Exploiter Elasticsearch pour améliorer les performances de 1 000 %
Voxpopme est l'une des premières plateformes d'études en vidéo au monde. Créée en 2013, l'entreprise a été fondée sur le principe simple que la vidéo est le moyen le plus puissant de permettre à des centaines et des milliers de personnes de s'exprimer en même temps. Notre logiciel unique ingère les vidéos enregistrées par les consommateurs et le contenu de longue durée (par exemple, les groupes de discussion) auprès de divers partenaires de sondages, et fournit des données commerciales précieuses sous la forme de graphes, de thèmes à parcourir et de bandes démo personnalisables.
Depuis notre lancement, nous avons passé quatre ans à optimiser et à automatiser les informations que l'on peut obtenir grâce à la vidéo, afin d'éliminer les obstacles qui empêchent une connexion véritable entre les marques et les clients. Pour améliorer l'expérience des clients, nous utilisons les derniers outils de NLP (Natural Language Processing, traitement automatique du langage) d'IBM Watson pour identifier et rassembler l'opinion des participants aux sondages. Nous avons également un partenariat exclusif avec Affectiva pour analyser les expressions faciales émotionnelles. En 2017, nous avons ajouté Elasticsearch à notre arsenal d'outils pour offrir la meilleure expérience possible à nos clients.
Au-delà de notre infrastructure existante
Chez Voxpopme, notre pile technologique a connu des changements importants au cours des douze derniers mois. En 2017, notre plateforme a traité un demi-million de sondages vidéo : autant que l'ensemble des quatre années précédentes. Et ce chiffre devrait doubler en 2018. Nous avons été confrontés à des problèmes de montée en charge. Ce problème était un bon signe, mais un problème tout de même.
Les problèmes provenaient de notre système existant, qui se composait d'une application PHP monolithique, qui interagissait avec un certain nombre de bases de données différentes pour les fonctionnalités de base. À l'origine, la logique sur laquelle reposait cette séparation des données faisait sens :
- La plupart de nos données étaient stockées dans une base de données MySQL. Cela comprenait les utilisateurs, les réponses vidéo individuelles, et autres données similaires – des données relationnelles structurées, reliées entre elles par des clés étrangères, et qui étaient créées, lues, mises à jour et supprimées à l'aide d'une API RESTful ;
- Les données des clients étaient stockées dans un cluster MongoDB, que nous avions accepté tel qu'il nous avait été fourni. Cela permettait aux utilisateurs d'ajouter des balises, des annotations et des filtres à leurs vidéos selon leur propre terminologie ;
- Nous stockions les transcriptions des vidéos de nos participants dans un petit cluster Elasticsearch, que nous utilisions pour les recherches en texte intégral.
Cette approche a très bien fonctionné pendant longtemps, mais il y avait un problème évident.
La puissance de calcul n'est ni gratuite ni infinie
Une recherche sur notre plateforme pouvait être extrêmement simple ou très complexe. Dans les instances plus simples, nous laissions les utilisateurs rechercher par clé principale d'une réponse vidéo. C'est facile, et il suffit d'une simple requête dans la base de données MySQL indexée.
Mais comment faire pour les requêtes dans lesquelles un utilisateur veut filtrer à l'aide d'un entier indexé, certaines de ses données en texte libre, et limiter les résultats à tous les participants mentionnant un sujet en particulier ? Par exemple :
Trouver tous les enregistrements dont la date de réponse est comprise entre le premier et le dernier jour du mois de juin, lorsque les revenus du ménage du participant sont compris entre 100 000 $ et 125 000 $, et qui comprennent l'expression "trop cher".
