Elastic APM Javaエージェントのプラグインに貢献する方法
既知のフレームワークおよびライブラリのインストルメンテーションとトレースがAPMエージェントによって自動的に実行されれば理想的ですが、APMエージェントで実際にサポートされる内容は、キャパシティと優先順位の兼ね合いが反映された結果です。Elasticがサポートしているテクノロジーとフレームワークのリストは、ユーザーからの貴重なインプットに基づく優先順位に従いながら常に大きくなっています。それでも、Elastic APM Javaエージェントの初期状態のままではサポートされていない機能について不自由を感じている場合は、それをトレースできる方法があります。
たとえば、ElasticのパブリックAPIを使用して自身のコードをトレースすることや、 Elasticの優れたカスタムのメソッドトレース設定を使用してサードパーティライブラリの特定のメソッドの基本的な監視を行うことができます。ただし、サードパーティのコードからの特定データに対する可視性を拡張するには、さらに作業が必要になる場合があります。幸いにも、Elasticのエージェントはオープンソースであるため、自分の思い通りに実行することが可能です。あなたのその作業をぜひコミュニティにシェアしましょう。シェアすることによる大きな利点は、より広くフィードバックを得ることができること、また自身のコードを他の環境で実行してもらえることです。
Elasticの機能拡張への貢献は大歓迎です。ただし、当社として要求しなければならないいくつかの基準を満たしていただくことが必要になります。これらはユーザーの皆さまがElasticに期待しているものです。例として、OkHttpクライアントの呼び出しに関するこちらのPRやJAX-RSサポートに関するこちらの拡張機能をご確認ください。キーボードを使ってコードの作成を開始する前に、Elasticのコードベースに貢献する際に知っておいていただくべき事柄を以下に説明します。このプラグイン実装ガイドの理解に役立つテストケースを提示して説明します。
テストケース:Elasticsearch Java RESTクライアントのインストルメンテーション
エージェントをリリースする前、私たちは弊社独自のデータストアクライアントをサポートしようとしていました。Elasticsearch Java RESTクライアントのユーザーが次のことを把握できるようにと考えていました。
- Elasticsearchに対して実行されたクエリ
- そのクエリにかかる時間
- リクエストされたクエリに応答したElasticsearchのノード
- クエリ結果についてのいくつかの情報(ステータスコードなど)
- エラーが発生した時間
- クエリ自体(
_searchオペレーション用)
また、最初のステップとして、同期クエリのみをサポートし、適切なインフラストラクチャーが用意できるまで非同期クエリのサポートは遅らせることに決定しました。
