Elasticオブザーバビリティでコンテナー化したKafkaを監視する
Kafkaはベアメタル上のほか、仮想化、コンテナー化した環境で、またマネージドサービスとして実行できる、分散型の高可用イベントストリーミングプラットフォームです。本来KafkaはPub/Sub(出版-購読型モデル)システムの1種であり、イベントを分配する“ブローカー”として動作します。具体的には、メッセージ送信者(出版側)がイベントを“トピック”に投稿し、メッセージ受信者(購読側)が“トピック”を受け取ります。新規のイベントがトピックに送信されると、そのトピックを購読、つまりサブスクライブするメッセージの受信者に新規のイベント通知が届きます。このモデルで、メッセージ送信者は複数のクライアントにアクティビティを通知することができますが、パブリッシュするイベントを誰が購読しているか把握する必要はありません。たとえば新規の注文が来て、Webストアが注文の詳細情報を含むイベントをパブリッシュするとします。このイベントは、受注処理の部署で受信されて棚からどの商品を出すかを知らせたり、発送処理の部署で宛先の印刷情報を伝えたり、その他の関係者のアクションに活用したりすることができます。どの受信者に新規メッセージを取得させるかは、受信者のグループやパーティションの設定で制御できます。
一般的に、KafkaはZooKeeperとともにデプロイされ、トピックやパーティション、複製/冗長性の情報といった設定情報がZooKeeperに格納されます。Kafkaのクラスターを監視するにあたっては、その監視と同様、関連するZooKeeperインスタンスを監視することが重要です。ZooKeeperに問題が生じると、Kafkaのクラスターにも問題が波及するためです。
KafkaをElastic Stackと組み合わせて使う方法は多数あります。MetricbeatやFilebeatを設定してデータをKafkaのトピックに送ることも、KafkaからLogstashにデータを送ることも、LogstashからKafkaに送ることも、あるいはElasticを使ってKafkaとZooKeeperを監視し、クラスターを常時把握することも可能です。本ブログ記事では、この監視の手法についてご紹介します。先ほど、注文の詳細を含むイベントの例を挙げました。このようなイベントは、LogstashとKafkaインプットプラグインを組み合わせてサブスクライブし、データをElasticsearchクラスターに入れることも可能です。ビジネスデータ、あるいは環境内で起きていることを真に理解するために必要なデータを追加することにより、組織のシステムのオブザーバビリティを高めることができます。
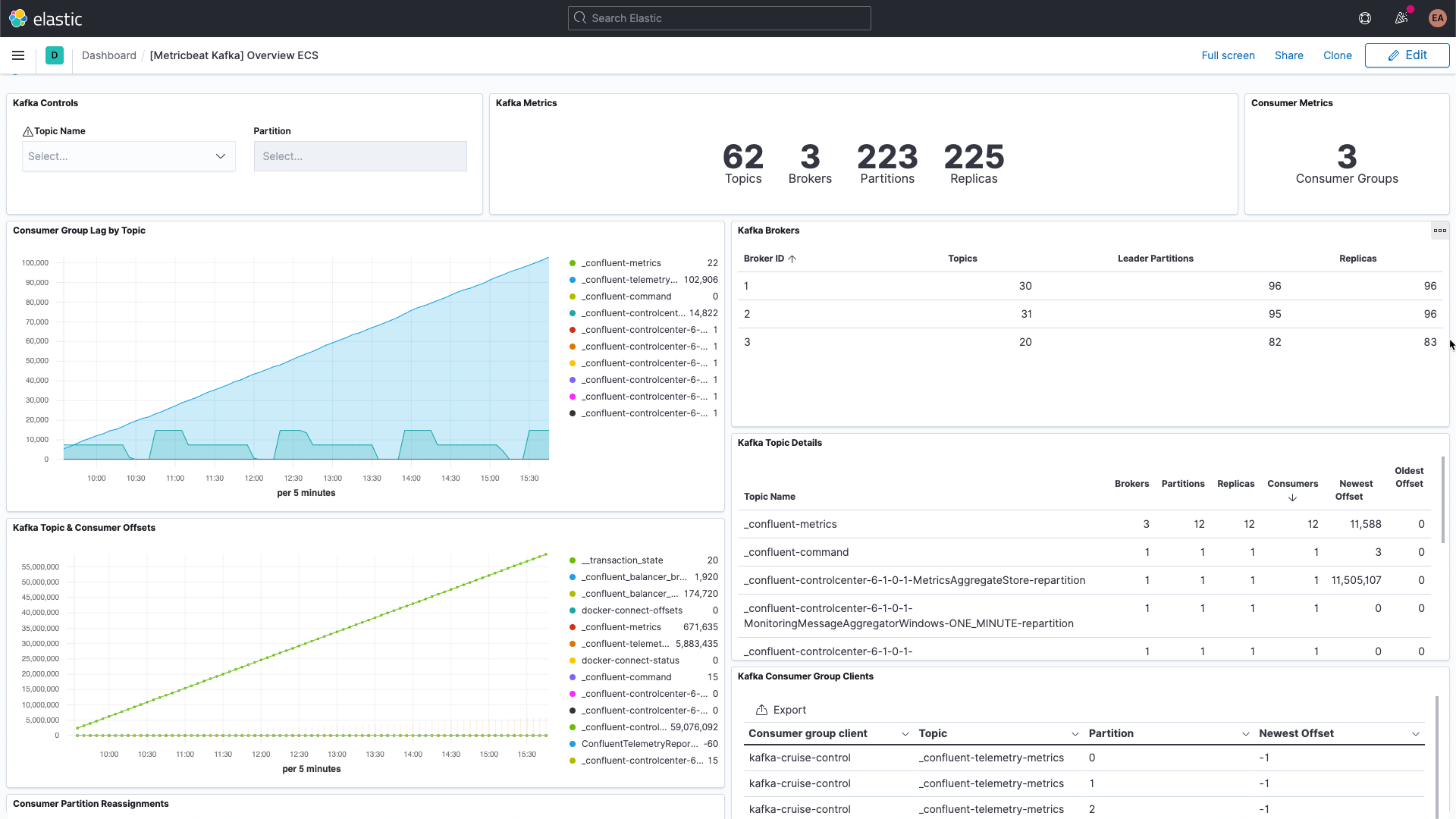
Kafkaの監視に際して注目すべきポイント
Kafkaはいくつかの可動部品で成立します。通常は複数のブローカーとZookeeperインスタンスで構成されるKafkaのサービスがあり、それと別にKafkaを使うクライアントであるプロデューサー、コンシューマーが存在します。Kafkaが送信するメトリックには複数の種類があり、ブローカー自体から送信されるものもありますが、JMX経由で送信されるものもあります。ブローカーは、パーティションとコンシューマーグループ向けのメトリックを送信します。パーティションは複数のブローカーにわたってメッセージを分割し、並列で処理できるようにします。コンシューマーは単一のトピックパーティションからメッセージを受信しますが、複数のコンシューマーをグループ化して、1つのトピックからくるすべてのメッセージを受信させることができます。このようなコンシューマーグループを活用すると、複数の作業者に負荷を分散させることができます。
各Kafkaメッセージには、オフセットが含まれています。オフセットとは基本的に、メッセージシーケンス中でそのメッセージの位置を示す識別子です。プロデューサーがトピックにメッセージを追加するたび、新しいオフセットがメッセージに付与されます。あるパーティション内で最新のオフセットが、最新のIDを示します。コンシューマーはトピックからメッセージを受信しますが、最新のオフセットとコンシューマーが受信したオフセットとの差分をコンシューマーラグと呼びます。コンシューマーがメッセージを受信するタイミングは、プロデューサーが送信するタイミングより常に少し遅れています。ここで気を付けたいのが、コンシューマーラグが悪化し続ける場合です。これは、負荷を処理するコンシューマーの追加を視野に入れるべき、という意味になります。
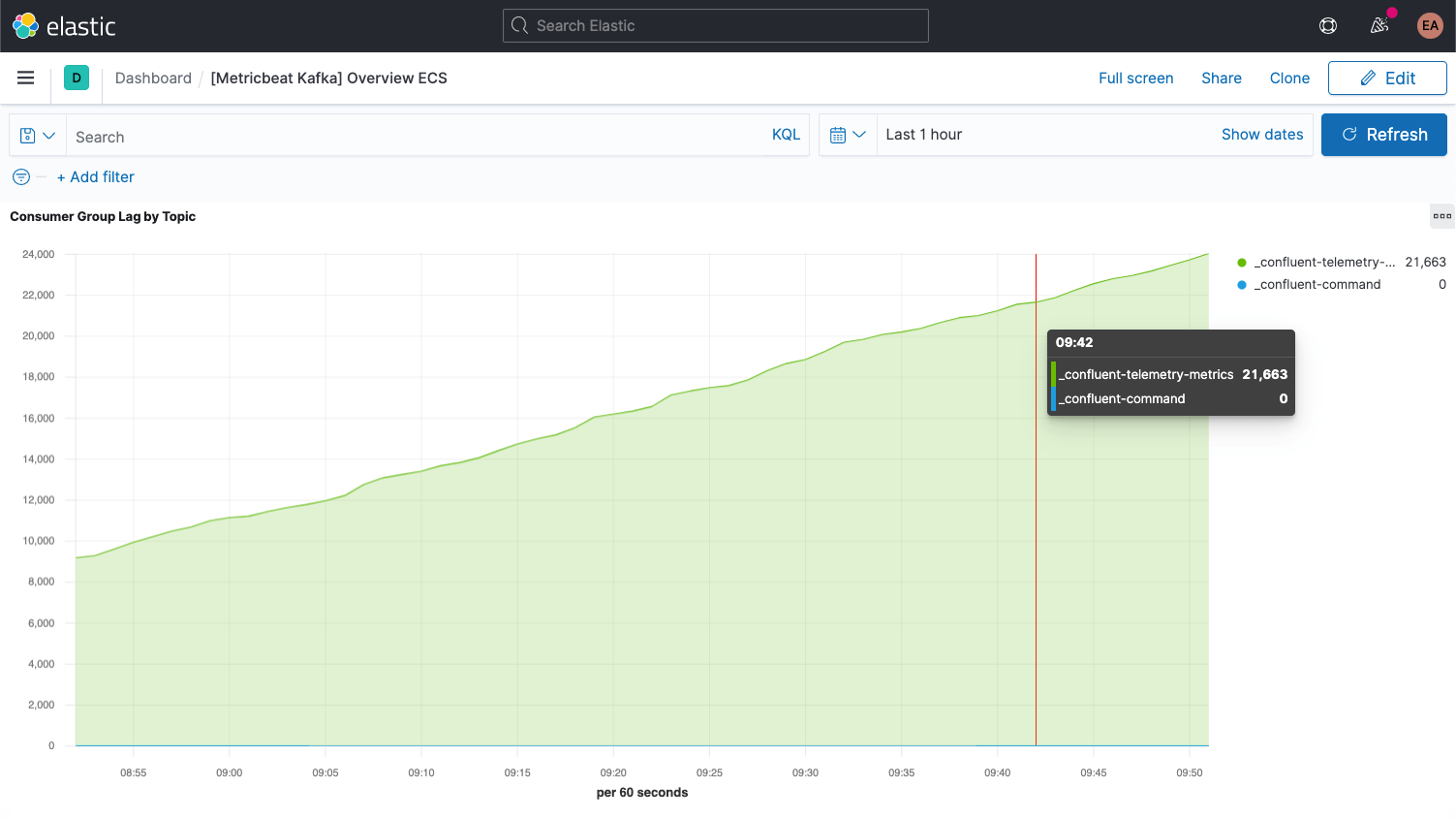
トピック自体のメトリックを確認する際は、コンシューマーが1つもないトピックに注目することが大切です。これは、実行されるべきものが存在しないことを意味します。
