その空気はキレイですか?:Elastic CloudのElasticsearchで空気質データを分析
Elastic Stackが得意とする処理の1つが、データを収集・インデックスし、インサイト情報を引き出すことです。複数回の連載にわたり、Elastic Stackを活用した統合情報管理の機能性と、その面白さについてもお伝えします。本記事では、有意義な生のデータから大都市居住者の健康管理に役立つ判断を導く方法について、詳細に説明します。
いま世界中の大都市で、人口増加によるさまざまな課題が生じています。中でも特に都市生活者の健康に影響をもたらすのが大気汚染の問題です。一部の公的機関では警報を通知し、市民が自ら緊急措置を講じることができるような取り組みを行っています。市内にさまざまな汚染物質濃度の情報を収集するをセンサーを配置するというものです。
こうした測定は公的機関の管理下で行われており、そのデータが公開されることも多くあります。今回はサンプルケースとして、ヨーロッパでも有数の人口(300万人超)を抱える都市マドリッドのデータを使用します。
Elasticsearchを使えば簡単に、汚染データからマドリッド市民の日常を垣間見ることもできます。
CSVファイルからElasticsearchドキュメントを作成する
はじめにデータソースを確認しましょう。マドリッド市役所の 公開データポータルに1時間ごとの空気質測定データセット(スペイン語)があります。
ここでCSVファイルを提供するHTTPエンドポイントは毎時間更新されており、当日最長1時間前までの測定データ(毎時)を含んでいます。
ファイルの各行は(場所、汚染物質)というキーペアで、1時間おき、1日分の測定結果を記載しています。1行に、次のように毎時の値が入っています。
| ... | ステーション | 汚染物質 | ... | 月 | 日 | AM0時 測定値 | AM0時 有効か? | ... | PM11時 測定値 | PM11時 有効か? |
| 数値(コード) | コード(コード) | 数値 | 数値 | 数値 | 'V' / 'F'(真/偽) | 数値 | 'V' / 'F'(真/偽) |
「ステーション」や「汚染物質」列には、それぞれ地理的位置情報と化合物に関連付けられた数値が入ります。詳しい情報は、データ元のサイトで表形式で提供されています。
これに対し、毎時の測定データ(AM/PM i時 測定値)と有効なデータであるかを示すフラグ(AM/PM i時 有効か?)行にはraw値が入ります。単位はソースにある別の表に示されています。またバリデーションフラグの'V' / 'F'はスペイン語の“Verdadero”と“Falso”の略で、それぞれ“True / 真”と“False / 偽”を意味します。
化学物質のサンプリング結果は時間と空間の測定結果として表示されます。おわかりでしょうか。つまり、空間イベントの時系列となります。行はイベントではありません。そうではなく、各行に最大24のイベントが収集され、そのすべてが同じ場所と化合物の結果です。
各イベントをJSONドキュメントとしてエンコードした場合、下のようになります。
{
"timestamp":1532815200000,
"location": {
"lat":40.4230897,
"lon": -3.7160478
},
"measurement": {
"value":7,
"chemical":"SO2",
"unit": "μg/m^3"
}
}
オプションとして、測定結果のサブドキュメント内に追加のフィールドを加えることにより、世界保健機関(WHO)が定める制限を使って簡単にエンリッチすることもできます。CSVの各行を別のJSONドキュメントとして個別化することで理解しやすくなり、Elasticsearchへの投入も容易になります。
{
"timestamp":1532815200000,
"location": {
"lat":40.4230897,
"lon": -3.7160478
},
"measurement": {
"value":7,
"chemical":"SO2",
"unit": "μg/m^3",
"who_limit":20
}
}
これらのドキュメントの構造はは、別のJSONドキュメントを使って記述することができます。これがElasticsearchのマッピングです。マッピングを使い、任意のインデックスでドキュメントを格納する方法を記述します。
{
"air_measurements": {
"properties": {
"timestamp": {
"type": "date"
},
"location": {
"type": "geo_point"
},
"measurement": {
"properties": {
"value": {
"type": "double"
},
"who_limit": {
"type": "double"
},
"chemical": {
"type": "keyword"
},
"unit": {
"type": "keyword"
}
}
}
}
}
}
Elastic Cloudに数秒でクラスターをデプロイする
このステップは、ローカルにElasticsearchクラスターを設定しても、14日間の無料トライアルを利用してElastic CloudのElasticsearch Serviceを使用しても実行できます。数クリックで新しいクラスターをはじめる方法(英語)をご覧ください。この記事では、Elastic Cloudを使用します。
はじめにElastic Cloudにログインし、新しいクラスターをデプロイします。今回のユースケースのクラスターサイズは、どのように選べばよいでしょうか。JSONでエンコードした1か月分の測定イベントファイルはディスク容量(インデックス前)で約34MBです。したがって、最少のクラスターとなる1 GB RAM / 24 GBディスク容量を使用します。最少クラスターでこのデータを十分ホストすることができます。Elastic Cloudは簡単にスケールすることができる設計となっています。後からサイズや、アベイラビリティゾーン数を増やしたり、クラスターに変更を加えることもできます。
冷凍食品を温め終わるよりも早く、Elasticsearchクラスターを設定して測定イベントデータをインデックスすることができます。
抽出、変換、ロード
元のCSVファイルから、測定結果をコーディングした一連のJSONドキュメントに変換する作業を手動でやりたい、という人は多くありません。平たく言えば、これは少々辛い作業です。では、自動化するにはどうすればよいでしょうか。
まずCSVテーブルをフラット化してJSONドキュメントにする自動化スクリプトを考えてみましょう。Scalaを使います。
- プログラムフローよりもデータフローを中心に置く言語であるScalaは、ドキュメントの集合を簡単に変換することができます。
- 多数のJSON操作ライブラリがあります。
- Ammoniteを活用して、データ操作スクリプトを簡単に記述することができます。
以下は、変換ロジックを要約したextractor.scスクリプトの一部です。
//マドリッド市役所の公開データポータルからファイルを取得します
lazy val sourceLines = scala.io.Source.fromURL(uri).getLines().toList
sourceLines.headOption foreach { head =>
/* CSVの1行目には列のラベルがあり、ラベルから
マップを計算することができます。これで残りのコードをより
見やすくできます。 */
lazy val label2pos = head.split(";").zipWithIndex.toMap
// 各行に対して、flatMapを使用して簡単に複数のイベントを生成します。
lazy val entries = sourceLines.tail flatMap { rawEntry =>
val positionalEntry = rawEntry.split(";").toVector
val entry = label2pos.mapValues(positionalEntry)
/* 最初の8ポジションは24時間の測定に共通する情報を
抽出するために使われています。 */
val stationId = entry("ESTACION").toInt
val ChemicalEntry(chemical, unit, limit) = chemsTable(entry("MAGNITUD").toInt)
//測定値は末尾の24列に含まれています。
positionalEntry.drop(8).toList.grouped(2).zipWithIndex collect {
case (List(value, "V"), hour) =>
val timestamp = new DateTime(
entry("ANO").toInt,
entry("MES").toInt,
entry("DIA").toInt,
hour, 0, 0
)
//これで完了です。ケースクラスとして生成されたイベントです。
Entry(
timestamp,
location = locations(stationId),
measurement = Measurement(value.toDouble, chemical, unit, limit)
)
}
}
- 毎時公開されるレポートの最新データを取得します。最長1時間前の測定結果が含まれます。
- 各行に対し、
- 行で生成されたすべてのイベントに共通するフィールド、つまりステーションIDと測定された化学物質を抽出します。
- その日これまでに実施された測定結果と一致するものを抽出します。測定が"有効"とされていない結果を除外します。
- 上述の各データに対し、行の日付と測定列番号を組み合わせ、測定タイムスタンプを生成します。行の共通フィールド、タイムスタンプと記録された値を結合し、1つのイベントオブジェクト(エントリ)にします。
スクリプトはEntryオブジェクトをJSONドキュメントとしてシリアル化し、個別のJSONの連なりとしてプリントし続けます。
Extractor.scは引数を受け取り、ローカルファイルなどの他のソースからデータを取得して変換したり、1日分のファイルをアップロードする際にElasticsearchのBulk APIに必要なアクションを追加することもできます。
extractor --uri String (default http://www.mambiente.munimadrid.es/opendata/horario.csv) --bulkIndex --bulkType
Elasticsearchにデータをアップロードする
これで、CSVファイルをドキュメントリストに変換するスクリプトを作成することができました。このドキュメントを、どのようにインデックスすればよいでしょうか?それほど難しくはありません。クラスターに何度かリクエストだけです。
インデックスを作成する
はじめにインデックスを作成する必要があります。先ほどドキュメントのマッピングのJSONを記述しました。次のような形で、インデックスの定義内にこのJSONをネストさせることができます:./payloads/index_creation.json
{
"settings" : {
"number_of_shards" :1
},
"mappings" : {
"air_measurements" : {
"properties" : {
"timestamp": { "type": "date" },
"location" : { "type" : "geo_point" },
"measurement": {
"properties": {
"value": { "type": "double" },
"who_limit": { "type": "double" },
"chemical": { "type": "keyword" },
"unit": { "type": "keyword" }
}
}
}
}
}
}
次にこれを、クラスターのインデックス作成エンドポイントにリクエストします。
curl -u "$ESUSER:$ESPASS" -X PUT -H 'Content-type: application/json' \
"$ESHOST/airquality" \
-d "@./payloads/index_creation.json"
これでairqualityインデックスを作成することができます。
バルクアップロード
これらすべてのデータをElasticsearchに最も速くロードする方法は、Bulk APIを使うものです。考え方としては、接続を確立し、ドキュメントのパッケージをアップロードして操作を完了する、ということになります。 1度に1ドキュメントずつアップロードする場合、各測定結果CSVの各行ごとに、TCP接続を確立してドキュメントを送信し、確認を受信して接続を閉じる、というプロセスが必要になり、効率的ではありません。
Bulk APIのリファレンスに記載されているように、1ドキュメントにつき2行で構成されるNDJSONファイルをアップロードする必要があります。
- 1行目はElasticsearchで実行するアクションです。
- 2行目はそのアクションの対象となるドキュメントのラインです。ここではindex(登録)がそのアクションです。
したがってextractor.scから各ドキュメントの直前にインデックスアクションとアピアランスを制御する2つの追加オプションを得ることができます。
- bulkIndex INDEX:渡されると、インデックスからINDEXにするアクションで各ドキュメントに先行する抽出スクリプトを作成します。
- bulkType TYPE:bulkIndex後に渡されると、ドキュメントにマッチするtypeを使用してインデックスアクションを完了します。
/* イベントの集合はこの後シリアル化され、標準アウトプットでプリントされます。
これにより、それらをndjsonファイルとして使うことができます。
*/
val asJsonStrings = entries flatMap { (entry:Entry) =>
Some(bulkIndex).filter(_.nonEmpty).toList.map { index =>
val entryId = {
import entry._
val id = s"${timestamp}_${location}_${measurement.chemical}"
java.util.Base64.getEncoder.encodeToString(id.getBytes)
}
/* オプションとして、データ転送パフォーマンスの向上のために、バルク
アクションをシリアル化することもできます。 */
BulkIndexAction(
BulkIndexActionInfo(
_index = index,
_id = entryId,
_type = Some(bulkType).filter(_.nonEmpty)
)
).asJson.noSpaces
} :+ entry.asJson.noSpaces
}
asJsonStrings.foreach(println)
このようにして、その日のすべてのエントリを含む巨大なNDJSONファイルを生成することができます。
time ./extractor.sc --bulkIndex airquality --bulkType air_measurements > today_bulk.ndjson
1.46秒で、Bulk APIに送信できるファイルが次のように生成されます。
time curl -u $ESUSER:$ESPASS -X POST -H 'Content-type: application/x-ndjson' \
$ESHOST/_bulk \
--data-binary "@today_bulk.ndjson" | jq '.'
