LogstashおよびJDBCを使用してElasticsearchとリレーショナルデータベースの同期を維持する方法
Elasticsearchが提供する強力な検索機能を活用するために、多くの企業は既存のリレーショナルデータベースとともにElasticsearchをデプロイします。このようなシナリオでは、Elasticsearchと、関連するリレーショナルデータベースに保存されたデータとの同期を維持する必要性が高くなります。そのためこのブログでは、Logstashを使用して、効率的にレコードをコピーし、リレーショナルデータベースに関する更新をElasticsearchに同期させる方法について説明します。ここで提示するコードと手法はMySQLでテスト済みであり、論理的にはどのRDBMSでも機能するはずです。
システム構成
このブログでは下記の構成でテストしています。
- MySQL:8.0.16.
- Elasticsearch:7.1.1
- Logstash:7.1.1
- Java:1.8.0_162-b12
- JDBCインプットプラグイン:v4.3.13
- JDBCコネクター:Connector/J 8.0.16
同期手順の概要
このブログでは、LogstashおよびJDBCインプットプラグインを使用してElasticsearchとMySQLの同期を維持します。コンセプトとしては、LogstashのJDBCプラグインはループで実行されます。つまり、ループの前回の実行後に挿入または変更されたレコードについて、MySQLに定期的にポーリングします。これが正確に実行されるようにするためには、次の条件が満たされる必要があります。
- MySQLのドキュメントがElasticsearchに書き込まれるため、Elasticsearchの「_id」フィールドがMySQLの「id」フィールドに対応するものとして設定されている必要があります。これにより、MySQLレコードとElasticsearchドキュメントの間で直接マッピングされます。MySQLでレコードが更新された場合、Elasticsearchで関連付けられているドキュメント全体が上書きされることになります。Elasticsearch内のドキュメントの上書きは、更新のオペレーションと同じくらい効率的です。更新の実際の作業は、古いドキュメントの削除と、その後の新しいドキュメント全体のインデックス付けで構成されています。
- MySQLでレコードが挿入または更新されると、そのレコードには、挿入または更新の時刻の情報を保持するフィールドが含まれます。このフィールドを使用することで、Logstashは、ポーリングループの前回の実行以降に変更または挿入されたドキュメントのみを要求することが可能になります。LogstashはMySQLにポーリングするたびに、MySQLから読み取った最終レコードの更新時刻または挿入時刻を保存します。これにより、Logstashはポーリングループの次の実行時に、前回の実行時に受信した最終レコードよりも新しい更新時刻または挿入時刻を持つレコードのみを要求するだけで済みます。
上記の条件が満たされた場合、新たに挿入または変更されたレコードを定期的にMySQLから要求し、それらのレコードをElasticsearchに書き込むようにLogstashを構成することができます。このためのLogstashのコードについては、この後、このブログで提示します。
MySQLのセットアップ
MySQLのデータベースとテーブルは次のように構成することができます。
CREATE DATABASE es_db; USE es_db; DROP TABLE IF EXISTS es_table; CREATE TABLE es_table ( id BIGINT(20) UNSIGNED NOT NULL, PRIMARY KEY (id), UNIQUE KEY unique_id (id), client_name VARCHAR(32) NOT NULL, modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP );
