Elastic Stack 7.0.0 リリース
7.0が出ました!このリリースでは861名のコミッターからの1万以上のプルリクエストが含まれています。 まず最初に、コミュニティならびに従業員に感謝いたします。
本リリースに関する情報を聞きたい方は、ライブバーチャルイベント を太平洋夏時間の2019年4月25日の午前8時に開催いたしますので、ぜひご参加ください。7.0のデモまた、ElasticのエンジニアによるAMA(Ask Me Anything)も行う予定です。また、日本でもライブウェビナーを4月23日に開催する予定です。日本のウェビナーの詳細はこちらのページをご覧ください。
Elastic Stack 7.0はすでに利用可能です。ダウンロードしたり、Elastic CloudのElasticsearch Service(新機能を提供する唯一のマネージドElasticsearchのサービス)でいますぐお試しください。
7.0では様々な機能がリリースされており、どこから始めれば良いか迷うかもしれません。いくつかを簡単にご紹介いたします。
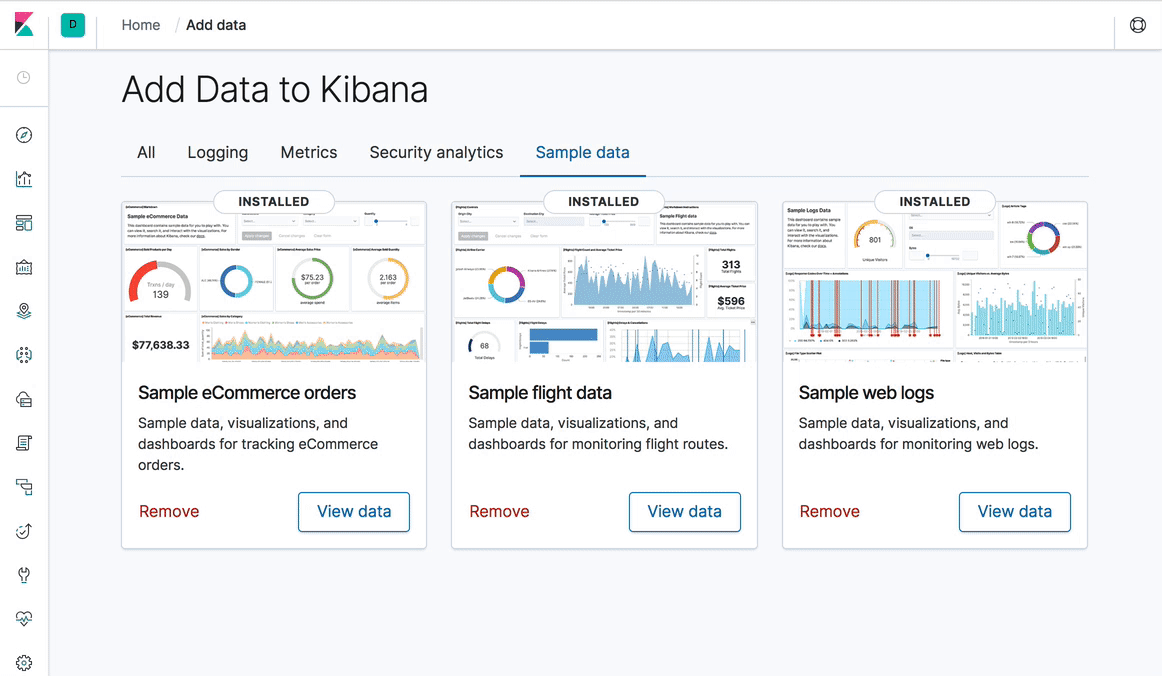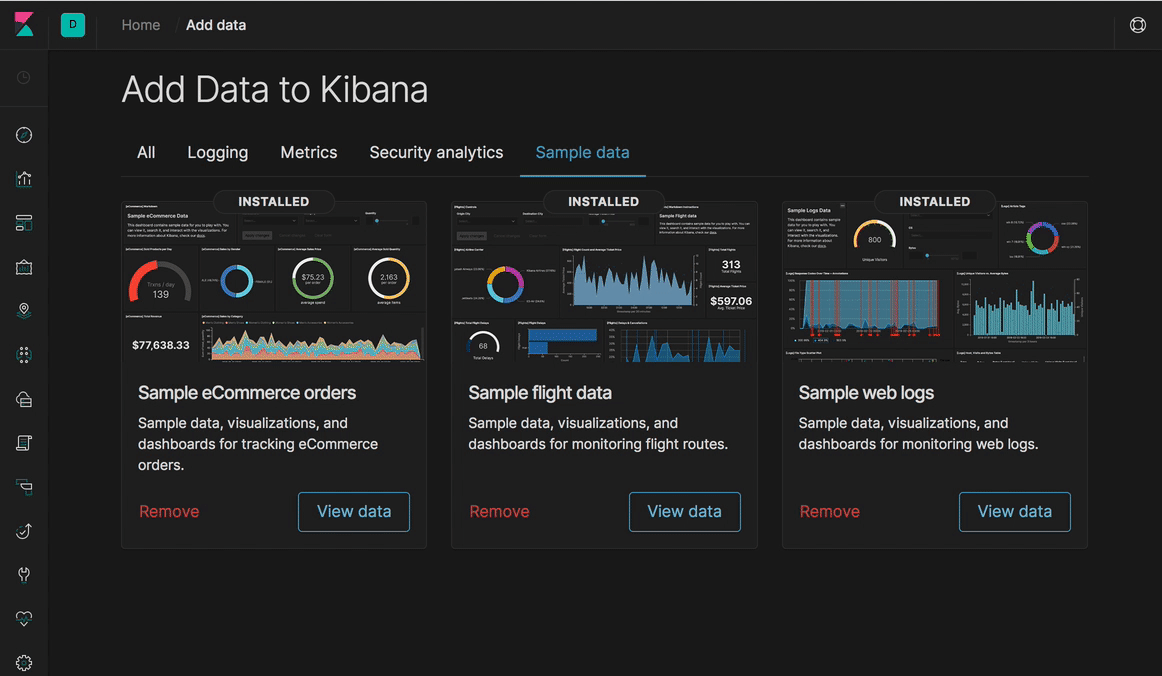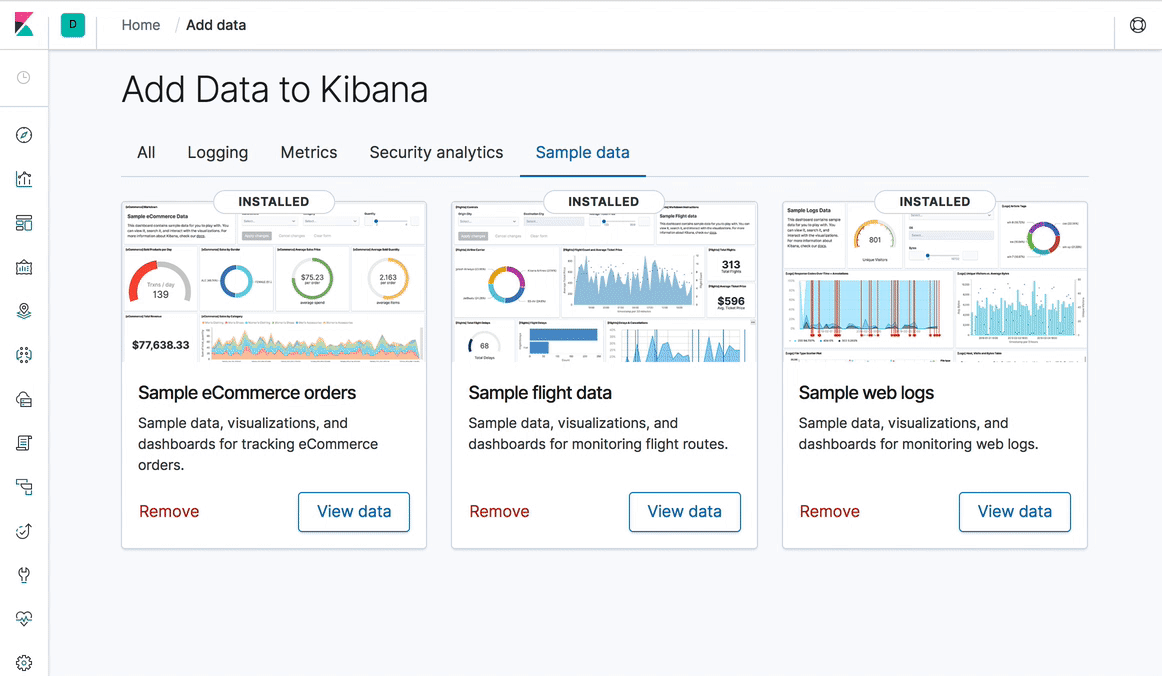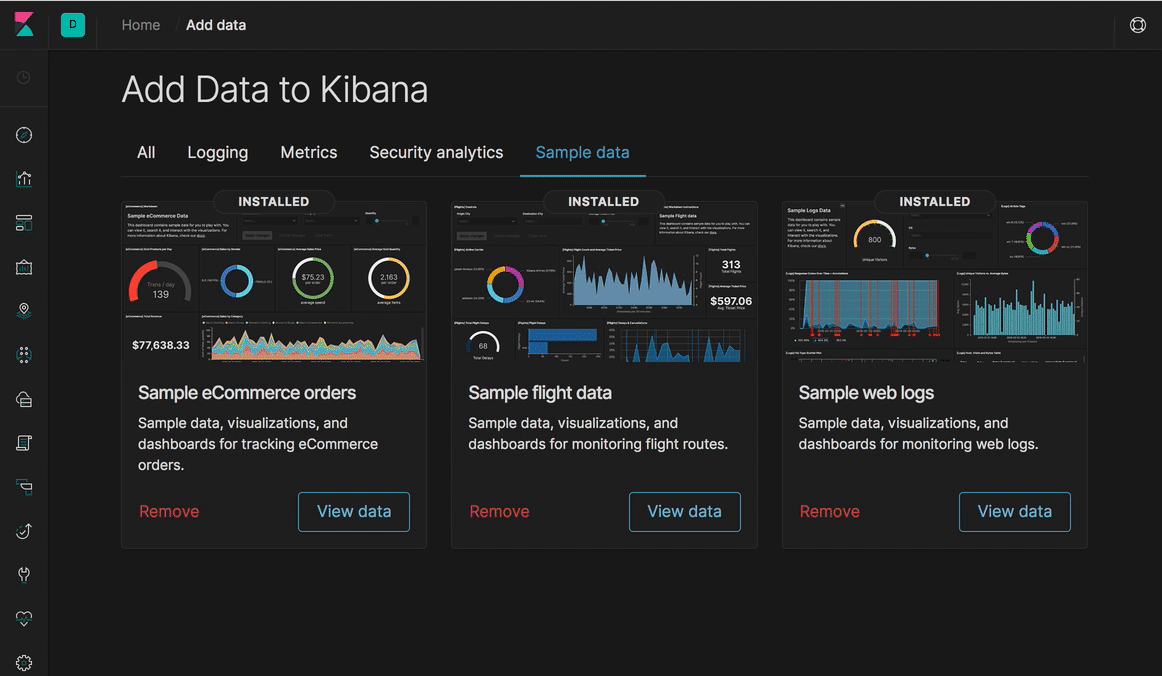
Kibana 7.0: 新デザイン & ナビゲーション。そしてダークモード!
Kibana7.0のデザインでは、よりコンテンツにフォーカスしてもらうように、UI は全体として明るく、最小限の構成になりました。最も目を引く変更内容は、新しいグローバルナビゲーションの導入です。Kibana スペースの切り替え、階層リンクの表示、パスワードの変更やログアウトなどのユーザー操作の開始を行うための固定ヘッダーを導入しています。また、この実現と一貫性を保つために、Elastic UI Frameworkを作成しました。ここ1年の間に、これらのコンポーネントを使用するために Kibana のほとんどを書き換えました。これらのコンポーネントを使用して、設計チームと技術部門の徹底的な努力により、スタイルやスタイルシートがどのように適用されるかについても大幅に簡略化しました。
