Elasticsearch 7.5.0 released
Today we are pleased to announce the release of Elasticsearch 7.5.0, based on Lucene 8.3.0. Version 7.5 is the latest stable release of Elasticsearch, and is now available for deployment via Elasticsearch Service on Elastic Cloud.
As with the previous release, Elasticsearch 7.5 features a number of improvements to core search and analytics capabilities, cluster management and administration, machine learning, and more.
If you’re interested in learning more about this release's new features, you're in the right place as we dive deeper into many of the release highlights below. Alternatively, if you’d rather skip ahead and get right to work by spinning up a cluster on Elastic Cloud, downloading the latest bits to your laptop, or reviewing the release notes, we have the links you need:
- Start Elasticsearch on Elastic Cloud
- Download Elasticsearch
- Elasticsearch 7.5.0 release notes
- Elasticsearch 7.5.0 breaking changes
Core search & analytics improvements
Simplifying ingest with the new enrich processor
We are pleased to announce the addition of the new enrich processor. This powerful new processor enables users to more easily lookup and enrich data as it comes into Elasticsearch. With the new enrich processor in place, users seeking to query or aggregate by information that does not exist in the original documents, but that can be inferred from information in other (existing) indices, is not only possible - it’s easy.
The ingest pipeline has been a powerful tool for users to control the flow of data, and to extract and transform data in real time. Processors can perform tasks like: IP address lookups, timestamp identification, regex data extraction, and the general massaging of data (with set, rename, remove, lowercasing, and HTML stripping). The enrich processor uses the speed and scale of the ingest pipeline to bring lookup-based data enrichment to documents as they are processed.
For example, users may search by a department name, while the document that was sent to Elasticsearch only included the department ID, alternatively a user may aggregate by an electoral constituency by using the name of the constituency, while the documents that were indexed only included the geo location (longitude and latitude) of each voter.
Here’s how it works: like most things in Elasticsearch it all starts with data. The enrich processor uses data within your existing indices to build a lookup index. This source index could be things like user data, geo location data, IP blacklists, product data, and so forth. Next comes the creation of an enrich policy. The policy contains 4 items: the type, index, match field, and enrich fields. With respect to types, we have 2 types today: match and geo_match. These types are used by the enrich processor to match incoming documents with data stored in the lookup index. Match issues a term query against the lookup index while the geo_match uses geo_shapes. Once the policy is defined you can execute the policy. This creates the lookup index based on the index and fields defined in the policy. The final step is to create or add an ingest pipeline for the enrich processor. Once this is done, incoming data that uses this pipeline will be enriched automatically. A user can always refresh the lookup index by re-running the policy as new data comes into the source index.
The enrich processor is being released under Elastic’s free Basic subscription tier.
Higher resolution geotile analysis with composite aggregations
Composite aggregations (introduced in 6.1) are used to group together all documents (even those from potentially different sources) that have the same values in certain fields. With 7.5, geo tile grid aggregations can now be a data source for a composite aggregation. This enhancement enables users to more easily aggregate / collect all documents within a given tile or set of tiles on a geographical map and provides a memory-efficient way to scroll through buckets.
This enhancement is particularly useful when needing to further process a large quantity of geo tile grid buckets, which was practically impossible prior to this enhancement. The geo tile grid aggregation answered the need for showing data to users on a map, because the number of tiles a user can comprehend is rather small, but what if an extra stage of analysis is performed by a machine, which can, and would benefit from handling, a much larger number of buckets? Enabling geotile grid aggregation to efficiently scroll through buckets facilitates more sophisticated use cases, such as running machine learning tools that utilize the initial analysis performed at scale within Elasticsearch. This also allows for the presentation of fine grained maps, which would have been challenging using geotile aggregation without a composite aggregation.
Geotile grid aggregation as a source for composite aggregation is being released under the Apache 2.0 license.
Shape support in SQL
Whether you’re a new user (likely proficient in SQL but not DSL) or seeking to integrate Elasticsearch with systems that have mechanisms for integrating with data sources using SQL, SQL support remains a top priority of the Elasticsearch team. To this end, with the release of Elasticsearch 7.5, all SQL functionality that worked for geo_shape will now work for the new shape field type (new as of Elasticsearch 7.4).
Shape support in SQL is being released as an experimental feature under Elastic’s free Basic subscription tier.
Cluster management and administration
Snapshot lifecycle management retention
Elasticsearch 7.5 improves snapshot lifecycle management (SLM), first seen in Elasticsearch 7.4, a background snapshot manager that enables an administrator to define when and how often automatic snapshots of an Elasticsearch cluster are taken.
New to SLM is the ability to manage snapshot retention. SLM retention gives users a configurable and automated way to manage the removal of snapshots. Retention also provides a way for users to ensure they have a minimum number of snapshots even if a snapshot has expired - protecting users from failed snapshots. Elastic also knows that users want a way to protect their storage, so we have created a way to prevent too many snapshots being created with a maximum number of snapshots to keep.
