La visualisation appliquée aux archives avec Elasticsearch et Kibana
En tant que chef de projet pour l’accès aux ressources numériques des Archives nationales, je travaille sur un projet de visualisation de données élaborée avec Kibana à partir des métadonnées que nous publions. Bien que cette « preuve de concept » (POC) soit une initiative personnelle elle vient alimenter nos réflexions professionnelles sur les projets en cours.
Afin de comprendre pourquoi cette expérimentation ouvre de nouvelles perspectives, penchons-nous rapidement sur le fonctionnement des Archives Nationales. L’activité y est organisée selon le processus des quatre « C » : Collecter > Conserver > Classer > Communiquer. Chacune des étapes s’intéresse aux documents originaux et métadonnées (descriptives, techniques ou de gestion) qui les accompagnent.
A l’heure actuelle, les filières de traitement des archives physiques (parchemin, papier, plans, photo, audiovisuel, etc.) et numériques (bureautique, messagerie, base de données, photo, audiovisuel, etc.) sont globalement disjointes. Nous concevons progressivement des systèmes de gestion, d’interrogation et de consultation mutualisés pour l’ensemble des corpus, indépendamment de leur (im)matérialité.
La pratique archivistique actuelle de description –très littéraire– conditionne l’offre que nous sommes en mesure de proposer au public (citoyens, chercheurs, journalistes, historiens, généalogistes, acteurs publics, etc.). Prenons l’exemple du Fond Simone VEIL. L’usager effectue une recherche « plein-texte » sur notre application web “Salle des Inventaires Virtuelle”, puis consulte la liste des résultats (notices descriptives rédigées). Ensuite il doit lire chaque notice qui l’intéresse et éventuellement relancer une recherche connexe pour découvrir d’autres ressources.
Les usagers rencontrent les difficultés suivantes :
- Une consultation chronophage - la pratique de recherche est séquentielle (consulter les notices une à une) et itérative (recherches successives)
- Une consultation verticale - a manière dont les notices sont classées crée un mini-silo d’informations, rendant toute recherche thématique compliquée.
- Une approche opaque - l’interface de recherche est basée sur une zone de saisie textuelle. Pour trouver les ressources, il faut savoir exactement ce qu’on recherche, or l’usager préférerait qu’on lui présente d’abord les ressources disponibles.
- Une modélisation des ressources hétérogènes - chaque archive, matérielle et numérique, a une modélisation différente rendant compliquée la création d’un moteur de recherche central.
Pourquoi Elasticsearch ?
Pour améliorer l’offre que nous proposons aux usagers, j’ai développé une preuve de concept à l’attention de mes collègues. La première étape a été de trouver une solution avec laquelle je puisse expérimenter. Dans l’immédiat, je me suis focalisé sur Kibana mais l’expérimentation s’intéresse aux multiples modalités d’accès à l’information : indexation, recherche, API / interopérabilité, visualisation, cartographie, chronologie, statistiques, etc. La Suite Elastic, basée sur un moteur de recherche et proposant des couches de traitement complémentaires, est parfaitement adaptée à l’exploration interactive de métadonnées descriptives, techniques, de gestion ou d’usage. Enfin, Kibana favorise les échanges informels autour d’un démonstrateur opérationnel installé sur un simple ordinateur portable.
J’ai alors étudié trois cas d’usage :
- « Grand public », pour offrir aux usagers une nouvelle expérience de recherche.
- « Professionnelle », afin de proposer aux archivistes un outil d’aide à la décision.
- La « convergence » des interfaces de recherche, pour les archives traditionnelles et numériques.
Modélisation et normalisation
Glissons vers une approche exclusivement « data centric ». Au sein des notices XML essentiellement littéraires, nous allons extraire quelques métadonnées afin d’établir une description structurée pour chaque fonds.

Avec quelques lignes de code (Bash), je parcours chaque notice XML pour extraire les informations que je souhaite finalement représenter dans Kibana. Ces scripts produisent des fichiers CSV, qui sont ensuite retraités avec OpenRefine et remodélisés en JSON. Les documents obtenus sont alors indexés dans une instance locale d’Elasticsearch (sur mon PC portable) et interfacée avec Kibana. L’exploration des fonds d’archives peut alors commencer…
Explorer les fonds
Une représentation visuelle facilite la navigation entre les masses d’information et stimule la sérendipité ou les rebonds.
