Elasticsearch Service에서 hot-warm 로깅 클러스터 배포
Amazon Elasticsearch Service와 Elastic 공식 Elasticsearch Service 간의 차이점에 대해 좀더 알아보고 싶으세요? AWS Elasticsearch 비교 페이지에서 확인해 보세요.
로깅부터 검색 분석 등에 이르기까지 모든 사용 사례를 지원하기 위해 최근에 Elastic Cloud Elasticsearch Service에 새로운 기능이 많이 추가되었습니다. 주요 발표 한 가지는 hot-warm 아키텍처 배포 템플릿의 추가였습니다. 이것은 인하된 가격 모델과 쌍을 이루는 것으로, 로깅 사용 사례에 대해 Elasticsearch Service를 사용할 때 더 큰 가치를 제공해 줍니다.
이 블로그 포스팅에서는 머신 러닝, 알림 등과 같은 다른 강력한 Elastic Stack 기능들과 더불어 새로운 hot-warm 배포 템플릿 사용 방법을 다룹니다. 다 합쳐 10분도 채 걸리지 않으며, 로그 데이터 내에서 더 많은 인사이트를 발견하는 데 도움이 되실 것입니다. Elasticsearch Service 계정이 없으시면, 14일 무료 체험판에 등록하세요.
hot-warm 아키텍처란?
hot-warm 아키텍처는 Elasticsearch 배포를 “hot” 데이터 노드와 “warm” 데이터 노드로 분리시키는 강력한 방법입니다. hot 데이터 노드는 새롭게 들어오는 모든 데이터를 처리하며, 신속하게 데이터를 수집하고 검색할 수 있도록 더 빠른 저장 공간을 사용합니다. warm 노드는 저장 공간 밀도가 더 높으며, 로그 데이터를 더 효과적인 비용으로 보관합니다. 이 두 가지 유형의 데이터 노드를 함께 사용하면 들어오는 데이터를 효과적으로 처리하고 쿼리 작업에 사용될 수 있도록 하며, 동시에 큰 비용을 들이지 않고 더 오랜 기간 동안 데이터를 보유할 수 있습니다.
이것은 최근 로그(즉, 지난 2주)에 대부분의 중점을 두게 되고, 더 오래된 로그(보관 정책이나 다른 이유로 필요할 수 있는)는 더 느린 쿼리 시간에 맞게 조정할 수 있어, 특히 로깅 사용 사례에 유용합니다.
hot-warm 배포 만들기
Elasticsearch Service는 다른 호스트형 Elasticsearch 공급자와는 다르게 Elastic Cloud를 특별하게 만들어주는 기능인 hot 데이터 노드를 warm 데이터 노드로 이전하는 인덱스 큐레이션 정책 관리를 포함해 hot-warm 아키텍처를 아주 쉽고 간단하게 배포할 수 있게 해줍니다. 얼마나 쉽고 간단할까요? 이 블로그에서는 무료 1GB 머신 러닝 노드와 1GB Kibana 노드를 포함해 hot-warm 로깅 클러스터를 5분 이내에 실행시킬 것입니다.
시작하려면, Elasticsearch Service 콘솔로 가서 배포 만들기를 클릭합니다.