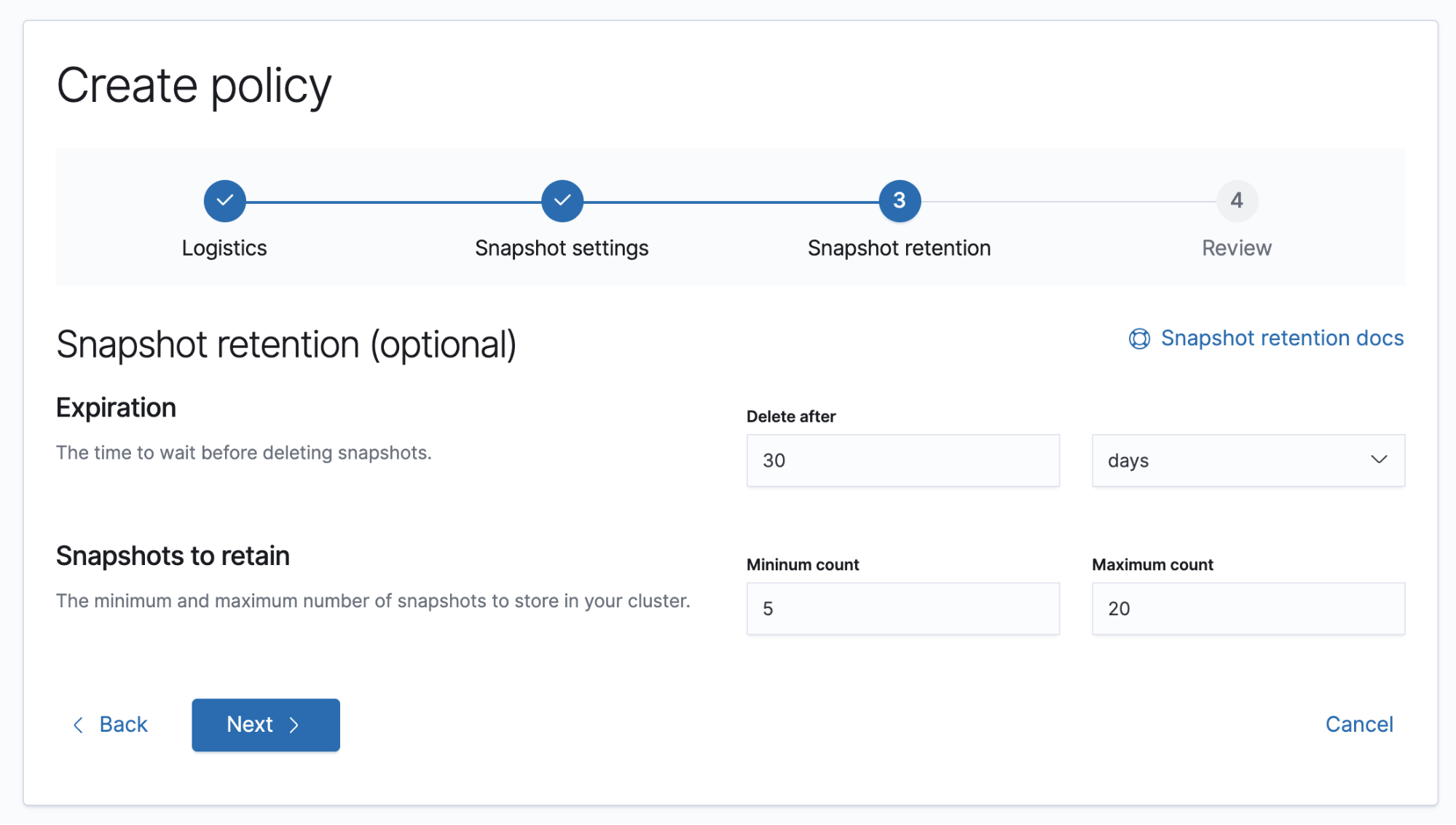
Snapshot lifecycle management retention is being released under Elastic’s free Basic subscription tier.
Cluster security enhancements
In our last release of Elasticsearch we introduced new cluster privileges to manage API keys. Elasticsearch 7.5 builds upon this functionality with the introduction of an API keys app in Kibana. This new user interface allows users to easily view and invalidate their own API keys and administrators to view and invalidate all users' API keys.