アップロードリクエストは0.98秒で処理されました。
この手法で処理にかかった時間は計2.44秒(データの取得と変換に1.46秒、バルクアップロードリクエストに0.98秒)でした。1度に1つのドキュメントをアップロードした場合に比べて182倍速くなります。もう1度強調しておきましょう。2.44秒と、7分26秒です!
ここが大切なポイントです:大量のドキュメントのインデックスプロセスには、バルクアップロードを使用しましょう!
データからインサイトを得る
さて、都市の大気汚染データをElasticsearchでインデックスする段階が無事に完了しました。つまり、情報をダウンロード、抽出して手動で検索する場合に比べてはるかに簡単にデータを検索・取得できるようになりました。
たとえばこんな状況を考えてみましょう。プラド美術館でお目当ての『ラス・メニーナス』の絵を鑑賞した後、2つの選択肢を考えます。
- 温暖なマドリッドを楽しむため屋外でアクティブに過ごす
- このままプラド美術館でたくさんの作品を堪能する
健康という観点からどちらがより良いか判断するために、Elasticsearchに半径1km以内の最も近い観測ステーションにおけるNO2(二酸化窒素)の状況をたずねることができます:./es/payloads/search_geo_query.json
{
"size":"1",
"sort": [
{
"timestamp": {
"order": "desc"
}
},
{
"_geo_distance": {
"location": {
"lat":40.4142923,
"lon": -3.6912903
},
"order": "asc",
"unit": "km",
"distance_type": "plane"
}
}
],
"query": {
"bool": {
"must": {
"match": {
"measurement.chemical":"NO2"
}
},
"filter": {