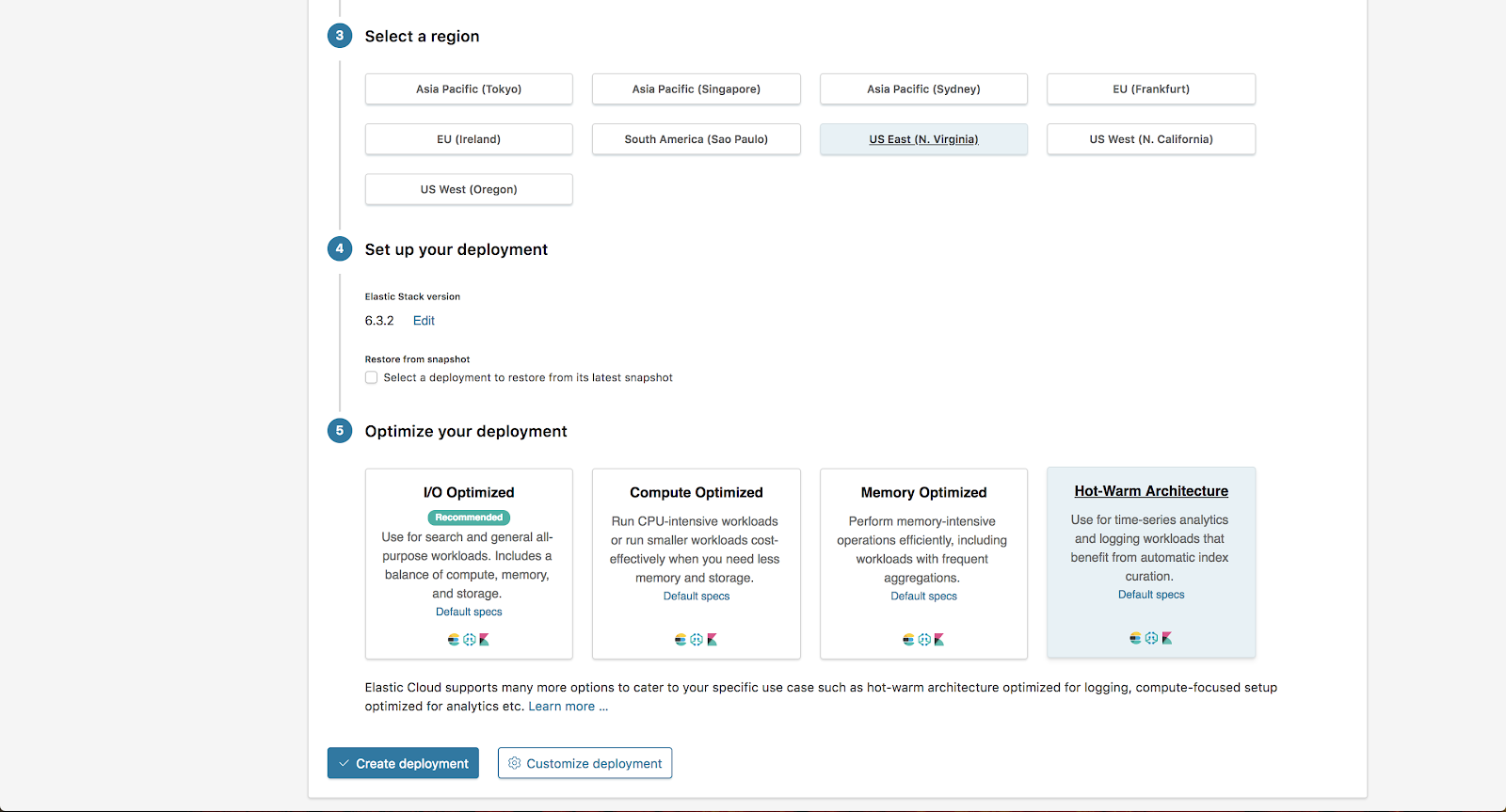
여기서는, AWS에서 미국 동부 지역을 선택하고, “배포 최적화” 섹션에서 “hot-warm 아키텍처”를 선택합니다. 여기에서 배포 사용자 정의를 선택하겠습니다.
사용자 정의 페이지에서, hot 인스턴스 구성과 warm 인스턴스 구성의 크기를 독립적으로 조정할 수 있습니다. 구체적인 필요에 맞춰 이 인스턴스 크기를 조정하는 방법을 알아보려면, hot-warm 크기 조정 블로그 포스팅을 확인해 보세요.
이 예에서는 기본값을 유지하겠습니다.
