Subsonic utilise Elasticsearch comme base de données orientée documents
Cet article décrit une stratégie permettant d'utiliser Elasticsearch comme support de stockage principal au travers d'un cas d'utilisation concret. Si le projet vous intéresse, vous pouvez retrouver toutes les sources sur GitHub.
Introduction
Subsonic est un serveur multimédia développé en Java. Il permet de construire une librairie musicale à partir de fichiers audio (et vidéo) stockés sur un disque dur et d'écouter la musique en streaming sur différents périphériques.
Remarque : Subsonic était open source jusqu'en mai 2016 lorsque son développeur a décidé de fermer les sources. Si le projet vous intéresse, je vous conseille plutôt de vous diriger vers Libresonic, un fork open source communautaire de Subsonic.
La librairie musicale est matérialisée classiquement dans une base de données relationnelle. La base de données est une simple instance HSQLDB embarquée dans l'application web.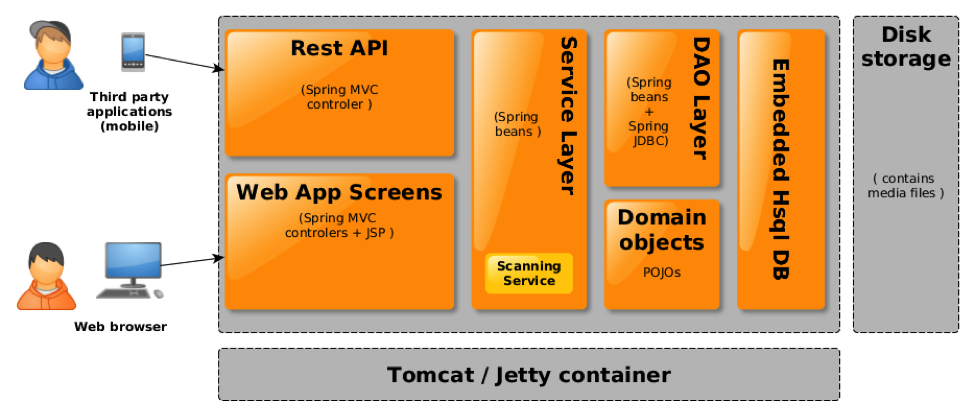
Figure 1 - Structure globale de Subsonic
Subsonic dispose d'un service spécial pour alimenter la base de données à partir des fichiers musicaux présents sur disque, appelé « scanning service ». Il parcourt le système de fichier à la recherche de fichiers musicaux et met à jour les descriptions de documents musicaux dans la base de données.
Toutes les données significatives sont contenues dans quelques tables seulement (MEDIA_FILE, ALBUM, ARTIST et GENRE). Les autres tables servent à des fins d'administration.
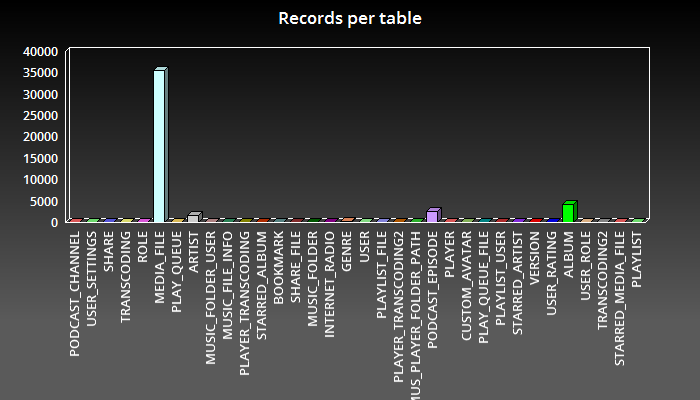
Figure 2 - Distribution du nombre d’enregistrements par table
En observant la distribution du nombre d'enregistrements par table, on se rend compte que pratiquement toute la donnée est contenue dans la table MEDIA_FILE. Il y a très peu de logique relationnelle dans cette base de données. En outre, Subsonic utilise un index Lucene pour ses fonctions de recherche. Voilà ce qu'on peut appeler un système orienté documents et, ce n'est pas surprenant, puisqu'un fichier musical n’est en réalité qu’un document.
