RAG avec un contexte auquel vous pouvez faire confiance
Les applications d'IA doivent fournir des résultats précis à grande échelle pour gagner la confiance des utilisateurs. Appuyez-vous sur la précision de la recherche hybride d'Elasticsearch pour alimenter les grands modèles de langage (LLM), et déployez à l'échelle la génération augmentée par récupération (RAG) qui offre une faible latence et une efficacité optimale.
RAG conçue pour une précision inégalée et un scaling vectoriel efficace
Fournissez le contexte adéquat avec les performances vectorielles, la rentabilité et la sécurité requises en production.
Donnez à vos applications RAG le contexte adéquat grâce à la recherche hybride, au reclassement sémantique et à l'inférence intégrée, en utilisant des modèles Jina AI de pointe, natifs ou tiers. Remplacez la recherche vectorielle classique par une requête unique combinant mots-clés, vecteurs et filtres.

Scalez le contexte sur des milliards de documents, qu'il s'agisse de données structurées, non structurées ou vectorielles, sans compromis entre la qualité du rappel et les ressources utilisées. La quantification et les algorithmes optimisés pour le disque, comme DiskBBQ, réduisent l'utilisation de la mémoire jusqu'à 95 % tout en maintenant une qualité de classement élevée et une faible latence.

Simplifiez votre pipeline grâce à une plateforme unifiée qui extrait le contexte des documents ainsi que des enregistrements structurés et non structurés en une seule requête. Mettez en place des contrôles d'accès au niveau du document et des contrôles basés sur les rôles (RBAC) afin que les LLM n'exposent que les données accessibles aux utilisateurs autorisés.
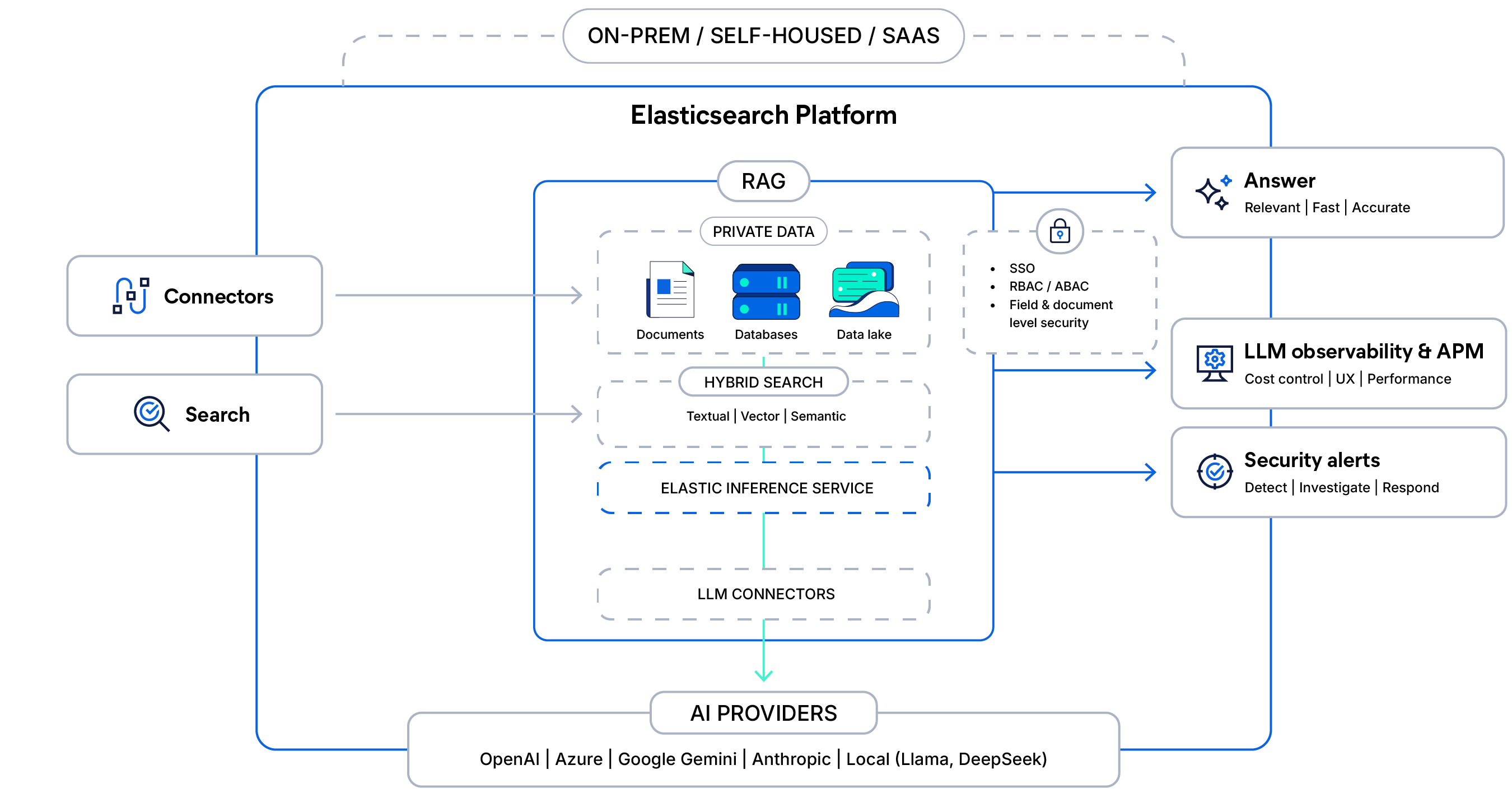
L'architecture à l'appui de la RAG contextuelle
Connectez vos données privées grâce à la recherche hybride sécurisée et à l'inférence gérée, ancrez les réponses LLM avec des contrôles d'accès et fournissez des réponses rapides, observables et prêtes pour la production à grande échelle.
Que construisez-vous ?
Créez des chats basés sur vos données et des agents guidés par le contexte. Explorez notre catalogue complet de formations ou suivez nos tutoriels sur Elasticsearch Labs.

