Ce que vous respirez : analyser les données sur la qualité de l'air avec Elasticsearch sur Elastic Cloud
La Suite Elastic a largement fait ses preuves pour ce qui est de la collecte, de l'indexation et de la fourniture d'informations utiles à partir des données. Non seulement la gestion intégrée des informations est possible, mais, comme nous le verrons dans cette série de billets, elle peut même être agréable. Nous observerons la totalité du processus, des données brutes et vides de sens aux conclusions sur lesquelles les citadins d'aujourd'hui peuvent s'appuyer pour améliorer leur vie de tous les jours.
L'augmentation constante de la population dans les grandes villes du monde pose de nombreux problèmes, notamment la pollution de l'air, qui est sans doute l'un des problèmes ayant le plus d'impact sur la santé des habitants. Dans le cadre d'un effort pour informer les citoyens et prendre des mesures d'urgence, certaines institutions publiques ont déployé une multitude de capteurs pour récolter des informations sur la concentration de différents polluants dans la ville.
Ces mesures relevant de la responsabilité des institutions publiques, il n'est pas rare qu'elles soient publiées et mises à disposition de quiconque souhaite y accéder. C'est le cas des échantillons prélevés dans l'une des plus grandes villes européennes (pour ce qui est de la population, qui s'élève à plus de trois millions d'habitants) : Madrid.
Voyons comment Elasticsearch permet de faire parler facilement ces mesures chimiques obscures pour qu'elles révèlent les habitudes des Madrilènes.
Des fichiers CSV aux documents Elasticsearch
Nous devons d'abord observer la source des données. La mairie de Madrid dispose d'un portail de données ouvertes qui permet d'accéder à un jeu de données de mesures horaires de la qualité de l'air (en espagnol).
Sur ce portail, on peut obtenir un point de terminaison HTTP délivrant un fichier CSV actualisé toutes les heures et contenant les mesures du jour, jusqu'à la dernière heure écoulée.
Chaque ligne du fichier correspond à une paire de clés (Lieu, Produit chimique) et contient les mesures heure par heure pour la journée complète. Chaque valeur horaire est notée dans une colonne.
| ... | STATION | PRODUIT CHIMIQUE | ... | MOIS | JOUR | 0 h Mesure | 0 h Valide ? | ... | 23 h Mesure | 23 h Valide ? |
| Numéro (code) | Code (code) | Numéro | Numéro | Numéro | "V" ou "F" (Vrai/Faux) | Numéro | "V" ou "F" (Vrai/Faux) |
Des valeurs numériques sont attribuées aux champs tels que STATION et PRODUIT CHIMIQUE. Elles sont respectivement associées à des positions géographiques et à des formulations de composés chimiques. Cette association est indiquée dans des tableaux présents sur le site de source de données.
À l'inverse, les mesures horaires ("Mesure x h") et les marqueurs permettant de savoir si elles sont valides ("x h valide ?") sont indiqués par des valeurs brutes. Les unités sont indiquées dans un autre tableau de la spécification de source, tandis que l'indicateur de validation peut avoir la valeur "V" ou "F", signifiant "Verdadero" ou "Falso" ("Vrai" ou "Faux" en espagnol).
Les résultats des échantillonnages de produits chimiques sont représentés sous la forme de mesures dans l'espace et dans le temps. Cela vous rappelle quelque chose ? Eh oui : les séries temporelles d'événements spatiaux. Cela veut dire que les lignes ne correspondent pas à des événements. Au contraire, chaque ligne rassemble jusqu'à 24 événements, qui partagent tous le même lieu et le même composé chimique.
Si nous encodions chaque événement dans un document JSON, cela ressemblerait à l'exemple ci-dessous :
{
"timestamp": 1532815200000,
"location": {
"lat": 40.4230897,
"lon": -3.7160478
},
"measurement": {
"value": 7,
"chemical": "SO2",
"unit": "μg/m^3"
}
}
Par ailleurs, on pourrait facilement l'enrichir avec les limites de l'Organisation mondiale de la santé (OMS) en ajoutant simplement un champ supplémentaire dans le sous-document de mesures. La séparation de chaque ligne du fichier CSV en plusieurs documents JSON permet de mieux les comprendre, et de les ingérer encore plus facilement dans Elasticsearch.
{
"timestamp": 1532815200000,
"location": {
"lat": 40.4230897,
"lon": -3.7160478
},
"measurement": {
"value": 7,
"chemical": "SO2",
"unit": "μg/m^3",
"who_limit": 20
}
}
L'ensemble de tous les documents correspondant à cette structure peut être décrit à l'aide d'un autre document JSON. Cela constitue un mapping dans Elasticsearch, que nous allons utiliser pour décrire la manière dont les documents sont stockés dans un index donné.
{
"air_measurements": {
"properties": {
"timestamp": {
"type": "date"
},
"location": {
"type": "geo_point"
},
"measurement": {
"properties": {
"value": {
"type": "double"
},
"who_limit": {
"type": "double"
},
"chemical": {
"type": "keyword"
},
"unit": {
"type": "keyword"
}
}
}
}
}
}
Déployez un cluster en quelques secondes sur Elastic Cloud
À ce stade, vous pouvez configurer un cluster Elasticsearch localement, ou commencer une période d'essai gratuit de 14 jours d'Elasticsearch Service sur Elastic Cloud. Découvrez comment déployer un nouveau cluster en quelques clics seulement. Pour cette démonstration, je vais utiliser Elastic Cloud.
Une fois connecté à Elastic Cloud, vous devrez déployer un nouveau cluster. Pour évaluer la taille du cluster pour ce cas d'utilisation, il faut savoir qu'un fichier JSON d'événements de mesure sur un mois prend environ 34 Mo d'espace disque (avant l'indexation) : nous pouvons donc utiliser le plus petit cluster proposé (1 Go de RAM, 24 Go d'espace disque). Ce petit cluster devrait être suffisant pour héberger nos données de départ. Elastic Cloud permet une montée en charge en toute simplicité. Si nécessaire, il sera toujours possible d'augmenter la taille plus tard, de modifier le nombre de zones de disponibilité ou d'apporter d'autres modifications à notre cluster.
En moins de temps qu'il n'en faut pour préparer un plat au micro-ondes, notre cluster Elasticsearch est prêt à recevoir et à indexer notre ensemble d'événements de mesure.
Extraire, transformer, charger
Personne ne voudrait devoir effectuer manuellement le passage du fichier CSV d'origine à un ensemble de documents JSON pour coder des mesures. (En fait, cela rappelle plutôt un châtiment sisyphéen.) C'est une tâche qu'il faut automatiser.
Pour cela, commençons par dresser un script d'automatisation pour aplatir le tableau CSV en documents JSON. Nous allons utiliser Scala pour cette étape :
- c'est un langage qui permet de se concentrer sur le flux de données plutôt que sur le flux du programme. Il propose ainsi des opérations pour transformer facilement des collections de documents ;
- il est fourni avec de nombreuses bibliothèques de manipulation JSON ;
- grâce à Ammonite, il est possible d'écrire des scripts de manipulation de données en un clin d'œil.
L'extrait de script extractor.sc ci-dessous condense la logique de transformation :
// Récupérer le fichier sur le portail de données ouvertes de la mairie de Madrid
lazy val sourceLines = scala.io.Source.fromURL(uri).getLines().toList
sourceLines.headOption foreach { head =>
/* La première ligne du fichier CSV contient les noms des étiquettes, il est facile
de calculer une carte à partir des étiquettes aux positions pour rendre le reste du code
plus lisible. */
lazy val label2pos = head.split(";").zipWithIndex.toMap
// Pour chaque ligne, produire facilement plusieurs événements avec flatMap
lazy val entries = sourceLines.tail flatMap { rawEntry =>
val positionalEntry = rawEntry.split(";").toVector
val entry = label2pos.mapValues(positionalEntry)
/* Les 8 premières positions sont utilisées pour extraire les informations communes aux
24 mesures horaires. */
val stationId = entry("ESTACION").toInt
val ChemicalEntry(chemical, unit, limit) = chemsTable(entry("MAGNITUD").toInt)
// Les valeurs de mesure sont contenues dans les 24 dernières colonnes
positionalEntry.drop(8).toList.grouped(2).zipWithIndex collect {
case (List(value, "V"), hour) =>
val timestamp = new DateTime(
entry("ANO").toInt,
entry("MES").toInt,
entry("DIA").toInt,
hour, 0, 0
)
// Et voilà : l'événement généré comme classe de cas.
Entry(
timestamp,
location = locations(stationId),
measurement = Measurement(value.toDouble, chemical, unit, limit)
)
}
}
- Récupérer le dernier rapport horaire publié, qui contient les mesures réalisées jusqu'à l'heure qui vient de s'écouler.
- Pour chaque ligne :
- Extraire les champs communs à tous les événements générés à partir de la ligne (ID de la station et produit chimique mesuré).
- Extraire les mesures correspondant à celles réalisées actuellement pendant la journée (24 max). Filtrer les valeurs qui ne sont pas marquées comme des mesures valides.
- Pour chacune d'entre elles, générer l'horodatage de la mesure en associant la date de la ligne et le numéro de la colonne de mesure. Combiner les champs communs de la ligne, l'horodatage et la valeur enregistrée en un seul objet d'événement (Entrée).
Le script continue à sérialiser les objets Entrée comme documents JSON et à les imprimer dans une succession de JSON indépendants.
