Génération et visualisation d’alphas avec les ensembles de données Vectorspace AI et Canvas
Résumé
Nous allons découvrir aujourd’hui l’histoire de Vectorspace et les raisons qui ont poussé la plateforme à utiliser la Suite Elastic et Canvas dans Kibana pour exploiter ses ensembles de données afin de visualiser des informations et libérer le plein potentiel des données.
Arrière-plan
Remontons en 2002. Cette année-là, au laboratoire national Lawrence Berkeley, Vectorspace crée des vecteurs de caractéristiques basés sur la compréhension du langage naturel (NLU), que l’on connaît aussi aujourd’hui sous le nom de plongements lexicaux. Les vecteurs de caractéristiques servent à générer des ensembles de données de matrices de corrélation, dont la fonction est d’analyser les relations invisibles existant entre les gènes et le prolongement de la durée de vie, le cancer du sein et les réparations d’ADN endommagé par des rayonnements spatiaux.
Les sources de données utilisées sont nombreuses : expériences en laboratoire, articles scientifiques issus de la National Library of Medicine, ontologies, vocabulaires contrôlés, encyclopédies, dictionnaires et autres bases de données de recherche sur le génome.
À cette époque, Vectorspace met également en œuvre AutoClass, un système de classification bayésien servant à classifier les étoiles, ainsi que les groupes de gènes d’après un ensemble de données contenant les valeurs d’expression des gènes. Les pertes sont limitées et les résultats gagnent en pertinence grâce aux plongements lexicaux et à la modélisation thématique qui viennent enrichir les ensembles de données. L’objectif est alors d’imiter les connexions conceptuelles qu’un chercheur biomédical pourrait effectuer avant une découverte, in silico. Une partie des travaux réalisés fait l’objet d’un article publié, décrivant les relations invisibles entre les gènes et le prolongement de la durée de vie de nématodes. En 2005, la division SPAWAR de l’US Navy s’implique dans le projet, ce qui permet d’allouer davantage de ressources à la recherche pour travailler dans des domaines tels que les marchés financiers.
Optimisation des ensembles de données
Au fil du temps, Vectorspace apprend à optimiser les ensembles de données en enrichissant ou en liant des vecteurs de caractéristiques représentés par des plongements lexicaux. Cela entraîne la génération de nouvelles visualisations, interprétations, hypothèses ou découvertes. En utilisant ces types de vecteurs de caractéristiques pour enrichir les ensembles de données temporelles pour les marchés financiers, il devient possible de produire des signaux uniques ou de générer des alphas. Tout ce qu’il faut pour démarrer, ce sont des sources de données optimisées pour un contexte ou un thème donné, comme illustré ci-dessous :
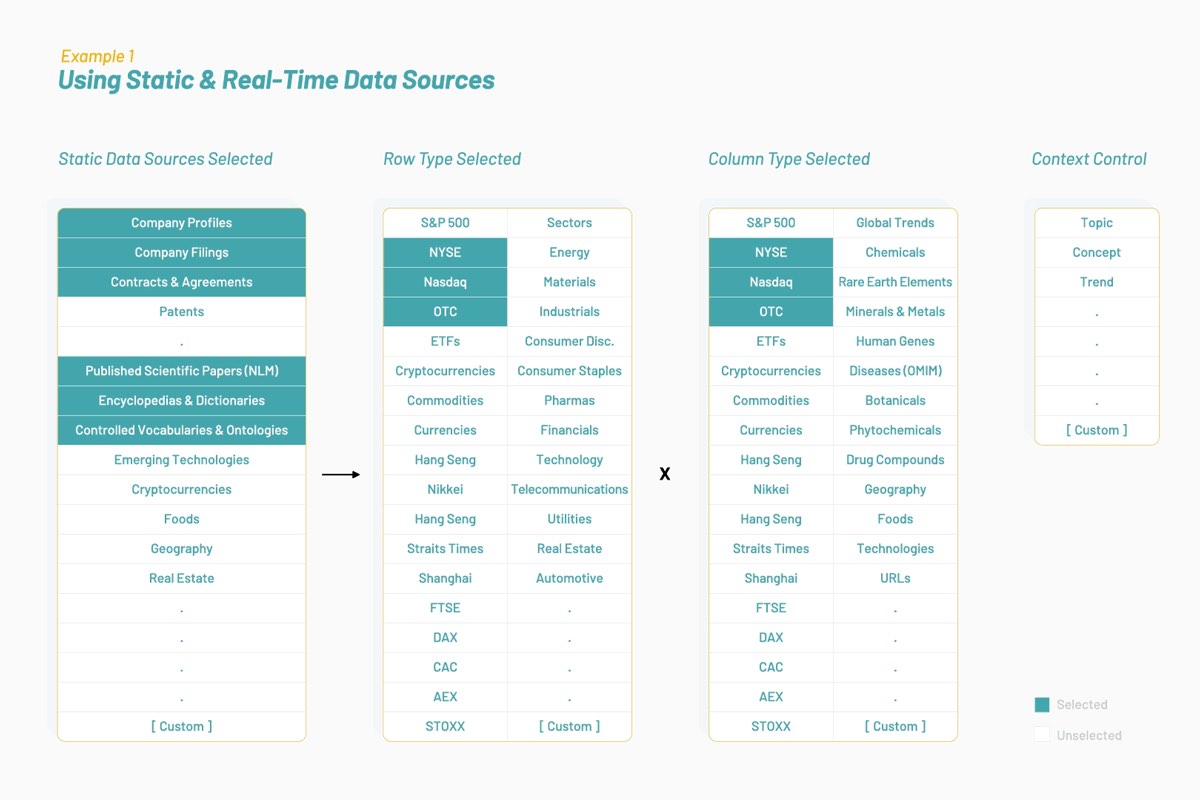
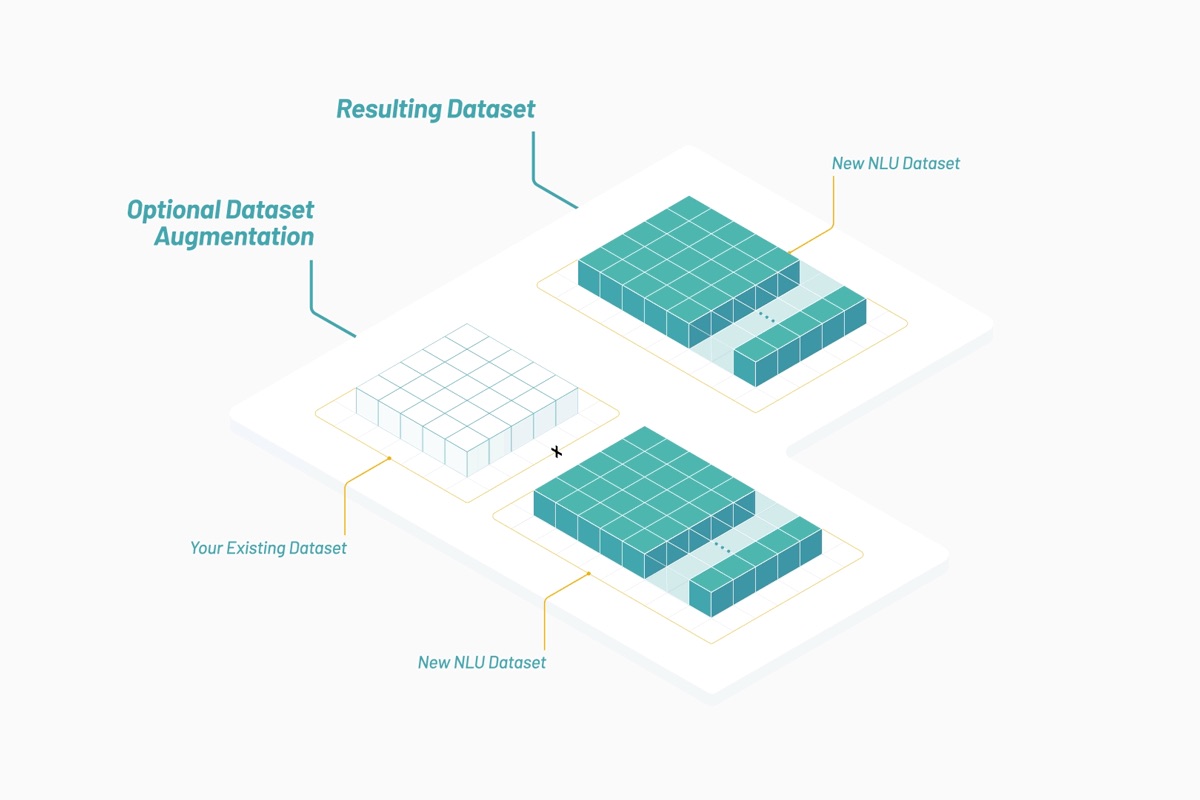
Les ensembles de données générés sont composés de vecteurs de caractéristiques représentés par des plongements lexicaux qui se basent sur des articles biomédicaux et sur le langage humain autour des entreprises cotées au NYSE et au Nasdaq. Dans le cadre d’une approche interdisciplinaire de la recherche, on pourrait chercher à déterminer si les gènes et les actions partagent des attributs et des comportements communs dans leur façon d’interagir.
Définition d’un objectif en deux parties
Partie un : déterminer où appliquer aux actions les connaissances tirées de l’observation des interactions entre les gènes, les protéines, les médicaments et les maladies.
