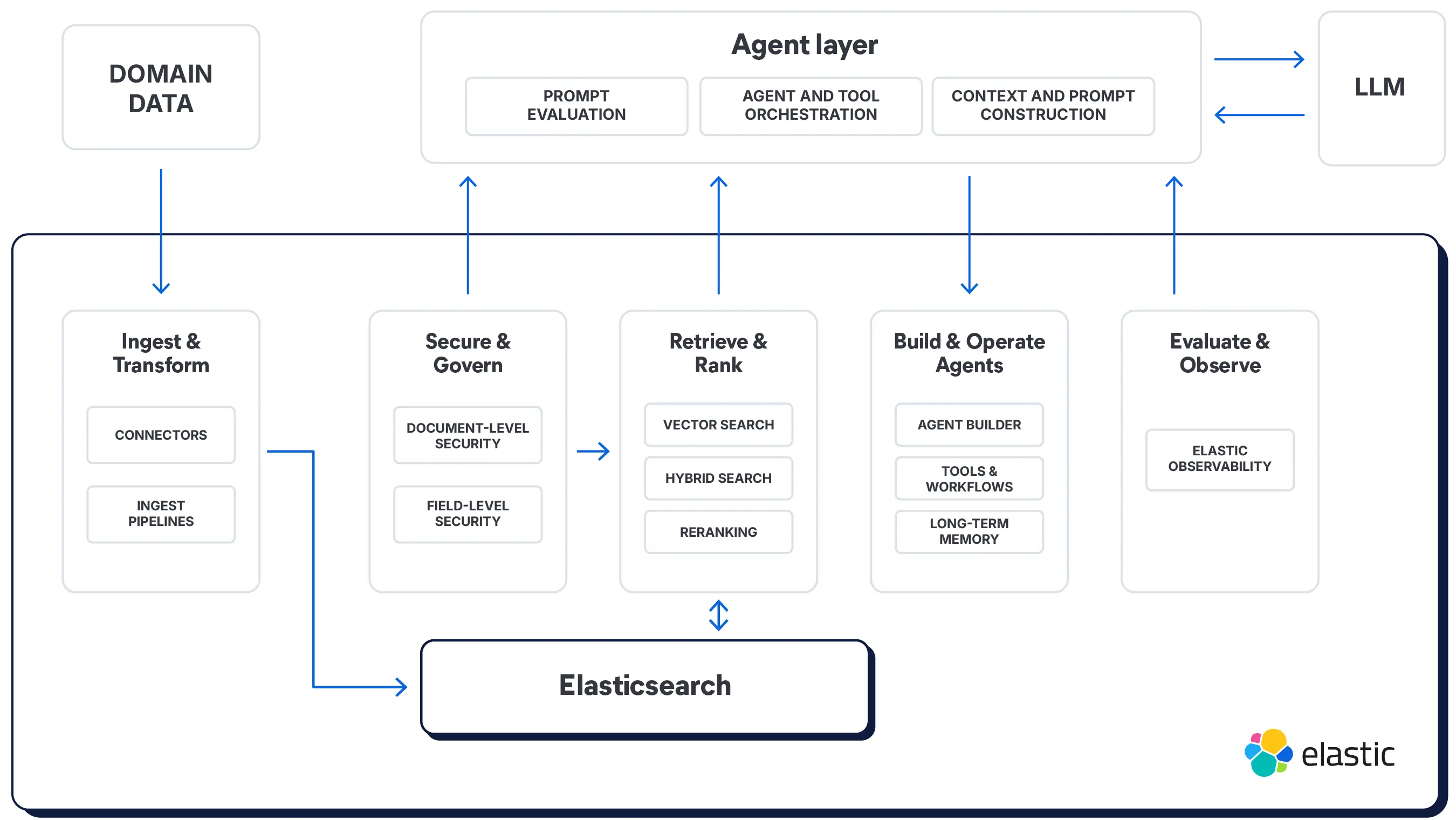
컨텍스트 엔지니어링용 런치패드
데이터 수명 주기를 위한 견고한 API. 텍스트, 임베딩, 지리 정보, 시계열 데이터, 메타데이터에 대해 인덱싱, 검색, 필터링을 수행하고 역할 기반 접근 제어(RBAC)를 적용하세요.
출처가 명확하고 필드 구문 분석이 가능하도록 문서를 정리하고 레이블을 지정하며 정규화하는 수집 파이프라인을 정의하세요.