Extractor.sc peut recevoir des arguments lui ordonnant de récupérer les données pour les transformer à partir d'autres sources, comme des fichiers locaux, ou d'ajouter des actions requises par l'API Bulk d'Elasticsearch lors du chargement de fichiers de journée entière en une seule fois.
extracteur --uri String (default http://www.mambiente.munimadrid.es/opendata/horario.csv) --bulkIndex --bulkType
Envoyer des données à Elasticsearch
Nous avons maintenant un script qui se charge de traduire les fichiers CSV en listes de documents. Comment les indexer ? C'est simple : il suffit de passer quelques appels à notre cluster.
Création d'index
Pour commencer : il faut créer l'index. Nous avons déjà créé un JSON pour nos mappings de documents et nous pouvons l'intégrer à notre définition d'index : ./payloads/index_creation.json
{
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"air_measurements" : {
"properties" : {
"timestamp": { "type": "date" },
"location" : { "type" : "geo_point" },
"measurement": {
"properties": {
"value": { "type": "double" },
"who_limit": { "type": "double" },
"chemical": { "type": "keyword" },
"unit": { "type": "keyword" }
}
}
}
}
}
}
Transférons-le au point de terminaison de création d'index de notre cluster :
curl -u "$ESUSER:$ESPASS" -X PUT -H 'Content-type: application/json' \
"$ESHOST/airquality" \
-d "@./payloads/index_creation.json"
Nous obtenons alors l'index airquality (qualité de l'air).
Chargement groupé (bulk)
L'API Bulk est la méthode la plus rapide pour charger toutes ces données dans Elasticsearch. Cette méthode consiste à établir une connexion, à charger un ensemble de documents, et à terminer l'opération. Pour charger les documents un par un, il faudrait établir une connexion TCP, envoyer le document, recevoir une confirmation, et fermer la connexion pour chaque mesure de chaque ligne du fichier CSV. C'est beaucoup trop inefficace.
Comme indiqué par la documentation de l'API Bulk, vous devez charger un fichier NDJSON avec deux lignes par document :
- une avec l'action à effectuer dans Elasticsearch
- et l'autre avec le document concerné par cette action. L'action qui nous intéresse est l'indexation.
L'outil extractor.sc est donc fourni avec deux options supplémentaires permettant de contrôler l'action d'indexation et son apparence juste avant chaque document :
- bulkIndex INDEX : si cette étape est passée, le script d'extraction passe à chaque document par le biais d'une action index dans INDEX.
- bulkType TYPE : si cette étape passe après bulkIndex, termine l'action d'indexation avec le type auquel le document doit correspondre.
/* L'ensemble d'événements est ensuite sérialisé et imprimé dans la sortie standard.
Cela permet de les utiliser comme fichier ndjson.
*/
val asJsonStrings = entries flatMap { (entry: Entry) =>
Some(bulkIndex).filter(_.nonEmpty).toList.map { index =>
val entryId = {
import entry._
val id = s"${timestamp}_${location}_${measurement.chemical}"
java.util.Base64.getEncoder.encodeToString(id.getBytes)
}
/* En option, il est aussi possible de sérialiser les actions groupées pour améliorer la performance
du transfert de données. */
BulkIndexAction(
BulkIndexActionInfo(
_index = index,
_id = entryId,
_type = Some(bulkType).filter(_.nonEmpty)
)
).asJson.noSpaces
} :+ entry.asJson.noSpaces
}
asJsonStrings.foreach(println)
Cela permet de générer notre fichier NDJSON massif contenant toutes les entrées de la journée :
time ./extractor.sc --bulkIndex airquality --bulkType air_measurements > today_bulk.ndjson
En 1,46 seconde, il a généré le fichier que nous pouvons envoyer à l'API Bulk comme suit :
time curl -u $ESUSER:$ESPASS -X POST -H 'Content-type: application/x-ndjson' \
$ESHOST/_bulk \
--data-binary "@today_bulk.ndjson" | jq '.'
Il a fallu 0,98 seconde pour terminer la requête de chargement.
Avec cette méthode, le temps total de l'opération a été de 2,44 secondes (1,46 seconde à partir de la récupération et de la transformation de données et 0,98 seconde à partir de la requête de chargement groupé) : c'est 182 fois plus rapide qu'en chargeant les documents un par un. Vous avez bien lu : 2,44 secondes contre 7 minutes et 26 secondes.
La conclusion importante est la suivante : utilisez l'API bulk pour les processus qui indexent de grandes quantités de documents.
Des données aux informations
Toutes nos félicitations pour ce (très) bon choix. Nous avons atteint le point où les mesures de l'air de la ville sont indexées dans Elasticsearch. Cela signifie, par exemple, que nous pouvons facilement rechercher et récupérer des données, d'une manière beaucoup plus simple que s'il fallait télécharger, extraire et rechercher manuellement les informations qui nous intéressent.
Prenez ce cas d'étude, par exemple. Si, après avoir admiré Les Ménines, nous devions choisir entre :
- profiter du beau temps à Madrid, et
- continuer à profiter du musée du Prado
nous pourrions demander à Elasticsearch de nous conseiller le meilleur choix pour notre santé, en lui demandant de nous indiquer la dernière mesure de NO2 effectuée à la station météorologique la plus proche, dans un rayon de 1 km : ./es/payloads/search_geo_query.json
{
"size": "1",
"sort": [
{
"timestamp": {
"order": "desc"
}
},
{
"_geo_distance": {
"location": {
"lat": 40.4142923,
"lon": -3.6912903
},
"order": "asc",
"unit": "km",
"distance_type": "plane"
}
}
],
"query": {
"bool": {
"must": {
"match": {
"measurement.chemical": "NO2"
}
},
"filter": {
"geo_distance": {
"distance": "1km",
"location": {
"lat": 40.4142923,
"lon": -3.6912903
}
}
}
}
}
}
curl -H "Content-type: application/json" -X GET -u $ESUSER:$ESPASS $ESHOST/airquality/_search -d "@./es/payloads/search_geo_query.json"
Et recevoir la réponse suivante :
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4248,
"max_score": null,
"hits": [
{
"_index": "airquality",
"_type": "air_measurements",
"_id": "okzC5mQBiAHT98-ka_Yh",
"_score": null,
"_source": {
"timestamp": 1532872800000,
"location": {
"lat": 40.4148374,
"lon": -3.6867532
},
"measurement": {
"value": 5,
"chemical": "NO2",
"unit": "μg/m^3",
"who_limit": 200
}
},
"sort": [
1532872800000,
0.3888672868035024
]
}
]
}
}
Ce qui nous indique que la station météorologique du Retiro rapporte un taux de 5 µg/m^3 de NO2. C'est un bon résultat, si l'on considère que la limite définie par l'OMS est de 200 µg/m^3. Profitons-en pour aller déguster quelques tapas !
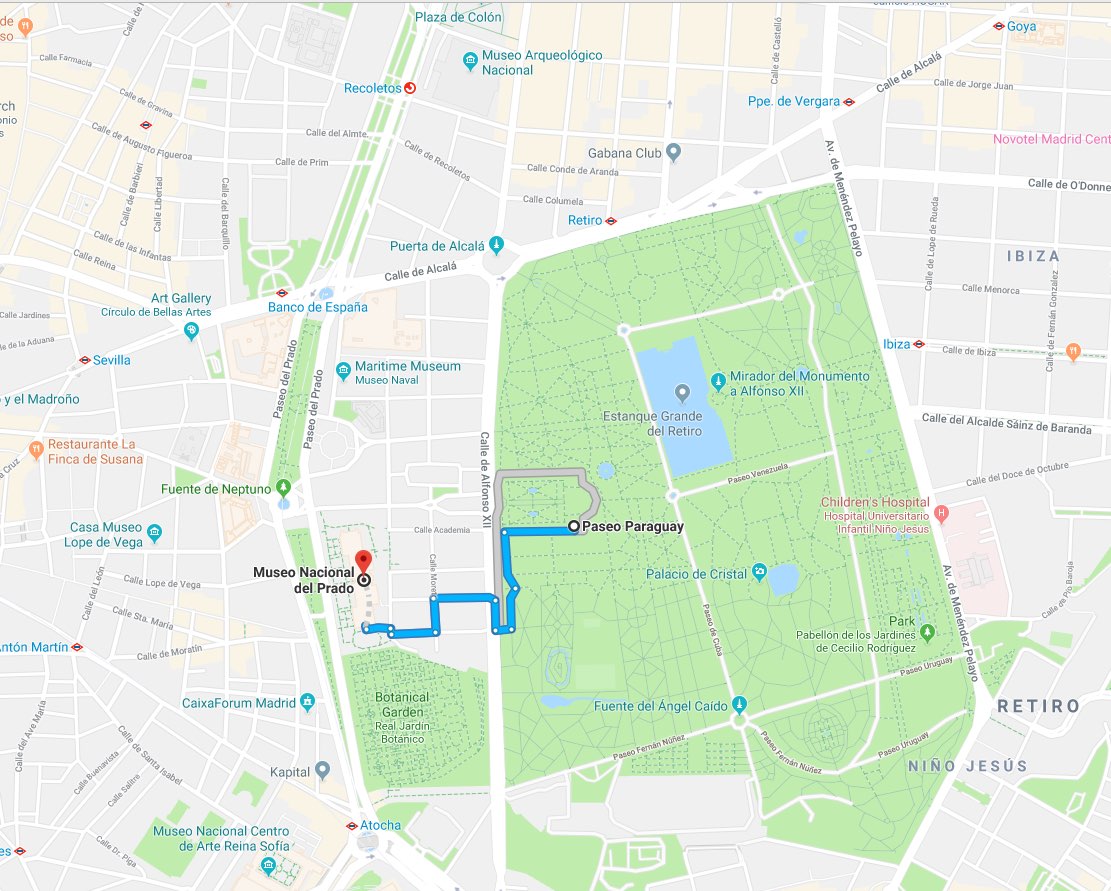
Pour être honnête, je n'ai jamais vu personne sortir son ordinateur portable pour saisir des commandes cURL dans un musée. Mais ces requêtes sont si faciles à coder dans pratiquement tous les langages de programmation qu'il est possible de fournir des applications en frontend en quelques jours. En effet, nous avons déjà un backend analytique complet avec notre index d'informations.