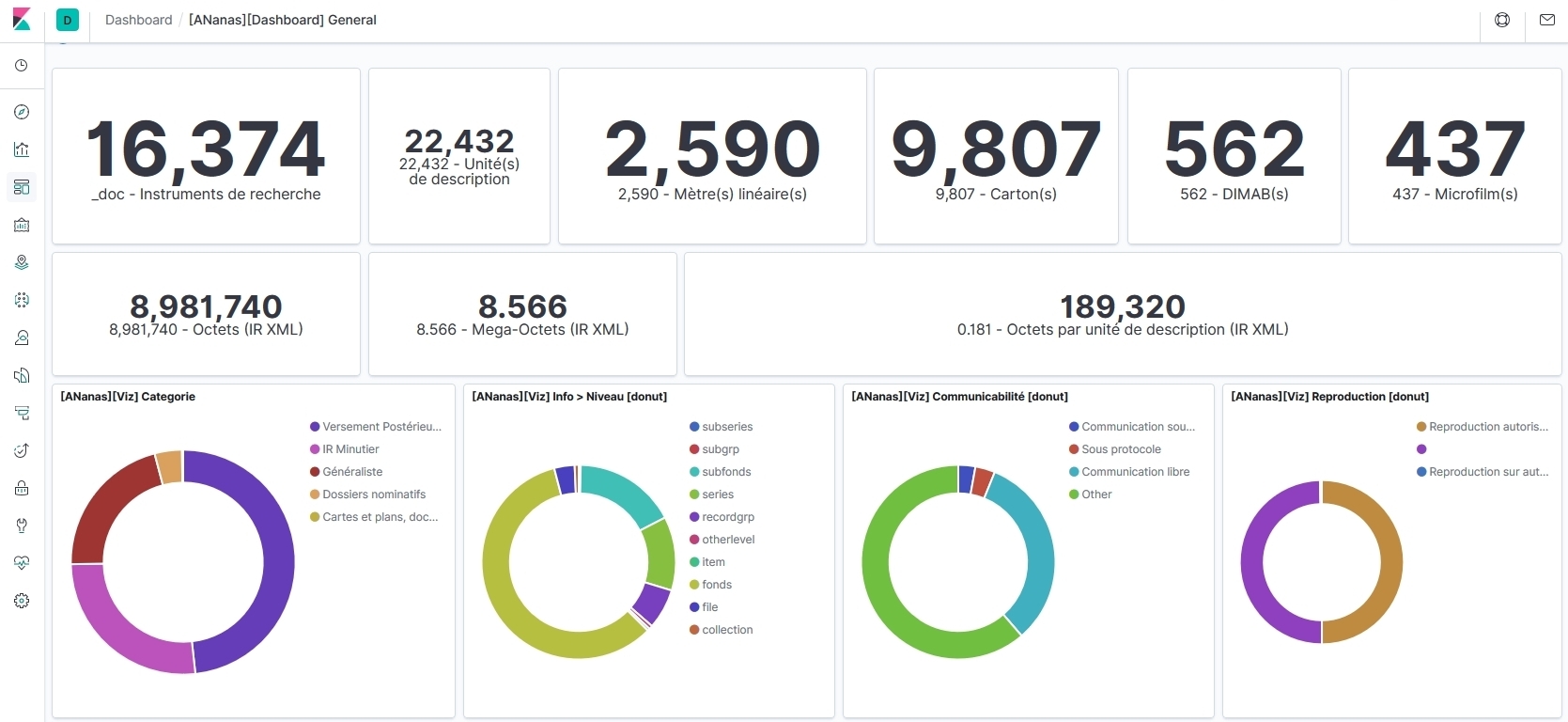
Sur le tableau de bord Kibana, constitué d’une vingtaine d’indicateurs simples, l’usager combine les critères « à volonté » et obtient une recherche filtrée « en temps réel ». Il affine progressivement son besoin, dans une exploration empirique et infinie.
Notre tableau de bord est composé de trois ensembles :
- La liste des notices remplissant les critères de sélection (répondant aux filtres actifs).
- Des indicateurs quantitatifs, permettant d’évaluer le volume de résultats.
- Une vingtaine de filtres combinables :
- Période de production des documents (ex : 1974-1978)
- Entité productrice (ex : Premier Ministre)
- Périmètre fonctionnel (ex : Exécutif)
- Sujet (ex : Budget)
- Fonction (ex : Réglementation)
- Lieux référencés (ex : Paris)
- Typologie (ex : Contrat)
- Site de stockage (Paris / Pierrefitte-sur-Seine / Fontainebleau)
- etc.