A partir de là, il m'a semblé intéressant d'essayer de remplacer le système de stockage relationnel par un système plus nativement orienté documents. Dans une telle application, la fonction de recherche est très importante. En raison de mon intérêt pour Lucene, j'ai voulu tenter l'expérience de remplacer la base HSQLDB par un service Elasticsearch. L'objectif était donc d'arriver à l'architecture suivante :
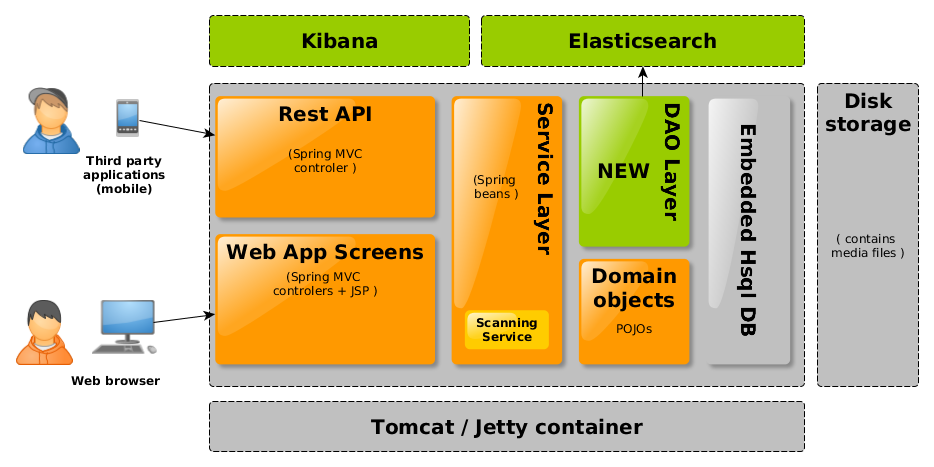
Figure 3 - Nouvelle structure Subsonic
La base de données embarquée est progressivement supprimée (elle sera peut être conservée pour les données d'administration). Par ailleurs, on remarque que l'ajout de Kibana doit nous permettre d'avoir une nouvelle vue sur les données métiers.
La stratégie
Comme vous l'avez certainement remarqué, Subsonic dispose d'une couche Data Access Object (DAO). En théorie, il est possible de changer de gestionnaire de stockage en ré-écrivant simplement la couche DAO tant que le contrat de la couche DAO reste inchangé. On doit donc pouvoir remplacer la base de données relationnelle par Elasticsearch sans avoir à toucher à la couche services.
Partant de là, la principale préoccupation est de trouver une structure d'index et une bonne méthode d'interrogation pour reproduire les comportements attendus par la couche DAO.
Deux problèmes épineux
Est-ce si simple de réécrire la couche DAO ? Globalement oui, mais j'ai tout de même été confronté à deux problèmes délicats.
Le problème des identifiants
Subsonic utilise des entiers comme identifiants (id) d'objets et Elasticsearch génère des id de document qui ne sont pas numériques. Or, il est impossible de changer le type des id sans casser le contrat général de l'API Rest Subsonic. J'ai finalement opté pour un système à deux id. Un id est généré par Elasticsearch lors de l'indexation d'un document puis un second id numérique est créé en calculant le hashcode du chemin d'accès au fichier audio (ou vidéo) sur disque.
Le problème des transactions
Elasticsearch n'est pas un système de gestion de base de données ACID. L'indexation d'un nouveau document n'est pas transactionnelle puisqu'elle s'effectue de façon asynchrone. En effet, lorsqu'on indexe un nouveau document, ce dernier n’est visible qu’au bout d'un certain laps de temps (très court bien sûr, mais indéterminé).
Cela n'est pas spécialement problématique dans un cas d'utilisation tel que Subsonic ; en effet les documents sont ajouté par le scanning service et cela ne met pas en jeu de transaction à proprement parler. Le problème vient du fait que, dans Subsonic, le scanner service est développé de telle manière que chaque document ajouté dans la base de données est immédiatement relu pour effectuer différents traitements. J'ai donc été amené à reconcevoir le processus de scan.
Design des index
Comme vu plus haut, les données « business » de Subsonic sont contenues dans un nombre de tables restreint, la plus importante étant MEDIA_FILE. Cette dernière contient chaque document audio de la bibliothèque. A côté, les tables telles que ARTIST, ALBUM ou GENRE créent des relations entre les notions d'artiste, d'album de genre et les documents audio eux même.