ブローカー向けのその他の主要なメトリックについては、セットアップ手順の後に説明します。
KafkaとZookeeperをセットアップする
この記事ではセットアップ例として、Confluent Platformベースでコンテナー化したKafkaクラスターを実行し、3つのKafkaブローカー(CPサーバーイメージ)とZookeeperインスタンス1つを組み合わせます。実際のセットアップではおそらく、Zookeeperにも堅牢で高可用な構成が必要となりますのでご注意ください。
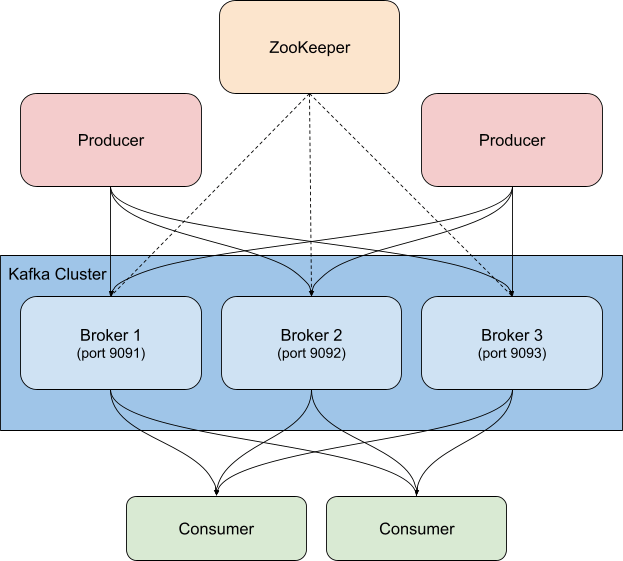
このセットアップをコピーして、cp-all-in-oneディレクトリに切り替えました。
git clone https://github.com/confluentinc/cp-all-in-one.git cd cp-all-in-one
本記事の手順はすべて、このcp-all-in-oneディレクトリで完了します。
また、ご紹介のセットアップではポートに変更を加えて、どのポートがどのブローカーに接続するかわかりやすいようにしています(各ポートがホストにエクスポーズされているため、別のポートが必要となります)。たとえば、broker3はポート9093に接続しています。また一貫性のために、1番目のブローカー名をbroker1に変更しています。インストルメンテーションの前に、オフィシャルレポジトリのGitHubフォークで筆者が公開している完全なファイルを確認していただくことも可能です。
ポートを再調整した後、broker1の設定は次のようになります。
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID:1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP:PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS:PLAINTEXT://broker1:29092,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR:1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS:0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR:1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR:1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR:1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR:1
KAFKA_JMX_PORT:9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS:1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
ご覧の通り、ホスト名の出現箇所もbrokerからbroker1に変更しています。もちろんbrokerを参照するdocker-compose.ymlに略述されたその他の設定も変更されることになり、たとえばクラスターの3つすべてのノードに反映されます。またConfluent control centerも、3つのブローカーすべての依存する形に変更されています。
control-center:
image: confluentinc/cp-enterprise-control-center:6.1.0
hostname: control-center
container_name: control-center
depends_on:
- broker1
- broker2
- broker3
- schema-registry
- connect
- ksqldb-server
(...)
ログとメトリックを収集する
このセットアップ例で、KafkaとZookeeperのサービスはコンテナー内にあり、開始時点では3つのブローカーとともに実行されます。スケールアップやスケールダウンを実施する、あるいはZookeeper側をより堅牢にする場合に、監視を再設定、あるいは再起動するアプローチは好ましくありません。動的に実行する方がいいからです。これを実現するために、今回の手順ではKafkaクラスターと並行してDockerコンテナーでも監視を実行することとし、またElastic Beatsのヒントベースの自動検知機能も活用します。
ヒントベースの自動検知
