Elasticsearch et la mise en cache, ou comment accélérer les requêtes à l'aide des caches
Pour récupérer des données rapidement, rien de tel qu'un cache. Même plusieurs. Et ce n'est pas Elasticsearch qui vous dira le contraire. Vous avez envie d'en savoir plus ? Bloquez vos 15 prochaines minutes, installez-vous confortablement et attaquez la lecture de cet article. Pour que vous puissiez récupérer rapidement les données auxquelles vous avez déjà accédé, Elasticsearch utilise différentes fonctionnalités de mise en cache. Dans cet article, nous nous intéresserons uniquement aux caches suivants :
- Cache de pages (aussi appelé cache du système de fichiers)
- Cache de requête au niveau de la partition
- Cache de requête
Vous découvrirez le fonctionnement de ces caches et apprendrez à déterminer celui qui convient le mieux à votre cas d'utilisation. Nous verrons aussi que la mise en cache sera contrôlée soit par vous directement, soit par un autre composant sur lequel vous devrez vous appuyer.
Nous aborderons également la façon dont les caches de pages gèrent l'expiration des données. Car, cela va sans dire, il est inenvisageable qu'un cache renvoie des données obsolètes. Un cache doit suivre le cycle de vie de vos données.
Vous vous demandez si cet article vous concerne ? Que vous utilisiez Elasticsearch ou Elastic Cloud, vous êtes le bienvenu ! À présent, entrons dans le vif du sujet.
Cache de pages
Le premier cache se trouve au niveau du système d'exploitation. Même si cette section concerne principalement l'implémentation Linux, d'autres systèmes d'exploitation disposent d'une fonctionnalité similaire.
Le principe de base du cache de pages consiste à placer les données dans la mémoire disponible après les avoir lues à partir du disque, afin que la prochaine lecture se fasse à partir de la mémoire, sans passer par une recherche des données sur le disque. Toute cette procédure est complètement transparente pour l'application, laquelle émet les mêmes appels système. Toutefois, le système d'exploitation a la possibilité d'utiliser le cache de pages plutôt que de procéder à une lecture à partir du disque.
Penchons-nous sur le diagramme ci-dessous. L'application exécute un appel système pour lire les données à partir du disque. Le noyau/système d'exploitation accède alors au disque pour effectuer la première lecture et place les données dans un cache de pages dans la mémoire. Une seconde lecture pourrait être redirigée par le noyau vers le cache de pages dans la mémoire du système d'exploitation, ce qui permettrait d'accélérer l'opération.
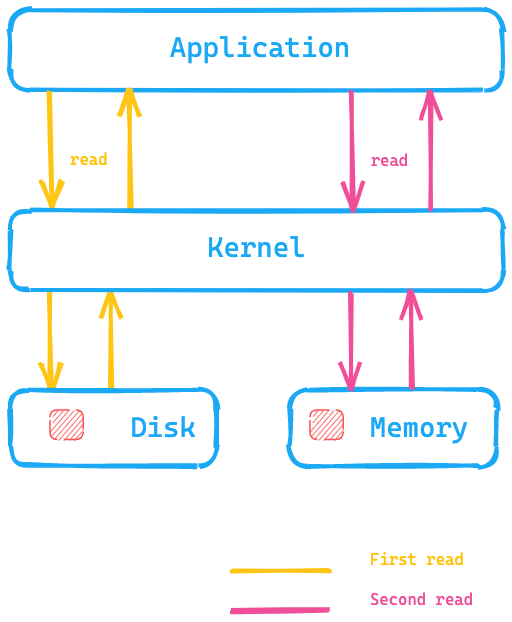
Qu'est-ce que cela signifie pour Elasticsearch ? Au lieu de lire les données à partir du disque, le moyen le plus rapide pour y accéder consiste à se servir du cache de pages. C'est l'une des raisons pour lesquelles la recommandation en matière de mémoire pour Elasticsearch est d'utiliser au maximum la moitié de votre mémoire totale disponible. Ainsi, l'autre moitié peut servir au cache de pages. Cela signifie également qu'il n'y a aucun gaspillage de mémoire, car celle-ci est réutilisée pour le cache de pages.
