1PBのクラウドストレージ上のデータを10分で検索する
Frozenデータティアは、Elasticがリリースした最新のデータティアです。演算処理とストレージが分離されており、Google Cloud StorageやAzure Blob Storage、Amazon S3などのローコストオブジェクトストアをダイレクトに検索できます。Frozenティアを使うと効率的にデータをクエリする能力を保ったままストレージを無制限にスケールでき、検索前にデータのリハイドレーションを行う必要はありません。従来のティアに比べて、大量のデータを簡単かつ安価に管理できます。
このブログ記事では、新登場のFrozenティアと既存のElasticsearchデータティアの検索パフォーマンスを比較実演します。Frozenティアを使うとはるかに大量のデータを格納・検索でき、やや低いパフォーマンスで活用できることを示します。Frozenティアの主な特徴は次の通りです。
- データがキャッシュされていない場合、4TBのデータセットに対してシンプルなクエリをかけると、わずか数秒で結果を返す。データがキャッシュされている場合は数ミリ秒で検索結果を返し、WarmまたはColdティアと同等のパフォーマンスとなる。
- データがキャッシュされていない場合、4TBのデータセットに対して複雑なKibanaのダッシュボードを演算処理すると、5分以内に完了する。データがキャッシュされている場合は数秒で完了し、、WarmまたはColdティアと同等のパフォーマンスとなる。
- データ量を増やし、簡単に1PBのデータセットにスケールできる。キャッシュされていない場合、シンプルな用語のクエリの結果を10分以内に返す。
本記事の執筆時点で、FrozenティアはElasticsearch 7.12およびElastic Cloudでテクニカルプレビューで提供されています。近日、一般公開を予定しています。
データティアの概要
データティアは多様なニーズ、たとえば新しさやデータソース、その他の基準に基づいてデータにアクセスできるよう、最適なストレージと処理能力を提供します。Hotティアは典型的には、クラスターに取り込む新規データのすべてのインデキシングを扱うほか、クエリ頻度が最も高い傾向にあるデイリーな最新のインデックスを保持します。インデキシングは大抵の場合、I/Oインテンシブなアクティビティです。ノードを実行するハードウェアに高い処理能力が要求されるため、通常はSSDストレージを使います。Warmティアはクエリの頻度がやや低い、大容量のインデックスを扱うことができるため、超大容量の回転ディスクなどの安価なストレージなどで長期にわたってデータを保持できます。長期にデータを保持する際の全体的なコストを軽減でき、保持データをクエリできます。
最近導入されたColdティアとFrozenティアは、ローコストストレージを活用して大量のデータをコスト効率よく管理します。どちらも、データを検索する能力を備えています。