Partie deux : chercher un moyen de financer la recherche concernant la sécurisation des voyages spatiaux à long terme pour les humains en utilisant des ensembles de données enrichis pour générer des alphas dans les marchés financiers.
Déclenchements d’événements en hausse
Les interactions observées au niveau des gènes sont-elles similaires à celles observées au niveau des actions ? Le 20 septembre 2004 s’est produit un événement qui a répondu à cette question de façon partielle. Merck (MRK) a vu chuter son action de 21 % (probablement) car on suspectait que Vioxx, un médicament qu’elle commercialisait, provoquait des attaques cardiaques. Cet événement a créé un mouvement similaire latent, par effet boule de neige, sur le prix des actions d’autres entreprises pharmaceutiques, comme Pfizer (PFE). Grâce à un ensemble de données enrichi, Vectorspace a pu prédire qu’il y aurait une réaction à retardement de ce type sur le prix de l’action PFE, à cause de son lien avec le médicament Vioxx fabriqué par Merck. Nous allons à présent voir comment.
Intéressons-nous tout d’abord à un article publié dans The Journal of Finance, intitulé "Contagious Speculation and a Cure for Cancer: A Non-Event that Made Stock Prices Soar" (Une spéculation contagieuse et un remède contre le cancer : un événement qui n’en est pas un fait s’envoler le prix des actions). Cet article décrit un événement relatif à une entreprise nommée EntreMed (dont le code était ENMD à l’époque) :
"Un article paru dans l’édition du dimanche du New York Times sur le développement potentiel d’un nouveau remède contre le cancer a provoqué la hausse du prix de l’action d’EntreMed, qui est passé de 12,063 $ le vendredi à la fermeture, à 85 $ le lundi à l’ouverture pour terminer à environ 52 $ à la fermeture. Au cours des trois semaines suivantes, l’action était aux alentours de 30 $ à la fermeture. Cet enthousiasme débordant a eu une conséquence bénéfique sur les actions d’autres entreprises de biotechnologies. Pourtant, cette avancée potentielle dans la recherche contre le cancer avait déjà été signalée dans le journal Nature et d’autres journaux populaires, dont le Times!, plus de cinq mois auparavant. C’est donc l’attention d’un public enthousiaste qui a suscité une hausse permanente dans le prix des actions, même si aucune information véritablement nouvelle n’a été communiquée." Parmi les nombreuses observations pertinentes émises par les chercheurs, l’une ressortait particulièrement dans la conclusion : "Les mouvements [des prix] peuvent être concentrés au niveau des actions partageant certaines caractéristiques, mais ces caractéristiques ne sont pas forcément économiques". — (Huberman and Regev 387)
Vectorspace s’est alors entourée d’équipes ayant de l’expérience en développement d’algorithmes quantitatifs, en banque d’investissement et en gestion de sociétés cotées en bourse pour rechercher des similarités entre les gènes et les actions. Tout comme les gènes, les actions ont des "valeurs d’expression", des attributs, des relations invisibles les unes avec les autres et avec des événements extérieurs, des thèmes ou des tendances mondiales. Ces relations sont une forme de connaissance qui tend à être intégrée dans le langage humain plus que tout autre chose. Tout comme les gènes, des clusters d’actions peuvent interagir et évoluer en fonction les uns des autres. Ces données peuvent être utiles pour prédire les corrélations à venir entre des capitaux propres en raison d’un "enchevêtrement latent". Des clusters d’actions peuvent être regroupés en "paniers" partageant des relations connues et invisibles les uns avec les autres, et avec des événements extérieurs. Les clusters, ou paniers, peuvent être déterminés en fonction du contexte.