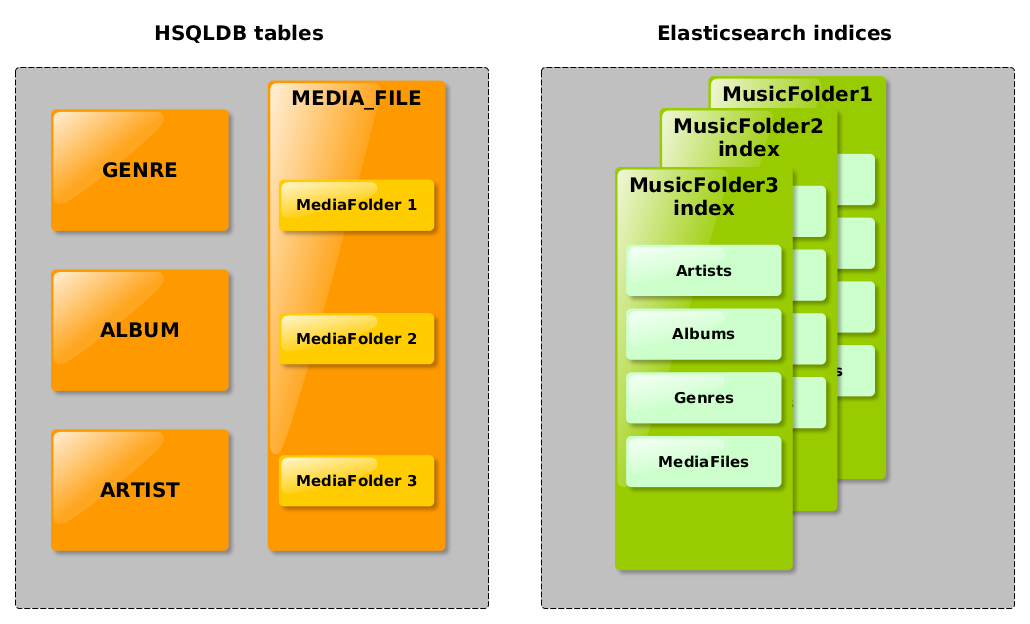
Figure 4 - Structure des index de la base de données
Dans l'optique de stocker toutes les données dans Elasticsearch, il n'est pas question de créer un index pour chacune de ces tables ; ce serait un contresens. A la place, on crée un index unique contenant tous les documents audio. La structure très souple des index Elasticsearch permet d'enregistrer les notions d'artiste, album, genre en tant qu'attribut de chaque document. Ainsi, une bibliothèque de musiques est un ensemble de documents, tout simplement. Notons au passage que notre index Elasticsearch remplace à la fois la base de données relationnelle et l'index Lucene créé par Subsonic pour ses recherches.
Dans Subsonic, on peut déclarer plusieurs dossiers de musique. Chaque dossier est une partie de la librairie musicale, ce qui permet d'attribuer des droits distincts à différents utilisateurs. J'ai décidé de créer un index distinct pour chaque dossier musical, ce qui est très pratique pour implémenter les droits d'accès des utilisateurs puisque Elasticsearch permet de choisir facilement sur quels index doit porter une requête de recherche.
Réécriture de la couche DAO
La couche DAO est composée de beans métier et de beans Spring qui implémentent les opérations de lecture et écriture sur la base de données.
L'objectif est de réécrire les beans Spring de façon à attaquer un index Elasticsearch à la place de la base HSQLDB pour chaque opération élémentaire (CRUD). Pour ce faire, j'ai utilisé une combinaison de deux techniques : le client Java-Elasticsearch (transport client) et le query DSL basé sur JSON. Les beans métier eux même ne sont pas modifiés sauf pour ce qui est de l'ajout d'un identifiant Elasticsearch.
Une classe utilitaire DAO
La classe ElasticSearchDaoHelper se charge de créer les index et fournit des utilitaires pour interroger Elasticsearch.
Au démarrage de l'application, si aucun index n'existe, la classe ElasticSearchDaoHelper va créer explicitement un index pour chaque dossier musical définit dans Subsonic, comme l'illustre le code ci-dessous.