私は関連コードを抽出し、それをGistにアップロードして作業中に参照しました。このコードは、GitHubリポジトリで見つかる実際のコードではありませんが、完全に機能し、関連性があります。
Javaエージェント固有の側面
Javaエージェントのコードを記述する際には、特別な考慮事項があります。テストケースを検討する前に、それらを簡単に見ておきましょう。
バイトコードのインストルメンテーション
心配はいりません、バイトコードで書く必要はありません。Byte Buddyライブラリを使います(つまり、ASMを活用します)。たとえば、アノテーションを使用して、インストルメンテーションメソッドの最初および最後に何をインジェクトすべきかを示します。頭に入れておく必要があるのは、記述するコードの一部は、記述する場所で実際に実行されず、コンパイルされたバイトコードとして他のユーザーのコードにインジェクトされるということです(これこそオープン性の大きな利点です。インジェクトされるコードは具体的に知ることができます)。

クラスの可視性
これは最も理解が難しい要素であり、ほとんどの落とし穴が潜んでいるポイントでもあります。コードの各部分がどこからロードされ、実行時にそれらのどれが利用可能と想定されるかについて、詳細に認識しておく必要があります。プラグインを追加する際に、コードは少なくとも2つの個別の場所にロードされます。1つはインストルメントされたライブラリ/アプリケーションのコンテキスト、もう1つはコアエージェントコードのコンテキストです。たとえば、先ほどのコードでは、Elasticsearchクライアントに付属のApache HTTPクライアントクラスであるHttpEntityとの依存関係があります。このコードはクライアントのクラスの1つにインジェクトされるため、その依存関係が有効であることは明らかです。一方、IOUtils(コアエージェントクラス)を使用すると、コアJavaおよびコアエージェント以外の依存関係が想定できません。Javaクラスのロードの概念に詳しくない場合は、その概要だけでも把握しておくと役立つでしょう(たとえば、こちらの優れた概要をお読みになることをお勧めします)。
オーバーヘッド
常にパフォーマンスが求められているというのは常識です。非効率的なコードを書こうとする人はいないでしょう。通常のコードの記述ではオーバーヘッドトレードオフを決定しますが、エージェントコードを記述するときにはこれができません。あらゆる面で無駄を省く必要があります。パーティに参加しながら仕事もスムーズに実行することが求められているのです。
エージェントのパフォーマンスオーバーヘッドとそのチューニング方法の詳細については、こちらの優れたブログ記事をご覧ください。
同時実行