"geo_distance": {
"distance":"1km",
"location": {
"lat":40.4142923,
"lon": -3.6912903
}
}
}
}
}
}
curl -H "Content-type: application/json" -X GET -u $ESUSER:$ESPASS $ESHOST/airquality/_search -d "@./es/payloads/search_geo_query.json"
回答は次の通りです。
{
"took":4,
"timed_out": false,
"_shards": {
"total":1,
"successful":1,
"skipped":0,
"failed":0
},
"hits": {
"total":4248,
"max_score": null,
"hits": [
{
"_index": "airquality",
"_type": "air_measurements",
"_id": "okzC5mQBiAHT98-ka_Yh",
"_score": null,
"_source": {
"timestamp":1532872800000,
"location": {
"lat":40.4148374,
"lon": -3.6867532
},
"measurement": {
"value":5,
"chemical":"NO2",
"unit": "μg/m^3",
"who_limit":200
}
},
"sort": [
1532872800000,
0.3888672868035024
]
}
]
}
}
レティーロ公園のステーションで観測されたNO2の値は5 μg/㎥でした。WHO(世界保健機関)の定める上限が200 μg/㎥であることを考えれば、悪くない数値と言えます。それではタパスを食べに行きましょう!
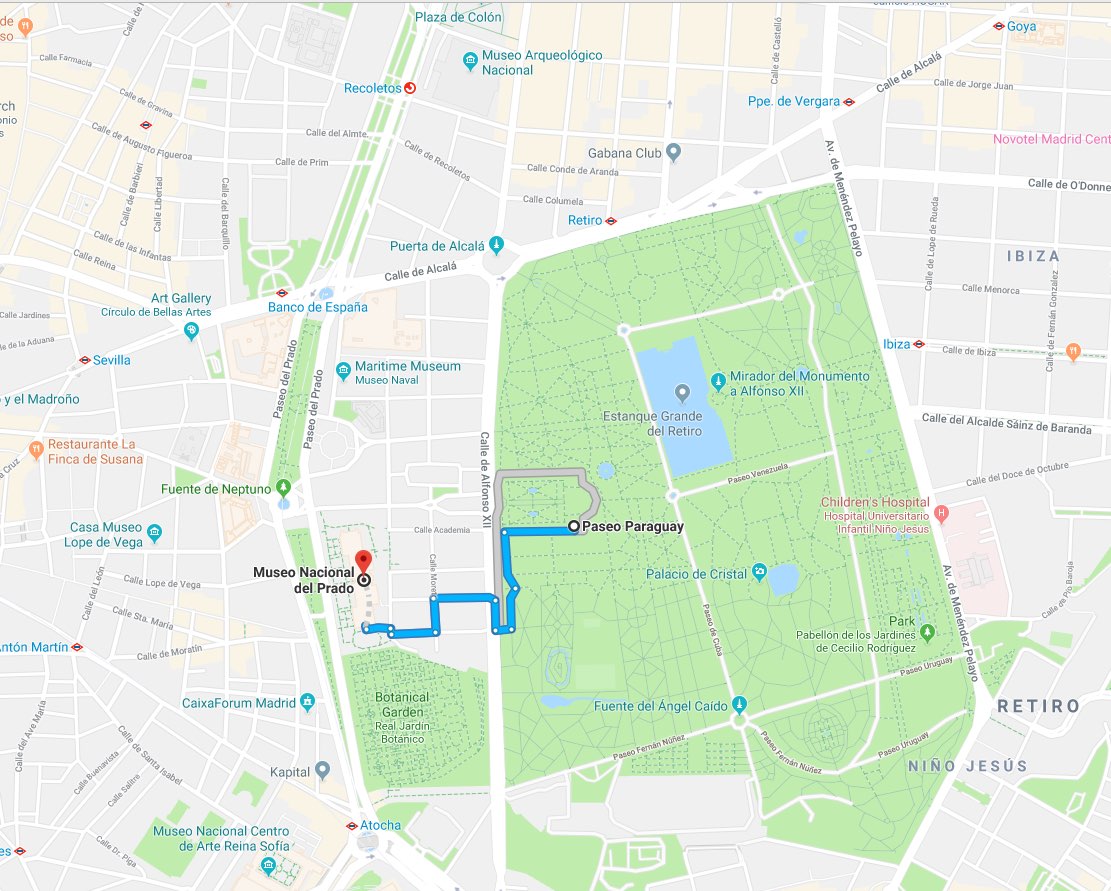