Coldティアではデータを複製する必要がなく、復旧を伴うイベントには、スナップショットからデータを復元して対応します。HotティアとWarmティアでは通常、ディスク容量の半分がレプリカシャードの格納に使用されます。この冗長なレプリカは高速かつ一貫性のあるクエリパフォーマンスをもたらすほか、マシンの故障時にはレプリカがプライマリシャードとなることで、レジリエンシーが確実に提供される仕組みです。ライフサイクルが進み、データが読み取り専用になると、今度は復旧をスナップショットに任せることができます。つまり、Coldティアにレプリカシャードは存在しませんが、ノードやディスクにエラーが生じた場合、データはスナップショットから自動的に復旧されてクラスターの完全なコピーが再構築されます。こうして、再びローカルディスクを検索に使うことが可能になります。この目的に最適に使えるのがスナップショットレポジトリです。blobストアに格納するとローカルのSSDや回転ディスクに格納するよりもはるかに安上りで、しかも多くの場合、バックアップ用のデータが既にblobストアに存在しています。したがってColdティアに必要なストレージ容量はWarmティアの半分です。クエリパフォーマンスはWarmティアとほぼ同等、可用性はわずかに劣りますが、コストはWarmティアの2分の1になります。
Frozenティアはさらに進化し、クラスター内のデータのごくわずかな部分、つまり頻繁にアクセスがあるデータだけをキャッシュすることにより、ストレージと演算処理を分離しています。オブジェクトストアからは、必要なとき、すなわち検索が実行された場合にだけデータをフェッチします。この結果、Frozenティアの演算処理対ストレージ比は、Elasticsearchで実現しうる最高比率になります。Frozenティアで検索を実行すると、Hotティア、Warmティア、Coldティアよりも遅くなる可能性があります。しかし運用やセキュリティに伴う調査、法的証拠開示、パフォーマンス履歴の比較といった頻度の低い検索の用途であれば、トレードオフを許容する余地があります。Elasticsearchはデフォルトですべてのドキュメントをインデックスし、それがFrozenティアの機能のパワフルな動作を支えています。クエリを実行するにあたってデータの完全なスキャンを行う必要がなく、インデックスストラクチャーを活用して大量のデータセットからもすばやく結果を返すことができます。
Frozenティアが動作する仕組み
Frozenティア内の1つのノードに、すべてのインデックスを完全にコピーするほどのディスク容量を持たせる必要はありません。その代わり、Elasticは“オンディスクLFUキャッシュ”を導入しました。これは、所与のクエリを実行する際に、blobストアからダウンロードされたインデックスデータの部分だけをキャッシュします。このオンディスクLFUキャッシュの動作はOSのページキャッシュに類似しており、blobストアデータの中で、リクエストの頻度が高い部分へのアクセスを高速化します。具体的には、Luceneレベルでの読み取りリクエストがローカルキャッシュの読み取りリクエストにマッピングされます。キャッシュがない場合、blobストアから広範な領域(16MBのチャンク)のLuceneファイルがダウンロードされて、検索に使えるようになります。次回Luceneがファイルの同じ領域にアクセスすると、ローカルキャッシュが直接その領域を提供します。