上記のMySQLの構成には、いくつかの興味深いパラメーターがあります。
es_table:これは、レコードが読み取られるMySQLのテーブル名であり、それらのレコードはElasticsearchに同期されます。id:このレコードの固有の識別子です。「id」はプライマリキー(主キー)であるとともに、ユニークキー(一意キー)として定義されます。このため各「id」は、現在のテーブルに1回のみ出現します。これが「_id」に変換されて、Elasticsearchのドキュメントが更新またはElasticsearchにドキュメントが挿入されます。client_name:これは、各レコードに保存されるユーザー定義データを示すフィールドです。このブログでは説明をシンプルにするために、ユーザー定義データのフィールドは1つにしますが、これらのフィールドは簡単に追加できます。ここではこのフィールドを変更し、新たに挿入されたMySQLレコードだけがElasticsearchにコピーされるのではなく、更新されたレコードもElasticsearchに正しく同期されることを示します。modification_time:このフィールドが定義されているのは、MySQLへの任意のレコードの挿入または更新によって、その変更時刻の値が設定されるようにするためです。この変更時刻により、Logstashが前回MySQLにドキュメントを要求した時刻以降に変更された任意のレコードを取得することが可能になります。insertion_time:このフィールドは主にデモンストレーション用であり、厳密には同期が正しく機能するために必要なものではありません。 これを使用して、レコードが最初にMySQLに挿入された時期を追跡します。
MySQLオペレーション
上記の構成を指定すると、次のようにしてレコードがMySQLに書き込まれるようにすることができます。
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name>);
以下のコマンドを使用して、MySQLのレコードを更新することができます。
UPDATE es_table SET client_name = <new client name> WHERE id=<id>;
以下のようにすることで、MySQLのアップサートが可能になります。
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name when created> ON DUPLICATE KEY UPDATE client_name=<client name when updated>;
同期コード
以下のLogstashパイプラインにより、前のセクションで説明した同期コードを実装できます。
input {
jdbc {
jdbc_driver_library => "<path>/mysql-connector-java-8.0.16.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => <my username>
jdbc_password => <my password>
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
# stdout { codec => "rubydebug"}
elasticsearch {
index => "rdbms_sync_idx"
document_id => "%{[@metadata][_id]}"
}
}