実際のところ、プラド美術館でノートPCを開き、cURLコマンドを記述するというのは少々考えにくいことです。しかし、このようなリクエストはほとんどのプログラミング言語で簡単にコードを書くことができ、わずか数日でフロントエンドアプリケーションを提供することだって可能です。情報インデックスを備えた完全な分析バックエンドが、すでに使える状態になっているからです。
見えないものをKibanaで可視化する
ここで、アプリケーションを作る必要はない、と言ったらどうでしょうか?現在のクラスターを使って、クリックするだけでデータを検索し、インサイトに満ちた情報を入手できるとしたら?間違いなく、とても便利です。これは、Kibanaを使って実現することができます。クラスターを管理しているcloud.elastic.coで、Kibanaをデプロイするリンクをクリックします。
Kibanaでは、Elasticsearchにインデックスしたドキュメントを使用して包括的な可視化とダッシュボードを作成することができます。
Kibanaにインデックスを登録し、データを取り出して可視化できるようにしておくための設定が、インデックスパターンです。つまり、空気質インデックスを可視化するためには最初にこのインデックスを登録する必要があります。
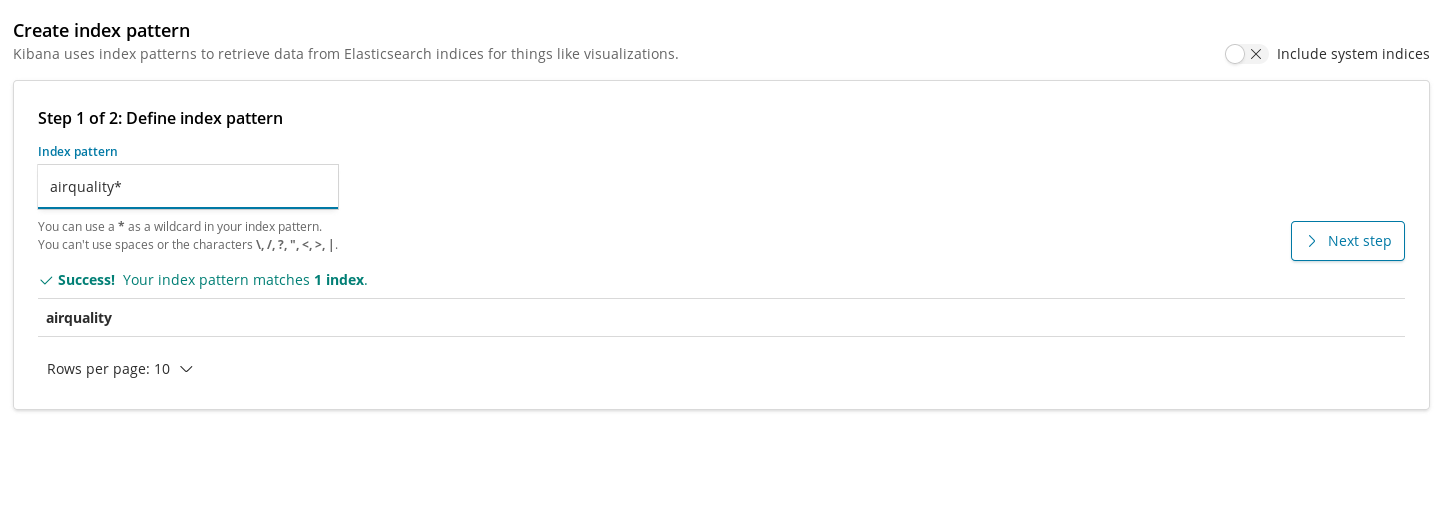
インデックスパターンを作成すると、最初の可視化を追加することができるようになります。まずシンプルなパターンを考えてみましょう。市全体で放出される化学物質の平均濃度を時間経過と共にプロットします。NO2(二酸化窒素)ではどうでしょうか。
はじめに折れ線グラフを作成します。Y軸はフィールドmeasurement.valueの平均アグリゲーション、X軸が1時間ごとのバケットを表示します。Kibanaのクエリバーを使用してNO2の測定結果をフィルターし、ターゲットとする化学物質を選択することができます。さらにautocompleteを有効化して入力候補を表示し、クエリを定義するプロセスをガイドしてもらうことができます。