一貫性とスタイルシートが強化されたことで、Kibana 履歴の中で最も大きな機能の要求の1つであるKibana全体のダークモードを利用できるようになっています。これらの変更のもう1つの利点として、Kibana のダッシュボードはレスポンシブデザインになったため、モバイルデバイスでの利便性を飛躍的に向上させる第一歩です。
新世代Elasticsearchクラスターコーディネーション
開発当初からElasticsearch を使いやすくし、壊滅的な障害に復旧できるようにすることに注力してきました。このような要件をサポートするために、個々のノードのスケーラビリティと信頼性を高めることから、Zen discoveryと呼ばれるクラスターの調整レイヤーを継続的に改善するということまで、複数のアプローチを行ってきました。7.0 では、両方の分野で、さらに大きな改善点が発表されています。
Elasticsearchのための完全に新しいクラスター調整レイヤーが登場します。高速かつ安全で、使いやすさを備えています。これを達成するために、私達は設計を検証するために形式モデルを使用して私達の新しい分散合意アルゴリズムの理論的正当性に焦点を合わせることから始めました。Paxos、Raft、Zab、Viewstamped Replication(VR)などのよく知られたコンセンサスアルゴリズムがありますが、Elasticsearchクラスターの要求には、クラスター変更のためのより高いスループット、クラスターの容易な拡大または縮小のサポート、およびシームレスローリングアップグレード戦略が必要で、これらの参照アルゴリズムでは提供できなかった機能がいくつかありました。新しいクラスター調整レイヤーには、人的ミスの可能性を減らし、壊滅的な障害から回復する際のより明確な選択を提供するいくつかの変更も含まれています。特にそのような中心的な要素において、信頼性、パフォーマンス、およびユーザーエクスペリエンスを一度に向上させることは容易ではありません。私たちは新しいクラスター調整レイヤーと、ここに到達するために私たちが引き受けたプロセスを誇りに思っています。詳細については、こちらのブログを読んでください。