ノードレベルのシャードキャッシュは、"least-frequently-used"(使用頻度が最も低い順)のポリシーに基づいてマップ済みのファイル領域を引退させます。これは一般に、Luceneファイルの中で一部の領域が他の領域より高頻度に使われると考えられるためです。つまり、Luceneファイルの一部の領域が、クエリの実行のために何度も要求される場合(@timestampフィールドでの範囲クエリなど)、そのデータはキャッシュ内に維持され、他のデータがキャッシュから引退します。
Frozenティアの検索ではアクセスするファイルの一部の領域をダウンロードする必要があるものの、Luceneは事前演算処理済みのインデックスストラクチャーに基づいて検索を実行するため、スキャンするデータ量はわずかであり、高速に検索できます。このシャードのメモリフットプリントを削減するため、Luceneインデックスは必要な場合、つまり、アクティブな検索がある場合しか利用されません。これにより、Frozenティアのノードには多数のインデックスを持たせることが可能です。
ベンチマーキングの目的
今回は、各ティアについて初回アクセス(ウォーミングアップを行っておらず、キャッシュを全く使えない状態)の検索パフォーマンスを測定し、その後、同じクエリ(キャッシュが使える状態)で検索を反復します。さらにFrozenティアでは、オンディスクLFUキャッシュがすべてのデータに一致しない場合の反復検索のパフォーマンスも確認します。
このベンチマークに対して、今回は2種類のクエリを使用します。1つ目はセキュリティ調査の代表的なクエリ、大規模なデータセットから一致する少数のドキュメントを見つける(干し草の山で針を探す)タイプのクエリです。2つ目は、Kibanaのダッシュボードに使う代表的なクエリで、大量のデータで複数の複雑なアグリゲーションを演算するというものです。
ベンチマークの目的は異なるデータティアでクエリのパフォーマンスを正確に比較することなので、今回はすべての測定に同じマシンタイプを使用します。しかし、実際のデプロイでは、コストとパフォーマンスのトレードオフによって各ティアに特化したマシンタイプを使用する必要がある点に注意してください。ベンチマークのベースラインは時系列Elasticsearchインデックスの定番である、Hotティアです。WarmティアはHotティアと同じ方法でデータにアクセスします。今回はベンチマークの目的に鑑みてすべてのティアに同じマシンタイプを使うため、WarmティアとHotティアに差異はなく、個別の測定は行いません。Coldティアでは、スナップショットからマウントした同じインデックスの完全なコピーを使用します。Frozenティアでは、オンディスクLFUキャッシュを使ってスナップショットからマウントしたインデックスを使用します。
ベンチマークのセットアップ