String[] indexNames = indexNames();
for (String indexName : indexNames) {
boolean indexExists = elasticSearchClient.admin()
.indices().prepareExists(indexName)
.execute().actionGet().isExists();
if (!indexExists) {
elasticSearchClient.admin().indices()
.prepareCreate(indexName)
.addMapping(MEDIA_FILE_INDEX_TYPE,
"path", "type=string,index=not_analyzed",
"parentPath", "type=string,index=not_analyzed",
"mediaType", "type=string,index=not_analyzed",
"folder", "type=string,index=not_analyzed",
"format", "type=string,index=not_analyzed",
"genre", "type=string,index=not_analyzed",
"artist", "type=string,index=not_analyzed",
"albumArtist", "type=string,index=not_analyzed",
"albumName", "type=string,index=not_analyzed",
"name", "type=string,index=not_analyzed",
"coverArtPath", "type=string,index=not_analyzed",
"created", "type=date",
"changed", "type=date",
"childrenLastUpdated", "type=date",
"lastPlayed", "type=date",
"lastScanned", "type=date",
"starredDate", "type=date")
.get();
}
}
Chaque champ déclaré dans le mapping correspond à une propriété de l'objet métier MediaFile. Notez que la plupart de ces champs sont not_analyzed et peuvent donc être utilisés pour faire des recherches selon des valeurs exactes (il faut se souvenir que dans ce contexte, Elasticsearch est utilisé comme une sorte de base de données).
Ajout de fichiers audio dans l'index
Des objets de type MediaFile sont ajoutés (ou mis à jour) dans Elasticsearch par le scanning service de Subsonic. Cela consiste à créer à chaque fois un nouveau document dans l'index. C'est le travail de la méthode indexObject ci-dessous :
public void indexObject(SubsonicESDomainObject obj, String indexName) {
try {
// Convert the object to a json string representation.
String mediaFileAsJson = getMapper().writeValueAsString(obj);
IndexResponse indexResponse = getClient().prepareIndex(
indexName,
ElasticSearchDaoHelper.MEDIA_FILE_INDEX_TYPE)
.setSource(mediaFileAsJson)
.setVersionType(VersionType.INTERNAL)
.get();
} catch (JsonProcessingException e) {
throw new RuntimeException("Error trying indexing object " + e);
}
}
Ici, le paramètre indexName est le nom de l'index correspondant au dossier musical dans lequel le document doit être ajouté. L'objet métier de type SubsonicESDomainObject (classe mère de tous les objets du domaine) devant être ajouté à l'index est préalablement sérialisé en JSON à l'aide de la librairie Jackson (getMapper() fait référence à la classe com.fasterxml.jackson.databind.ObjectMapper).
Recherche de documents dans l'index
La classe ElasticSearchDaoHelper contient un ensemble de méthodes utilitaires qui facilitent le requêtage sur Elasticsearch.
Pour exécuter une requête, le client Java-Elasticsearch est utilisé mais chaque requête est spécifiée sous forme JSON et placée dans un fichier de ressource hors du code Java. Chaque fichier de ressource contenant une requête est en fait un template FreeMarker dans lequel on place des variables correspondant aux paramètres de la requête.
Voici la méthode Java utilitaire permettant d'exécuter une recherche d'objet par clé primaire.
public <T extends SubsonicESDomainObject> T extractUnique(
String queryName, Map<String, String> vars, Class<T> type) {
String jsonQuery;
try {
jsonQuery = getQuery(queryName,vars);
} catch (IOException | TemplateException e) {
throw new RuntimeException(e);
}
SearchRequestBuilder searchRequestBuilder = getClient().prepareSearch(indexNames())
.setQuery(jsonQuery).setVersion(true);
SearchResponse response = searchRequestBuilder.get();
long totalHits = response == null ? 0 : response.getHits().totalHits();
if (totalHits == 0) {
return null;
} else if (totalHits > 1) {
throw new RuntimeException("Document is not unique "+type.getName()+" "+vars);
} else {
return convertFromHit(response.getHits().getHits()[0],type);
}
}
La méthode convertFromHit se charge de matérialiser un objet métier à partir du champ _source du document trouvé.
private <T extends SubsonicESDomainObject> T convertFromHit(SearchHit hit, Class<T> type) throws RuntimeException {
T object = null;
if (hit != null) {
String hitSource = hit.getSourceAsString();
try {
object = getMapper().readValue(hitSource,type);
object.setESId(hit.id());
object.setVersion((int)hit.getVersion());
} catch (IOException e) {
throw new RuntimeException("Error while reading MediaFile object from index. ", e);
}
}
return object;
}
Enfin, la classe ElasticSearchDaoHelper contient un ensemble de méthodes, nommées extractObjects, dont le but est d’extraire un ensemble d'objets à partir d'une liste de documents retrouvés depuis une requête Elasticsearch. Vous pouvez consulter la source de ces méthodes sur GitHub.
