Logging opérationnel chez Lyft : migration de Splunk Cloud à Amazon ES et Elasticsearch auto-géré
En quête d'une autre solution que Splunk ? En migrant de Splunk vers Elastic, vous pouvez unifier vos données d’observabilité et de sécurité sur une seule plate-forme, tout en réduisant vos coûts généraux et vos tâches administratives. Découvrez comment.
Cet article résume un témoignage d'utilisateur donné à l'Elastic{ON} 2018. Vous souhaitez voir d'autres présentations comme celle-ci ? Consultez les archives ou renseignez-vous sur les prochaines dates de l'Elastic{ON} Tour.
Quelle différence entre Amazon Elasticsearch Service et notre offre Elasticsearch Service officielle ? Pour le savoir, comparez les offres Elasticsearch Service d'AWS et d'Elastic sur cette page.
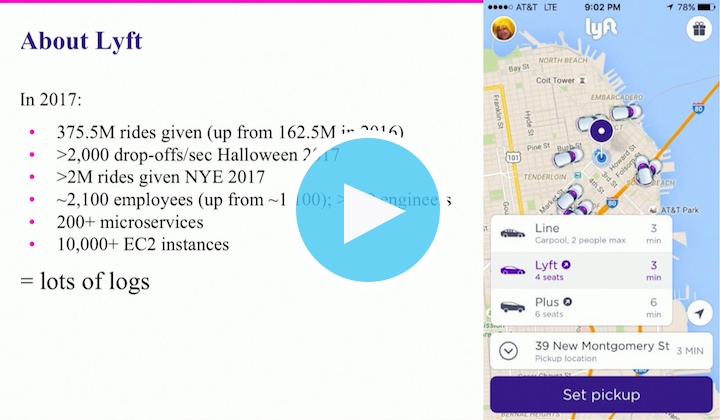
Lyft a besoin d'une infrastructure technologique puissante pour gérer des centaines de millions de trajets chaque année dans le monde entier (plus de 375 millions rien qu'en 2017) et veiller à ce que tous leurs clients puissent atteindre leur destination. En 2017, cela correspondait à plus de 200 microservices sur plus de 10 000 instances EC2. Ces valeurs sont encore plus importantes pour les périodes de pointe comme pour la Saint-Sylvestre (> 2 millions de trajets en un jour) et Halloween (plus de 2 000 trajets par minute en période de pointe). Pour assurer un fonctionnement parfait de tous ces systèmes et de tous ces trajets, il est important que les ingénieurs de Lyft aient accès à tous les logs opérationnels. Pour Michael Goldsby et son équipe Observability, cela revient à assurer un service de pipeline des logs constant.
Au début de son expérience d'analyse de logs, Lyft a utilisé le prestataire de services Splunk Cloud. Mais à cause des limites de rétention liées à son contrat, des délais d’ingestion des sauvegardes pouvant atteindre 30 minutes en période de pointe, et des coûts associés à la montée en charge, Lyft a décidé de passer à Elasticsearch.
Fin 2016, une équipe de deux ingénieurs a pu réaliser la transition de Lyft de Splunk à Amazon Elasticsearch Service sur AWS en environ deux mois. Le passage à Elasticsearch était fantastique, mais certaines parties de l'offre AWS n'étaient pas parfaites. Pour commencer, l'équipe de Goldsby voulait passer à Elasticsearch 5.x, mais AWS ne proposait que la version 2.3 à l'époque. De plus, les nouvelles instances étaient limitées à Amazon EBS pour le stockage, et la performance et la fiabilité à l'échelle de Lyft étaient sous-optimales. Enfin, les API Elasticsearch n'étaient pas toutes exposées sur AWS. Mais les limites d'AWS n'étaient rien par rapport aux avantages de la transition depuis Splunk Cloud.
Une fois les limites d'ingestion supprimées (ou du moins, repoussées considérablement), l'équipe Observability a décidé d'ouvrir grand les portes et d'adopter une nouvelle philosophie : "envoyez-nous tous vos logs". Les taux d'ingestion sont rapidement passés de 100 000 événements par minute à 1,5 million d'événements par minute. Cette nouvelle approche a permis un fonctionnement parfait pendant environ quatre mois. Lorsque l'équipe de Goldsby a commencé à rencontrer des expirations des délais d'ingestion, une réduction de la rétention et un ralentissement des tableaux de bord Kibana, il a suffi de monter en charge. Et lorsque la limite de 20 nœuds a été atteinte sur AWS, elle a reçu une exception spéciale lui permettant d'utiliser jusqu'à 40 nœuds.
Mais même avec 40 nœuds, certains problèmes subsistaient. Des problèmes de cluster rouge.
Les clusters rouges étaient un problème que l'équipe de Goldsby savait corriger (redémarrer, remplacer les nœuds, etc.). Le véritable problème, c'est qu'elle n'avait aucun accès direct aux clusters. À la place, il fallait créer un ticket chez Amazon et attendre le support technique, parfois pendant des heures en période de pointe. Le ticket était ensuite remonté, car la première ligne de support technique ne pouvait pas accéder aux clusters. Finalement, Lyft a appris que pour accélérer le processus de remontée, il était possible de s'adresser directement au Technical Account Manager (TAM), qui s'occuperait de faire en sorte que les clusters repassent au vert.
Entre les interventions inévitables du support technique, la limite à la version 2.3, l'exigence d'EBS et les autres limites imposées par AWS (équilibrage de charge en round-robin, délais d'expiration de 60 secondes, obscurcissement des API, etc.), l'équipe Observability a décidé de procéder à une nouvelle transition, cette fois, vers un déploiement Elasticsearch auto-géré. "[Sur AWS], on ne profite pas de toutes les fonctionnalités. On ne peut pas appuyer sur tous les boutons", explique Goldsby. "Nous sentions que nous avions assez d'expérience opérationnelle avec Elasticsearch en interne pour pouvoir réussir."
Avec une équipe un peu plus importante que celle utilisée pour la migration depuis Splunk, Lyft a pu passer d'Amazon Elasticsearch Service à une solution Elasticsearch auto-gérée en seulement deux semaines. Lyft dispose désormais de son propre déploiement, ainsi que de toutes les fonctionnalités qui étaient auparavant limitées sur AWS. Cela signifie également que l'entreprise est responsable de tous les aspects opérationnels de la Suite Elastic, y compris maintenir ses clusters dans le vert et assurer la satisfaction de ses utilisateurs (collègues).
Découvrez comment Lyft a mis en œuvre son propre déploiement Elasticsearch auto-géré en regardant la présentation La folle aventure de Lyft d'Amazon ES à Elasticsearch auto-géré pour l'analyse des logs opérationnels à l'Elastic{ON} 2018. Vous découvrirez les choix concernant le matériel, les décisions de gestion du cycle de vie des indices et bien plus, y compris la raison pour laquelle "tout logger" ne signifie pas "logger tout" pour ce qui est de la qualité de service.