Elasticsearch 7.12.1を使い、Google Cloudでベンチマークを実行します。また、ベンチマークは、Elasticが多様な機能のベンチマーキングに使用しているWebサーバーログのイベントベースデータセットに基づいて測定します。ディスクにインデックスされたデータセットのサイズは4TB(各マッピングに80GB&35フィールドのシャードを5つ持つ、10個の時系列インデックス)です。シャードは強制的にマージされて1セグメントになっています。これには読み取りパフォーマンスを最適化するメリットがあり、データをFrozenティアに移行する場合にインデックスライフサイクル管理が使用するデフォルトのオプションにもなっています。各ティアのベンチマーク測定には同じ(事前演算処理済みの)データのスナップショットを使用し、Elasticsearchのrepository-gcsプラグインを使用してGoogle Cloud Storageでアクセスします。人為的なパフォーマンス制限を起こさないため、リカバリースロットリングは無効化しています。
1つ目のベンチマーク測定で実行する検索には、データセット内で、所与のIPアドレスがWebサーバーにアクセスしたデータの出現を見つけるシンプルな用語クエリ、"nginx.access.remote_ip":"1.0.4.230"を使用します。
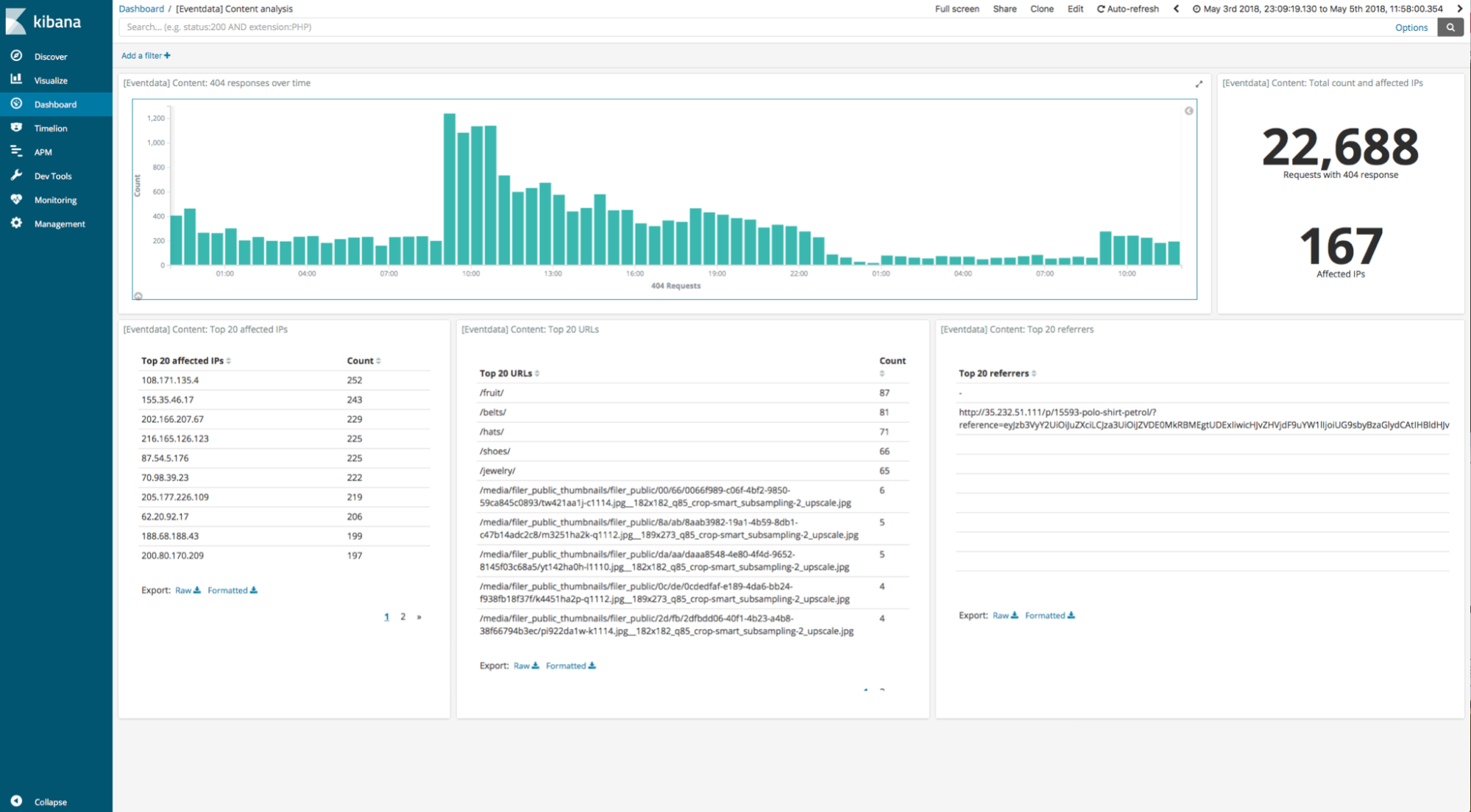
2つ目に実行する検索は、404レスポンスコードが生じたリクエストを分析する(たとえば、表示先が存在しないリンクを見つけるなどの)目的で設計され、5つの可視化を組み込んでいるKibanaのダッシュボードです。
各ベンチマークシナリオを実行する前に、ランツーランのばらつきを抑制する準備の手順をいくつか実行します。この手順にはOSのキャッシュとslabオブジェクトの縮小、SSDdディスクのトリミングを含みます。HotティアとWarmティアでは、Elasticsearchはデフォルトでhybridfs store typeを使用します。これは、Luceneの一部のファイルタイプのマップを記憶します。ColdティアとFrozenティアは、メモリマッピングを使用しません。メモリマッピングは、ページをプリフェッチしてページキャッシュに影響を与えます。今回はメモリマッピングを使う場合のHot/Warmティアの結果のほかに、"niofs" index.store.typeを設定する場合の結果も求めます。"niofs" index.store.typeでローカルファイルにアクセスする手法は、ColdティアおよびFrozenティアに類似しています。
シンプル化のために今回はシングルノードクラスターだけを使ってベンチマークを測定しますが、各データティアはマルチノードのクラスターもサポートしています。Hot/WarmティアおよびColdティアに使用するシングルノードクラスターは、Google Cloudで8 vCPU、64GB RAMを備えるN2D(n2d-custom-8vCPUs-64GB))インスタンスと、4TBのデータセットに完全に適合するRAID-0の16x375GBローカルスクラッチSSDディスクです。これは、オンディスクLFUキャッシュ向けに高速なローカルディスクを搭載し、Google Cloud Storageと高速にネットワーク接続することから、適切なインスタンス候補です。
さらに、反復検索におけるキャッシュの重要性を検証するため、異なる2つのキャッシュサイズ、200GB(データセットの5%)と、20GB(データセットの0.5%)でFrozenティアのオンディスクLFUキャッシュを試します。
