Elasticsearch、Kibana、およびBeatsでKafkaを監視
FilebeatでKafkaを監視することに関するブログを初めて投稿したのは、2016年でした。6.5リリース以降、BeatsチームはKafkaモジュールをサポートしています。このモジュールは、Kafkaクラスターの監視に関する多くの作業を自動化します。
このブログでは、FilebeatおよびMetricbeatのKafkaモジュールでログおよびメトリックデータを収集することについて取り上げます。それらのデータをElasticsearch Serviceでホストされたクラスターに投入し、 Beatsモジュールによって提供されるKibanaダッシュボードで確認します。
このブログではElastic Stack 7.1を使用します。環境の例についてはGitHubで提供されています。
モジュールを使用する理由
Filebeatモジュールを使用すると、ログ収集のセットアップが簡素化されます。複雑なLogstash Grokフィルターで作業したことがある人なら誰でも、そのシンプルさに感謝するはずです。それ以外にも、監視の構成においてモジュールを活用することには利点があります。
- ログおよびメトリック収集の構成の簡素化
- Elastic Common Schemaによるドキュメントの標準化
- 最適なフィールドデータタイプを提供する実用的なインデックステンプレート
- 適切なインデックスサイズ。BeatsはロールオーバーAPIを使用することで、Beatsインデックスに関して健全なシャードサイズを維持できるようにします。
FilebeatおよびMetricbeatがサポートするモジュールの全一覧についてはドキュメントを参照してください。
環境の導入
ここでのセットアップ例は、3つのノードのKafkaクラスター(kafka0、kafka1、およびkafka2)で構成されています。それぞれのノードはKafka 2.1.1、およびFilebeatとMetricbeatを実行してノードを監視します。BeatsはクラウドIDを通じて構成されており、データをElasticsearch Serviceクラスターに送信します。FilebeatおよびMetricbeatに同梱されているKafkaモジュールは、ビジュアライゼーションのためにKibana内でダッシュボードをセットアップします。ちなみに、自身のクラスターでこれを試す場合は、すべての機能が備わったElasticsearch Serviceの14日間無料トライアルを使用できます。