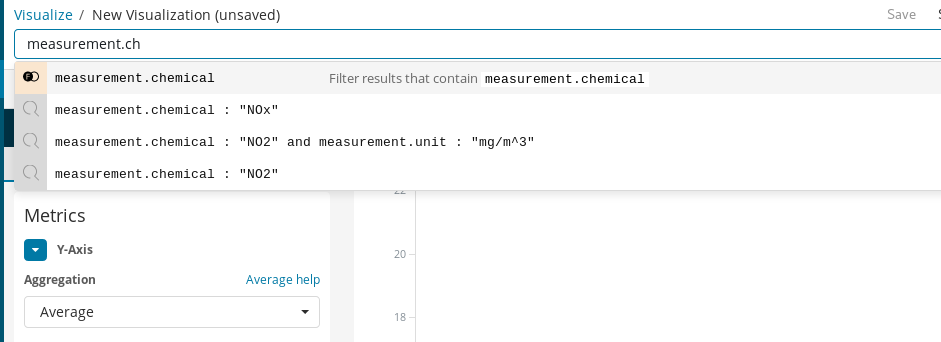
最後に、Time Rangeでデータを可視化するタイムスパンを選択できます。
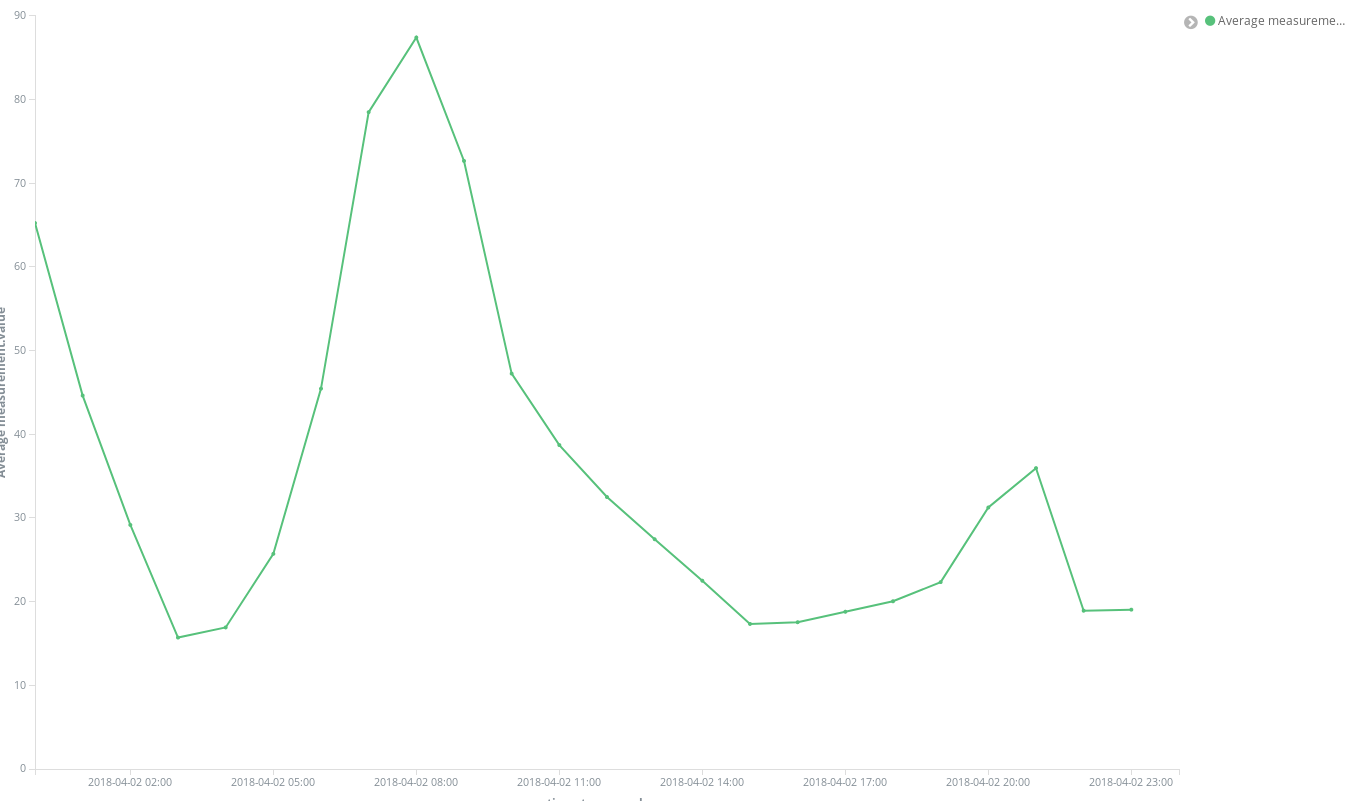
わずか数クリックで結果が表示されました。
このデータセットから表示できる有用なチャートの1つが座標マップ(Coordinate Map)です。各測定結果にはステーションの座標情報を含むことから、汚染のホットスポットマップとして表すことができます。時間バケット内の空間的エントリの平均を見るという発想から、空間的ロケーションの中の平均的な時間エントリを見るという発想に変える、ということになります。したがってこの場合。バケットはロケーションに対するジオハッシュのアグリゲーション、観測地点の情報を含むフィールドとなります。
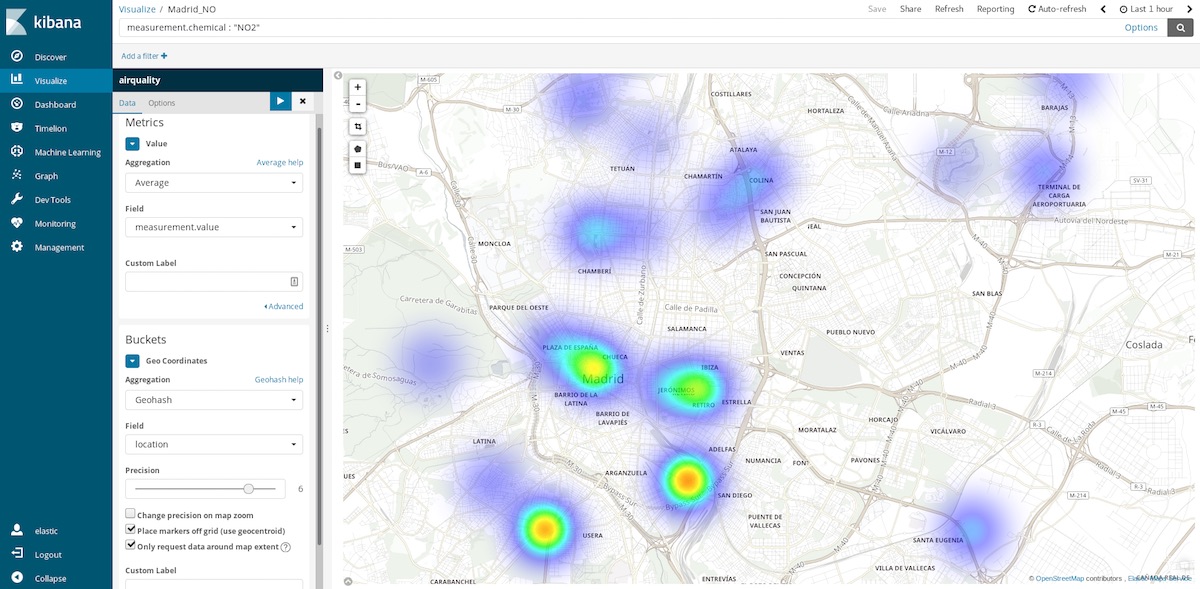
たとえばTime Rangeで1時間前を選択して、いま空気が比較的きれいなエリアに行く計画を立てる、といった使い方をすることもできます。Time Rangeで年間を指定すれば、地域ごとの平均汚染度を見ることができます。家を購入する際、より健康に暮らすならどのエリアにするか判断する手がかりにするといったことも可能です。
スクリプト化されたフィールド
今回のドキュメントは一部の化学物質についてWHOの推奨レベルを参照しており、「大気がどの程度不健康か」を可視化することも可能です。1つの方法は、WHOが定める上限と測定値を使用してゲージ形式で可視化(gauge visualization)するやり方です。データをロードした時点で、そのような割り算は行っていませんでしたが問題はありません。というのも、この段階でもPainlessスクリプト言語を使用し、インデックス済みのドキュメントに新しいフィールドを生成することができるためです。