監視用に、KafkaブローカーとZookeeperインスタンスからログとメトリックを収集します。メトリックにはMetricbeatを、ログにはFilebeatを使用し、いずれもコンテナーで実行します。このプロセスを起動するには、Docker用のそれぞれの構成ファイル、metricbeat.docker.ymlとfilebeat.docker.ymlをダウンロードする必要があります。本記事の手順では、監視データをElastic CloudのElasticsearch Serviceに筆者のElasticオブザーバビリティデプロイに送信しています(ご興味がおありの方は、無料トライアルに登録して同じ設定をお試しください)。セルフマネージドのクラスターをお好みの場合は、Elastic Stackをダウンロードしてローカルで実行することもできます。本記事には、Elastic CloudとElastic Stackの両方のシナリオの手順を掲載しています。
Elastic Cloudのデプロイを使う場合でも、セルフマネージドのクラスターを実行する場合でも、クラスターを見つける方法を把握しておく必要があります。具体的には、KibanaやElasticsearchのURLと、クラスターへのログオンに使う資格情報が必要です。Kibanaエンドポイントではデフォルトのダッシュボードと設定情報を、ElasticsearchではBeatsによるデータの送信先を確認できます。Elastic Cloudをお使いの場合は、クラウドIDにエンドポイント情報が含まれています。
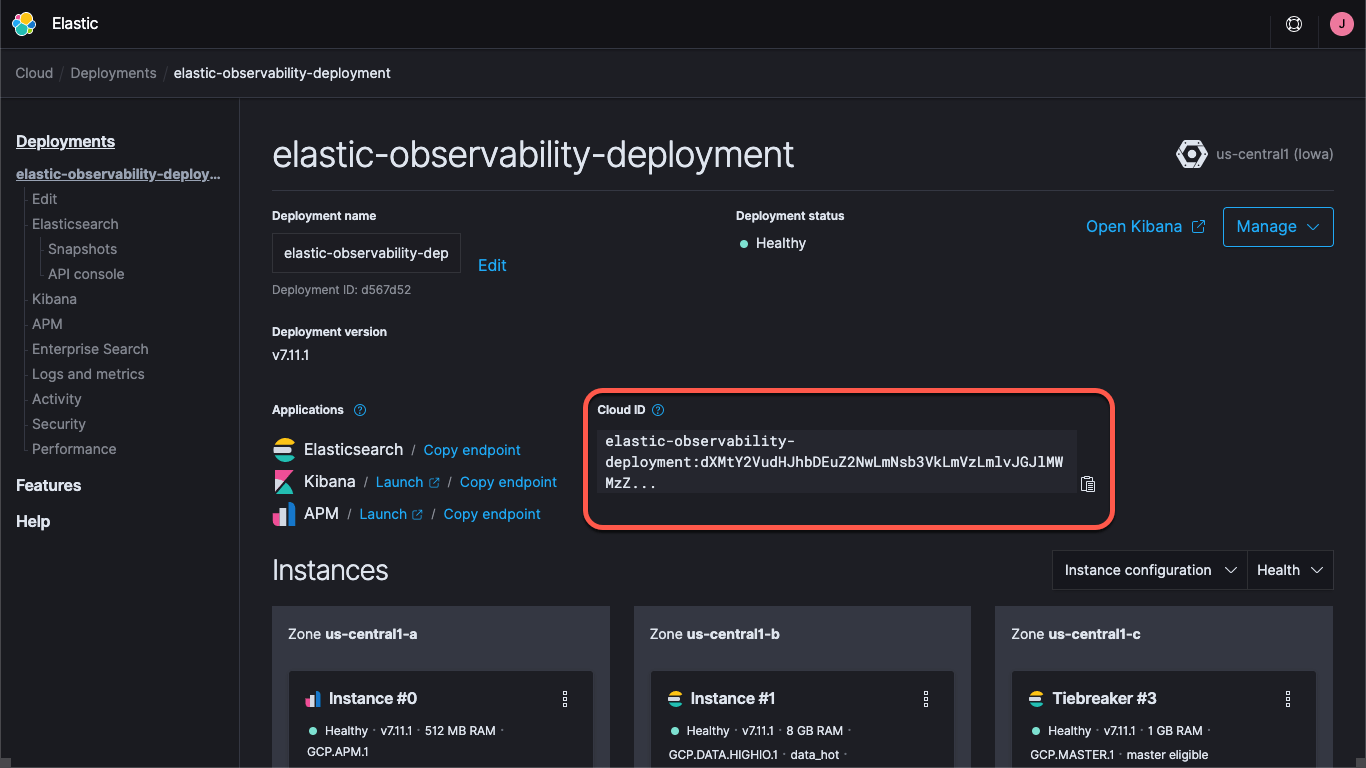
Elastic Cloudにデプロイを作成すると、elasticユーザー用のパスワードが発行されます。本記事の手順ではシンプル化のためにこれらの資格情報を使用しますが、ベストプラクティスは、APIキー、またはタスクに必要な最小の権限を持つユーザーとロールを作成するやり方です。
それではいよいよ、MetricbeatとFilebeatのデフォルトのダッシュボードを読み込んでみましょう。この手順は1回実行すれば十分で、各Beatでも似たような手順になります。Metricbeatのコラテラルを読み込むには、以下を実行します。
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
このコマンドでMetricbeatコンテナー(metricbeat-setupと呼ばれます)が作成されます。またダウンロードしておいたmetricbeat.docker.ymlファイルが読み込まれ、Kibanaインスタンス(cloud.idフィールドから取得)に接続します。その後setupコマンドを実行して、ダッシュボードを読み込みます。Elastic Cloudを使わない場合はこの手順に代えて、setup.kibana.hostとoutput.elasticsearch.hostsフィールドに個々の資格情報フィールドとともにKibanaとElasticsearchのURLを入力します。コマンドは以下のようになります。
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E setup.kibana.host=localhost:5601 \
-E setup.kibana.username=elastic \
-E setup.kibana.password=your-password \
-E output.elasticsearch.hosts=localhost:9200 \
-E output.elasticsearch.username=elastic \
-E output.elasticsearch.password=your-password \
-e -strict.perms=false \
setup
この -e -strict.perms=falseは、Dockerファイルのオーナーシップと権限に関して避けられない問題の軽減に役立ちます。
同様に、ログのコラテラルをセットアップするには、Filebeat向けに同様のコマンドを実行します。
docker run --rm \
--name=filebeat-setup \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
デフォルトで、これらの設定ファイルはコンテナーログとメトリックを収集し、一般的なコンテナーを監視するセットアップです。このままでもある程度便利ですが、今回はサービス固有のログとメトリックについても確実に捉えることを目的としています。そこで先ほど言及したように、MetricbeatとFilebeatのコンテナーを設定し、自動検知を使用します。この設定を実施する方法はいくつかあります。特定のイメージや名前を探すようBeatsをセットアップすることもできますが、それには事前に多くの情報を把握する必要があります。そこで今回は別の方法を採用します。ヒントベースの自動検知を使用し、コンテナーからBeatsに監視方法を指示するという方法です。