Voir l'invisible avec Kibana
Et si nous n'avions même pas besoin de composer l'application ? Et si, dans notre cluster actuel, nous pouvions simplement commencer à explorer les données en cliquant pour obtenir des informations pertinentes ? C'est tout à fait possible avec Kibana. Nous pouvons accéder au management de cluster sur cloud.elastic.co et cliquer sur le lien pour accéder à notre déploiement Kibana :
Kibana permet de créer des visualisations et des tableaux de bord complets à partir des documents indexés dans Elasticsearch.
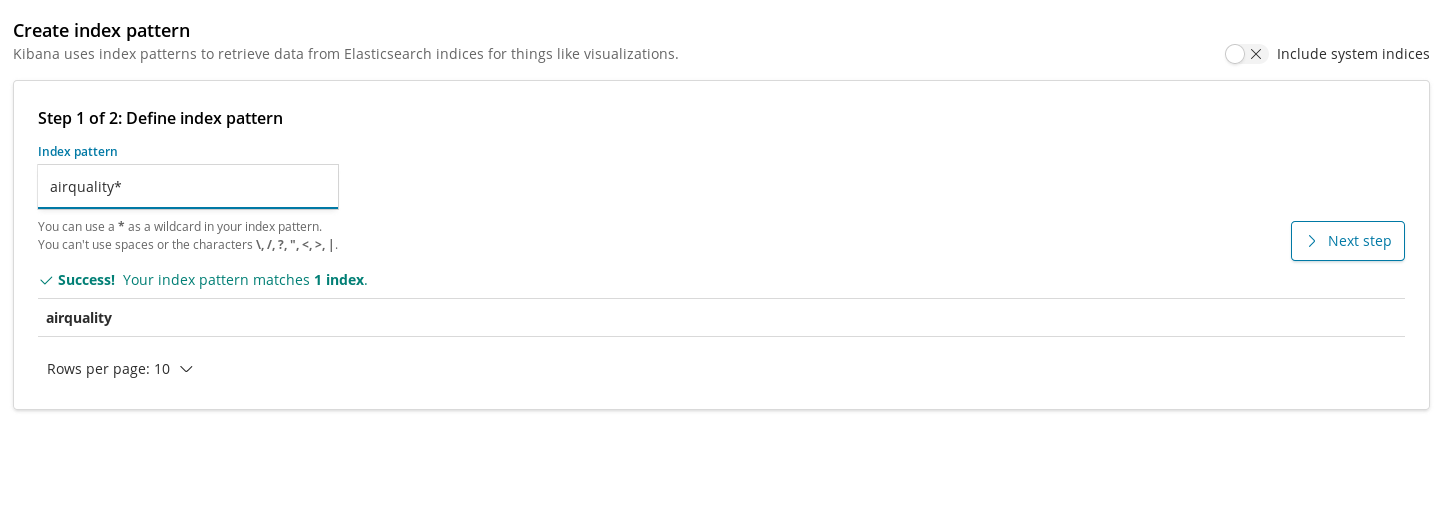
Les modèles d'indexation sont notre méthode pour enregistrer les index dans Kibana afin qu'ils puissent être utilisés par les visualisations pour extraire les données. Avant de créer des graphiques pour notre index airquality (qualité de l'air), la première étape est donc de déclarer cet index.
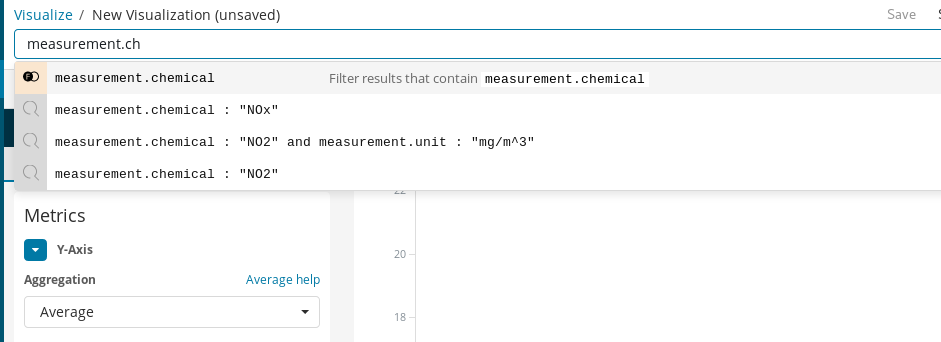
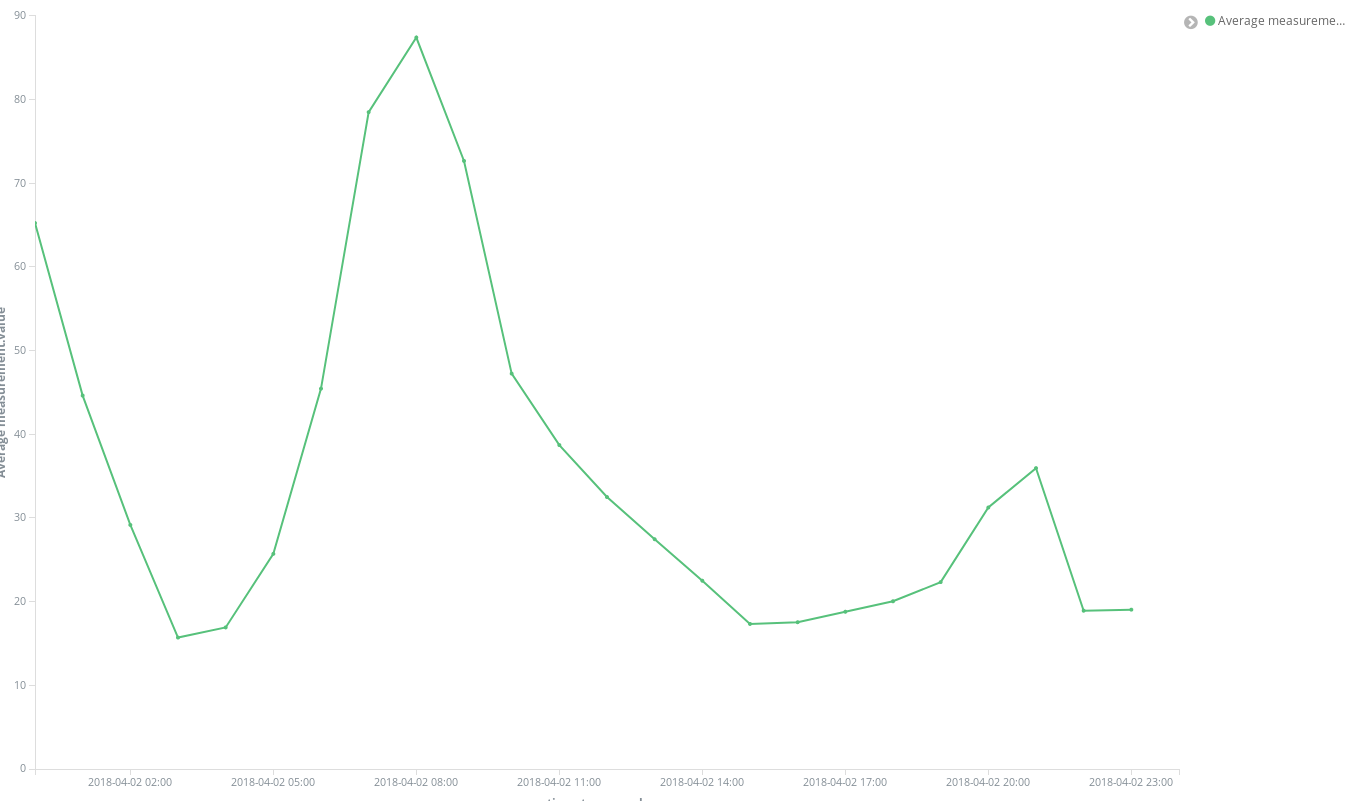
Après la création, nous pouvons ajouter notre première visualisation. Commençons par quelque chose de simple : un graphique de l'évolution des niveaux de concentrations moyennes d'un produit chimique dans la ville au fil du temps. Par exemple, le NO2 :
Tout d'abord, il faut créer un graphique linéaire dans lequel l'axe Y représente une agrégation moyenne pour le champ measurement.value (valeur.mesure) sur les intervalles horaires représentés sur l'axe X. Pour sélectionner le produit chimique qui nous intéresse, nous pouvons utiliser la barre de recherche de Kibana, qui permet de filtrer rapidement les mesures de NO2. De plus, en activant la fonction de saisie semi-automatique, nous pouvons obtenir des suggestions pour nous guider tout au long du processus de définition de la recherche.
Enfin, avec Time Range (Plage horaire), nous pouvons choisir la période des données visualisées.