Comment les données expirent-elles hors du cache ? Lorsque les données sont modifiées, le cache de pages les marque comme étant non fiables. Elles sont alors libérées du cache de pages. Étant donné que les segments ne sont écrits qu'une fois avec Elasticsearch et Lucene, ce mécanisme est particulièrement adéquat pour le stockage des données. Après l'écriture initiale, les segments apparaissent en lecture seule. Ce qui signifie que, pour que les données soient modifiées, il faut qu'il y ait une fusion ou un ajout de nouvelles données. Dans un tel cas, un nouvel accès au disque s'avèrera nécessaire. Les données peuvent être également modifiées lorsque la mémoire arrive à saturation. Le cache se comportera alors de la même façon qu'un cache LRU, comme l'indique la documentation du noyau.
Test du cache de pages
Envie de tester la fonctionnalité du cache de pages ? Vous pouvez utiliser hyperfine, un outil d'évaluation comparative de CLI. Commençons par créer un fichier d'une taille de 10 Mo via dd :
dd if=/dev/urandom of=test1 bs=1M count=10
Si vous souhaitez exécuter la commande ci-dessus avec macOS, vous pouvez utiliser gdd à la place,
en veillant à ce que coreutils soit installé via brew.
# pour Linux hyperfine --warmup 5 'cat test1 > /dev/null' \ --prepare 'sudo sync; sudo echo 3 > /proc/sys/vm/drop_caches'
# pour osx hyperfine --warmup 5 'cat test1 > /dev/null' --prepare 'sudo purge' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 38.1 ms ± 6.4 ms [User: 1.4 ms, System: 17.5 ms] Range (min … max): 30.4 ms … 50.5 ms 10 runs hyperfine --warmup 5 'cat test1 > /dev/null' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 3.8 ms ± 0.6 ms [User: 0.7 ms, System: 2.8 ms] Range (min … max): 2.9 ms … 7.0 ms 418 runs
Résultat : sous mon instance macOS locale, l'exécution de la même commande cat sans effacer le cache de pages va 10 fois plus vite, car l'accès au disque peut être ignoré. Il n'y a pas à dire, c'est vraiment le schéma d'accès idéal aux données Elasticsearch !
Étude approfondie
Pour lire un index Lucene, la classe à utiliser est HybridDirectory. Selon l'extension des fichiers se trouvant dans l'index Lucene, vous devrez décider soit d'utiliser un mapping de mémoire, soit d'utiliser un accès standard aux fichiers à l'aide de Java NIO.
Remarque : Certaines applications sont plus sensibles que d'autres à leur propre schéma d'accès. Elles sont accompagnées de leurs propres caches et de caches optimisés. Le cache de pages risque de les contrer. Si nécessaire, une application peut contourner le cache en utilisant O_DIRECT à l'ouverture d'un fichier. Nous y reviendrons à la fin de cet article.
Si vous souhaitez connaître le taux d'accès au cache, vous pouvez vous servir de cachestat, qui fait partie de perf-tools.
Une dernière chose concernant Elasticsearch. Vous pouvez configurer Elasticsearch pour qu'il charge préalablement les données dans le cache de pages à l'aide des paramètres d'index. Attention toutefois : ce paramétrage demande une certaine expertise. Aussi, faites attention à ne pas évincer le cache de pages.
Résumé
Le cache de pages permet d'accélérer l'exécution de recherches arbitraires en chargeant des structures complètes de données d'index dans la mémoire principale de votre système d'exploitation. Il s'agit d'un cache général, qui se base uniquement sur le schéma d'accès à vos données. Le système d'exploitation se charge de l'expulsion.
Passons maintenant au prochain niveau de cache.
Cache de requête au niveau de la partition
Ce cache permet d'accélérer Kibana en mettant en cache les réponses aux recherches qui se composent uniquement d'agrégations. Combinons la réponse d'une agrégation avec des données extraites de plusieurs index pour visualiser le problème résolu par ce cache.
