ElasticオブザーバビリティでNVIDIAのGPUメトリックを監視する
グラフィックスプロセッシングユニット、すなわちGPUの用途は、PCゲームに限定されません。GPUは現在ニューラルネットワークの教育や数値流体力学のシミュレーション、ビットコインのマイニング、データセンターのプロセスワークロードにも使用されています。さらにGPUはハイパフォーマンスコンピューティングシステムの心臓部であり、データセンターにおけるGPUパフォーマンスの監視は、CPUパフォーマンスの監視と並ぶ重要タスクとなっています。
このような状況をふまえ、本記事ではElasticオブザーバビリティとNVIDIAのGPU監視ツールを組み合わせ、GPUパフォーマンスを観測、最適化する方法を解説します。
依存性
NVIDIA GPUのメトリックを取得し、活用するには、ソースコード(Go)からNVIDIA GPU監視ツールをビルドする必要があります。もちろん、NVIDIA GPU自体も必要です。AMDや他の各種のGPUタイプは異なるLinuxドライバーや監視ツールを使用しており、これらの監視方法については別の記事で取り上げる予定です。
NVIDIAのGPUはGoogle CloudやAmazon Web Services(AWS)など、多数のクラウドプロバイダーで提供されています。本記事では、Genesis Cloudで実行するインスタンスを使用します。
はじめに、NVIDIAのDCGM Getting Started GuideでUbuntu 18.04向けのインストールのセクションを参照し、NVIDIA Datacenter Managerをインストールします。注:記述に沿って手順を進めるにあたり、<architecture>パラメーターを独自の値に変更する点に特に注意してください。アーキテクチャーは、unameコマンドを使って見つけることができます。
uname -a
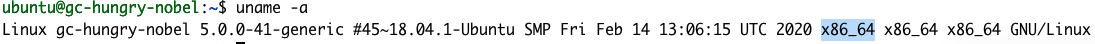
このレスポンスでは、アーキテクチャーがX86_64だとわかります。したがって、Getting Started Guideの「step 1」は次のようになります。
echo "deb http://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list