Des résultats immédiats en quelques clics :
Les cartes de coordonnées sont l'un des graphiques les plus utiles à utiliser pour ce jeu de données. Comme chaque mesure contient les coordonnées de la station ayant effectué cette mesure, nous pouvons représenter les points chauds de la pollution. C'est-à-dire, passer d'une moyenne des entrées spatiales sur les intervalles de temps à une moyenne des entrées temporelles dans des emplacements spatiaux. Les intervalles sont désormais des agrégations Geohash par lieu, le champ contenant le point de mesure.
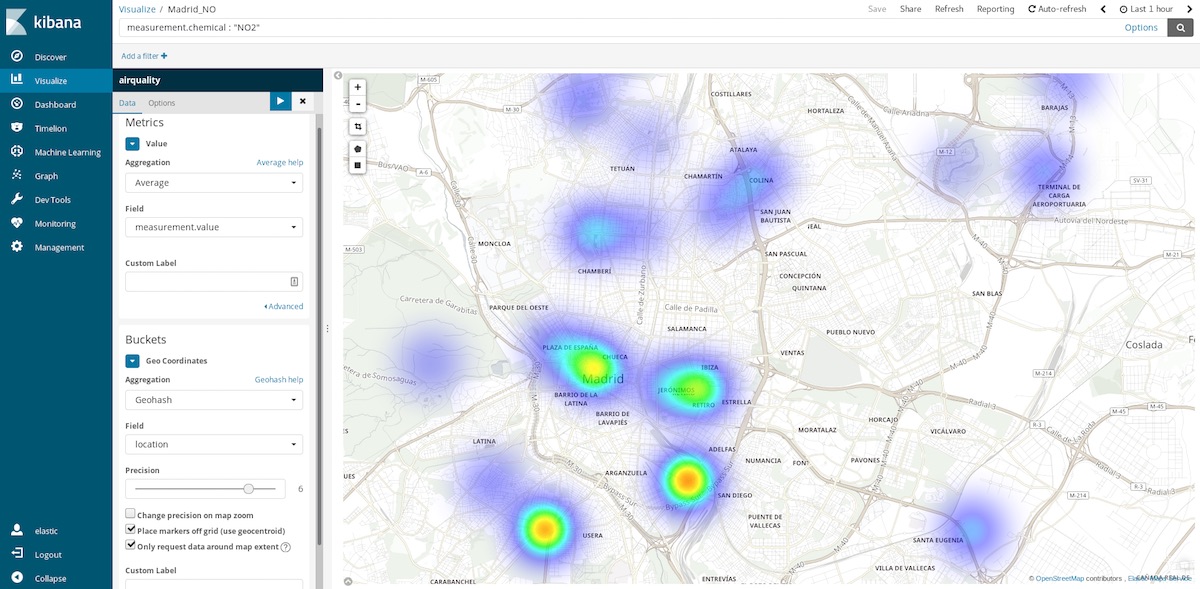
En sélectionnant la plage de la dernière heure écoulée, nous pouvons nous faire une idée des zones les plus propres à visiter en ce moment. Les plages annuelles nous indiquent les zones les plus propres en moyenne et peuvent nous aider, par exemple, à prendre une décision sur l'endroit où acheter une maison pour vivre plus sainement.
Champs scriptés
Comme nos documents suivent les niveaux recommandés par l'OMS pour certains produits chimiques, nous pouvons déterminer à quel point l'air est sain ou non. Par exemple, en utilisant une visualisation de jauge sur une proportion de la concentration mesurée et de la limite établie par l'OMS. Mais cette division n'a pas été effectuée lorsque nous avons chargé les données. Ce n'est pas un problème, car il est toujours possible de générer de nouveaux champs à partir des champs indexés à l'aide du langage de script Painless, qu'une personne ayant déjà utilisé Java n'aura aucun problème à comprendre et à utiliser (depuis Kibana 6.4, il est également possible d'obtenir un aperçu des résultats fournis par le script Painless).