Voici l'approche que nous avions adoptée :
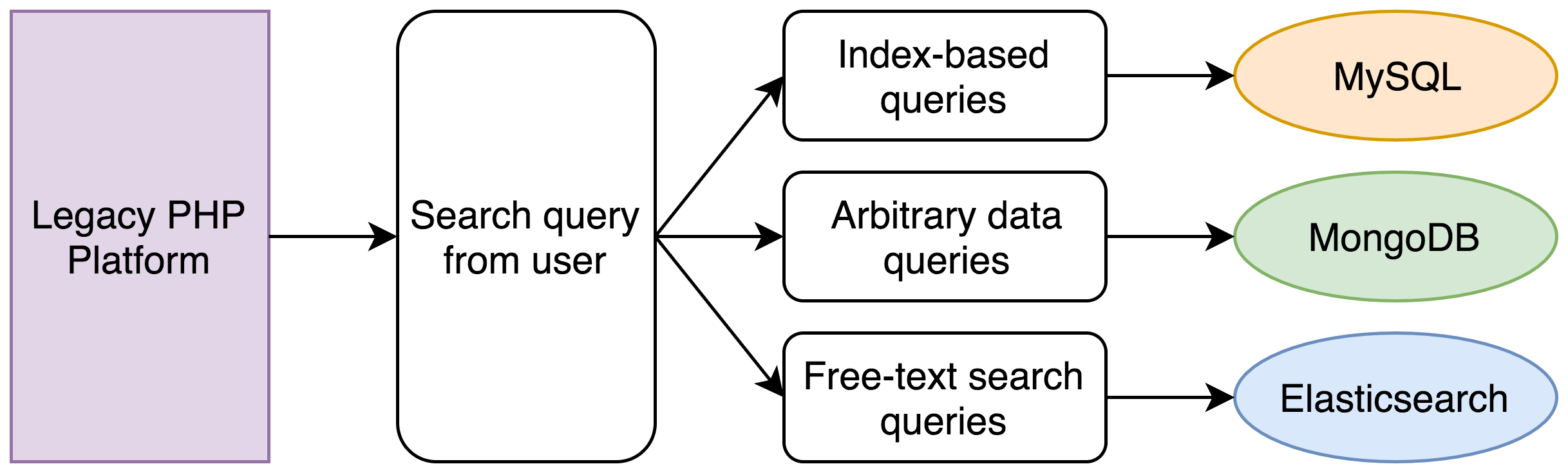
Dans notre système existant, les opérations suivantes devaient se produire :
- Une recherche MySQL trouvait tous les enregistrements compris dans la plage de dates ;
- Une recherche MongoDB trouvait tous les enregistrements compris dans la plage de revenus (les revenus ne sont qu'un exemple ; les clients stockent souvent des informations complètement arbitraires chez nous) ;
- Une recherche Elasticsearch trouvait tous les enregistrements dont la transcription contenait l'expression correspondante ;
- Une intersection des ID des trois ensembles d'enregistrements était calculée ;
- Un nouvel ensemble de recherches MySQL et MongoDB était exécuté pour obtenir l'ensemble de données complet pour chaque enregistrement ;
- Les enregistrements étaient triés et paginés.
Un ensemble de critères de recherche simples pouvait facilement nécessiter cinq recherches distinctes dans des bases de données. Au début, cette opération prenait moins d'une seconde. Cependant, avec cinq ans de données et le fait que le PHP fonctionne avec un seul thread, les recherches dans la base de données devaient être effectuées l'une après l'autre et pouvaient facilement prendre 30 secondes.
Ce modèle nous a permis de nous installer rapidement sur le marché et il nous a bien servi pendant de nombreuses années, mais sa montée en charge n'était pas adaptée. Lorsque nous avons remarqué que l'expérience de nos utilisateurs commençait à se dégrader, nous avons décidé qu'il était temps de réécrire le mécanisme de recherche.
Nous avions déjà un peu d'expérience avec Elasticsearch dans notre pile existante. Nous avons donc contacté un responsable de ventes Elastic pour parler des problèmes auxquels nous étions confrontés pour réaliser des recherches complexes sur une plage de données stockées dans plusieurs endroits. Il était essentiel de trouver la bonne solution : notre produit a pour but d'afficher et d'exécuter des calculs sur nos données rapidement et efficacement. Les goulots d'étranglement lors de la récupération des données étaient inacceptables.
Nous avons également envisagé d'agrandir notre cluster MongoDB existant, mais après une courte consultation téléphonique avec Elastic, l'équipe de développement a décidé qu'Elasticsearch était la seule solution nous permettant de stocker, rechercher et manipuler facilement des données (c'est-à-dire, les agrégations).