上記のパイプラインで注目すべきいくつかの領域について説明します。
tracking_column:このフィールドは、Logstashが最後にMySQLから読み取ったドキュメントを追跡するのに使用される「unix_ts_in_secs」フィールド(のちほど説明)を定義します。これは、ディスクの.logstash_jdbc_last_runに保存されます。この値は、Logstashがポーリングループの次の実行時に要求するドキュメントの開始値を決めるのに使用されます。.logstash_jdbc_last_runに保存された値には、SELECT文で「:sql_last_value」を使用することでアクセスできます。unix_ts_in_secs:これは上記のSELECT文で生成されるフィールドであり、標準のUnixタイムスタンプ(エポックからの経過秒数)として「modification_time」が含まれています。このフィールドは、先述の「tracking_column」で参照されます。時間の経過を追跡するために、通常のタイムスタンプではなくUnixタイムスタンプが使用されます。UMTとローカルタイムゾーン間の変換を正しく実行することは複雑であり、通常のタイムスタンプではエラーが発生する可能性があるからです。sql_last_value:これは組み込みのパラメーターであり、Logstashのポーリングループにおける現在の実行の開始ポイントが含まれています。上記のjdbc入力設定のSELECT文の行で参照されます。これは「unix_ts_in_secs」の最も直近の値に設定され、 .logstash_jdbc_last_runから読み取られます。Logstashのポーリングループによって実行されるMySQLクエリで返されるドキュメントの開始ポイントとして使用されます。この変数をクエリに含めると、Elasticsearchに前回伝達された挿入または更新が再度Elasticsearchに送信されることはありません。schedule:これは、Logstashが変更に関してMySQLにポーリングする頻度を指定するCron構文です。"*/5 * * * * *"と指定すると、Logstashは5秒ごとにMySQLにポーリングします。modification_time < NOW():これはSELECT文の一部であり、説明が最も難しい概念の1つです。そのため、詳細については次のセクションで説明します。filter:このセクションでは、MySQLレコードから「id」の値を単純に「_id」という名称のメタデータフィールドにコピーし、後から出力でそれを参照します。こうすることで確実に、各ドキュメントが適切な「_id」値でElasticsearchに書き込まれるようにすることができます。メタデータフィールドを使用することで、この一時的な値によって新しいフィールドが作成されないようにすることができます。また、Elasticsearchに書き込まれないようにするために、ドキュメントから「id」、「@version」、および「unix_ts_in_secs」フィールドを削除することもできます。output:このセクションでは、各ドキュメントをElasticsearchに書き込み、filterセクションで作成したメタデータフィールドから取得した「_id」を割り当てる必要があることを指定します。また、コメントアウトされたrubydebug出力があり、デバッグを支援するために有効化することが可能です。
SELECT文の正確性の分析
このセクションでは、SELECT文にmodification_time < NOW()を含めることの重要性を説明します。この概念を説明するために、まず逆の例として、2つの最も直感的なアプローチが正しく機能しない理由をデモンストレーションします。その後、modification_time < NOW()を含めることで、それら直感的なアプローチによる問題が克服できることを示します。