通常、各イベントの最初のトレースオペレーションは、プール内の多数のスレッドの1つであるリクエスト処理スレッドで実行されます。このスレッドでの処理はできるだけ少量、高速にして、より重要なオペレーションを処理できるように解放する必要があります。このアクションの副産物は共有コレクションで処理され、そこでは同時実行の問題にさらされることになります。たとえば、最初の部分に記述したSpanオブジェクトは、リクエスト処理スレッド上でこのコード全体に渡って複数回更新されますが、後で別のスレッドによってシリアル化およびAPMサーバへの送信のために使用されます。さらに、同期または潜在的に非同期のオペレーションをトレースするかどうかを知っておく必要があります。まずいずれかのスレッドでトレースが開始され、別のスレッドで続行される場合は、それを考慮する必要があります。
テストケースに戻る
以下に、Elasticsearch RESTクライアントプラグインを実装するために必要なことを説明します。便宜上、3つの手順に分けています。
注意: ここからはかなり技術的な内容になります。
手順1:何をインストルメントするかを選択
このプロセスでの最も重要な手順です。調査してこれを適切に実行できれば、最適なメソッドを見つけられる可能性が高くなり、簡単な作業になります。考慮事項は次のとおりです。
- 関連性:以下のメソッドをインストルメントする必要があります。
- キャプチャ対象とするものを正確にキャプチャする。たとえば、メソッドの終了時間から開始時間の差は、作成するスパンの期間を正確に反映する必要がある
- 誤検出がない。メソッドの呼び出しは常に把握しておく必要がある
- 検出漏れがない。スパン関連のアクションが実行されるとメソッドが必ず呼び出される
- 開始または終了時に関連情報がすべて利用できる
- 上位互換性:頻繁に変更される可能性が低い一元化APIを意図している。トレースされているライブラリの各マイナーバージョンに合わせてコードをアップデートしない
- 下位互換性:このインストルメンテーションはどのくらい過去までサポートするか?
私は、クライアントコードについては(Elasticのものでさえ)何も知らない状態で、最新のバージョン(当時は6.4.1)をダウンロードして調べ始めました。Elasticsearch Java RESTクライアントは、高レベルおよび低レベルの両方のAPIを提供します。高レベルのAPIは低レベルのAPIに依存しており、すべてのクエリは最終的に低レベルのAPIを通過します。したがって、両方をサポートする場合は、必然的に低レベルのクライアントのみを見ることになります。
コードを詳しく見てみると、Response performRequest(Request request) (GitHubで参照)という記述のメソッドがあります。そして、同じメソッドのオーバーライドが4つあり、それらすべてがこれを呼び出しているとともに、すべてdeprecatedと記述されています。さらに、このメソッドはperformRequestAsyncNoCatchを呼び出します。これを呼び出す他の唯一のメソッドには、void performRequestAsync(Request request, ResponseListener responseListener)と記述されています。もう少し調べると、非同期パスが同期パスとまったく同じになっていることが分かります。