La marée montante ne fait pas avancer tous les bateaux
Vectorspace a entrepris d’analyser l’origine de ces corrélations observées étant donné qu’elle avait identifié une opportunité de créer un moyen de financement basé sur l’exploitation d’une inefficacité des marchés financiers s’appuyant sur des "poches d’informations explorables". Elle a commencé à observer des réactions à retardement au niveau des actions. Un peu comme un port ou une baie qui s’emplit d’eau et fait avancer les bateaux plusieurs minutes ou heures après le début de la marée montante. La montée des eaux dans un port peut être déclenchée par un événement qui fait ensuite avancer les bateaux dans le port. Dans notre cas, les bateaux s’apparentent à des clusters de ressources commercialisables comme les actions. Sur les marchés financiers, certains bateaux avancent. D’autres, non. Le fait de pouvoir déterminer par anticipation les ressources qui sont reliées à tel ou tel événement, ainsi que la force et le contexte de ces corrélations, peut donner de précieuses indications. Cela revient à disposer d’informations asymétriques qui peuvent servir à prendre une longueur d’avance sur un marché ou à réduire les risques à court ou long terme lors du déploiement de capitaux. On peut également parler de "génération d’alphas", qui sont visualisables et interprétables.
Pour mettre à l’épreuve cette hypothèse probabiliste sur l’avancée des bateaux, quelque 20 années de données ont été analysées. Le but : rechercher des mouvements similaires ou un enchevêtrement latent au niveau du prix des actions de sociétés cotées en bourse en fonction d’événements du marché. De nombreux exemples ont été découverts, parmi lesquels les trois événements suivants : EntreMed (ENMD) 1998, Merck (MRK) 2004 et Celgene (CELG) 2019.
Événement 1 : EntreMed (ENMD) voit le prix de son action augmenter de 608 % (4 mai 1998)
Un vendredi, après la fermeture de la Bourse, EntreMed annonce qu’elle a mis au point un remède contre un certain type de cancer. Le prix de son action était de 12 $ le vendredi à la fermeture et est monté à 85 $ le lundi à l’ouverture. De manière similaire, un panier d’actions a vu son prix commencer à monter. Ce panier avait des corrélations avec ENMD basées sur le langage humain autour de la science des protéines en lien avec les traitements contre le cancer.
L’article décrivant cet événement contenait quelques extraits pertinents :
Page 392, par. 4 "Trois entreprises similaires ont constaté une augmentation de plus de 100 % du prix de leurs actions, deux autres, entre 50 % et 100 %, et encore deux autres, entre 25 % et 50 %. En comparant ces retours constatés, dont la répartition exceptionnelle est indiquée au tableau I, on peut voir à quel point il est inhabituel d’observer de telles retombées sur les actions de ces sept entreprises de biotechnologies, et surtout, à quel point elles se ressemblent, un fait totalement inédit."
Page 395, par. 1 "Qu’une nouvelle sur l’avancée majeure dans la recherche contre le cancer ait un effet sur l’action d’une entreprise disposant de droits de commercialisation sur le produit créé n’a rien de surprenant ; le marché peut supposer qu’il y aura un effet bout de neige et partir du principe que d’autres entreprises bénéficieront de cette innovation."
Page 396 par. 3 "Les mouvements peuvent être concentrés au niveau des actions partageant certaines caractéristiques, mais ces caractéristiques ne sont pas forcément économiques."
Événement 2 : Merck (MRK) voit son action chuter de 25,8 % (30 septembre 2004)
Merck a retiré du marché le médicament Vioxx, pesant 2,5 milliards de dollars, car il provoquait des attaques cardiaques et des AVC à cause des inhibiteurs sélectifs de la COX-2. Cette corrélation a eu des répercussions. MRK, dont l’action était cotée à 45,07 $ à la fermeture, a enregistré une baisse avec un prix à 33,40 $ à l’ouverture le lendemain, le 30 septembre. Lors d’une expérience menée avec des plongements lexicaux utilisés comme vecteurs de caractéristiques, il a été déterminé que Pfizer (PFE) était l’entreprise la plus proche de Merck car toutes deux travaillaient sur un médicament similaire basé sur un inhibiteur sélectif de la COX-2. Quelques semaines après cet événement, PFE enregistrait à son tour une baisse.
"Le 17 décembre 2004, Pfizer et l’Institut national du cancer des États-Unis annonçaient qu’ils avaient cessé d’administrer du Celebrex (célécoxib), un inhibiteur sélectif de la cyclooxygénase-2 (COX-2), lors d’une étude clinique en cours portant sur l’utilisation de ce médicament pour prévenir les polypes du colon, en raison de l’augmentation du risque d’accidents cardiovasculaires. Le rofécoxib de Merck (Vioxx), un autre inhibiteur sélectif de la COX-2, a été retiré du marché mondial en septembre 2004 en raison de l’augmentation du risque d’infarctus du myocarde et d’AVC." - CMAJ.
Ce jour-là, l’action PFE a perdu 24 %, passant d’une valeur de 28,98 $ à la fermeture la veille à une valeur de 21,99 $.