直感的なシナリオ1
このセクションでは、WHERE句にmodification_time < NOW()が含まれておらず、その代わりにUNIX_TIMESTAMP(modification_time) > :sql_last_valueが指定されている場合にどうなるかを見てみます。この場合、SELECT文は次のようになります。
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value) ORDER BY modification_time ASC"
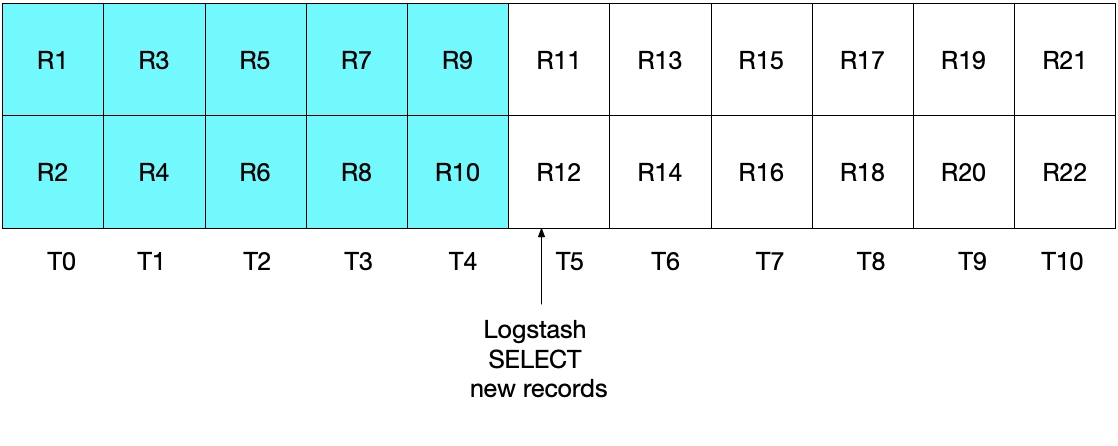
一見すると、上記のアプローチは正常に機能するように思えますが、エッジケースではいくつかのドキュメントの漏れが発生します。たとえば、MySQLが1秒ごとに2つのドキュメントを挿入し、LogstashがSELECT文を5秒ごとに実行する場合を考えてみましょう。1秒をT0からT10として表し、MySQLのレコードをR1からR22で表すと次の図のようになります。Logstashのポーリングループの最初の実行はT5で発生し、R1からR11(水色のボックス)までのドキュメントが読み取られます。この時点でsql_last_valueに保存された値は、読み取られた最終レコード(R11)のタイムスタンプであるT5です。そして、LogstashがMySQLのドキュメントを読み取った直後に、R12がMySQLにタイムスタンプT5で挿入されることになります。
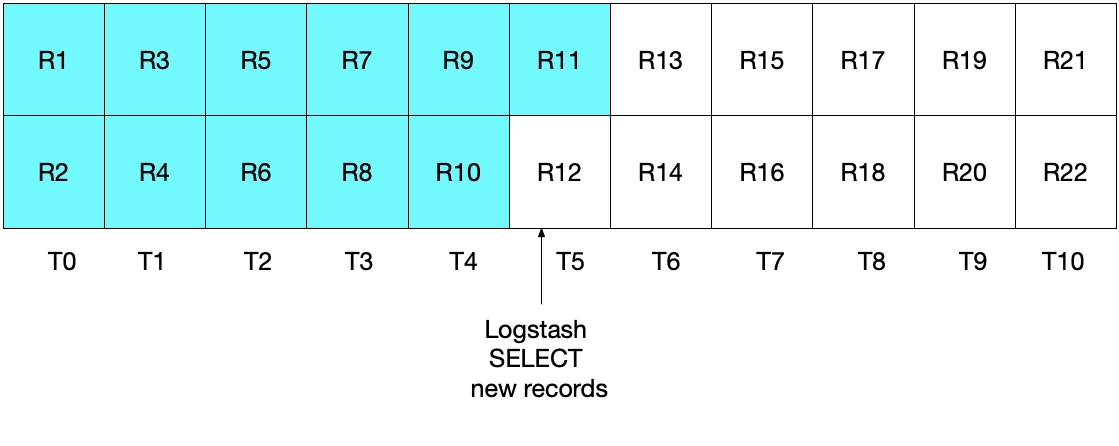
上記のSELECE文の次の実行では、挿入時刻がT5WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value)で指定されているとおり)されるため、レコードR12はスキップされることになります。下の図はそれを示しています。水色のボックスはLogstashによる今回の実行によって読み取られるレコードを示しており、グレーのボックスはLogstashの前回の実行によって読み取られたレコードを示しています。
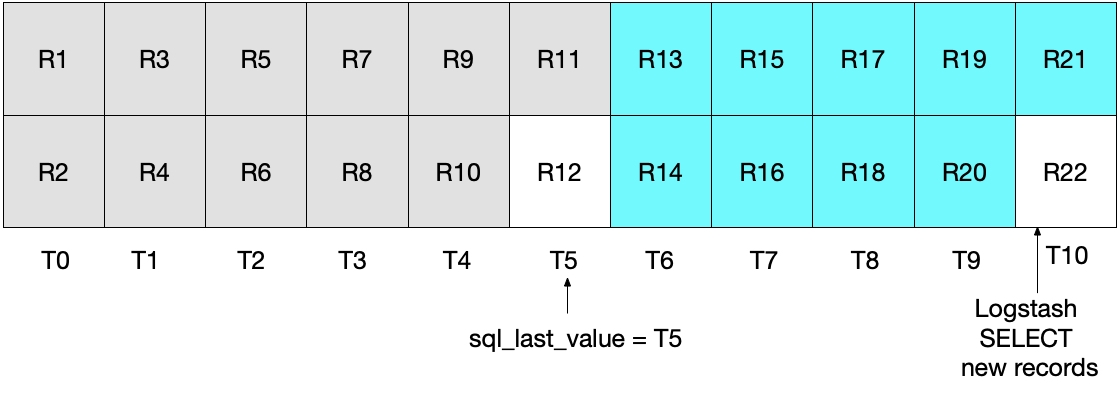
このシナリオのSELECT文では、レコードR12はElasticsearchに書き込まれることはありません。
直感的なシナリオ2
上記の問題を修正するために、次のようにWHERE句を
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) >= :sql_last_value) ORDER BY modification_time ASC"
しかし、この実装も理想的ではありません。このケースの問題は、最も直近のインターバルでMySQLから読み取られた最も直近のドキュメントがElasticsearchに再送されることです。これによって結果の正確性の面で問題が発生することはありませんが、不要な作業が発生します。前のセクションと同様に、Logstashの最初のポーリングの実行後にどのドキュメントがMySQLから読み取られたかを下の図で見てみましょう。
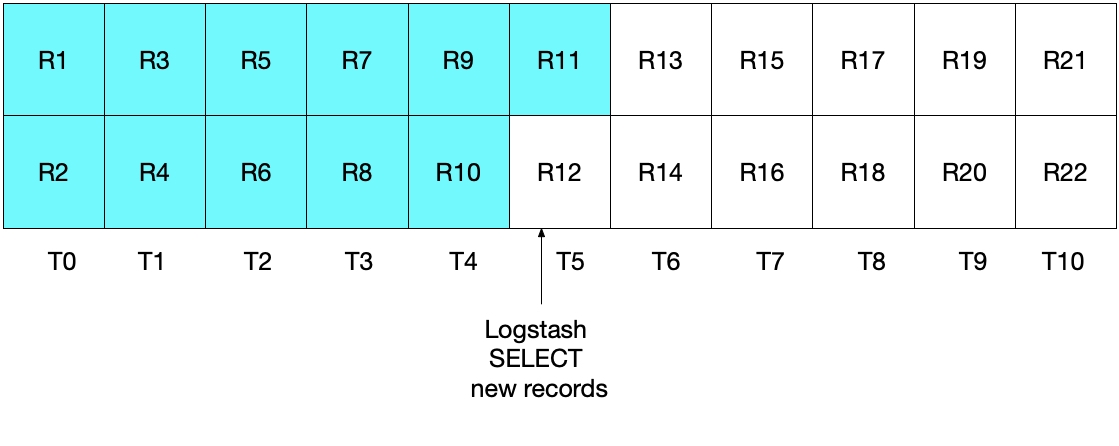
Logstashによる次のポーリングでは、T5
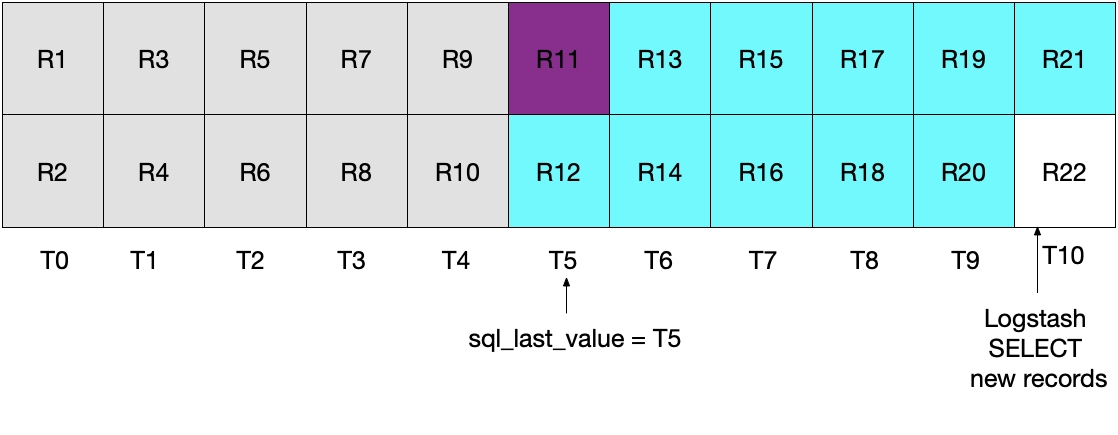
上記の2つのシナリオは両方とも、理想的ではありません。最初のシナリオではデータが失われる可能性があり、2つ目のシナリオでは冗長データがMySQLから読み取られ、Elasticsearchに送信されます。
直感的なアプローチを修正する方法