回復性を考慮して、Elasticsearch 内の個々のノードを作成してます。ノードに送信する要求が多すぎる場合、または要求が大きすぎる場合、ノードはプッシュバックします。この処理を、Elasticsearch のサーキットブレーカーで実現し、特定の要求を扱うことができないノードで、場合によっては、クライアントに再試行を要求します (その場合は別のノードで応答するなど)。より小さな JVM ヒープサイズを持つノードの場合、ユーザーが大規模なマルチテナントクラスターではなく、そのようなクラスター単位のモデルに移動するほど一般的になり、これはさらに重要になります。7.0では、サービス不能なリクエストをより正確に検出し、それらが個々のノードを不安定にするのを防ぐためのリアルメモリサーキットブレーカを導入しました。この変更によってノードおよびクラスタ全体の信頼性がどのように向上するかについての詳細はこちらのブログを読んでください。
ユース・ケース全体にわたる関連度と速度の向上
関連度と検索の速度は優れた検索エクスペリエンスの要です。および Elasticsearch 7.0 は、両方を向上させる基本的な機能をいくつか導入しています。
- **上位kクエリの高速化:**多くの検索ユースケースでは、クエリで上位k(20件など)の結果をすばやく表示することは、正確なヒット数(つまり、クエリに一致する結果の総数)よりもはるかに重要です。たとえば、電子商取引のWebサイトで誰かが商品を検索している場合、検索クエリに一致した他の120,897件の結果ではなく、最も関連性の高い10件の結果に関心があります。Elasticsearch 7.0(およびLucene 8.0)新しいアルゴリズム(Block-Max WAND)を実装 しています。これは、トップヒットを取得するときに大幅な速度向上をもたらします。
- Intervalクエリ: 法律や特許の検索のようなユースケースでは、単語やフレーズが互いに一定の距離内にあるレコードを検索する必要が生じることがあります。Elasticsearch 7.0のIntervalクエリは、そのようなクエリを構築するためのまったく新しい方法を導入しており、以前の方法(スパンクエリ)と比べて使用および定義が非常に簡単です。Intervalクエリはまた、スパンクエリと比較してエッジケースに対してはるかに回復力があります。
- Function score 2.0: カスタムスコアは、関連性と結果のランク付けをより細かく制御したい、高度な検索のユースケースの基本です。Elasticsearchは、初期の頃からこれを実行する機能を提供してきました。7.0では、レコードごとにランク付けスコアを生成するための、よりシンプルでモジュール式、そしてより柔軟な方法を提供する、次世代の関数スコア機能が導入されています。新しいモジュール構造により、ユーザーは一連の算術関数と距離関数を組み合わせて任意の関数のスコア計算を構築し、結果のスコア付けとランク付けをより詳細に制御できます。