POST /_ingest/pipeline { "description": "Clean and enrich documents", "processors": [ { "set": { "field": "source", "value": "access_logs_prod" } }, { "grok": { "field": "message", "patterns": [ "{TIMESTAMP_ISO8601:timestamp} User %{WORD:user} accessed - %{IP:ip}" ] } } ] }
POST /_ingest/pipeline
{
"description": "Clean and enrich documents",
"processors": [
{
"set": {
"field": "source",
"value": "access_logs_prod"
}
},
{
"grok": {
"field": "message",
"patterns": [
"{TIMESTAMP_ISO8601:timestamp} User %{WORD:user} accessed - %{IP:ip}"
]
}
}
]
}
에이전트 구성
단일 스니펫으로 도구, 에이전트 및 채팅 인터페이스를 생성하고 확장하세요.
POST /api/agent_builder/tools
{
"id": "find_client_exposure_to_negative_news",
"type": "esql",
"description": "Finds client portfolio exposure to negative news",
"configuration": { "query": "ES|QL query here" },
"params": { "time_duration": { "type": "keyword" } }
}
동급 최고입니까? 바로 내장되어 있습니다
Elastic Inference Service(EIS)에서 Jina AI 모델로 시작해 보세요. 또한 AI 에코시스템 전반에 걸친 네이티브 통합을 통해 기존에 사용 중인 모델을 연동할 수도 있습니다.
관련성 여정 최적화
Elasticsearch는 정밀 검색부터 전체 대화형 AI 스택에 이르기까지 모든 수준에서 관련성을 제어할 수 있습니다.
Elasticsearch Labs 블로그에서 전체 튜닝 과정을 살펴보세요.
자주 묻는 질문
컨텍스트가 AI와 에이전트에 중요한 이유는 무엇인가요?
컨텍스트가 AI와 에이전트에 중요한 이유는 무엇인가요?
에이전트는 워크플로우 전반에 걸쳐 장기적인 컨텍스트, 상태 및 메모리를 유지관리하는 데 어려움을 겪습니다. 컨텍스트가 있어야 시간이 지나도 일관성과 인식을 유지할 수 있습니다. 컨텍스트가 없으면 아무리 강력한 모델이라도 중요한 사항을 놓쳐 격차, 환각 또는 오해로 이어질 수 있습니다. 컨텍스트 엔지니어링은 모든 응답이 정확하고 관련성 있으며 시기적절한 정보에 기반하게 합니다.
Elasticsearch는 어떻게 컨텍스트 엔지니어링을 가능하게 하나요?
Elasticsearch는 어떻게 컨텍스트 엔지니어링을 가능하게 하나요?
Elasticsearch는 대규모 확장 환경에서도 관련성을 유지하도록 설계되어 있으며, 이는 컨텍스트 엔지니어링의 기반이 됩니다. 단일 플랫폼에 벡터, 키워드, 정형 데이터 검색을 분석, 추론 및 가시성과 함께 통합하기 때문에 개발자가 정형화 및 비정형화 비즈니스 데이터를 정밀하게 저장, 검색 및 순위화할 수 있으며, 그 결과 에이전트는 항상 정확한 컨텍스트를 제공할 수 있습니다.
Elasticsearch는 Agent Builder를 통해 채팅, 검색, 도구 생성 및 오케스트레이션 기능을 플랫폼 내부로 직접 통합하여 기능을 확장합니다. 개발자는 자체 데이터, 모델 및 도구를 활용하여 몇 분 만에 컨텍스트 중심의 에이전트를 구축하고 테스트 및 확장할 수 있습니다. 이 모든 과정은 Elasticsearch의 관련성과 보안성 그리고 성능으로 지원됩니다.
자체 모델이나 프레임워크를 사용할 수 있습니까?
자체 모델이나 프레임워크를 사용할 수 있습니까?
예. 개방형 추론 API와 LangChain, LlamaIndex, 모델 컨텍스트 프로토콜(MCP) 통합을 통해 자체 모델을 가져와 Elasticsearch에서 에이전트 빌더 워크플로우를 직접 확장할 수 있습니다.
컨텍스트 엔지니어링을 온프레미스 환경이나 에어갭 환경에서 수행할 수 있나요?
컨텍스트 엔지니어링을 온프레미스 환경이나 에어갭 환경에서 수행할 수 있나요?
예. Elasticsearch는 외부 연결이 필요하지 않은 완전한 온프레미스와 에어갭 배포 환경에서 주권형 클라우드를 지원합니다. 국방, 정부, 금융 서비스, 의료 분야의 조직은 하이브리드 검색, 시맨틱 순위 재지정, 에이전틱 워크플로우, RBAC를 포함한 완전한 컨텍스트 엔지니어링 파이프라인을 전적으로 자체 인프라 내에서 구축할 수 있습니다. Elastic Cloud Enterprise(ECE)를 사용하면 Elastic이 Elastic Cloud를 운영하는 데 사용하는 것과 동일한 도구로 온프레미스 Elasticsearch 클러스터를 대규모로 오케스트레이션할 수 있습니다.