「step 2」には誤字があります。$distributionの末尾にある>を削除して進めてください。
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/7fa2af80.pub
インストールが完了すると、nvidia-smiコマンドを実行してGPUの詳細情報を確認できるようになっているはずです。
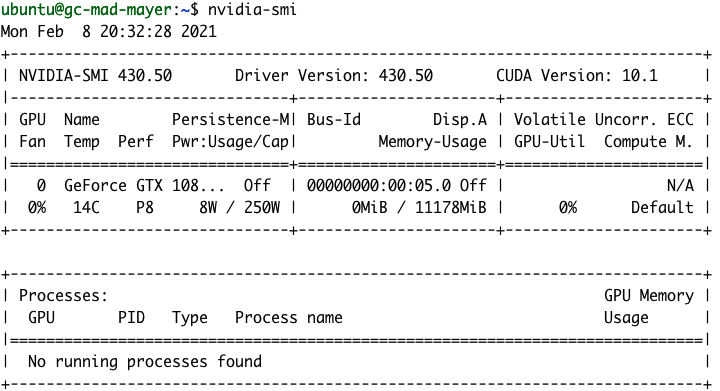
NVIDIA gpu-monitoring-tools
NVIDIAのgpu-monitoring-tools(GPU監視ツール)を構築するには、Golangのインストールが必要です。早速開始しましょう。
cd /tmp wget https://golang.org/dl/go1.15.7.linux-amd64.tar.gz sudo mv go1.15.7.linux-amd64.tar.gz /usr/local/ cd /usr/local/ sudo tar -zxf go1.15.7.linux-amd64.tar.gz sudo rm go1.15.7.linux-amd64.tar.gz
次に、GitHubにあるNVIDIAのgpu-monitoring-toolsをインストールすればNVIDIAのセットアップは完了です。
cd /tmp git clone https://github.com/NVIDIA/gpu-monitoring-tools.git cd gpu-monitoring-tools/ sudo env "PATH=$PATH:/usr/local/go/bin" make install
Metricbeat
いよいよ、Metricbeatをインストールします。Metricbeatの最新のバージョン番号はelastic.coで簡単に確認できます。次のコマンド中のバージョン番号は、適宜調整してお使いください。
cd /tmp wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.10.2-amd64.deb sudo dpkg -i metricbeat-7.10.2-amd64.deb # 7.10.2 is the version number
Elastic Cloud