Un exemple de bean DAO : MediaFileDao
La classe MediaFileDao est le principal bean DAO car l'objet MediaFile est l'objet pivot du domaine métier Subsonic. Voici à titre d'exemple deux méthodes de ce DAO qui utilisent l'utilitaire décrit au chapitre précédent :
Recherche d'un fichier audio à partir de son chemin d'accès unique sur disque
public MediaFile getMediaFile(String path) {
Map<String,String> vars = new HashMap<>();
vars.put("path",path);
return elasticSearchDaoHelper.extractUnique("searchMediaFileByPath",vars,MediaFile.class);
}
L’appel de la méthode extractUnique fait ici référence au fichier searchMediaFileByPath.flt qui contient la requête de recherche par identifiant d’un document audio.
{
"constant_score" : {
"filter" : {
"bool" : {
"must" : [
{"term" : {"path" : "${path}"}},
{"type" : {"value" : "MEDIA_FILE"}}
]
}
}
}
}
Recherche de toutes les chansons d'un même album
public List<MediaFile> getSongsForAlbum(String artist, String album) {
Map<String,String> vars = new HashMap<>();
vars.put("artist",artist);
vars.put("album",album);
return elasticSearchDaoHelper.extractObjects(
"getSongsForAlbum",vars,MediaFile.class);
}
La requête correspondante est contenue dans le fichier getSongsForAlbum.flt:
{
"constant_score" : {
"filter" : {
"bool" : {
"must" : [
{"term" : {"albumArtist" : "${artist}"}},
{"term" : {"albumName" : "${album}"}},
{"type" : {"value" : "MEDIA_FILE"}}
],
"should" : [
{"term" : {"mediaType" : "MUSIC"}},
{"term" : {"mediaType" : "AUDIOBOOK"}},
{"term" : {"mediaType" : "PODCAST"}}
]
}
}
}
}
Jouons avec les données
Nous avons maintenant tout ce qu'il faut pour construire un index de documents musicaux. Nous pouvons utiliser les formidables fonctionnalités de recherche d'Elasticsearch pour exploiter nos données.
Au début de l'article, j'ai mentionné le fait que Subsonic possède des tables permettant de répertorier les albums, les artistes et les genres musicaux. Maintenant ces information font partie intégrante des propriétés de nos documents musicaux indexés.
Cependant, il ne s'agit pas de rechercher des documents un par un mais nous devons aussi réaliser des recherches groupées. Ainsi, l'API Subsonic doit pouvoir répondre à des questions telles que :
- Quels sont les différents genres musicaux de ma librairie ? Combien y a-t-il de chansons et d'albums pour chaque genre ?
- Qui sont les différents artistes et combien ont-ils d'albums dans ma librairie ?
Pour répondre à ces questions, nous pouvons utiliser le framework d'agrégation d'Elasticsearch. Par exemple, la méthode MediaFileDao.getGenres retourne une liste ordonnée de tous les genres musicaux de la librairie. L'objet Genre contient par ailleurs le nombre de chansons et d'albums concernés.
public List<Genre> getGenres(boolean sortByAlbum) {
List<Genre> genres = new ArrayList();
SearchResponse genresResponse = elasticSearchDaoHelper.getClient().prepareSearch()
.setQuery(QueryBuilders.typeQuery("MEDIA_FILE"))
.addAggregation(AggregationBuilders.terms("genre_agg").field("genre")
.subAggregation(AggregationBuilders.terms("mediaType_agg").field("mediaType")))
.setSize(0).get();
StringTerms genreAgg = genresResponse.getAggregations().get("genre_agg");
for (Terms.Bucket genreEntry : genreAgg.getBuckets()) {
Genre genre = new Genre(genreEntry.getKeyAsString());
StringTerms mediaTypeAgg = genreEntry.getAggregations().get("mediaType_agg");
for (Terms.Bucket mediaTypeEntry : mediaTypeAgg.getBuckets()) {
if ("ALBUM".equals(mediaTypeEntry.getKeyAsString())) {
genre.setAlbumCount((int) mediaTypeEntry.getDocCount());
}
if ("MUSIC".equals(mediaTypeEntry.getKeyAsString())) {
genre.setSongCount((int) mediaTypeEntry.getDocCount());
}
}
genres.add(genre);
}
// Sort the list.