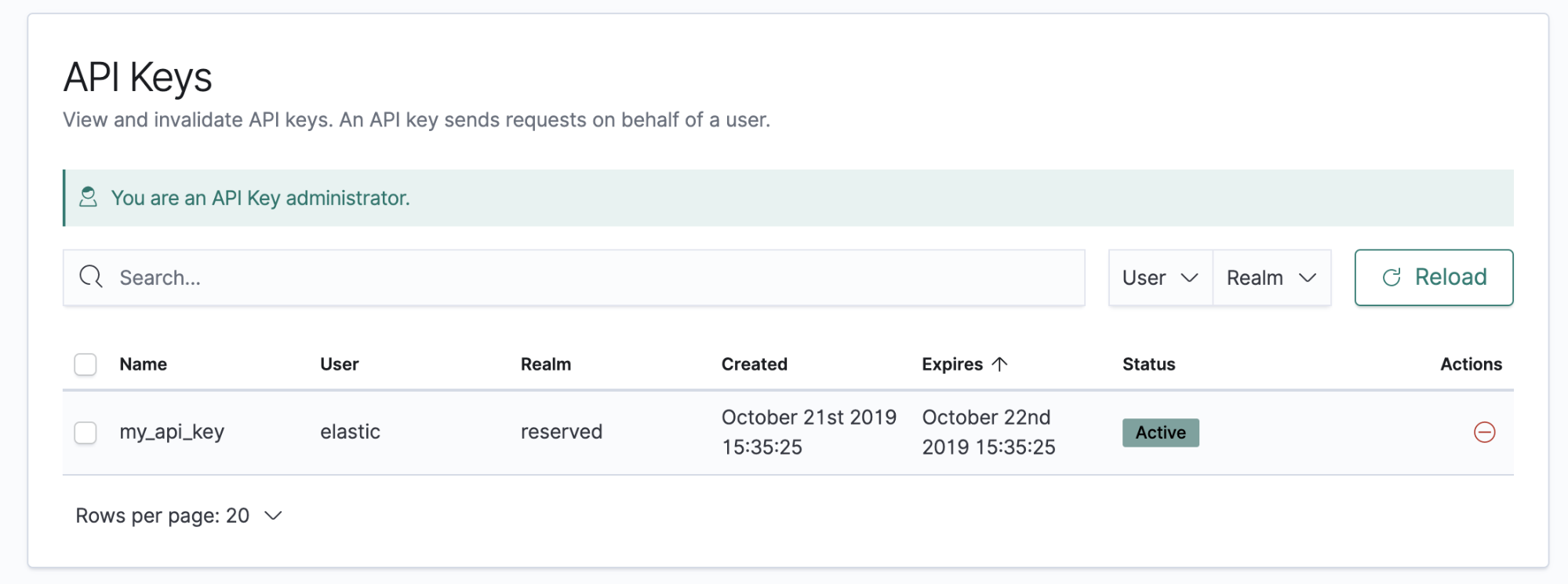
In additional security news, Elasticsearch 7.5 includes the new create_doc index privilege. With the previous set of index privileges, users that were allowed to index new documents were also allowed to update existing ones.
With the new create_doc privilege, cluster administrators can create a user that is allowed to add new data only. This gives the minimum privileges needed by ingest agents, with no risk that that user can alter and corrupt existing logs. These administrators can (now) rest assured knowing that components that live directly on the machines that they monitor cannot corrupt or hide tracks that are already into the index.
Both the API keys user interface and the new create_doc index privilege are being released under Elastic’s free Basic subscription tier.
Improvements to upgrades with Cross-Cluster Replication (CCR)
In March 2019 we introduced one of the most heavily requested features for Elasticsearch — cross-cluster replication (CCR). CCR has a variety of use cases, including cross-datacenter and cross-region replication, replicating data to get closer to the application server and user, and maintaining a centralized reporting cluster replicated from a large number of smaller clusters.
With the release of Elasticsearch 7.5 we are excited to introduce pause and resume API endpoints for CCR auto-flow patterns. CCR bi-directional replication (i.e., cross-replicating indices between multiple Elasticsearch clusters so no manual failover event is needed) is quickly becoming a popular CCR architecture. In an effort to make it easier to upgrade clusters with this architecture, the CCR pause / resume auto-follow patterns API enables a user to temporarily pause CCR auto-follow patterns during the upgrade process, essential to bi-directional replication architectures.
Pause / resume CCR auto-flow patterns are being released under Elastic’s Platinum subscription tier.
Machine Learning
Classification API
Elasticsearch 7.5 adds the ability to build machine learning data frame analytics jobs via API for binary classification. Classification is a machine learning process for predicting the class or category of a given data point in a dataset. With binary classification the variable you want to predict has only two potential values.
The classification API is being released as an experimental feature under Elastic’s Platinum subscription tier
That's not all, folks!
While the above listed features might have taken the spotlight, there were many more features included with the release of Elasticsearch 7.5 - be sure to check out the release notes for additional information.
Ready to get your hands dirty? Spin up an Elasticsearch cluster on Elastic Cloud or download Elasticsearch today. Try it out. And be sure to let us know what you think on Twitter (@elastic) or in our forum. You can report any problems on the GitHub issues page.