結果
クエリパフォーマンスは、OSレベルのページキャッシュから、Elasticsearchのシャードリクエストキャッシュ、さらにノードクエリキャッシュなどのアプリケーションレベルのインメモリキャッシュまで、様々なキャッシングメカニズムの影響を受けます。本記事では、このようなキャッシュが各結果にどのように作用するかについても説明します。またランツーランのばらつきを軽減するため、以下では5回の試行の中央値を結果として記載しています。
シンプルな用語のクエリ
まずはじめに、シンプルな用語のクエリの結果を見てみましょう。この結果で注目すべきポイントは、Frozenティアが4TBのデータセットに対して、結果(一致ドキュメント5つ)を数秒以内に返したということ、また一致する要素を見つけるにあたり、データのごく一部しかダウンロードしていないということです。これは、Luceneのパワフルなインデックスストラクチャーによって高速な参照が実現したことを強調する結果となっています。
クエリを反復実行する場合、FrozenティアではローカルのオンディスクLFUキャッシュからデータが提供されるため、すべてのティアでほぼ同等のパフォーマンスとなっています。Elasticsearchのインメモリリザルトキャッシュは、このタイプのクエリではキャッシュされないため、結果に影響しません。Hot/WarmティアおよびColdティアでの反復実行のパフォーマンスは、ページキャッシュで利用できるデータの影響を受けています。
4TBのデータセットでシンプルな用語のクエリを実行する | |||
アクション | Hot/warmティア、niofs | Coldティア | Frozedティア |
シンプルな用語のクエリの初回実行 | 92ミリ秒 | 95ミリ秒 | 6257ミリ秒 |
シンプルな用語のクエリの反復実行 | 29ミリ秒 | 38ミリ秒 | 76ミリ秒 |
注:Frozenティアでキャッシュの再利用によるクエリのパフォーマンス向上を確認する目的で、全てのティアに同一のマシンタイプを使用しています。現実的なデプロイにおいて、異なるティア間のクエリパフォーマンスがこのようになるという意味ではありません。詳しくは、ベンチマークの目標をご確認ください。
niofsの代わりにデフォルトのインデックスストアタイプ、hybridfsを使うと、HotティアとWarmティアのパフォーマンスはわずかに低下します(92ミリ秒から285ミリ秒に低下)。この点について詳しくは、次のセクションで説明します。
Kibanaのダッシュボード
Kibanaのダッシュボードで同じプロセスを実行した結果を見てみましょう。この結果で注目すべきポイントは、ローカルデータにアクセスする他のティアで演算処理したダッシュボードの所要時間が約20秒であったのに対し、Frozenティアが同じ4TBのデータセットでダッシュボードを実行して5分以内に返していることです。このダッシュボードは時間範囲フィルターを使ってデータセットの75%をアグリゲーションしていますが、インデックスストラクチャーのおかげで、レポジトリのデータのごく一部(今回の測定では約3%、詳細は後述します)しかダウンロードしていません。
4TBのデータセットでKibanaのダッシュボードを実行する | ||||