Questions-réponses sur vos données. Construisez un système RAG avec Gemma, Hugging Face et Elasticsearch.

Accélérez le développement d'applications RAG agentiques avec LangGraph et Elasticsearch.

Elastic a créé un assistant de support technique alimenté par l'IA générative : explorez l'architecture, les techniques et les bonnes pratiques pour créer le vôtre.
Questions fréquentes
Qu'est-ce que la génération augmentée de récupération (RAG) dans l'IA ?
Qu'est-ce que la génération augmentée de récupération (RAG) dans l'IA ?
La génération augmentée par récupération (communément appelée RAG) est un modèle de traitement du langage naturel qui permet aux entreprises de rechercher des sources de données propriétaires et de fournir un contexte qui ancre les grands modèles de langage. Cela permet d'obtenir des réponses plus précises et en temps réel dans les applications d'IA générative.
Quels sont les avantages de la génération augmentée de récupération (RAG) ?
Quels sont les avantages de la génération augmentée de récupération (RAG) ?
Lorsqu'elle est mise en œuvre de manière optimale, la RAG offre un accès sécurisé aux données propriétaires pertinentes et spécifiques au domaine en temps réel. Elle peut réduire l'incidence des hallucinations dans les applications d'IA générative et augmenter la précision des réponses.
Quels sont les avantages de l'utilisation d'Elastic pour les workflows RAG ?
Quels sont les avantages de l'utilisation d'Elastic pour les workflows RAG ?
Elastic rend les systèmes RAG opérationnels en prenant en charge nativement les aspects les plus complexes : l'ingestion et l'intégration de données de haute qualité, la recherche précise et efficace à grande échelle, la mise en œuvre d'une sécurité au niveau du document et des rôles, et la préservation de l'attribution des sources pour des réponses fiables. Grâce à la recherche vectorielle, lexicale et hybride native, aux modèles propriétaires comme ELSER et à l'intégration flexible de modèles tiers au sein de l'écosystème d'IA générative, ainsi qu'à des performances éprouvées à l'échelle de l'entreprise, Elastic aide les équipes à concevoir des systèmes RAG plus rapides à lancer, plus faciles à paramétrer et plus fiables en production.
Comment Elasticsearch permet-il l'ingénierie du contexte ?
Comment Elasticsearch permet-il l'ingénierie du contexte ?
Elasticsearch est conçu pour une pertinence à grande échelle, fondement de l'ingénierie du contexte. Il réunit la recherche vectorielle, par mots-clés et structurée avec l'analyse, l'inférence et l'observabilité sur une plateforme unique. Les développeurs peuvent ainsi facilement stocker, récupérer et classer avec précision les données métier structurées et non structurées, garantissant aux agents un contexte toujours pertinent.
Avec Agent Builder, Elasticsearch va encore plus loin en intégrant directement à sa plateforme le chat, la récupération de données, la création d'outils et l'orchestration. Les développeurs peuvent ainsi créer, tester et déployer à grande échelle des agents contextuels en quelques minutes, en utilisant leurs propres données, modèles et outils, le tout bénéficiant de la pertinence, de la sécurité et des performances garanties par Elasticsearch.