Dois-je utiliser Logstash ou les nœuds d'ingestion Elasticsearch ?
Logstash est l'un des premiers produits de la Suite Elastic. Il a donc longtemps été l'outil tout indiqué pour l'analyse, l'enrichissement et le traitement des données. Au fil des ans, nous l'avons enrichi d'un très grand nombre de plug-ins d'entrée, de sortie et de filtre. Résultat : Logstash est aujourd'hui un outil extrêmement puissant et flexible, que vous pouvez exploiter dans un très grand nombre d'architectures.
Les nœuds d'ingestion ont quant à eux fait leur apparition avec Elasticsearch 5.0. Leur mission : traiter les documents dans Elasticsearch avant leur indexation. Ils permettent la création d'architectures simples dans lesquelles les composants sont réduits au strict minimum et où les applications envoient directement les données vers Elasticsearch pour traitement et indexation. Cela simplifie souvent la tâche à ceux qui font leurs premiers pas avec la Suite Elastic, tout en leur laissant la possibilité de scaler pour accompagner la croissance du volume des données.
Toutefois, il est vrai que le nœud d'ingestion Elasticsearch fait doublon avec certaines fonctionnalités de Logstash. Il n'est donc pas rare que les utilisateurs se demandent laquelle des deux technologies utiliser. Dans cet article, nous allons nous pencher sur les aspects architecturaux dont vous devez tenir compte au moment de faire votre choix – l'objectif étant de vous aider à prendre une décision éclairée.
Cet article est le troisième d'une série de posts qui répondent aux questions que se posent souvent les utilisateurs. N'hésitez pas à consulter les précédents :
- How many shards should I have in my Elasticsearch cluster? (Combien de shards doit comporter mon cluster Elasticsearch ?)
- Why am I seeing bulk rejections in my Elasticsearch cluster? (Pourquoi certaines requêtes groupées sont parfois rejetées dans mon cluster Elasticsearch ?)
Comment fonctionne le transfert des données en entrée et en sortie ?
L'une des grandes différences entre Logstash et le nœud d'ingestion réside dans le mode de transfert des données en entrée et en sortie.
Comme un nœud d'ingestion s'exécute dans le flux d'indexation d'Elasticsearch, le transfert des données vers ce dernier doit se faire via des requêtes groupées ou des requêtes d'indexation. Autrement dit, un processus doit écrire activement les données dans Elasticsearch. Un nœud d'ingestion ne peut pas extraire les données depuis une source externe (file d'attente de messages ou base de données, par exemple).
Il existe une restriction similaire une fois les données traitées : la seule possibilité est de procéder à l'indexation locale des données dans Elasticsearch.
Le pipeline Logstash, quant à lui, intègre un très grand choix de plug-ins d'entrée et de sortie, et il est compatible avec différentes architectures. Il peut faire office de serveur et accepter les données envoyées par des clients sur TCP, UDP et HTTP, mais aussi extraire activement les données depuis des bases de données ou des files d'attente de messages, par exemple. S'agissant des données en sortie, il offre plusieurs possibilités : files d'attente de messages comme Kafka et RabbitMQ, ou encore archivage des données à long terme sur S3 ou HDFS.
Quid de la mise en file d'attente et de la régulation du flux ?
Lors de l'envoi de données vers Elasticsearch, que ce soit directement ou via un pipeline d'ingestion, chaque client doit pouvoir gérer les cas où Elasticsearch ne parvient plus à suivre le rythme ou à accepter davantage de données. C'est à ce moment qu'intervient ce qu'on appelle la fonctionnalité de régulation du flux. Si les nœuds de données ne parviennent plus à accepter de données, le nœud d'ingestion cesse d'en accepter à son tour.
Pour les architectures qui n'intègrent pas de mécanisme de mise en file d'attente dans leur pipeline de traitement (que ce soit à la source ou en cours de traitement), il existe un risque potentiel de perte de données si Elasticsearch n'est pas joignable ou ne peut accepter de données sur une période prolongée. Cela peut entraîner l'incapacité des agents Beats à stocker et lire les données des fichiers, ou encore l'incapacité d'autres processus à écrire directement dans Elasticsearch (par exemple, syslog-ng).
Logstash, en revanche, est capable de mettre les données en file d'attente sur le disque grâce à ses files d'attente persistantes. Cela lui permet de garantir la livraison des données au moins une fois et de les mettre localement en mémoire tampon lors des pics d'ingestion. Logstash prend aussi en charge l'intégration de différents types de files d'attente de messages. Il est donc compatible avec un très grand nombre de modèles de déploiement.
