ステートレス — Elasticsearchによる検索の新しい状態
進化するElasticsearchのアーキテクチャでデプロイを簡素化



Twitter


リンクトイン


Facebook


メール


印刷
これまでの経緯
最初のバージョンのElasticsearchは、2010年に、分散型のスケーラブルな検索エンジンとしてリリースされました。これにより、ユーザーは重要なインサイトをすばやく検索し、浮き彫りにできるようになりました。それから12年、65,000回以上のコミットを経て、Elasticsearchはさまざまな検索の問題に対して検証された解決策をユーザーに提供し続けています。Elasticの正社員数百人を含む1,500人以上の貢献者の努力により、Elasticsearchは検索分野で発生する新しい課題に対応するために常に進化を続けています。
Elasticsearchの初期の頃、データ損失の懸案事項が生じたときに、Elasticチームは数年にわたる努力を続け、クラスター調整システムを再作成し、確認されたデータが確実に安全に格納されるようにしました。大規模なクラスターでのインデックスの管理が面倒であることがはっきりしたとき、チームは拡張ILMソリューションの実装に取り組みました。そして、ユーザーがインデックスパターンとライフサイクルアクションをあらかじめ定義できるようにすることで、この作業を自動化しました。ユーザーがメトリックや時系列データを大量に格納する必要があることがわかったとき、圧縮率を高めるなど、データサイズを小さくするためのさまざまな機能が追加されました。大量のコールドデータを検索するストレージコストが増大したときには、当社は、低コストのオブジェクトストアで直接ユーザーデータを検索する方法として、検索可能スナップショットの作成に投資しました。
これらの投資は、Elasticsearchの次の進化のための基礎となるものです。クラウドネイティブサービスや新しいオーケストレーションシステムの成長に伴い、クラウドネイティブシステムと連携する際の体験を改善するために、Elasticsearchを進化させる時期が来たと判断しています。当社は、このような変化は、Elastic CloudでのElasticsearchの運用中に、運用、パフォーマンス、コストの改善の機会であると考えています。
将来の展望 — 将来はステートレス
Elasticsearchの運用やオーケストレーションにおける主な課題の1つは、それが多数の永続的な状態に依存しており、このためにステートフルなシステムであるということです。主な項目は、トランスログ、インデックスストア、クラスターメタデータの3つです。この状態は、ストレージが永続的でなければならず、ノードの再起動や交換の間に失うことが許されないことを意味します。
