l'Institut national de l'audiovisuel utilise Elasticsearch comme moteur de recherche pour ses archives Twitter
Depuis sa création en 1974, Institut national de l’audiovisuel (Ina) a pour mission de recueillir, sauvegarder et mettre à disposition les fonds audiovisuel français. En 1992, suite à ses obligations, l'Ina s'est vu confié la responsabilité du Dépôt Légal de la radio et de la télévision.
En 2006, le Dépôt Légal a été étendu aux contenus web français, responsabilité partagée par la Bibliothèque nationale de France et l'Ina. Depuis, l'équipe du dlweb de l'Ina est chargée d'archiver tous les sites web français liés aux diffuseurs radio et télévision, et également de fournir une interface pour permettre à ses utilisateurs de visualiser et d’analyser ces archives. Dans le cadre de ces efforts, depuis 2004, l'équipe collecte et archive aussi des tweets en suivant 12 000 utilisateurs et 600 hashtag grâce aux API de Twitter.
Pour indexer les archives des pages web, à savoir 4,5 milliards de pages web, l'équipe dlweb a migré son moteur de recherche vers Elasticsearch. Durant ce projet, Elasticsearch s'est illustré par sa puissance et sa flexibilité dans l’indexation et la recherche, c'est pourquoi nous avons décidé de l'utiliser pour indexer nos archives Twitter, représentant 400 millions de tweets, avec une moyenne de 300 000 nouveaux tweets par jour. Notre index Twitter utilise notre déploiement d'Elasticsearch principal, c'est-à-dire 32 shards répartis sur 4 serveurs - 32 nœuds. Chaque serveur est doté de 4 SSD de 1 To et de 96 Go de RAM. Après une série d'essais, nous avons trouvé un « sweet spot » de performance : 2 nœuds elasticsearch par SSD. Nous avons donc finalement opté pour 8 nœuds elasticsearch de 6 Go de mémoire heap par serveur afin d'optimiser le fonctionnement entre entrée/sortie et les processeurs. Nous passerons bientôt à 12 serveurs et 96 nœuds.
Fournir une interface de recherche efficace avec de multiples filtres (ex. dates, hashtag, mentions, etc.) est très important lorsqu'on traite des données archivées. Notre interface de recherche combine requêtes de recherche et filtres d'Elasticsearch, comme présenté ci-dessous.
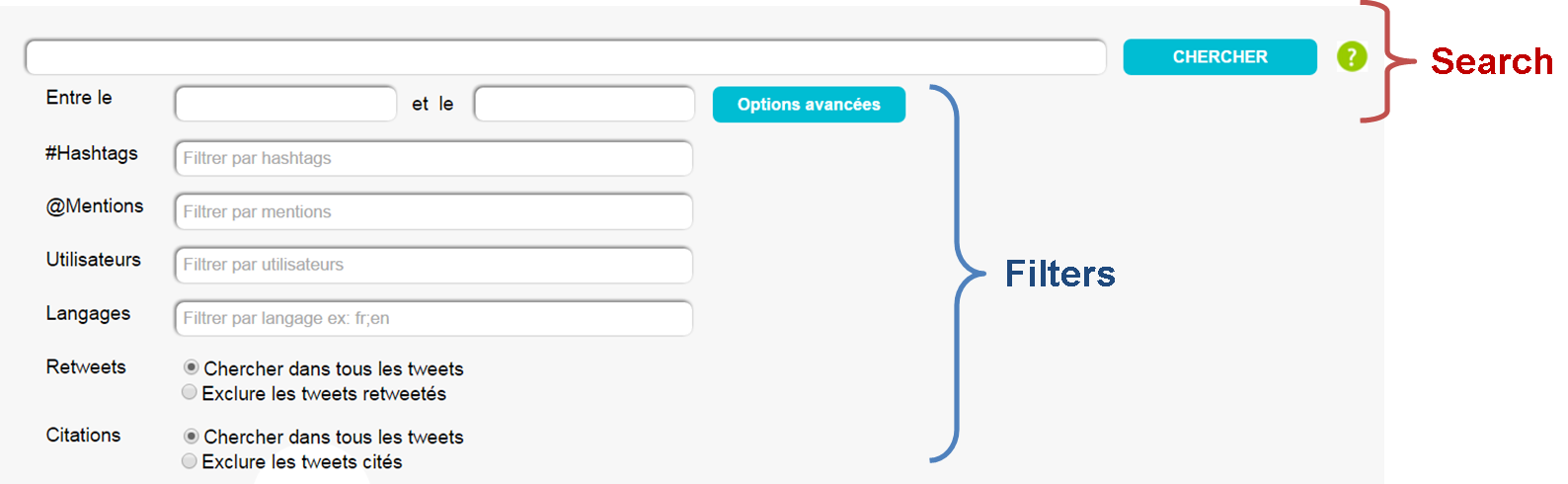
Figure 1 - Interface de recherche des archives Twitter
Analyser les données de Twitter nécessite non seulement des recherches textuelles mais également une agrégation des données à différents niveaux. Pour satisfaire des besoins variés en termes de recherche, nous devons offrir des solutions génériques. Grâce à Elasticsearch, nous pouvons à la fois rechercher et filtrer des données ainsi qu'exécuter des analyses, et ce simultanément à l'aide d'une seule recherche. Kibana nous a aidé à élaborer des tableaux de bord et à déterminer le type d'agrégation que nous proposons à nos utilisateurs. Grâce aux agrégations et aux sous-agrégations, nous sommes en mesure de fournir différentes analyses (ex. timeline, hashtags les plus populaires, tweets les plus repris, etc.) pour une requête donnée, avec une performance élevée comme indiqué ci-dessous.