アクション | Hot/warmティア、niofs | Coldティア | Frozedティア (5%キャッシュ) | Frozenティア(0.5%キャッシュ) |
ダッシュボードの初回実行 | 16.3秒 | 16.6秒 | 282.8秒 | 321.5秒 |
ダッシュボード:完全な反復実行、Elasticsearchのリザルトキャッシュなし | 6.2秒 | 7.1秒 | 11.1秒 | 224.1秒 |
ダッシュボード:完全な反復実行、Elasticsearchのリザルトキャッシュあり | 80ミリ秒 | 75ミリ秒 | - | - |
ダッシュボード:類似の反復実行、Elasticsearchのリザルトキャッシュなし | 19.5秒 | 20.3秒 | 23.4秒 | 238.4秒 |
Elasticsearchのリザルトキャッシュが無効化されている場合、反復検索のパフォーマンスは主にページキャッシュに依存します。そしてその結果は、クエリに必要なデータの割合がオンディスクLFUキャッシュに完全に適合する場合のFrozenティアのパフォーマンスとほぼ同等です。もう1つ注目すべきポイントとして、この特定のワークロードに対し、Hot/Warmティアのメモリマッピングがページキャッシュスラッシングを起こしていることです。これは、デフォルトのストアタイプを使う場合、Hot/Warmティアのパフォーマンスにネガティブな(niofsを使った結果が6.2秒であったのに対し、3倍近く遅くなっている)影響をもたらしています。
Frozenティアでは、反復検索における重要性を検証するため、2つの異なるキャッシュサイズで実行しました。はじめに、オンディスクのLFUキャッシュのサイズを200GBに指定しました。これは、4TBのデータに対してはごく少量(データセットのサイズの5%)ですが、このダッシュボードを演算処理するためにダウンロードしたデータ(およそ3%、120GB)を入れるには十分な大きさでした。2回目のベンチマーク測定では、サイズを20GB(元のデータセットのサイズの0.5%)に指定しました。これは、ダッシュボードを演算処理するためのデータすべてを入れるには不十分でした。
Elasticsearchのインメモリキャッシュが有効化されている場合、Elasticsearchノード上でクエリ結果の一部を直接利用でき、再度の演算処理が不要となることから、反復検索を一層高速に実行することができました。一方、Frozenティアは現在のところ、このようなインメモリのElasticsearchキャッシュを使わない仕様です。
さて今回は、フィルターする国コードを変えただけの、わずかに異なるダッシュボードを演算処理するケースでもベンチマークを測定しています。Frozenティアでは、既にダウンロードされていたデータの大部分が、このわずかに異なるクエリを満たす上でも有効となったことでメリットが生じ、他のティアとかなり近い速度で処理できています。
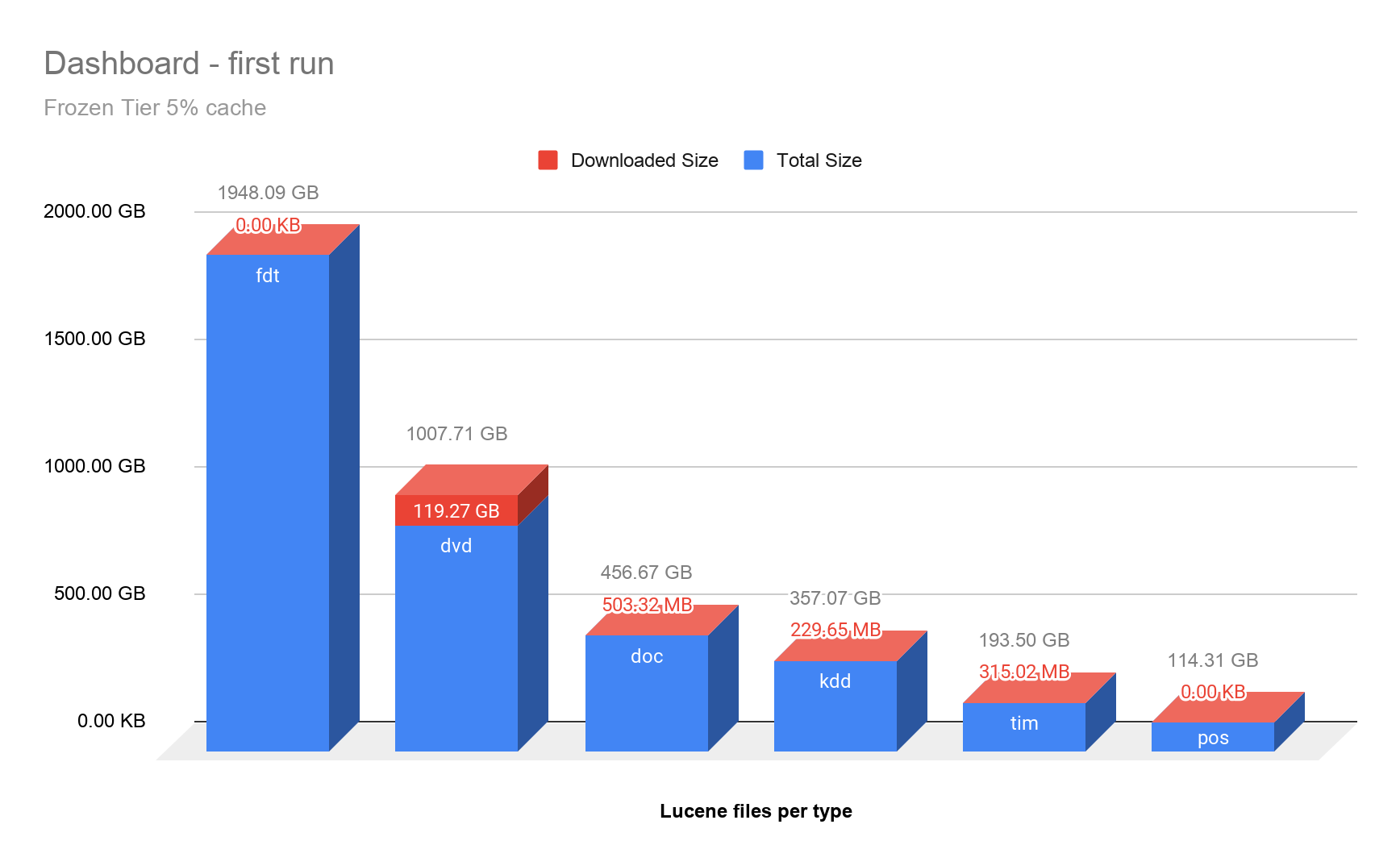