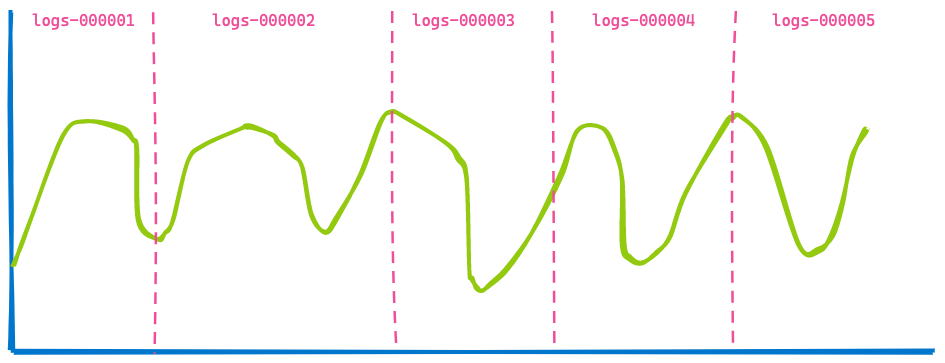
En général, un tableau de bord Kibana affiche les données de plusieurs index. Votre mission à vous consiste simplement à définir un intervalle, par exemple, les 7 derniers jours. Vous n'avez pas à vous préoccuper du nombre d'index ou de partitions qui ont été interrogés dans le cadre de la requête. De ce fait, si vous utilisez des flux de données pour vos index temporels, vous devriez obtenir une visualisation de ce type (ici, cinq index ont été utilisés) :
À présent, avançons dans le temps et voyons comment le tableau de bord se présente trois heures après :
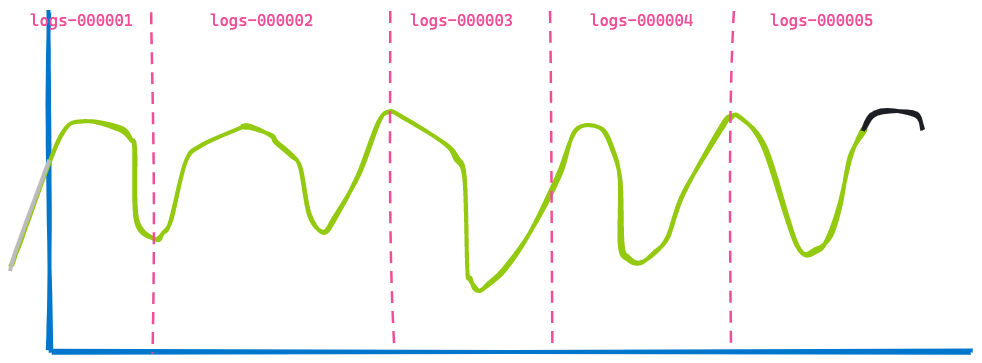
La deuxième visualisation ressemble beaucoup à la première. Certaines données n'apparaissent plus étant donné qu'elles sont anciennes (à gauche de la ligne bleue), tandis que de nouvelles données ont été ajoutées à la fin (ligne noire). Maintenant, pouvez-vous déterminer ce qui n'a pas changé ? Ce sont les données renvoyées par les index logs-000002, logs-000003 et logs-000004.
Même si ces données avaient été dans le cache de pages, nous aurions tout de même dû exécuter la recherche et l'agrégation sur la base des résultats. Aussi, inutile de faire ce double travail. Pour cela, une optimisation supplémentaire a été ajoutée à Elasticsearch : la possibilité de réécrire une requête. Au lieu d'indiquer une plage temporelle pour les index de logs logs-000002, logs-000003 et logs-000004, nous pouvons réécrire la requête en match_all en interne, car chaque document de cet index correspond à la plage temporelle (d'autres filtres peuvent s'appliquer, bien entendu). Avec cette réécriture, les deux requêtes aboutissent finalement à une seule et même requête sur ces trois index et peuvent donc être mises en cache.
Nous disposons maintenant d'un cache de requête au niveau de la partition. Le principe consiste à mettre en cache la réponse intégrale d'une requête, pour ne pas avoir à faire de recherche et pour renvoyer la réponse instantanément, à condition cependant que les données n'aient pas été modifiées entretemps.
Étude approfondie
Le composant responsable de la mise en cache est la classe IndicesRequestCache. Cette méthode est utilisée dans SearchService lors de l'exécution de la requête. Une vérification supplémentaire permet de déterminer si une requête est éligible à la mise en cache. Par exemple, les requêtes profilées ne sont jamais mises en cache pour éviter de biaiser les résultats.