具体的には、ヒントベースの自動検知を使ってDockerコンテナーにlabels(ラベル)を追加します。他のコンテナーが起動した際、起動していないmetricbeatとfilebeatのコンテナーに通知が届き、これにより監視を開始することができます。そのためのセットアップとして、ブローカーのコンテナーがKafka Metricbeatモジュールと、Kafka Filebeatモジュールから監視を受けるように設定し、またMetricbeatがZookeeperモジュールを使ってメトリックを収集するように設定します。Filebeatは特別なパースを行わずにZookeeperのログを収集します。
Zookeeperの設定はKafkaより分かりやすいので、こちらの設定からはじめましょう。docker-compose.ymlファイル内で、Zookeeper用の初期設定は次のようになっています。
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT:2181
ZOOKEEPER_TICK_TIME:2000
ここでは以下のように、YAMLにlabelsのブロックを追加してモジュール、接続情報、メトリックセットを指定します。
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
このラベルはmetricbeatコンテナーに対し、zookeeperモジュールを使用してこのコンテナーを監視するよう指示します。また、metricbeatコンテナーがホスト/ポートzookeeper:2181を経由してこのコンテナーにアクセスできることを伝えています。zookeeper:2181は、Zookeeperがリッスンするよう設定されているポートです。さらにこのラベルは、ZooKeeperモジュールのmntrメトリックセットとserverメトリックセットを使うよう指示しています。ところで、ZooKeeperの最近のバージョンでは“4字の用語”と見なされるパターンが一部禁止されています。したがってここで、KAFKA_OPTS経由でsrvrコマンドとmntrコマンドをデプロイ内の認可済みリストに追加する必要があります。ここまでの手順を完了すると、Composeファイル内のZooKeeperの設定は次のようになります。
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT:2181
ZOOKEEPER_TICK_TIME:2000
KAFKA_OPTS: "-Dzookeeper.4lw.commands.whitelist=srvr,mntr"
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
ブローカーからログを捕捉する手順は単純明快です。各々にロギングモジュール用のラベルco.elastic.logs/module=kafkaを追加するだけです。一方、ブローカーのメトリックは少々複雑です。Metricbeat Kafkaモジュールには、5つの異なるメトリックセットがあります。
- consumer group(コンシューマーグループ)メトリック
- partition(パーティション)メトリック
- broker(ブローカー)メトリック
- consumer(コンシューマー)メトリック
- producer(プロデューサー)メトリック
最初の2つのメトリックセットはブローカーから直接捉えるのに対し、後半3つはJMX経由で捉えます。最後の2つ、consumerメトリックとproducerメトリックはそれぞれJavaベースのコンシューマーとプロデューサー(Kafkaクラスターのクライアント)に限り適用できるメトリックです。したがって本記事では割愛します(この後の解説と同じパターンの手順で設定できます)。まず最初の2つのメトリックセットからはじめましょう。この2つは設定方法が同じです。broker1用のComposeファイル内のKafkaの設定は、最初は次のようになっています。