deprecatedとなっている4つのオーバーライドは、deprecatedになっていない1つのメソッドを呼び出しており、この1つのメソッドはperformRequestAsyncNoCatchを呼び出すことで実際のリクエストを実行します。つまり、関連性についてはperformRequestメソッドは100%合格となります。同期リクエストのみをすべて正確にキャプチャし、リクエストと応答の両方の情報が開始/終了時に利用できます。完璧です。このメソッドをインストルメントすることをByte Buddyに指示する方法は、関連するmatcher提供メソッドをオーバーライドすることです。

今後については、この新しい一元化APIは安定性のための優れた選択肢になると思われます。しかし、バージョン6.4.0以前ではこのAPIはなかったため、それまでは優れた選択肢ではありませんでした。
インストルメンテーションに関してこれが完璧な候補だったため、私はこれを使用することに決定し、Elasticsearch RESTクライアントの長期的なサポートを達成しました。そして、旧バージョンにもインストルメンテーションを追加することにしました。その候補を見つけるために私は同様のプロセスを実行し、2つのソリューションに行き着きました。1つはバージョン5.0.2から6.4.0用、もう1つはバージョン6.4.1以降用です。
手順2:コード設計
Mavenを使用します。新たなテクノロジーをサポートするために導入した新しい各インストルメンテーションは、プラグインと呼ばれるモジュールになります。私のケースでは、新旧両方のElasticsearch RESTクライアントをテストするつもりだったため(つまり、クライアントの依存関係の競合)、また、インストルメンテーションがそれぞれで少し異なっていたために、それぞれが固有のモジュール/プラグインを持つことが理に適っていました。どちらも同じテクノロジーのサポートを意図していたため、共通の親モジュールの下に入れ子にして、下記の構造にしました。
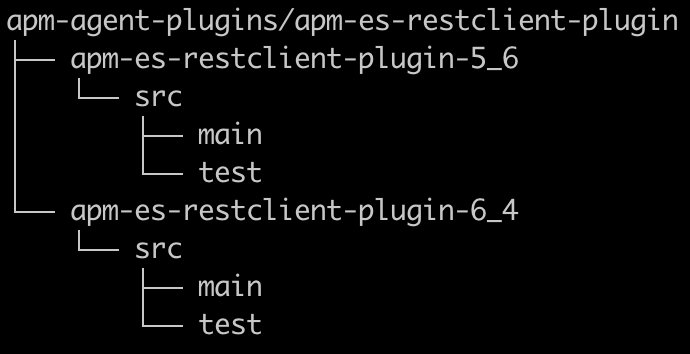
重要なのは、実際のプラグインコードのみがエージェントにパッケージされるため、pom.xmlではライブラリの依存関係のスコープはprovidedとなり、テストの依存関係のスコープはtestとなることです。サードパーティのコードを追加した場合は、シェードする必要があります。つまり、再パッケージしてElastic APM Javaエージェントのルートパッケージ名を使用します。
実際のコードについては、以下がプラグインの追加に関する最小要件となります。
Instrumentationクラス
ElasticApmInstrumentation抽象クラスの実装です。これはインストルメンテーションの正しいクラスとメソッドの特定に役立ちます。タイプとメソッドのマッチングによってアプリケーションの起動時間が相当長くなる場合があるため、インストルメンテーションクラスがマッチングプロセスを強化するフィルターとなります。たとえば、クラスの名前に特定の文字列が含まれていない場合、またはクラスローダーにロードされたクラスで、探しているタイプに対する可視性がまったくない場合、それらのクラスは無視されます。また、これにより、設定を通じてインストルメンテーションをオンおよびオフに変えるいくつかのメタ情報が提供されます。