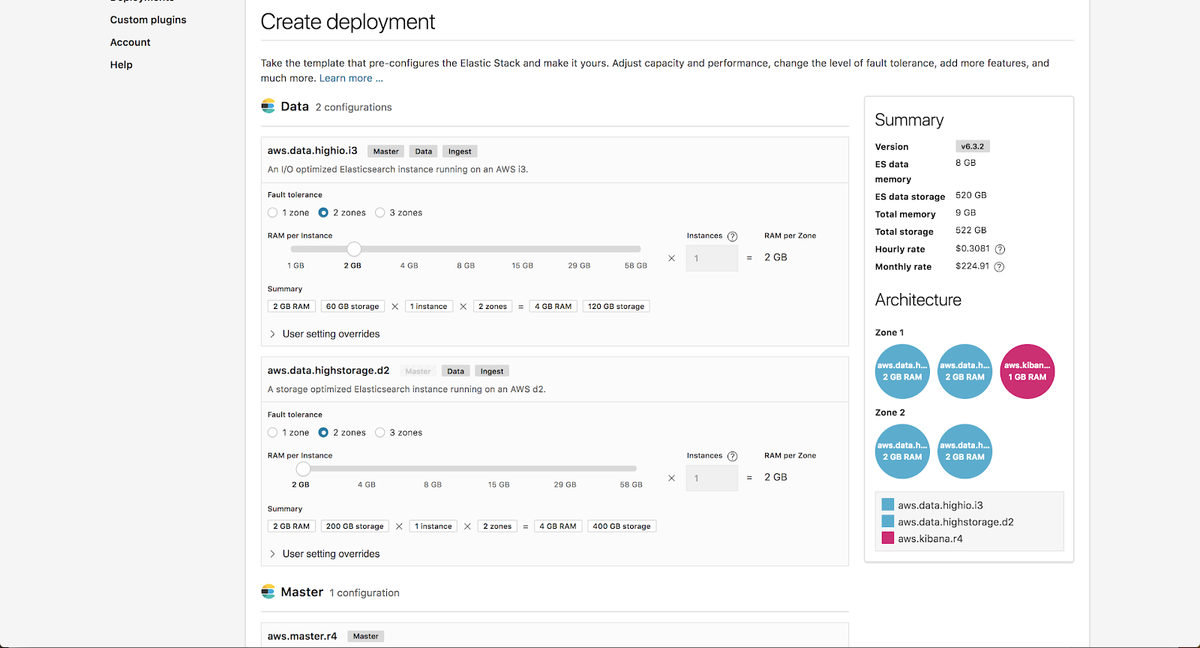
추가로, 배포에서 머신 러닝을 활성화하겠습니다. Elasticsearch Service의 모든 배포에는 무료 