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID:1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP:PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS:PLAINTEXT://broker1:29091,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR:1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS:0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR:1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR:1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR:1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR:1
KAFKA_JMX_PORT:9101
KAFKA_JMX_HOSTNAME: broker1
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29091
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS:1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
ZooKeeperの設定と同様、MetricbeatにKafkaメトリックの収集方法を指定するlabels(ラベル)を追加します。
labels:
- co.elastic.logs/module=kafka
- co.elastic.metrics/module=kafka
- co.elastic.metrics/metricsets=partition,consumergroup
- co.elastic.metrics/hosts='$${data.container.name}:9091'
これで、MetricbeatとFilebeatのkafkaモジュールをセットアップし、Kafkaログとpartitionメトリック、およびconsumergroupメトリックをコンテナーでポート9091のbroker1から収集することができます。この例ではホスト名の代わりにdata.container.nameという変数(ダブルドルマークでエスケープされた部分)を使用していますが、お好みのパターンで設定していただくことができます。この手順を各ブローカーに対して反復しますが、ポート番号の9091の部分を変更します。上の手順は9091の設定で始まっているので、ブローカー2に9092、ブローカー3に9093を使用してください。
Confluentのクラスターは、docker-compose up --detachを実行して起動できます。またここまでの手順を完了すると、MetricbeatとFilebeatを起動し、Kafkaのログとメトリックを収集することが可能です。
cp-all-in-one Kafkaクラスターを起動すると、クラスターが自らの仮想ネットワーク、cp-all-in-one_defaultを作成、実行します。この手順ではラベル内のサービス/ホスト名を使用するので、名前と接続を正しく解決するには、Metricbeatを同じネットワーク内で実行する必要があります。Metricbeatを起動させるため、実行コマンドにネットワーク名を含めます。
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
Filebeatの実行コマンドも同様ですが、Filebeatは他のコンテナーと接続せず、Dockerホストから直接収集するのでネットワークは必要ありません。
docker run -d \
--name=filebeat \
--user=root \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
--volume="/mnt/data/docker/containers:/var/lib/docker/containers:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
各ケースで設定用のYAMLファイルを読み込み、docker.sockファイルをホストからコンテナーにマッピングし、接続情報を含めています(セルフマネージドのクラスターを実行している場合、コラテラルを読み込む際に使用した資格情報を把握しておきます)。ただし、MacでDocker Desktopを実行している場合、ログは仮想マシンに格納されるため、ログにアクセスできない点に注意してください。
KafkaとZookeeperのパフォーマンスと履歴を可視化する
ここまでの手順で、Kafkaのブローカーからくるサービス固有のログの捕捉と、KafkaおよびZookeeperのログとメトリックの収集を実行することができるようになっています。Kibanaのダッシュボードを開いてフィルターをかけると、Kafkaのダッシュボードが表示されるはずです。