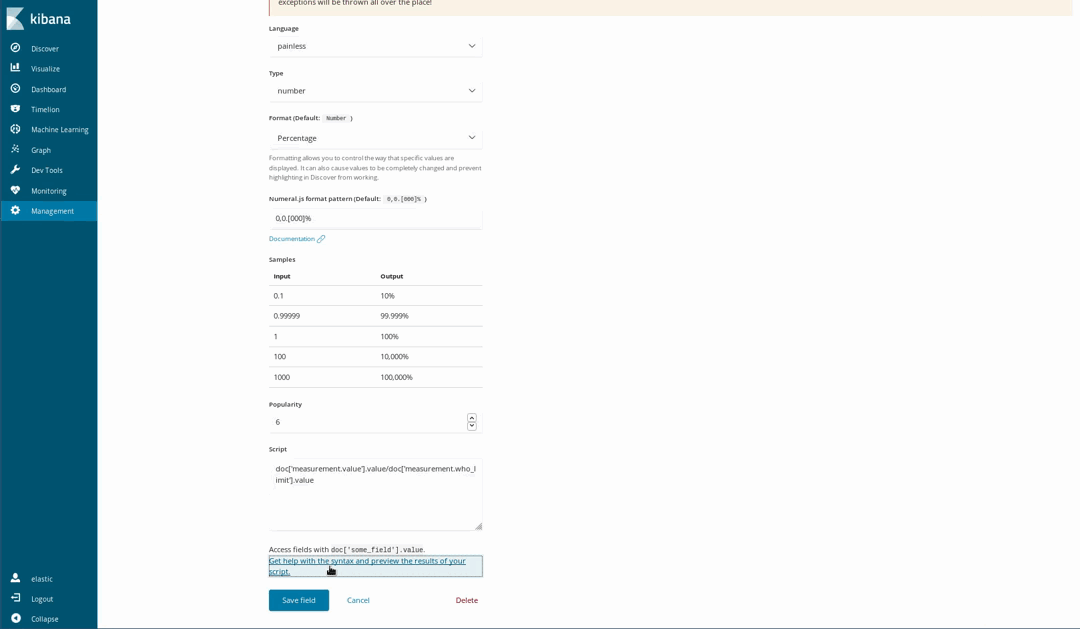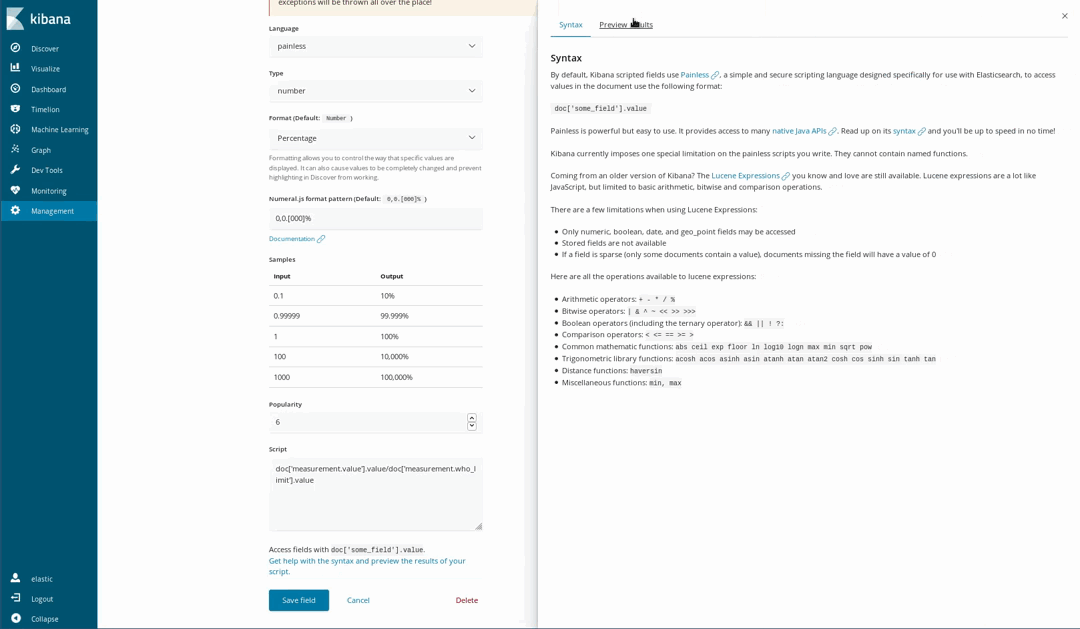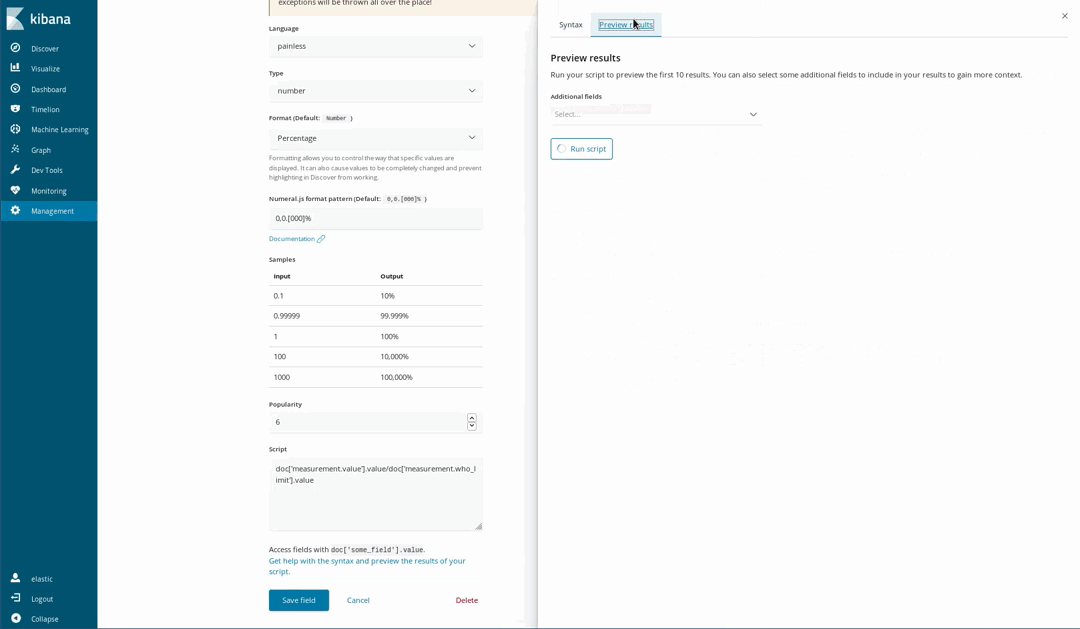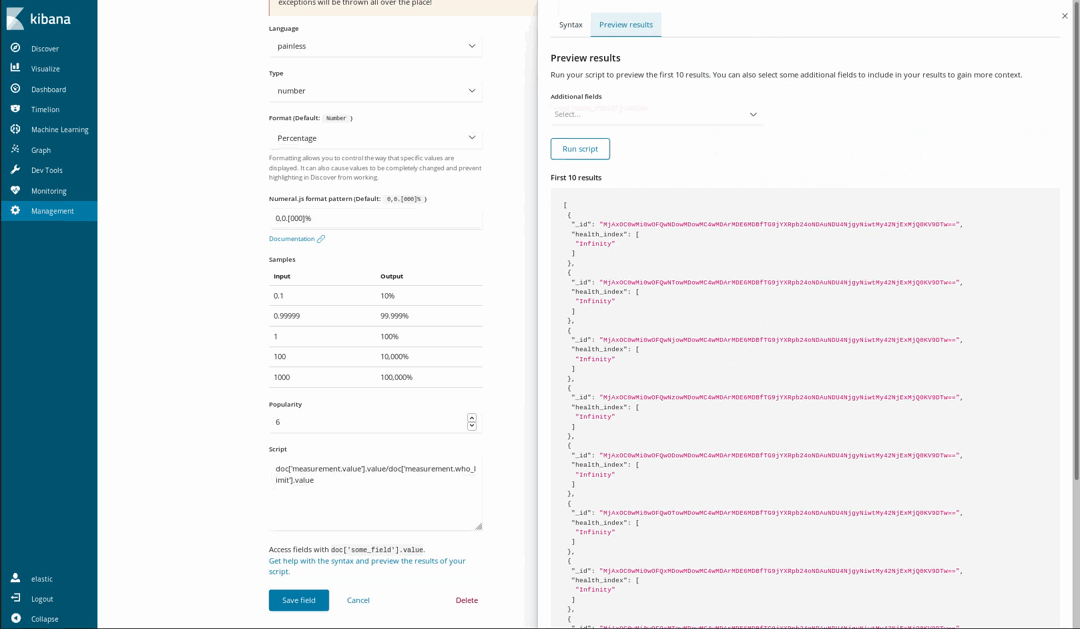
Nous pouvons ensuite les utiliser dans nos visualisations, comme s'il s'agissait de champs indexés ordinaires :
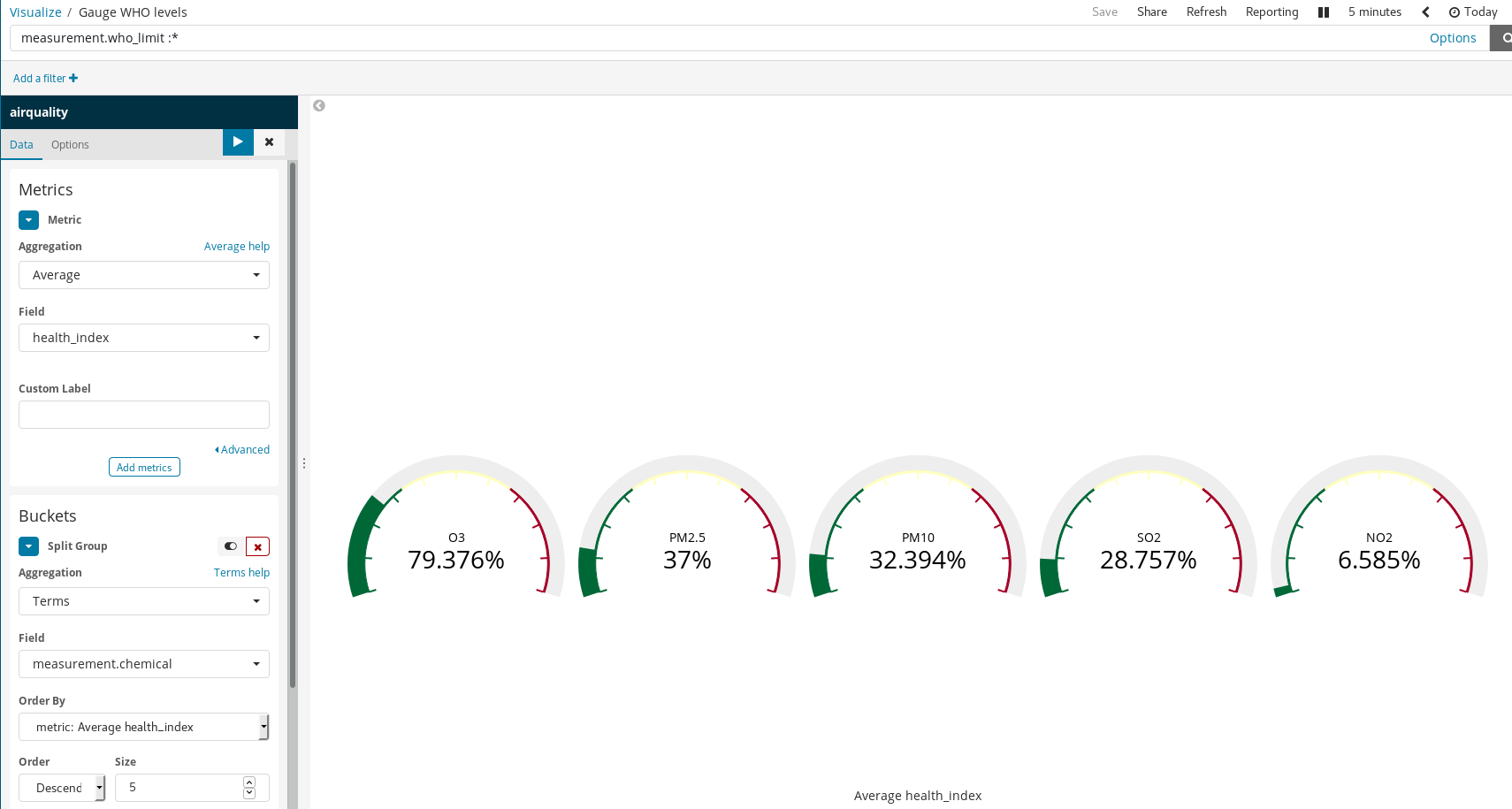
Regardez : de simples règles permettent d'obtenir des visualisations riches dans Kibana. Dans l'exemple ci-dessus, nous avons :
- filtré les documents, en sélectionnant uniquement ceux pour lesquels il existe des limites définies par l'OMS ;
- utilisé les fonctions Split Groups (Groupes divisés) et Terms Aggregation (Agrégation de termes) sur le champ
measurement.chemical.
Cela a permis de générer un graphique de jauge de chaque produit chimique pour lesquels il existe des limites OMS connues.
Comprendre la pollution à Madrid
Exploitez les visualisations Kibana pour élaborer des tableaux de bord qui regroupent les visualisations – la clé pour interpréter et comprendre l'état d'un système en temps réel. Dans ce cas, le système est la composition de l'atmosphère, et ses interactions avec les activités humaines.
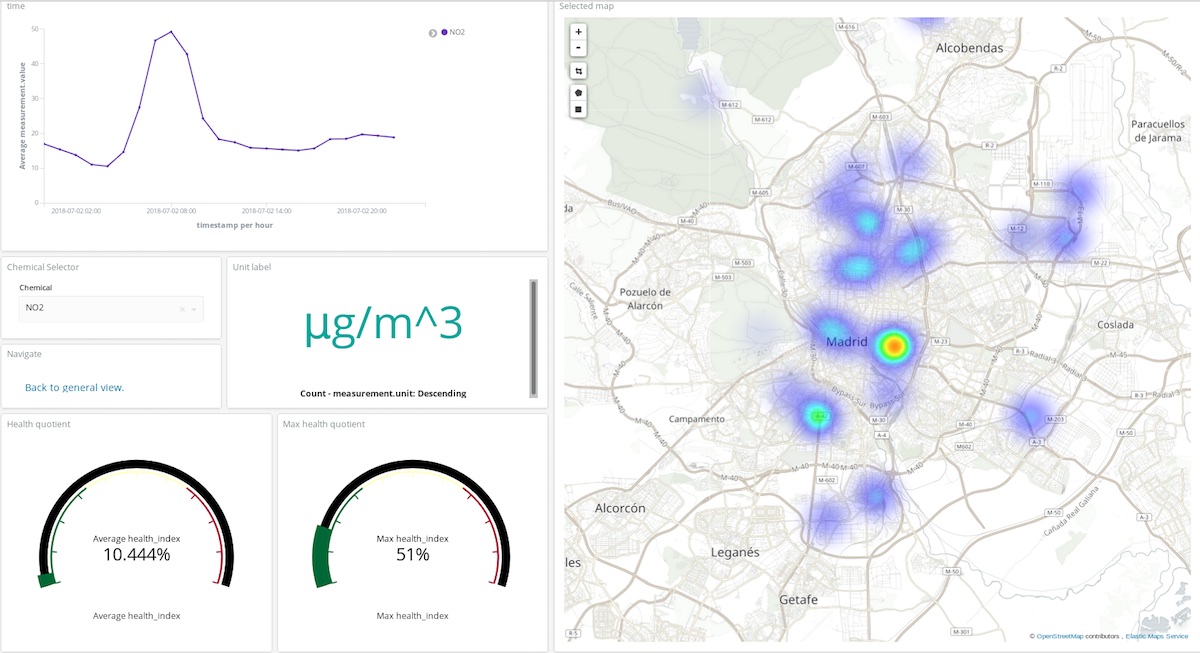
Dans le tableau de bord ci-dessus, un utilisateur peut choisir n'importe quel produit chimique et n'importe quelle plage, et se faire une idée assez précise des endroits et du degré de pollution de l'atmosphère par ce composé. Essayez par vous-même ! (identifiant : test, mot de passe : madrid_air).
