Elastic Cloud Elasticsearch Service에서 로깅과 메트릭을 위한 hot-warm 아키텍처 설정
Amazon Elasticsearch Service와 Elastic 공식 Elasticsearch Service 간의 차이점에 대해 좀더 알아보고 싶으세요? AWS Elasticsearch 비교 페이지에서 확인해 보세요.
정말로 기대됩니다! Elastic Cloud Elasticsearch Service가 최근에 확장된 하드웨어 선택 및 배포 템플릿에 대한 지원을 추가했습니다. 이것은 로깅과 메트릭에 관련된 작업을 효율적으로 처리하는 데 안성맞춤입니다. 이 확장 기능으로 인해 새롭고 유연한 수많은 선택이 가능해졌습니다. 사용 사례에 가장 적합한 아키텍처를 선택하고 필요한 클러스터 크기를 계산하는 것은 까다로운 일이 될 수 있습니다. 걱정하지 마세요. 저희가 도와드리겠습니다!
이 블로그 포스팅을 통해 로깅 및 메트릭 사용 사례에 흔히 사용되는 다른 아키텍처와 언제 그 아키텍처를 사용해야 하는지에 대해 알려드리겠습니다. 또한 클러스터를 최대한 활용하실 수 있도록 클러스터 크기를 조정하고 관리하는 방법에 대한 지침도 제공해 드립니다.
내 로깅 클러스터에 사용할 수 있는 아키텍처는 어떤 것이 있을까?
가장 기본적인 Elasticsearch 클러스터 에서는 모든 데이터 노드가 동일한 사양을 가지며 모든 역할을 처리합니다. 이런 유형의 클러스터가 확장되면, 특정 작업을 위한 노드가 추가되는 경우가 많습니다. 예를 들면, 마스터 전용 노드, 수집 노드, 머신 러닝 노드 등입니다. 이것은 데이터 노드의 부담을 덜어줌으로써 클러스터가 효율적으로 운영될 수 있도록 합니다. 이 유형의 클러스터에서는 모든 데이터 노드가 색인과 쿼리 작업 부하를 균등하게 공유합니다. 모두가 동일한 사양이므로, 이것을 동일(uniform) 또는 균일(homogenous) 클러스터 아키텍처라고 부르곤 합니다.
로그와 메트릭 같은 시계열 데이터 작업을 할 때 특히 인기있는 또다른 아키텍처는 hot-warm 아키텍처라고 하는 것입니다. 이 아키텍처는 데이터가 일반적으로 변경이 불가능하고 시계열 기반 인덱스로 색인 된다는 원칙을 따릅니다. 따라서 각 인덱스가 포함하는 데이터는 특정 기간별로 구분되며, 나중에 인덱스 단위로 삭제를 함으로써 데이터의 보존과 수명 주기를 관리할 수 있게 됩니다. 이 아키텍처에는 다른 하드웨어 프로필을 갖는 다른 유형의 데이터 노드 두 개가 있는데, 바로 ‘hot’과 ‘warm’ 데이터 노드입니다.
hot 데이터 노드는 최신 인덱스들을 저장하며, 클러스터의 모든 색인 부하를 처리합니다. 또한 통상적으로 최신 데이터에 대한 쿼리가 가장 많기 때문에 이 노드는 일반적으로 매우 바쁩니다. Elasticsearch로의 색인은 CPU와 I/O를 대단히 집약적으로 사용하며, 추가적인 쿼리 부하는 이 노드가 강력하고 가장 빠른 저장 공간을 갖추어야 한다는 것을 의미합니다. 일반적으로 이것은 로컬 SSD를 장착한 형태입니다.
반면에 warm 노드는 비용 효율적인 방법으로 클러스터에서 읽기 전용 인덱스의 장기간 저장을 처리하기 위해 최적화됩니다. 이것은 일반적으로 상당한 양의 RAM과 CPU를 갖추지만 SSD 대신 로컬로 장착된 회전 디스크나 SAN을 사용하는 경우가 많습니다. 일단 hot 노드의 인덱스가 hot 노드 보존 기간을 초과하여 더 이상 색인이 되지 않으면, warm 노드로 이전됩니다.