下の図は、最初のダッシュボードの実行中にFrozenティアにダウンロードされたデータの内容を確認するため、リクエストされた最も大きい6つのLuceneファイルタイプと、それぞれのダウンロード割合を可視化したものです。確認した結果、最も容量を消費(ドキュメントを格納)していたのはfdt(Field Data)ファイルですが、アグリゲーションの演算処理にあたってアクセスの対象とはなっていませんでした。予想通り、最もアクセスがあったのはLuceneのdvd(Per-Document Values)ファイルであり、アグリゲーションに使用されたのはdoc値でした。
オブジェクトストレージの大部分への高速なアクセス
Frozenティアにクエリをかけると確かに低速にはなります。しかし、Frozenティアの主たるメリットは、アクセス頻度の低いデータを検索に利用するにあたってリハイドレーションを行う必要がない、という点です。比較してみると、完全なデータセットをローカルで使えるようにする作業は、1時間以上かかることもあります。さらにリカバリースロットリングが無効化されている場合、Frozenティアでダイレクトにクエリを実行するにはさらに長い時間が必要となります。
4TBのデータセットをアクセス可能な状態にする | |||
アクション | Hot/Warmティア | Coldティア | Frozedティア |
スナップショットからインデックスを復元する | 72.4分 | - | - |
スナップショットからインデックスをマウントする | - | 115秒 | 47秒 |
プレウォーミング(Coldティアでデータが完全に利用可能になるまでの時間) | - | 82.8分 | - |
ペタバイトへのスケール
ここまでは、各ティアのパフォーマンスを比較することに重点をおいてベンチマークを測定しました。しかし、まだFrozenティアが持つ能力の全容をはっきりと示せていません。Frozenティアは、他のティアより演算処理対ストレージ比が高いという特徴があります。そこで極端なシナリオとして、同じデータセットを250回以上、それぞれ別の名前でマウントし、個別のインデックスとして扱われるように準備しました。使用するシングルノードのクラスターには各80GBのシャードが12,500個でき、これはきっかり1PB(ペタバイト)のデータに相当します。この1PB(=100万GB)のデータセットでシンプルな用語のクエリを実行すると、結果が返されるまでの時間は10分未満でした。これは、大規模なデータセットにもFrozenティアの実装がうまくスケールすることを示しています。
1PBのデータセットでシンプルな用語のクエリを実行する | |||
アクション | Hot/Warmティア | Coldティア | Frozedティア |
シンプルな用語のクエリの初回実行 | 実行不能(1PBのローカルストレージが必要となるため) | 554秒 | |
シンプルな用語のクエリの反復実行(4TBのオンディスクLFUキャッシュを使用) | 127秒 | ||
現実には、単一のノードにこれほど多数のシャードを持たせ、またオブジェクトストレージサイズに対するローカルディスクキャッシュを極端に低い割合にするやり方は、理想的なセットアップではありません。Frozenティアノードでこの規模になると、データセットのストレージコストからみた演算処理コストのバランスも悪くなるため、いくつかノードを追加することで、ほとんどコストを増やさずにパフォーマンスを劇的に改善することができます。
