elasticsearch.douane.gouv.fr - testé et approuvé

Le contexte
La Douane n'est pas un mythe : cette administration composée de moins de 17 000 fonctionnaires oeuvre au quotidien, au maintien et à la défense des intérêts sociaux, culturels, économiques de la France. Sa devise : « Agir pour protéger ».
L'action de la Douane se concentre sur la régulation des flux de marchandises. Cette action s'étend et se diversifie avec de nombreuses autres missions : mission fiscale, lutte contre la fraude et les grands trafics internationaux, protection de la santé et de la sécurité des citoyens, soutien à la compétitivité des entreprises, etc.
La problématique
L'informatique est devenue indispensable pour exercer ces missions. Les différentes applications développées doivent traiter les flux de données reçues en temps réel. Le traitement met en œuvre des modules de validation, de profilage, d'analyse de risques et de taxation. A ce traitement s'ajoutent les contraintes de stockage réglementaire des informations déclarées, pouvant nécessiter un délai de garde de 10 ans. Enfin, ces données stockées doivent pouvoir être recherchées, visualisées à tout moment au sein du système d’information opérationnel.
Le cas d’utilisation
Comment stocker, rechercher et visualiser en temps réel, des données variées sur de gros volumes ?
1. Variété des données
Les données traitées dans les applications douanières sont complexes d'un point de vue structurel : une seule déclaration (d'un flux de marchandises) peut se représenter par une structure comprenant plusieurs niveaux et sous-niveaux imbriqués, contenant chacun des collections multi-valuées :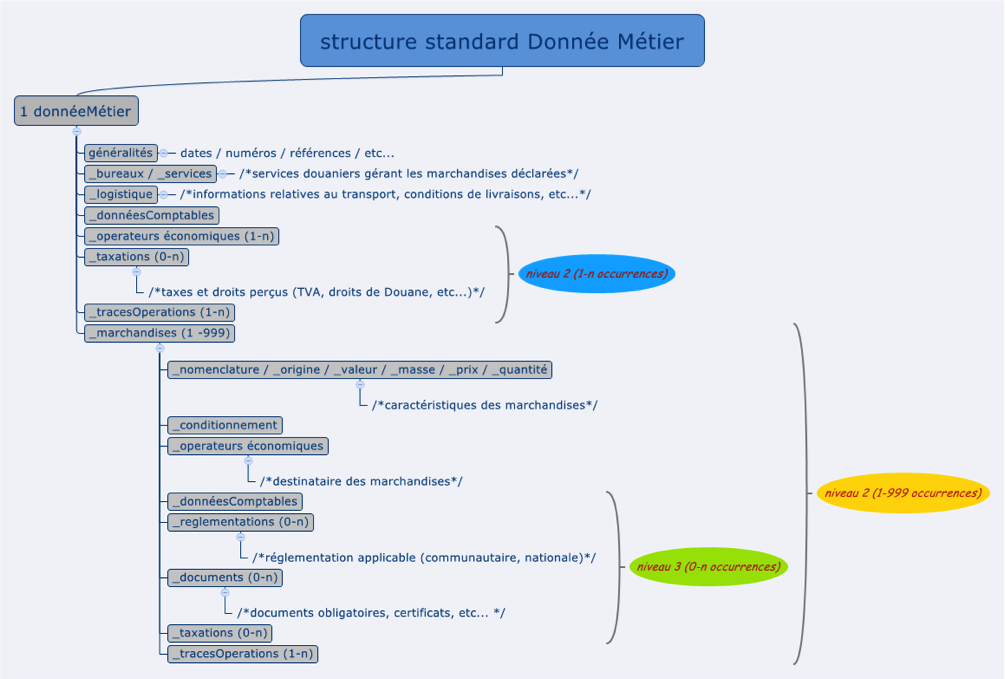
L'inventaire de ces structures de données aboutit à des centaines de rubriques pour un même type de flux.
2. Le volume des données
Chaque année, le système informatique de la Douane traite, exploite, analyse, contrôle et taxe des millions de déclarations : cela génère des centaines de millions de marchandises déclarées. Le stockage de ces données nécessite des dizaines de téra-octets.
3. Les temps de réponse
Dans ce contexte, concevoir une application informatique performante et apte à
- traiter les flux de marchandises des opérateurs économiques,
- stocker ces flux sur le long terme (10 ans),
- offrir des fonctionnalités de recherche avancées
s'avère délicat.