前述の2つのシナリオはどちらも理想的ではないため、代替アプローチを採用するべきです。(UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW())と指定することで、各ドキュメントを確実に1回のみ、Elasticsearchに送信できます。
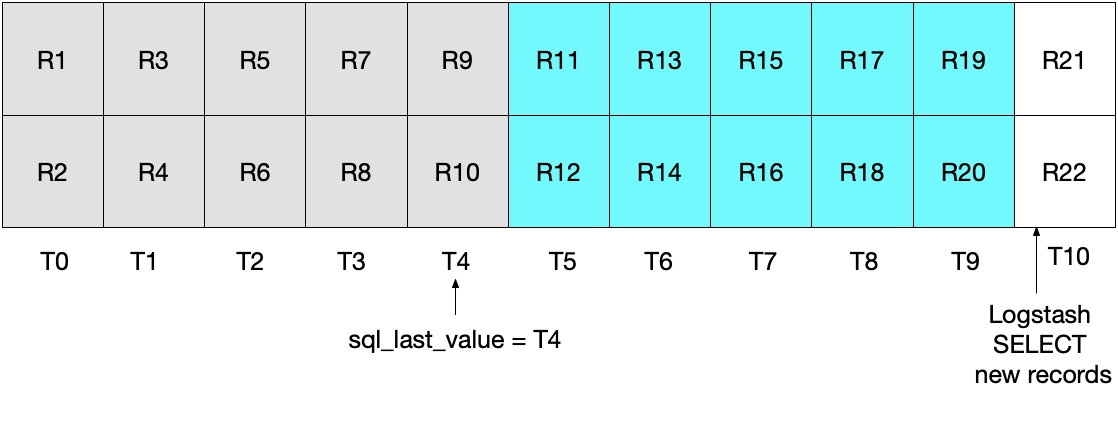
これを示しているのが下の図です。LogstashによるポーリングがT5の時点で実行されると、modification_time < NOW()が満たされる必要があるため、T5までの期間のドキュメント(その時点を含まない)がMySQLから読み取られることになります。T4のすべてのドキュメントが取得され、T5のドキュメントは何も取得されないため、Logstashのポーリングループの次の実行の基準となるsql_last_valueがT4に設定されます。
下図は、Logstashのポーリングループの次の実行でどのようになるかを示しています。UNIX_TIMESTAMP(modification_time) > :sql_last_valueとなっており、sql_last_valueがT4に設定されているため、T5以降のドキュメントのみが取得されることになります。そして、modification_time < NOW()を満たすドキュメントのみが取得されるため、T9まで(T9を含む)のドキュメントのみが取得されます。先ほどと同様、T9のすべてのドキュメントが取得され、次のポーリングの基準となるsql_last_valueはT9に設定されます。このアプローチにより、どのインターバルでも、MySQLドキュメントの一部のみが取得されるというリスクを回避できます。
システムのテスト
シンプルなテストによって、この実装が予想通りに機能することを見てみましょう。以下のようにして、MySQLにレコードを書き込むことができます。
INSERT INTO es_table (id, client_name) VALUES (1, 'Jim Carrey'); INSERT INTO es_table (id, client_name) VALUES (2, 'Mike Myers'); INSERT INTO es_table (id, client_name) VALUES (3, 'Bryan Adams');
MySQLからレコードを読み取り、それらのレコードをElasticsearchに書き込むというJDBCインプットスケジュールがトリガーされると、下記のElasticsearchクエリを実行してElasticsearch内のドキュメントを確認することができます。
GET rdbms_sync_idx/_search
これによって次のような応答が返されます。
"hits" : {
"total" : {
"value" :3,
"relation" : "eq"
},
"max_score" :1.0,
"hits" : [
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" :"1",
"_score" :1.0,
"_source" : {
"insertion_time" :"2019-06-18T12:58:56.000Z",
"@timestamp" :"2019-06-18T13:04:27.436Z",
"modification_time" :"2019-06-18T12:58:56.000Z",
"client_name" :"Jim Carrey"
}
},
Etc …
次に、以下のようにして、_id=1に対応するドキュメントをMySQLで更新できます。
UPDATE es_table SET client_name = 'Jimbo Kerry' WHERE id=1;