PainlessはJavaを使用したことがある人なら誰でも簡単に理解し、記述することができます(Kibana 6.4以降は、Painlessスクリプトの結果をプレビューすることもできるようになりました)。
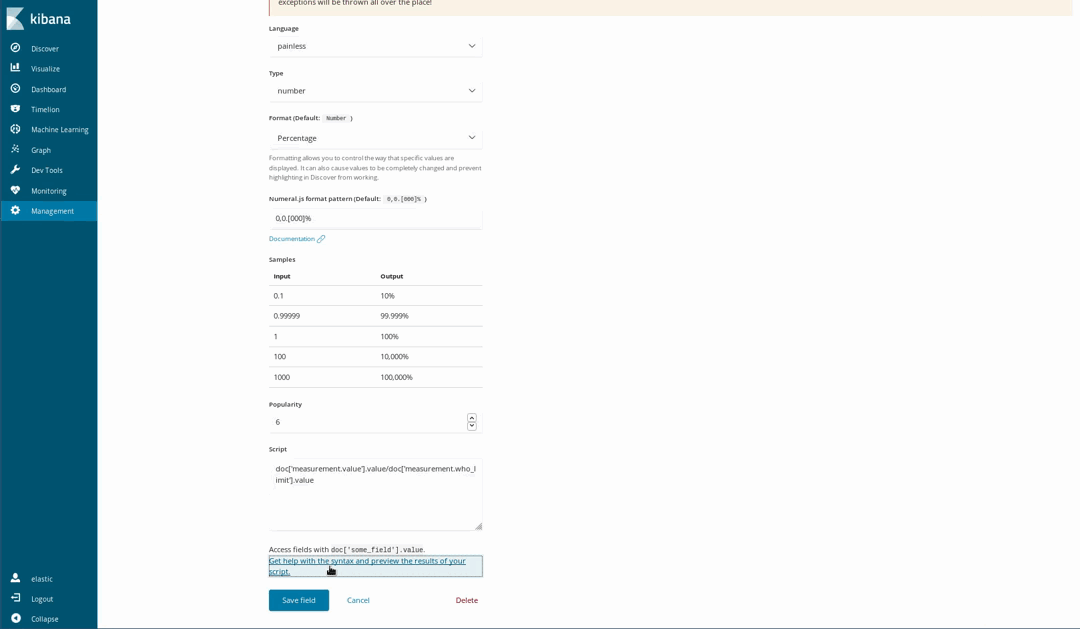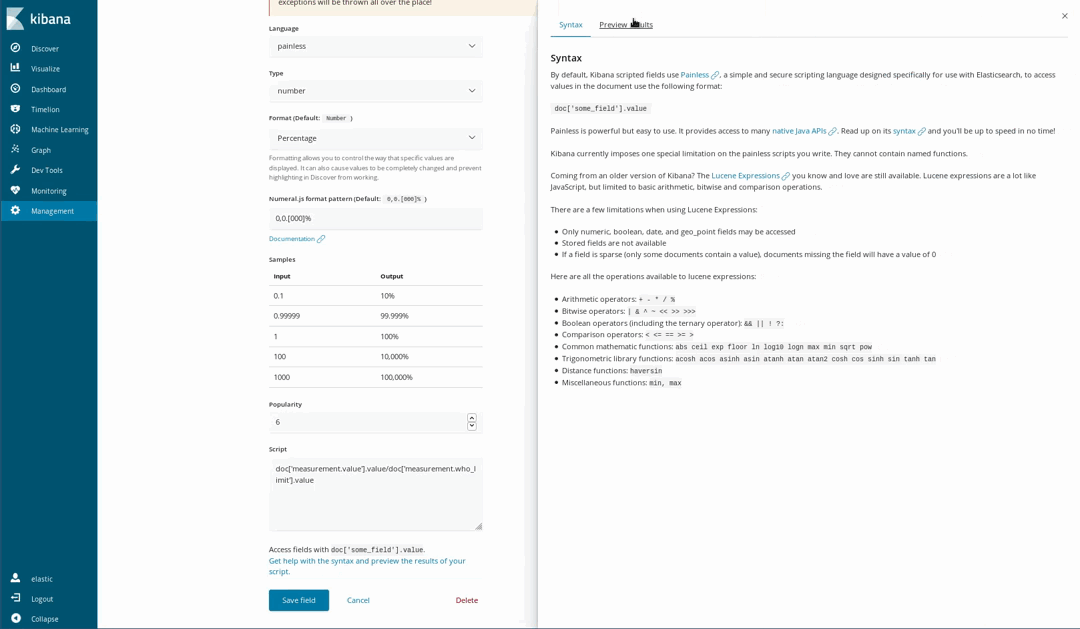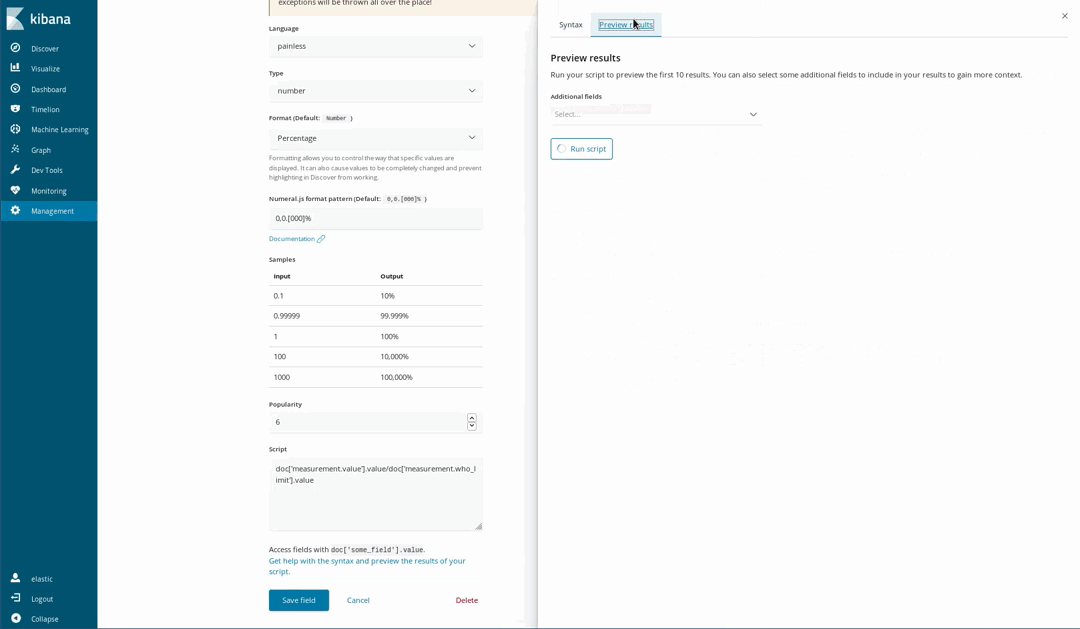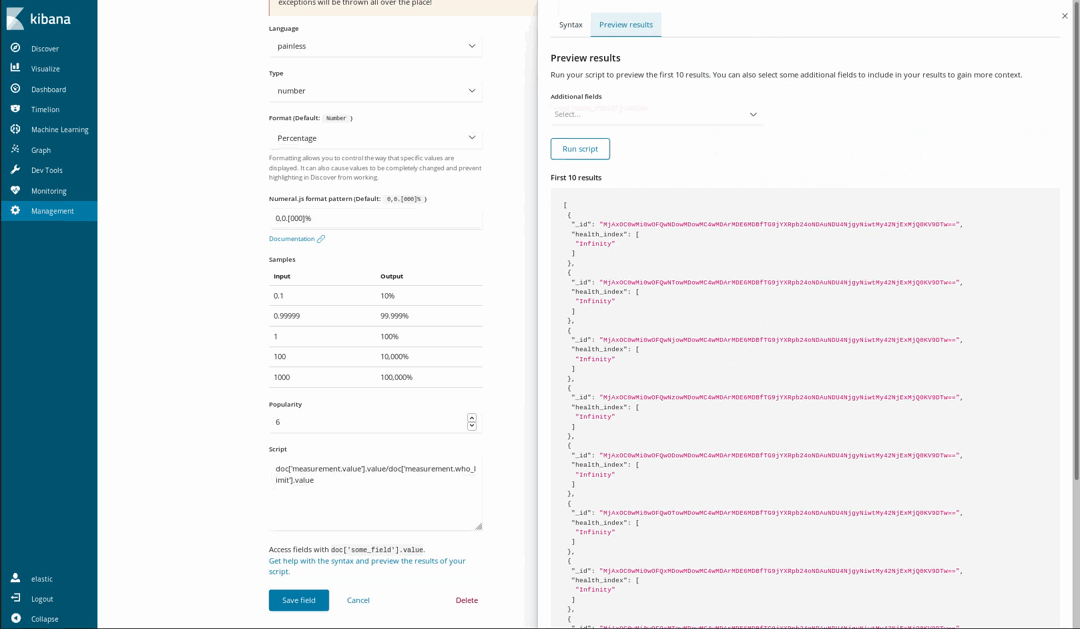
次に、これを通常のインデックスフィールドと同じように可視化します。
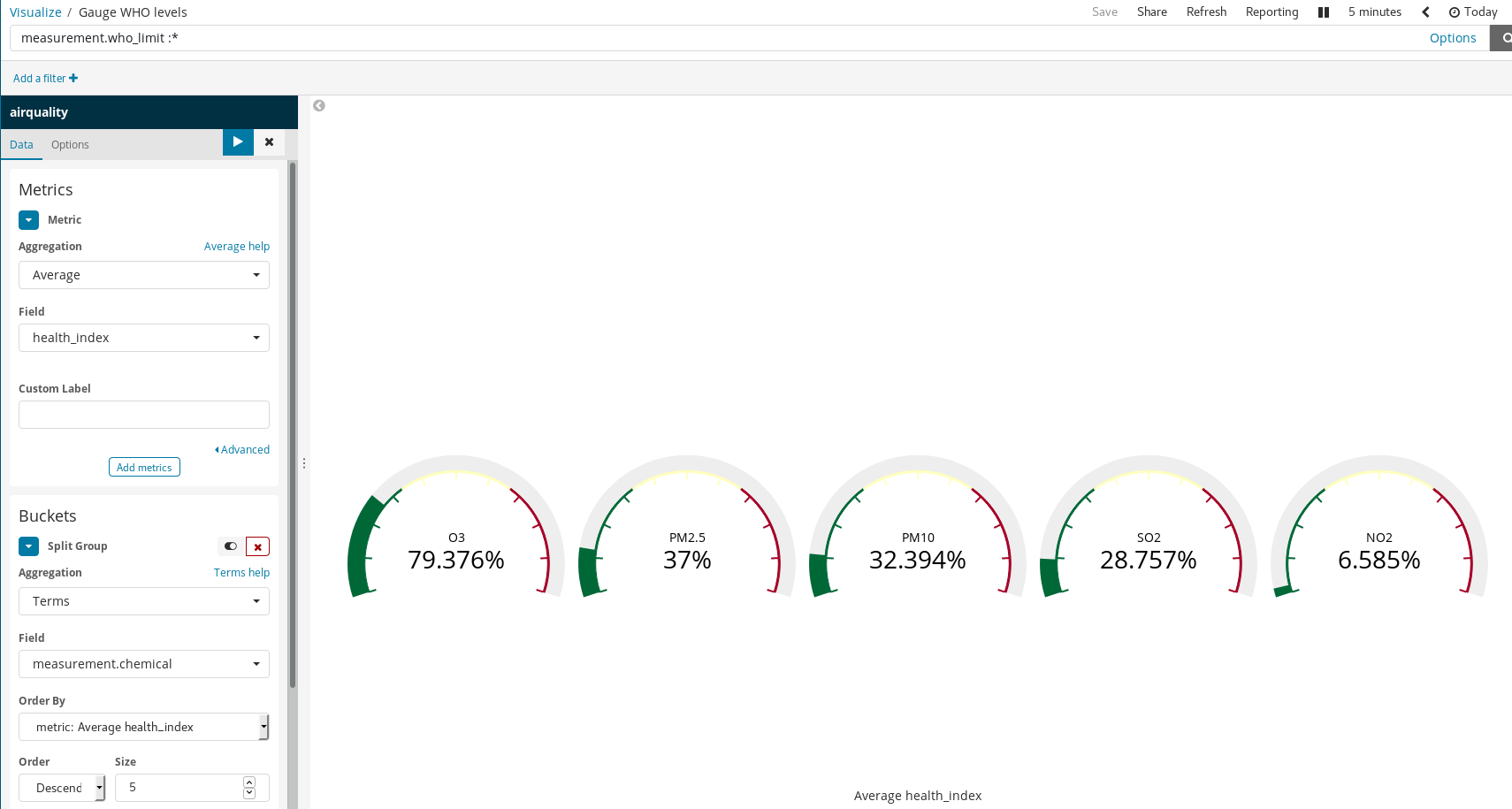
Kibanaで、シンプルなルールでこれほどリッチな可視化を作成することができます。上述の例では、以下の処理を行いました。
- ドキュメントをフィルタリング:WHOで上限の規定があるものだけを選択しました。
measurement.chemicalに対してSplit GroupsとTerm Aggregationを使用しました。
これで、WHOが上限を定める各化学物質についてゲージグラフを生成することができます。
マドリッドの汚染について学ぶ
Kibanaの可視化機能を活用すると、可視化を集約するダッシュボードを構築することができます。これは、任意のシステムの状態をリアルタイムに解釈・理解する際に役立ちます。このケースの場合、大気の組成と、人間の活動との相互作用が「システム」に相当しています。
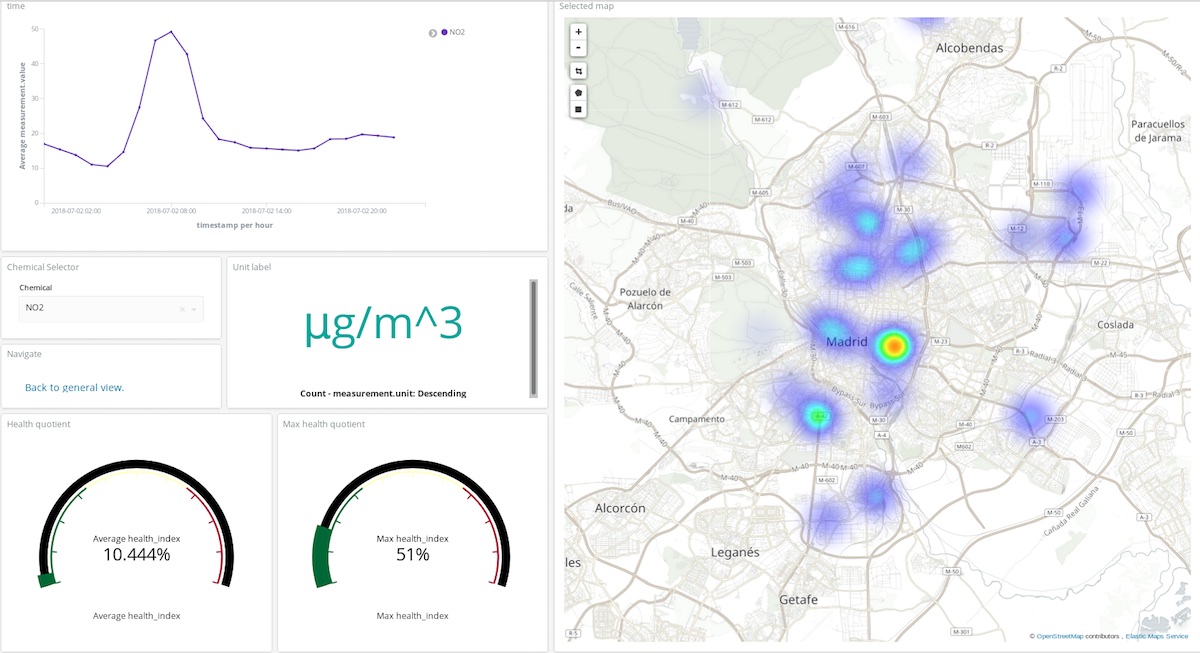
上のダッシュボードでは、ユーザーが化学物質と期間を選んで表示させることができ、いつどこで、どんな物質が大気を汚染していたかが一目でわかります。実際のダッシュボードはこちらでご覧ください(ユーザー名:test、 パスワード:madrid_airです)。