Tout est question de point de vue...
1. SGBDR / SQL
Utiliser les SGBDR et le SQL offre l'avantage de la connaissance technique partagée. Cependant, cette approche s'essouffle rapidement : le SQL à générer devient lourd, très complexe (modèle relationnel) et ne permet pas de répondre à des besoins de recherche en évolution constante. Faire évoluer un schéma de base reste une opération coûteuse (charge, impact, délais). Effectuer un travail d'optimisation des index de la base est inévitable, récurrent (mais hélas vain). Mettre en œuvre des options de partitionnement ne solutionne pas le problème de la complexité du SQL. Cette approche est inadaptée au cas d'usage Douane.
2. Infocentre décisionnel
Mettre en œuvre une solution infocentre décisionnel permet de régler la question du volume des données et des temps de réponses. Cependant, la connaissance technique reste à acquérir, le socle logiciel est conséquent et l'ensemble des besoins utilisateurs doit être connu pour mettre en œuvre les différents datamarts et calculer les cubes. La visualisation de la donnée source initiale n'est plus possible. La mise à jour des cubes en temps réel est difficile et toute évolution de la structure de donnée impacte très fortement les datamarts et les cubes. Cette approche ne satisfait pas tous les cas d'usage Douane.
3. La solution noSQL
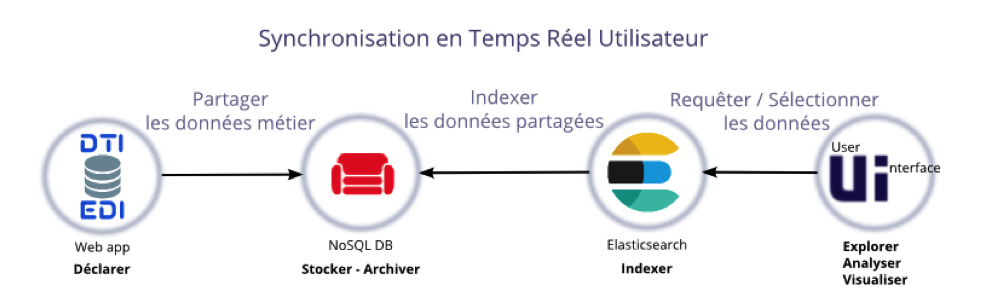
- Les applications douanières se concentrent sur leur domaine de compétence : traiter les flux de marchandises en garantissant des temps de réponse performants (fonction Déclarer).
- Un module spécifique assure le dépôt des déclarations dans une base noSQL, base de donnée orientée documents.
- Cette base de données est insensible aux structures de données variées (fonction Stocker). Configurée en cluster, elle offre haute disponibilité, résilience, réplication des données pour la synchronisation temps réel, ainsi qu'une scalabilité « à chaud » pour le stockage (fonction Archiver).
- Un module spécifique assure l'indexation de chaque flux de données (fonction Indexer). Un cluster Elasticsearch est utilisé et propose des fonctionnalités de recherches avancées.
- Des interfaces utilisateurs permettent la recherche et la sélection des données (fonctions Explorer, Analyser, Visualiser).
De la théorie à la pratique
1. Phase 1 : Proof Of Concept – Tester & Convaincre
C'est avec la version 0.17 que les tests ont débuté. Après plusieurs tentatives et plusieurs versions d’Elasticsearch, c'est finalement la version 0.19.7 qui a permis de résoudre toutes les difficultés et répondre au cas d'utilisation. En 2013, la première version opérationnelle a été lancée pour un seul flux de donnée. Cette première version utilise actuellement la version 0.90.5 d'elasticsearch, mais sera définitivement arrêtée avant fin 2016.
2. Phase 2 : Scalabilité opérationnelle
Un programme de consolidations techniques et d'extensions fonctionnelles a été réalisé durant le premier quadrimestre 2016 : la version 2 est opérationnelle depuis juin 2016. Cette version s'appuie sur Elasticsearch 1.7 et s'étend désormais sur 4 flux de données différents. De nouveaux flux sont en cours d'intégration : la plus-value apportée dans le système d'information de la Douane est inégalée.
Mise en œuvre Technique
1. Cluster : la Config
Le cluster est constitué :
- Des nœuds de données (node.data :true & node.master :false)
- Des nœuds maîtres (node.data :false & node.master :true)
Cela permet de réduire l'impact sur les données en cas de Split Brain.