Par exemple, voici une vue synthétique obtenue sur le corpus « Les archives des notaires de Paris », disséminé sur 2 365 notices :
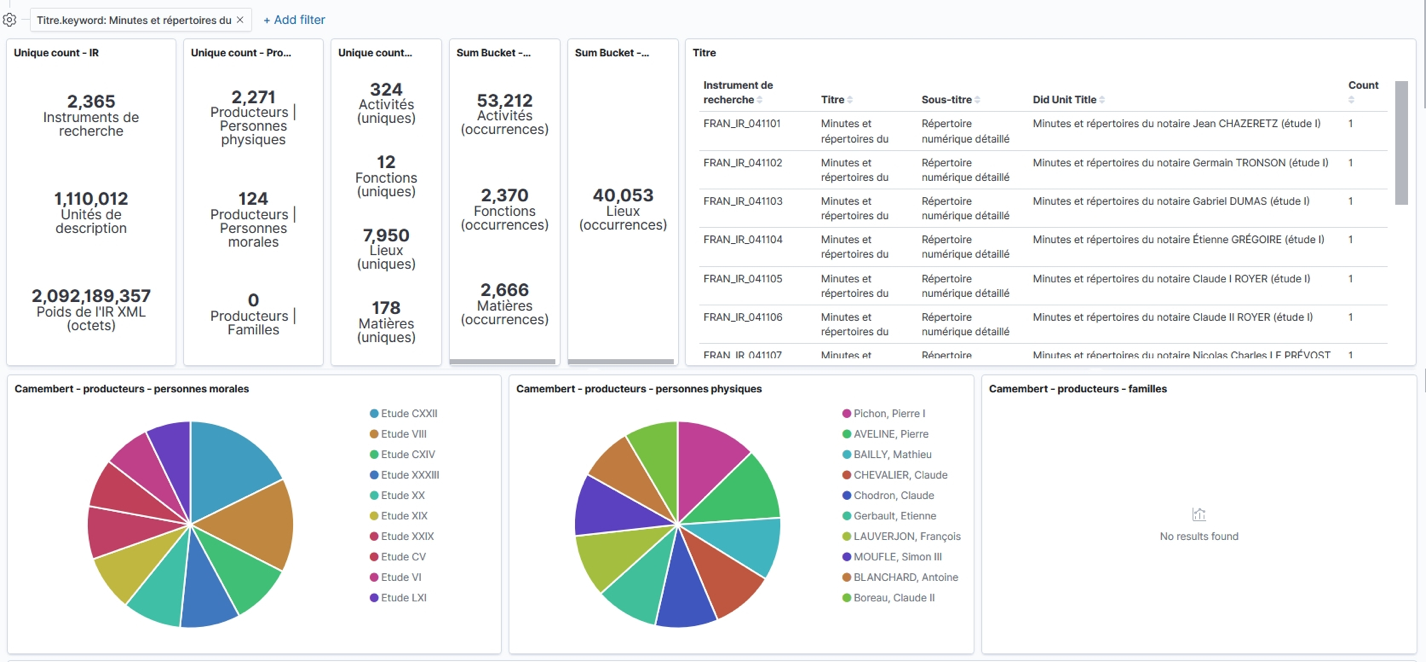
Le tableau de bord nous présente également la typologie des documents produits par les notaires et archivés aux Archives nationales. L’usager peut activer des filtres directement en cliquant sur les valeurs remontées dynamiquement par l’indicateur.

De même, l’usager peut parcourir le corpus en fonction des dates de rédaction des documents. L’activation et la combinaison des filtres produit un tableau de bord entièrement recalculé. L’usager affine progressivement sa recherche par ajout, modulation on suppression de filtres. Lorsque le processus a finalement permis de délimiter un périmètre restreint de corpus, l’usager enregistre la liste des quelques notices répondant à ses critères pour lecture en SIV.

Le pilotage par la métadonnée
La visualisation améliore notre compréhension du stock d’information. Dès lors, elle peut être envisagée comme outil d’audit qualité, de traçabilité des flux ou de pilotage de l’activité.
Par exemple, l’archiviste peut chercher les notices qui ne sont pas associées au référentiel des « types de document » en isolant celles pour lesquelles la valeur de l’indicateur est « VIDE » :

Une analyse statistique permet d’observer des tendances sur les flux entrants.