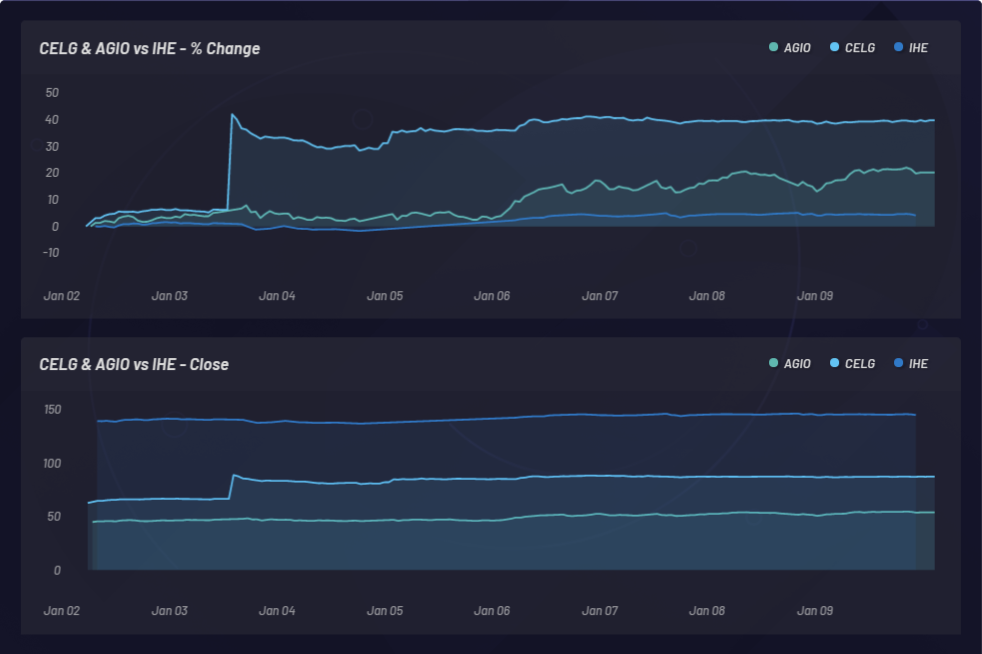
Événement 3 : Celgene (CELG) enregistre une augmentation de 31,8 % (3 janvier 2019)
Le 3 janvier 2019, Bristol-Myers Squibb (BMY) a acquis Celgene (CELG) pour 74 milliards de dollars. L’action CELG est passée du jour au lendemain de 66,64 $ à 87,86 $, soit une augmentation de 31,8 %. Sur une période de quatre jours, un panier d’actions liées à CELG a constaté une augmentation de 20 %, basée sur les relations identifiées dans le langage humain autour de ces entreprises. Parmi les sources de données établissant des connexions entre ces entités, on trouve les référentiels des profils des sociétés cotées en bourse et des articles scientifiques publiés, revus par des pairs.
En analysant ce processus, Vectorspace a remarqué que certaines corrélations NLU pouvaient entraîner des corrélations latentes basées sur le prix entre les capitaux propres, et entre les capitaux propres et les événements. L’équipe a observé de nombreux exemples similaires à ceux indiqués ci-dessus. Il est possible de les exploiter pour prendre une longueur d’avance sur le marché ou pour procéder à un certain arbitrage des informations.
Visualisation des alphas
Aujourd’hui, chez Vectorspace AI, les ensembles de données ont un objectif : celui de détecter les réseaux de relations invisibles existant entre les gènes, les protéines, les microbes, les médicaments et les interactions entre les maladies dans le domaine des sciences de la vie, ou entre les capitaux propres sur les marchés financiers. La plupart du temps, nos clients utilisent ces ensembles de données pour enrichir leurs propres ensembles de données. Les ensembles de données sont générés en combinant des vecteurs de caractéristiques composés d’attributs auxquels est affecté un score, en fonction de la vectorisation des mots et des objets. Ces ensembles sont mis à jour en temps quasi-réel et accessibles par l’intermédiaire d’une API à l’aide de crédits d’utility token.
Avec la Suite Elastic et Canvas, Vectorspace peut fournir aux clients des visualisations et des interprétations de données en temps quasi-réel, dans des vues en marque blanche entièrement configurables. Il s’agit là d’un aspect important du processus, car de nouvelles interprétations et de nouvelles informations exploitables peuvent donner lieu à de nouvelles hypothèses, de nouveaux signaux ou de nouvelles découvertes.
Il n’est pas rare que les entreprises de gestion de ressources demandent à disposer de solutions sur site de pipeline d’ingénierie des données pour des raisons de confidentialité. En combinant notre pipeline d’ingénierie des données avec Elastic Cloud Enterprise, nous proposons une solution clé en main permettant de générer des signaux.
Les clients financiers de Vectorspace ont plusieurs objectifs : optimiser les rapports signal-bruit, générer des alphas, limiter une fonction de perte ou augmenter les ratios de Sharpe ou de Sortino. Pour y parvenir, ils s’appuient sur la visualisation et l’interprétation des résultats de leurs stratégies de backtesting, lesquelles se basent sur l’enrichissement des ensembles de données en temps quasi-réel, tout en limitant le surapprentissage.
La fréquence de mise à jour des ensembles de données peut aller d’une minute à un mois, selon la versatilité des sources de données impliquées. L’un des packages d’ensembles de données les plus demandés est constitué d’un ensemble de données sur des tarifs au fil du temps, contenant des lignes indiquant les entreprises pharmaceutiques cotées en bourse, enrichi avec des vecteurs de caractéristiques correspondant à des formulations médicamenteuses ayant un score de corrélation basé sur la NLU. Le choix du contexte dans lequel opérer peut s’avérer crucial. Tout comme une définition varie selon le contexte, un score de corrélation peut changer au fil du temps selon les contraintes contextuelles appliquées. Le contexte peut également avoir un impact sur la force d’une relation entre les entités, et entre les entités et les événements.
Visualisation avec Canvas
Pour approfondir le sujet, nous allons utiliser l’un de ces ensembles de données pour générer et visualiser le panier d’actions liées à Celgene (CELG), ainsi que l’événement ayant entraîné une hausse à retardement du prix de certaines de ces actions. Nous verrons les étapes qu’exécute généralement un client de Vectorspace à l’aide de ces ensembles de données, tout en interprétant les résultats en temps quasi-réel et les résultats d’un backtest dans Canvas. Tout d’abord, regardons les résultats nets d’un groupe intégral de paniers pour confirmer que le panier Celgene n’a pas été sélectionné délibérément.