Elastic Cloudの既存のElasticsearchアーキテクチャは、障害時の冗長性を確保するために、複数のアベイラビリティゾーンでインデックスを複製する必要があります。Elasticは、このデータの永続性を、ローカルディスクからAWS S3のようなオブジェクトストアに移行するつもりです。このデータの保存を外部サービスに頼ることで、インデックスのレプリケーションを不要にし、インジェストに関連するハードウェアを大幅に削減します。また、AWS S3、GCP Cloud Storage、Azure Blob Storageなどのクラウドオブジェクトストアは複数のアベイラビリティゾーンにまたがってデータをレプリケーションするため、このアーキテクチャは非常に高い耐久性を保証しています。
また、インデックスストレージの負荷を外部サービスに分散することで、インデックス作成と検索の責任を分離し、Elasticsearchを再設計できます。プライマリインスタンスとレプリカインスタンスで両方のワークロードを処理するのではなく、インデックスティアと検索ティアを展開するつもりです。これらのワークロードを分離することで、独立してスケールでき、それぞれのユースケースに合わせてハードウェアを選択することもできます。また、検索とインデックスの負荷が相互に影響を及ぼすという長年の課題も解決できます。
数か月に及ぶ概念実証と実験段階を経て、これらのオブジェクトストアサービスは、インデックスストレージとクラスターメタデータに関して当社が想定する要件を満たしていると確信しています。当社のテストとベンチマークによると、これらのストレージサービスは、Elastic Cloudで見られた最大のクラスターの高いインデックス作成ニーズに対応できることが示されています。さらに、データをオブジェクトストアにバックアップすることで、インデックスのコストを削減し、検索パフォーマンスのチューニングを簡素化できます。データを検索するために、Elasticsearchは、データがクラウドネイティブのオブジェクトストアに永続的に保存され、ローカルディスクが頻繁にアクセスされるデータのキャッシュとして使用される、実証済みの検索可能スナップショットモデルを使用します。
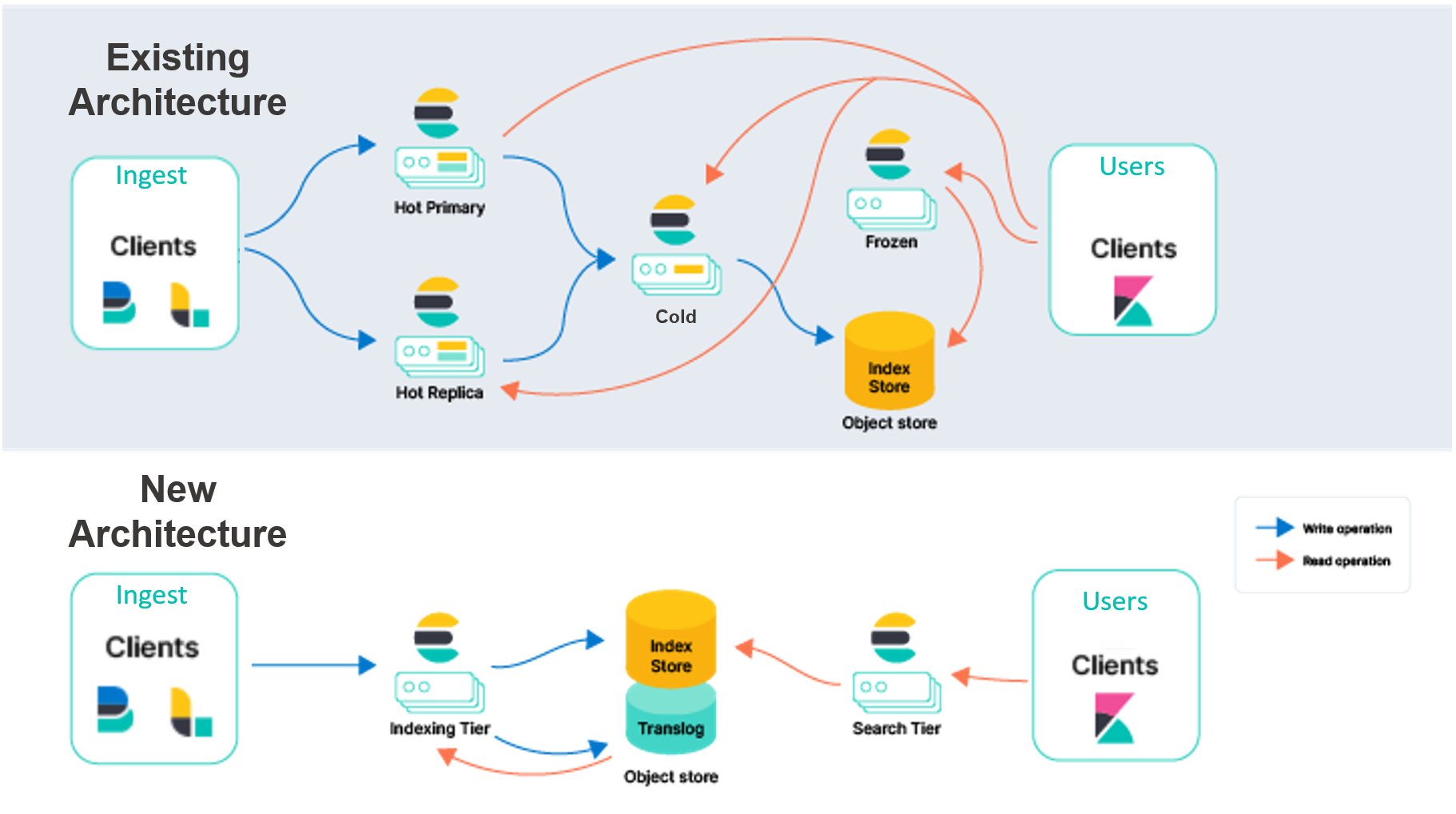