Beatsのセットアップ
次に、Beatsを構成し、実行します。
Beatsサービスのインストールと有効化
入門ガイドに従って、FilebeatとMetricbeatの両方をインストールします。Ubuntu上で実行するため、APTリポジトリを使用してBeatsをインストールします。
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list sudo apt-get update sudo apt-get install filebeat metricbeat systemctl enable filebeat.service systemctl enable metricbeat.service
Elasticsearch ServiceデプロイのクラウドIDの構成
Elastic CloudコンソールからクラウドIDをコピーし、FilebeatとMetricbeatの出力の構成に使用します。
CLOUD_ID=Kafka_Monitoring:ZXVyb3BlLXdlc...
CLOUD_AUTH=elastic:password
filebeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/filebeat/filebeat.yml
metricbeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/metricbeat/metricbeat.yml
FilebeatとMetricbeatでKafkaおよびシステムモジュールを有効化
次に、両方のBeatsでKafkaおよびシステムモジュールを有効化する必要があります。
filebeat modules enable kafka system metricbeat modules enable kafka system
有効化すると、Beatsセットアップを実行することができます。これにより、モジュールで使用するインデックステンプレートとKibanaダッシュボードが構成されます。
filebeat setup -e --modules kafka,system metricbeat setup -e --modules kafka,system
Beatsを開始
すべてが構成されました。FilebeatとMetricbeatの実行を開始しましょう。