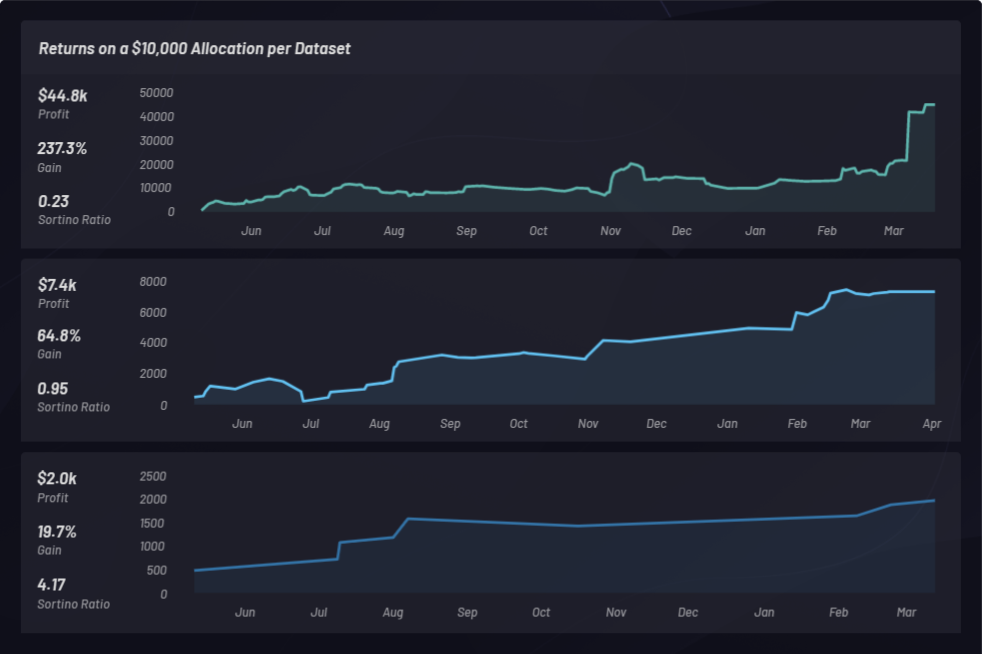
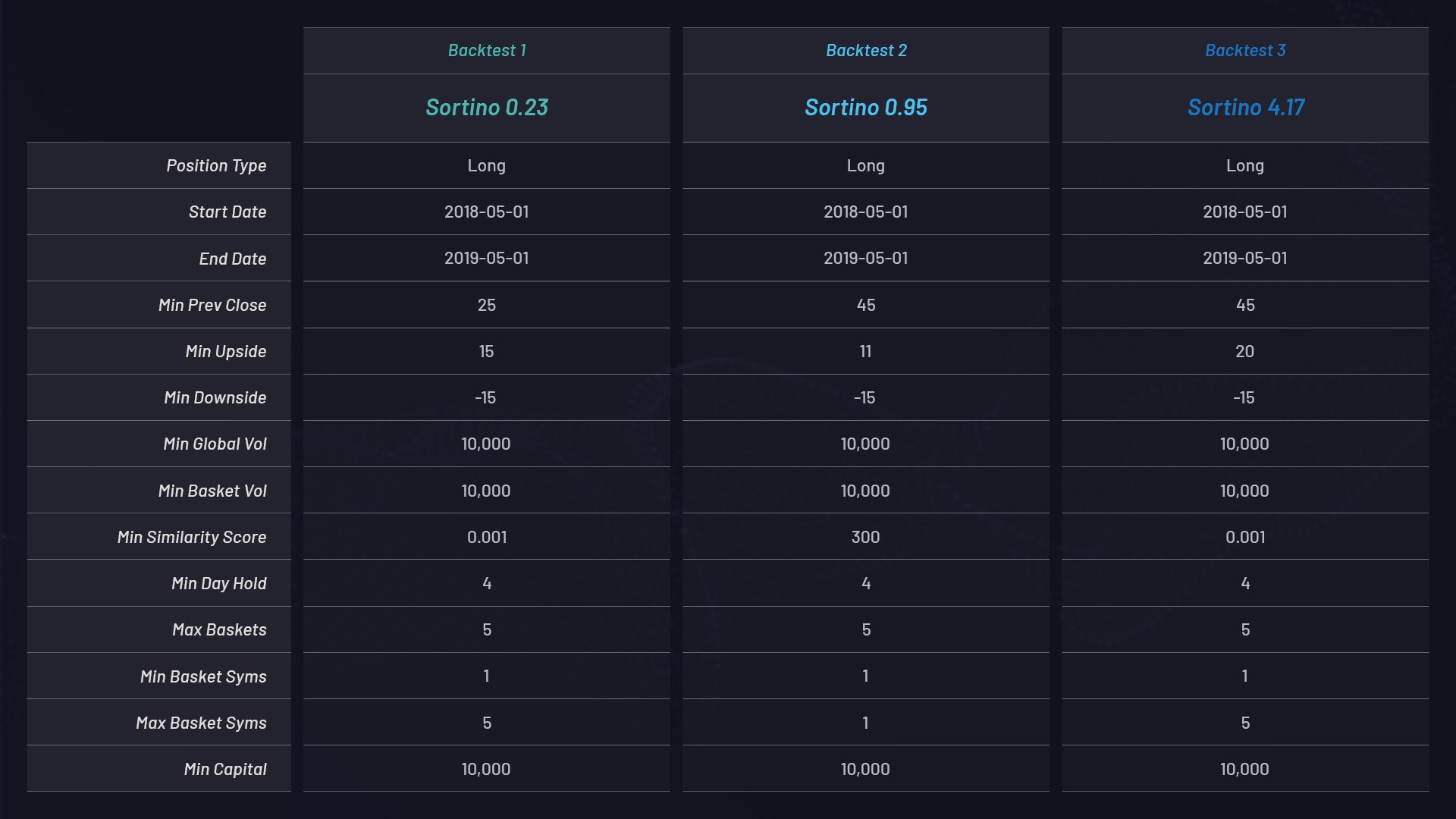
Nous avons ci-dessous trois backtests distincts, exploitant des paniers à position longue uniquement, avec des paramètres différents. Chaque panier dispose d’un capital de 10 000 $ et est classé en fonction de son ratio de Sortino :
Les paramètres de chaque panier sont les suivants :
Ci-dessous, les résultats des backtests sont chargés dans Kibana et les statistiques sont affichées :
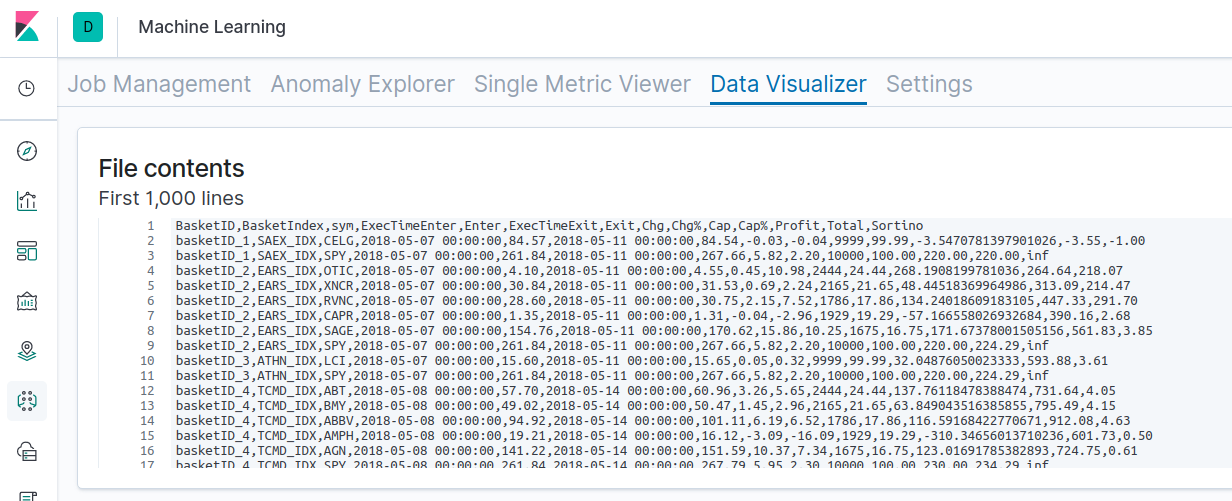
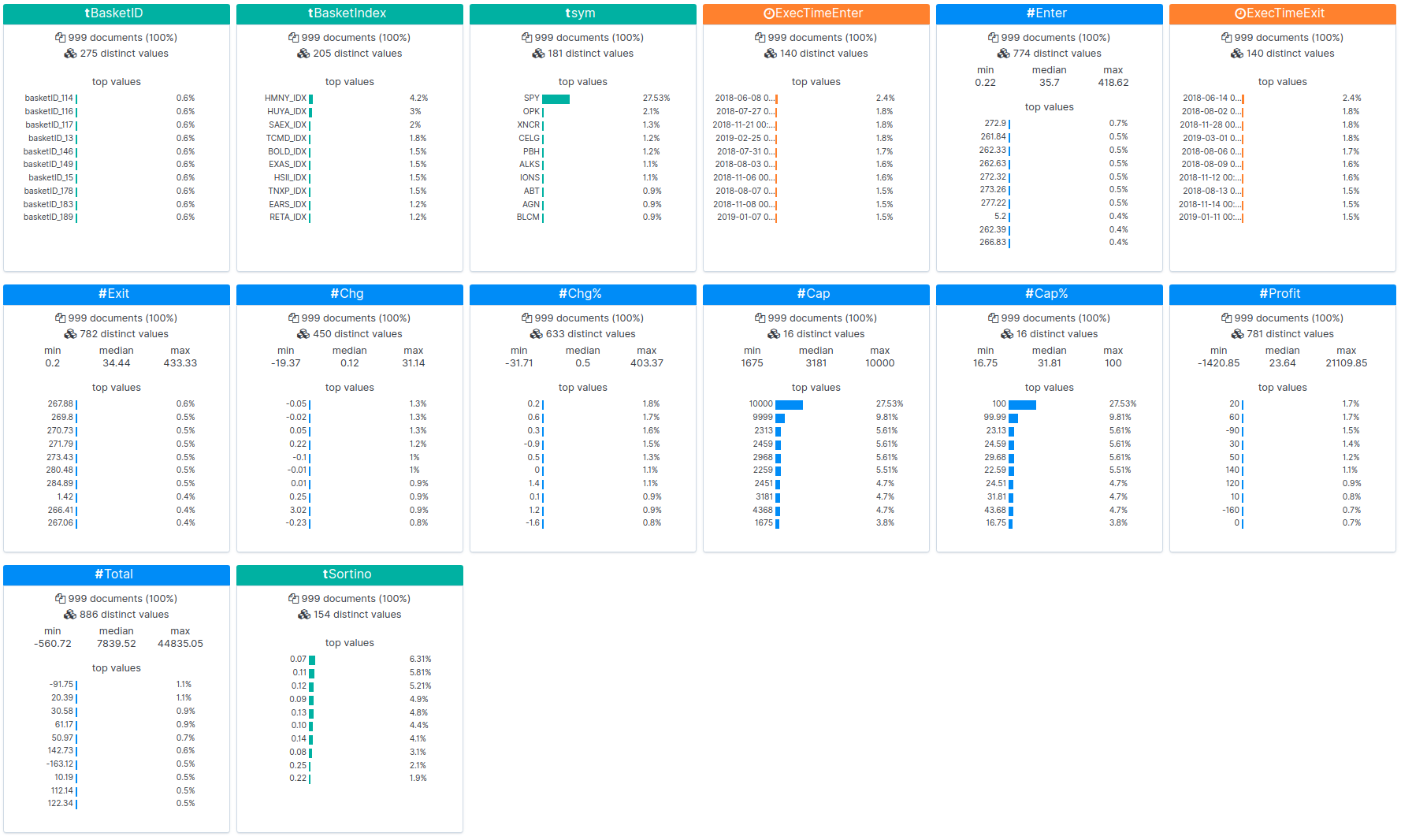
Vous pouvez visualiser les résultats bruts de l’un des backtests ici. Pour effectuer le backtest d’ensembles de données enrichis par NLU, procédez comme indiqué ci-dessous. C’est cette procédure que nous avons appliquée pour générer les résultats affichés ci-dessus.
- Des plongements lexicaux utilisés comme vecteurs de caractéristiques sont générés pour l’ensemble des actions NYSE et Nasdaq à l’aide d’une API d’ensemble de données.
- Pour analyser l’origine d’événements spéciaux tels que les pics dans le prix d’une action, étudions les données collectées au cours d’une période antérieure d’un an, allant du 1er mai 2018 au 1er mai 2019, pour l’ensemble des actions NYSE et Nasdaq.
- Pour toutes les actions enregistrant un pic supérieur à un certain pourcentage, p. ex. 15 %, un cluster ou panier d’actions associées est généré à l’aide de l’ensemble de données. Observez le paramètre MIN_UPSIDE dans le tableau ci-dessus.
- Pour affiner le panier, nous utilisons des paramètres de filtrage, comme le volume, la capitalisation boursière (marketcap), le flottant, etc.
- L’entrée et la sortie sont déterminées en fonction d’une période de conservation en portefeuille de quatre jours.
- Les retours sont calculés pour les paniers à position longue et à position courte par rapport au S&P 500, qui permet de faire des comparaisons, en plus des ratios de Sortino.
- Les ensembles de données et les retours sont monitorés, visualisés et interprétés à l’aide de Canvas.