区別するために、Elasticでは、既存のモデルは「ノード間」レプリケーションと呼ばれています。このモデルのホットティアでは、プライマリシャードとレプリカシャードの両方が同じ負荷で、インジェストを処理し、検索リクエストに対応します。これらのノードは、ローカルディスクに頼って、ホストするシャードのデータを安全に永続させるという点で「ステートフル」です。また、プライマリシャードとレプリカシャードは常に通信して同期されています。これを実現するために、プライマリシャードで実行された処理がレプリカシャードにレプリケーションされます。つまり、処理のコスト(主にCPU)は指定された各レプリカに対して発生します。インジェストでこの処理を実行する同じシャードやノードは、検索リクエストにも対応しているため、プロビジョニングとスケーリングは、両方のワークロードを考慮して行われる必要があります。
検索とインジェストだけでなく、ノード間レプリケーションモデルのシャードは、Luceneセグメントのマージなど、他の集中的な責任も処理します。この設計にも利点がありますが、当社は、長年にわたってお客様とともに学んできたことや、より広いクラウドエコシステムの進化に基づき、多くの機会を見出しました。
新しいアーキテクチャは、以下のような多数の短期で実現できる改善や将来の改善を可能にします。
- 同じハードウェアでインジェストのスループットを大幅に向上させることができます。また、別の見方をすれば、同じインジェストワークロードでも大幅に効率化できます。この効果は、すべてのレプリカのインデックス操作の重複を解消したことによります。CPUに負荷のかかるインデックス処理は、インデックスティアで一度だけ行えばよく、その後、作成されたセグメントをオブジェクトストアに格納する。そこから、検索ティアはデータをそのまま消費できます。
- 演算処理とストレージを分離して、クラスタートポロジーを簡素化できます。現在、Elasticsearchには複数のデータティア(コンテンツ、ホット、ウォーム、コールド、フローズン)があり、データとハードウェアプロファイルを一致させています。ホットティアはリアルタイムに近い検索用で、フローズンは検索頻度の低いデータ用です。これらのティアは価値を提供しますが、複雑さも高まります。新しいアーキテクチャでは、データティアが不要になり、Elasticsearchの構成や運用がシンプルになります。また、インデックスを検索から分離しています。これにより、さらに複雑さを軽減し、両方のワークロードを独立してスケールできます。
- ローカルディスクに保存しなければならないデータ量を減らすことで、インデックスティアでのストレージコストの改善を実現できます。現在、Elasticsearchは、インデックス目的で、ホットノード(プライマリとレプリカの両方)に完全なシャードコピーを保存する必要があります。オブジェクトストアに直接インデックスを作成するステートレスアプローチでは、必要となるのは、そのローカルデータの一部だけです。追加のみのユースケースでは、インデックス用に特定のメタデータのみを保存する必要があります。これにより、インデックスに必要なローカルストレージを大幅に削減できます。