Nos premières impressions
Le cluster Elasticsearch que nous avions utilisé pour la recherche de texte était un cluster de version 1.5 de Compose.io. Comme nous avons fortement investi dans AWS pour le reste de notre infrastructure, nous avons d'abord choisi Amazon Elasticsearch Service avec un cluster de version 5.x.
Notre nouveau modèle impliquait de maintenir toutes les données disparates d'un enregistrement dans un seul document Elasticsearch, en utilisant des valeurs imbriquées et des clés connues pour les données sous forme libre plus compliquées de nos clients. Une seule recherche Elasticsearch permettait alors de gérer n'importe quelle recherche utilisateur.
Sous une semaine, nous avions une démonstration de faisabilité basique avec quelques milliers de documents. Nos premières impressions de l'exécution de recherches avec Kibana étaient suffisantes et nous avons décidé de passer à une réécriture totale de notre mécanisme de recherche en backend.
Notre nouvelle approche était la suivante :
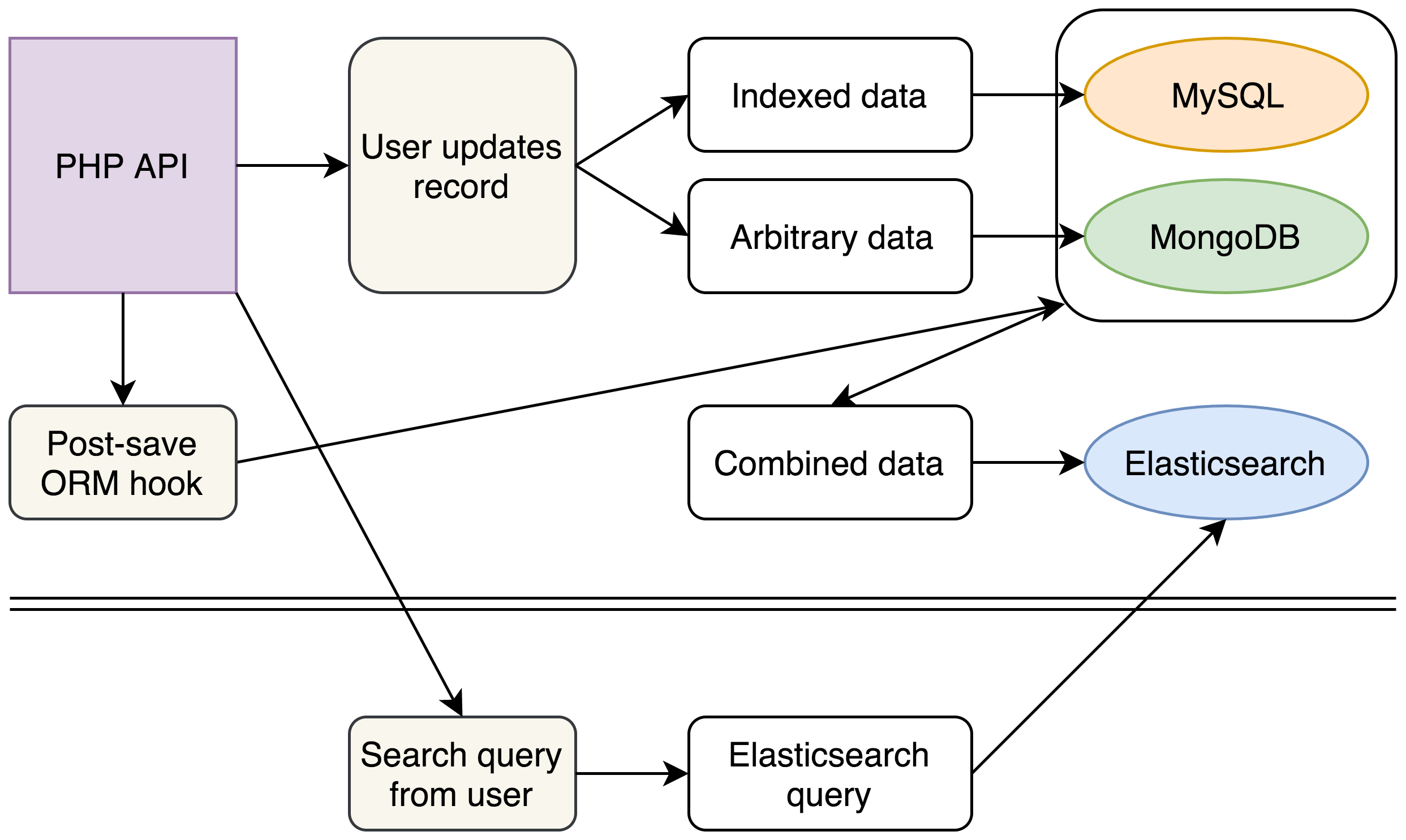
(Pour le moment, nos bases de données existantes ne changeaient pas, mais l'introduction de notre nouveau cluster Elasticsearch pour les recherches complexes nous a permis de prévoir de supprimer complètement MongoDB de notre pile)
Avec notre nouvelle pile, nous avons continué à écrire des données dans MySQL et MongoDB, comme auparavant. Toutefois, chaque écriture déclenchait également un événement qui recueillait et aplatissait toutes nos données provenant des diverses sources dans un seul document JSON inséré dans Elasticsearch.
En backend, nous avons formulé un nouveau mécanisme de recherche pour construire des recherches Elasticsearch complexes à partir des recherches existantes de nos utilisateurs et nous avons complètement supprimé le code existant qui envoyait une demande à MySQL et MongoDB. En interrogeant un seul cluster Elasticsearch, nous pouvions obtenir les mêmes données en une fraction du temps nécessaire auparavant.