1GB 머신 러닝 노드와 1GB Kibana 노드가 포함됩니다.
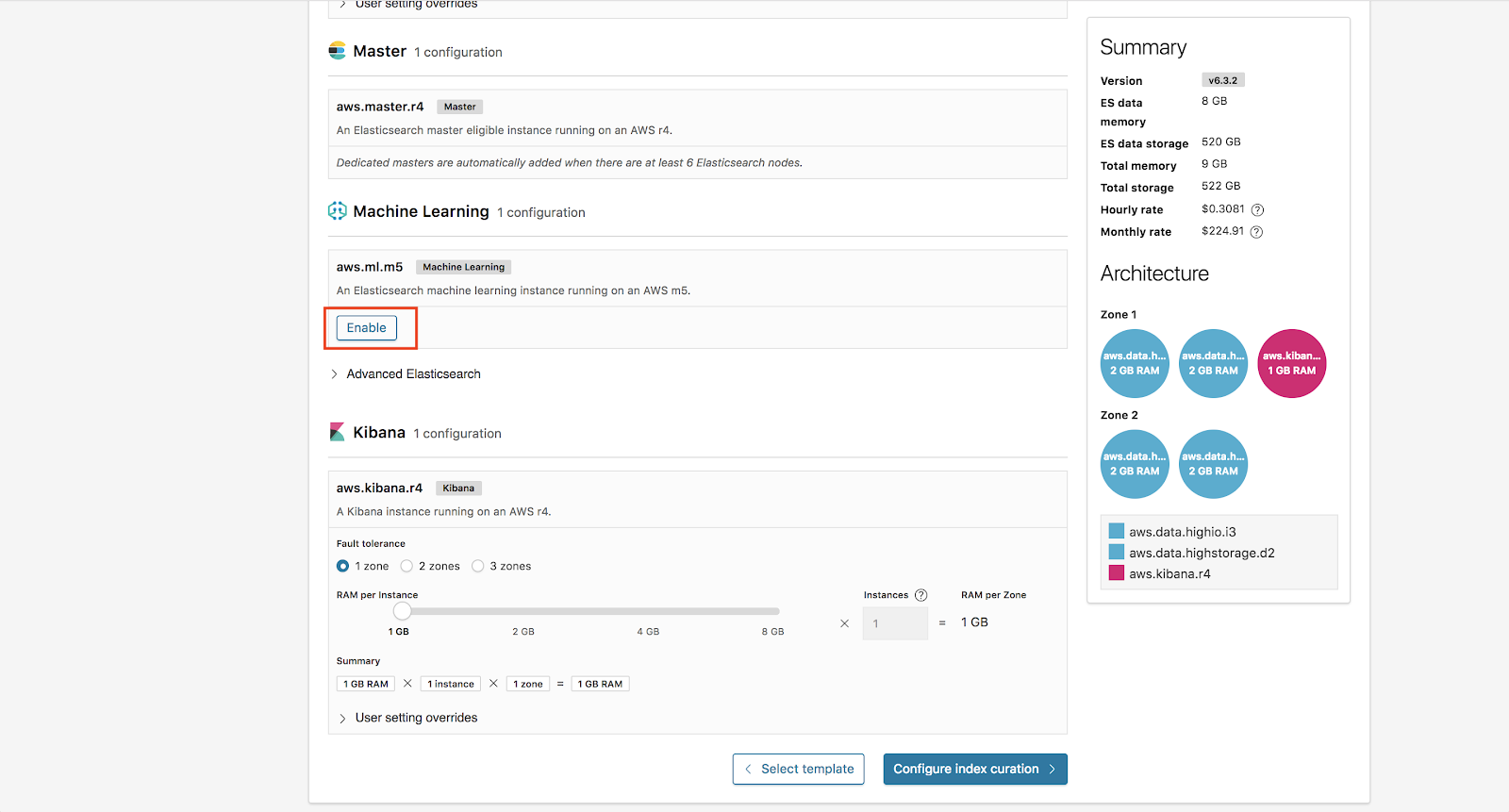
여기에서, 이제 인덱스 큐레이션 구성을 클릭합니다.