Ce cache est activé par défaut. Il peut prendre jusqu'à 1 % du bloc total et peut être même configuré en fonction de la requête si vous le souhaitez. Par défaut, ce cache est activé pour les requêtes de recherche qui ne renvoient aucun résultat. Comme une requête de visualisation Kibana ! Vous pouvez toutefois activer ce cache même si des résultats sont renvoyés. Pour cela, il vous suffit de modifier le paramétrage.
Pour récupérer les statistiques relatives à l'utilisation de ce cache, passez par :
GET /_nodes/stats/indices/request_cache?human
Résumé
Le cache de requête au niveau de la partition mémorise la réponse intégrale à une requête de recherche et la renvoie si la même requête est exécutée à nouveau, sans passer par le disque ou le cache de pages. Comme son nom l'indique, cette structure de données est liée à la partition qui contient les données et ne renverra jamais de données obsolètes.
Cache de requête
Le cache de requête est le dernier cache dont nous parlerons dans cet article. Là encore, la façon dont ce cache fonctionne est différente de celle des autres caches. Le cache de pages met en cache les données, indépendamment du volume d'entre elles qui sont réellement lues à partir d'une requête. Le cache de requête au niveau de la partition met en cache les données lorsqu'une requête similaire est utilisée. Le cache de requête va encore plus loin dans le détail et peut mettre en cache les données qui sont réutilisées d'une requête à l'autre.
Voyons comment fonctionne ce cache. Imaginons que nous fassions une recherche sur des logs. Trois utilisateurs différents parcourent les données du mois en cours. Néanmoins, chacun d'eux utilise un terme de recherche différent :
- L'utilisateur 1 fait une recherche sur le terme "échec".
- L'utilisateur 2 fait une recherche sur le terme "exception".
- L'utilisateur 3 fait une recherche sur le terme "pcre2_get_error_message".
Chacune des recherches renvoie des résultats différents. Pourtant, la plage temporelle prise en compte est la même. C'est là qu'intervient le cache de requête : il est capable de mettre en cache juste une partie d'une requête. Le principe de base consiste à mettre en cache les informations et de ne faire une recherche que sur les documents mis en cache, sans passer par le disque. Votre requête ressemblera probablement à l'exemple ci-dessous :
GET logs-*/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "pcre2_get_error_message"
}
}
],
"filter": [
{
"range": {
"@timestamp": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
}
]
}
}
}
Pour chaque requête, la partie filter reste la même. Il s'agit là d'une vue extrêmement simplifiée de la présentation des données dans un index inversé. Chaque horodatage est mappé à un ID de document.
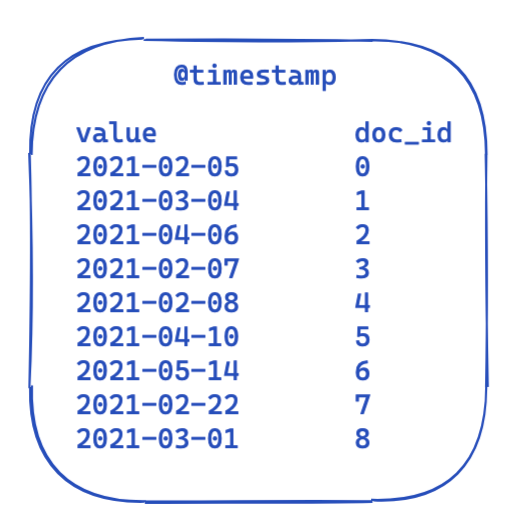
Aussi, comment optimiser ces éléments et les réutiliser d'une requête à l'autre ? L'heure est venue pour les tableaux de bits de faire leur entrée. Un tableau de bits est un tableau dans lequel chaque bit représente un document. Nous pouvons créer un tableau de bits pour ce filtre @timestamp spécifique couvrant une période d'un mois. Un 0 signifie que le document est en dehors de cette plage temporelle, tandis qu'un 1 signifie que le document y est. Le tableau de bits ressemblerait alors à l'exemple ci-dessous :
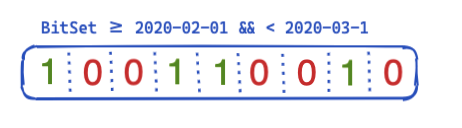
Une fois le tableau de bits créé sur une base par segment (ce qui signifie qu'il devra être recréé après une fusion ou à la création d'un nouveau segment), la prochaine requête n'a pas besoin d'accéder au disque pour exclure cinq documents avant même d'exécuter le filtre. Les tableaux de bits présentent des propriétés intéressantes. Tout d'abord, il est possible de les combiner. Si vous disposez de deux filtres et de deux tableaux de bits, vous pouvez facilement déterminer les documents où ces deux bits sont définis, ou fusionner une requête OR. Autre aspect intéressant des tableaux de bits : la compression. Par défaut, vous avez besoin d'un bit par document par filtre. Toutefois, si vous utilisez une autre implémentation que des tableaux de bits fixes, par exemple les roaring bitmaps, vous pouvez réduire les besoins en mémoire.