Kafkaのログのダッシュボードを見ることができます。
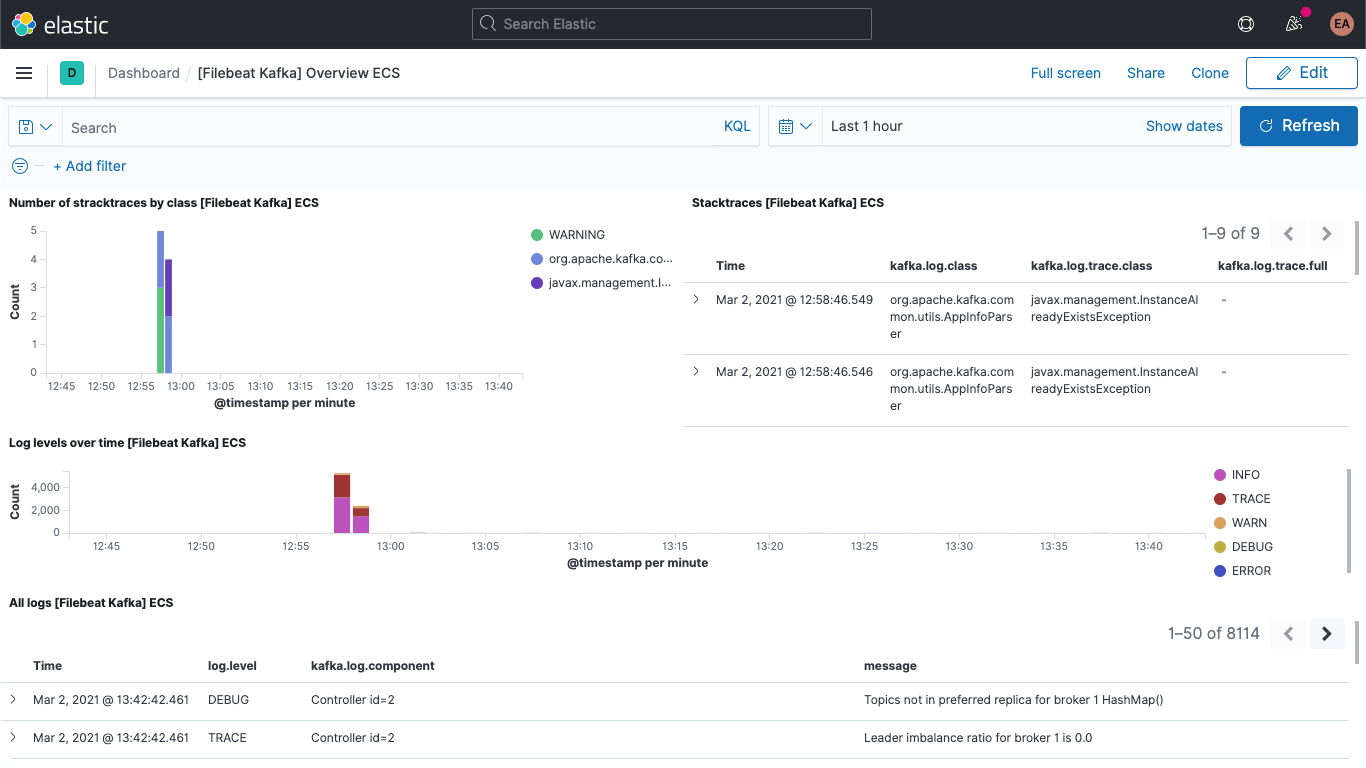
Kafkaのメトリックダッシュボードもあります。
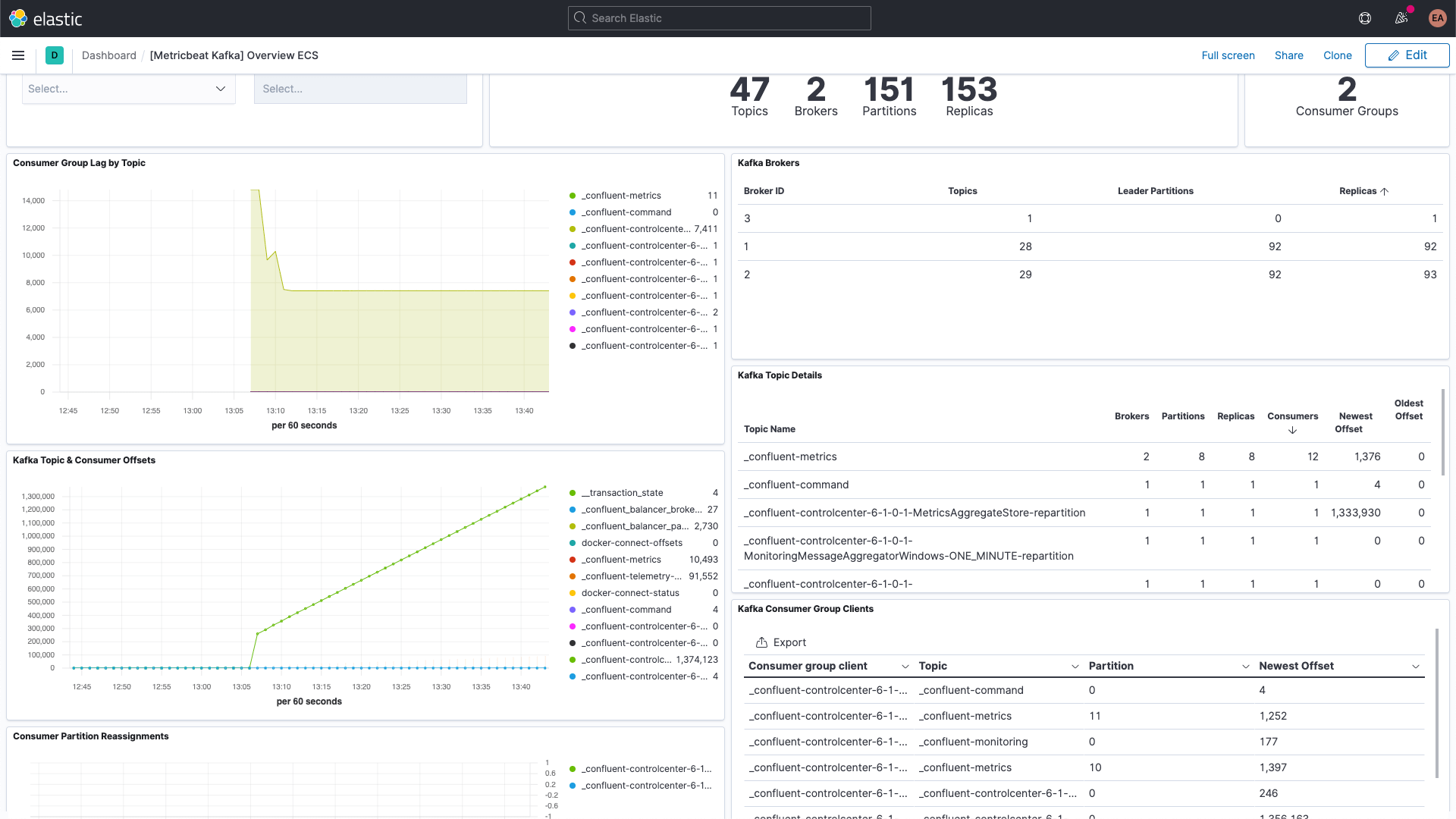
こちらはZookeeperメトリックのダッシュボードです。
さらに、KibanaのLogsアプリでもKafkaとZookeeperのログを確認できます。このアプリを使うと、ログの絞り込みや検索、分析を実行できます。
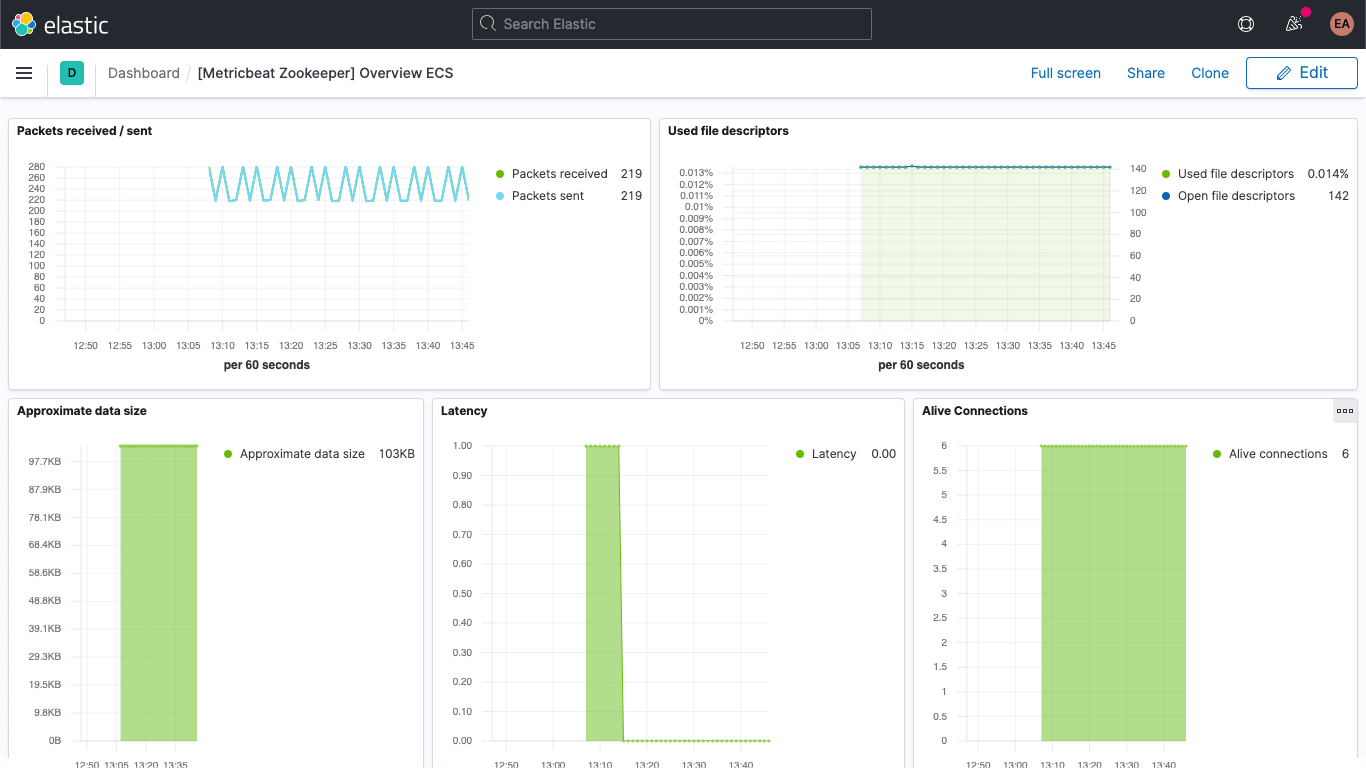
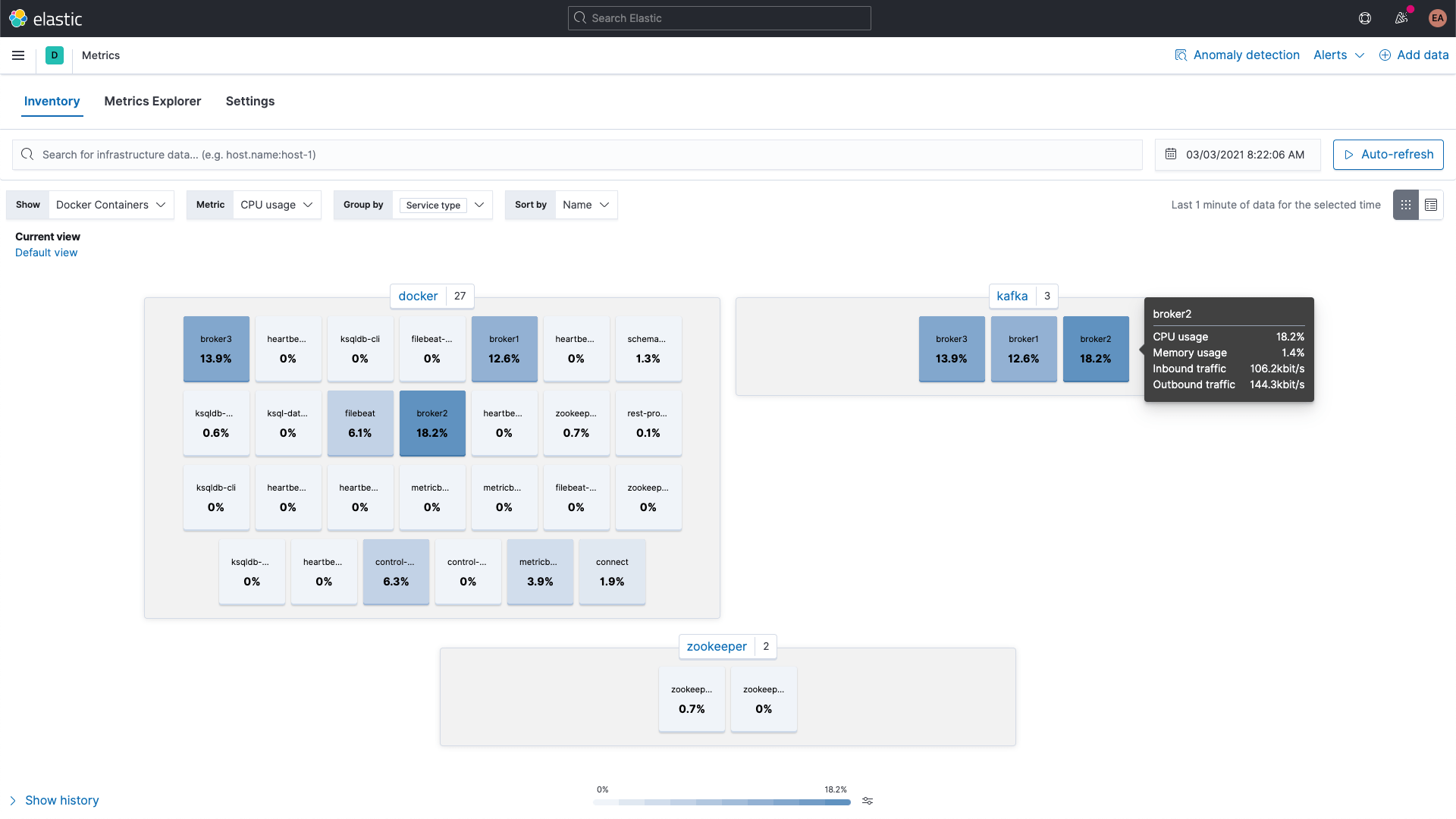
KafkaとZookeeperのコンテナーのメトリックはKibanaのMetricsアプリで閲覧できます。下の画像ではサービスタイプのグループ別に表示されています。
broker(ブローカー)メトリック
ここで、kafkaモジュールで収集したbrokerメトリックセットに話を戻しましょう。先ほど、これらのメトリックセットがJMXから収集されていることを説明しました。実は、ブローカー、プロデューサー、コンシューマーメトリックセットはJMXとHTTPのブリッジとなるJolokiaを使用しています。brokerメトリックセットはkafkaモジュールの一部ですが、JMXを使うので、consumergroupメトリックセットやpartitionメトリックセットと異なるポートを使用する必要があります。つまり、ブローカーのlabelsに、multiple sets of hints(ヒントの複数セット)の注釈設定のような要領で、新しいブロックを追加しなければなりません。
さらに、Jolokia用のjarも追加する必要があります。ブローカーコンテナーへのjarの追加はvolume経由で実施し、セットアップまで行います。ダウンロードページによるとJolokia JVMエージェントの最新のバージョンは(本記事の執筆時点で)1.6.2となっており、これを使用します(-OLはcURLにこのファイルをリモート名として保存し、またリダイレクトに従うよう指示します)。
curl -OL https://search.maven.org/remotecontent?filepath=org/jolokia/jolokia-jvm/1.6.2/jolokia-jvm-1.6.2-agent.jar
各ブローカーの設定に1つセクションを追加し、コンテナーにJARファイルを添付します。
volumes:
- ./jolokia-jvm-1.6.2-agent.jar:/home/appuser/jolokia.jar
JARをJavaエージェントとして添付するには、KAFKA_JVM_OPTSを指定します(ブローカーごとにポートが設定されている点に注意します。ブローカー1-3が8771-8773です)。
KAFKA_JMX_OPTS: '-javaagent:/home/appuser/jolokia.jar=port=8771,host=broker1 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false'
認証を一切使用しない代わり、いくつかフラグを追加して立ち上げを行う必要があります。KAFKA_JMX_OPTS内のjolokia.jarファイルパスがvolume上のパスと同一であることに注目してください。
ここでいくつか小さな変更を追加する必要があります。手順ではJolokiaを使用するので、もうportsセクションのKAFKA_JMX_PORTをエクスポーズする必要はありません。代わりに、Jolokiaがリッスンするこのポートを8771にエクスポーズします。さらに、設定からKAFKA_JMX_*値を削除します。
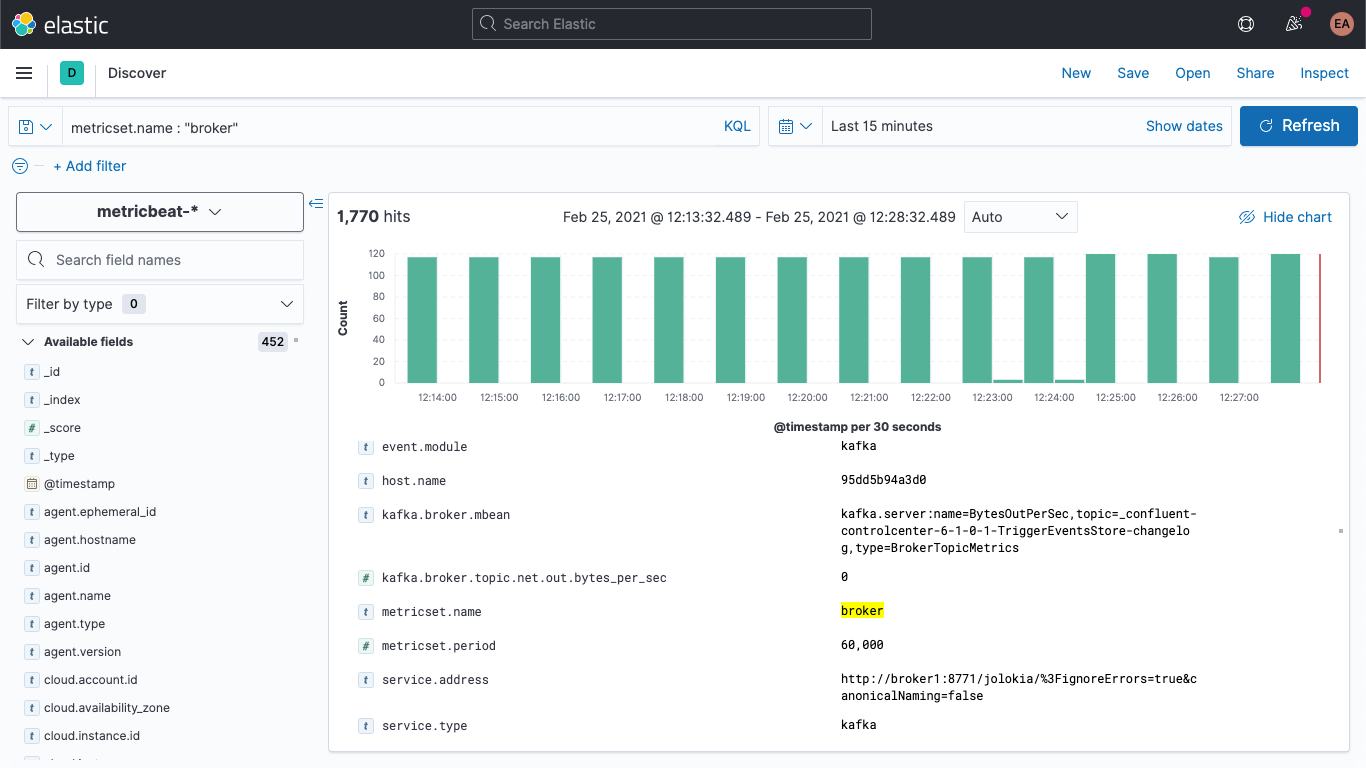
Kafkaクラスターを再起動すると(docker-compose up --detach)、Elasticsearchのデプロイにこのブローカーメトリックが現れるのを確認できるはずです。さらに、[Discover]タブを開いてmetricbeat-*インデックスパターンを選択し、metricset.name : "broker"を検索することで、データが実際に入っていることを確認できます。
ブローカーメトリックは、次のような構造になっています。
kafka
└─ broker
├── address
├── id
├── log
│ └── flush_rate
├── mbean
├── messages_in
├── net
│ ├── in
│ │ └── bytes_per_sec