데이터를 hot 노드에서 warm 노드로 이전하는 것이 꼭 쿼리 작업이 느려지게 된다는 뜻은 아니라는 점에 유의하시는 것이 중요합니다. warm 노드는 리소스를 많이 소모하는 색인 작업을 하지 않기 때문에, SSD 기반의 저장 공간을 사용하지 않고도 짧은 시간에 더 오래된 데이터에 대한 쿼리 작업을 효율적으로 처리할 수 있는 경우가 많습니다.
이 아키텍처의 데이터 노드들은 각 역할이 특화되어 있고 큰 부하 상태에 있을 수 있기 때문에, 전용 마스터, 수집, 머신 러닝 및 코디네이트 전용 노드를 사용할 것을 권장합니다.
어느 아키텍처를 선택해야 할까?
대부분의 경우 어떤 아키텍처든 잘 작동하기 때문에, 어느 쪽을 선택해야 할지 확실치 않을 때가 있습니다. 그러나 특정 조건과 제약 사항에 따라 한 쪽 아키텍처가 다른 쪽보다 좀 더 적합할 수 있습니다.
클러스터에 이용할 수 있는 저장 공간 유형은 중요한 고려사항 입니다. hot/warm 아키텍처에서 hot 노드는 속도가 빠른 디스크가 필요하기 때문에, 클러스터가 속도가 느린 디스크만 사용할 수 있도록 제한되어 있는 경우 이 아키텍처는 적합하지 않습니다. 이 경우에는 균일 아키텍처를 사용하고 가능한 한 많은 노드에 걸쳐 색인 및 쿼리 작업을 분배하는 것이 더 낫습니다.
SSD의 사용이 점점 더 보편화되고 있긴 하지만, 균일 클러스터는 블록 저장소로 장착된 로컬 회전 디스크나 SAN이 지원하는 경우가 많습니다. 속도가 느린 저장 공간은 아주 빠른 속도의 색인이 불가능할 수 있습니다. 특히, 쿼리 작업이 동시에 실행되고 있는 경우에는 더 그렇습니다. 따라서 이용 가능한 디스크 공간을 가득 채우는 데 시간이 오래 걸릴 수 있습니다. 그러므로 노드당 대량의 데이터 볼륨을 유지하는 것은 필요에 따른 긴 보존 기간을 갖는 경우에만 사용해야 합니다.
사용 사례가 예를 들어, 10일 미만 등 아주 짧은 보존 기간을 규정하는 경우, 데이터가 일단 색인되면 디스크에서 그리 오랫동안 유휴 상태로 남아있지 않게 됩니다. 이에 따라 성능 기준에 맞는 저장 공간이 필요합니다. hot/warm 아키텍처가 잘 작동할 수도 있지만, hot 데이터 노드만 갖춘 균일 클러스터가 관리가 더 편하고 좋을 수 있습니다.
얼만큼의 저장 공간이 필요할까?
로깅 및/또는 메트릭 사용 사례를 위한 클러스터의 규모를 조정할 때 주된 영향 요소 중 하나는 저장 공간의 양입니다. 원시 데이터의 볼륨과 Elasticsearch에서 색인 및 복제가 끝난 후 디스크에서 얼만큼의 공간을 차지하게 될지 간의 비율은 데이터의 유형과 이것이 색인되는 방법에 따라 많이 달라집니다. 데이터가 색인되는 동안 거치게 되는 여러 단계가 아래 다이어그램에 나와 있습니다.