地理タイルでElastic Mapsをスムーズに拡大
長年にわたり、ジオサポートがElasticsearchに最初に追加された、Bkd-Treeデータ構造をLuceneに導入してそれを使用するまで、ジオデータのサポートは継続的に向上しています。 Kibanaのグローバルベースマップを強化するElastic Mapsサービスにより、ジオシェイプクエリのパフォーマンスが25倍以上向上しました。
7.0では、この改善を継続し、ユーザーが結果データの形状を変更することなく地図上でズームインおよびズームアウトできるように(ジオ)地図タイルを処理するためのElasticsearchの新しい集計を導入します。新しいgeotilegrid アグリゲーションでは、geopointsをグリッド内のセルを表すバケットにグループ化し、各セルをマップ内のタイルと関連付けます。この変更の前は、長方形のタイルは異なるズームレベルで向きが変わるため、ズームレベルの変更に伴ってシェイプのフリンジがわずかに変わる可能性がありました。拡大縮小してもビューが安定していることを確認するために、7.0のElastic Mapsはすでにこの新しい集計を使用しています。攻撃者からネットワークを保護したり、特定の場所でアプリケーションの応答が遅い時間を調べたり、tracking your brother hiking the Pacific Crest Trailなど、このレベルの精度は重要です。
ナノ秒の精度サポートによる時系列ユースケースの強化
インフラストラクチャメトリクス、システム監査ログ、ネットワークトラフィック、火星の移動局など、Elastic Stackを使用するの多くがデータシリーズデータを扱っています。複数のシステムやサービスにわたって、イベントの正確な順序付けと関連付けを行うことが重要です。
これまで、Elasticsearchはミリ秒単位でのみタイムスタンプを格納していました。7.0では数桁のゼロが追加されてナノ秒の精度が扱えます。高頻度のデータ収集を必要とするユーザーは、このデータを正確に格納してシーケンス処理するために必要な精度を持つことができます。