Vous pouvez aussi vous faire une idée générale de la qualité de l'air à Madrid en utilisant le même identifiant et le même mot de passe.
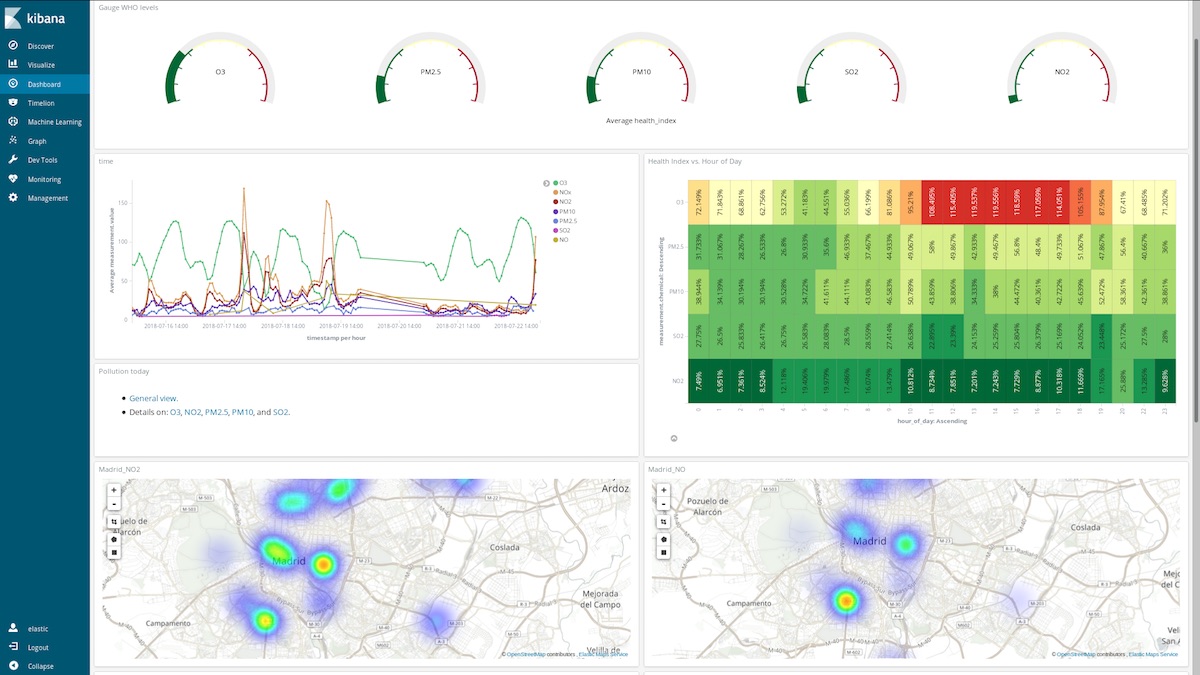
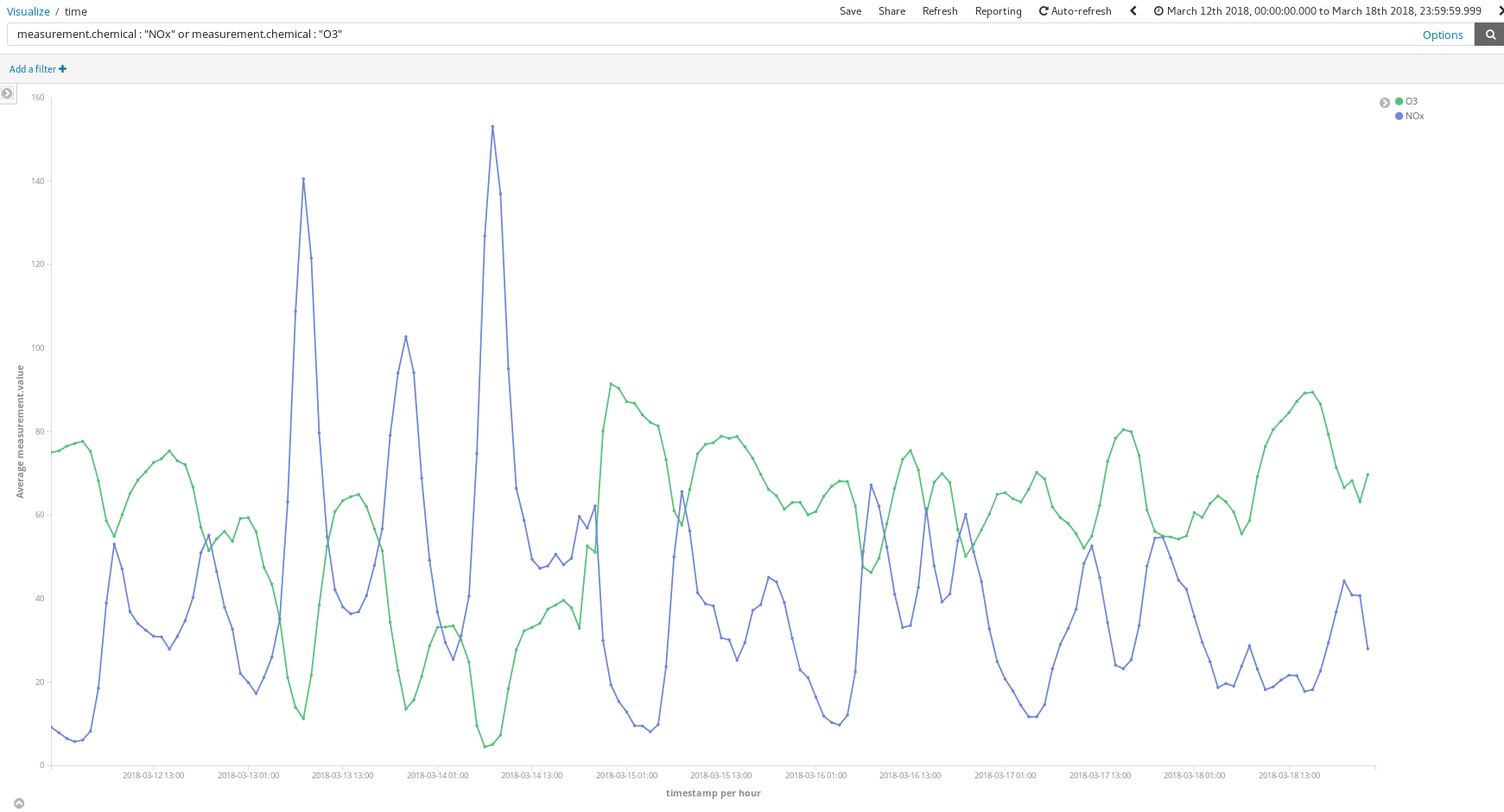
Comment ces tableaux de bord peuvent-ils aider ? Observons une semaine au hasard au mois de mars (du 12 mars au 18 mars) :
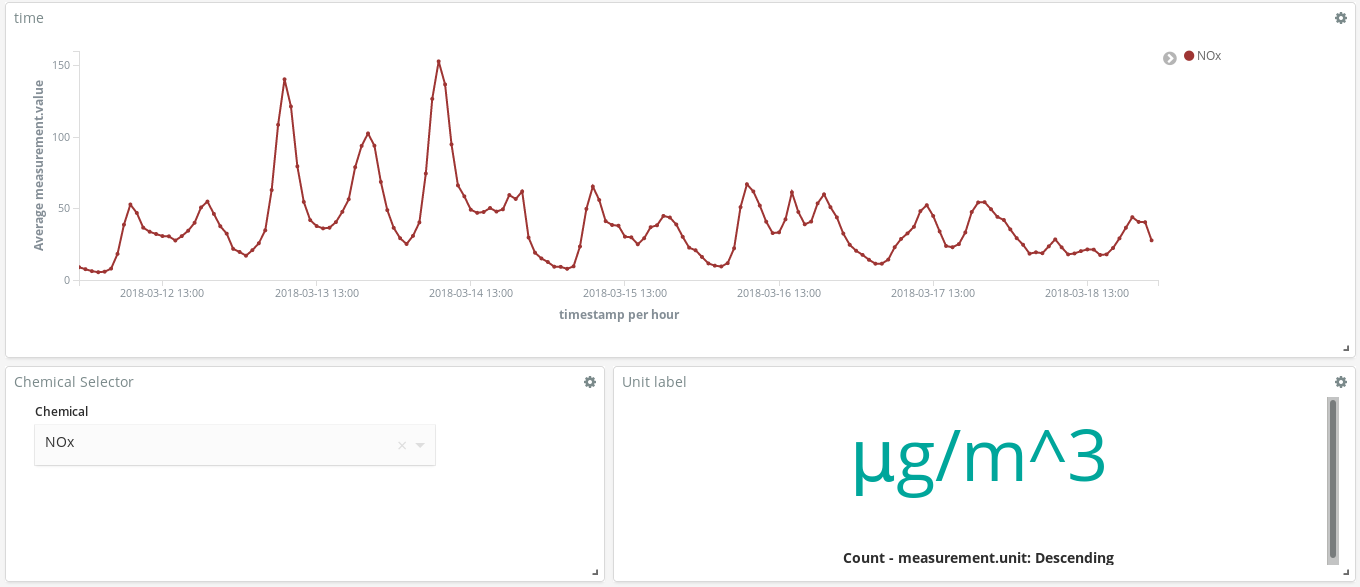
Ces pics de NOx (un composé produit par la combustion dans les moteurs diesel) nous révèlent-ils quelque chose sur les habitudes des Madrilènes ? Oui. Des habitudes que l'on observe deux fois par jour...