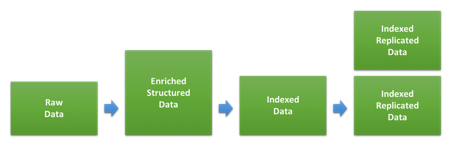
첫 번째 단계는 원시 데이터를 Elasticsearch로 색인할 JSON 문서로 변환하는 것과 관련됩니다. 이것이 데이터의 크기를 얼마나 바꾸게 되느냐는 원래 형식과 추가되는 구조에 따라 다르지만, 다양한 유형의 보강을 통해 추가되는 데이터의 양에 따라서도 달라집니다. 이것은 다른 유형의 데이터마다 상당히 다를 수 있습니다. 로그가 이미 JSON 형식이고 추가 데이터를 더하지 않는 경우, 크기는 전혀 달라지지 않을 수도 있습니다. 반면에 웹 액세스 로그 기반의 텍스트를 가지고 있는 경우, 사용자 에이전트 및 위치정보에 대해 추가되는 내용은 상당히 클 수도 있습니다.
일단 이 데이터를 Elasticsearch로 색인하고 나면, 사용된 인덱스 설정과 매핑에 따라 디스크에서 얼만큼의 공간을 차지하는지가 결정됩니다. Elasticsearch가 적용하는 기본 동적 매핑은 일반적으로 디스크에서 최적화된 저장 공간 크기보다는 유연성을 가지도록 설계되어 있습니다. 따라서 사용자 정의 인덱스 템플릿을 통해 사용하는 매핑을 최적화 함으로써 디스크 공간을 절약할 수 있습니다. 이에 대한 자세한 지침은 튜닝 설명서에서 보실 수 있습니다.
특정 유형의 데이터가 클러스터에서 얼만큼의 디스크 공간을 차지할 것인지 계산하려면, 프로덕션에서 사용할 가능성이 높은 샤드의 크기에 도달할 것인지 확인하기에 충분히 큰 데이터를 색인해 보세요. 너무 작은 데이터 볼륨을 테스트하는 것은 꽤 흔한 실수로 부정확한 결과를 얻을 수 있습니다.
색인과 쿼리 작업의 균형을 어떻게 맞출까?
대부분의 사용자들이 클러스터 크기를 조정할 때 실행하는 첫 번째 벤치마크는 클러스터의 최대 색인 처리량을 알아보기 위한 것일 경우가 많습니다. 이것은 사실 설정과 실행이 꽤 쉬운 벤치마크이며, 그 결과 또한 데이터가 디스크에서 얼만큼의 공간을 차지할 것인지 알아보는 데 사용될 수 있습니다.
일단 클러스터와 수집 프로세스가 튜닝되고 지속할 수 있는 최대 색인 속도를 파악했으면, 최대 처리량으로 계속 색인을 하는 경우 데이터 노드에서 디스크를 모두 채우는 데에 시간이 얼마나 걸릴 것인지를 계산할 수 있습니다. 이것은 이용 가능한 디스크 공간 사용을 최대화하고자 한다는 가정 하에 해당 노드 유형에 대해 최소 보존 기간이 어느 정도인지를 알려주게 됩니다.
필요한 크기를 알아내기 위해 파악한 수치 대로 적용하고 싶어지겠지만, 모든 시스템 리소스가 색인에 사용될 것이기 때문에 쿼리 작업을 위한 여유분이 남지 않게 됩니다. 대부분의 사용자들은 어느 시점에는 데이터들에 대한 쿼리 작업을 할 수 있고, 그 작업이 좋은 성능으로 수행 되기를 기대하며 Elasticsearch에 데이터를 저장하고 있습니다.
그렇다면 쿼리 작업을 위해 남겨두어야 하는 여유 공간은 어느 정도일까요? 이것은 예상되는 쿼리 작업의 양과 성격 및 사용자가 기대하는 대기 시간이 어느 정도인지에 따라 많이 달라지기 때문에 일반적인 답변을 하기에는 어려운 질문입니다. 이것을 알아내는 가장 좋은 방법은 다른 데이터 볼륨과 색인 속도를 이용해 현실적인 수준의 쿼리 작업을 시뮬레이션하는 벤치마크를 실행하는 것입니다. 이에 대한 내용은 이 정량 클러스터 크기 조정에 대한 Elastic{ON} 대담과 Rally를 사용한 클러스터 벤치마킹 및 크기 조정에 대한 웨비나에서 설명하고 있습니다.