Comment enrichir et traiter mes données ?
Le nœud d'ingestion propose plus de 20 processeurs différents, qui couvrent les fonctionnalités des plug-ins Logstash les plus utilisés. Il impose toutefois une contrainte : son pipeline ne peut fonctionner que dans le contexte d'un événement unique. Par ailleurs, les processeurs ne peuvent généralement pas appeler d'autres systèmes, ni lire les données à partir d'un disque, ce qui limite quelque peu les types d'enrichissement possibles.
Le choix de plug-ins que propose Logstash est considérablement plus étendu. Citons par exemple les plug-ins qui permettent l'ajout ou la transformation de contenu en fonction des recherches effectuées dans les fichiers de configuration, dans Elasticsearch ou dans les bases de données relationnelles.
Beats et Logstash prennent aussi en charge l'exclusion et la suppression d'événements en fonction de critères configurables, ce qui n'est actuellement pas possible dans le nœud d'ingestion.
Lequel des deux produits est le plus simple à configurer ?
Voilà une question très subjective. La réponse dépend de votre parcours et de vos habitudes. Chaque pipeline du nœud d'ingestion est défini dans un document JSON stocké dans Elasticsearch. Vous pouvez définir un grand nombre de pipelines distincts, mais chaque document ne peut être traité que par un seul pipeline lorsqu'il transite par le nœud d'ingestion. Ce format peut s'avérer un peu plus simple à utiliser que le fichier de configuration Logstash, du moins pour les pipelines simples et bien définis.
Pour les pipelines plus complexes qui traitent différents types de formats de données, le fait que Logstash permette l'utilisation d'instructions conditionnelles pour le contrôle du flux le rend souvent plus simple à utiliser. Logstash permet aussi de définir plusieurs pipelines logiquement distincts, que vous pouvez gérer via une interface utilisateur basée sur Kibana.
Soulignons aussi que l'évaluation et l'optimisation des performances du pipeline est généralement plus simple dans Logstash. En effet, celui-ci prend en charge la fonctionnalité Monitoring et intègre l'excellente IU Pipeline Viewer, qui permet la détection rapide des goulets d'étranglement et des problèmes potentiels.
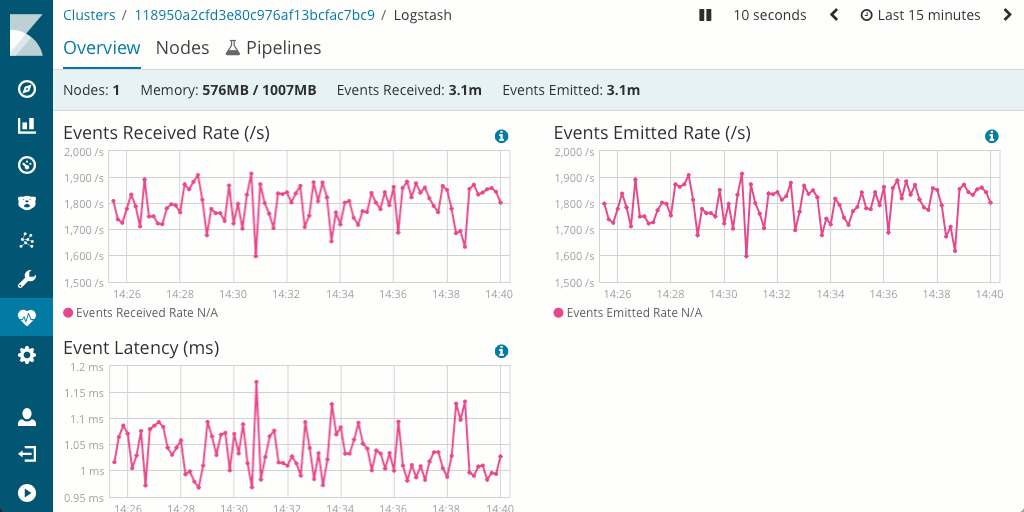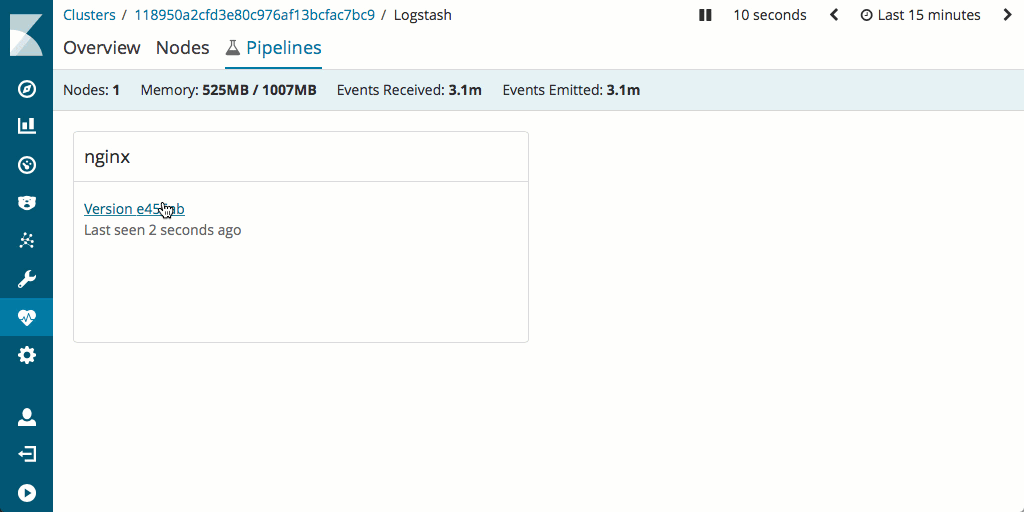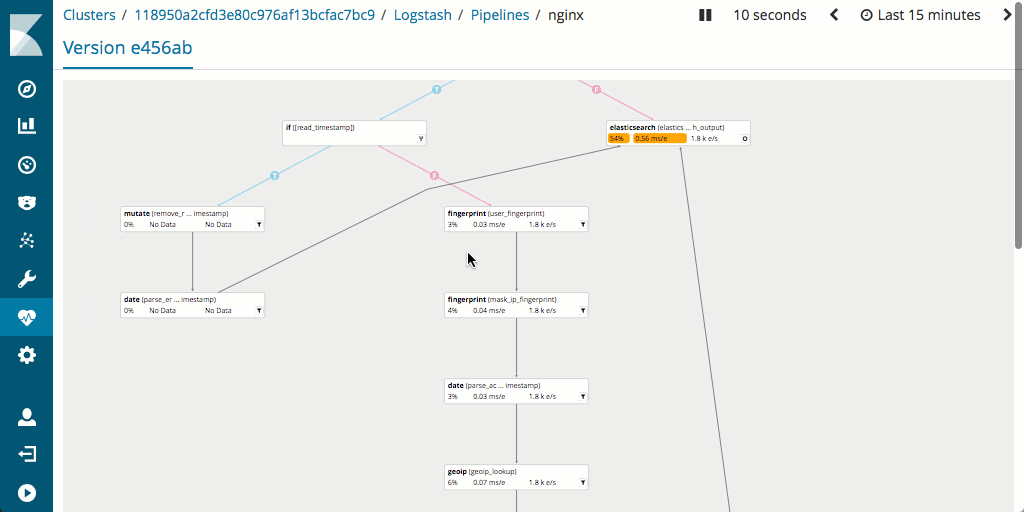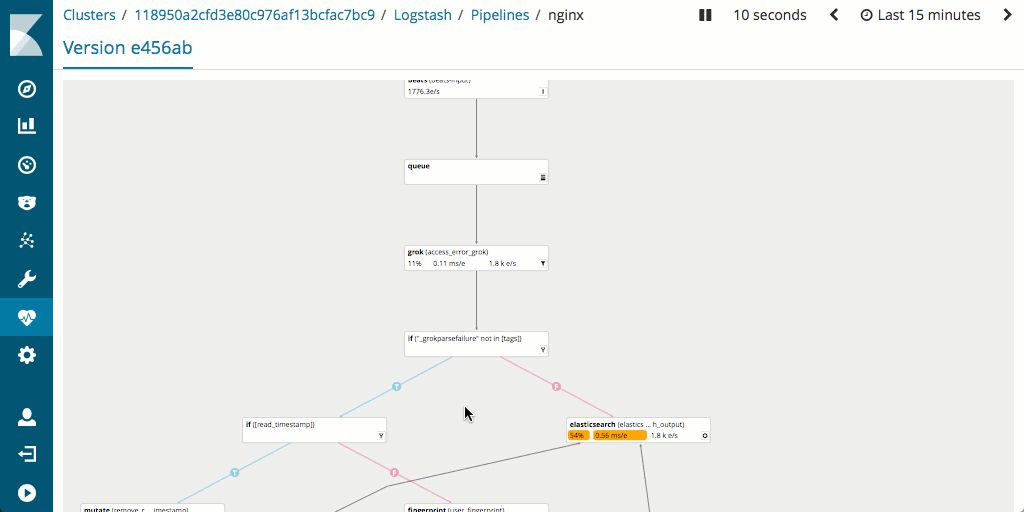
Quel impact sur l'empreinte matérielle ?
