Nouveauté de la version 7.7 : diminution significative de votre utilisation du segment de mémoire d'Elasticsearch
Les utilisateurs d'Elasticsearch repoussent toujours les limites des volumes de données qu'ils peuvent stocker sur un nœud Elasticsearch. Ainsi, il arrive que le segment de mémoire vienne à manquer avant de ne plus avoir d'espace disque à disposition. Ce problème est très frustrant. Souvent, les utilisateurs ont besoin de pouvoir stocker autant de données que possible dans chaque nœud afin de diminuer leurs coûts.
Pourquoi Elasticsearch a-t-il besoin d'un segment de mémoire pour le stockage des données ? L'espace disque n'est-il pas suffisant ? La réponse est multiple. La raison principale est la nécessité pour Lucene de stocker certaines informations en mémoire afin de savoir où mener les recherches sur le disque. Par exemple, l'index inversé de Lucene comprend un dictionnaire qui regroupe les mots en blocs sur le disque et les trie selon des critères spécifiques, mais aussi un index de termes afin d'accélérer les recherches dans le dictionnaire. Cet index mappe les préfixes des termes en tenant compte de l'offset sur le disque au début de l'emplacement du bloc qui contient les termes avec les préfixes concernés. Le dictionnaire des termes se trouvait sur le disque, tandis que l'index était sur le segment de mémoire jusqu'à récemment.
De quelle quantité de mémoire les index ont-ils besoin ? En règle générale, quelques Mo par Go d'index suffisent. Or, les utilisateurs connectent de plus en plus de téraoctets de disque à leurs nœuds. Par conséquent, les index ont besoin de 10 à 20 Go de segment de mémoire afin de stocker ces téraoctets. Étant donné qu'Elastic recommande de ne pas dépasser 30 Go de segment de mémoire, il ne reste pas grand-chose pour d'autres opérations gourmandes, comme les agrégations. En outre, cela ouvre la porte à des problèmes de stabilité si la Machine virtuelle Java (JVM) n'a plus assez de place pour les opérations de gestion des clusters.
Étudions le problème sous un angle pratique. Elastic exécute toutes les nuits des évaluations de plusieurs ensembles de données et met en place un suivi de divers indicateurs dans le temps afin d'étudier l'utilisation particulière de la mémoire par les segments. L'ensemble de données Geonames est un cas intéressant : il montre clairement l'impact des différents changements apportés à Elasticsearch 7.x.
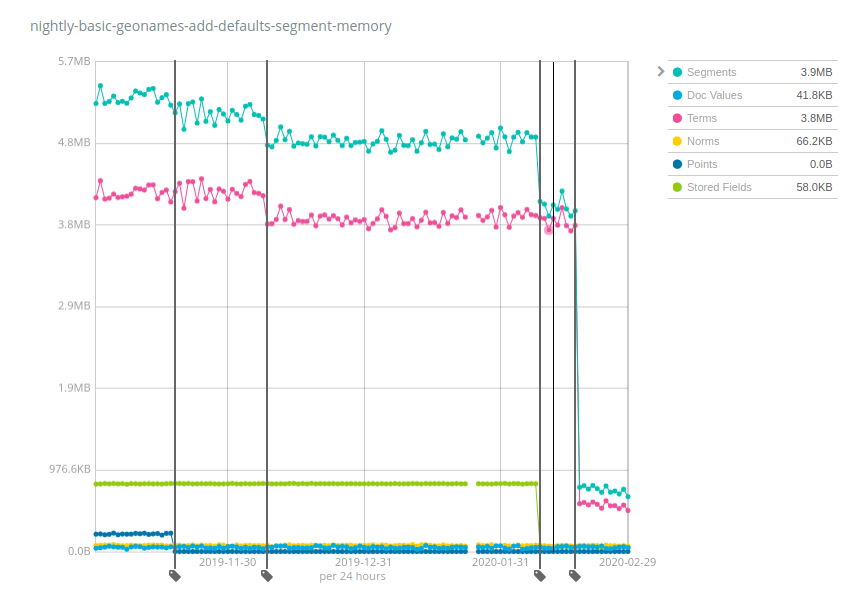
Cet index représente environ 3 Go sur le disque et nécessitait environ 5,2 Mo de mémoire il y a 6 mois, soit un ratio segment de mémoire-stockage d'environ 1 à 600. Ainsi, si 10 To au total sont connectés à chaque nœud, vous aurez besoin de 17 Go de segment de mémoire (10 To / 600) simplement pour garantir le fonctionnement des index stockant des données similaires à geonames. Toutefois, comme vous pouvez le voir ci-dessous, les choses se sont améliorées au fil du temps : les points (en bleu foncé) nécessitent moins de mémoire, suivis par les termes (en rose), les champs stockés (en vert) et enfin les termes à nouveau de manière plus importante. Désormais, le ratio segment de mémoire-stockage est d'environ 1 à 4 000, ce qui représente des capacités quasiment 7 fois plus performantes par rapport aux versions 6.x et 7.x. Vous avez donc besoin de seulement 2,5 Go de segment de mémoire pour garantir le fonctionnement de 10 To d'index.