인덱스 큐레이션
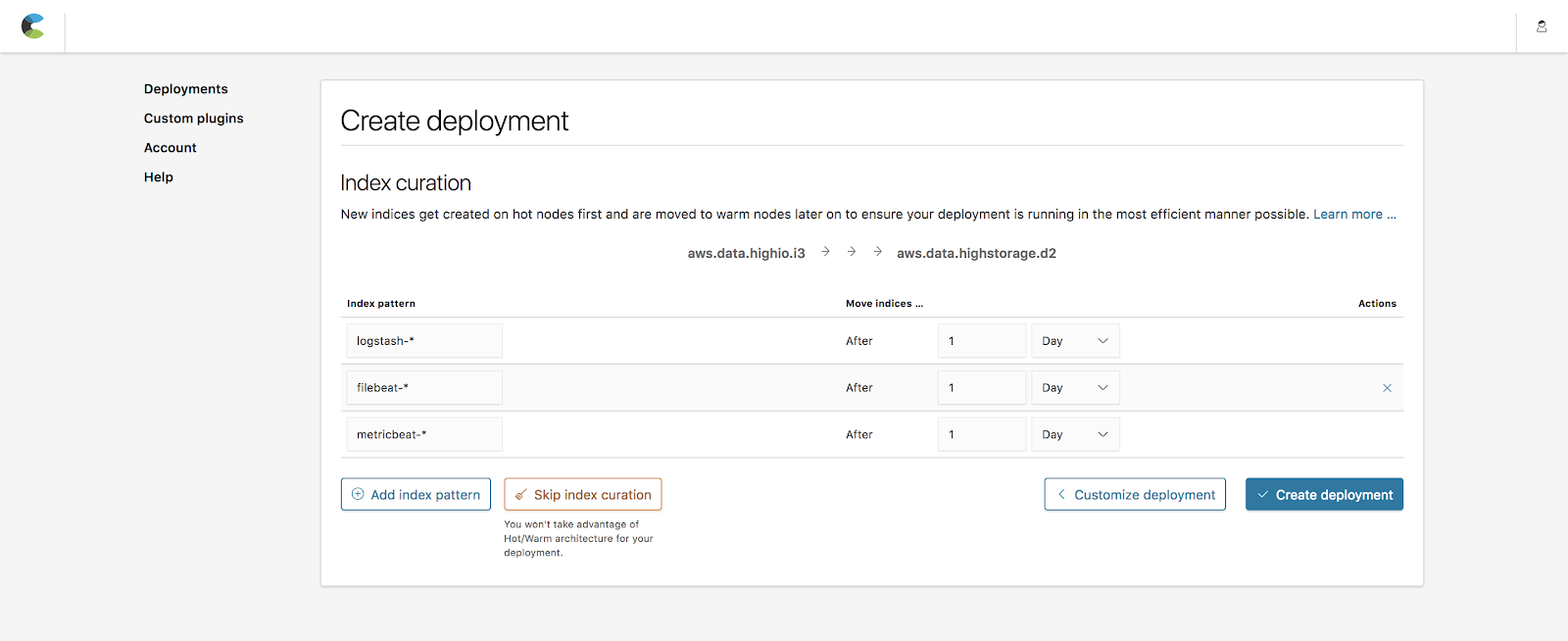
인덱스 큐레이션은 인덱스를 hot 노드에서 얼마나 오래 유지하다가 warm 노드로 이전할 것인지 정의할 수 있게 해줍니다. 기본값에는 이전하기 전에 1일 동안 Beats(metricbeat-*, filebeat-*)와 Logstash(logstash-*)가 생성한 익숙한 인덱스들이 포함됩니다. 이 예에서는 이 기본값을 유지하겠습니다.
참고: 배포 후에도 배포 메뉴에 있는 운영 페이지로 가서 언제든지 이 규칙을 변경할 수 있습니다.
다 마치고 나면, 배포 만들기를 클릭합니다.
축하합니다. 이제 당당하게 강력한 hot-warm 아키텍처를 배포했습니다!
데이터 전송
이제 hot-warm 배포가 실행되고 있으니, 일부 로깅 데이터 전송을 시작해 보겠습니다. 이렇게 하려면, 로컬 컴퓨터에 Beats를 설치한 다음, 배포에서 생성된 Elasticsearch Service 클라우드 ID와 비밀번호를 사용해 데이터 전송을 시작합니다. Beats와 Elasticsearch Service 설정에 대한 전체 세부사항은 Elasticsearch Service에서 Metricbeat를 사용하는 데 대한 블로그 포스팅을 봐주세요.
클라우드 ID를 찾으려면, 배포 페이지 > 클라우드 ID로 가시면 됩니다.