if (sortByAlbum) {
genres.sort((o1, o2) -> {
if (o1.getAlbumCount() > o2.getAlbumCount()) {
return -1;
}
if (o1.getAlbumCount() < o2.getAlbumCount()) {
return 1;
}
return 0;
});
} else {
genres.sort((o1, o2) -> {
if (o1.getSongCount() > o2.getSongCount()) {
return -1;
}
if (o1.getSongCount() < o2.getSongCount()) {
return 1;
}
return 0;
});
}
return genres;
}
Aller encore plus loin avec Kibana
Un des apports indéniables de la Suite Elastic, est de pouvoir utiliser Kibana en parallèle d’Elasticsearch pour interroger facilement les données. En effet, en seulement quelques minutes, vous pouvez créer vos propres tableaux de bord pour visualiser la distribution des genres musicaux et la liste des artistes les plus écoutés de la librairie.
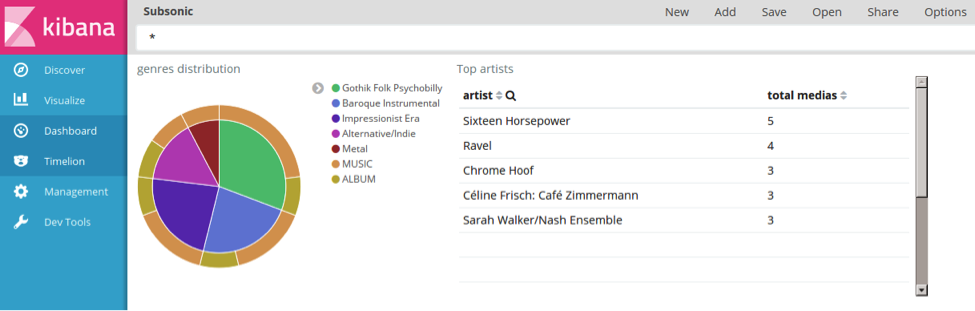
Figure 5 - Tableau de bord Kibana
On peut reconnaître ici les agrégations genre_agg/mediaType_agg que l'on a utilisées dans la méthode MediaFileDao.getGenres. Chaque ensemble (bucket) de l'agrégation est représentée par une part du camembert.
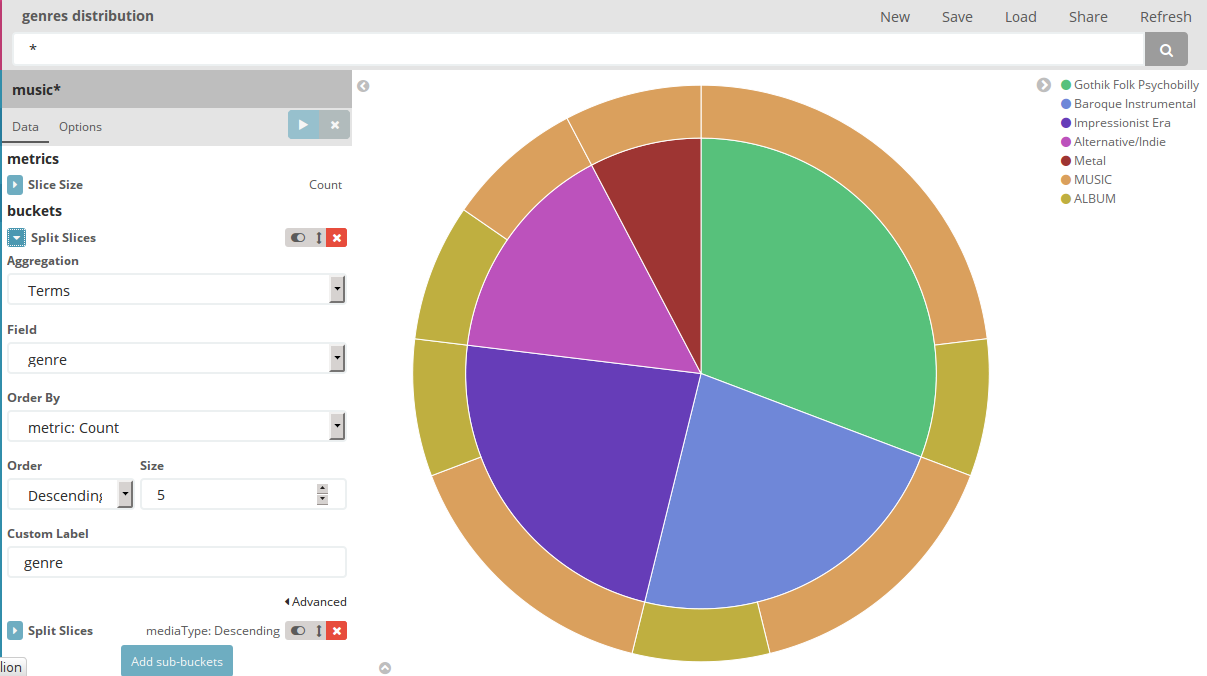
Figure 6 - Ecran de visualisation des genres musicaux dans Kibana
Il est également très agréable de naviguer parmi les documents indexés en appliquant quelques filtres à la souris.