- 検索クエリに関連するストレージコストを下げることができます。検索可能スナップショットモデルをデータ検索のネイティブモードにすることで、検索クエリに関連するストレージコストを大幅に削減できます。Elasticsearchでは、ユーザーの検索レイテンシのニーズに応じて、頻繁にリクエストされるデータのローカルキャッシュを増やすように調整できます。
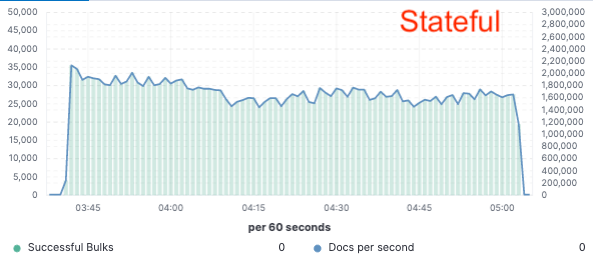
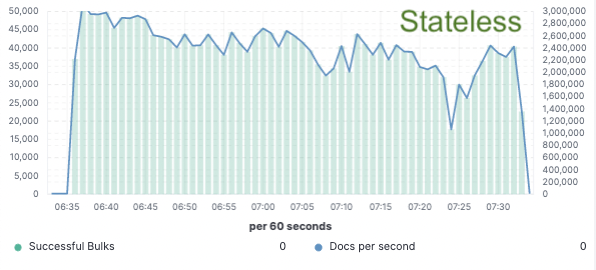
ベンチマーク - インデックスのスループットが75%向上
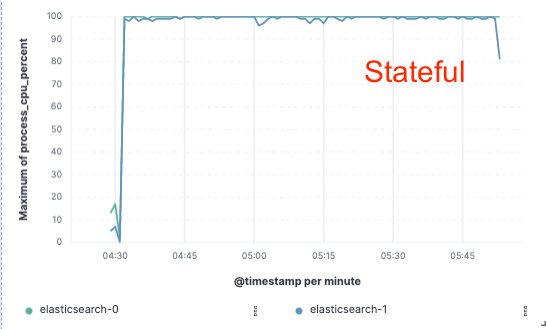
このアプローチを検証するために、Elasticは大規模な概念実証を実施しました。ここでは、データは単一ノードでのみインデックスされ、レプリケーションはクラウドオブジェクトストア経由で実現されました。そして、ハードウェアをインデックスのレプリケーション専用にする必要性を解消することで、インデックススループットを75%改善できることがわかりました。さらに、オブジェクトストアからデータを取得するだけのCPUコストは、現在のホットティアで必要なようなデータのインデックスやローカルへの書き込みに比べてはるかに低いものでした。つまり、検索ノードは完全にCPUを検索専用にすることができるようになります。
これらのパフォーマンステストは、3つの主要なパブリッククラウドプロバイダー(AWS、GCP、Azure)すべてに対して、2ノードのクラスターで実施しました。今後、Elasticは、ステートレス実装の本番化に向け、より大きなベンチマークを構築していく予定です。
インデックススループット
CPU使用状況
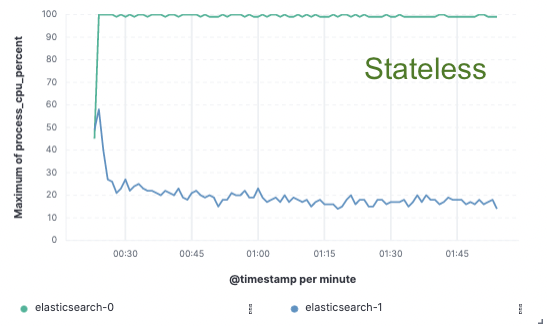
Elasticのステートレスでコストの削減
Elastic Cloudのステートレスアーキテクチャにより、インデックスのオーバーヘッドの削減、インジェストと検索の独立したスケール、データティアの管理の簡素化、スケールやアップグレードなどの運用の高速化が可能になります。これは、Elastic Cloudプラットフォームの大幅な最新化に向けた最初のマイルストーンです。
Elasticのステートレスビジョンに参加する
このソリューションを誰よりも先に試したい場合は、ディスカッションまたはElasticのコミュニティslackチャンネルでお問い合わせください。新しいアーキテクチャの方向性を形作るために、ぜひ皆様のご意見をお聞かせください。
シェアする
Twitter
リンクトイン
Facebook
メール
印刷