Figure 2 - Délai d'exécution d'une requête
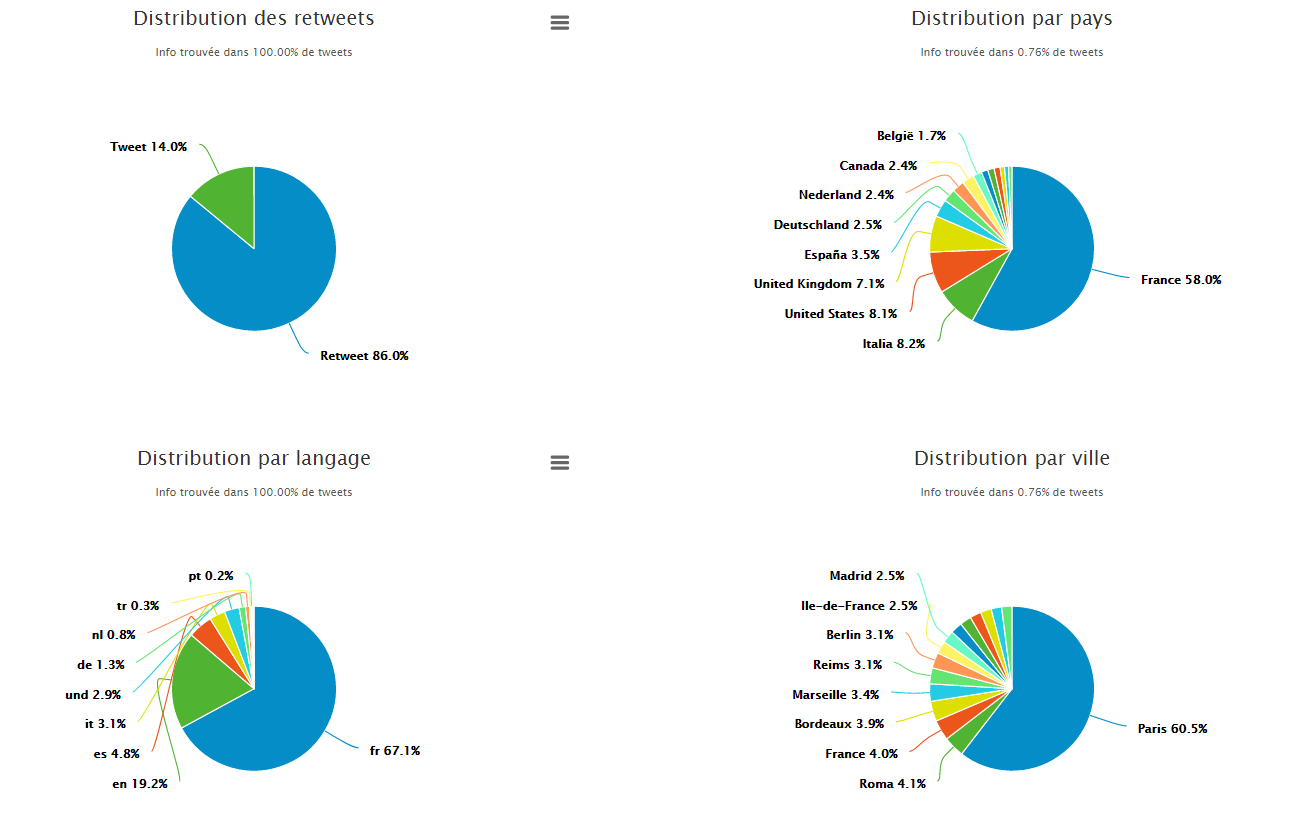
Figure 3 - Tableaux de bord des agrégations et sous-agréagations
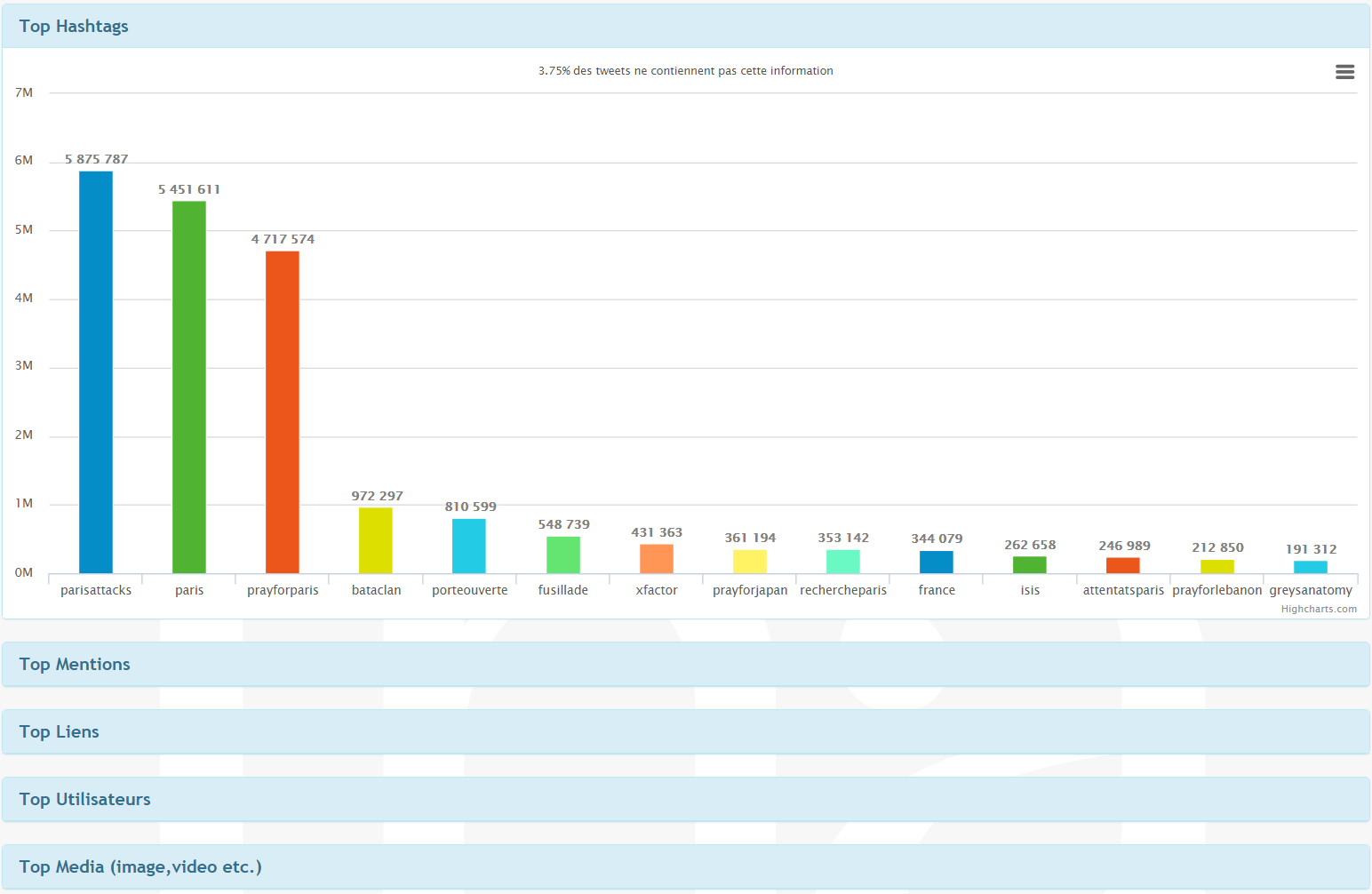
Figure 4 - Principales entités pour une requête donnée
Le Dépôt Légal des archives web de l'Ina sont consultables uniquement à des fins d'étude et de recherche à l'Inatheque.
L'équipe dlweb participe à plusieurs projets de recherche nationaux et internationaux sur les données Twitter, comme ASAP : https://asap.hypotheses.org/ et REAT: https://reat.hypotheses.org/ où l'interface présentée ci-dessus est utilisée par plusieurs chercheurs.