systemctl start metricbeat.service systemctl start filebeat.service
監視データの確認
デフォルトのロギングダッシュボードには以下が表示されます。
- Kafkaクラスターで見られた最近の例外。例外は、例外クラスと例外の完全な詳細によってグループ化されます
- レベルごとのログスループットの概要と、ログの完全な詳細
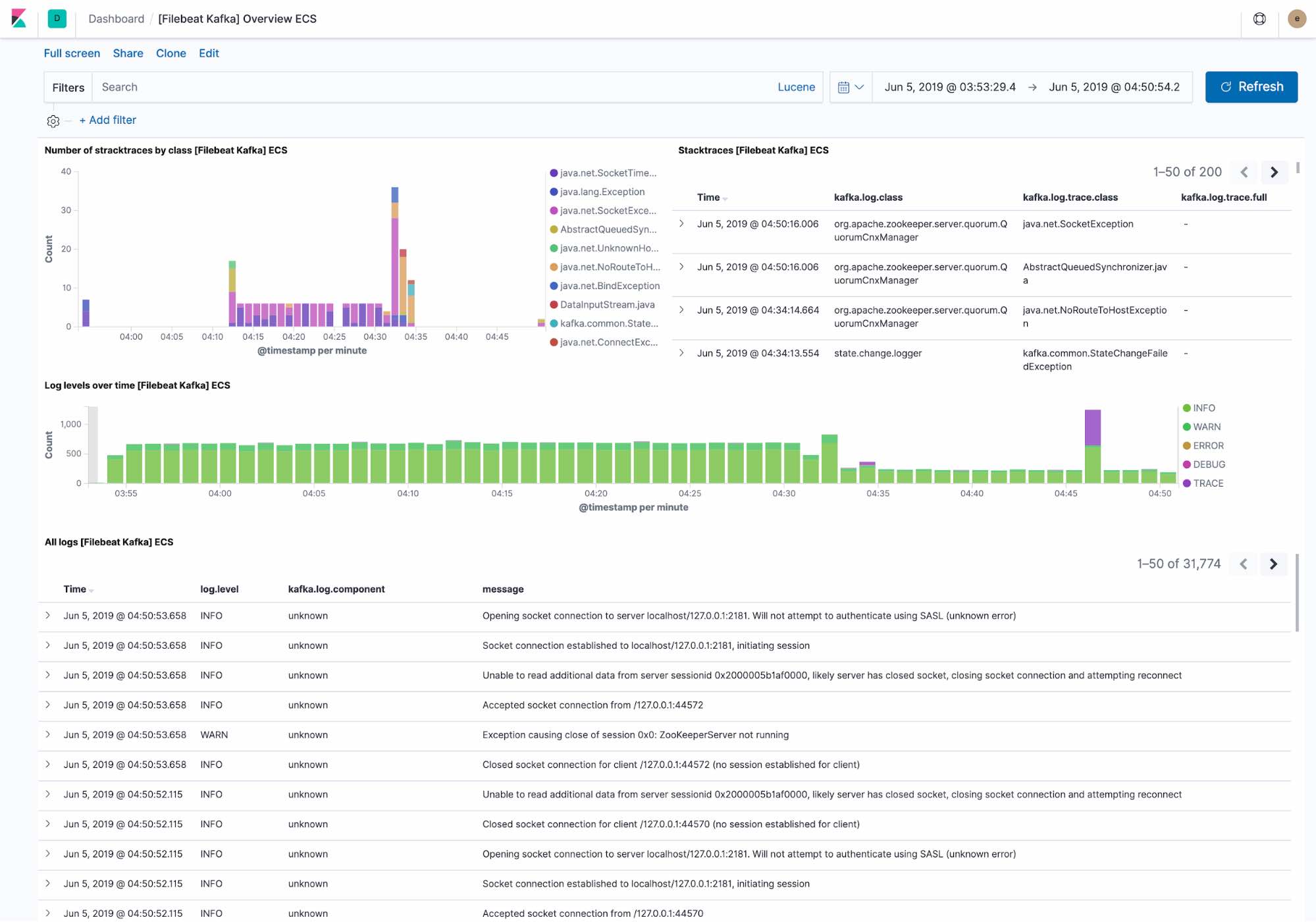
FilebeatはElastic Common Schemaに従ってデータを投入します。データはホストレベルまでフィルターすることができます。
Metricbeatのデータを基にしたダッシュボードには、Kafkaクラスター内における任意のトピックの現在の状態が表示されます。また、ダッシュボードを単一のトピックにフィルターするドロップダウンもあります。
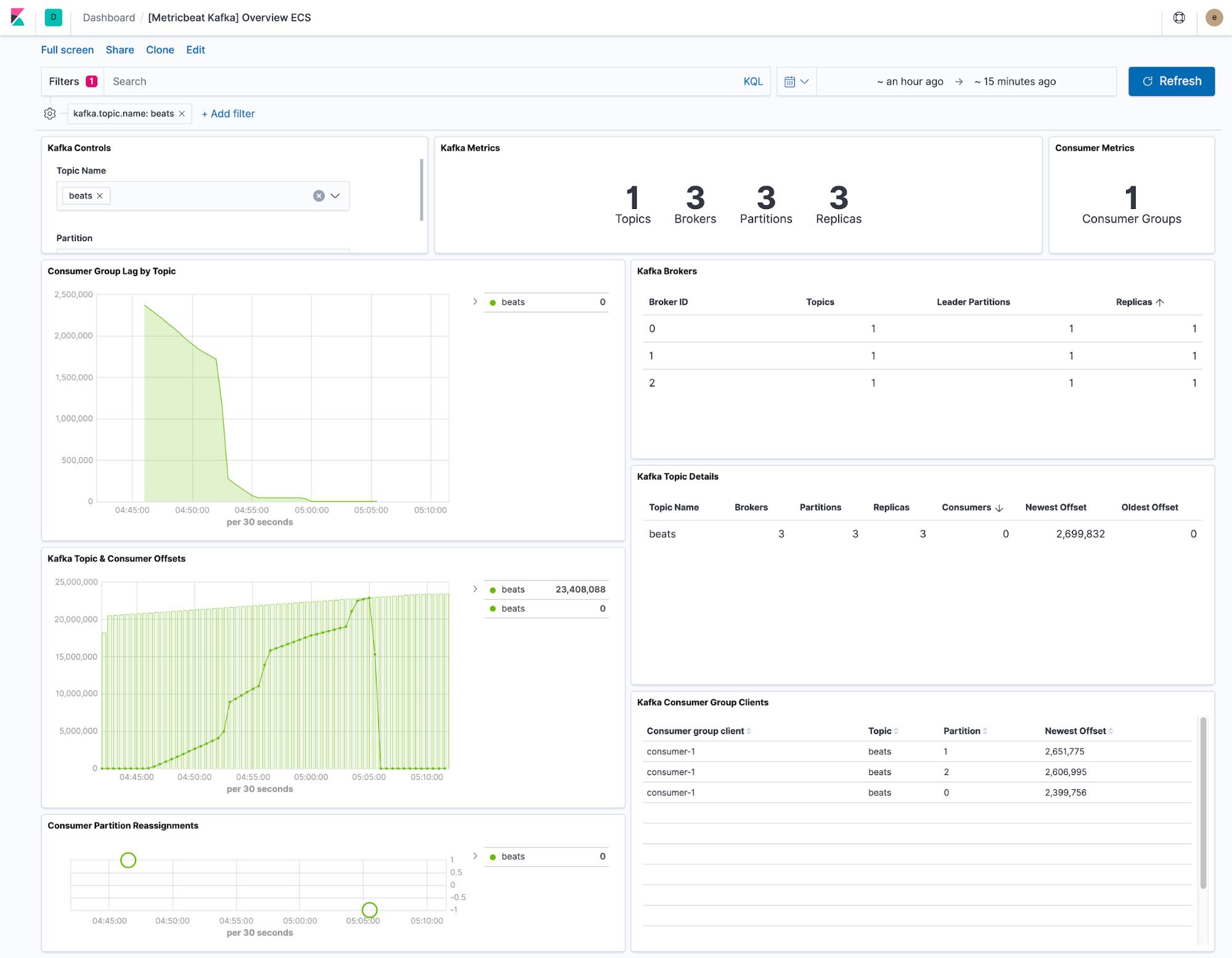
コンシューマーのラグとオフセットのビジュアライゼーションは、特定のトピックに関してコンシューマーに遅延が発生しているかどうかを示します。パーティションごとのオフセットは、単一のパーティションに遅延が発生しているかどうかを示します。
デフォルトのMetricbeat構成では、2つのデータセット(kafka.partitionおよびkafka.consumergroup)が収集されます。これらのデータセットは、Kafkaクラスターとそのコンシューマーの状態に関するインサイトを提供します。
kafka.partitionデータセットには、クラスター内のパーティションの状態に関する完全な詳細が含まれます。このデータは次のために使用することができます。
- パーティションがどのようにクラスターノードにマッピングされているかを示すダッシュボードの構築
- 同期レプリカのないパーティションに関するアラート
- パーティション割り当ての経時的な追跡
- パーティションのオフセット制限の経時的な視覚化
以下が完全なkafka.partitionのドキュメントです。

kafka.consumergroupデータセットは、単一のコンシューマーの状態を捕捉します。このデータは、単一のコンシューマーがどのパーティションを読み取っているかを示すことや、そのコンシューマーの現在のオフセットを示すために使用できます。