Concrètement, comment cela est-il implémenté dans Elasticsearch et Lucene ? C'est ce que nous allons voir.
Étude approfondie
Elasticsearch dispose d'une classe IndicesQueryCache. Cette classe est liée au cycle de vie d'IndicesService, ce qui signifie qu'il ne s'agit pas d'une fonctionnalité par index, mais d'une fonctionnalité par nœud. Et c'est plutôt logique, étant donné que le cache en tant que tel se sert du bloc Java. Ce cache de requête d'index propose deux options de configuration :
indices.queries.cache.count: nombre total d'entrée de cache ; par défaut, 10 000.indices.queries.cache.size: pourcentage du bloc Java utilisé pour ce cache ; par défaut, 10 %.
Dans le constructeur IndicesQueryCache, un nouvel élément ElasticsearchLRUQueryCache est défini. Ce cache s'étend à partir de la classe LRUQueryCache de Lucene. Cette classe dispose du constructeur suivant :
public LRUQueryCache(int maxSize, long maxRamBytesUsed) {
this(maxSize, maxRamBytesUsed, new MinSegmentSizePredicate(10000, .03f), 250);
}
L'élément MinSegmentSizePredicate garantit que seuls les segments comptant au moins 10 000 documents sont éligibles à la mise en cache et disposent de plus de 3 % du nombre total de documents de la partition.
À partir de là, les choses se compliquent un peu. Même si les données se trouvent dans le bloc JVM, il y a un autre mécanisme qui suit les parties de requête les plus communes et place uniquement celles-ci dans ce cache. Or, ce suivi se fait au niveau de la partition. Il y a une classe UsageTrackingQueryCachingPolicy qui utilise un élément FrequencyTrackingRingBuffer (implémenté à l'aide de tableaux d'entiers à taille fixe). Cette politique de mise en cache applique des règles supplémentaires dans sa méthode shouldNeverCache, laquelle empêche de mettre en cache certaines requêtes, comme les requêtes de termes, les requêtes "match all"/"no docs" ou les requêtes vides, car celles-ci sont suffisamment rapides pour qu'il ne soit pas nécessaire de les mettre en cache. Pour qu'une requête soit éligible à la mise en cache, elle doit avoir une fréquence minimale. Cette condition permet de s'assurer que le cache ne soit pas plein à la suite d'une simple invocation. Vous pouvez suivre l'utilisation, le taux d'accès au cache et d'autres informations via :
GET /_nodes/stats/indices/query_cache?human
Résumé
Le cache de requête va encore plus loin dans la précision. L'avantage, c'est qu'il est possible de le réutiliser d'une requête à l'autre. Avec sa fonctionnalité heuristique intégrée, ce cache met uniquement en cache les filtres qui sont utilisés plusieurs fois. Par ailleurs, selon le filtre appliqué, il décide s'il est préférable d'effectuer la mise en cache ou si la méthodologie de requête existante est suffisamment rapide pour éviter de gaspiller un segment de mémoire. Le cycle de vie des tableaux de bits est lié au cycle de vie d'un segment, afin d'empêcher que des données obsolètes soient renvoyées. Lorsqu'un nouveau segment est utilisé, un nouveau tableau de bits doit être créé.
Les caches sont-ils la seule option pour accélérer les choses ?