ElasticApmInstrumentationがサービスとして使用されていることに注意してください。つまり、各実装はプロバイダー設定ファイルにリストされる必要があるということです。
サービスプロバイダー設定ファイル
ElasticApmInstrumentationの実装はサービスプロバイダーであり、リソースディレクトリMETA-INF/servicesにあるプロバイダー設定ファイルを介して実行時に識別されます。プロバイダー設定ファイルの名前はサービスの完全修飾名であり、このファイルにはサービスプロバイダーの完全修飾名のリストが含まれています(1行に1つずつ)。
Adviceクラス
これは、トレースされたメソッドにインジェクトされる実際のコードを提供するクラスです。一般的なインターフェイスを実装するのではなく、通常はByte Buddyの @Advice.OnMethodEnterおよび/または@Advice.OnMethodExitアノテーションを使用します。これは、メソッドの開始および終了直前にインジェクトするコードをByte Buddyに指示する方法です(Throwableをスローして、または何もスローせずに)。機能豊富なByte Buddy APIにより、次のようなさまざまなことが可能になります。
- メソッド終了時に利用できるローカル変数をメソッド開始時に作成できます。
- メソッド引数、戻り値またはスローされた
Throwableを監視し、可能な場合は置換します(該当する場合)。 thisオブジェクトを監視します。
最終的に、私のElasticsearch RESTクライアントモジュール構造は次のようになりました。
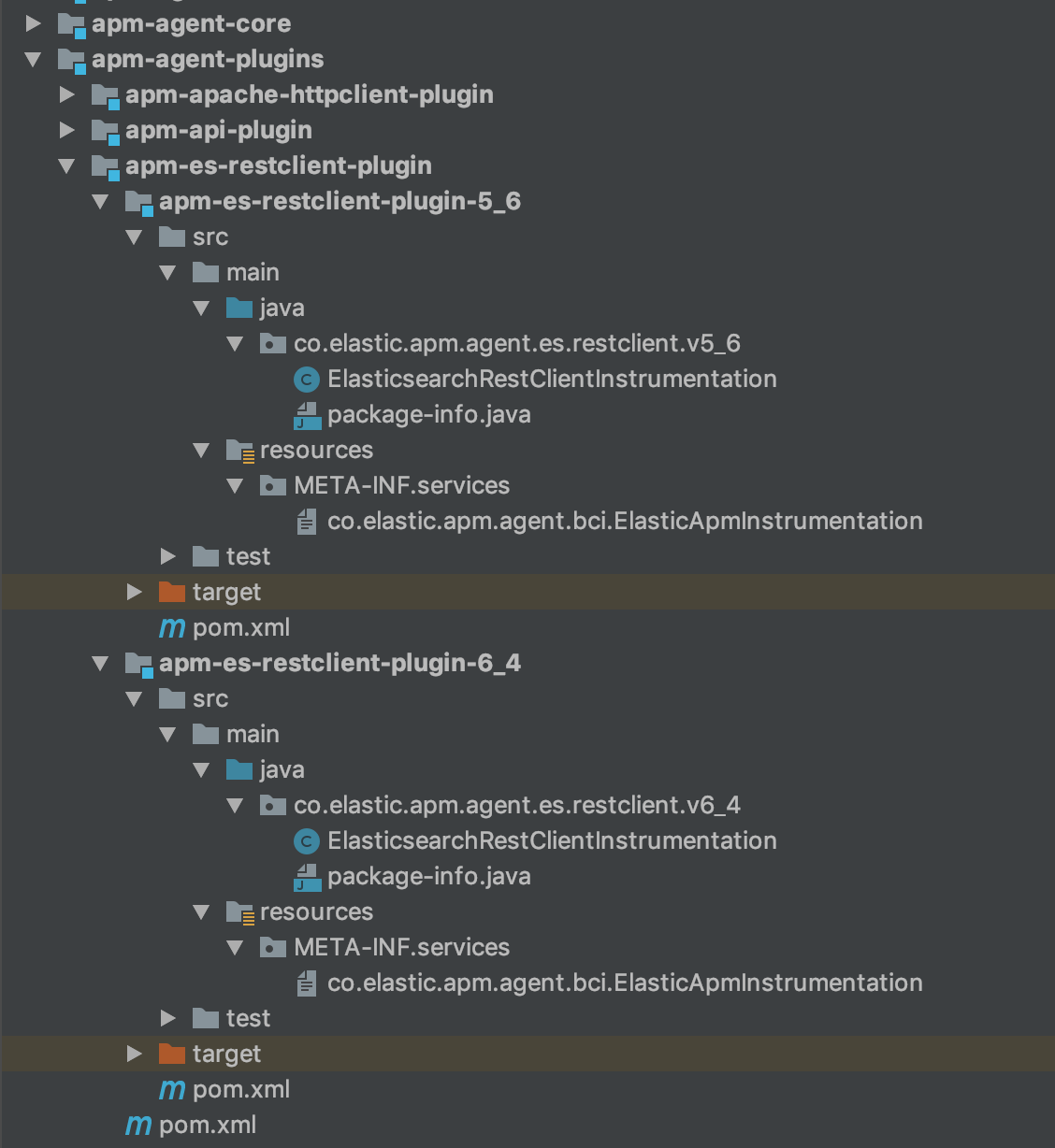
手順3:実装
上述のとおり、エージェントコードの記述には独自の特性がいくつかあります。このプラグインで、これらの概念がどのようにして生まれたのかについて見ていきましょう。
スパンの作成とメンテナンス
Elastic APMではスパンを使用して、HTTPリクエストの処理、DBクエリの作成、リモート呼び出しの実行など、特に関心のある各イベントを反映します。エージェントによって記録された、各スパンツリーのルートスパンは、トランザクションと呼ばれます(詳細についてはElasticのデータモデルに関するドキュメントをご覧ください)。ここでは、Spanを使用してElasticsearchクエリを説明しています。これはサービスに記録されたルートイベントではないからです。ここでのケースのように、プラグインは通常、スパンを作成し、それを有効化し、それにデータを追加して、最終的に無効化して終了します。有効化と無効化は、スレッドのコンテキストステータスを維持するアクションであり、これによって、コードの任意の場所の現在有効なスパンの取得が可能になります(スパン作成時に実行したのと同様)。スパンは終了される必要があり、有効化されたスパンは無効化される必要があるため、この点においてtry/finallyを使用することがベストプラクティスとなります。また、エラーが発生した場合は、それも報告する必要があります。