次に、Elastic Stackを立ち上げて実行します。新規にGPU監視データを収集するための保存先を用意しましょう。Elastic Cloudに新規のデプロイを作成します。現在Elastic Cloudをご利用でない場合も、14日間の無料トライアルに登録してお使いいただくことができます。または、ローカルに独自のデプロイを立ち上げることも可能です。
本記事では、Elastic Cloudに新規のElasticオブザーバビリティデプロイを作成します。
クラウドのデプロイが立ち上がったら、Cloud IDと認証情報をお手元に控えておいてください。この情報は後ほど、Metricbeatの設定に使用します。
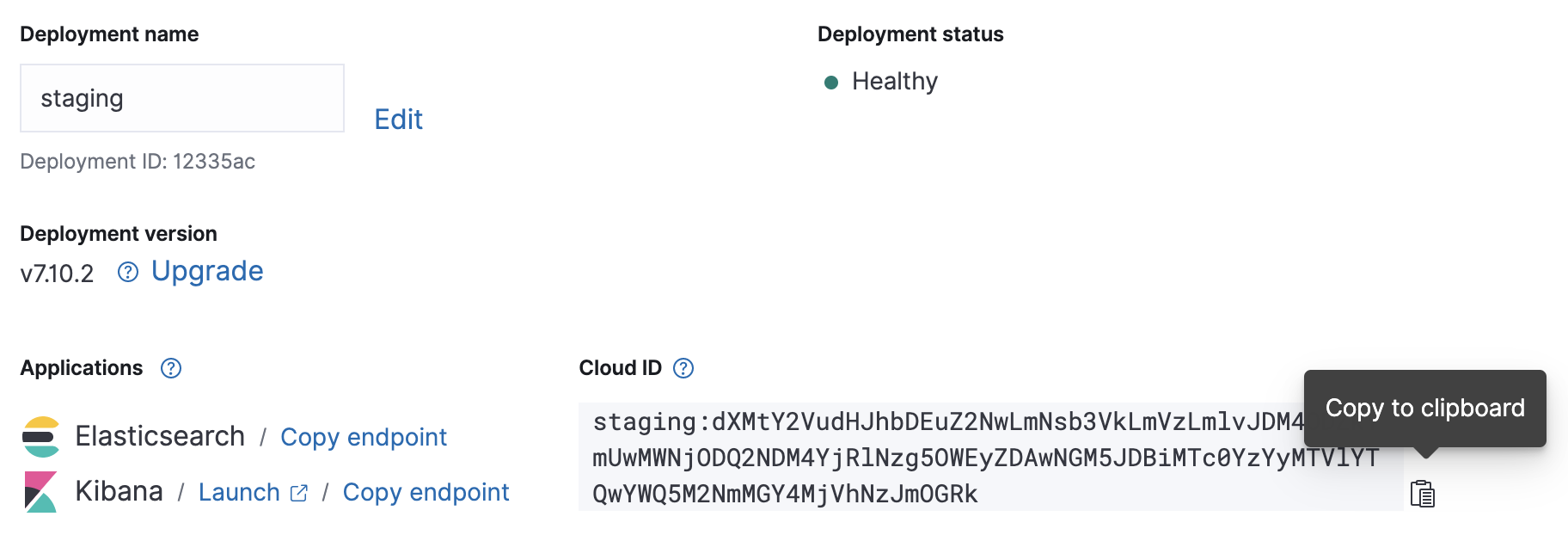
設定
Metricbeatの設定ファイルは/etc/metricbeat/metricbeat.ymlにあります。このファイルをお好みのエディターで開き、cloud.idパラメーターとcloud.authパラメーターが、ご自身のデプロイの値と一致するように編集します。
先ほどのスクリーンショットの情報を使ってMetricbeatの設定変更を実施すると、次のようになります。
cloud.id: "staging:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmVzLmlvJDM4ODZkYmUwMWNjODQ2NDM4YjRlNzg5OWEyZDAwNGM5JDBiMTc0YzYyMTVlYTQwYWQ5M2NmMGY4MjVhNzJmOGRk" cloud.auth: "elastic:J7KYiDku2wP7DFr62zV4zL4y"
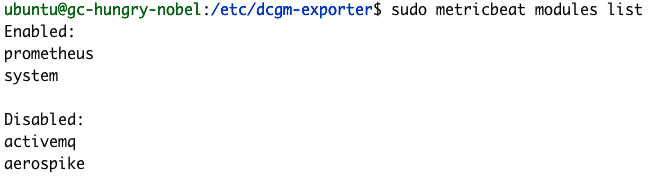
Metricbeatのインプットconfigはモジュール式です。NVIDIAのgpu-monitoring-toolsはPrometheus経由でGPUメトリックをパブリッシュするので、次のコマンドを使い、Prometheus Metricbeatモジュールを有効化します。
sudo metricbeat modules enable prometheus
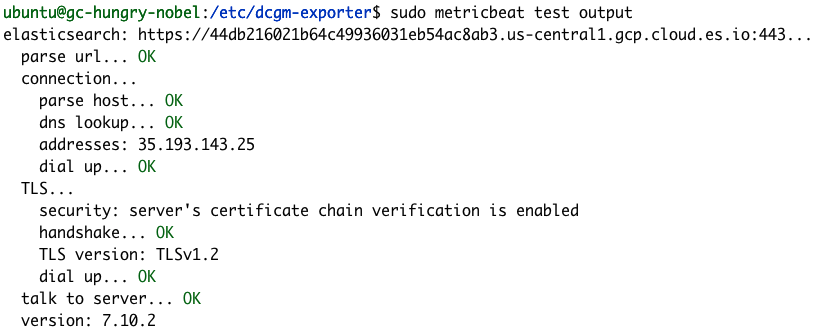
Metricbeatのテストコマンドとモジュールコマンドを使用すると、Metricbeatの設定が正しく行われていることを確認できます。