Sans surprise, la réponse est : ça dépend. Un développement récent du noyau Linux est plutôt prometteur : io_uring. Il s'agit d'une nouvelle méthode pour exécuter des entrées-sorties asynchrones sous Linux à l'aide des files d'attente d'achèvement disponibles depuis Linux 5.1. Notez que io_uring est toujours en développement. Cependant, quelques essais ont déjà été réalisés pour utiliser io_uring dans l'univers Java, comme avec netty. Et on peut vous le dire : les tests de performances effectués pour de simples applications sont épatants. Il va falloir néanmoins attendre un peu avant d'obtenir les résultats des performances réelles, mais on s'attend à une petite révolution. Croisons les doigts pour que cette méthode soit prise en charge à un moment donné au sein du JDK. Il est prévu de prendre en charge io_uring dans le cadre du Project Loom, ce qui permettrait d'intégrer io_uring à la JVM. D'autres optimisations, comme la capacité à suggérer le schéma d'accès au noyau Linux via madvise(), ne sont pas encore proposées non plus pour la JVM. La suggestion empêche au noyau d'effectuer une lecture par anticipation, c'est-à-dire d'essayer de lire plus de données qu'il n'en faudrait en prévision de la prochaine lecture, ce qui est inutile lorsqu'un accès aléatoire est requis.
Et ce n'est pas tout. Comme toujours, les développeurs de Lucene travaillent d'arrache-pied pour tirer le meilleur parti d'un système, quel qu'il soit. Une première ébauche d'une réécriture de Lucene MMapDirectory à l'aide de l'API d'accès à la mémoire directe devrait être proposée en préversion dans Java 16. Toutefois, elle n'a pas été réalisée dans une optique de performances, mais dans le but de surmonter certaines limitations de l'implémentation MMap actuelle.
Autre changement récent dans Lucene : la suppression des extensions natives grâce à l'utilisation d'entrées-sorties directes (O_DIRECT) dans la classe FileChannel. Cela signifie que l'écriture des données ne malmènera pas le cache de pages. Cette fonctionnalité sera proposée dans Lucene 9.
Parfois, vous pouvez aussi accélérer les choses pour ne pas avoir à penser au cache, afin de réduire la complexité de vos opérations. Récemment, les agrégations date_histogram ont fait l'objet de plusieurs améliorations. Pour en savoir plus, prenez votre temps pour lire cet article sur le sujet. Il regorge d'informations !
Un autre très bon exemple d'amélioration (sans mise en cache) est l'implémentation de l'algorithme Block-Max WAND dans Elasticsearch 7.0. Pour en savoir plus, consultez cet article d'Adrien Grand.
Conclusion sur les caches
J'espère que vous avez apprécié ce petit tour d'horizon des caches et que vous comprenez désormais quand utiliser quel cache. Comme nous l'avons vu, il est très utile de monitorer vos caches, en particulier pour déterminer si un cache est approprié ou s'il est constamment évincé lors d'un ajout ou d'une expiration. Une fois le monitoring de votre cluster Elastic activé, vous pouvez consulter la consommation de mémoire du cache de requête et du cache de requête au niveau de la partition dans l'onglet Advanced (Avancé) d'un nœud. Vous pouvez aussi la déterminer par index, si vous étudiez un index spécifique :
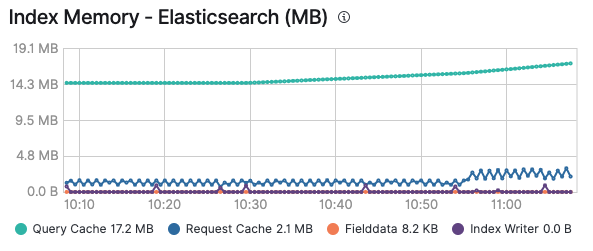
Ces caches sont utilisés par l'ensemble des solutions existantes adossées à la Suite Elastic. Ils leur permettent d'exécuter les requêtes et de fournir les données recherchées avec une vitesse inégalée. Pour rappel, d'un simple clic, vous pouvez activer le logging et le monitoring dans Elastic Cloud pour que tous vos clusters soient monitorés, sans frais supplémentaires. Jugez-en par vous-même !