L'un des grands atouts du nœud d'ingestion est qu'il permet des architectures simplissimes, dans lesquelles les agents Beats peuvent directement écrire dans un pipeline de nœud d'ingestion. N'importe quel nœud de cluster Elasticsearch peut servir de nœud d'ingestion, ce qui se traduit potentiellement par une maîtrise des ressources matérielles et une simplification de l'architecture, du moins pour les cas d'utilisation peu complexes.
Lorsque le volume des données prend de l'ampleur ou que le traitement devient plus complexe et entraîne une plus grande charge processeur, il est généralement recommandé de passer à des nœuds d'ingestion dédiés. À ce stade, que ce soit pour héberger vos nœuds d'ingestion dédiés ou Logstash, vous aurez besoin de matériel supplémentaire. En termes d'empreinte matérielle, la différence de ressources nécessaires dépendra beaucoup de votre cas d'utilisation.
Le nœud d'ingestion intègre-t-il des fonctionnalités non disponibles dans Logstash ?
Vous avez peut-être l'impression que le nœud d'ingestion ne propose qu'un sous-ensemble des fonctionnalités qu'intègre Logstash. Mais cela n'est pas complètement exact.
Le nœud d'ingestion est compatible avec le plug-in Ingest Attachment Processor, qui permet le traitement et l'indexation des pièces jointes aux formats courants, tels que .ppt, .xls et .pdf. Il n'existe actuellement pas de plug-in équivalent pour Logstash. Si vous prévoyez d'indexer différents types de pièces jointes, vous aurez donc probablement besoin d'un nœud d'ingestion.
Le pipeline d'ingestion s'exécutant juste avant l'indexation des données, il s'agit aussi de la meilleure méthode si vous voulez ajouter un horodatage indiquant le moment de l'indexation de l'événement (par exemple, lorsqu'il s'agit de mesurer et d'analyser avec précision les retards enregistrés au cours de l'ingestion). Définir cet horodatage avant que les données ne soient bien parvenues dans Elasticsearch laisse place à une marge d'erreur : il peut en effet y avoir un décalage entre le moment où l'horodatage est défini et celui où les données sont indexées dans Elasticsearch. C'est le cas, par exemple, si la régulation du flux est appliquée ou si le client doit multiplier les tentatives d'indexation des données avant qu'elle ne soit effective. Vous pouvez utiliser ce type d'horodatage pour mesurer le retard enregistré lors de l'ingestion de chaque document.
Peut-on associer Logstash et un nœud d'ingestion ?
Bien qu'on décide souvent d'opter pour l'un ou pour l'autre, il est bien sûr possible de les associer, puisque Logstash permet d'envoyer les données vers un pipeline d'ingestion. Pour les architectures complexes, il peut aussi y avoir plusieurs flux logiques aux exigences très différentes. Vous pouvez ainsi en envoyer certains vers Logstash et d'autres directement vers les nœuds d'ingestion Elasticsearch. S'appuyer sur la méthode la plus pertinente selon le flux de données concerné facilite généralement la maintenance de l'architecture.
Conclusion
Les fonctionnalités de Logstash et du nœud d'ingestion Elasticsearch se chevauchent. Cela signifie que certaines architectures peuvent être implémentées au moyen de l'une ou de l'autre de ces technologies. Toutefois, chacune des deux options présente des points forts et des limites qui lui sont propres. Il est donc important d'analyser les exigences et l'architecture de tout votre pipeline de traitement pour choisir la méthode la plus adaptée en fonction des critères abordés dans cet article. Enfin, il ne s'agit pas nécessairement de choisir une technologie plutôt que l'autre : comme nous venons de le voir, vous pouvez les associer pour les utiliser simultanément ou en parallèle selon les parties du pipeline de traitement concernées.