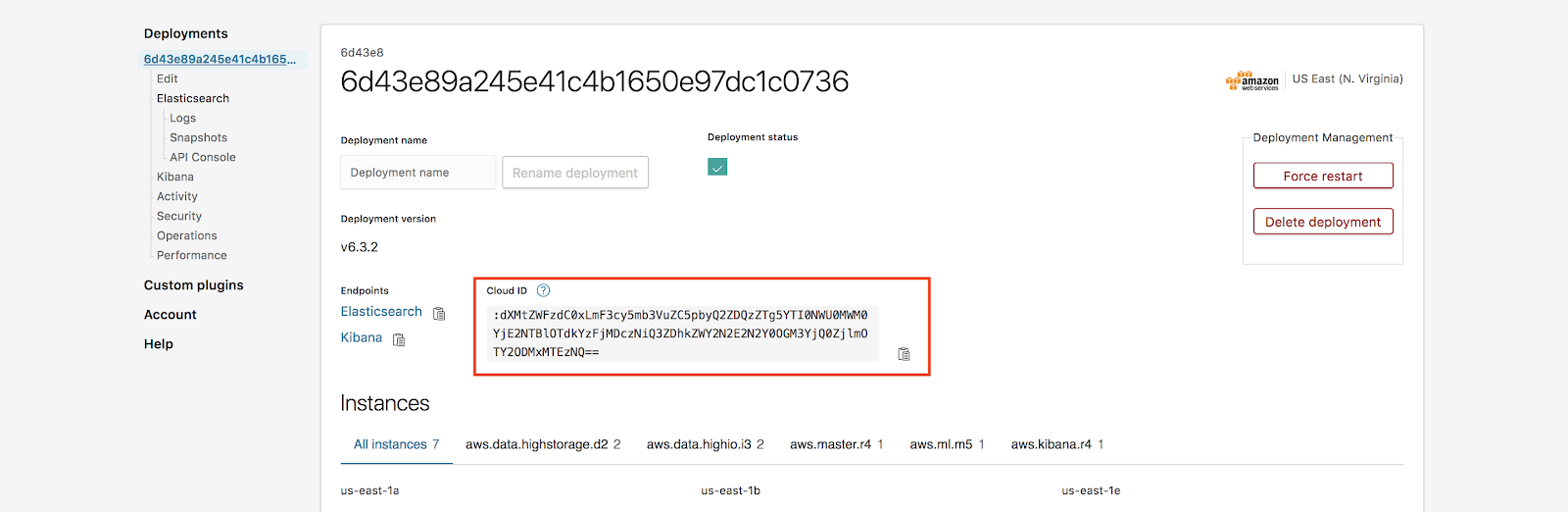
참고: 비밀번호를 잊으셨나요? 문제 없습니다! Elasticsearch Service의 경우, 배포 -> 보안 -> 비밀번호 재설정에서 Elastic 사용자 비밀번호를 재설정할 수 있습니다.
로컬 컴퓨터에서 흘러나오는 데이터가 있으니 Kibana에 로그인해서 대시보드를 확인해 봅시다. 계속해서 더 많은 데이터가 들어오므로, Elasticsearch Service는 날마다 계속해서 hot 노드에서 warm 노드로 데이터를 돌리게 됩니다.
머신 러닝 추가
Elasticsearch Service의 또다른 멋진 새 기능은 이제 머신 러닝을 지원한다는 것입니다. 아울러, 모든 사용자가 배포와 함께 1GB 머신 러닝 노드를 무료로 추가할 수 있습니다. 이미 우리 배포에 이것이 포함되어 있으므로, Kibana로 가서 머신 러닝 앱을 열어 머신 러닝 작업을 만들 수 있습니다.
머신 러닝 및 다른 사용 사례에 대한 더 자세한 정보는 다음의 Elastic 머신 러닝 기능 페이지를 확인해 주세요.
결론
Elasticsearch Service의 새 기능은 간단한 클릭 몇 번만으로 강력한 hot-warm 아키텍처를 시작할 수 있게 해줍니다. 아울러, 머신 러닝과 보안 같은 다른 Elastic Stack 기능과 함께 Elasticsearch Service에서 로그 및 메트릭 모니터링은 그 어느 때보다도 강력해졌습니다.
궁금하신가요? 14일 체험판을 직접 사용해 보세요.