オンディスクLFUキャッシュのサイズ指定
すでに確認したように、反復検索で優れたパフォーマンスを達成する上で、オンディスクLFUキャッシュのサイズ指定が重要な役割を果たします。適切なサイズは、実行するクエリの種類、とりわけ、クエリの結果を返すためにアクセスする必要のあるデータ量に大きく依存します。したがって、大量のデータをマウントするときに、必ず大きなオンディスクキャッシュが必要になるわけではありません。たとえば時間範囲フィルターを適用するとき、時系列インデックスのコンテクストに適用することで、クエリに必要なシャードの数は減少します。多くの場合、データアクセスのパターンにはなんらかの潜在的な空間的局所性、または時間的局所性があるため、Frozenティアは非常に大きなデータセットに対しても効率的にクエリを実行することができます。現時点における知見から、ElasticはオンディスクLFUキャッシュのサイズをマウントするデータセットのサイズに応じて、1%から10%の範囲で指定することを推奨しています。様々なサイズを試す場合、5%からはじめると良いでしょう。
演算処理を並列に実行するFrozenティアは、垂直方向と水平方向のスケールのいずれもサポートする点に留意してください。パフォーマンスの高いマシンタイプを使用したり、あるいはクラスターにノードを追加するだけで、簡単にFrozenティアの検索パフォーマンスを向上させることができます。
まとめ
この記事では、Frozenティアが2つのパターンのクエリを優れたパフォーマンスで実行できることを実証しました。“デフォルトでインデックスする”戦略を用いるElasticsearchを利用する場合、Frozenティアのパフォーマンスは、データセットを完全にスキャンするアプローチに比べて何倍も高速になります。Frozenティアの反復検索ではオンディスクキャッシュの強みが一層発揮され、他のティアとほぼ同等のパフォーマンスを達成します。
コスト効率に優れたストレージとフレキシブルな演算処理対ストレージ比とを組み合わせることが主目的となるケースで、Frozenティアは大きな価値を生み出します。Frozenティアのデータには他の通常のインデックスのデータと同じようにアクセスでき、既存の設定をほんの少し変えるだけでこのエキサイティングな新機能を活用できます。立ち上げも難しくありません。バックアップに使用している既存のスナップショットレポジトリを再利用する仕組みであり、またHot/Warm/Coldティアからのデータ移行はインデックスライフサイクル管理を利用して実施できます。Frozenティアはインデックスライフサイクル管理に完全統合されています。Kibanaの非同期検索統合を組み合わせて、Frozenティアの性能をさらに活用する手もあります。非同期検索を使うと実行に時間がかかるダッシュボードがバックグラウンドで処理され、処理の完了後に可視化が表示されます。
FrozenティアはセルフマネージドのデプロイとElastic Cloudのどちらでもご利用可能です。ぜひドキュメントを確認してお試しください。皆様からのフィードバックもお待ちしています。