これで、_idが1として認識されるドキュメントが正常に更新されます。Elasticsearchで直接そのドキュメントを見るために、以下を実行します。
GET rdbms_sync_idx/_doc/1
これによって次のようなドキュメントが返されます。
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" :"1",
"_version" :2,
"_seq_no" :3,
"_primary_term" :1,
"found" : true,
"_source" : {
"insertion_time" :"2019-06-18T12:58:56.000Z",
"@timestamp" :"2019-06-18T13:09:30.300Z",
"modification_time" :"2019-06-18T13:09:28.000Z",
"client_name" :"Jimbo Kerry"
}
}
ここでは_versionが2に設定されていること、およびmodification_timeがinsertion_timeと異なっており、client_nameフィールドが新しい値に正しく更新されていることに注目してください。この例では、@timestampフィールドは特に注目すべき項目ではありません。これはLogstashによってデフォルトで追加されます。
MySQLへのアップサートは次のように実行できます。このブログをお読みいただいている方々なら、正しい情報がElasticsearchに反映されることを検証できるでしょう。
INSERT INTO es_table (id, client_name) VALUES (4, 'Bob is new') ON DUPLICATE KEY UPDATE client_name='Bob exists already';
削除されたドキュメントはどうなるのでしょうか。
お気づきの方もいらっしゃると思いますが、MySQLからドキュメントが削除されたら、その削除はElasticsearchには伝達されません。この問題に対処するために次のアプローチを検討してください。
- MySQLのレコードには、すでに有効ではなくなっていることを示す「is_deleted」フィールドを含めることが可能です。これは「soft delete」(ソフトデリート、論理削除)として知られています。MySQLレコードへのその他の更新と同様、「is_deleted」フィールドはLogstashを通じてElasticsearchに伝達されます。このアプローチを実装する場合、ElasticsearchおよびMySQLクエリは、「is_deleted」がtrueとなっているレコード/ドキュメントを除外するように記述する必要があります。 そうすることで、バックグラウンドジョブによってそのようなドキュメントがMySQLとElasticの両方から削除されます。
- 別の代替案としては、MySQLのレコードの削除を担うシステムが、その削除後に続けて、Elasticsearch内の対応するドキュメントを直接削除するコマンドを実行するように設定する方法もあります。
まとめ
このブログでは、Logstashを使用してElasticsearchをリレーショナルデータベースに同期させる方法を説明しました。ここで提示するコードと手法はMySQLでテスト済みであり、論理的にはどのRDBMSでも機能するはずです。
Logstashについて、またはElasticsearchに関するその他のトピックについてご質問がある場合は、ディスカッションフォーラムにアクセスし、重要なディスカッション、インサイトや情報をご確認ください。また、Elasticsearch Serviceもぜひお試しください。Elasticsearchの開発元が提供するElasticsearchオフィシャルマネージドサービスです。