Retours des backtests
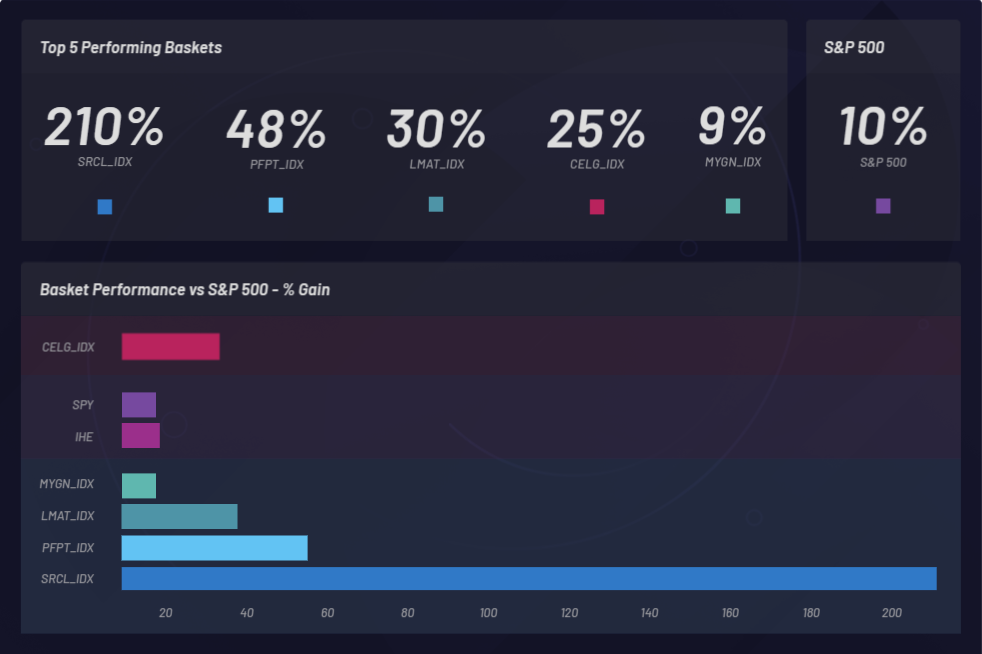
Observons à présent les résultats globaux obtenus pour les trois backtests effectués par Canvas sur une période d’un an, allant du 1er mai 2018 au 1er mai 2019, d’après les performances générées par l’ensemble des paniers sur cette période.
Les backtests ont permis d’identifier les entreprises cotées dont le prix d’action a augmenté après l’acquisition de Celgene. Il est possible d’observer des corrélations dans l’ensemble de données enrichi qui a été chargé. Les paniers (clusters) générés à partir de l’ensemble de données peuvent être aussi étudiés par rapport à leurs performances. Les performances d’un panier peuvent être comparées aux performances de référence du S&P 500 pour vérifier qu’il se démarque de la concurrence. Les paniers individuels sont monitorés pour déterminer s’ils surpassent le S&P 500 (SPY) en termes de performances :
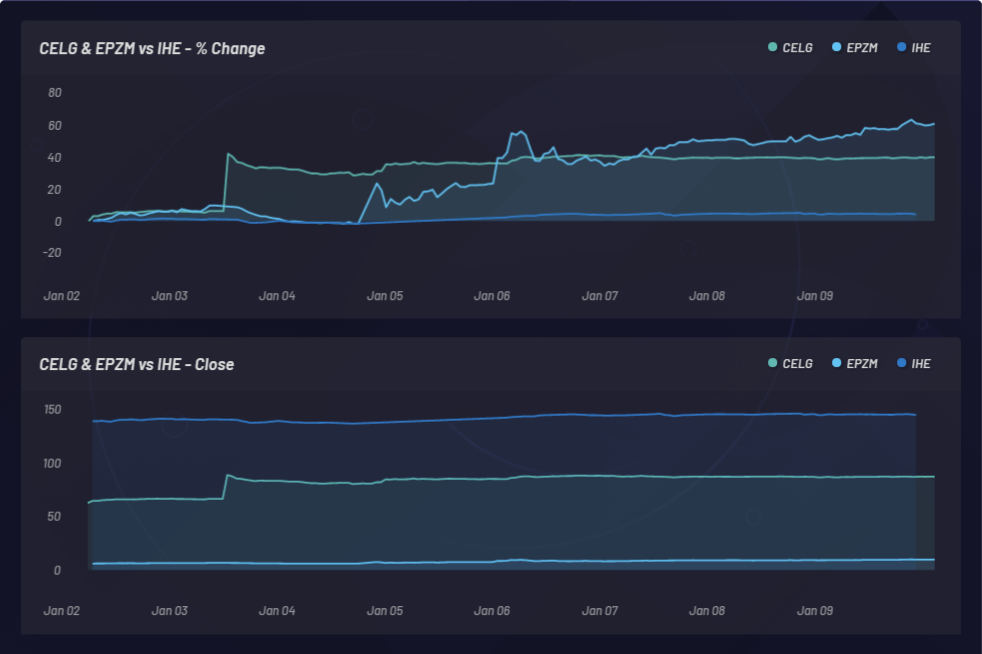
Le graphique ci-dessous illustre le monitoring d’un événement et les mouvements similaires latents qui en résultent sur d’autres actions. Dans le cas présent, CELG (Celgene) constitue l’événement et EPZM (Epizyme) est sélectionné en tant que composant du panier qui en résulte. Les corrélations basées sur la NLU peuvent prédire les corrélations basées sur les prix. Le fait de pouvoir capturer la mise à jour des corrélations basées sur la NLU entre les capitaux et les événements peut donner un avantage en ce qui concerne l’arbitrage des informations asymétriques. Il est possible de prendre une longueur d’avance sur le marché uniquement s’il y a une réaction à retardement au niveau de l’action ou de la corrélation des prix par rapport à toute corrélation basée sur la NLU entre CELG et EPZM, comme on peut le voir ici :
CELG (Celgene) par rapport à AGIO (Agios Pharmaceuticals) :
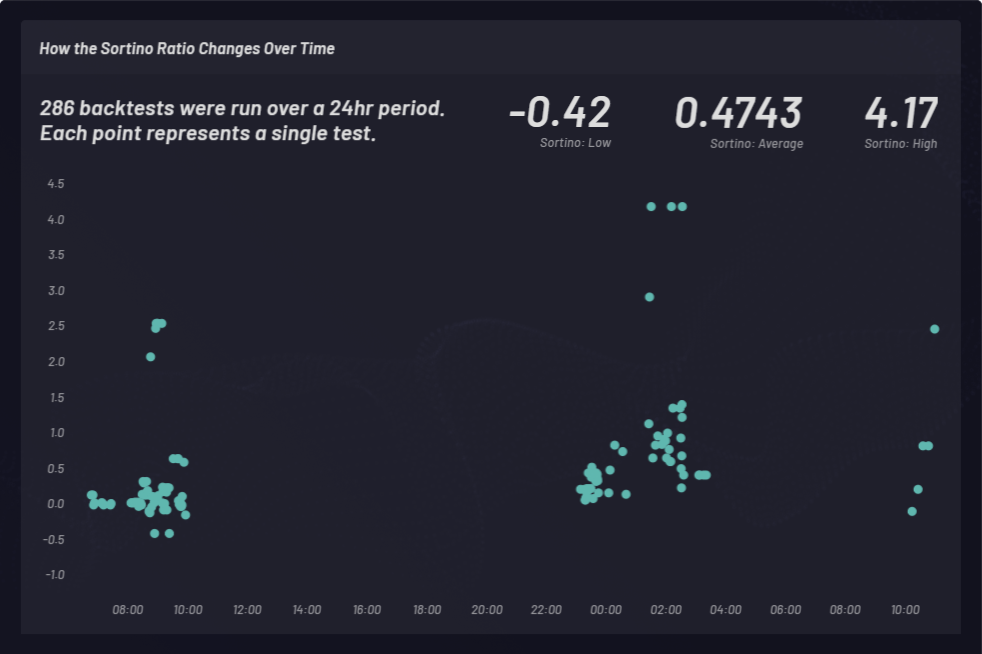
Un ratio de Sortino est calculé pour mesurer les retours en fonction des risques. Dans l’exemple suivant, un ratio de Sortino a été choisi à la place d’un ratio de Sharpe pour factoriser un peu mieux l’instabilité en hausse. Le ratio de Sortino évolue au fil du temps. Les backtests ont été effectués sur des paniers à position longue à trois moments différents sur une période de 24 heures, comme on peut le voir ci-dessous. Au total, 286 backtests ont été exécutés, avec des paramètres généraux variables. Chaque point dans le cluster ci-dessous représente un seul et même backtest, avec le ratio de Sortino correspondant sur l’axe y :
Exploitation des corrélations changeantes
La National Library of Medicine publie chaque jour près de 1 500 articles revus par des pairs. Elle fait partie des sources de données sur lesquelles Vectorspace s’appuie.

Les corrélations entre les gènes, la formulation d’un médicament, les actualités pharmaceutiques et les entreprises cotées en bourse évoluent au fil de temps, parfois en l’espace de quelques secondes. Cela peut avoir une incidence sur les rapports signal-bruit lorsque l’on découvre un composé pouvant potentiellement entraîner la requalification ou le repositionnement d’un médicament.
Si un changement se produit dans les valeurs de corrélation entre une entreprise pharmaceutique cotée en bourse et un gène, une protéine, une formulation de médicament, un microbe ou une maladie, la nouvelle relation sera répercutée dans l’ensemble de données et pourra être monitorée en temps quasi-réel dans Canvas.

Lors de la création d’ensembles de données basés sur la NLU, l’application de contexte peut donner à lieu à de nouveaux types de scores de corrélation. L’application de contexte aux relations NLU peut jouer un rôle essentiel dans la découverte de nouvelles informations exploitables.