Ces chiffres varient considérablement selon les ensembles de données. La bonne nouvelle est que Geonames est l'un des ensembles de données à présenter la plus petite réduction de l'utilisation du segment de mémoire. Cette dernière a été quasiment divisée par 7 sur Geonames. En comparaison, elle a été divisée par plus de 100 sur les ensembles de données concernant les taxis de New York et les logs HTTP. Ce changement favorise la réduction des coûts en stockant bien plus de données par nœud par rapport aux capacités des versions précédentes d'Elasticsearch.
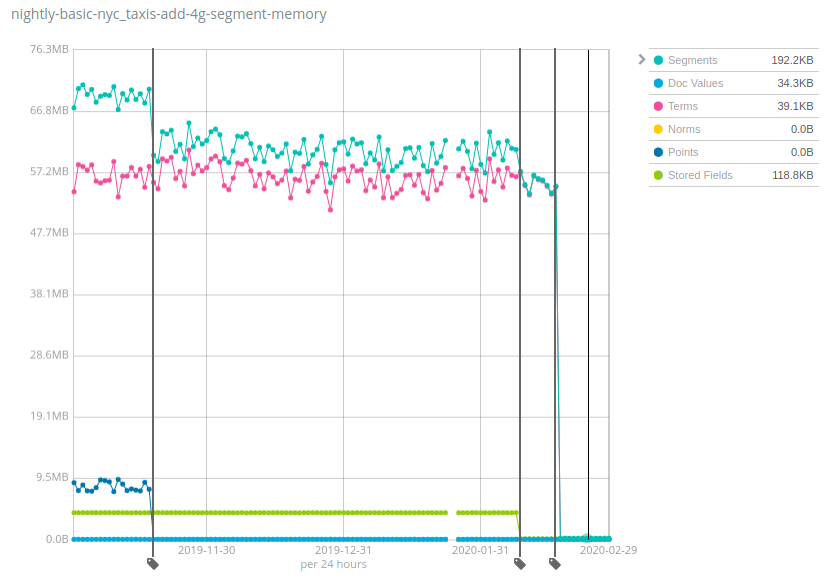
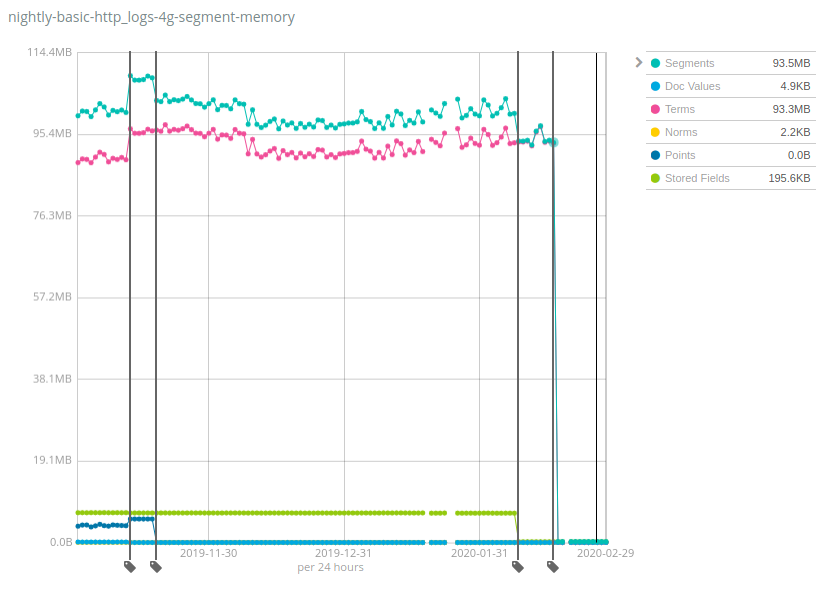
Comment cela fonctionne-t-il et quels sont les écueils à éviter ? La même recette a été appliquée sur le long terme à plusieurs composants d'index Lucene. Les structures de données sont passées du segment de mémoire de la JVM au disque. En outre, le cache du système de fichiers (souvent appelé cache de page ou cache du système d'exploitation) a permis de conserver en mémoire les bits "chauds". On peut supposer que cette mémoire est toujours en utilisation et attribuée à d'autres opérations. Or, une part importante de cette mémoire n'a tout simplement jamais été utilisée, selon vos cas d'utilisation. Par exemple, la goutte d'eau qui a fait déborder le vase pour Terms a été le transfert de l'index des termes du champ _id sur disque, qui permet seulement d'utiliser l'API GET ou d'indexer les documents avec des identifiants explicites. La grande majorité des utilisateurs qui indexent des logs et des indicateurs dans Elasticsearch n'effectuent jamais aucune de ces opérations. Ils pourraient ainsi bénéficier d'un réel gain de ressources.
Diminution de votre segment de mémoire Elasticsearch avec la version 7.7
Nous sommes ravis de vous présenter les améliorations qui seront disponibles dans Elasticsearch 7.7. Nous espérons qu'elles vous plairont. Le lancement de cette nouvelle version sera bientôt annoncé. Ne passez pas à côté et n'hésitez pas à la tester. Essayez-la dans votre déploiement existant ou inscrivez-vous à un essai gratuit d'Elasticsearch Service sur Elastic Cloud (qui comprend toujours la dernière version d'Elasticsearch). Nous aimons connaître votre opinion. Donc, n'hésitez pas à nous faire part de vos commentaires sur Discuss.