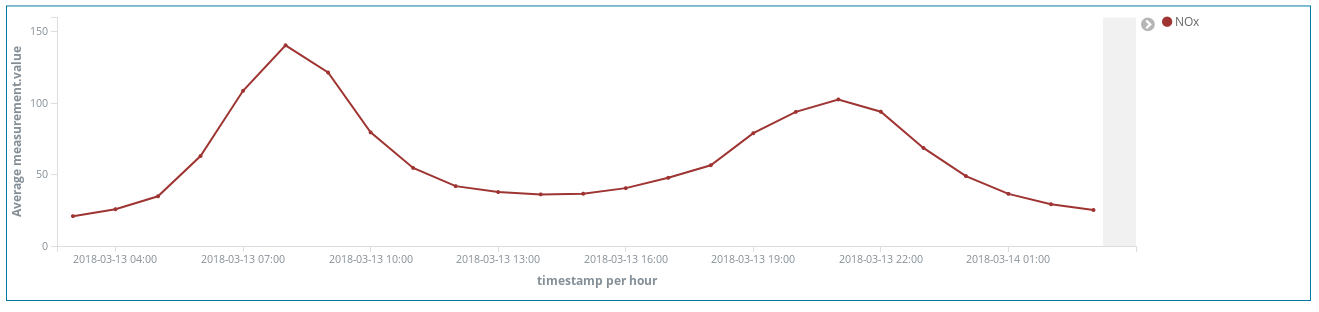
Une fois vers 8 h CEST, et une fois vers 21 h CEST. Ce que l'on observe, c'est l'augmentation de l'utilisation des voitures diesel pour les déplacements dans la ville, lorsque les travailleurs se rendent sur leur lieu de travail. Ensuite, presque personne n'utilise ces véhicules pendant les heures d'ouverture des bureaux, et l'on observe un autre pic de fumées lorsque les travailleurs ont terminé leur journée et rentrent chez eux.
Il est également intéressant de constater que la concentration en O3 augmente lorsque celle en NOx diminue. L'ozone (O3) est un produit dérivé des réactions entre les NOx et les composés organiques en présence de la lumière du soleil : on peut donc s'attendre à une corrélation entre les NOx et l'O3.
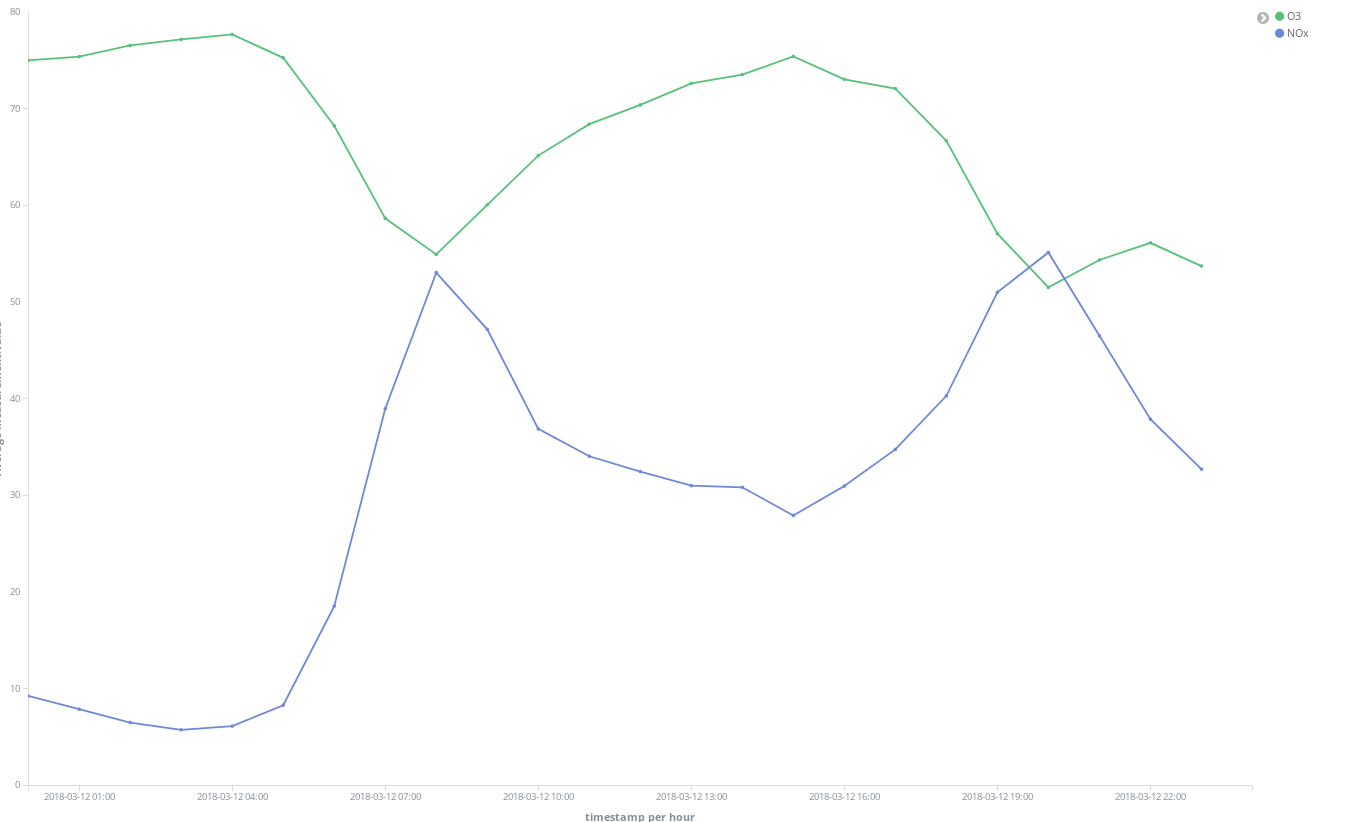
On peut également observer que la situation générale s'améliore le week-end :
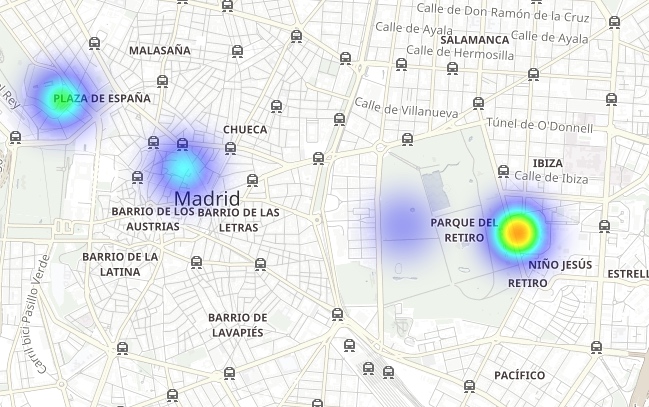
Observez comment le parc El Retiro (un immense espace vert au cœur de la ville) est entouré de points chauds d'émission de NO2, tout en étant une zone d'émissions plus faibles grâce à la végétation importante et à l'absence de trafic :
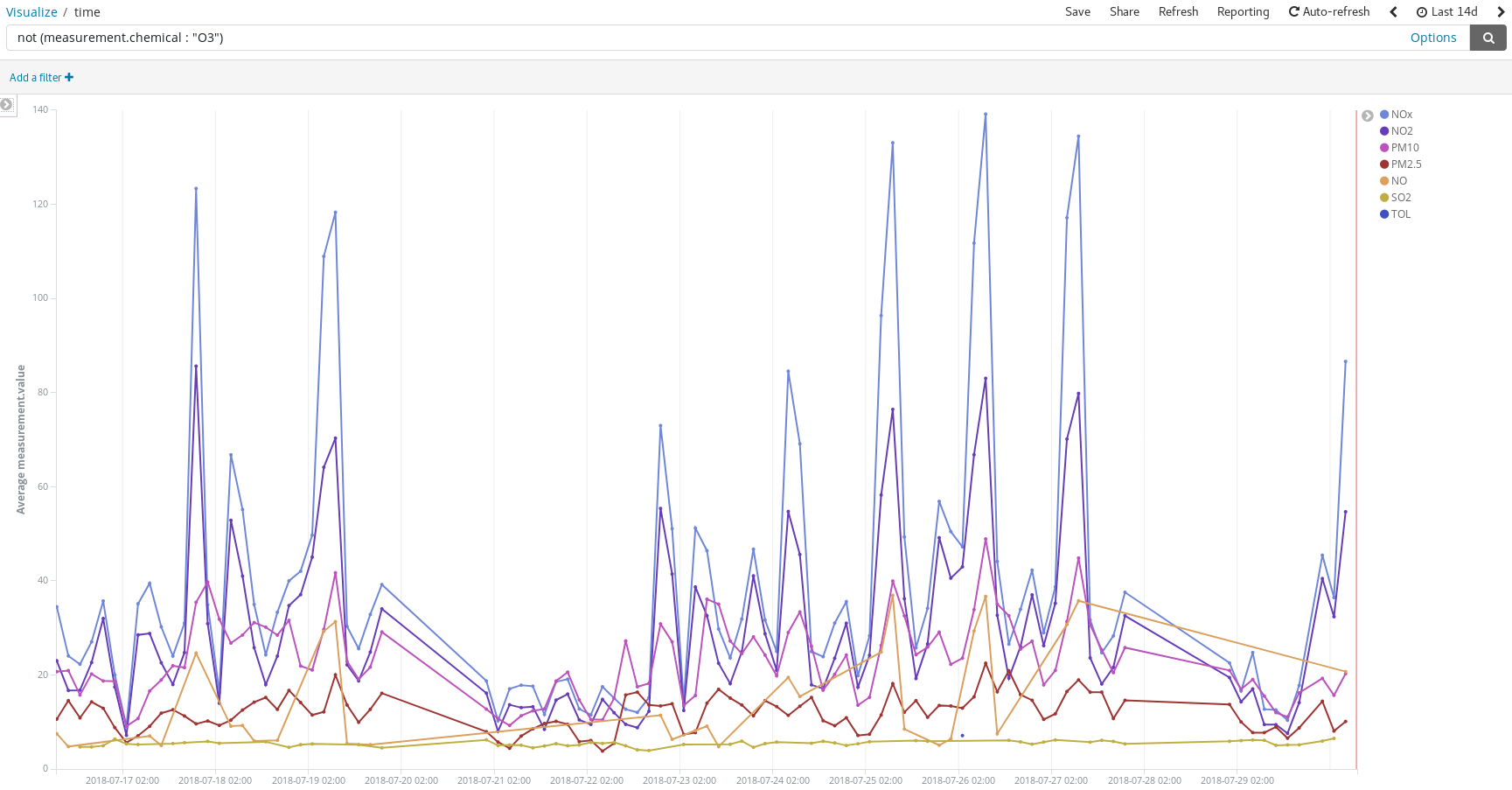
Détectez les pics de pollution les jours où les gens ont l'habitude de prendre la voiture pour se rendre sur leurs lieux de vacances pour l'été :
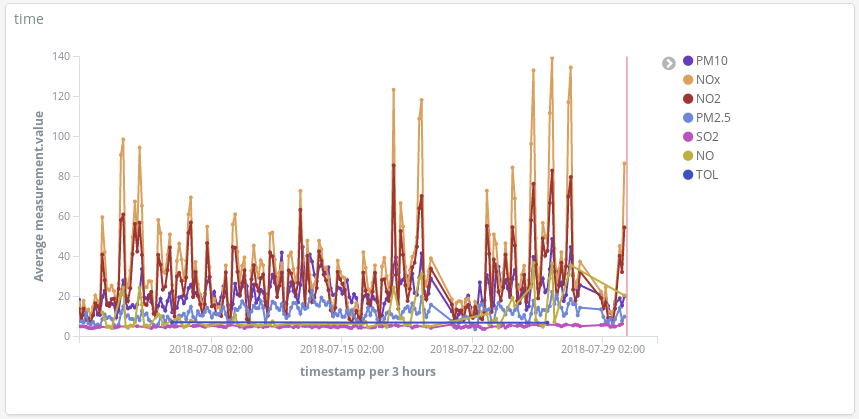
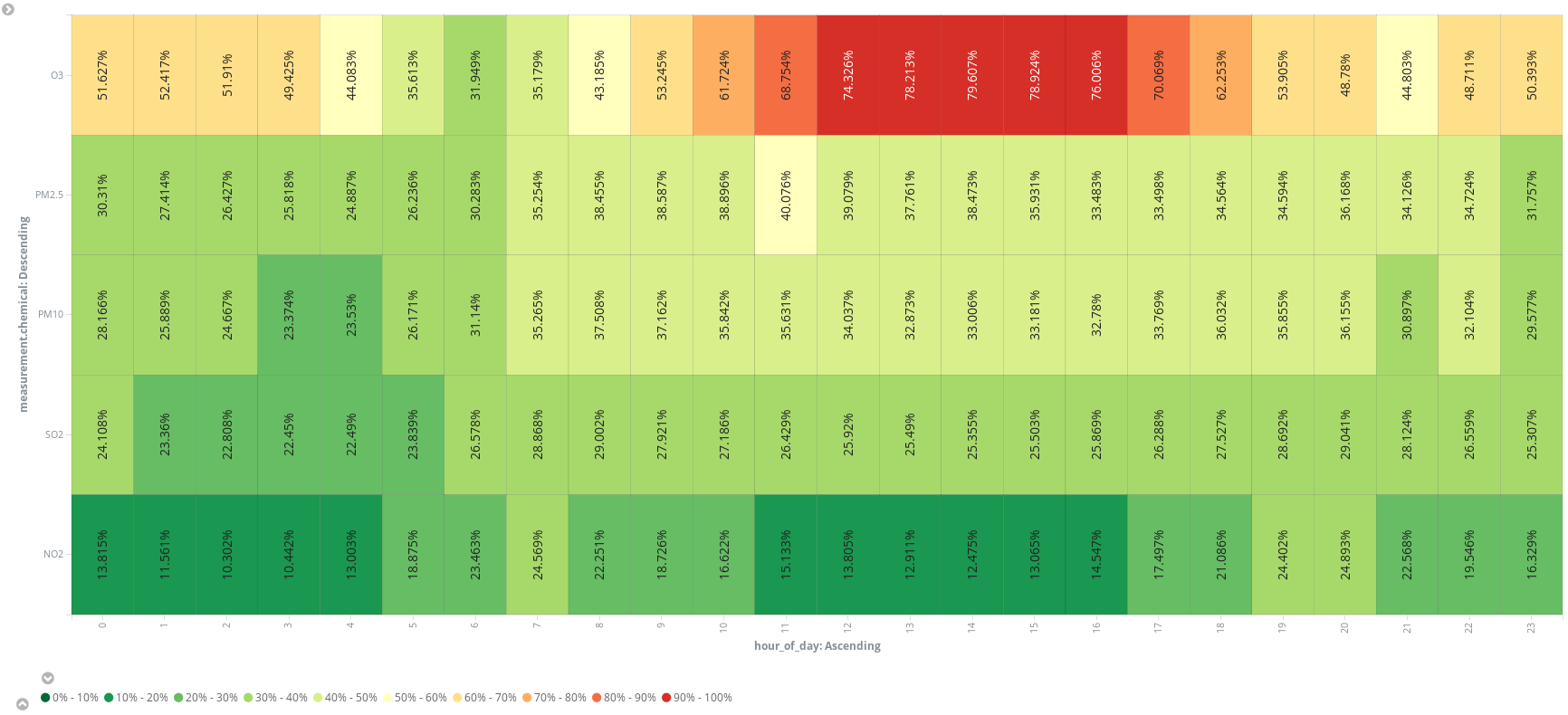