sudo metricbeat test config

sudo metricbeat test output
sudo metricbeat modules list
上の例のように、設定テストが上手くいかない場合は、ElasticのMetricbeat troubleshooting guide(Metricbeatトラブルシューティングガイド)をご参照ください。
セットアップコマンドを実行してMetricbeatの設定を完了すると、デフォルトのダッシュボードが読み込まれ、インデックスマッピングがセットアップされます。このセットアップコマンドの実行完了には、通常数分程度かかります。
sudo metricbeat setup

メトリックをエクスポートする
それでは、メトリックをエクスポートしましょう。まずNVIDIAのdcgm-exporterを起動します。
dcgm-exporter --address localhost:9090 # アウトプット INFO[0000] Starting dcgm-exporter INFO[0000] DCGM successfully initialized! INFO[0000] Not collecting DCP metrics:Error getting supported metrics:This request is serviced by a module of DCGM that is not currently loaded INFO[0000] Pipeline starting INFO[0000] Starting webserver
注:このDCP警告は無視して構いません。
dcgm-exporterメトリック設定の定義は/etc/dcgm-exporter/default-counters.csvファイルにあり、デフォルトで38の異なるメトリックが定義されています。可能な値の完全なリストは、DCGM Library API Reference Guideをご覧ください。
別のコンソールを開き、Metricbeatを起動しましょう。
sudo metricbeat -e