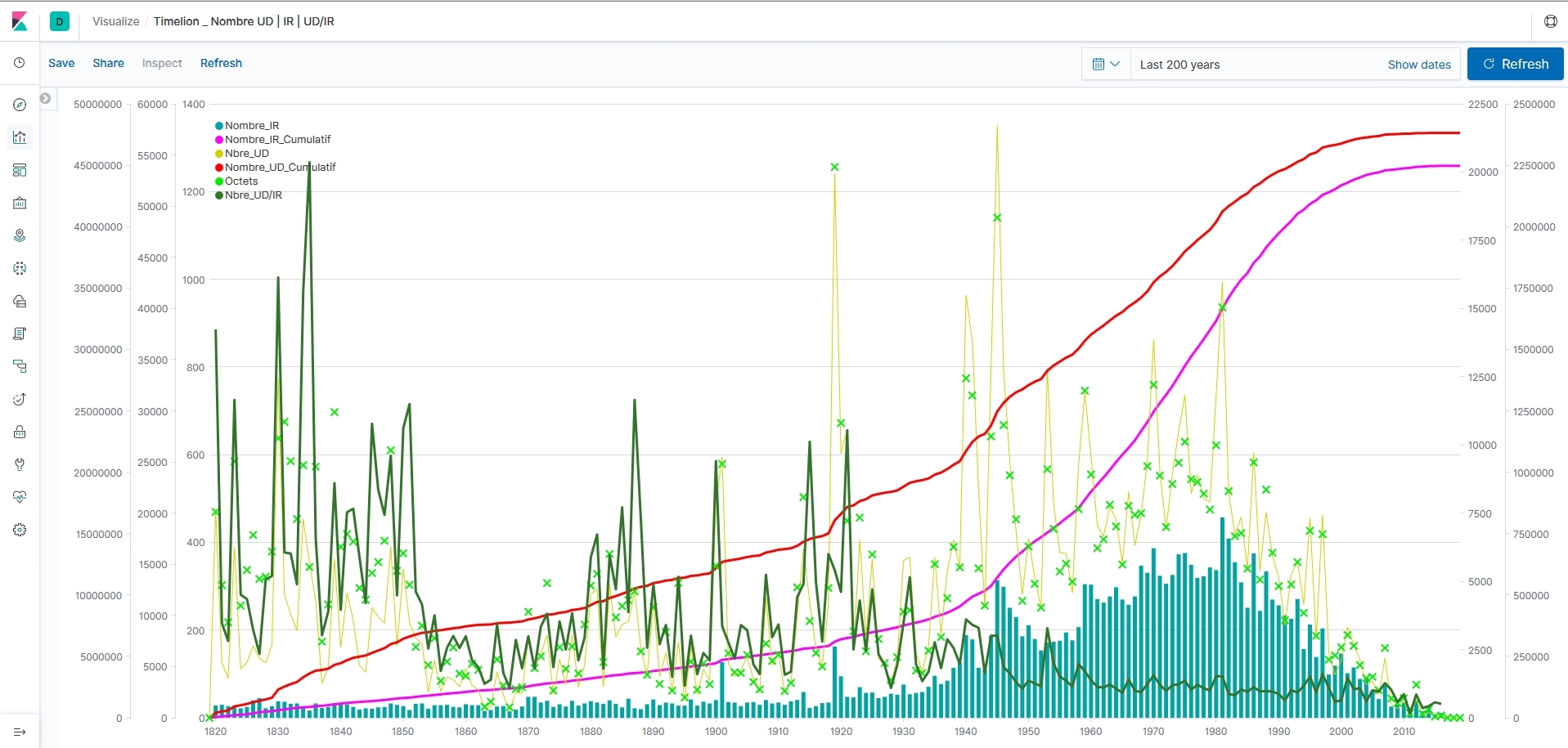
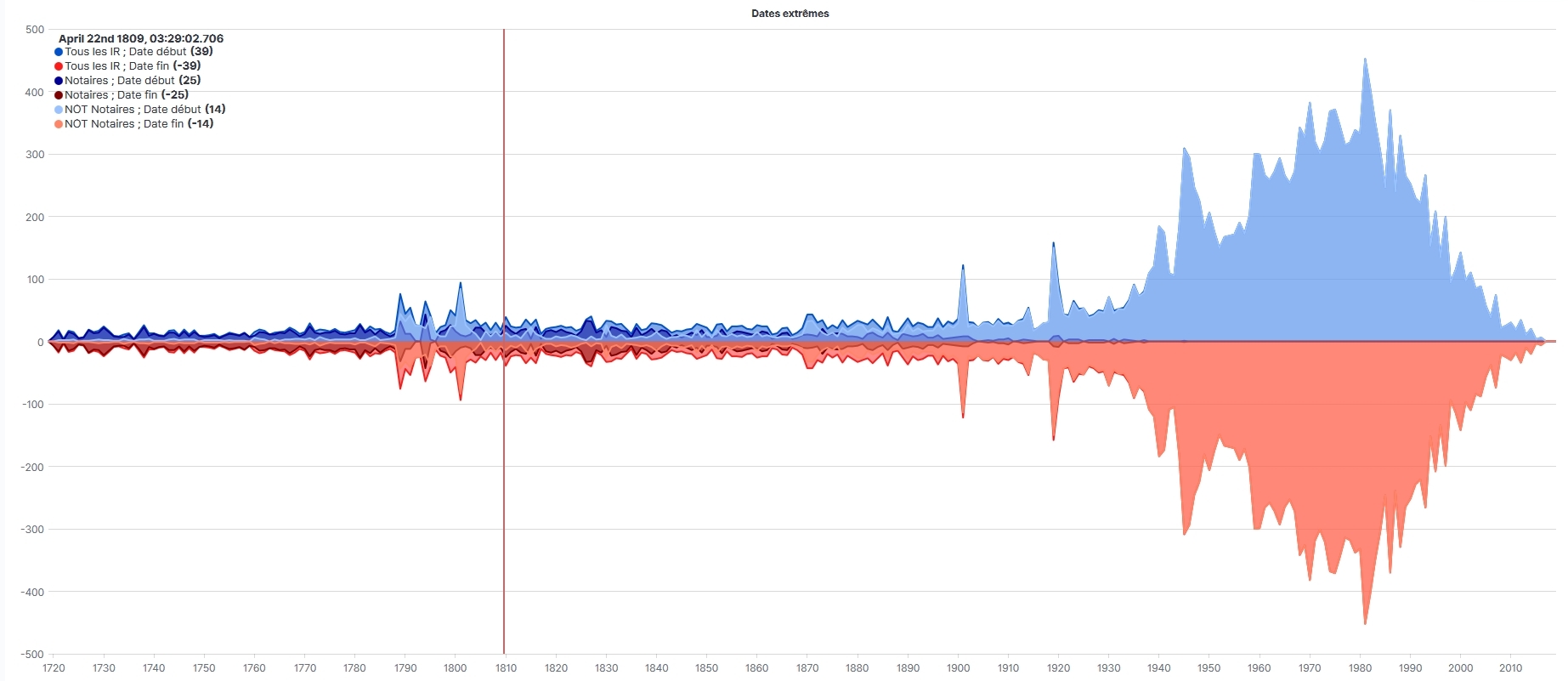
Une analyse chronologique expose l’évolution des pratiques métiers séculaires. A partir de là, nous pouvons focaliser l’attention sur les archives d’une période spécifique (par exemple : entre 1720 et 1865) ou un sous-ensemble (par exemple : les inventaires des notaires de Paris).
A Suivre…
Finalement, la création du POC s’est avérée relativement simple. A l’issue d’un projet de quelques jours-hommes, j’ai pu présenter un produit minimal mais opérationnel à de nombreux collègues. Ces démonstrations amorcent toujours des échanges très riches et souvent inattendus. Elles nous permettent de réfléchir collectivement au stock d’information sur lequel nous travaillons (les archives et les métadonnées), à l’évolution du métier ou à l’émergence de nouveaux besoins. Au sein du réseau national des archives (départementales, nationales, interministérielles), le POC (dont une nouvelle version est à l’étude) participe activement à l’évolution des pratiques et des regards sur l’information que nous produisons. A l’issue des premières démonstrations, plusieurs partenaires envisagent de s’inspirer de cette expérimentation pour intégrer Kibana à leur système d’information. En quelques semaines à peine, le démonstrateur a impulsé sa dynamique et œuvré à la conduite du changement. Cet article reflète l’état des travaux en cours. Pour suivre l’actualité du POC, rendez-vous sur https://twitter.com/louivig

| Chef de projet pour l'accès aux ressources numériques des Archives nationales (France), Louis Vignaud est responsable de l’application « Salle des Inventaires Virtuelle » (SIV) permettant aux usagers d’effectuer une recherche sur les archives, consulter les documents numérisés ou d’accéder à la salle de lecture. En tant que Product Owner délégué aux questions d’accès en salle et diffusion web, il participe au projet ADAMANT/ VITAM, pour la prise en charge des archives numériques de l’Etat. |