La structure de nos documents Elasticsearch nous a permis d'obtenir d'autres avantages. Notre API affiche des documents JSON. Nous avons donc pu structurer nos documents Elasticsearch de manière à ce qu'ils correspondent exactement à notre sortie API existante, pour gagner quelques autres secondes qui étaient préalablement requises pour combiner et restructurer les données provenant de MySQL et MongoDB.
Nous avons pu annoncer une augmentation de performance préliminaire de 1 000 % pour les parties principales de notre plateforme aux différents acteurs du secteur.
Ce n'est pas le fournisseur que vous recherchez
Après avoir promis une augmentation de performance de 1 000 % à tout le monde, l'étape suivante consistait à indexer toutes nos données et espérer que les chiffres résistent à la pression.
Avec toutes nos données indexées, malheureusement, le cluster AWS ne s'en est pas bien sorti.
Si nous avions simplement indexé les données une fois pour les rechercher plusieurs fois, il en aurait peut-être été autrement. Mais notre modèle s'appuyait sur le fait de combiner et de réindexer les données chaque fois qu'elles étaient mises à jour dans MySQL ou MongoDB. Cela pouvait correspondre à des milliers de fois pendant la période pendant laquelle il était plus probable que la recherche ait lieu.
Nous avons découvert que la performance en pâtissait, et les temps de recherche atteignaient parfois plusieurs secondes. Cela avait pour conséquence un blocage potentiel de notre application PHP, ce qui pouvait laisser des connexions MySQL ouvertes et, par un terrible effet de domino, c'est toute notre pile qui pouvait cesser de répondre.
Nous avons rencontré ces problèmes lorsque Elastic{ON} est arrivé à Londres, et nous avons profité de cette occasion pour parler avec un représentant Elastic sur le stand AMA des tailles de cluster et des problèmes auxquels nous étions confrontés. Nous avons mentionné que nos meilleurs délais de recherche étaient d'environ 40 ms. Le représentant nous a conseillé d'utiliser le service Elastic Cloud d'Elastic au lieu d'AWS pour atteindre des temps de réponse se rapprochant de 1 ms avec les paramètres par défaut.