Pour chaque nœud de données, la RAM est de 30 Go : les différents tests effectués sur des configurations inférieures, n'étaient pas concluants par rapport aux volumes et à la structure des données indexées.
2. Les Données : les index, le Mapping, les méta-données
Pour chaque type de donnée, les index créés ont une granularité mensuelle (AAAA-MM).
Compte tenus des besoins particuliers du cas d'usage, pour chaque type de donnée, deux séries d'index mensuels sont créées :
- Une série d'index de niveau "déclaration" : permet la recherche sur tous les niveaux de la structure de donnée et retourne un résultat de niveau "déclaration"
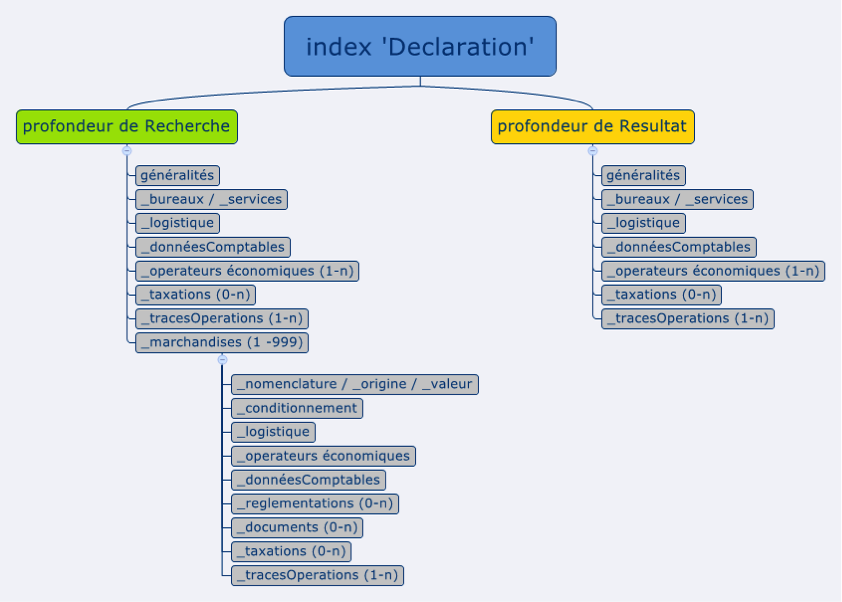
- Une série d'index de niveau "marchandise" : permet la recherche sur tous les niveaux de la structure de donnée et retourne un résultat de niveau "marchandise" (uniquement les marchandises qui correspondent aux critères de recherche)
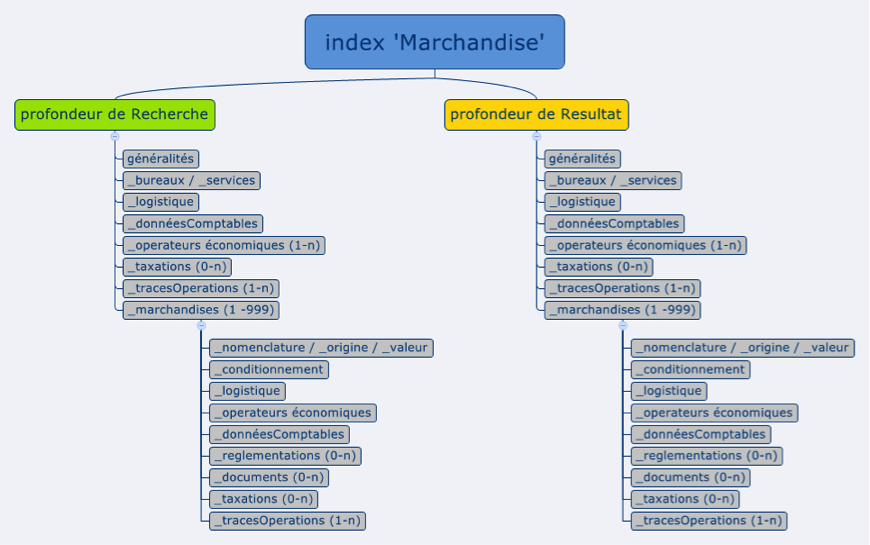
La génération des index se fait sur la base d'un mapping qui :
- Utilise des analyseurs et des filtres
- Définit des structures 'nested', (l'approche parent-child n'a pas été retenue car lors de nos tests -2012-, le chargement en mémoire des child provoquait des OutOfMemory)
- Active la réplication des données
- Partitionne les données sur 5 shards
- La notion d'alias, pour référencer les index, allège et simplifie la requête Elasticsearch.