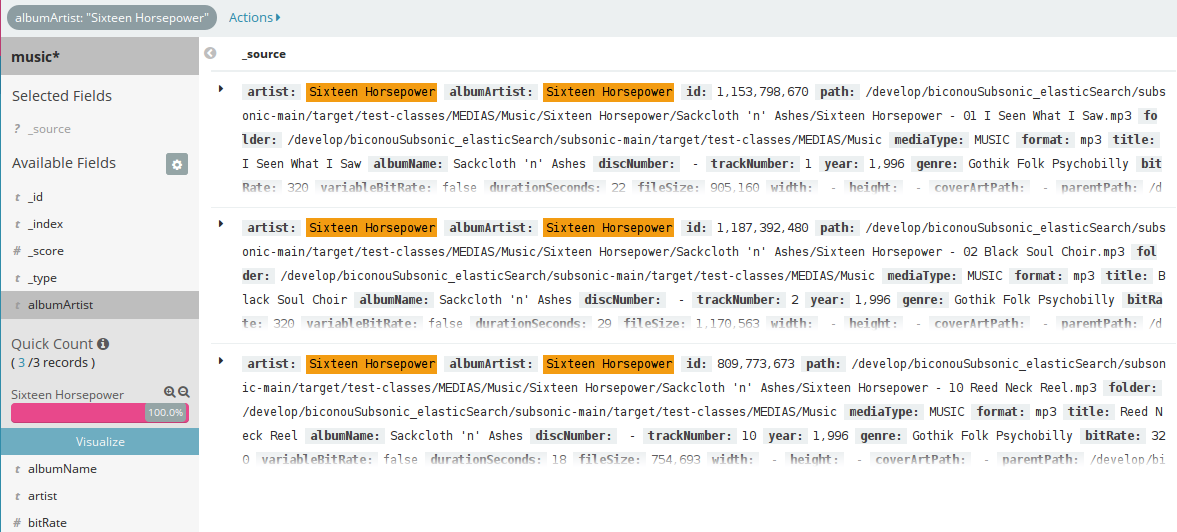
Figure 7 - Exemple de filtrage de documents musicaux à partir d’un nom d’artiste
Conclusion
Elasticsearch est l’outil idéal pour implémenter rapidement des fonctions de recherche sur une application. La plupart du temps, il est utilisé en parallèle de la base principale afin d’indexer les données. Cependant, lorsqu’on est en présence d’une application réellement orientée documents, Elasticsearch, de par la structuration qu’il apporte au travers de ses API peut tout à fait être utilisé comme base de données primaire.
C’est ce que j’ai voulu expérimenter au travers de ce Proof Of Concept (POC) et je dois dire que je ne suis pas déçu.
Elasticsearch est rapide à mettre en œuvre, structurant, élégant et performant. C’est un outil incontournable dans la mise en place d’une application documentaire.
Rémi Cocula a appris à développer avec Turbo Pascal en 1992. Il est désormais architecte et développeur Java chez Sopra-Steria. Passionné de musique et développeur, il a toujours un casque Hi-Fi sur les oreilles. Libresonic est donc un terrain de jeu idéal.