La disponibilité de Fonctionnalités de la Suite Elastic (initialement regroupées dans X-Pack) sur Elastic Cloud représentait un avantage considérable pour nous, car nous n'avions que des systèmes de logging et de graphes limités à l'époque. Comme X-Pack est absent de l'offre Elasticsearch d'AWS, nous avons décidé de déployer un cluster Elastic Cloud pour effectuer quelques tests comparatifs. Si les performances de ce cluster étaient au moins équivalentes à celles du cluster AWS, nous savions que nous l'adopterions pour les autres avantages qu'il proposait.
L'interface utilisateur d'Elastic Cloud était très épurée et facile à utiliser. Pendant l'indexation, nous avions besoin d'augmenter l'échelle, car nous avions ajouté plus de travailleurs pour traiter les données. Nous avons été impressionnés par la simplicité avec laquelle nous pouvions gérer le cluster. Il n'y a qu'à faire glisser un curseur vers la droite ou vers la gauche et à cliquer sur "Update" (Mise à jour).
Une fois les données indexées dans le nouveau cluster, nous avons pu exécuter des recherches complexes en seulement 2 ms, avec très peu de blocages (depuis, nous avons renforcé l'optimisation du système pour éliminer complètement les blocages). Même si l'utilisateur final ne perçoit généralement pas un délai supplémentaire de quelques millisecondes, les techniciens parmi nous étaient ravis de voir que la latence était réduite à 5 % de sa valeur précédente.
Tirer le meilleur de nos données
Nous ne voulions pas nous contenter de la vieille école et utiliser Elasticsearch comme moteur de recherche pour les utilisateurs finaux. Beaucoup des histoires de réussite que nous avions entendues sur la technologie semblaient se concentrer sur les logs, et nous avons rapidement découvert que nous ne faisions pas exception à la règle.
Nous avons configuré un cluster de logging séparé pour ingérer les logs de nos pods Kubernetes et avons désormais une meilleure visibilité sur l'état de nos serveurs, ce qui n'était pas possible auparavant, et nous pouvons réagir plus vite en cas de problème.
Nous avons également pu proposer quelque chose de similaire aux utilisateurs de notre plateforme. Grâce aux agrégations, nous avons pu fournir à nos utilisateurs une méthode de visualisation graphique des données. Cela était un excellent ajout à notre plateforme, et ce n'était qu'un effet secondaire rendu possible par la présence de nos données dans Elasticsearch.
Ces derniers mois, nous avons affiné et amélioré nos processus, et nous observons maintenant une meilleure performance de nos clusters Elasticsearch chaque semaine. Ces augmentations de la performance comprennent des gains de mémoire importants en déplaçant les champs nécessitant les fielddata de notre cluster principal dans un cluster plus petit, auquel on accède moins souvent (notre pression mémoire de référence est désormais de 25 %, contre 75 % auparavant). Nous avons également optimisé notre code pour écrire les nouvelles données en vrac, plutôt qu'à la demande, ce qui a rendu le cluster beaucoup plus réactif pendant les heures de pointe.
À l'avenir, nous prévoyons d'utiliser largement Elasticsearch pour analyser les données internes que nous détenons en tant qu'entreprise. Comme cette méthode a fait ses preuves au cœur de notre produit destiné aux utilisateurs finaux, nous avons déjà commencé à faire des expériences en stockant nos propres données dans les index Elasticsearch, et nous comptons utiliser la Suite Elastic pour obtenir des informations sur l'efficacité opérationnelle de notre entreprise.
 David Maidment est ingénieur logiciel en chef chez Voxpopme. Il se consacre à assurer la pérennité du codebase de la plateforme au cours de la croissance exponentielle de l'entreprise.
David Maidment est ingénieur logiciel en chef chez Voxpopme. Il se consacre à assurer la pérennité du codebase de la plateforme au cours de la croissance exponentielle de l'entreprise.
 Andy Barraclough est un cofondateur et Directeur technique de Voxpopme. Il se concentre sur la gestion de l'équipe technique et la coordination de la vision de l'entreprise sur le long terme.
Andy Barraclough est un cofondateur et Directeur technique de Voxpopme. Il se concentre sur la gestion de l'équipe technique et la coordination de la vision de l'entreprise sur le long terme.