일단 괜찮은 성능으로 사용자들에게 쿼리 작업을 제공하면서 동시에 지속할 수 있는 최대 색인 처리량 부분의 크기가 얼마나 되는지를 알아내고 나면, 이 감소된 색인 속도에 매칭되는 예상 보존 기간을 조정할 수 있습니다. 더 느린 페이스로 색인을 하는 경우, 디스크를 모두 채우는 데 시간이 더 오래 걸리게 됩니다.
이 조정은 트래픽에서 작은 피크들을 처리할 수 있도록 해줄 수도 있지만, 일반적으로 시간이 지남에 따라 꽤 꾸준한 색인 속도를 가정합니다. 피크가 있고 하루 종일 변동되는 트래픽 수준을 예상하는 경우, 조정된 색인 속도가 피크 수준에 상응하는 것으로 가정하고 각 노드가 처리할 수 있으리라 생각되는 평균 색인 속도를 훨씬 더 줄여야 할 수도 있습니다. 변동이 예측 가능하고, 예를 들어, 업무 시간 동안이라던가 하는 등 오랫동안 지속되는 경우, 또다른 옵션은 해당 기간 동안 hot 영역의 크기를 증가시키는 것이 될 수 있습니다.
이 모든 저장 공간을 어떻게 사용할까?
hot-warm 아키텍처에서, warm 노드는 대량의 데이터를 보존할 수 있을 것으로 기대됩니다. warm 노드는 또한 오랜 보존 기간을 갖는 균일 아키텍처에서 데이터 노드에 적용됩니다.
정확히 얼만큼의 데이터가 노드에서 성공적으로 보존될 수 있는지는 대개 힙 사용량을 얼마나 잘 관리할 수 있느냐에 달려 있습니다. 힙 사용량은 밀도가 높은 노드들에 있어 주된 제한 요인이 되는 경우가 많습니다. 색인, 쿼리 작업, 캐싱, 클러스터 상태, 필드 데이터, 샤드 여유 공간 등 수많은 영역들이 Elasticsearch 클러스터에서 힙 사용량에 영향을 미치기 때문에, 결과는 사용 사례 마다 달라지게 됩니다. 해당 사용 사례에 대해 제한이 어느 정도인지 정확하게 알아내는 가장 좋은 방법은 현실적인 데이터 및 쿼리 패턴을 기반으로 벤치마크를 실행하는 것입니다. 그러나 로깅 및 메트릭에 대한 일반적인 모범 사례가 많이 있으며, 이것은 데이터 노드를 가능한 한 최대로 활용할 수 있도록 도와줍니다.
매핑의 최적화
앞서 얘기한 것처럼, 데이터에 사용되는 매핑은 그것이 디스크에서 압축되는 정도에 영향을 미칠 수 있습니다. 또한 얼만큼의 필드 데이터를 사용하고 힙 사용량에 영향을 미칠 것인지에도 영향을 줄 수 있습니다. Filebeat 모듈이나 Logstash 모듈을 사용해 데이터 구문을 분석하거나 데이터를 수집하는 경우, 최적화된 매핑을 바로 사용할 수 있고, 이 점에 대해서는 그리 걱정할 필요가 없을 수도 있습니다. 그러나 사용자 정의 로그 구문 분석을 하고 새 필드에 동적으로 매핑하는 Elasticsearch 기능을 광범위하게 사용하는 경우, 반드시 계속 읽어보시기 바랍니다.
Elasticsearch가 동적으로 문자열을 매핑할 때, 기본 동작은 멀티 필드를 사용하여 대소문자를 구분하지 않는 풀텍스트 검색에 사용될 수 있는 text와 Kibana에서 데이터를 집계할 때 사용되는 keyword, 이 양쪽 모두로 데이터를 매핑하는 것입니다. 이것은 최적화된 유연성을 제공하기 때문에 상당히 유용한 기본값이지만, 불리한 점은 디스크의 인덱스 크기와 사용되는 필드 데이터의 양을 증가시킨다는 것입니다. 따라서 가능할 때마다 살펴보고 매핑을 최적화하는 것을 권장합니다. 그렇게 하면 데이터 볼륨이 증가함에 따라 상당한 차이가 생길 수 있습니다.