マドリッドの空気質について概要を見ることもできます(ユーザー名とパスワードは同じ)。
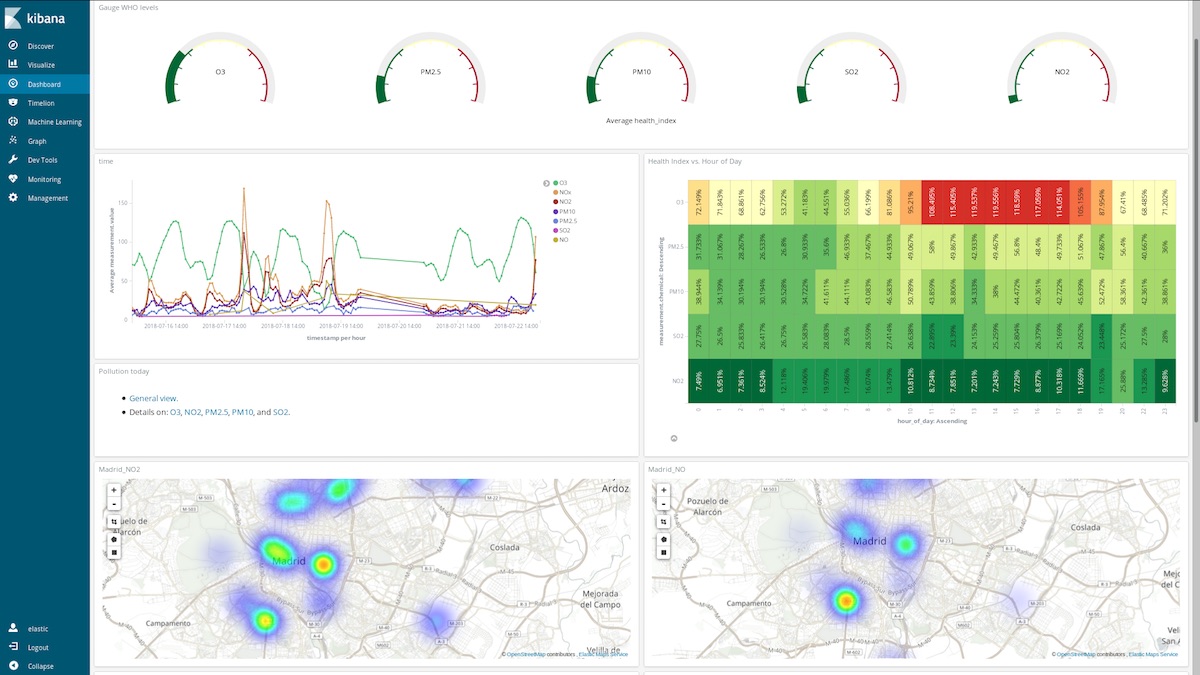
このダッシュボードをどのように役立てることができるでしょうか。2018年3月の任意の週について見てみましょう(3月12日-18日)。
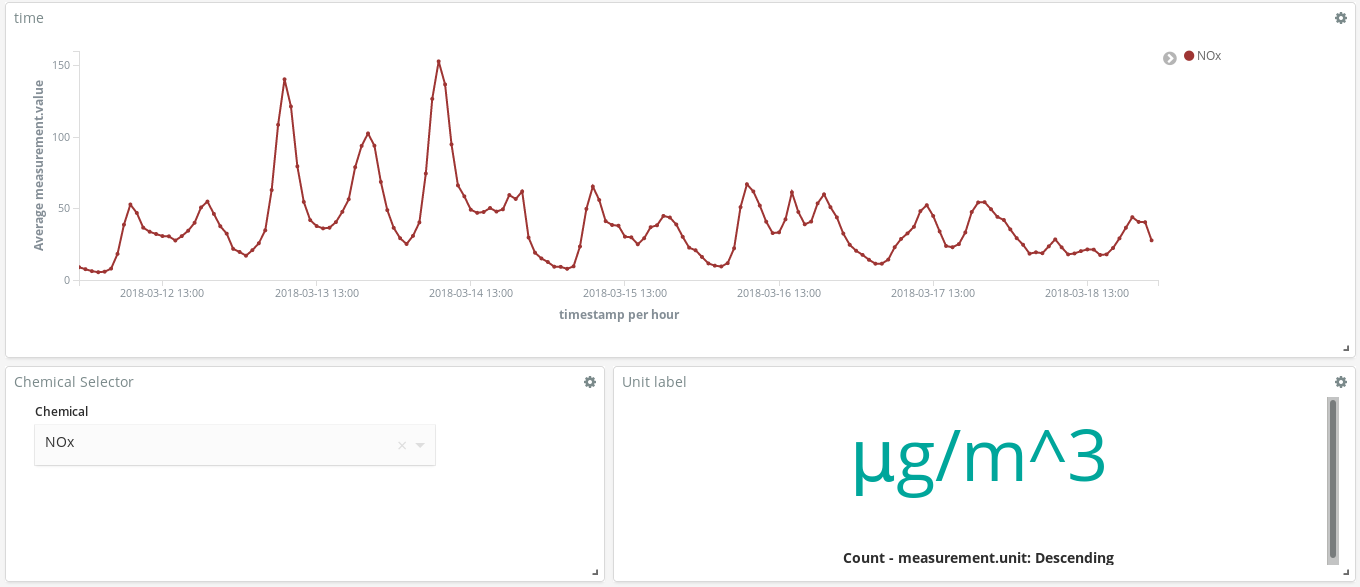
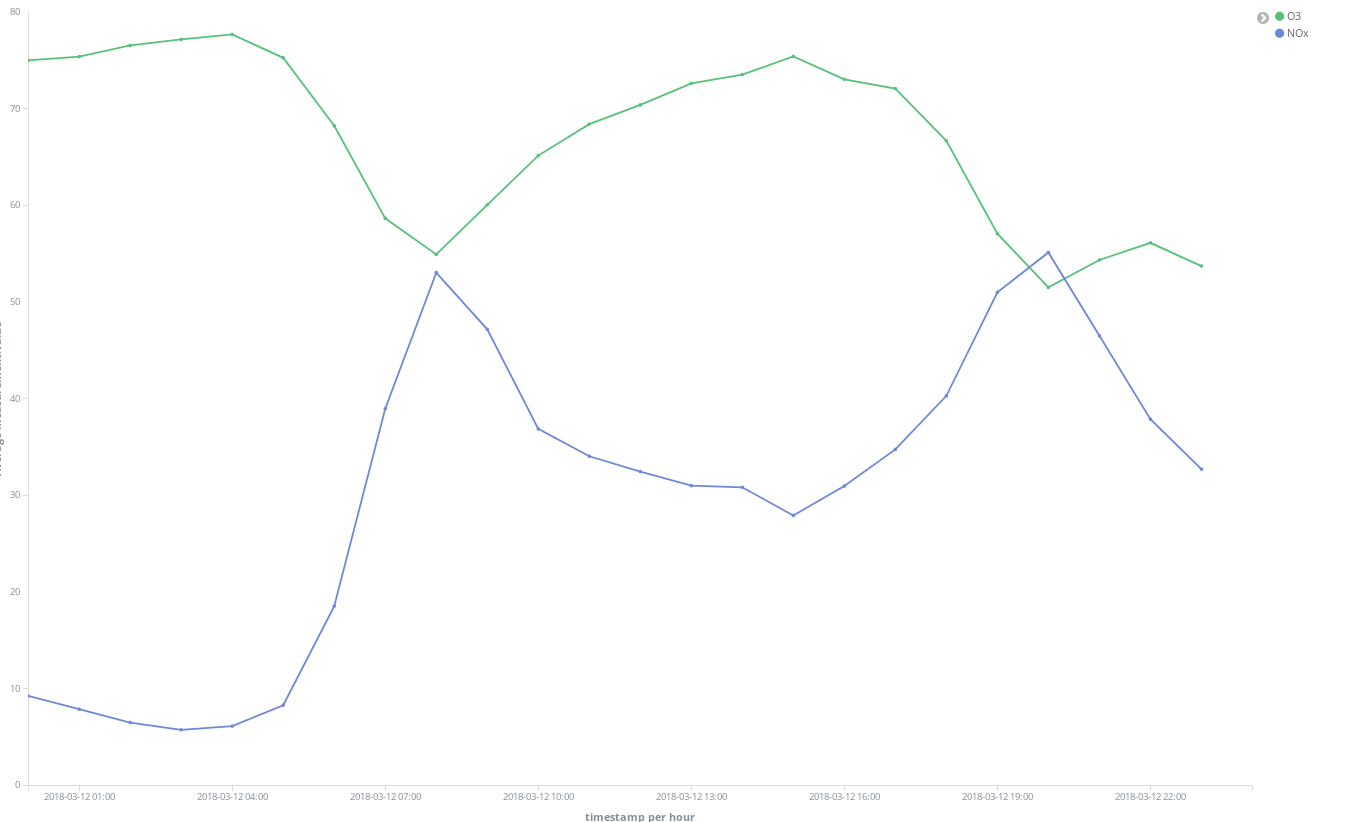
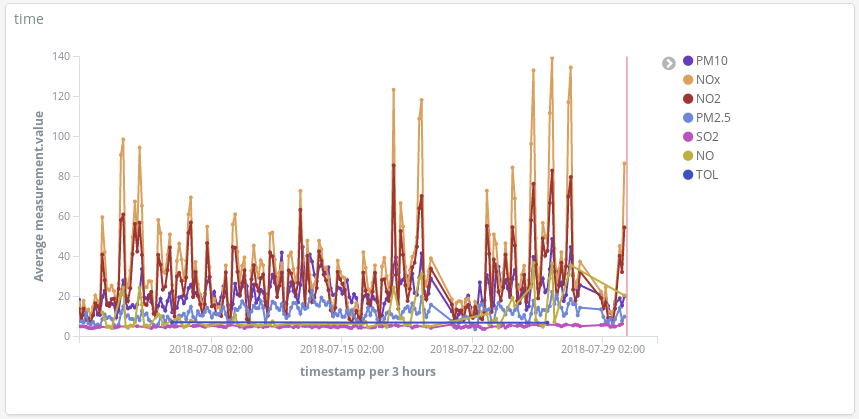
NOx(ディーゼルエンジンなどが排出する窒素酸化物)のピークがあります。ここからマドリッド市民の生活について、どのようなことがわかるでしょうか?お気づきですね。1日2回ピークがあります。
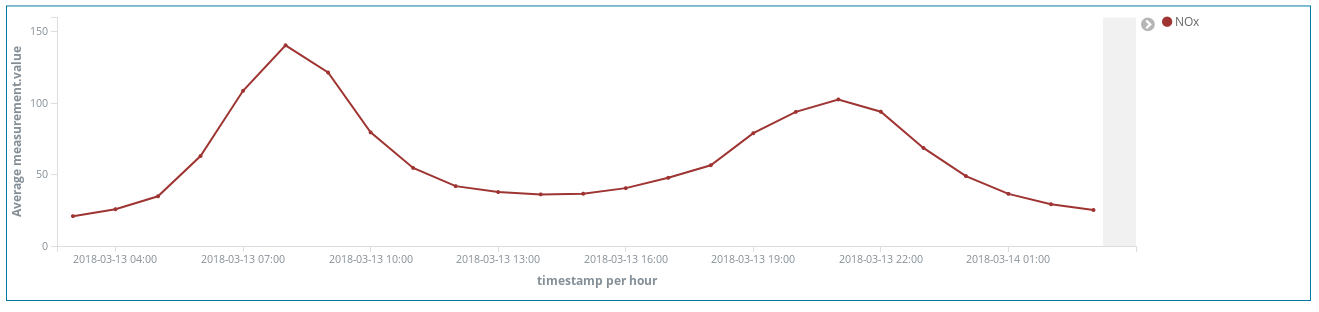
1回目は中央ヨーロッパ夏時間で午前8時頃、2回目が午後9時ごろです。多くの人が職場に向かう時間にはディーゼル車の使用も増えています。勤務中の時間にあたる日中は、あまり乗っているがいないようです。そして勤務時間が終わり、自宅に向かう頃になると再び排出ガスのピークが発生します。
興味深いのは、NOxが減少する時間帯にO3(オゾン)濃度が上昇している点です。O3はNOxと有機化合物が太陽光線を受けて起こす反応を起こす結果生じる副産物なので、NOxとO3には関連性があると考えられます。
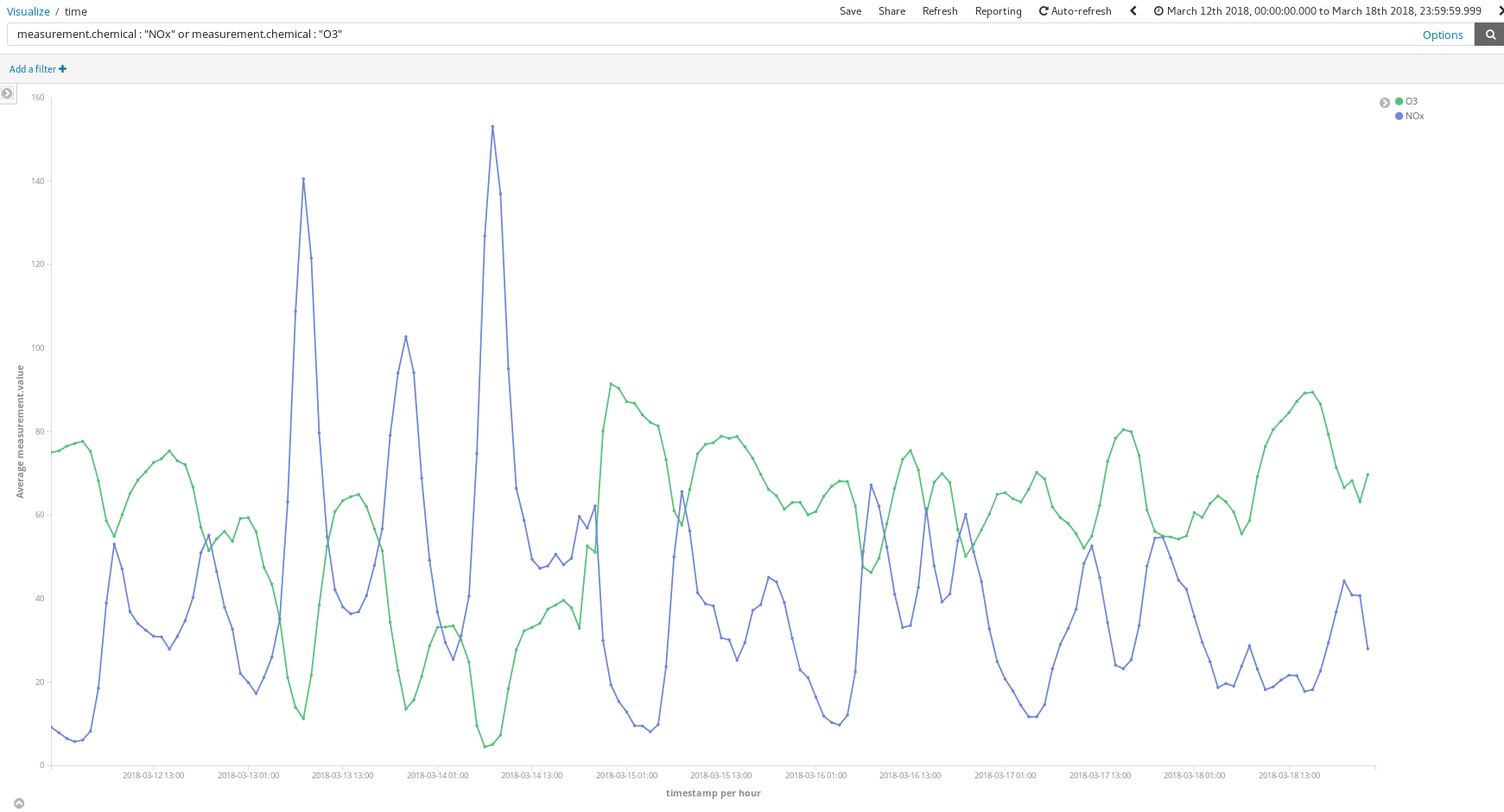
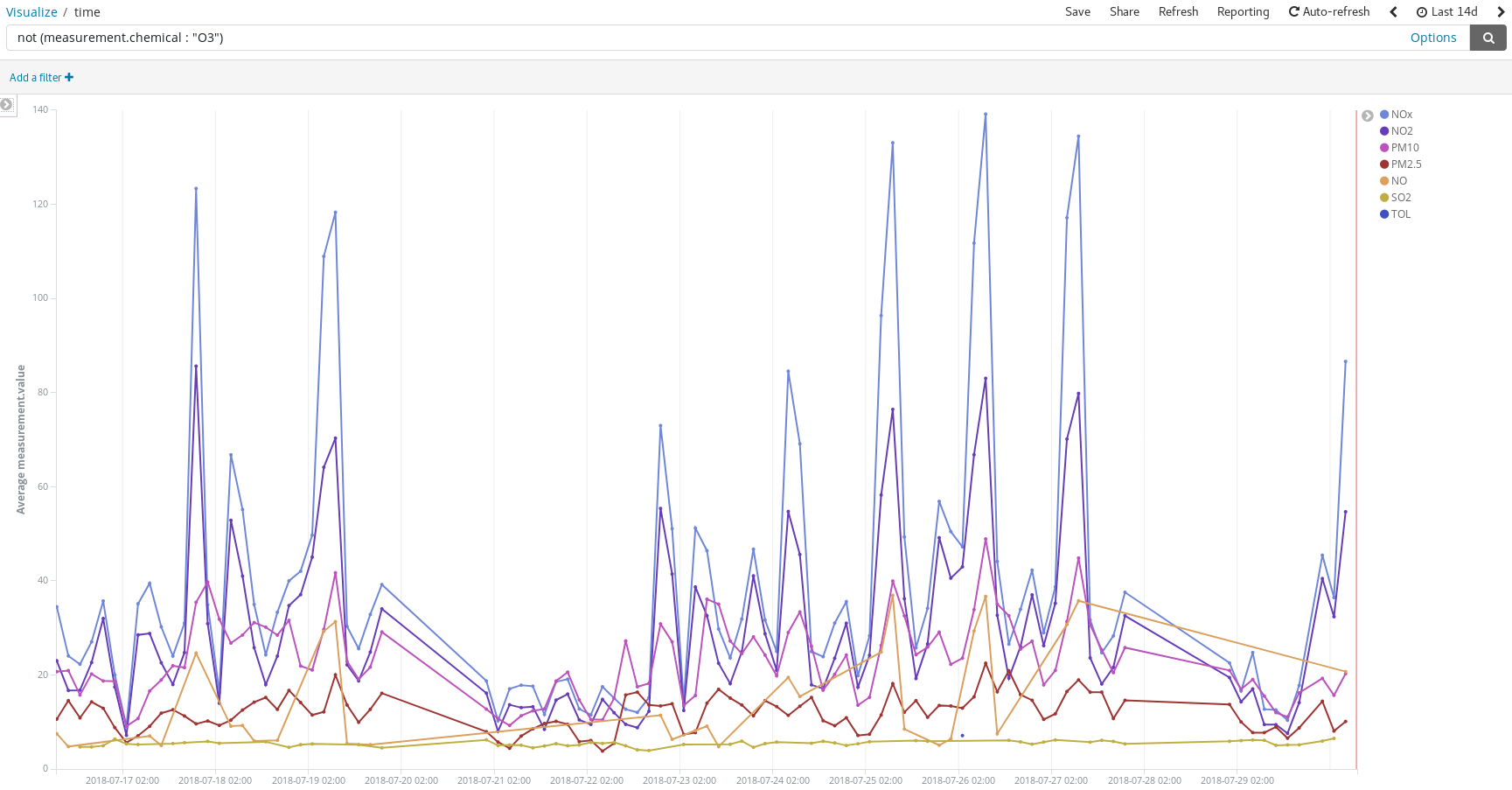
また、週末には全体的に汚染が改善されることもわかります。
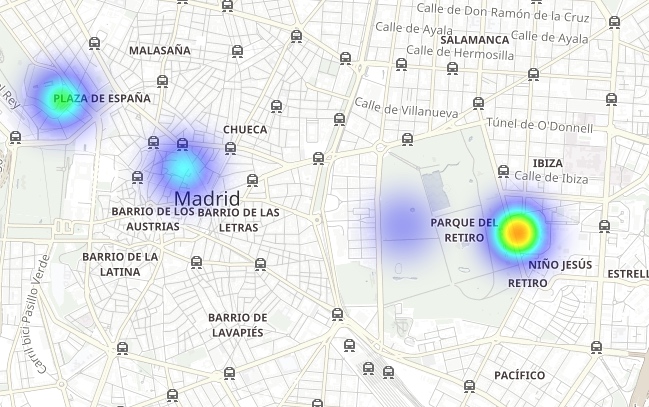