Lorsque les ensembles de données basés sur la NLU sont mis en contexte, ils peuvent aider les chercheurs à répondre aux questions qu’ils se posent, tout en leur offrant le moyen de visualiser et d’interpréter les réponses et résultats dans Canvas. Exemple de question : "Quelles sont les actions pharmaceutiques reliées à telle ou telle formulation médicamenteuse dans le contexte des gènes de réparation de l’ADN endommagé d’après les dernières recherches ?".
Étant donné que près de 1 500 articles scientifiques revus par des pairs sont publiés chaque jour, en plus des actualités et autres documents publics, les scores de corrélation changent, ce qui entraîne la mise à jour des relations, par exemple, entre les entreprises pharmaceutiques cotées en bourse et la formulation de médicaments. Lorsque des ensembles de données basés sur la NLU sont associés à des sources de données internes, ils permettent de fournir des signaux uniques.
Conclusion
Les corrélations basées sur le traitement du langage naturel (NLP) et la NLU favorisent la découverte de nouvelles informations exploitables ou hypothèses.
Mais ce n’est pas tout ! On peut aller bien plus loin avec ces ensembles de données basés sur la NLU, que ce soit dans le domaine des sciences de la vie ou sur les marchés financiers, grâce aux corrélations contextualisées, aux sources de données alternatives, aux vecteurs de caractéristiques, à la visualisation et à l’interprétation. Peut-être qu’à l’avenir, nos équipes aborderont certains de ces sujets, notamment l’enrichissement des ensembles de données temporelles, pour différentes ressources commercialisables. Grâce aux vecteurs de caractéristiques NLU individuels, nos équipes peuvent expliquer comment concevoir des réseaux de relations basés sur des graphes ou des réseaux entiers de clusters rendus avec Canvas et d’autres outils dans la Suite Elastic. En outre, nos équipes peuvent décrire différentes façons d’aider les machines à échanger des vecteurs de caractéristiques pour limiter les fonctions de perte sélectionnées en combinant une API d’utility token avec un carnet de commandes en open market.
Vectorspace continue à construire des applications associées pour les ensembles de données intervenant dans le domaine de la réparation des chromosomes endommagés en lien avec les rayonnements spatiaux, l’épigénétique et la durée de vie dans le cadre des voyages spatiaux des humains. Et pour encore plus de créativité et d’utilité, la Suite Elastic est là, avec Canvas et d’autres outils. Si vous souhaitez en savoir plus sur l’enrichissement des ensembles de données ou sur l’obtention de crédits gratuits pour l’API d’utility token, contactez Vectorspace. Nous serons heureux de vous fournir les données dont vous avez besoin pour bien démarrer.
Et si vous souhaitez tester la Suite Elastic, bénéficiez d’une version d’essai gratuite de 14 jours pour Elasticsearch Service ou téléchargez la solution dans le cadre de sa distribution par défaut.
Vectorspace invente des systèmes et des ensembles de données qui imitent les facultés humaines en matière d’arbitrage des informations et de découverte scientifique (IA/NLP/ML de haut niveau) pour Genentech, Lawrence Berkeley National Laboratory, le Ministère américain de l’Énergie (DOE), le Ministère américain de la Défense (DOD), la division des biosciences spatiales de la NASA, le DARPA et la SPAWAR (division de l’US Navy) entre autres.
Shaun McGough est chef de produit chez Elastic. Il dispose d’une expertise dans le domaine de la visualisation des données et des investissements alternatifs.