샤드 크기를 가능한 한 크게 유지
Elasticsearch에서 각 인덱스는 하나 이상의 샤드를 포함하고 있으며, 각 샤드에는 약간의 힙 공간을 사용하는 오버헤드가 있습니다. 이 샤드에 대한 블로그 포스팅에서 설명하고 있는 것처럼, 크기가 작은 샤드는 크기가 큰 샤드에 비해 데이터 볼륨당 오버헤드가 더 많이 생깁니다. 대량의 데이터를 보존하기 위한 노드에서 힙 사용량을 최소화하려면 샤드 크기를 가능한 한 크게 유지하는 것이 중요합니다. 경험상으로 보면 장기간 보존을 위한 평균 샤드 크기를 20GB에서 50GB 사이로 유지하는 것이 좋습니다.
각 쿼리나 집계가 샤드당 단일 스레드로 실행되기 때문에, 최소 쿼리 지연 시간은 통상적으로 샤드 크기에 달려 있습니다. 이것은 데이터와 쿼리에 따라 달라지며, 동일한 사용 사례 내의 인덱스들 사이에서조차 다를 수 있습니다. 그러나 특정 데이터 볼륨과 데이터 유형의 경우, 크기가 작은 샤드가 다수 있는 것이 크기가 큰 샤드가 하나 있는 것보다 성능이 더 좋다고 확신할 수는 없습니다.
쿼리 사용과 최소 여유 공간에 대해 최적화에 이르려면 샤드 크기의 효과를 테스트하는 것이 중요합니다.
저장 공간 볼륨 튜닝
JSON 소스를 효율적으로 압축하는 것은 디스크에서 데이터가 얼만큼의 공간을 차지할 것인지에 상당한 영향을 미칠 수 있습니다. Elasticsearch는 기본적으로 저장 공간과 색인 속도 사이의 균형을 위해 튜닝된 압축 알고리즘을 이용하여 이 데이터를 압축하지만 또한 옵션으로 보다 적극적인 압축을 제공합니다. 바로 best_compression 코덱입니다.
이것은 모든 새로운 인덱스에 대해 지정될 수 있지만 색인 동안 약 5-10%의 성능 저하가 있습니다. 하지만 디스크 공간 확보가 상당할 수 있으므로 그만한 가치가 충분합니다.
앞 섹션의 조언에 따라 인덱스들을 병합(force merge)하고 있는 경우, 병합 작업을 하기 직전에 개선된 압축을 적용하는 옵션도 있습니다.
불필요한 부하 피하기
여기서 다루려고 하는 힙 사용량에 영향을 미치는 마지막 요소는 요청 처리입니다. Elasticsearch로 보내지는 모든 요청은 도착하는 노드에서 조정됩니다. 그리고 나서 작업이 분할되고 데이터가 있는 곳까지 분산됩니다. 이것은 쿼리는 물론 색인에도 적용됩니다.
요청 및 응답의 구문 분석과 코디네이션은 결과적으로 상당한 힙 사용량을 발생시킬 수 있습니다. 코디네이트 작업을 하는 노드나 색인을 하는 노드가 이것을 처리하기에 충분한 힙 여유 공간을 갖도록 해야 합니다.
장기간 데이터 보존을 위해 튜닝된 노드의 경우, 전용 데이터 노드로 작업하도록 하고 수행해야 하는 추가 작업을 최소화하는 것이 합리적일 때가 많습니다. 모든 쿼리를 hot 노드나 코디네이트 전용 노드로 보내면 이것을 수행하는 데 도움이 될 수 있습니다.
Elasticsearch Service 배포에 이것을 어떻게 적용할까?