ユーザーコードを壊さない(そして副作用を回避)
「防御的な」コードを記述することに加えて、例外がスローされる可能性があることを常に前提としているため、アドバイスとしてsuppress = Throwable.classを使用しています。これによってByte Buddyには、アドバイスコードの実行中にスローされたすべてのThrowableタイプのExceptionハンドラーの追加が指示されます。こうすることで、インジェクトされたコードが失敗してもユーザーコードが実行されるようにすることができます。
また、アドバイスコードによって、インストルメントされたコードのステータスが変更され、結果としてその振る舞いに影響が出るという副作用が起きないようにする必要があります。私のケースでは、これはElasticsearchクエリのリクエスト本文の読み取りに該当しました。本文は、getContent APIを介してリクエストコンテンツのストリームを取得することで読み取られます。このAPIの実装の中には、呼び出しごとに新しいInputStreamインスタンスを返すものもあれば、リクエストごとの複数の呼び出しについて同じインスタンスを返すものもあります。実行時にどの実装が使用されるかを把握しているだけであるため、本文の読み取りがクライアントからの読み取りを妨げないようにする必要があります。幸いにも、それを知ることができるisRepeatable APIもあります。この保証ができないと、クライアントの機能を壊す可能性があります。
クラスの可視性
デフォルトでは、InstrumentationクラスはAdviceクラスでもあります。ただし、この2つには、その役割に起因する1つの重要な相違点があります。Instrumentationメソッドは、インストルメント対象のライブラリが実際に利用可能かまったく使用されていないかに関係なく、常に呼び出されます。一方、Adviceコードは、特定のライブラリの関連クラスが検出されたときのみ使用されます。私のAdviceコードは、リクエストに使用されるURL、リクエスト本文、 レスポンスコードなどの情報を取得するために、Elasticsearch RESTクライアントコードとの依存関係があります。したがって、Adviceコードを別のクラスにコンパイルし、必要な場合にはInstrumentationクラスによってのみ参照するようにすると安全です。多くの場合、Adviceコードは、インストルメントされたライブラリに依存することになるため、一般的にこれは良好なプラクティスだと考えられます。
パフォーマンスオーバーヘッドに関する考慮事項