ここでKibanaインスタンスを開き、「metricbeat-*」インデックスパターンを更新します。この操作は、[Stack Management](スタック管理) > [Kibana] > [Index Patterns](インデックスパターン)に進み、リストで[metricbeat-*]インデックスパターンを選択することで実行できます。次に、[Refresh field list](フィールドリストを更新)をクリックします。
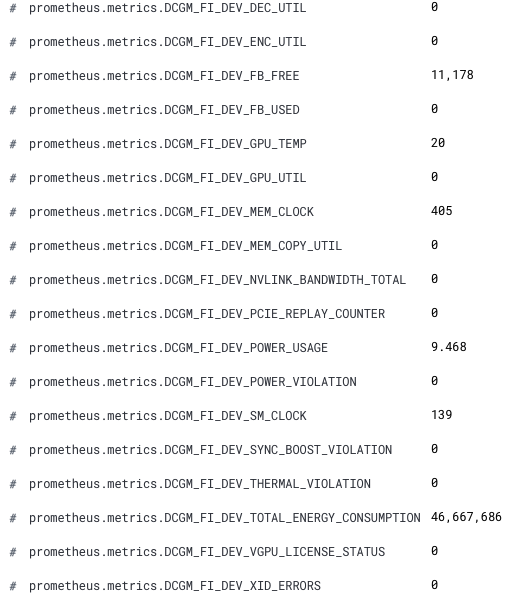
これでKibanaでGPUメトリックを確認できるようになりました。新しいフィールド名は、先頭にprometheus.metrics.DCGM_がつきます。下のスクリーンショットは、[Discover]の新しいフィールドを示しています。
お疲れさまでした!これでElasticオブザーバビリティでGPUメトリックを分析する準備が整いました。
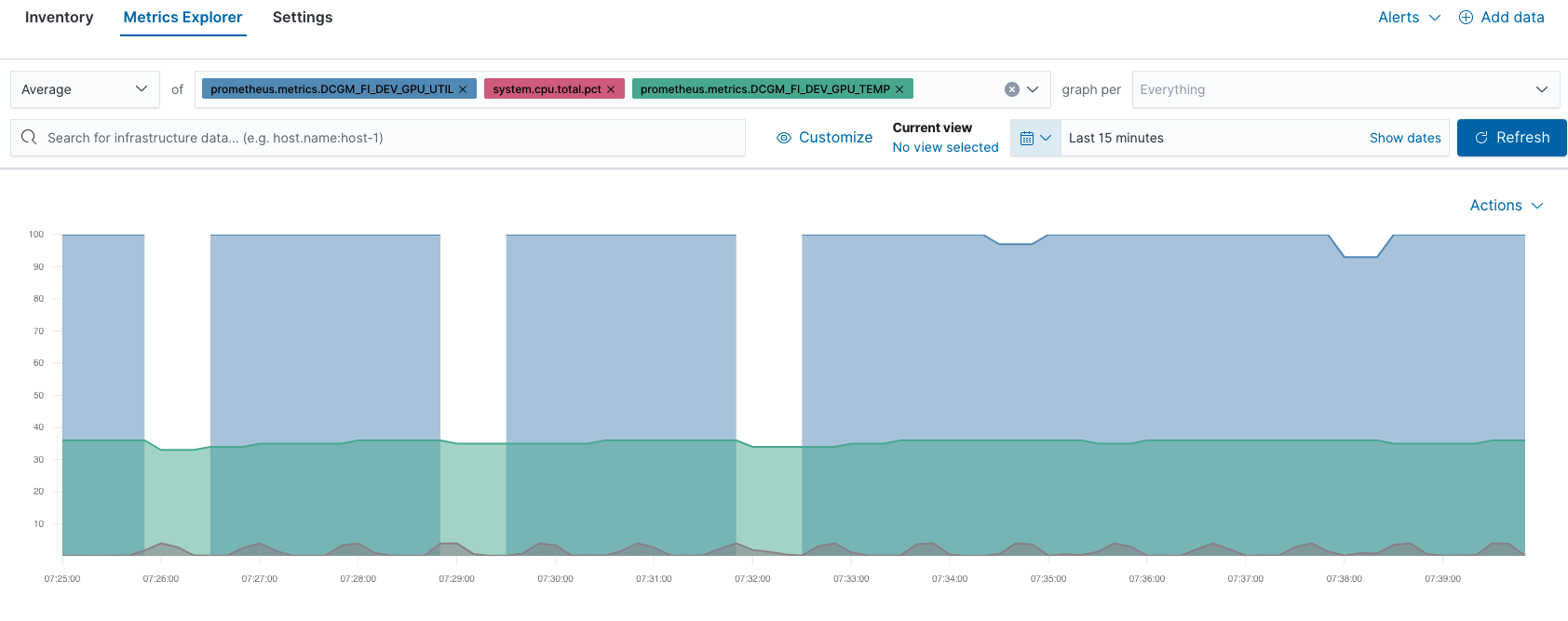
たとえば、Metrics ExplorerでGPUとCPUのパフォーマンスを比較することもできます。
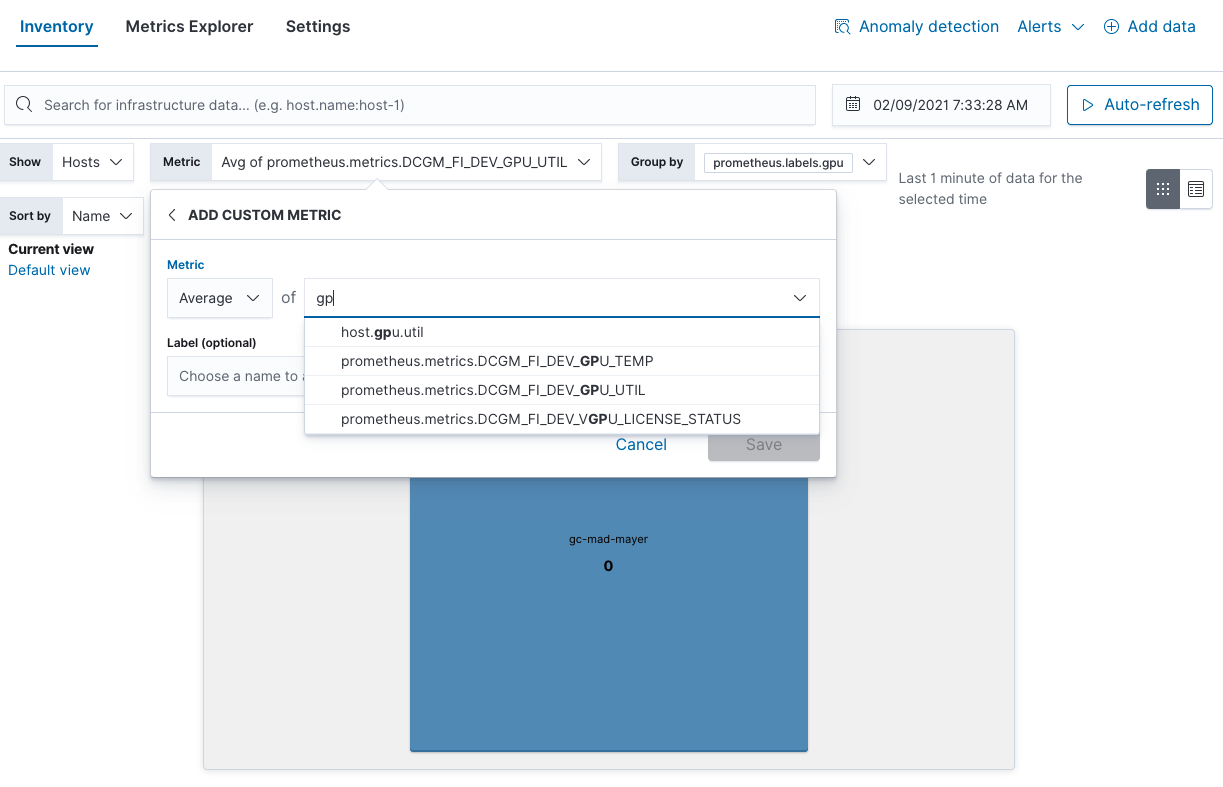
また、インベントリービューでGPU使用状況のホットスポットを見つけることもできます。
GPU監視のヒントと補足
本記事が少しでもお役に立てば幸いです。今回はわずかな監視オプションしかご紹介していませんが、Elasticオブザーバビリティはあらゆる目的に使うことができます。NVIDIAのGPU監視に役立つ指標の例には、次のようなものもあります。
- GPUの温度:ホットスポットの確認
- GPUの電気使用量:電気使用量が期待値を超える場合⇒ハードウェアの問題が疑われる
- 現在のクロック周波数:期待値を下回る場合⇒パワーキャッピング(電力制限)またはハードウェアの問題
またGPUの負荷のシミュレーションは、dcgmproftester10コマンドを使用して実施できます。
dcgmproftester10 --no-dcgm-validation -t 1004 -d 30
あるいはElasticアラートを使って詳細な監視を実践し、NVIDIAの推奨内容を自動化することも可能です。さらに機械学習使ったGPUインフラの異常検知を実装し、高度な監視を実践することもできます。現在Elastic Cloudをご利用でない方も、本記事でご紹介した手順をお試しいただくことができます。14日間の無料トライアルに登録してご利用ください。