レティーロ公園(市中央の広大な緑地)には豊かな植栽があり、自動車が通行しないエリアであるにもかかわららず、排出されたNO2のホットスポットに囲まれていることもわかります。
多くの人が車で夏の行楽地へ向かう日に汚染のピークを検出しているとわかります。
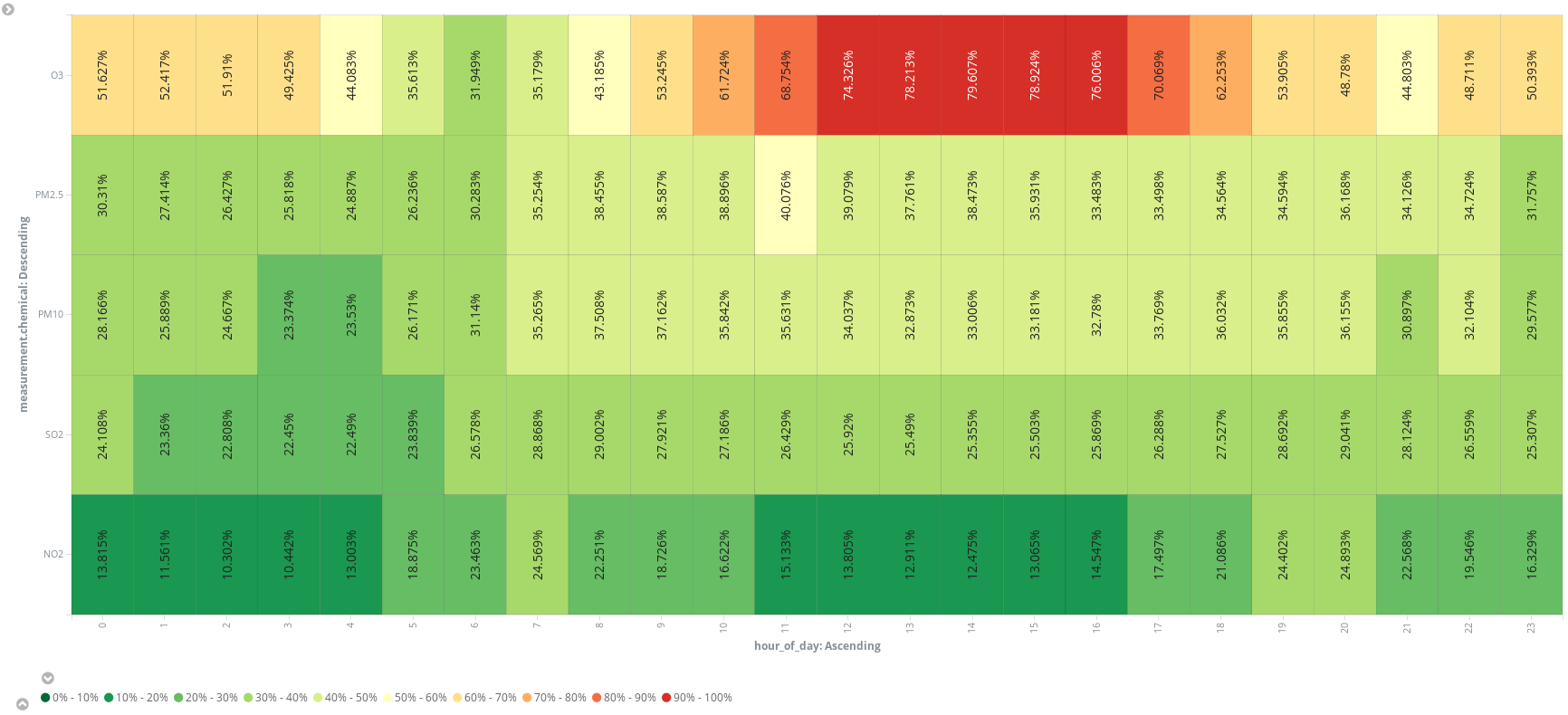
追加のスクリプトフィールド(hour_of_day)を追加すると、ヒートマップ内で時間帯のバケットに区切り、化学物質ごとの平均測定結果を表示することができます。ランニングの予定を立てるなら、午前6時ごろが最も良さそうです。
ここまでの分析で、(残念ながら)大気中には窒素、酸素、二酸化炭素、アルゴン、水以外の物質がそれなりに含まれているということがわかりました。マドリッドのグランビア通りを散策しながら肺に入れた空気には、少々余計な化学物質も入っていたようです。では、マンハッタンを観光する場合は?... 気になる方は、ぜひご自身で確認してみてください。こちらのデータソースを使用してはじめることができます。
まとめ
もしエンジニアとしてデータサイエンティストにマドリッドの大気汚染度を分析するよう頼まれたら、Kibanaに空気質インデックスパターンを登録して、メールにリンクを貼り付けたところで任務は完了です。あとはデータサイエンティストがKibanaで自由に楽しむでしょう。Elastic Stackには分析に必要な機能がすべて備わっています。数分で回答を入手でき、操作も直感的です。必要に応じてコードを記述する場合も、スクリプト化されたフィールドへ入力するだけで済みます。
Elastic Cloudを使うことでデータエンジニアの仕事は非常にシンプルになります。数回クリックして、ETL(Extract Transform Load)サービスを記述するだけです。ところで、取得のためにETLを記述して、データをElasticsearchに投入する作業は本当に必要なのでしょうか?次回記事では、Elastic Stackにこの作業を実行させる方法をご紹介する予定です。