実行を希望していた内容の1つに、_searchクエリの取得があります。これは、 InputStreamの形式でアクセスするHTTPリクエスト本文を読み取ることを意味します。本文のコンテンツをどこかに格納する必要があるということに対しては従うしかないため、メモリのオーバーヘッドは少なくとも、トレースされた各リクエストで読み取りを許可した本文の長さになります。ただし、メモリの割り当てに関してはやるべきことがたくさんあります。メモリはCPUに影響し、ガーベージコレクションの実行時には一時停止します。そのため、ByteBufferを再利用して、ストリームから読み込んだバイトをコピーし、 CharBufferを使用してクエリコンテンツを格納します。その後、このコンテンツはシリアル化され、APMサーバーとさらにはCharsetDecoderに送信されます。このようにすることで、リクエストごとにメモリを割り当ておよび割り当て解除しなくて済みます。これには多少複雑なコード(IOUtilsクラス内のコード)を使用することになりますが、オーバーヘッドを減少させることができます。
結果
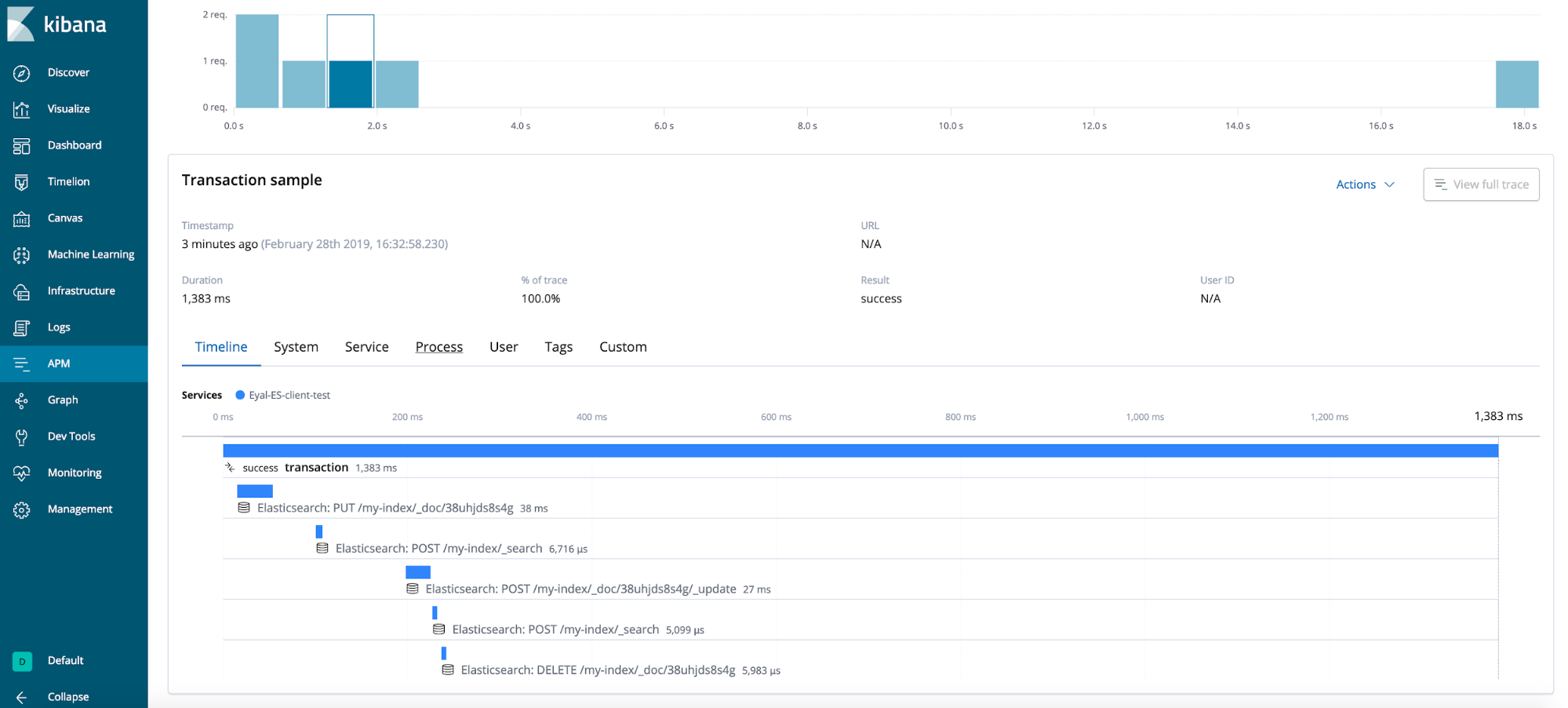
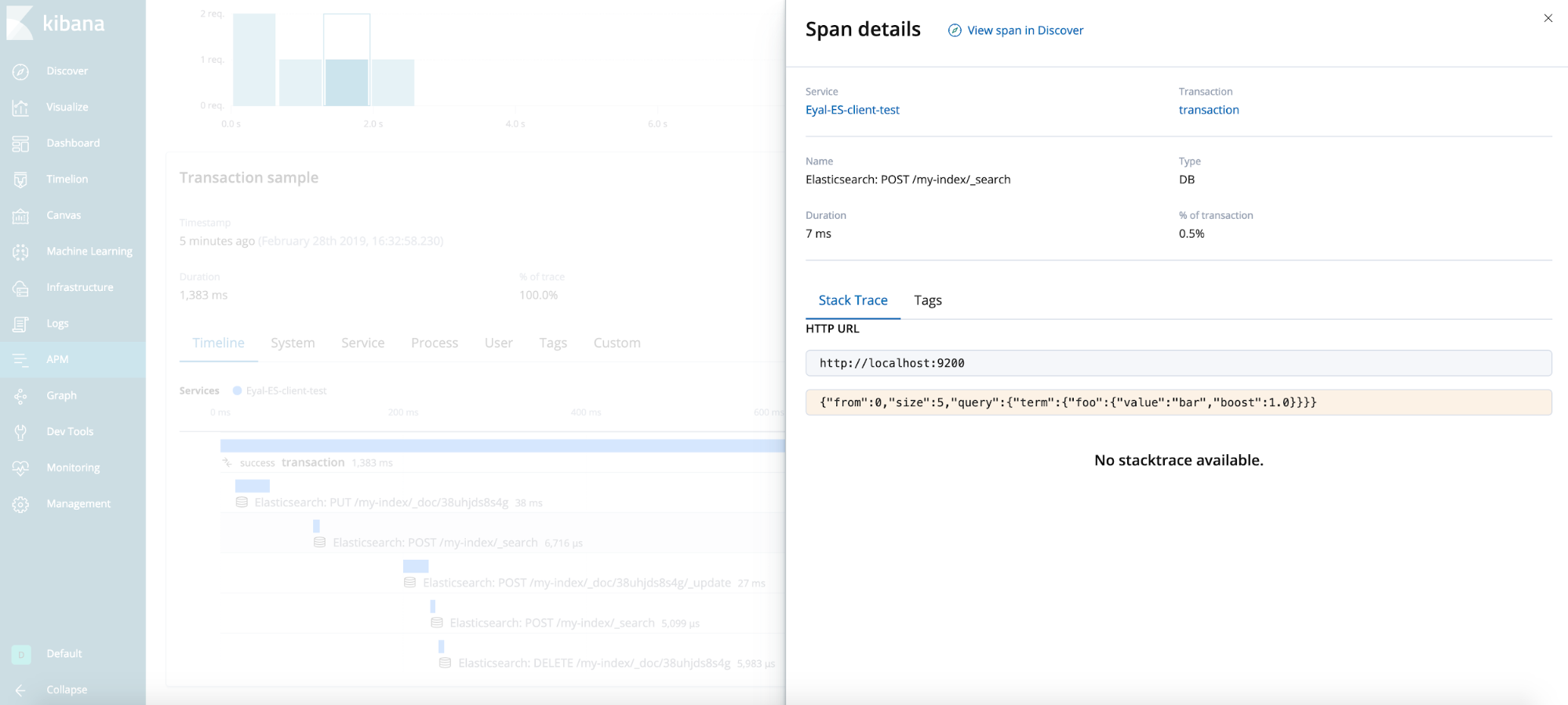
一般的なヒント(テストケースで示されていないもの)
入れ子にした呼び出しに注意
ケースによっては、APIメソッドをインストルメントする際に、インストルメントされた1つのメソッドが別のインストルメントされたメソッドを呼び出す場合があります。たとえば、オーバーライドメソッドがそのスーパークラスのメソッドを呼び出す、またはAPIの1つの実装が別のAPIをラッピングするなどです。同一のアクションに複数のスパンがレポートされないようにするために、このようなシナリオに注意することが重要です。いつ適用され、いつ適用されないかを規定する規則はなく、異なるシナリオ/設定では異なる振る舞いとなる可能性があるため、ここでのヒントとしては、そのようなことを認識してコードを記述するということです。
自己監視に気を付ける
トレースしているコードが、トレースされるアクションを呼び出さないようにする必要があります。そうしないと、トレースプロセス自体のオペレーションがトレースされてレポートされる場合や、最悪のケースではスタックオーバーフローが発生することもあります。例として、JDBCトレースがあります。 java.sql.Connection#getMetaData APIを使用してDBの情報を取得しようとすると、DBクエリが発生し、それがトレースされて別のjava.sql.Connection#getMetaDataが呼び出され、これが繰り返されるというケースです。
非同期オペレーションに気を付ける
非同期の実行では、スパン/トランザクションがスレッドに作成され、別のスレッドで有効化される可能性があります。各スパン/トランザクションは1回のみで終了され、それが有効化された各スレッドで常に無効化される必要があります。この点を必ず認識しておく必要があります。