│ ├── out
│ │ └── bytes_per_sec
│ └── rejected
│ └── bytes_per_sec
├── replication
│ ├── leader_elections
│ └── unclean_leader_elections
└── request
├── channel
│ ├── fetch
│ │ ├── failed
│ │ └── failed_per_second
│ ├── produce
│ │ ├── failed
│ │ └── failed_per_second
│ └── queue
│ └── size
├── session
│ └── zookeeper
│ ├── disconnect
│ ├── expire
│ ├── readonly
│ └── sync
└── topic
├── messages_in
└── net
├── in
│ └── bytes_per_sec
├── out
│ └── bytes_per_sec
└── rejected
└── bytes_per_sec
kafka.broker.mbeanフィールドに示されるように、このメトリックは基本的に名前/値のペアで収集されます。メトリックの一例として、kafka.broker.mbeanフィールドを見てみましょう。
kafka.server:name=BytesOutPerSec,topic=_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog,type=BrokerTopicMetrics
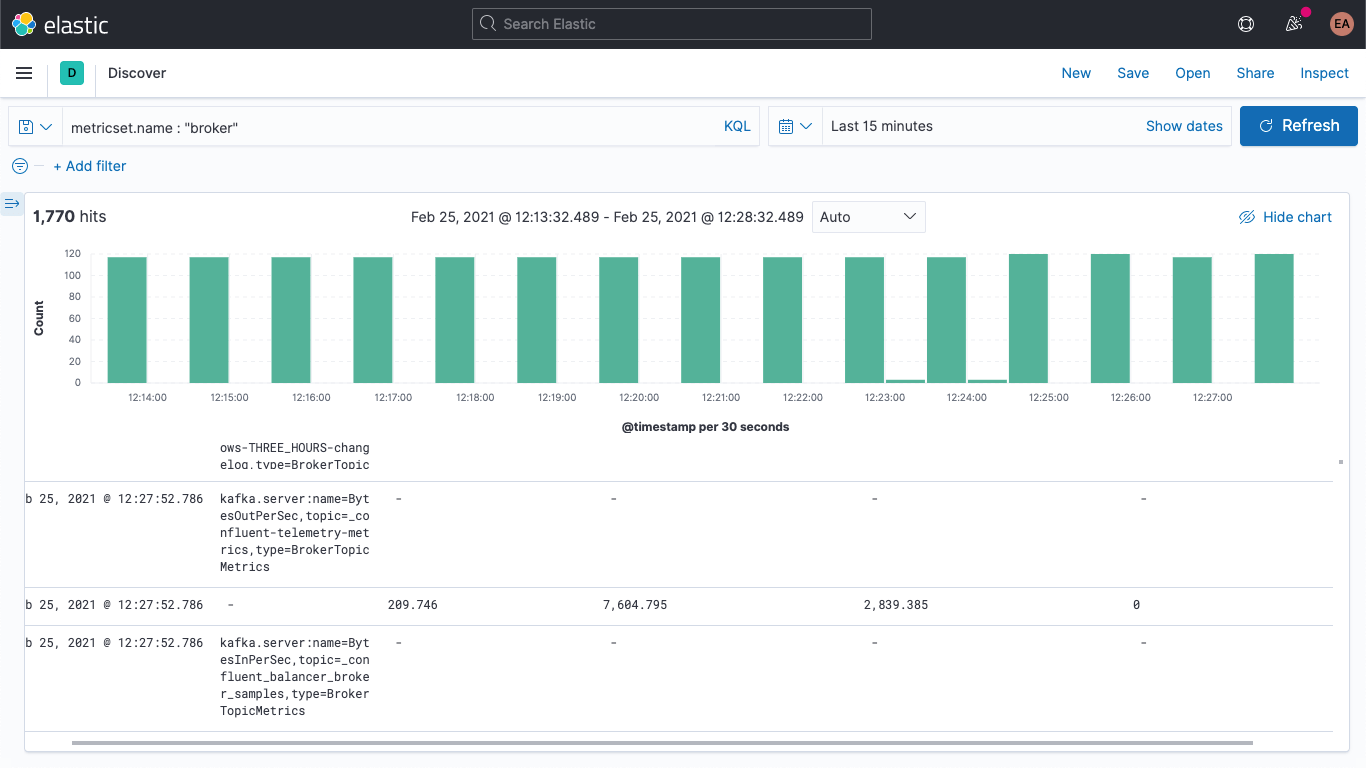
このフィールドには、メトリック名(BytesOutPerSec)と、このフィールドが参照するKafkaのトピック(_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelogkafka)、およびメトリックタイプ(BrokerTopicMetrics)が含まれています。セットされるフィールドは、メトリックの種類と名前により異なります。この例では、kafka.broker.topic.net.out.bytes_per_secだけがポピュレートされています(値は0です)。棒グラフ状に表示すると、データが非常に疎であることがわかります。
インジェストパイプラインを追加することでこれを少し圧縮し、mbeanフィールドを個別のフィールドに分割できます。これで、より簡単にデータを可視化することができます。次のように、3つのフィールドに分けましょう。
- KAFKA_BROKER_METRIC(上の例のbeBytesOutPerSecです)
- KAFKA_BROKER_TOPIC(上の例のbe_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelogです)
- KAFKA_BROKER_TYPE(上の例のbeBrokerTopicMetricsです)
Kibanaで[DevTools]に移動します。
移動したら以下の記述をコピー&ペーストして、kafka-broker-fieldsというインジェストパイプラインを定義します。
PUT _ingest/pipeline/kafka-broker-fields
{
"processors": [
{
"grok": {
"if": "ctx.kafka?.broker?.mbean != null",
"field": "kafka.broker.mbean",
"patterns": ["kafka.server:name=%{GREEDYDATA:kafka_broker_metric},topic=%{GREEDYDATA:kafka_broker_topic},type=%{GREEDYDATA:kafka_broker_type}"
]
}
}
]
}
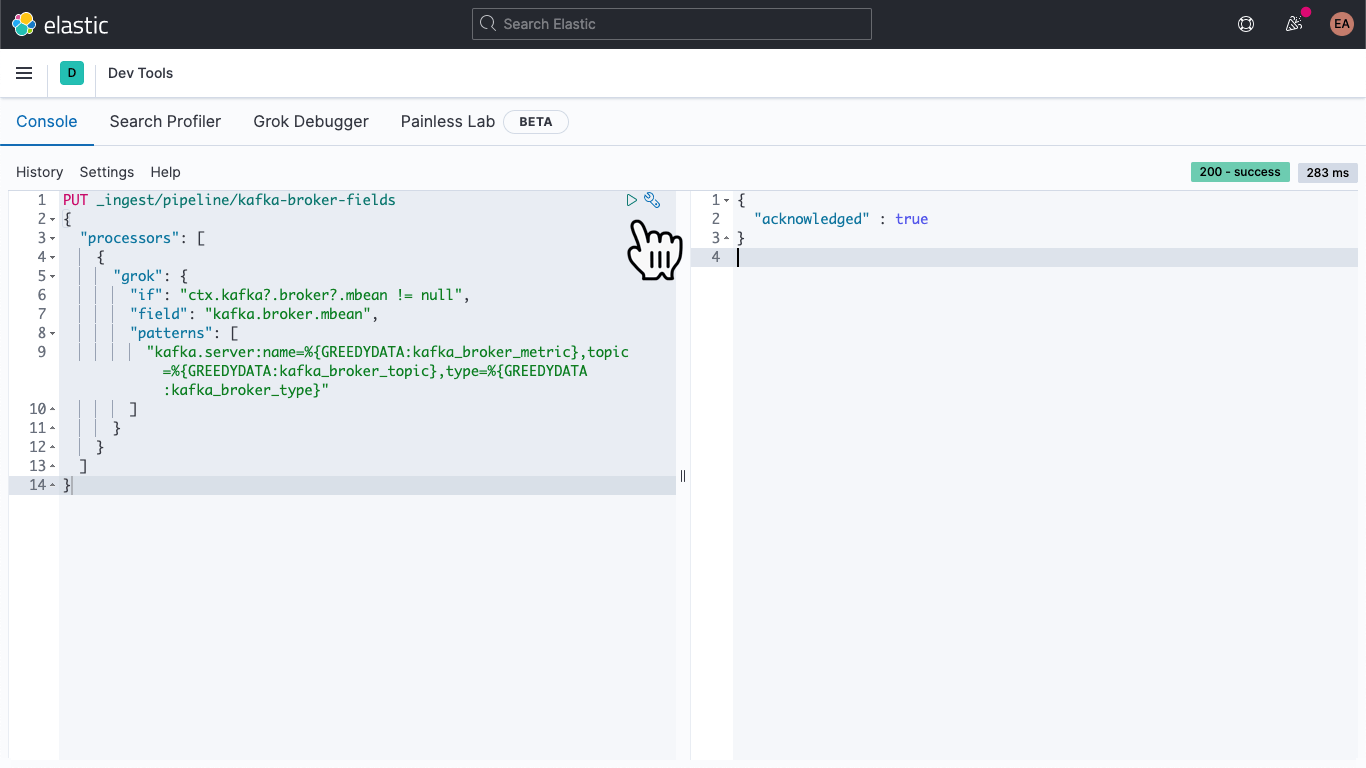
次に[プレイ]ボタンを押します。すると最後に、上の画像のような確認メッセージが現れるはずです。
これでインジェストパイプラインを追加しましたが、まだ何も完成していません。これまで収集したデータは疎でアクセスしにくく、新しいデータもまだ同じような状態で収集されています。まずは後者の問題に着手しましょう。
お好みのテキストエディターでmetricbeat.docker.ymlファイルを開き、output.elasticsearchブロックに一行追加します(使用しない場合はホスト、ユーザー名、パスワードを削除して構いません)。次に、以下のようにパイプラインを指定します。