Elasticsearch Service는 현재 AWS와 GCP에서 제공되고 있으며, 동일한 인스턴스 구성과 배포 템플릿이 양쪽 플랫폼에서 모두 제공되고 있긴 하지만, 사양은 조금 다릅니다. 이 섹션에서는 다른 인스턴스 구성들과 우리가 앞서 얘기한 아키텍처에 이 구성들이 얼마나 잘 부합되는지를 살펴보겠습니다. 또한 예제 사용 사례를 지원하는 데 필요한 클러스터 크기 계산을 어떻게 시작할 수 있는지에 대해서도 살펴보려고 합니다.
사용 가능한 인스턴스 구성
Elasticsearch Service에서 일반적으로 Elasticsearch 노드는 속도가 빠른 SSD 저장 공간을 기반으로 합니다. 이것을 highio 노드라고 하며, I/O 성능이 탁월합니다. 따라서 이 노드는 hot-warm 아키텍처에서 hot 노드로 대단히 적합하지만, 또한 균일 아키텍처에서 데이터 노드로도 사용될 수 있습니다. 성능 기준에 맞는 저장 공간이 필요한 짧은 보존 기간을 갖는 경우 많이 권장되기도 합니다.
AWS와 GCP에서 highio 노드는 디스크 대 RAM 비율이 30:1이며, 따라서 RAM 1GB마다 30GB의 저장 공간을 사용할 수 있습니다. GCP의 노드는 1GB, 2GB, 4GB, 8GB, 16GB, 32GB, 64GB의 크기로 제공되는 반면, AWS에서 사용 가능한 노드 크기는 1GB, 2GB, 4GB, 8GB, 15GB, 29GB, 58GB입니다.
최근에 Elastic Cloud에 도입된 또 다른 노드 유형은 저장 공간에 최적화된 highstorage 노드입니다. 여기에는 속도가 느린 대용량 저장 공간이 장착되며 디스크 대 RAM 비율은 100:1입니다. GCP의 64GB highstorage 노드는 6.2TB 이상의 저장 공간이 제공되지만, AWS의 58GB 노드는 5.6TB를 지원합니다. 이 노드는 각각의 플랫폼에서 highio 노드와 동일한 RAM 크기를 갖습니다.
이 노드는 통상적으로 hot/warm 아키텍처에서 warm 노드로 사용됩니다. highstorage 노드의 벤치마크는 크기의 차이를 고려하더라도 GCP에서 이 유형의 노드가 AWS에 비해 상당한 성능상의 이점이 있음을 보여줍니다.
두세 개의 가용 영역 사용
대부분의 리전에서는 두세 개의 가용 영역에서 실행하도록 선택하는 옵션이 있으며, 클러스터에서 영역당 다른 영역 개수를 선택할 수 있습니다. 고정된 개수의 가용 영역 내에서 유지할 때는, 최소한 크기가 작은 클러스터의 경우, 가용 클러스터 크기가 대략 두 배 증가합니다. 두세 개의 가용 영역을 사용하는 데 개방되어 있는 경우, 동일한 노드를 갖는 두세 개의 가용 영역에서 진행하면 용량이 50%만 증가하기 때문에 좀 더 소규모 단계로 크기를 조정할 수 있습니다.
크기 조정 사례: Hot-warm 아키텍처
이 예에서는, 보존 기간이 30일인 일별 원시 웹 액세스 로그 100GB 수집을 처리할 수 있는 hot-warm 클러스터 크기 조정을 살펴보겠습니다. AWS와 GCP의 Elastic Cloud에서 이것을 배포하는 것을 비교해보려고 합니다.
여기서 사용되는 데이터는 예일 뿐임에 유의해 주세요. 실제 사용 사례에서는 다를 가능성이 아주 높습니다.
1단계: 총 데이터 볼륨 계산
이 예에서는, 데이터가 Filebeat 모듈을 사용해 수집되며 따라서 매핑이 최적화되어 있다고 가정하고 있습니다. 이 예에서는 단순하게 하기 위해 단일한 유형의 데이터만 다뤄보겠습니다. 색인 벤치마크 동안, 디스크에서 원시 데이터의 크기와 색인된 크기 간의 비율이 약 1.1임을 보았습니다. 따라서 100GB의 원시 데이터는 디스크에서 110GB의 색인된 데이터가 될 것으로 계산됩니다. 복제본이 추가되면 220GB로 두 배가 됩니다.