Lors de la phase d'indexation, des templates sont utilisés pour créer les nouveaux index mensuels. Il y a un template 'Declaration' et un template 'Marchandise' par type de donnée métier.
3. Les requêtes
Les requêtes des utilisateurs sont issues des interfaces applicatives (ensemble de formulaires). Ces requêtes sont adressées au cluster par un client HTTP qui est créé pour chaque type de données métier.
Le cas d'usage recense des besoins utilisateurs principalement axés sur la recherche exacte de valeurs. Aucun besoin de recherche 'full text' n'est nécessaire. La notion _score (pertinence) n'est pas utile. Les requêtes sont de type filtered query et manipulent des filtres pour sélectionner les déclarations. Les requêtes mettent en oeuvre deux type mécanismes supplémentaires pour la présentation du résultat :
- la pagination (from, size) qui permet un confort de navigation et favorise les temps de réponse,
- la liste des rubriques attendues dans la réponse (fields du document _source).
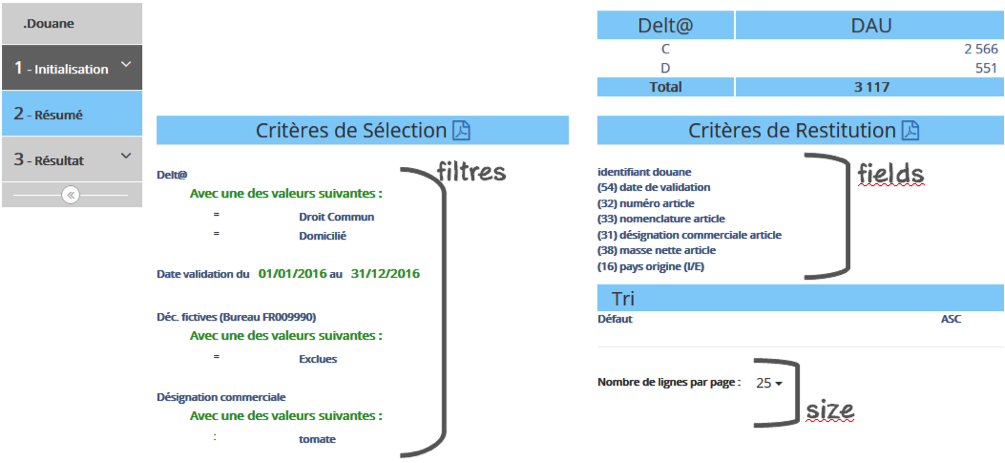
Figure 1 - Résumé de la recherche : filtres, fields, size
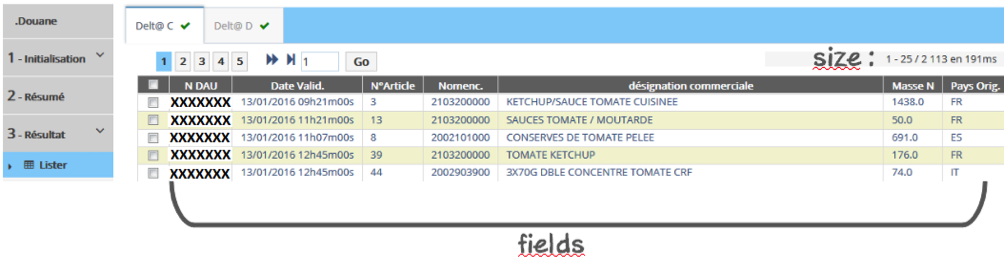
Figure 2 - Résultats de la recherche : pagination et fields
Interface Homme Machine (IHM)
1. Aide utilisateur
Pour les informations issues d'une saisie libre (information non codifiée), l'utilisateur peut appeler la fonctionnalité ‘_suggester’ pour obtenir l'ensemble des termes approchants et ainsi améliorer les critères de sélection des données. Par exemple, l’utilisation du ‘_suggester’ sur le terme ‘tomate’, informera l’utilisateur qu’il existe des déclarations ayant un terme ‘tomato’, ‘tomats’, etc.