output.elasticsearch: pipeline: kafka-broker-fields
この行は、Elasticsearchに対し、取り込むドキュメントはこのパイプラインを通過させて、mbeanフィールドを確認するよう指示しています。Metricbeatを再起動します。
docker rm --force metricbeat
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
[Discover]で、新規のドキュメントに新しいフィールドがあることを確認できます。
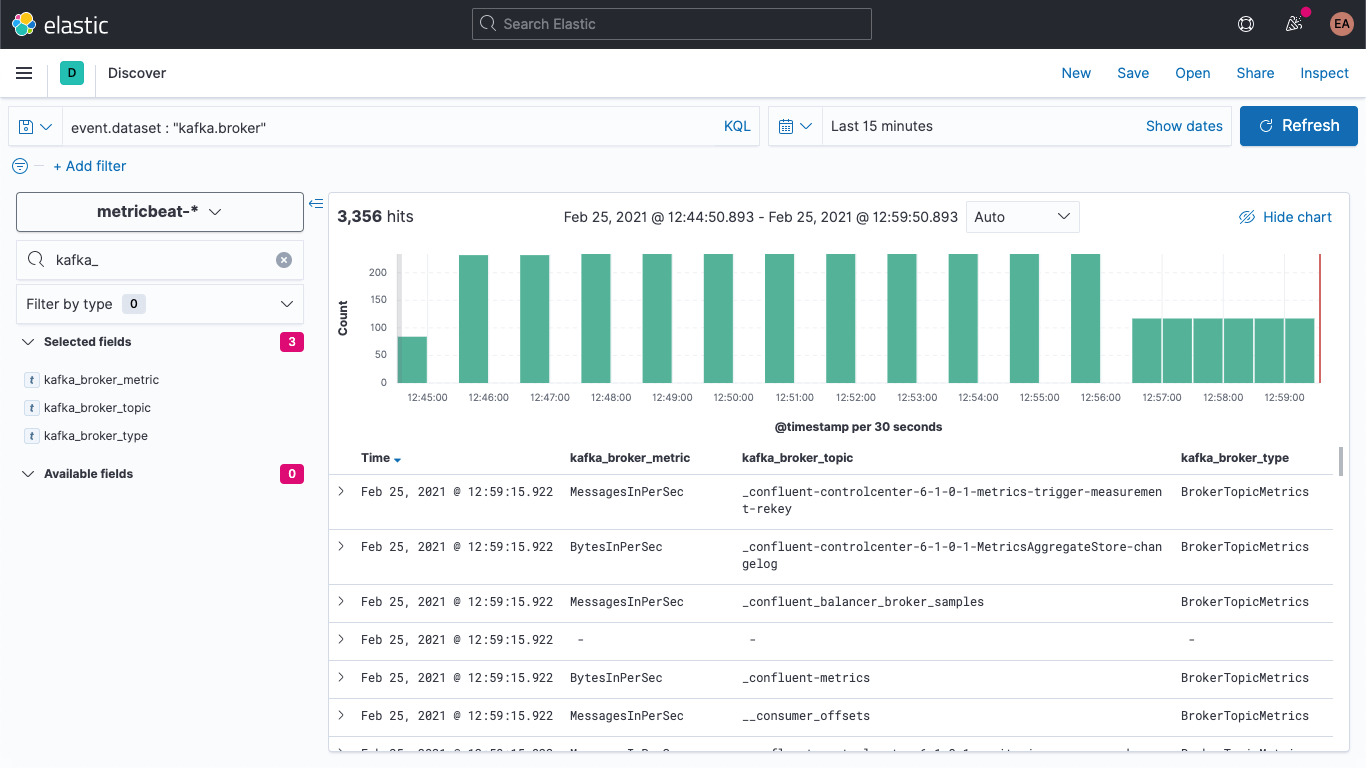
同様に古いドキュメントを更新して、このようにポピュレートされたフィールドを持たせることができます。[DevTools]に戻り、次のコマンドを実行します。
POST metricbeat-*/_update_by_query?pipeline=kafka-broker-fields
おそらくタイムアウトの警告が表示されますが、コマンドはバックグラウンドで実行され、非同期的に完了します。
brokerメトリックを可視化する
Metricsアプリに移動し、[Metrics Explorer]タブを選択すると、新しいフィールドが現れます。kafka.broker.topic.net.in.bytes_per_secとkafka.broker.topic.net.out.bytes_per_secをペーストして、一緒にプロットしてみましょう。
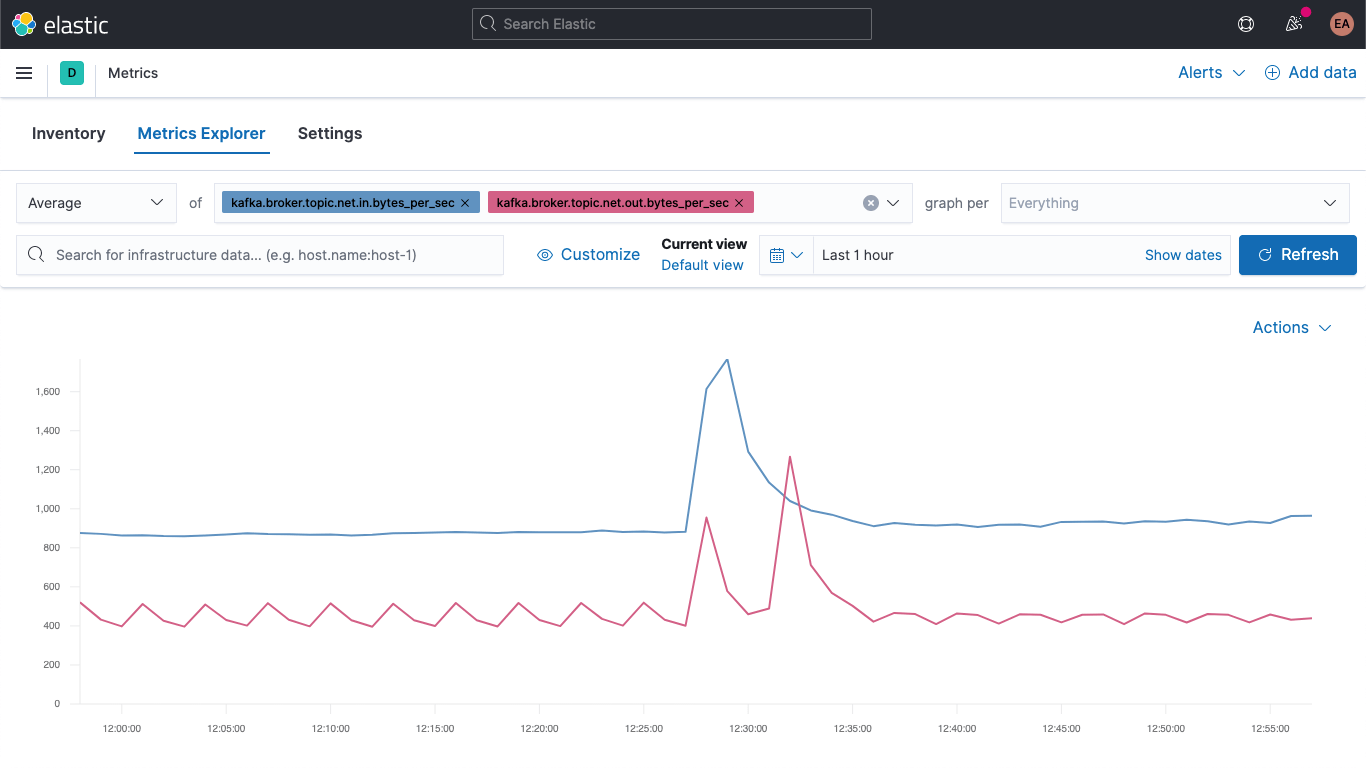
次に、[graph per]ドロップダウンを開いてkafka_broker_topicを選択し、新しいフィールドを活用します。
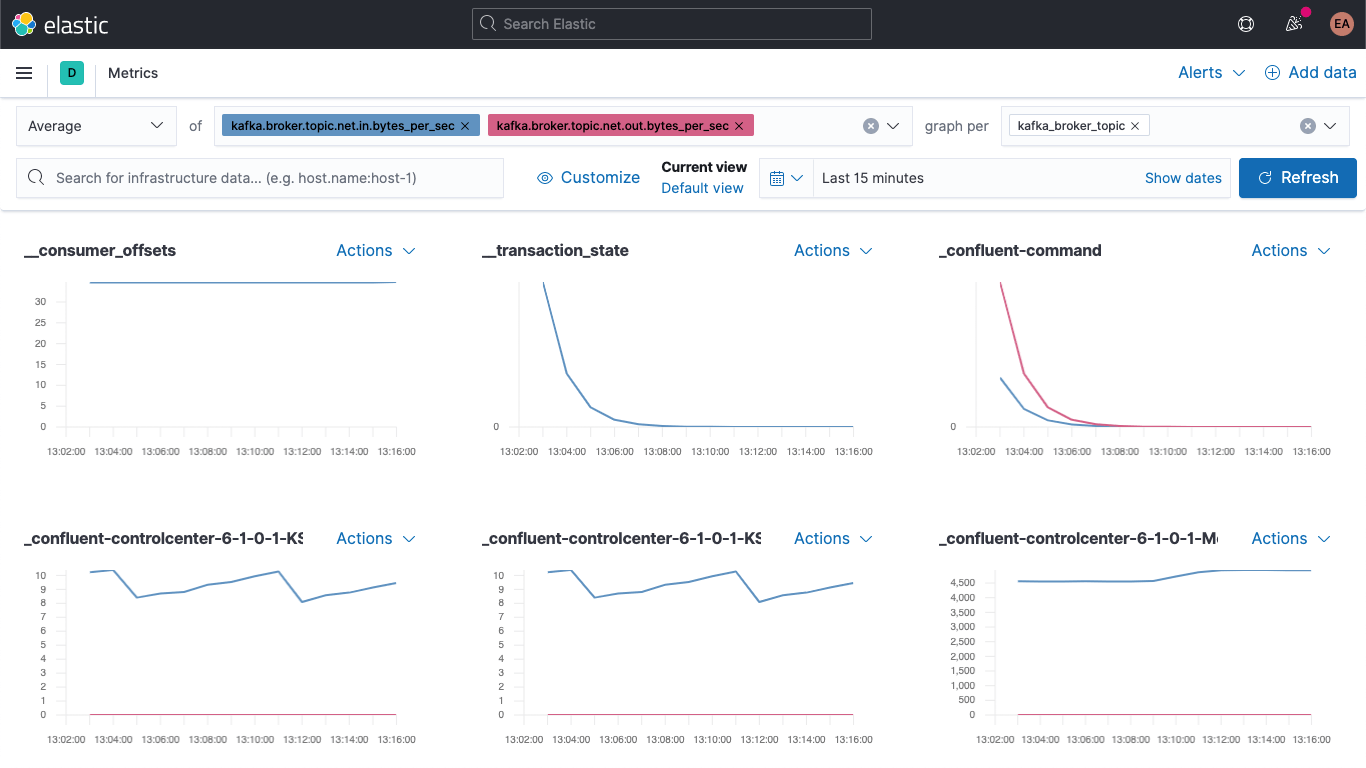
すべてのメトリックに0以外の値が表示されるわけではありません(今クラスターであまり多くのことが起きていません)が、それでもブローカーメトリックのプロッティングとトピック別の分析をはるかに簡単に行うことができます。ここに表示されているグラフはいずれも、可視化としてエクスポートしてKafkaメトリックダッシュボードに読み込ませることができるほか、Kibanaに搭載されているさまざまなチャートやグラフを使って独自の可視化を作成することもできます。ドラッグ&ドロップ操作による可視化構築がお好みの場合は、Lensを試してみてください。
ブローカーメトリックの可視化にはじめて挑戦する際におすすめなのが、produceブロックとfetchブロックのエラーです。
kafka
└─ broker
└── request
└── channel
├── fetch
│ ├── failed
│ └── failed_per_second
├── produce
│ ├── failed
│ └── failed_per_second
└── queue
└── size
エラーの重大性は、ユースケースに大きく依存します。エコシステムの中でエラーが起きている場合、断続的なアップデートしか受信しません。たとえば株価や温度測定などの場合、すぐに次のデータが送られてくるので、1つや2つのエラーが生じても大したことはないかもしれません。しかし、注文システムでいくつかのメッセージが抜け落ちると、大惨事になりかねません。顧客に商品が届かない可能性があります。
まとめ
本記事でご紹介した手順で、Elasticオブザーバビリティを使用してKafkaのブローカーとZookeeperを監視することができます。またヒントを活用して、コンテナー化されたサービスの新規インスタンスを自動で監視する方法や、データを手軽に可視化するためのインジェストパイプラインの設定方法についても説明しました。ご紹介した手順は、Elastic CloudのElasticsearch Serviceを無料トライアルを試用するか、Elastic Stackをダウンロードしてローカルで実行することにより、今すぐお試しいただけます。
現在、コンテナー化したKafkaクラスターではなく、マネージドサービスやベアメタルでKafkaクラスターを実行されているという方は、近日公開の記事をぜひご覧ください。本ブログ記事の公開後まもなく、次のような関連記事をいくつか公開する予定です。
- How to monitor a standalone Kafka cluster with Metricbeat and Filebeat(スタンドアローンのKafkaクラスターをMetricbeatとFilebeatで監視する)
- How to monitor a standalone Kafka cluster with Elastic Agent(スタンドアローンのKafkaクラスターをElastic Agentで監視する)