30일이 지나면, 클러스터가 전체적으로 처리해야 하는 색인되고 복제된 총 데이터 볼륨은 6600GB가 됩니다.
이 예는 1개의 복제본 샤드가 모든 영역에 걸쳐 사용되는 것으로 가정하고 있습니다. 이것이 성능과 가용성 면에서 모범 사례로 간주되기 때문입니다.
2단계: hot 노드 크기
이 데이터 세트를 사용해 hot 노드에 대한 최대 색인 벤치마크를 일부 실행하였고, AWS와 GCP에서 highio 노드의 디스크를 가득 채우는 데 약 3.5일이 걸리는 것을 보았습니다.
쿼리 작업과 트래픽의 작은 피크들을 위한 약간의 여유 공간을 남겨 두기 위해, 최대 수준의 50% 정도로만 색인을 지속할 수 있을 것으로 가정하겠습니다. 이 노드에서 사용 가능한 저장 공간을 최대한 활용할 수 있으려면, 더 장기간 동안 노드로 색인을 해야 하고, 따라서 이를 반영하여 이 노드에서 보존 기간을 조정합니다.
Elasticsearch는 또한 효율적으로 작업하기 위해 약간의 예비 디스크 공간이 필요합니다. 따라서 디스크 워터마크를 초과하지 않도록 하기 위해, 15%의 별도 디스크 공간이 필요하다고 가정하겠습니다. 아래 열에 필요한 디스크 공간이 나와 있습니다. 이것을 기준으로, 공급자별로 필요한 RAM의 총량을 알아볼 수 있습니다.
| 플랫폼 | 디스크:RAM 비율 | 모두 채우는 데 드는 일수 | 유효 보존(일수) | 보존 데이터 볼륨(GB) | 필요 디스크 공간(GB) | 필요 RAM(GB) | 영역 사양 |
| AWS | 30:1 | 3.5 | 7 | 1440 | 1656 | 56 | 29GB, 2AZ |
| GCP | 30:1 | 3.5 | 7 | 1440 | 1656 | 56 | 32GB, 2AZ |
3단계: warm 노드 크기
hot 노드에서 보존 기간을 초과하는 데이터는 warm 노드로 이전됩니다. 높은 워터마크를 위한 여유 공간을 고려하여, 이 노드가 보존해야 하는 데이터 양을 계산하여 필요한 크기를 추정할 수 있습니다.
| 플랫폼 | 디스크:RAM 비율 | 유효 보존(일수) | 보존 데이터 볼륨(GB) | 필요 디스크 공간(GB) | 필요 RAM(GB) | 영역 사양 |
| AWS | 100:1 | 23 | 5060 | 5819 | 58 | 29GB, 2AZ |
| GCP | 100:1 | 23 | 5060 | 5819 | 58 | 32GB, 2AZ |
4단계: 추가 노드 유형 더하기
데이터 노드에 더하여, 클러스터의 복원성과 가용성이 향상되도록 하려면 일반적으로 3개의 전용 마스터 노드가 필요합니다. 이것은 트래픽을 처리하지 않기 때문에 크기가 꽤 작을 수 있습니다. 처음에 가용 영역 3개에 걸쳐 1GB~2GB 노드를 할당하면 시작하기에 좋은 크기입니다. 그리고 나서 관리형 클러스터 크기가 증가함에 따라 가용 영역 3개에 걸쳐 약 16GB까지 이 노드의 크기를 조정합니다.
이제 그 다음은?
아직 시작하지 않으셨다면, Elasticsearch Service 14일 무료 체험판 사용을 시작해 보세요! 설정과 관리가 얼마나 쉬운지 직접 확인하세요. Elastic Cloud Elasticsearch Service 크기 조정 방법에 대해 질문이 있거나 추가 도움말이 필요하시면, 저희에게 직접 연락하시거나 공개된 포럼 게시판에 참여해 주세요.