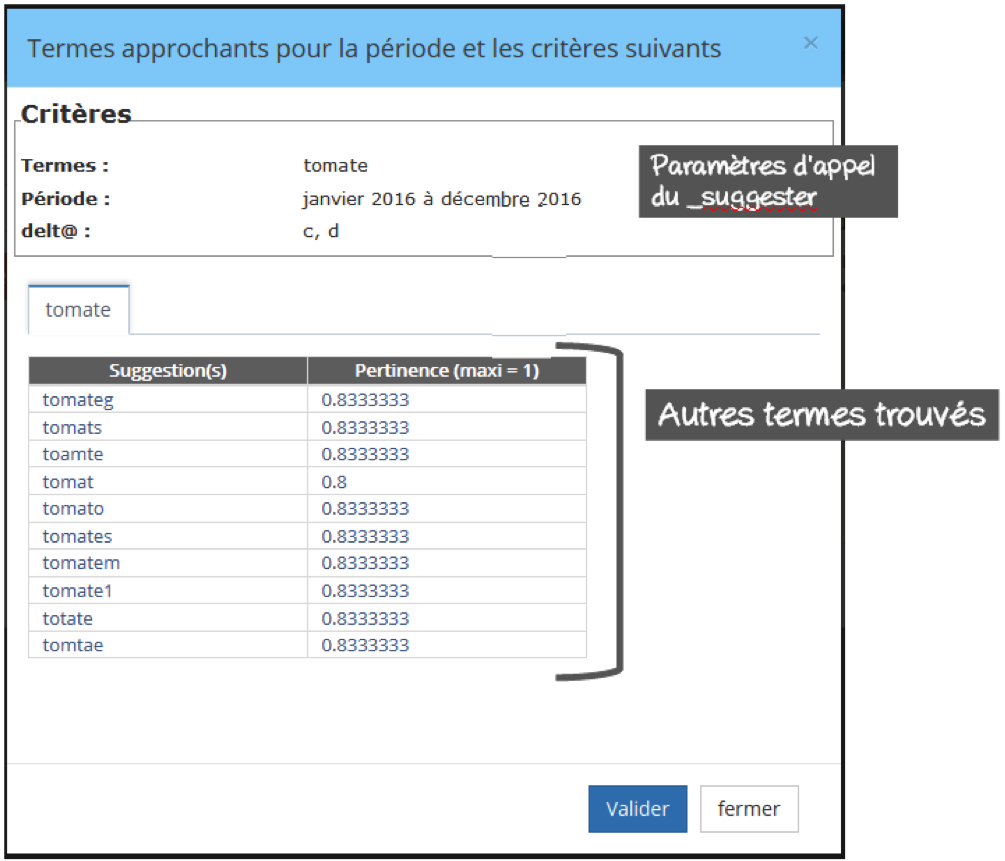
2. Visualisation
Le résultat d'une recherche peut être rendu sous deux formes :
- Une liste de lignes (tableau paginé)
- Une analyse graphique
Les fonctionnalités d'analyse d'Elasticsearch, et notamment depuis la version 1, les agrégations, offrent une puissance de visualisation et d'exploration des données remarquable.
Pouvoir répondre à tout instant à de nouveaux besoins d'analyse sans avoir à refabriquer une version applicative et/ou des index est unique !
Ces deux formes de résultats sont complémentaires : audit, suivi opérationnel global / détaillé, analyse de tendance, détection, modélisation sont facilités.
L'ère du changement
Avec la mise en œuvre de cette architecture basée sur Elasticsearch, les utilisateurs sont désormais en situation d'explorer et visualiser la totalité des informations concernant un flux de données.
Vers un autre cycle : V5
Le prochain programme technique concernera la version 5 de la Suite Elastic et de la pile logicielle elasticsearch. Certaines fonctionnalités d’X-Pack sont d'ores et déjà très attractives... (Graph, Prelert).
Intuition – Imagination – Innovation
Bravo (le mot est faible …) à Shay Banon pour ce projet à la conception remarquable.
Mention spéciale à David Pilato qui nous a suggéré en 2011 cette technologie après l’avoir mise en oeuvre sur un autre projet.
Cyril Vialard est adjoint au Chef de pôle développement du Centre Informatique Douanier. Il est notamment concepteur et architecte de la solution Elasticsearch ‘Douane’ qui permet de traiter de nombreux flux de données en temps réel. Il a également conduit le premier programme télé-service e-Customs : NCTS/NSTI.