Ou ajoutez un champ scripté supplémentaire (hour_of_day) (heure de la journée) pour présenter les entrées par heure afin de présenter les mesures moyennes par produit chimique sur une carte thermique. On dirait que 6 h est le meilleur moment pour aller courir :
En fin de compte, nous sommes convaincus que l'air n'est pas seulement un mélange d'azote, d'oxygène, de dioxyde de carbone, d'argon et d'eau. Loin de là. Nous ne respirons pas que de l'air lorsque nous descendons la Gran Vía à Madrid. Et sans doute pas non plus lorsque vous explorez Manhattan. Vous voulez le vérifier par vous-même ? Vous savez maintenant comment faire. Tout commence par une source de données ouvertes.
Conclusion
Si nous étions des ingénieurs de données responsables de configurer des outils pour que les scientifiques de données de notre entreprise puissent analyser les niveaux de pollution à Madrid, nous n'aurions eu qu'à enregistrer le modèle d'indexation airquality (qualité de l'air) dans Kibana, intégrer le lien d'accès dans un e-mail et les laisser jouer avec. La Suite Elastic offre une suite analytique complète permettant d'obtenir des réponses en quelques minutes, de manière très intuitive, et dans laquelle le seul code à écrire concerne l'un des champs scriptés (si nécessaire).
Grâce à Elastic Cloud, notre travail en tant qu'ingénieurs de données a été simplifié : nous n'avons plus que quelques clics à réaliser et le service Extraire, Transformer, Charger (ETL, Extract Transform Load) à écrire. Mais avons-nous vraiment besoin d'écrire un ETL pour récupérer et intégrer nos données dans Elasticsearch ? Dans le prochain billet, nous verrons que la Suite Elastic peut également s'en charger.